L'angle mort de la recherche mondiale : 92% des journaux scientifiques africains sont invisibles dans Scopus ou Web of Science (WoS). Si votre veille scientifique repose uniquement sur les plateformes globales, vous manquez la quasi-totalité de la production africaine subsaharienne. C'est l'un des défis de la recherche moderne : “l'impérialisme bibliométrique”(CSISZAR 2023).
Dans le prochain numéro de BASES (à paraître fin de semaine), François Libmann décortique cet enjeu majeur et vous offre la méthodologie pour rendre cette information accessible : • Pourquoi 9 revues sur 10 ne sont-elles jamais indexées en Afrique sub-saharienne ? • Quelles plateformes et dépôts consulter pour couvrir réellement le continent ? Ne laissez pas votre veille ignorer tout un continent ! 🌍 ➡️ Le nouveau numéro de BASES arrive en fin de semaine. Abonnez-vous ou soyez prêt à le commander : https://lnkd.in/eMGy2DTe
"If you like interesting snippets on all sorts of subjects relevant to academia, information, the world, highly recommended is @grip54 's collection:"
La curation de contenus, la mémoire partagée d'une veille scientifique et sociétale
Gilbert C FAURE's insight:
... designed to collect posts and informations I found and want to keep available but not relevant to the other topics I am curating on Scoop.it (on behalf of ASSIM):
because we have a long standing collaboration through a french speaking medical training program between Faculté de Médecine de Nancy and WuDA, Wuhan university medical school and Zhongnan Hospital
🚨New paper, now out in The Royal Society's Open Science.
How do educational videos affect people's behaviour on social media? Probably not much, but there's a massive risk of finding signal where there's only noise. Depending on how you run your analyses, you can get completely different results.
We ran two large, pre-registered field experiments on Twitter/X, to see if a previously validated "inoculation" video (about emotional manipulation), when deployed on social media, would prompt people to share less negative-emotional content.
To do so, we collected two lists of about 100,000 Twitter/X users and used the ad space to target them with either the "inoculation" video or a control video, respectively. We then scraped these users' timelines during a one-month window around the intervention's deployment, and ran emotion classifiers on their tweets and retweets. We hypothesised that the sharing of negative-emotional content and low-quality news would go down for treatment group users (compared to the control group), but not positive-emotional content or high-quality news.
Unfortunately, we didn't find any support for our hypotheses. As you can see in the first figure, there are no meaningful differences between the treatment and control groups.
Even worse is that we can't really claim a "true" null: our experiment was hampered by several design problems, including Twitter/X's "fuzzy matching" policy. This is a feature of the Twitter/X ad space (at the time anyway), where the company doesn't target the users you want to target, but rather 30% of them, with the remaining 70% being similar users Twitter/X has "matched" to your user sample according to some characteristics. This means that only 30% of our users were shown our interventions, but we don't know which 30%. In the end, we ran our analyses with about 92% noise (possibly more), making it impossible to find meaningful effects. We therefore call for social media companies to make it easier to do this type of research.
We also ran a series of additional (non-preregistered) longitudinal analyses, using different statistical frameworks. Our findings are cautionary: depending on your statistical choices and the analytical time window (looking at effects over 1h, 2hrs, 6hrs etc.), you get entirely different (and sometimes significant!) effects. In other words, without a strict a-priori analysis protocol, finding what you want to find becomes far too easy.
We therefore call on researchers to 1) create robust pre-registrations and follow them closely, being up-front about any deviations, and 2) conduct extensive robustness checks for intervention effects, before declaring positive findings.
This study was funded by Jigsaw, and written with the brilliant Jana Lasser, Malia Marks, Tianzhu Qin, David Garcia, Ramit Debnath, Beth Goldberg, Sander van der Linden, and Stephan Lewandowsky.
L'angle mort de la recherche mondiale : 92% des journaux scientifiques africains sont invisibles dans Scopus ou Web of Science (WoS). Si votre veille scientifique repose uniquement sur les plateformes globales, vous manquez la quasi-totalité de la production africaine subsaharienne. C'est l'un des défis de la recherche moderne : “l'impérialisme bibliométrique”(CSISZAR 2023).
