 Your new post is loading...

|
Scooped by
Charles Tiayon
September 19, 2022 10:33 PM
|
Sur Netflix, Disney+ ou TF1, ils sont toujours présents, pour accompagner les meilleurs films et séries : les sous-titreurs et auteurs de doublages sont les héros de l’ombre de nos œuvres favorites. Si vous avez toujours rêvé de savoir pourquoi Elfe est le surnom de Eleven dans Stranger Things, vous êtes au bon endroit ! Vous avez probablement déjà vécu cette situation : vous êtes tranquillement installé dans votre canapé, devant votre série ou votre film préféré, et vous avez activé la VO sous-titrée en français. Et, là, malheur, vous vous apercevez que la traduction écrite ne correspond pas au texte des acteurs en langue originale. Avant de décrocher votre plus belle plume pour concocter un tweet assassin contre votre plateforme de SVOD, on vous invite plutôt à découvrir le métier de celles et ceux qui sont si souvent décriés : les sous-titreurs et auteurs de doublage. Ces traducteurs travaillent dans l’ombre pour nous permettre de savourer nos séries du moment, sans avoir à devenir bilingue en anglais, en espagnol ou en coréen du jour au lendemain. Le doublage, un univers méconnu Pour les amateurs de VF, ce sont les auteurs ou adaptateurs de doublages qui vous sauvent la mise. Un travail complexe qui doit respecter plusieurs règles : traduire l’œuvre d’origine sans trahir le propos, respecter la synchronisation labiale qui permet au texte d’être calé sur les mouvements de bouches des acteurs… François Dubuc, qui a travaillé sur l’adaptation de la récente Sandman sur Netflix, le faisait justement remarquer dans un thread publié sur Twitter le 19 août 2022, après la sortie de la série. Il y explique comment, avec son collègue Jonathan Amram, ils ont écrit la traduction de la première saison et quels choix ont été opérés pour conserver l’esprit de la bande dessinée originelle. J'ai vu passer quelques remarques sur certains de nos choix d'adaptation pour la VF de #TheSandman.
Je me permets donc de revenir dessus.
– Nous avons choisi de garder Morpheus en VF au lieu de Morphée comme dans la BD pour une stricte question de synchro.
1/7 — François Dubuc (@dubfra_adapt) August 19, 2022 Ces choix difficiles, Caroline Lecoq les expérimente également sur chacun de ses nouveaux projets. L’autrice de doublage indépendante, qui a notamment voyagé dans l’Upside Down pour traduire les quatre saisons de Stranger Things, traite généralement avec des studios spécialisés, qui servent d’intermédiaires avec la plateforme de diffusion, comme Netflix. Vous avez peut-être déjà aperçu le nom de Dubbing Brothers, par exemple, à la fin de certains génériques. Pour les longs projets comme des séries, les adaptateurs de doublage travaillent généralement en binômes. « Le studio et le directeur artistique nous envoient des notes de traduction, avec les termes que l’on doit garder ou au contraire ceux que l’on doit adapter », détaille Caroline Lecoq. On peut voir ça comme du soutien à la traduction, en plus de notre travail de recherche et de lecture en amont, si l’œuvre est tirée d’un livre par exemple. » El ou Elfe ? Parfois, certaines consignes sont tout de même plus difficiles à mettre en place que d’autres. Avec sa collègue Fanny Béraud, Caroline Lecoq a ainsi dû trouver un surnom français à Eleven, surnommée El en anglais dans Stranger Things. « On s’est pris des cailloux par certains spectateurs pour ça, mais déjà, il était totalement logique de traduire Eleven en Onze. Netflix nous avait confirmé que ce numéro avait une importance dans l’histoire et que d’autres personnages feraient leur apparition. D’autant que dans la scène où l’on apprend son prénom, un protagoniste voit le chiffre tatoué sur son bras, donc la logique française l’empêche de dire ‘Ah Eleven !’. Pour le surnom, c’était une demande de Netflix, donc nous avons décidé de créer Elfe, en référence au fait que les personnages de la série jouent à Donjons et Dragons et qu’ils trouvent Eleven dans la forêt. » Sur la première saison, une séquence a également posé un problème : la scène des lettres sur le mur, illuminées par Will pour communiquer avec Joyce depuis l’Upside Down. « Dès qu’il y a un texte écrit à l’écran, c’est un peu notre bête noire puisqu’il est difficile de le contourner et de le traduire. Là, dans Stranger Things, Will épelle visuellement « Right here » sur le mur et en français Joyce répète « Juste ici ». On nous avait demandé trois propositions de traduction pour cette scène et, selon moi, ils ont choisi la pire solution. On l’a su à la diffusion en plus, donc j’étais horrifiée de découvrir le résultat en regardant l’épisode, mais cela arrive malheureusement. » Entre 7 et 10 minutes traduites par jour Mais, pour Caroline Lecoq, travailler pour Netflix n’est pas forcément plus difficile que de créer des adaptations pour TF1, au contraire : « En général, on est même presque plus libres lorsqu’on écrit pour une plateforme que pour une chaîne de télévision classique. En France, le CSA fait très attention à ce qui est diffusé et à quelle heure. Pour TF1, qui est une chaîne populaire, on doit être attentif à ne pas faire l’apologie de l’alcool, à ne pas utiliser des mots trop compliqués ou à ne pas conserver le nom des marques. Parfois, on ne peut donc pas être entièrement conformes à la VO, pour qu’un public non averti ne soit pas heurté. » Matt Damon devant une télé dans Bienvenue à Suburbicon. // Source : Concorde Filmverleih GmbH / Hilary Bronwyn Gayle L’adaptatrice de doublage estime tout de même que son travail n’est pas si différent d’une chaîne à l’autre. « Le processus est en général le même : en tant qu’adaptateurs de doublage, on écrit entre 7 et 10 minutes d’épisodes par jour, donc les studios nous laissent au minimum ce temps nécessaire pour la traduction. Ensuite, notre travail est relu par le directeur artistique en amont, avant l’enregistrement des voix avec les comédiens. » Sous-titrage et doublage : deux métiers distincts Du côté des sous-titreurs aussi, la tâche n’est pas aisée. Si vous êtes plutôt amateurs de VO, c’est leur travail qui vous change la vie lors de soirées Netflix & Chill. Si certains aspects sont communs au doublage, les deux métiers restent complètement différents. « La contrainte de lisibilité du sous-titreur et celle de la synchronisation labiale du doublage imposent deux styles de traduction », estime Sylvain Caschelin, sous-titreur et responsable du Master 2 Traduction audiovisuelle et accessibilité à l’Université de Strasbourg. Nathan Tardy, également auteur de traduction audiovisuelle, le confirme : « Là où le doublage doit coller aux lèvres, en sous-titrage, nous avons des limites de temps et de caractère à respecter. Nous avons donc chacun des énigmes différentes à résoudre. » Le cerveau des sous-titreurs et des doubleurs lorsqu’ils travaillent. // Source : Giphy Pour Netflix, par exemple, les sous-titres ne doivent pas excéder 17 caractères par seconde de dialogue, pour être considérés comme faciles à lire. « Cela dépend également du type de produit », précise Sylvain Caschelin. « Dans un programme de télé-réalité, les protagonistes parlent vite, se coupent beaucoup et il y a énormément de texte, donc cela peut être compliqué. À l’inverse, certains documentaires sont plus contemplatifs. Mais, la difficulté principale, c’est le temps donné pour travailler, qui est extrêmement variable : avec Arte, on peut avoir un mois et demi pour traduire un film de 90 minutes, tandis que pour Netflix, on peut avoir 3 ou 4 jours pour écrire un épisode de 44 minutes. Netflix ne nous met pas forcément plus de pression, mais on sait que si l’on accepte de travailler pour eux, ça se passera comme ça. » « Je ne traduis pas des mots, je traduis une idée » Caroline Lecoq En parallèle de toutes ces contraintes techniques, les adaptateurs de doublage et sous-titreurs doivent par ailleurs faire face au cœur de leur métier : les choix de traduction en eux-mêmes. Pour Nathan Tardy, les adaptations dépendent largement de l’auteur : « Qu’importe le texte, chaque traducteur va l’adapter à sa manière, selon ses connaissances, son contexte, son interprétation de certains éléments… Selon moi, le plus important est de conserver l’âme du texte, tout en le rendant immédiatement compréhensible. Parfois, on a beau retourner un problème dans tous les sens, on ne trouve pas d’adaptation satisfaisante, notamment avec des cultures très différentes de la nôtre. C’est le cas des animes japonais, sur lesquels je travaille régulièrement, et dont l’humour et les jeux de mots sont complexes à retranscrire. Mais, tant que ma traduction est comprise par mon public, je considère que mon travail est réussi. » Pas facile de traduire les blagues de The Office, par exemple. // Source : NBC Sylvain Caschelin partage ce constat : « On se demande toujours si nos parents comprendraient une blague, par exemple. En écrivant des sous-titres, il faut aussi constamment trouver un équilibre entre la langue parlée et écrite. Si notre œil s’arrête sur un mot que l’on a jamais vu écrit alors qu’on l’entend sans problème, comme ‘seum’, on va rater les trois sous-titres suivants et il ne faut surtout pas que cela arrive. » De son côté, Caroline Lecoq vit certains choix de traduction comme des « crève-cœurs », mais essaie toujours de se concentrer sur le principe général : « Je ne traduis pas des mots, je traduis une idée et j’essaie de le faire de façon spontanée, pour que cela soit naturel dans la bouche des acteurs. » La rentabilité avant tout Régulièrement critiquées, notamment sur les réseaux sociaux, mais aussi parfois par les traducteurs eux-mêmes comme sur le film Roma en 2019, les adaptations ne sont pas si simples à mettre en œuvre. Caroline Lecoq, elle, ne lit plus les retours puisque, « en général, les gens n’aiment pas la VF, donc ce n’est jamais très gentil. C’est un métier souvent méprisé, mais il est facile de critiquer lorsqu’on ne connaît pas les tenants et les aboutissants. À moins d’être né Dieu du doublage ou du sous-titrage, on reste des êtres humains. Parfois, on se trompe. Puis, le streaming a malheureusement vu naître des traductions littérales à n’en plus finir. » Nathan Tardy le confirme : la traduction est souvent le dernier wagon de la production. « Netflix, comme les autres plateformes, vise avant tout la rentabilité. Bien sûr, on fait tous des erreurs de temps en temps. Mais, quand cela s’étend sur des épisodes entiers, c’est forcément qu’il y a eu un problème général : soit le délai alloué à la traduction était trop serré pour travailler dans de bonnes conditions, soit le budget était si bas que le sous-titrage a été confié à des amateurs, car les professionnels refusaient le contrat… Les causes sont multiples et proviennent bien souvent d’un manque d’organisation, de rigueur ou de rémunération de la part du diffuseur. La traduction est le pilier du succès de Netflix dans tous les pays non anglophones. Cependant, l’entreprise a l’air d’avoir encore un peu de mal à le comprendre, d’où la médiocrité de certaines traductions qu’elle héberge. » Nous devant certains sous-titres automatiques. // Source : Netflix Sylvain Caschelin, traducteur depuis plus de 20 ans, a également vu le métier évoluer depuis l’apparition des plateformes de SVOD : « Certains essais de sous-titres automatiques, générés par une machine, ont été réalisés. Le problème, c’est que, très souvent, cela ne ressemble à rien. En plus de signer la mort de nos métiers, cela habitue le spectateur à lire de mauvais sous-titres, mal placés, mal traduits, et qui peuvent contenir des fautes. Cela devient extrêmement difficile, pour nous, de faire comprendre aux clients qu’ils doivent payer pour notre travail, mais aussi de faire réaliser aux spectateurs qu’il y a des personnes derrière ces sous-titres. » Alors, lorsque vous râlez sur la prétendue infériorité de la VF par rapport à la VO sous-titrée ou sur la qualité de certaines traductions, gardez cet article en tête. Rappelez-vous que des dizaines de personnes ont travaillé à son élaboration, et méritent votre considération.

