Your new post is loading...
Your new post is loading...

|
Scooped by
Gilbert C FAURE
October 13, 2013 8:40 AM
|
is a personal Notebook Thanks John Dudley for the following tweet "If you like interesting snippets on all sorts of subjects relevant to academia, information, the world, highly recommended is @grip54 's collection:" La curation de contenus, la mémoire partagée d'une veille scientifique et sociétale
|
|
Scooped by
Gilbert C FAURE
November 21, 10:48 AM
|
|
|
Scooped by
Gilbert C FAURE
November 21, 10:41 AM
|
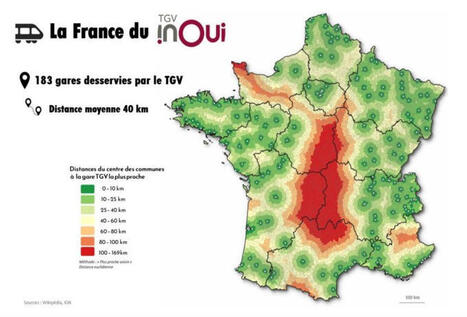
🇫🇷 🚄 Impressionnant. Voici la France des gares TGV.
🔴 En rouge, ce sont les zones à plus de 100km d'une gare de train à grande vitesse.
Je vous laisse réagir à cet excellent travail de Boris Mericskay
Découvrez tout son travail ici
https://buff.ly/4gRj2Ek
#train #transport #france #mobilité #aménagement #territoire
Pour vous abonner à ma newsletter, vous pouvez cliquer ici
https://buff.ly/3vC6uhc | 72 comments on LinkedIn
|
|
Scooped by
Gilbert C FAURE
November 21, 4:17 AM
|
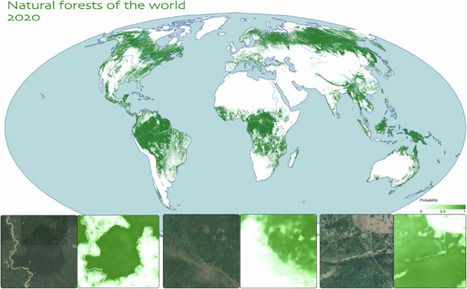
Informed decisions to reduce deforestation, protect biodiversity, and curb carbon emissions require not just knowing where forests are, but understanding their composition. Identifying natural forests, which serve as critical biodiversity hotspots and major carbon sinks, is particularly valuable. We developed a novel global natural forest map for 2020 at 10 m resolution. This map can support initiatives like the European Union’s Deforestation Regulation (EUDR) and other forest monitoring or conservation efforts that require a comprehensive baseline for monitoring deforestation and degradation. The globally consistent map represents the probability of natural forest presence, enabling nuanced analysis and regional adaptation for decision-making. Evaluation using a global independent validation dataset demonstrated an overall accuracy of about 92%.
|
|
Scooped by
Gilbert C FAURE
November 20, 4:44 AM
|
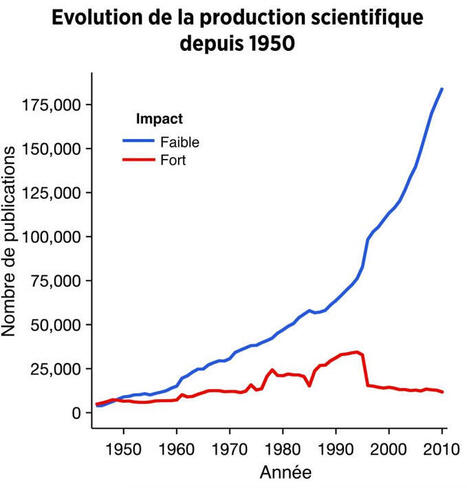
J'étais un peu sonné en découvrant ce graph : La production scientifique n’a jamais été aussi élevée...et pourtant, les grandes découvertes stagnent.
Ici, on voit comment évolue le nombre d'articles scientifiques parus depuis 1950.