Dans le prochain numéro de BASES (à paraître fin de semaine), François Libmann décortique cet enjeu majeur et vous offre la méthodologie pour rendre cette information accessible : • Pourquoi 9 revues sur 10 ne sont-elles jamais indexées en Afrique sub-saharienne ? • Quelles plateformes et dépôts consulter pour couvrir réellement le continent ? Ne laissez pas votre veille ignorer tout un continent ! 🌍 ➡️ Le nouveau numéro de BASES arrive en fin de semaine. Abonnez-vous ou soyez prêt à le commander : https://lnkd.in/eMGy2DTe
Information about the roles of each author of a paper can help to build trust, integrity and responsible research assessment. Coordinated efforts are needed to consolidate progress.
Une marche poétique et contemplative dans les cols et les forêts blessées des Vosges. Ce film n’est pas un documentaire classique. C'est un hommage silencieux à ceux qui ont combattu, à ceux qui sont tombés, à ceux que l’on n’oublie pas.
À travers des images immersives et des souvenirs qui transpirent dans la pierre et la forêt, ce voyage vous invite à ressentir plus qu’à comprendre.
🕯️ Lieux visités : Col de Sainte-Marie, Carrefour Duchesne, Lingekopf, Nécropole du Wettstein, Hartmannswillerkopf, Cimetière allemand de Montgoutte, La Fontenelle, La Chipotte…
🔍 Mots-clés : Vosges, Première Guerre mondiale, mémoire 14-18, film poétique guerre, lieux de mémoire, WW1, document historique, col du Linge, Lingekopf, poilus, champs de bataille, Hartmannswillerkopf, HWK, film contemplatif, front des Vosges, mémoire des soldats, guerre 14-18 France.
⏱️ Chapitres : 00:00 – Prologue 00:39 – Borne frontière 1871 01:17 – Col du Bonhomme 01:52 – Nécropole nationale de Sainte-Marie-aux-Mines 02:47 – Bunker en forêt 03:37 – Cimetière militaire du Carrefour Duchesne 05:33 – Lingekopf (Col du Linge) 12:13 – Nécropole nationale du Wettstein 15:08 – Hartmannswillerkopf (Vieil Armand) 24:03 – Historial Franco-Allemand / partie sommitale 28:29 – Cimetière allemand de Montgoutte 31:27 – Nécropole nationale de La Fontenelle 33:44 – Abords de La Fontenelle 34:54 – Nécropole nationale de La Chipotte
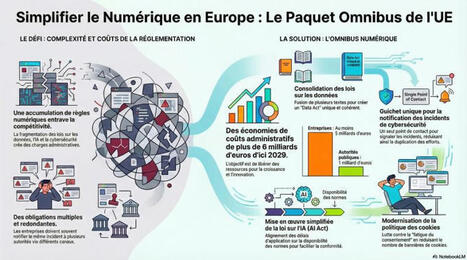
C'est assez cocasse : je teste la fonction infographie de notebookKLM sur le paquet omnibus digital de l'UE... il y avait dans les 10 sources des articles critiques sur les modifications envisagées. Le Llm n'a retenu que l'argumentaire pro paquet omnibus. Il est vrai statistiquement plus volumineux dans le corpus.
There have been plenty of big studies in hundreds of thousands of children across the world that have thoroughly investigated the claim and found no link between vaccines and autism.
ALL evidence has been considered by public health authorities in Europe and beyond.
Only exception is for fraudolent studies, which I guess we ALL agree should be ignored, right?
Instead, what we should be mainly concerned today is the resurgence of measles.
Let’s keep our children vaccinated and protected!