Researchers across Africa, Asia and the Middle East are building their own language models designed for local tongues, cultural nuance and digital independence
"In a high-stakes artificial intelligence race between the United States and China, an equally transformative movement is taking shape elsewhere. From Cape Town to Bangalore, from Cairo to Riyadh, researchers, engineers and public institutions are building homegrown AI systems, models that speak not just in local languages, but with regional insight and cultural depth.
The dominant narrative in AI, particularly since the early 2020s, has focused on a handful of US-based companies like OpenAI with GPT, Google with Gemini, Meta’s LLaMa, Anthropic’s Claude. They vie to build ever larger and more capable models. Earlier in 2025, China’s DeepSeek, a Hangzhou-based startup, added a new twist by releasing large language models (LLMs) that rival their American counterparts, with a smaller computational demand. But increasingly, researchers across the Global South are challenging the notion that technological leadership in AI is the exclusive domain of these two superpowers.
Instead, scientists and institutions in countries like India, South Africa, Egypt and Saudi Arabia are rethinking the very premise of generative AI. Their focus is not on scaling up, but on scaling right, building models that work for local users, in their languages, and within their social and economic realities.
“How do we make sure that the entire planet benefits from AI?” asks Benjamin Rosman, a professor at the University of the Witwatersrand and a lead developer of InkubaLM, a generative model trained on five African languages. “I want more and more voices to be in the conversation”.
Beyond English, beyond Silicon Valley
Large language models work by training on massive troves of online text. While the latest versions of GPT, Gemini or LLaMa boast multilingual capabilities, the overwhelming presence of English-language material and Western cultural contexts in these datasets skews their outputs. For speakers of Hindi, Arabic, Swahili, Xhosa and countless other languages, that means AI systems may not only stumble over grammar and syntax, they can also miss the point entirely.
“In Indian languages, large models trained on English data just don’t perform well,” says Janki Nawale, a linguist at AI4Bharat, a lab at the Indian Institute of Technology Madras. “There are cultural nuances, dialectal variations, and even non-standard scripts that make translation and understanding difficult.” Nawale’s team builds supervised datasets and evaluation benchmarks for what specialists call “low resource” languages, those that lack robust digital corpora for machine learning.
It’s not just a question of grammar or vocabulary. “The meaning often lies in the implication,” says Vukosi Marivate, a professor of computer science at the University of Pretoria, in South Africa. “In isiXhosa, the words are one thing but what’s being implied is what really matters.” Marivate co-leads Masakhane NLP, a pan-African collective of AI researchers that recently developed AFROBENCH, a rigorous benchmark for evaluating how well large language models perform on 64 African languages across 15 tasks. The results, published in a preprint in March, revealed major gaps in performance between English and nearly all African languages, especially with open-source models.
Similar concerns arise in the Arabic-speaking world. “If English dominates the training process, the answers will be filtered through a Western lens rather than an Arab one,” says Mekki Habib, a robotics professor at the American University in Cairo. A 2024 preprint from the Tunisian AI firm Clusterlab finds that many multilingual models fail to capture Arabic’s syntactic complexity or cultural frames of reference, particularly in dialect-rich contexts.
Governments step in
For many countries in the Global South, the stakes are geopolitical as well as linguistic. Dependence on Western or Chinese AI infrastructure could mean diminished sovereignty over information, technology, and even national narratives. In response, governments are pouring resources into creating their own models.
Saudi Arabia’s national AI authority, SDAIA, has built ‘ALLaM,’ an Arabic-first model based on Meta’s LLaMa-2, enriched with more than 540 billion Arabic tokens. The United Arab Emirates has backed several initiatives, including ‘Jais,’ an open-source Arabic-English model built by MBZUAI in collaboration with US chipmaker Cerebras Systems and the Abu Dhabi firm Inception. Another UAE-backed project, Noor, focuses on educational and Islamic applications.
In Qatar, researchers at Hamad Bin Khalifa University, and the Qatar Computing Research Institute, have developed the Fanar platform and its LLMs Fanar Star and Fanar Prime. Trained on a trillion tokens of Arabic, English, and code, Fanar’s tokenization approach is specifically engineered to reflect Arabic’s rich morphology and syntax.
India has emerged as a major hub for AI localization. In 2024, the government launched BharatGen, a public-private initiative funded with 235 crore (€26 million) initiative aimed at building foundation models attuned to India’s vast linguistic and cultural diversity. The project is led by the Indian Institute of Technology in Bombay and also involves its sister organizations in Hyderabad, Mandi, Kanpur, Indore, and Madras. The programme’s first product, e-vikrAI, can generate product descriptions and pricing suggestions from images in various Indic languages. Startups like Ola-backed Krutrim and CoRover’s BharatGPT have jumped in, while Google’s Indian lab unveiled MuRIL, a language model trained exclusively on Indian languages. The Indian governments’ AI Mission has received more than180 proposals from local researchers and startups to build national-scale AI infrastructure and large language models, and the Bengaluru-based company, AI Sarvam, has been selected to build India’s first ‘sovereign’ LLM, expected to be fluent in various Indian languages.
In Africa, much of the energy comes from the ground up. Masakhane NLP and Deep Learning Indaba, a pan-African academic movement, have created a decentralized research culture across the continent. One notable offshoot, Johannesburg-based Lelapa AI, launched InkubaLM in September 2024. It’s a ‘small language model’ (SLM) focused on five African languages with broad reach: Swahili, Hausa, Yoruba, isiZulu and isiXhosa.
“With only 0.4 billion parameters, it performs comparably to much larger models,” says Rosman. The model’s compact size and efficiency are designed to meet Africa’s infrastructure constraints while serving real-world applications. Another African model is UlizaLlama, a 7-billion parameter model developed by the Kenyan foundation Jacaranda Health, to support new and expectant mothers with AI-driven support in Swahili, Hausa, Yoruba, Xhosa, and Zulu.
India’s research scene is similarly vibrant. The AI4Bharat laboratory at IIT Madras has just released IndicTrans2, that supports translation across all 22 scheduled Indian languages. Sarvam AI, another startup, released its first LLM last year to support 10 major Indian languages. And KissanAI, co-founded by Pratik Desai, develops generative AI tools to deliver agricultural advice to farmers in their native languages.
The data dilemma
Yet building LLMs for underrepresented languages poses enormous challenges. Chief among them is data scarcity. “Even Hindi datasets are tiny compared to English,” says Tapas Kumar Mishra, a professor at the National Institute of Technology, Rourkela in eastern India. “So, training models from scratch is unlikely to match English-based models in performance.”
Rosman agrees. “The big-data paradigm doesn’t work for African languages. We simply don’t have the volume.” His team is pioneering alternative approaches like the Esethu Framework, a protocol for ethically collecting speech datasets from native speakers and redistributing revenue back to further development of AI tools for under-resourced languages. The project’s pilot used read speech from isiXhosa speakers, complete with metadata, to build voice-based applications.
In Arab nations, similar work is underway. Clusterlab’s 101 Billion Arabic Words Dataset is the largest of its kind, meticulously extracted and cleaned from the web to support Arabic-first model training.
The cost of staying local
But for all the innovation, practical obstacles remain. “The return on investment is low,” says KissanAI’s Desai. “The market for regional language models is big, but those with purchasing power still work in English.” And while Western tech companies attract the best minds globally, including many Indian and African scientists, researchers at home often face limited funding, patchy computing infrastructure, and unclear legal frameworks around data and privacy.
“There’s still a lack of sustainable funding, a shortage of specialists, and insufficient integration with educational or public systems,” warns Habib, the Cairo-based professor. “All of this has to change.”
A different vision for AI
Despite the hurdles, what’s emerging is a distinct vision for AI in the Global South – one that favours practical impact over prestige, and community ownership over corporate secrecy.
“There’s more emphasis here on solving real problems for real people,” says Nawale of AI4Bharat. Rather than chasing benchmark scores, researchers are aiming for relevance: tools for farmers, students, and small business owners.
And openness matters. “Some companies claim to be open-source, but they only release the model weights, not the data,” Marivate says. “With InkubaLM, we release both. We want others to build on what we’ve done, to do it better.”
In a global contest often measured in teraflops and tokens, these efforts may seem modest. But for the billions who speak the world’s less-resourced languages, they represent a future in which AI doesn’t just speak to them, but with them."
Sibusiso Biyela, Amr Rageh and Shakoor Rather
20 May 2025
https://www.natureasia.com/en/nmiddleeast/article/10.1038/nmiddleeast.2025.65
#metaglossia_mundus

The Language Translation Device Market was valued at USD 1.22 billion in 2023 and is projected to reach USD 3.46 billion by 2032, registering a CAGR of 12.37% from 2024 to 2032.”
"Language Translation Device Market is growing rapidly due to AI advances, global travel, digital use, and cross-cultural communication demand.
Pune, June 25, 2025 (GLOBE NEWSWIRE) -- Language Translation Device Market Size Analysis:
“The Language Translation Device Market was valued at USD 1.22 billion in 2023 and is projected to reach USD 3.46 billion by 2032, registering a CAGR of 12.37% from 2024 to 2032.”
This expansion is mainly the product of the increase of globalization, the boom of international tourism as well as the increasing demand for real-time, portable and interchangeable communication tools. The increasing penetration of cross-border business and the rising usage of language translators in government, education, medical and other domains are also expected to drive the market growth. Moreover, the development of AI-based translation technology and the integration of voice recognition and neural machine translation functions are improving product accuracy and industry popularity.
The U.S. Language Translation Device Market was valued at USD 0.30 billion in 2023 and is anticipated to reach USD 0.84 billion by 2032, growing at a CAGR of 12.13% from 2024 to 2032. Growth is fueled by increasing international travel, diverse multilingual populations, and demand for real-time communication solutions."
https://finance.yahoo.com/news/language-translation-device-market-reach-140000631.html
#metaglossia_mundus