If you are interested, more details from European Medicines Agency on this and other vaccines topics just published here:
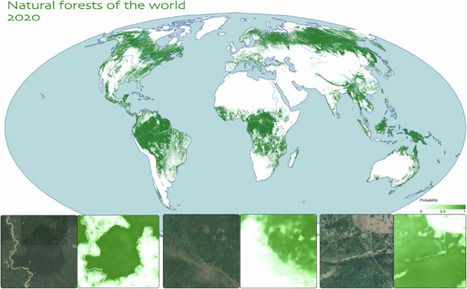
Informed decisions to reduce deforestation, protect biodiversity, and curb carbon emissions require not just knowing where forests are, but understanding their composition. Identifying natural forests, which serve as critical biodiversity hotspots and major carbon sinks, is particularly valuable. We developed a novel global natural forest map for 2020 at 10 m resolution. This map can support initiatives like the European Union’s Deforestation Regulation (EUDR) and other forest monitoring or conservation efforts that require a comprehensive baseline for monitoring deforestation and degradation. The globally consistent map represents the probability of natural forest presence, enabling nuanced analysis and regional adaptation for decision-making. Evaluation using a global independent validation dataset demonstrated an overall accuracy of about 92%.
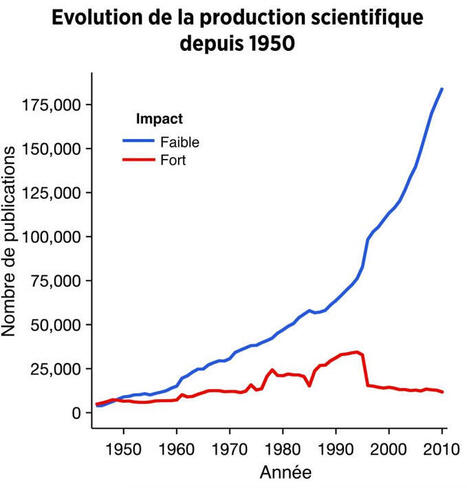
J'étais un peu sonné en découvrant ce graph : La production scientifique n’a jamais été aussi élevée...et pourtant, les grandes découvertes stagnent.
Ici, on voit comment évolue le nombre d'articles scientifiques parus depuis 1950. En bleu, les articles qui ont eu peu d'impact 🔵 En rouge, ceux qui ont changé quelque chose 🔴
Le constat n'est pas terrible : ➡️ La production totale explose. ➡️ Mais cette augmentation ne se fait pas ressentir sur le taux de grandes découvertes.
Le système académique est en cause. Les chercheurs sont poussés à publier plus et plus vite pour être compétitif. Résultat : on prend moins de risque, on s'aventure moins dans les territoires inconnus, on multiplie les petites avancées. Moi même, j'encourage mes doctorants à viser des petits projets faciles – pour assurer leur emploi après la thèse.
La science est une immense intelligence distribuée, mais pour que ça fonctionne, il faut que l'intérêt collectif prime sur l'intérêt individuel. Et depuis quelques décennies, c'est de moins en moins le cas.
Que faire ? ➡️ Encourager la prise de risque, même si elle n'est pas productive. Mais c'est plus facile à dire qu'à faire...
Update - la source du graph (désolé pour l’oubli) : https://lnkd.in/eg8UnD3X | 260 comments on LinkedIn
There is no bridge between LLMs and authoritative content. That is a huge problem, and it is exactly what we are fixing.
LLMs are transforming how we discover information, but they still cannot meaningfully engage with the most trustworthy content on the internet: peer-reviewed research.
Why? Paywalls and licensing.
Right now, there is no reliable, scalable way to connect AI retrieval to authoritative research. If LLMs are the future of how we find answers, that gap is a serious problem for research institutions, businesses, and education.
Building real-time feeds of new publications across many publishers is a massive technical lift. Negotiating and maintaining licensing so AI can use that content is an equally big and still evolving challenge.
The good news is that we do not have to start from scratch.
Scite already operates indexing infrastructure that connects to leading publishers and powers our smart citations. Those citations carry context and classification and are created under direct indexing and licensing agreements with publishers.
We're working with publishers to provide to create citations for LLMs.
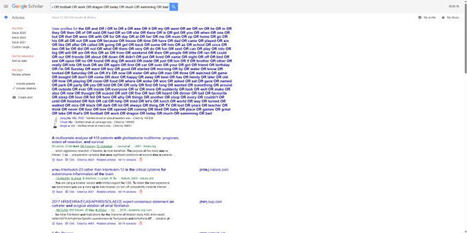
🚀 One week after Google launched Google Scholar Labs, everyone (rightfully) focused on the shiny new AI features.