International (MNN) -- unfoldingWord tools and technology expedite the Bible translation process.
"It often requires Western missionary linguists to spend years learning a language and then carefully translating the Bible, verse by verse...
While traditional methods have made a significant impact, they simply can’t keep up with the growing global demand for Scripture in more languages...
unfoldingWord’s innovative software, translationCore, is transforming how translation happens – putting powerful tools directly into the hands of the global Church.
International (MNN) — Bible translation has traditionally been a slow, labor-intensive process. It often requires Western missionary linguists to spend years learning a language and then carefully translating the Bible, verse by verse.
“We have profound respect for the accomplishment of our brothers and sisters in the traditional Bible translation world,” Dane with unfoldingWord says.
“Several of our founders spent 30 or 40 years in that movement. We couldn’t do what we do without their shoulders to stand on.”
While traditional methods have made a significant impact, they simply can’t keep up with the growing global demand for Scripture in more languages. That’s where unfoldingWord comes in.
unfoldingWord’s innovative software, translationCore, is transforming how translation happens – putting powerful tools directly into the hands of the global Church.
“It is our goal to deliver a comprehensive end-to-end Bible translation tool chain that’s self-service,” Dane says. “It provides self-service capabilities for drafting, checking accuracy, and even publishing translations.”
The impact has been dramatic. According to partners working with unfoldingWord, “‘When we have to check a Bible translation by hand, we can get through maybe 10 verses a day. When using translationCore, we can check 100 verses a day,’” Dane shares.
“They have all the tools right there. They don’t have to be a PhD consultant to do this.”
As the global Church increasingly takes the lead in translating Scripture for their communities, tools like translationCore are essential. However, developing this kind of technology takes resources. You can help by giving.
“It costs several hundred thousand dollars per year to develop these tools,” Dane notes. “We really need people to step up and help us to equip the global Church to translate the Bible for themselves.”"
By Katey Hearth
June 25, 2025
https://www.mnnonline.org/news/new-tools-speed-up-global-bible-translation/
#metaglossia_mundus

"Le patrimoine immatériel marocain traduit en mandarin grâce à un partenariat éditorial
À l’occasion de la 31e Foire internationale du livre de Pékin, un accord culturel majeur a été signé entre la maison d’édition marocaine Axions Communication et l’éditeur chinois People's Tianzhou Publishing. Deux ouvrages emblématiques du patrimoine marocain seront traduits en chinois, renforçant les liens littéraires et culturels entre les deux pays.
À l’occasion de la 31e Foire internationale du livre de Pékin, qui s'est tenu du 18 au 22 juin 2025, la maison d’édition marocaine Axions Communication a signé un accord important avec l’éditeur chinois People's Tianzhou Publishing Co., Ltd. pour la traduction en chinois de deux ouvrages majeurs consacrés au patrimoine culturel marocain. Cet accord marque une avancée significative dans les échanges littéraires et culturels entre le Maroc et la Chine.
Les deux ouvrages concernés sont « Trésors du patrimoine culturel immatériel du Maroc » et « Rabat, la Ville de Lumière ». Tous deux sont des livres richement illustrés, au format large de 240 pages, mettant en valeur la diversité culturelle et le charme architectural du Royaume du Maroc.
L’ouvrage « Trésors du patrimoine culturel immatériel du Maroc » met en lumière les traditions et expressions culturelles reconnues par l’UNESCO, telles que : la place Jemaa el-Fna de Marrakech, le Moussem de Tan-Tan dans le sud-ouest, la fête des cerises de Sefrou près de Meknès, les pratiques ancestrales liées à l’arganier, ainsi que la tradition musicale des Gnaouas.
Quant à « Rabat, la Ville de Lumière », il propose au lecteur une exploration photographique de la capitale marocaine, avec un accent particulier sur son paysage architectural et son développement urbain, notamment à travers de magnifiques images nocturnes.
La cérémonie de signature s’est déroulée au pavillon national du Maroc, organisé par l’Ambassade du Royaume du Maroc en Chine, en présence de Son Excellence l’Ambassadeur Abelkader Ansari.
Cet accord ouvre également la voie à une collaboration plus poussée entre les deux maisons d’édition, incluant la traduction d’autres ouvrages marocains vers le chinois ainsi que de futurs projets d’édition conjointe."
par Mohamed Elkorri
Mercredi 25 Juin 2025
https://www.lopinion.ma/Le-patrimoine-immateriel-marocain-traduit-en-mandarin-grace-a-un-partenariat-editorial_a69146.html
#metaglossia_mundus

"L’Institut fondamental d’Afrique noire (IFAN) annonce le lancement officiel de « Sentermino » en septembre 2025. Ce projet de banque de données terminologiques et de traductique (BDT) vise à harmoniser et uniformiser la production terminologique dans les langues nationales sénégalaises.
« ‘Sentermino’ est une initiative nationale d’envergure, qui vise à harmoniser, centraliser et valoriser les terminologies dans les langues nationales du Sénégal, notamment le wolof, le pulaar et le seereer », précise le communiqué transmis à l’APS. Ce projet facilitera l’enseignement bilingue et la traduction entre les langues nationales, ainsi qu’entre ces dernières et le français. La base de données centralisée, évolutive et accessible en ligne, contiendra des terminologies validées pour divers domaines : éducation, santé, environnement, artisanat, TIC et agriculture. « Sentermino » contribuera à l’opérationnalisation du modèle harmonisé de l’enseignement bilingue au Sénégal (MOHEBS) et à l’atteinte de l’Objectif de développement durable 4, relatif à une éducation de qualité, inclusive et équitable.
Selon Sud Quotidien, cette initiative vise à « faciliter la traduction entre les langues nationales elles-mêmes, et entre celles-ci et le français, grâce à la traductique »."
https://senego.com/ifan-lancement-de-la-plateforme-sentermino-pour-les-langues-nationales_1852463.html
#metaglossia_mundus

"Beyond Words: Defending Language as a Tool for Cultural Survival and Peoples’ Rights
June 25, 2025
Identities and Narratives, Highlighted News
The Unrepresented Nations and Peoples Organization (UNPO) has today published a new policy paper, “Beyond Words: Language as a Peoples’ Right”, highlighting how the erosion of linguistic diversity poses a direct threat to cultural survival, collective identity, and the ability of Peoples to exercise their right to self-determination.
Based on the experiences of UNPO members, the report demonstrates how the suppression of language is often one of the first steps taken by states to marginalise or erase Indigenous and minority communities. The paper makes a clear connection between language, identity, political participation, and cultural resilience.
Language as a Cornerstone of Rights
Language is not simply a tool for communication, it shapes how communities understand the world, relate to their environment, and pass on knowledge and identity. The paper shows that limitations on language use, especially through state policies of forced assimilation or exclusion, undermine the right of Peoples to self-determination and weaken cultural survival.
It outlines how these patterns of repression are visible across different regions, with examples from UNPO members:
Catalonia, where legal restrictions continue to weaken the Catalan language’s presence in public life and education, despite formal recognition.
Balochistan, where state policies have systematically eroded the Balochi language, contributing to the broader suppression of Baloch identity.
Khmer-Krom, where restrictions on Khmer language education and use reflect a wider system of exclusion targeting cultural and religious practices.
Kabylia, where refusal to fully recognise the Kabyle language and identity forms part of ongoing repression against the Kabyle people.
In all these cases, linguistic repression is closely linked to political marginalisation and cultural erasure. The paper emphasises that when a people’s language is excluded from education, media, public spaces, and governance, their capacity to maintain their identity, culture, and future is directly threatened.
According to UNESCO, 40% of the world’s languages are at risk of disappearing, with at least one language vanishing every two weeks. Globalisation, technological developments, mass migration, and authoritarian policies have accelerated these trends, undermining the ability of Indigenous Peoples and minority communities to transmit their languages to future generations.
The paper also raises concern about how technological advances, including the dominance of major global languages in artificial intelligence and digital platforms, further exclude minority languages, making it harder for them to survive and remain relevant in modern society.
Language Suppression as a Form of Control
The policy paper shows that states often use language as a political tool to assimilate, control, and silence Peoples. Restrictions on language use in education, media, or public life are rarely isolated, they form part of broader policies designed to weaken cultural resilience and suppress demands for recognition or self-governance.
Assimilationist policies, whether imposed through law or more subtle forms of pressure, target language to fragment communities and undermine collective rights. The paper underlines that defending language is an essential act of resistance, closely tied to protecting cultural identity and the right to self-determination.
UNPO’s Call to Action
The policy part is part of UNPO’s ‘Preserving Identities and Re-owning Narratives’ campaign and the 2025 webinar series, ‘Peoples’ Rights, Peoples’ Future – The Foundation of Our Shared Future’, which highlights the links between language rights, cultural survival, and self-determination.
UNPO urges governments, regional bodies, and the international community to:
Recognise and protect linguistic diversity within states;
Guarantee mother tongue education and language rights in public life;
End assimilationist policies and state practices that erode minority and Indigenous languages;
Ensure communities have a meaningful role in shaping language and education policies;
Safeguard linguistic rights as part of broader strategies to support self-determination and cultural resilience.
The loss of language is not only the disappearance of words, it represents the erasure of history, knowledge, identity, and the ability of Peoples to participate in shaping their own futures. Defending language rights is a necessary step towards resisting cultural repression and ensuring that unrepresented nations, Indigenous Peoples, and minority communities can thrive."
https://unpo.org/beyond-words-defending-language-as-a-tool-for-cultural-survival-and-peoples-rights/
#metaglossia_mundus
"IA africaine : quand le Bénin fait parler les langues oubliées du numérique
Le Bénin vient de poser une pierre fondatrice majeure dans la lutte contre l’exclusion numérique linguistique. Le 24 juin 2025, à Cotonou, l’Institut pour une Afrique Numérique Inclusive (IIDiA) et l’Agence des Systèmes d’Information et du Numérique (ASIN) ont lancé le Laboratoire Régional d’Innovation et des Technologies Numériques, avec un projet inaugural à fort retentissement : la création du premier modèle d’intelligence artificielle vocal en langue Fon.
Langue parlée par des millions de personnes au Bénin et dans les pays voisins, le Fon est jusqu’ici absent des interfaces technologiques dominantes. En ciblant les populations non francophones, notamment rurales et âgées, ce projet entend rompre la fracture linguistique numérique en permettant à chacun d’interagir vocalement avec la technologie dans sa langue maternelle, sans avoir recours à l’écrit ou à une langue étrangère.
ArticlesSimilaires
Sextorsion numérique : l’Afrique au cœur d’une nouvelle guerre cyber
Données africaines, serveurs africains : la riposte souveraine de ST Digital
Trois cas d’usage prioritaires ont été définis :
– Trouver les pharmacies de garde ;
– Consulter son solde Mobile Money (en partenariat avec Celtis) ;
– Accéder aux démarches administratives pour obtenir un acte de naissance, via des interactions vocales simplifiées.
Pour Marc André Loko, DG de l’ASIN, « il ne s’agit pas seulement de technologie, mais de dignité. Quand une grand-mère dans un village peut demander son solde bancaire en Fon et recevoir une réponse vocale immédiate, c’est ça, l’inclusion numérique. »
Un prototype fonctionnel est attendu dans 9 mois, reposant sur la collecte communautaire de données vocales et l’entraînement de modèles IA sur des GPU de dernière génération (NVIDIA A100/H100).
Ce projet, soutenu par la Fondation Gates et les ministères du numérique du Bénin, du Sénégal et de la Côte d’Ivoire, ambitionne d’être le premier jalon d’une infrastructure publique numérique africaine, multilingue, ouverte et souveraine. L’objectif est d’étendre ce modèle à d’autres langues locales et secteurs stratégiques : agriculture intelligente, e-santé, navigation, services publics digitalisés, éducation en langues locales."
par AITN
25 juin 2025
https://afriqueitnews.com/tech-media/ia-africaine-benin-fait-parler-langues-oubliees-numerique/
#metaglossia_mundus
"GLOSSARY OF GENDER EQUALITY
Glossary of Gender Equality
JUNE 25, 2025
Gender equality discourse in Armenia has often been shaped by direct borrowings from English, frequently without adaptation to Armenian linguistic norms. While these borrowings reflect global influence, they have also contributed to the perception that gender equality is a foreign concept, disconnected from Armenian cultural and intellectual traditions. This perception has created a communicative gap both linguistic and conceptual that limits broader engagement with gender-related issues.
The Glossary of Gender Equality directly addresses this gap. Developed by Assistant Professor Rafik Santrosyan of the American University of Armenia in collaboration with the UNDP Armenia Gender Equality Portfolio, the glossary enriches and standardizes gender-related terminology in Armenian. It introduces expanded definitions and new terms specifically adapted to Armenia’s sociolinguistic context, while drawing on international standards, scientific literature, and legal frameworks.
Designed as a practical reference for policymakers, researchers, educators, students, and practitioners, the glossary not only promotes the accurate use of global gender terminology in Armenian, but also revitalizes the expressive potential of the language itself. Rather than relying on uncritical translations, it restores underused native terms and introduces thoughtful neologisms aligned with Armenian linguistic logic.
The glossary’s innovations extend beyond terminology. Its definitions embed contextually grounded explanations that invite deeper understanding and more inclusive public discourse. In doing so, the Glossary of Gender Equality represents a decolonial intervention reclaiming space for gender discourse that is locally rooted, culturally resonant, and globally connected.
This publication reflects UNDP Armenia’s continued commitment to inclusive governance, linguistic equity, and the advancement of gender equality through accessible and culturally responsive knowledge."
https://www.undp.org/armenia/publications/glossary-gender-equality
#metaglossia_mundus

As the availability and performance of AI for language editing and translation continues to improve, we can imagine a future in which everyone can use their own language to write, assess and read science. The question is, how can we achieve it?
Tatsuya Amano, Lynne Bowker, Andrew Burton-Jones
In an ideal world, academic publishing is about “removing barriers and promoting inclusion in knowledge creation and sharing, and publishing research outputs that enable everyone to learn from, reuse and build upon scientific knowledge”. The use of English as the common language of science has boosted international scholarly communication, including publishing, but has also posed unignorable barriers to the progress and application of science. For example, reading, writing, and publishing papers requires much more time and effort for scientists whose first language is not English compared to native English speakers [1], which can lead to higher levels of anxiety and dissatisfaction [2]. Centralizing the publication of research around English also undermines the ability of people with limited English proficiency to read and use the research [3] and drives international research to ignore science published in other languages [4]. The scientific community urgently needs to move beyond the use of English as the singular default language to ensure that all scientists (and other actors and stakeholders) have an equal opportunity to access, contribute to, and benefit from science, regardless of their backgrounds [5].
A primary reasons that science has not yet become fully multilingual is that translation can be slow and costly. Artificial intelligence (AI), however, may finally allow us to overcome this problem, as it can provide useful, often free or affordable, support in language editing and translation [6]. Large language models are already widely used in academic writing, especially in countries where English is not widely spoken [7]. Existing AI has limitations, most notably variations in the availability and performance of AI among different languages [8]. However, assuming that this situation will continue to improve, we can now imagine two futures for academic publishing in which we could leverage the power of AI to overcome language barriers and improve equity in the publication, synthesis, and application of science.
In Future 1, English would continue to be the lingua franca in science (Fig 1A). Although international journals would continue to publish in English, researchers with limited English proficiency could write papers in their own language and use AI to translate them into English before submission. They could also use AI to translate English-language papers into their own language when reading, reviewing, and editing those papers. Scientific knowledge would continue to be centralized around English, but the use of AI would help to make science more easily producible and accessible for those with limited English proficiency.
Expand
Fig 1. Two futures for academic publishing using artificial intelligence language tools.
Information communicated in English is shown in pale blue and that in a language other than English (Japanese in this example) is shown in orange. (A) In Future 1, scientific papers continue to be published in English. Artificial intelligence (AI) is used by those with limited English proficiency to translate information between their preferred language and English when writing, assessing (reviewing and editing) and reading papers. (B) In Future 2, scientific papers are published in any language of the authors’ choice (English or Japanese in this example). AI is used by those without proficiency in the publication language (e.g., Japanese) to translate information between that language and their preferred language (e.g., English). Here, only one non-English language is shown for simplicity, but translation may be between different non-English languages. For example, Reviewer #1 may read a Japanese-written paper and provide feedback in Spanish, Reviewer #2 may do the same in Chinese, the Editor may read the paper and the reviewers’ comments and provide feedback in Arabic, and the authors would read all of their feedback in Japanese, all through AI translation.
doi:10.1371/journal.pbio.3003215.g001
More »
This future is less ‘disruptive’ because the scientific community would continue to operate using the existing publishing system. Also, as most AI models are disproportionately trained on English-language data, translation to and from English tends to be of higher quality than translation between non-English languages. However, Future 1 would have various drawbacks. Inequality between fluent and non-fluent English speakers would remain; any negative consequences of using AI in academic publishing, including translation inaccuracies and the financial cost of using AI tools, would be imposed only on non-fluent English speakers. As long as scientific knowledge is centralized around English, the ongoing ‘domain loss’ (the idea that the growing use of English in a certain domain leads to other languages losing status and eventually not being used at all [9]) for other languages will not decelerate and could even intensify. New concepts in science may be described only in English, and other languages may not even have terms for new concepts. People will not be able to talk about science in their own language easily, and this may further isolate science from non-scientists, potentially leading to a lower uptake of science in decision-making and less trust in science among the general public.
Now imagine another future, Future 2, in which academic journals publish papers written in any language (Fig 1B). This would enable authors to write and submit papers in their own language. Here, assessors (editors and reviewers) and recipients of science (both scientists and non-scientists) would use AI to read those papers in their own language. A major advantage of this future would be that everyone can use their own language for science, which would help maintain and promote the diversity of science and scientific languages. This would be a giant leap forwards for 95% of the world’s population (native speakers of languages other than English) who, at present, have little choice but to conduct science in English. Publishing science in other languages could also help to halt domain loss and facilitate the understanding and use of science in countries where English is not widely spoken.
That said, making academic publishing multilingual in a fair way will not be easy. For example, even with AI tools, will people find and read English-language papers and papers in unfamiliar languages equally frequently? Will the evaluation of papers written in a non-English language be conducted in an unbiased manner? Given that AI translation is inevitably imperfect, especially for low-resource languages, this future could introduce another bias in the assessment, visibility and use of science depending on the language of publication. Various pragmatic roadblocks also exist; for instance, literature search systems would need to integrate multilingual metadata and cross-language information retrieval to allow users to search for literature written in different languages. The AI-driven automation of literature searching, screening and data extraction using multilingual models should help researchers to better use evidence in multiple languages [10]. However, encouraging publishing in languages beyond English will require a systemic change, as the current English-based assessment of science and scientists drives scientists to publish in English, even in countries where English is not widely spoken.
We should be mindful about the inaccuracy of AI translation and its consequences in science. But we also need to understand trade-offs between the consequences of AI inaccuracy and the considerable benefits of overcoming existing language barriers. The acceptable risk of using AI translation likely differs depending on purpose and discipline. Training subject area experts continues to be essential for spotting improbable AI translations, and the involvement of such experts will be necessary, especially where misunderstanding evidence can have serious implications.
Despite these and other counterarguments, Future 2 is still our preferred future, as it would truly democratize academic publishing. People often express concern that AI translation does not meet a phantom gold standard. But the reality is that issues around inaccurate use and understanding of English are already widespread in every process of academic publishing, and these are now entirely attributed to a lack of effort by researchers with lower English proficiency. The use of AI can at least create a more level playing field in the sense that it does not privilege one language above all others. There is no single big step towards Future 2; what we need are small stepping stones, such as experimenting with multilingual publication in just a few languages. To make a start, we have launched various initiatives [11] and encourage others to follow suit. AI will no doubt be integrated into all elements of the academic publishing workflow in the near future, and we believe now is the time for the scientific community to start discussing how we can use its benefits to move towards making science multilingual.
Abstract
As the availability and performance of artificial intelligence for language editing and translation continues to improve, we can imagine a future in which everyone can use their own language to write, assess, and read science. The question is, how can we achieve it?
Citation: Amano T, Bowker L, Burton-Jones A (2025) AI-mediated translation presents two possible futures for academic publishing in a multilingual world. PLoS Biol 23(6): e3003215. doi:10.1371/journal.pbio.3003215
Published: June 23, 2025