But something else changed quietly — While reviewing the classic Google Scholar interface, Search Smart noticed that almost everything stayed the same… except one key feature: ⬆️ The maximum query length increased 8-fold — from 256 characters to 2048.
This means we can now run much more complex and expressive searches that were previously impossible because of strict query caps. A major boost for power users and advanced search strategies.
⚠️ IMPORTANT: Longer queries ≠ reliable Boolean logic: Despite the new 2048-character limit, Google Scholar’s Boolean operators remain highly unreliable (OR, NOT break immediately; AND fails under complex conditions). Don’t expect deterministic Boolean logic working similar to Scopus, PubMed, or Web of Science.
🔗Here is the full information on what you can and cannot do with Google Scholar (via Search Smart: https://lnkd.in/dcdcmKVT).
Anne-Wil Harzing 🟪 — this might be especially relevant for Publish or Perish, since PoP is still the most effective tool for querying and exporting Google Scholar data.
🔧Given the timing, I can’t help but wonder if the longer query limit is connected to how Labs handles natural-language questions — maybe it simply needs longer queries to work. | 11 comments on LinkedIn
J’ai analysé les grandes tendances de cette COP 30 sur 𝙓, 𝙇𝙞𝙣𝙠𝙚𝙙𝙄𝙣 𝙚𝙩 𝙡𝙚𝙨 𝙢𝙚́𝙙𝙞𝙖𝙨 𝙚𝙣 𝙡𝙞𝙜𝙣𝙚, à partir de données 𝘝𝘪𝘴𝘪𝘣𝘳𝘢𝘪𝘯. Une édition massive, ultra visible, mais surtout marquée par une rupture profonde dans la manière dont le climat est raconté.
✅ 𝗟𝗲 𝗰𝗹𝗶𝗺𝗮𝘁 𝗱𝗲𝘃𝗶𝗲𝗻𝘁 𝘂𝗻 𝗰𝗵𝗮𝗺𝗽 𝗱𝗲 𝗯𝗮𝘁𝗮𝗶𝗹𝗹𝗲 𝗻𝗮𝗿𝗿𝗮𝘁𝗶𝗳. À Belém, la COP n’a pas seulement produit des engagements, elle a révélé une bascule dans les discours.
1 ↳ 𝗨𝗻𝗲 𝗖𝗢𝗣 𝗺𝗼𝗻𝗱𝗶𝗮𝗹𝗲𝗺𝗲𝗻𝘁 𝘃𝗶𝘀𝗶𝗯𝗹𝗲 : plus de 500 000 mentions avant même l’ouverture et près de 2,8 M au global, malgré un agenda saturé (Trump, tensions géopolitiques, crises régionales). Le climat reste un sujet majeur, même au milieu du bruit mondial.
2 ↳ 𝗧𝗿𝗼𝗶𝘀 𝗺𝗼𝗻𝗱𝗲𝘀 𝗾𝘂𝗶 𝗻𝗲 𝘃𝗶𝘃𝗲𝗻𝘁 𝗽𝗮𝘀 𝗹𝗮 𝗺𝗲̂𝗺𝗲 𝗖𝗢𝗣 : sur X, indignation et conflictualités. Sur LinkedIn, institutionnalisation et solutions. Dans les médias, lecture diplomatique. Une schizophrénie numérique totale.
3 ↳ 𝗨𝗻𝗲 𝗿𝗲𝗽𝗿𝗶𝘀𝗲 𝗱𝘂 𝗻𝗮𝗿𝗿𝗮𝘁𝗶𝗳 𝗰𝗹𝗶𝗺𝗮𝘁𝗶𝗾𝘂𝗲 𝗽𝗮𝗿 𝗹𝗲 𝗦𝘂𝗱 𝗴𝗹𝗼𝗯𝗮𝗹 : le Brésil impose un récit plus politique, plus territorial et plus incarné. C’est une rupture majeure dans l’histoire des COP.