"Traduction, paix et confiance : JMT 2025
Le Conseil de la FIT a le plaisir d’annoncer le thème de la Journée mondiale de la traduction (JMT) 2025, inspiré par l’Année internationale de la paix et de la confiance des Nations Unies et par celui du Congrès de la FIT2025, Maîtres de la machine : façonnons l’intelligence de demain. Le thème de la JMT 2025 est
La traduction, garantie de votre confiance en l’avenir
Dans des temps troublés où souvent se joue l’avenir de la paix, où la défiance s’insinue dans les échanges internationaux, il met à l’honneur la confiance dans les relations humaines, spécifiquement le rôle des traducteurs et traductrices, interprètes et terminologues, garanties de fiabilité des communications, artisans du dialogue en confiance, maîtres des outils d’IA générative et de traduction automatique.
Dans sa résolution sur l’Année de la paix et de la confiance, l’Assemblée générale de l’ONU constate aussi la nécessité de prévenir et résoudre les conflits par le dialogue et la diplomatie. Si dans les négociations internationales, les interprètes ne sont pas visibles, nous savons que ces conversations stratégiques seraient impossibles sans leur travail et ne sauraient être laissées aux mains de la technologie.
Le thème rappelle également la résolution A/RES/71/288 de 2017 faisant du 30 septembre une Journée internationale du réseau des Nations Unies honorant la contribution de la traduction, l’interprétation et la terminologie professionnelles au rapprochement des nations et à la promotion de la paix et du développement.
Comme chaque année depuis plus de 35 ans, le Conseil encourage les membres à adopter pour leurs célébrations le thème de l’année. Et le Comité permanent des partenariats externes vous invite le 26 septembre 2025 à fêter la JMT en ligne avec la FIT lors du webinaire annuel."
https://fr.translatio.fit-ift.org/2025/03/28/traduction-paix-et-confiance-jmt-2025/
#metaglossia_mundus
"Ce webinaire est co-organisé par l'UNESCO et Translation Commons dans le cadre de la Décennie internationale des langues autĺochtones (DILA2022-2032) pour célébrer la Journée internationale de la traduction.
Traduction des langues autochtones : Façonner un avenir digne de confiance
30 septembre 2025 - 4:00 pm - 30 septembre 2025 - 6:30 pm
Location
UNESCO Headquarters, Paris, France
Rooms :
VIRTUAL ROOM A
Type :
Cat VII – Seminar and training
Arrangement type :
Virtual
Rejoignez l'UNESCO et Translation Commons pour un événement en ligne célébrant la Journée internationale de la traduction ! Le thème de cette année, la confiance dans la traduction autochtone, englobe plusieurs dimensions : la confiance dans l'exactitude et la sensibilité culturelle des traductions, la confiance dans le traitement éthique des connaissances et des données autochtones, et la confiance dans les technologies employées, en particulier en ce qui concerne l'intelligence artificielle. Il s'agit de s'assurer que le processus de traduction respecte l'autonomie des communautés autochtones. L'instauration de cette confiance nécessite la participation active des communautés autochtones, la transparence, des lignes directrices claires et le respect des droits moraux et matériels, tant pour les communautés que pour les professionnels de la langue concernés. L'établissement de la confiance est essentiel pour la préservation, la revitalisation et la promotion des langues autochtones, et pour garantir que leurs connaissances et leurs cultures sont représentées de manière précise et respectueuse.
Le webinaire sera en anglais.
Objectifs principaux
Le webinaire permettra de :
Explorer l'évolution des rôles et l'avenir des professionnels de la langue autochtone en examinant l'impact de la technologie, de l'IA et de l'évolution des compétences nécessaires dans le domaine.
Souligner l'importance de l'expertise humaine pour garantir l'exactitude, la sensibilité culturelle et la préservation de la signification spirituelle dans la traduction des langues autochtones.
Discuter et aborder les considérations éthiques liées à l'utilisation de l'IA et de la technologie numérique dans la traduction en langue autochtone, y compris la propriété des données, la protection de la vie privée, les préjugés et les cadres dirigés par la communauté.
Faciliter le dialogue sur les meilleures pratiques en matière de traduction et de validation communautaires, en garantissant une participation active et le respect de l'autonomie autochtone.
Sensibiliser aux droits moraux et matériels des communautés autochtones et des traducteurs/interprètes, en mettant l'accent sur une compensation, une reconnaissance et un soutien équitables.
Examiner le droit à l'accès culturel et linguistique pour les communautés autochtones, y compris l'aide juridique et l'interprétation dans des domaines critiques tels que les soins de santé.
Promouvoir la collaboration intergénérationnelle et les approches novatrices du travail linguistique à l'ère numérique.
Fournir des études de cas qui mettent en évidence le rôle essentiel des traducteurs humains dans la préservation du patrimoine linguistique et culturel.
Programme (en anglais seulement)
7.00 am PDT / 4 pm CEST
Welcome Address
7.10 am PDT / 4.10 pm CEST
The Enduring Trust in Human Voices: Ensuring Accuracy and Cultural Integrity within Indigenous Communities
7.50 am PST / 4.50 pm CEST
Navigating the Future: The Evolving Roles of Indigenous Language Professionals
8.30 am PST / 5.30 pm CEST
Ethical Pathways in the Digital Age: AI and the Future of Indigenous Language Translation
9.10 am PST / 6.10 pm CEST
Closing Address"
https://www.unesco.org/fr/articles/traduction-en-langues-autochtones-faconner-un-avenir-digne-de-confiance
#metaglossia_mundus

Traductrice, interprète, la Française Karine Martin accompagne au quotidien les expatriés francophones dans les démarches administratives de particuliers ou d'entreprises.
Karine Martin : "S’expatrier en Espagne demande beaucoup de traductions assermentées"
Pour les particuliers ou les entreprises, la traductrice, interprète, Karine Martin aide au quotidien les expatriés francophones dans les démarches administratives. Rencontre.
Écrit par Simon Legentil
Publié le 23 juin 2025, mis à jour le 25 juin 2025
Karine Martin pose ses valises en Espagne au début des années 2000, juste après ses études. Elle débute sa carrière à la Chambre de commerce, puis se lance dans l’entrepreneuriat en fondant Fidélité Idiomas, une entreprise de traduction et d’interprétation, à Alicante en 2006. Quelques années plus tard, elle s’installe à Barcelone pour son dynamisme, le cadre de vie et la proximité avec la France. Elle devient déléguée consulaire en 2021. Aujourd’hui, cette traductrice passionnée accompagne au quotidien la communauté francophone de Barcelone.
Fidélité Idiomas, concrètement, qu'est-ce que c'est ?
À la base, c'était moi en tant que traductrice-interprète. Espagnol, anglais vers le français. Au fil du temps, mes clients m'ont demandé de gérer des projets multilingues. Et c'est là où j'ai commencé à travailler en tant qu'agence avec des collègues freelance dans d'autres langues. Je n’ai pas de salariés, mais je collabore presque toujours avec les mêmes personnes. Vous savez, les bons traducteurs ne veulent pas être salariés. Ils préfèrent rester maîtres de leur temps, maîtres de leurs projets, maîtres de leurs clients.
Il y a deux versants de Fidélité Idiomas. Le premier, la traduction à l'écrit de textes simples, c'est-à-dire non assermentée. Ce sont des traductions pour des sites web, des annonces ou des textes commerciaux. Ensuite, il y a les traductions assermentées. Beaucoup de documents juridiques ont besoin d'être assermentés pour être présentés légalement devant les administrations. C’est le cas quand des Français viennent s’installer ici par exemple.
L’autre volet, c'est l’interprétation. J'accompagne des chefs d'entreprise qui viennent faire des réunions, des négociations ou qui viennent voir leurs équipes. Et il y a l'interprétation simultanée, pour des congrès ou des visites avec des audioguides par exemple.
On traduit énormément pour les Français qui viennent s'installer en Espagne.
Et comment les entreprises ou les particuliers font appel à vous ? C'est sur votre site ou c'est vous qui les démarchez ?
J'ai un site web. Je fais partie de nombreux réseaux d'entrepreneurs à Barcelone comme La Peña ou la Chambre de commerce française. Et je suis répertoriée sur la liste des interprètes recommandés par le consulat. Au niveau de l'interprétariat, les entreprises font leurs recherches et je pense que je remonte dans les recherches internet.
Quelles sont les plus grosses demandes des francophones qui vous sollicitent ?
Alors, on traduit énormément pour les Français qui viennent s'installer en Espagne. Il faut beaucoup de traductions assermentées pour s'expatrier ici. Je pense que les plus fortes demandes que nous avons sont les livrets de famille, les actes de naissance ou des diplômes. Ça va être des traductions assermentées pour les particuliers. Et ensuite, pour les entreprises, on va traduire beaucoup de documents destinés à ouvrir des filiales ici, comme le Kbis. C’est, on va dire, la carte d'identité de l'entreprise en France. Et ensuite, des contrats de collaboration, des négociations, etc. Ça, ce sont des traductions assermentées aussi.
En termes de délai, quand une entreprise ou un particulier demande de traduire un numéro ou une carte d'identité de l'entreprise, combien de temps ça met ?
Tout dépend des documents et de l’urgence de ceux-ci. Des documents courts, en général d'une à trois pages, on est très réactif. C'est d'ailleurs une des caractéristiques que nous avons et c'est pour cela qu'on est très connu de la communauté pour la gestion des urgences. Étant moi passée par ces démarches-là, je connais le stress que représente le fait de rater son rendez-vous parce qu'il nous manque un papier. Il nous arrive, de l'après-midi pour le lendemain, d'avoir la traduction.
Maintenant, pour des entreprises, les documents sont plus longs. Un document d’une vingtaine de pages, il faut quand même un minimum de temps pour pouvoir procéder. Mais on est toujours attentif et en bonne collaboration avec nos clients.
Le traducteur engage sa responsabilité sur les traductions, l'IA n'a rien d'officiel.
Comment devient-on traducteur-interprète ?
Alors, traducteur-interprète, ce sont de vraies études ! C'est bien que vous me posiez la question. On devient traducteur en faisant des études de traducteur. En France, il y a des écoles de traduction. En Espagne, cela se fait à l'université surtout.
C’est un vrai métier. De nos jours, l’IA vient réellement nous concurrencer. Alors, il faut la regarder avec un œil expert. Parce que sur de la traduction simple, comme des mails, ou des textes n’ayant rien d’engageant, je dois reconnaître que l'IA est très forte et rapide. Donc là, je me tire un peu une balle dans le pied. Mais il faut être réaliste. Maintenant, quand on parle des contrats, sur des documents confidentiels ou personnels, je pense qu'il faut être très précautionneux au niveau de la confidentialité. Il y a aussi un gros risque de contresens. Et je le répète, dans tout ce qui est juridique, on reste des experts, on engage notre responsabilité sur les traductions, l'IA n'a rien d'officiel."
https://lepetitjournal.com/barcelone/installation/karine-martin-expatriation-espagne-traductions-assermentees-416055
#metaglossia_mundus

Le ministère de l'Europe et des Affaires étrangères a lancé récemment DiploIA, un dispositif de traduction et de transcription multilingue à destination de ses quelque 13 000 agents, dont une part exerce à l'étranger. Pour répondre aux besoins des missions sensibles, le ministère a dû articuler sécurité et technologie.
"Avec DiploIA, le Quai d’Orsay met la traduction et la transcription au centre de sa stratégie IA
Par Victoria Beurnez - 23 juin 2025 -
Le ministère de l'Europe et des Affaires étrangères a lancé récemment DiploIA, un dispositif de traduction et de transcription multilingue à destination de ses quelque 13 000 agents, dont une part exerce à l'étranger. Pour répondre aux besoins des missions sensibles, le ministère a dû articuler sécurité et technologie.
Comme quelques-uns avant lui, le ministère de l’Europe et des Affaires étrangères s’est désormais lancé dans le déploiement d’outils d’intelligence artificielle internes, à destination de ses agents. Contrairement à ce qui se fait ces derniers mois, il n’est pas question ici d’un chatbot, mais d’outils pensés précisément pour les besoins des agents, notamment en dehors de la France. C’est en réfléchissant au plus près de ces besoins que la direction du numérique du ministère a déployé DiploIA auprès de ses quelque 13 000 agents, en France et à l’étranger, depuis le mois de mai.
“Nous avons une vraie attente de la part de nos agents sur de tels outils”, explique Virginie Rozière, directrice du numérique au ministère de l’Europe et des Affaires étrangères, auprès d’Acteurs publics. Pour autant, il n’était pas question de se lancer dans des outils sans réflexion en amont, qui pourraient dès lors “relever du gagdet”, tempère la directrice..."
https://acteurspublics.fr/articles/le-quai-dorsay-deploie-de-lia-au-service-de-ses-agents/
#metaglossia_mundus

The Faculty of Translation and Interpreting (FTI, formerly ETI) is deeply committed to fundamental and applied research. Our areas of expertise are: translation studies, interpretation, terminology and machine-assisted translation, multilingual communication and international mediation.
"Research at the FTI
At the Faculty of Translation and Interpreting (FTI) we are committed to innovative research at the highest levels of excellence. Our areas of expertise include translation studies, interpreting studies, terminology and machine-assisted translation, multilingual communication and international mediation.
Our researchers are key players in major national and international projects in these domains and work with likeminded partners across the globe. Their research output is disseminated through high quality journals and other specialised publications, including Parallèles, the FTI’s own journal.
Research by department:
The Department of Translation
The Department of Translation Technology
The Interpreting Department
Research groups:
Centre for Legal and Institutional Translation Studies (Transius)
Economics, Languages and Education Research Group (ELF)
Laboratory for Research in Interpreting and Complex Language Processing (LaborInt)
Interpreting and Technology (InTTech)
Access through interpretation-mediated communication (AXS)"
https://www.unige.ch/fti/en/recherches
#metaglossia_mundus
BEING one of the most multicultural regional centres in the country, Greater Shepparton has many bilingual people stepping up to be unofficial interpreters and translators for family, friends and co-workers.These community members help with everyday day scenarios, but when they are called to interpret educational, financial, legal and health matters, it becomes extremely challenging and could go against personal boundaries while breaching ethical codes.
"Interpreting the needs of multicultural communities
June 25, 2025
BEING one of the most multicultural regional centres in the country, Greater Shepparton has many bilingual people stepping up to be unofficial interpreters and translators for family, friends and co-workers.
These community members help with everyday day scenarios, but when they are called to interpret educational, financial, legal and health matters, it becomes extremely challenging and could go against personal boundaries while breaching ethical codes.
To help local organisations navigate the complexities of interpreting and translating, Monash University in conjunction with GSCC’s Resilience in Recovery team hosted several workshops for local stakeholders. The aim was to understand the role and responsibilities of interpreters and the importance of the National Accreditation Authority for Translators and Interpreters (NAATI) certification.
“The job of the interpreter is to convey the meaning and linguistic features from one language to another. That is law. It’s not to convey emotion, not to convey opinion, not to convey perception, it’s just to convey the meaning,” said Dr Leah Gerber, senior lecturer of translation and interpreting studies at Monash University.
INTERPRETERS AND TRANSLATORS… Monash University in conjunction with GSCC’s Resilience in Recovery team hosted workshops to help local organisations navigate the complexities of interpreting and translating language for local multicultural communities. Pictured is Dr Leah Gerber, senior lecturer of translation and interpreting studies at Monash University. Photo: Aaron Cordy
Linguistic skills, even fluency do not give you the skills and understanding of the ethics required to be an interpreter.
“Speaking the languages, reading the languages, writing the languages, does not mean you are a translator or an interpreter. In Australia, you usually must complete a one-and-a-half to two-year Master’s program or Advanced Diploma in order to qualify to sit the NAATI test,” said Dr Gerber.
The training sessions provided by Monash and the GSCC flood recovery team play an important role in this space, but more work needs to be done to help our local multicultural community access the training and services of qualified interpreters and translators.
“I think regional communities are really disadvantaged in the sense that all training for translators and interpreters happens in metropolitan Melbourne. There aren’t any regional opportunities other than either going to Melbourne to study or accessing the courses online, which doesn’t suit everybody’s learning needs,” said Dr Gerber.
“I think there’s a lack of awareness also of the very specific challenges that regional communities face, whether it’s in terms of a weather event, whether it’s in terms of particular language demands that you can’t just get an interpreter from Melbourne to come out to Shepparton when you need them. Those kinds of things are important to recognise.”"
https://www.sheppadviser.com.au/interpreting-the-needs-of-multicultural-communities/
#metaglossia_mundus

This study compares the quality of English-to-Arabic translations produced by Google Translate (GT) with those generated by student translators.
"Man vs. Machine: Can AI Outperform Student Translations?
Anas Alkhofi*
King Faisal University, Al-Ahsa, Saudi Arabia
This study compares the quality of English-to-Arabic translations produced by Google Translate (GT) with those generated by student translators. Despite advancements in neural machine translation technology, educators often remain skeptical about the reliability of AI tools like GT and often discourage their use. To investigate this perception, 20 Saudi university students majoring in English and Translation produced human translations in Arabic. These studentgenerated translations, along with their GT equivalents, were rated by 22 professors with experience in language-related fields. The analysis revealed a significant preference for GT translations over those produced by students, suggesting that GT's quality may exceed that of student translators. Interestingly, while GT translations were consistently rated higher, instructors often misattributed the better translations to students and the poorer ones to GT. This reveals a strong perceptual bias against AI-generated translations. The findings support the inclusion of AI-assisted translation tools in translation training. Incorporating these tools will help students prepare for a job market where AI is playing an increasingly important role.Incorporating such tools will help students prepare for a growing job market in which AI is playing a growing role. At the same time, educators should adopt strategies incorporating AI tools without sacrificing the development of students' core translation skills."
https://www.frontiersin.org/journals/artificial-intelligence/articles/10.3389/frai.2025.1624754/abstract
#metaglossia_mundus

Award, to be shared between poet and translator, is a joint project by three publishers and will give a $5,000 advance for a new collection
New prize for translated poetry aims to tap into boom for international-language writing
Award, to be shared between poet and translator, is a joint project by three publishers and will give a $5,000 advance for a new collection
Ella Creamer
Tue 24 Jun 2025 15.00 BST
A new poetry prize for collections translated into English is opening for entries next month.
Publishers Fitzcarraldo Editions, Giramondo Publishing and New Directions have launched the biennial Poetry in Translation prize, which will award an advance of $5,000 (£3,700) to be shared equally between poet and translator.
The winning collection will be published in the UK and Ireland by Fitzcarraldo Editions, in Australia and New Zealand by Giramondo and in North America by New Directions.
“We wanted to open our doors to new poetry in translation to give space and gain exposure to poetries we may not be aware of,” said Fitzcarraldo poetry editor Rachael Allen. “There is no other prize like this that we know.”
The prize announcement comes amid a sales boom in translated fiction in the UK. Joely Day, Allen’s co-editor at Fitzcarraldo, believes that “the space the work of translators has opened up in the reading lives of English speakers through the success of fiction in translation will also extend to poetry”.
Translated work is a focus of the three publishers behind the prize. Fitzcarraldo has published translated works by Nobel prize winners Olga Tokarczuk, Jon Fosse and Annie Ernaux. “Our prose lists have always maintained a roughly equitable balance between English-language and translation, and some of our greatest successes have been books in translation,” said Day. “We’d like to bring the same diversity of voices to our poetry publishing, and this prize will be a step in that direction.”
skip past newsletter promotion
Sign up to Bookmarks
Free weekly newsletter
Discover new books and learn more about your favourite authors with our expert reviews, interviews and news stories. Literary delights delivered direct to you
Enter your email address
Sign up
Privacy Notice: Newsletters may contain info about charities, online ads, and content funded by outside parties. For more information see our Privacy Policy. We use Google reCaptcha to protect our website and the Google Privacy Policy and Terms of Service apply.
after newsletter promotion
Four Nobels and counting: Fitzcarraldo, the little publisher that could
Read more
The prize is open to living poets from around the world, writing in any language other than English.
The prize is being launched to find works “which are formally innovative, which feel new, which have a strong and distinctive voice, which surprise and energise and move us,” said Day. “My personal hope is that the prize reaches fledgling or aspiring translators and provides an opening for them, that it enables translators of poetry in particular to find a platform and encourages translators who want to work with poetry to do so.”
Submissions will be open from 15 July to 15 August. A shortlist will be announced later this year, with the winner announced in January 2026 and publication of the winning collection scheduled for 2027.
The “unique” award “brings poetry from around the world into English, and foregrounds the essential role of translation in our literature,” said Nick Tapper, associate publisher at Giramondo. “Its global outlook will bring new readers to poets whose work deserves wide and sustained attention.”
This article was amended on 24 June 2025. An earlier version incorrectly listed the prize money amount as $3,000 rather than $5,000 in the subheading."
https://www.theguardian.com/books/2025/jun/24/new-prize-for-translated-poetry-aims-to-tap-into-boom-for-international-language-writing
#metaglossia_mundus
https://www.theguardian.com/books/2025/jun/24/new-prize-for-translated-poetry-aims-to-tap-into-boom-for-international-language-writing
#metaglossia_mundus

Microsoft has unveiled its on-device small language model, Mu, that allows users to change settings through natural language queries.
"Microsoft introduces small language model Mu to change settings in Windows 11
Accessible to Windows Insiders in the Dev Channel with Copilot+PCs, Mu responds to natural language queries
Microsoft on Monday (June 23, 2025) unveiled its on-device small language model, Mu, that allows users to change settings through natural language queries. The company said Windows Insiders in the Dev Channel with Copilot+PCs can access Mu.
The AI agent for Settings in Windows 11 was included in the existing search box for a seamless user experience, the company said.
“Mu is fully offloaded onto the Neural Processing Unit (NPU) and responds at over 100 tokens per second, meeting the demanding UX requirements of the agent in Settings scenario,” Vivek Pradeep, VP, Distinguished Engineer at Windows Applied Sciences noted in a company blog.
Trained over multiple phases using Nvidia’s A100 GPUs on Azure Machine Learning, Mu followed a similar technique as Microsoft’s previous small language model family, Phi.
It was pre-trained on “hundreds of billions of the highest-quality educational tokens, to learn language syntax, grammar, semantics and some world knowledge.” Mu was then distilled from the Phi models to enhance accuracy.
Published - June 24, 2025 02:03 pm IST"
Updated - June 24, 2025 02:44 pm IST
https://www.thehindu.com/sci-tech/technology/microsoft-introduces-small-language-model-mu-to-change-settings-in-windows-11/article69731231.ece
#metaglossia_mundus