4 ↳ 𝗟𝗮 𝗱𝗲́𝘀𝗶𝗻𝗳𝗼𝗿𝗺𝗮𝘁𝗶𝗼𝗻, 𝘂𝗻 𝗲𝗻𝗷𝗲𝘂 𝗽𝗼𝗹𝗶𝘁𝗶𝗾𝘂𝗲 : la COP 30 reconnaît la question de l’intégrité de l’information comme condition de l’action. Un tournant nécessaire à l’heure où les récits climatiques sont instrumentalisés.
🔍 L’IA redéfinit le rôle du veilleur : vers un analyste stratégique et expert
🎤 Merci au Journal du Net pour cette nouvelle collaboration autour d’un enjeu de fond pour les organisations à l’heure de l’IA !
Chez KB Crawl, nous voyons chaque jour comment l’IA générative redéfinit le métier de veilleur. Loin de le remplacer, elle renforce son rôle et l’amène à devenir un véritable analyste, capable de donner du sens, de contextualiser l’information et d’anticiper les mouvements du marché.
💡À travers la contribution d’Arnaud Marquant, notre Directeur des Opérations, nous partageons notre vision d’une veille capable d’éclairer les décisions stratégiques, d’identifier les signaux faibles et d’accompagner les organisations dans un environnement en constante évolution.
Si tu crois qu’un enseignant-chercheur passe 90 % de son temps à réfléchir dans le vide, regarde ça. Beaucoup pensent qu’un enseignant-chercheur donne quelques cours… puis rentre chez lui. La réalité : un métier passionnant… mais exigeant, polyvalent et souvent invisible. J’ai résumé en 10 slides ce que l’on ne dit pas assez et ce que je fais dans mon métier. | 62 comments on LinkedIn
Qui obtient le meilleur score à un test de diagnostics médicaux ? Le médecin, l’IA… ou le collectif ?
Dans cette étude conduite par mes collègues du Max Planck Institute, l’exercice est simple : retrouver la bonne maladie à partir du dossier d’un patient (sans examen physique, ce n’est pas aussi complexe qu'une vraie consultation ⚠️).
Et voici les résultats :
1️⃣ Individuellement, les LLM dépassent le médecin moyen. Pas si étonnant finalement : ils ont ingéré toute la littérature médicale.
2️⃣ L’intelligence collective cartonne Deux médecins = une IA. Cinq médecins = excellent score. Et, fait intéressant : on peut construire des collectifs d’IA, qui obtiennent aussi un très bon score.
3️⃣ Mais le meilleur de tous… c’est le collectif *hybride* : humain + IA en même temps. En fusionnant les diagnostics des deux, on obtient les performances les plus élevées.
Pourquoi ? Parce que les humains et les machines font des erreurs différentes. Leurs biais ne sont pas corrélés. C’est précisément cette diversité qui rend le mélange si puissant.
👉 Ce n’est donc ni l’humain, ni la machine, qui est le plus fort, mais la combinaison des deux : le collectif augmenté.
Bref, plutôt que d’opposer humains et IA, apprenons à les faire collaborer :)
------ Réf. : Zöller et al., 2025. “Human–AI collectives most accurately diagnose clinical vignettes”, PNAS.| 152 commentaires sur LinkedIn
Academic publishing is a very lucrative business for a very small number of private academic publishers. This paper provides a comprehensive overview of the direct and indirect channels through which public spending benefits big academic publishing companies (subscription costs, publication costs, peer reviews, scientific output). For Austria, the paper estimates that public spending (directly and indirectly) benefits publishing companies with an amount corresponding to about 25% of the annual basic funding Austrian universities receive from the Ministry of education.
Flashcards automatiques, quiz ajustables selon votre niveau, guides pédagogiques interactifs… et maintenant #DeepResearch pour décortiquer les sources web les plus complexes ! 📚✨ #NotebookLM n'en finit pas de s'améliorer. #EdTech #Apprentissage #Innovation
To get content containing either thought or leadership enter:
To get content containing both thought and leadership enter:
To get content containing the expression thought leadership enter:
You can enter several keywords and you can refine them whenever you want. Our suggestion engine uses more signals but entering a few keywords here will rapidly give you great content to curate.







 Your new post is loading...
Your new post is loading...