"A tale of trauma and the perils of misinterpretation
The debut novel by the Albanian American writer Ledia Xhoga tackles past trauma and communication breakdowns
Past trauma haunts the debut novel by Albanian American writer Ledia Xhoga. When the narrator, an unnamed Albanian interpreter, agrees to accompany Alfred, a Kosovar torture survivor, to therapy sessions, her life begins to unravel.
The interpreter lives in Brooklyn with her husband, Billy, a film professor. When she invites Leyla, a Kurdish poet seeking asylum, and her friend to stay for the weekend, Billy’s unexpected return exposes the cracks in their marriage. His angry reaction seems disproportionate until it becomes clear that the narrator’s compulsion to help fellow immigrants is taking a toll on their relationship. We are given a hint of her psychological entanglement when she says: “Sometimes words affected me physically, causing as much nausea as motion sickness.” This manifests in her work with Alfred, prompting his therapist to fire her.
As pressure builds, Billy accepts a six-month artist’s residency in Hungary, while the narrator visits Albania. The novel takes on a meditative tone as we learn of her mother’s inability to leave her home and the narrator’s troubled childhood. Xhoga raises the tension back in Brooklyn, as her protagonist faces the fallout from helping Leyla escape a stalker employed by her abusive ex-husband.
Xhoga writes perceptively about the alienation of immigrants – the narrator straddles two worlds, adrift in both – and the disconnect between privilege and precarity. Of Billy’s friend, a professional violinist, she observes: “How could Anna, who was born and raised in the West Village … understand water or electricity shortages, or helping out ageing parents and relatives who had worked all their lives only to end up with a retirement that didn’t even cover their basic necessities?”
Part of the pleasure of the novel, which is related in a direct, matter-of-fact tone, comes from second-guessing what the (occasionally unreliable) narrator has withheld or misinterpreted and how it affects others. Alfred misreads her compassion. She misconstrues others’ expectations, risking her marriage and mental health. The book is a nuanced exploration of communication failures, blurred boundaries and the emotional cost of unchecked altruism.
Misinterpretation by Ledia Xhoga is published by Daunt (£10.99)"
Lucy Popescu
22 June 2025
https://observer.co.uk/culture/books/article/the-perils-of-misinterpretation
#metaglossia_mundus
"ABSTRACT: Language is an underrecognized social driver of health that disproportionately affects Hispanic/Latino (H/L) patients and can negatively impact comprehension and engagement with medical care. Professional interpretation services can help overcome language barriers in the clinic or hospital setting; however, interpreters are not universally available and, even when they are, the quality of communication can be limited. In this secondary analysis of a qualitative study which examined the barriers and facilitators H/L patients and their caregivers experience when navigating rectal cancer care, we sought to explore how Spanish-speaking rectal cancer patients and their caregivers communicated with oncology providers and the ways in which professional interpretation may have facilitated or detracted from their care experiences. Methods We conducted a community-partnered qualitative study to explore H/L patients with rectal cancer and their caregivers’ experiences with medical interpretation during their oncologic care. We developed an interview guide based on the Ecological Model of Health Behavior and iteratively refined it with input from our Community Advisory Board. Data analysis utilized grounded theory and reflexive thematic analysis to identify core themes. Results Over a 6-month period, we conducted 21 semi-structured interviews. Three major themes related to language arose from our review of coded transcripts: (1) interpreters’ use of medical jargon; (2) dialect discordance between patient and hospital interpreter; and (3) lack of trust in the interpretation process. Conclusion Our sample of H/L rectal cancer patients and their caregivers reported barriers due to overuse of medical jargon and dialectic differences, both of which eroded trust in the interpretation process. Beyond simply hiring more interpreters, hospitals would benefit from re-envisioning the patient-interpreter relationship as a means of improving communication and fostering trust in the healthcare system."
June 2025
Supportive Care in Cancer
33(7)
DOI: 10.1007/s00520-025-09657-6
Eleanor Brown
Min Young Kim
Zaria N. Cosby
et al.
Aaron J. Dawe
https://www.researchgate.net/publication/392797572_Interpreters_don%27t_tell_you_everything_experiences_with_medical_interpretation_among_Latino_cancer_patients_and_caregivers_with_limited_English_proficiency
#metaglossia_mundus

"Intercultural Preparation in Higher Education
ByNing Chen
Edition1st Edition
First Published 2025
eBook Published 27 August 2025
Pub. LocationLondon
Imprint Routledge
Pages112
eBook ISBN9781003661818
SubjectsEducation
ABSTRACT
Intercultural Preparation in Higher Education critically examines the complexities of intercultural preparation, challenging reductionist, competence-based approaches and emphasising critical reflection, linguistic sensitivity and intersectional perspectives, which offer transformative insight.
This concise yet comprehensive book draws on the author's extensive experience in preparing students and educators for diversity and intercultural engagement within Chinese and Finnish higher education – two distinct yet interconnected settings. Chen advocates for reflexive, context-sensitive frameworks that address power dynamics, ideological influences and epistemic inequalities shaping intercultural encounters. Synthesising global and Chinese research, the author deconstructs interculturality as an ideological construct and proposes expanding it to encompass diverse diversities. Through case studies of Chinese Minzu education, Finnish teacher training and China's mental health and well-being education, the author explores how to equip educators and students for glocalised (global + local) realities. The book argues that mental health education in China, for instance, can redefine interculturality beyond 'international' or 'ethnic' binaries. By interrogating dominant paradigms and proposing equitable alternatives, the author advances a balanced and inclusive vision of preparation for all in higher education and beyond.
The title is designed for educators, researchers, students and practitioners interested in intercultural studies, higher education, as well as internationalisation and globalisation."
https://www.taylorfrancis.com/books/mono/10.4324/9781003661818/intercultural-preparation-higher-education-ning-chen
#metaglossia_mundus

"By Santa Barbara Unified School District
Tue Jun 24, 2025 | 11:43am
Students in Santa Barbara High School’s groundbreaking Translation & Interpretation Pathway graduated with professional certificates that qualify them to enter the growing field of interpretation and translation. This innovative Career Technical Education (CTE) program celebrates the bilingual assets of Santa Barbara’s many native Spanish speakers and empowers students to transform their language skills into viable career opportunities. Santa Barbara High School’s Translation & Interpretation Pathway, led by teacher Alison Mendoza, stands as the first and only high school CTE pathway of its kind in the state of California.
“Developing this pathway has been a career highlight”, says Alison Mendoza. “By committing to offering a Translation & Interpretation program, we have reimagined Spanish course offerings and connected language learning to the world that surrounds students in a new way. Students receive Language Other Than English (UC A-G) credit for participating and put their language abilities into practice. Watching this year’s cohort leave their high school experience with various college options, a tangible career possibility, a deeper sense of who they are, and pride in their linguistic backgrounds aligns with why I wanted to become a teacher. The collaboration with our local community partners, the district LAU team, and higher education gives students opportunities that they often hadn’t imagined yet”.
This year, the program significantly expanded its offerings to include “The Community Interpreter®” course and certificate. To earn this industry-recognized credential, students completed a rigorous 40-hour training led by Sofia Rubalcava of the Santa Barbara Unified School District’s highly regarded Language Access Unit. Programs like this are designed to strengthen the connection between classroom learning and real-world careers by integrating industry training, all while allowing students to embrace and connect with their home languages and cultures.
“This expansion of the Translation & Interpretation Pathway is a testament to our commitment to providing students with tangible skills that directly lead to meaningful careers,” said Superintendent Hilda Maldonado. “By empowering our bilingual students with professional certificates, we are not only opening doors to vital professions but also reinforcing the value of their linguistic and cultural heritage within our community and beyond. It is a testament to the resiliency of our teachers and staff. They started this even though we were in a pandemic. At SB Unified, we are resilient, strong, and bold!”
The Translation & Interpretation Pathway equips students with foundational skills in translation and interpretation, emphasizing cultural competence, ethics, and the critical importance of language access in diverse community settings. Students apply their learning through real-world experiences, serving their local community, and engaging with professionals currently working in the fields of court, medical, and community interpreting. This year alone, students in the pathway have interpreted the daily morning announcements at their school, created student-friendly translations with the Santa Barbara Museum of Art, volunteered at the Unity Shoppe, established internship opportunities with the Santa Barbara County Courthouse, and provided crucial support to parents and the community at the Know Your Rights event alongside the Language Access Unit team.
Jose Navarrete, a court interpreter at the Santa Barbara County Courthouse, is one of many professionals who actively support the program. He underscores the critical need to inspire a new generation of interpreters. “You need to bring up a whole new generation of interpreters. Approximately 35% of interpreters in the state are 65 years old or older. So they’re going to retire pretty soon. We’re going to need a new generation,” said Navarrete.
The program’s impact is evident in the students themselves. Rubiell Angel Fernandez, a graduating pathway senior, shared, “I’ve had Ms. Mendoza all four years of high school. It really means a lot, seeing how much the program and the pathway have grown throughout the years.” Student Jay Valencia added, “It’s a rigorous program, but even still, it’s served us well, it’s going to give us options for the future.”
This expansion solidifies Santa Barbara High School’s Translation & Interpretation Pathway as a national model for preparing bilingual students for in-demand careers while fostering cultural understanding and community engagement."
https://www.independent.com/2025/06/24/santa-barbara-high-schools-translation-interpretation-pathway-expands-to-provide-professional-certificate/
#metaglossia_mundus

Translation expertise significantly influences how translators manage cognitive resources, yet the specific ways in which professional and novice translators differ in their metacognitive strategy use remain incompletely understood. This gap is particularly evident in specialised contexts such as academic translation, where complex terminology and intricate syntactic structures pose unique cognitive challenges. This study investigated how professional and student translators deploy metacognitive strategies when translating academic texts from Chinese to English, focusing on differences in cognitive resource allocation across translation stages. The study compared 30 professional translators and 30 graduate students in translation studies as they translated two academic article introductions. Using keystroke logging, we recorded detailed temporal data about participants’ translation processes, including thinking time, writing time, and resource consultation patterns. Quantitative analysis revealed that professional translators demonstrated significantly shorter thinking times compared to students, while maintaining higher writing-to-thinking ratios. Analysis of cognitive resource distribution showed that professionals maintained more consistent engagement across translation stages compared to students’ more variable patterns. These findings suggest that translation expertise manifests not merely in faster processing times, but in qualitatively different approaches to cognitive resource allocation. Professional translators demonstrated greater flexibility in switching between automatic and controlled processes, adapting their strategies according to textual challenges. These results refine our understanding of translation expertise while offering practical implications for translator training, suggesting specific ways to help novice translators develop more efficient cognitive strategies. The study contributes to translation process research by providing empirical evidence of how expertise shapes metacognitive strategy use in specialised translation contexts.
"Interpreters of more than 130 languages have been called into New Zealand courts over the past decade - and the costs have soared by 229%.
The Waikato Times took a deep dive into the issue in the wake of remarks from Judge David Cameron about a case with a Filipino interpreter.
Thanks to an Official Information Act request with the Ministry of Justice, the Waikato Times can reveal the increased cost of court interpretation, the complete list of languages and the most - and least - common.
In 2014, it cost the Ministry $1,751,874 for interpreter services, a figure that rose to $5,619,896 in 2023.
The Ministry - and several law and linguistic experts the Waikato Times spoke to - said however that the spike in costs does not necessarily equate to more foreign criminals in New Zealand...
The Ministry said the cost increase between 2022 and 2023 - from $3,475,847 to $5,619,896 - was due to factors including the Coronial inquiry into the Christchurch terror attacks.
They also cited a 2023 change “to increase the fees payable to interpreters”.
Professor Tafaoimalo Tologata Leilani Tuala-Warren, Dean of Te Piringa Faculty of Law at the University of Waikato, also cautioned that there could be a few explanations.
“We may be seeing more witnesses, for both prosecutions and defence, in criminal trials needing interpreters. It could also suggest that the cost charged by interpreters has increased. It is important to not make assumptions without the benefit of examining the disaggregation of the data.”
Tineke Jannick, who is conducting doctoral research into court interpreting in New Zealand at the Victoria University of Wellington, told the Waikato Times the language list may simply be a reflection of “the reality of the highly multi-cultural and multi-lingual nation we live in”.
“Over a quarter of New Zealand’s population are born overseas and there are more than 150 languages spoken here,” she said...
Jannick also said interpretation services were “vital to our justice system, particularly as they pertain to fair trial rights”.
One defence lawyer who spoke to the Waikato Times on condition of anonymity cited the 2022 Accredited Employer Work Visa (AEWV) for the spike in costs.
More than 150,000 visas had been approved since - most before increased English language requirements imposed in 2024, they said, and the scheme was “widely rorted”.
“Many migrants have paid money to agents to get a work visa and a job, only to discover when they arrive in New Zealand that the job offers very few hours, or is entirely fake.
“Some ... turn to crime to pay the bills. Others came to New Zealand with the express purpose of committing crime, knowing from the beginning that their job was fake, but using it to obtain a visa in circumstances where applications were being rubber-stamped by Immigration New Zealand in the post-Covid immigration boom,” they said.
“I have personally dealt with many people on AEWVs who turned to crime shortly after arriving on their visa.”
The data also revealed the five most translated languages over the past decade: Mandarin, Samoan, Punjabi, Tongan and Vietnamese.
Those least required are Bulgarian, Hiligaynon [a regional Filipino language], Lingala [a language spoken in the Democratic Republic of the Congo], Ndebele [South Africa and Zimbabwe] and Oromo [Ethiopia].
Dr Simon Overall, University of Otago linguistics postgraduate coordinator, said the top five list was interesting.
“Two of them, Samoan and Tongan, have relatively small numbers of speakers, but of course significant numbers of those speakers live in New Zealand.
“Of the five, all except Vietnamese appear in the list of the top 20 languages spoken in New Zealand (according to 2018 census data).”
“I don’t know what demographic reason there might be for Vietnamese being there – perhaps the Vietnamese speaking community in New Zealand has increased in recent years?”
“All in all, the lists give a good picture of the New Zealand linguistic situation and to me it really highlights the vital importance of interpreters and translators, since we can’t simply expect that everybody (whether New Zealand citizens or not) knows English well enough to be able to represent themselves in court proceedings.”
Benn Bathgate
benn.bathgate@stuff.co.nz
June 23, 2025
https://www.waikatotimes.co.nz/nz-news/360732341/afar-zulu-130-plus-languages-required-translation-court-and-cost
#metaglossia_mundus
"Imagine microscopes, thermometers, balances, pipettes and bunsen burners having native names, and science and all subjects and courses, taught in our own languages.
We would have been able to compete favourably and equitably within the so-called global village.
The Ministry of Education should boldly prioritise Ghanaian languages in our education system.
By doing so, we can create a more inclusive and effective learning environment for our students.
When students are taught in their native language, they are more likely to understand and retain complex concepts, leading to better academic performance.
Moreover, prioritising Ghanaian languages can help preserve our cultural heritage and promote national identity.
Our languages are an integral part of our history and traditions, and by promoting them, we can ensure their survival for future generations.
The current system, which prioritises foreign languages, particularly English, puts an undue burden on students, especially those from rural areas where English may not be widely spoken.
This can lead to a high dropout rate and poor academic performance.
By adopting a more localised approach to education, we can empower our students to succeed and contribute to the development of our nation.
It's time for the Ministry of Education to rethink our language policy and prioritise Ghanaian languages in our education system.
This can be achieved by developing curriculum materials in Ghanaian languages, training teachers to teach in local languages and encouraging the use of Ghanaian languages in schools and communities.
By taking these steps, we can create a more inclusive and effective educational system that benefits all students, regardless of their background or location.
It's time to put our languages and cultures at the forefront of our education system and give our students the tools they need to succeed.
Moses Sackie Agbemava,
Presbyterian Church of Ghana,
Dansoman Estates, Accra"
https://www.graphic.com.gh/features/opinion/ghana-news-ministry-of-education-prioritise-ghanaian-languages-over-any-foreign-language.html
|



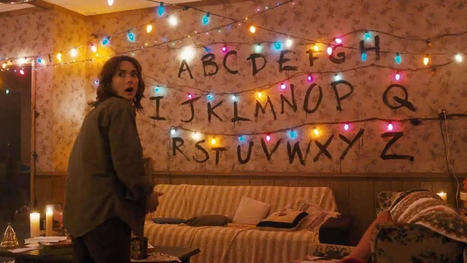







{kind=link}
{kind=link}
{kind=link}
"Entre 7 et 10 minutes traduites par jour
Mais, pour Caroline Lecoq, travailler pour Netflix n’est pas forcément plus difficile que de créer des adaptations pour TF1, au contraire : « En général, on est même presque plus libres lorsqu’on écrit pour une plateforme que pour une chaîne de télévision classique. En France, le CSA fait très attention à ce qui est diffusé et à quelle heure. Pour TF1, qui est une chaîne populaire, on doit être attentif à ne pas faire l’apologie de l’alcool, à ne pas utiliser des mots trop compliqués ou à ne pas conserver le nom des marques. Parfois, on ne peut donc pas être entièrement conformes à la VO, pour qu’un public non averti ne soit pas heurté. »
L’adaptatrice de doublage estime tout de même que son travail n’est pas si différent d’une chaîne à l’autre. « Le processus est en général le même : en tant qu’adaptateurs de doublage, on écrit entre 7 et 10 minutes d’épisodes par jour, donc les studios nous laissent au minimum ce temps nécessaire pour la traduction. Ensuite, notre travail est relu par le directeur artistique en amont, avant l’enregistrement des voix avec les comédiens. »
Sous-titrage et doublage : deux métiers distincts
Du côté des sous-titreurs aussi, la tâche n’est pas aisée. Si vous êtes plutôt amateurs de VO, c’est leur travail qui vous change la vie lors de soirées Netflix & Chill. Si certains aspects sont communs au doublage, les deux métiers restent complètement différents. « La contrainte de lisibilité du sous-titreur et celle de la synchronisation labiale du doublage imposent deux styles de traduction », estime Sylvain Caschelin, sous-titreur et responsable du Master 2 Traduction audiovisuelle et accessibilité à l’Université de Strasbourg. Nathan Tardy, également auteur de traduction audiovisuelle, le confirme : « Là où le doublage doit coller aux lèvres, en sous-titrage, nous avons des limites de temps et de caractère à respecter. Nous avons donc chacun des énigmes différentes à résoudre. »
Pour Netflix, par exemple, les sous-titres ne doivent pas excéder 17 caractères par seconde de dialogue, pour être considérés comme faciles à lire. « Cela dépend également du type de produit », précise Sylvain Caschelin. « Dans un programme de télé-réalité, les protagonistes parlent vite, se coupent beaucoup et il y a énormément de texte, donc cela peut être compliqué. À l’inverse, certains documentaires sont plus contemplatifs. Mais, la difficulté principale, c’est le temps donné pour travailler, qui est extrêmement variable : avec Arte, on peut avoir un mois et demi pour traduire un film de 90 minutes, tandis que pour Netflix, on peut avoir 3 ou 4 jours pour écrire un épisode de 44 minutes. Netflix ne nous met pas forcément plus de pression, mais on sait que si l’on accepte de travailler pour eux, ça se passera comme ça. »
En parallèle de toutes ces contraintes techniques, les adaptateurs de doublage et sous-titreurs doivent par ailleurs faire face au cœur de leur métier : les choix de traduction en eux-mêmes. Pour Nathan Tardy, les adaptations dépendent largement de l’auteur : « Qu’importe le texte, chaque traducteur va l’adapter à sa manière, selon ses connaissances, son contexte, son interprétation de certains éléments… Selon moi, le plus important est de conserver l’âme du texte, tout en le rendant immédiatement compréhensible. Parfois, on a beau retourner un problème dans tous les sens, on ne trouve pas d’adaptation satisfaisante, notamment avec des cultures très différentes de la nôtre. C’est le cas des animes japonais, sur lesquels je travaille régulièrement, et dont l’humour et les jeux de mots sont complexes à retranscrire. Mais, tant que ma traduction est comprise par mon public, je considère que mon travail est réussi. »
Sylvain Caschelin partage ce constat : « On se demande toujours si nos parents comprendraient une blague, par exemple. En écrivant des sous-titres, il faut aussi constamment trouver un équilibre entre la langue parlée et écrite. Si notre œil s’arrête sur un mot que l’on a jamais vu écrit alors qu’on l’entend sans problème, comme ‘seum’, on va rater les trois sous-titres suivants et il ne faut surtout pas que cela arrive. »
De son côté, Caroline Lecoq vit certains choix de traduction comme des « crève-cœurs », mais essaie toujours de se concentrer sur le principe général : « Je ne traduis pas des mots, je traduis une idée et j’essaie de le faire de façon spontanée, pour que cela soit naturel dans la bouche des acteurs. »
La rentabilité avant tout
Régulièrement critiquées, notamment sur les réseaux sociaux, mais aussi parfois par les traducteurs eux-mêmes comme sur le film Roma en 2019, les adaptations ne sont pas si simples à mettre en œuvre. Caroline Lecoq, elle, ne lit plus les retours puisque, « en général, les gens n’aiment pas la VF, donc ce n’est jamais très gentil. C’est un métier souvent méprisé, mais il est facile de critiquer lorsqu’on ne connaît pas les tenants et les aboutissants. À moins d’être né Dieu du doublage ou du sous-titrage, on reste des êtres humains. Parfois, on se trompe. Puis, le streaming a malheureusement vu naître des traductions littérales à n’en plus finir. »
Nathan Tardy le confirme : la traduction est souvent le dernier wagon de la production. « Netflix, comme les autres plateformes, vise avant tout la rentabilité. Bien sûr, on fait tous des erreurs de temps en temps. Mais, quand cela s’étend sur des épisodes entiers, c’est forcément qu’il y a eu un problème général : soit le délai alloué à la traduction était trop serré pour travailler dans de bonnes conditions, soit le budget était si bas que le sous-titrage a été confié à des amateurs, car les professionnels refusaient le contrat… Les causes sont multiples et proviennent bien souvent d’un manque d’organisation, de rigueur ou de rémunération de la part du diffuseur. La traduction est le pilier du succès de Netflix dans tous les pays non anglophones. Cependant, l’entreprise a l’air d’avoir encore un peu de mal à le comprendre, d’où la médiocrité de certaines traductions qu’elle héberge. »"
Pour en savoir plus: https://www.numerama.com/pop-culture/1110066-comment-sont-crees-les-sous-titres-et-doublages-de-vos-series-preferees.html
#metaglossia mundus