En bleu, les articles qui ont eu peu d'impact 🔵
En rouge, ceux qui ont changé quelque chose 🔴
Le constat n'est pas terrible :
➡️ La production totale explose.
➡️ Mais cette augmentation ne se fait pas ressentir sur le taux de grandes découvertes.
Le système académique est en cause. Les chercheurs sont poussés à publier plus et plus vite pour être compétitif. Résultat : on prend moins de risque, on s'aventure moins dans les territoires inconnus, on multiplie les petites avancées. Moi même, j'encourage mes doctorants à viser des petits projets faciles – pour assurer leur emploi après la thèse.
La science est une immense intelligence distribuée, mais pour que ça fonctionne, il faut que l'intérêt collectif prime sur l'intérêt individuel. Et depuis quelques décennies, c'est de moins en moins le cas.
Que faire ?
➡️ Encourager la prise de risque, même si elle n'est pas productive.
Mais c'est plus facile à dire qu'à faire...
Update - la source du graph (désolé pour l’oubli) :
https://lnkd.in/eg8UnD3X | 260 comments on LinkedIn
|
|
Scooped by
Gilbert C FAURE
November 18, 4:29 AM
|
There is no bridge between LLMs and authoritative content. That is a huge problem, and it is exactly what we are fixing.
LLMs are transforming how we discover information, but they still cannot meaningfully engage with the most trustworthy content on the internet: peer-reviewed research.
Why? Paywalls and licensing.
Right now, there is no reliable, scalable way to connect AI retrieval to authoritative research. If LLMs are the future of how we find answers, that gap is a serious problem for research institutions, businesses, and education.
Building real-time feeds of new publications across many publishers is a massive technical lift. Negotiating and maintaining licensing so AI can use that content is an equally big and still evolving challenge.
The good news is that we do not have to start from scratch.
Scite already operates indexing infrastructure that connects to leading publishers and powers our smart citations. Those citations carry context and classification and are created under direct indexing and licensing agreements with publishers.
We're working with publishers to provide to create citations for LLMs.
Want to learn more? DM me.
|
|
Scooped by
Gilbert C FAURE
November 18, 4:23 AM
|
BDM a #comparé les principaux #outils d'#IA BDM
|
|
Scooped by
Gilbert C FAURE
November 16, 4:50 AM
|
|
|
Scooped by
Gilbert C FAURE
November 15, 4:41 AM
|
Fraude scientifique : analyse d’un phénomène en hausse - Une Tribune à découvrir sur Polytechnique Insights
|
|
Scooped by
Gilbert C FAURE
November 14, 1:25 PM
|
14 Go, c’est le poids du modèle d’IA que je fais tourner… sur mon ordinateur, en local 💻
Pas sur les serveurs d’OpenAI, pas dans le cloud de Google... mais bien sur mon MacBook personnel. Et honnêtement, ça change pas mal de choses dans ma manière d’utiliser l’IA au quotidien.
Depuis plusieurs mois, je teste Ollama, un outil qui permet d’installer des modèles open source directement sur sa machine. Llama 3.2 (Meta), Mistral ou GPT-OSS, le modèle open source d’OpenAI… tout fonctionne en local, sans connexion internet, sans transfert de données et sans aucun abonnement mensuel. C’est simple à installer et, surtout, très confortable à l’usage.
Concrètement, voilà ce que j’y gagne :
→ Mes documents sensibles restent sur ma machine et n’en sortent jamais
→ Le coût mensuel tombe à… 0 € (pas d'abonnement à payer)
→ L’outil fonctionne partout, même hors ligne
→ Les modèles récents sont plutôt rapides et réactifs
→ L’impact environnemental est bien plus faible que dans le cloud
Attention, il y a quand même quelques limites à garder en tête :
→ Une machine avec 16 Go de RAM reste idéale pour une expérience fluide
→ Les modèles peuvent peser lourd (jusqu'à 65 Go pour les plus puissants)
→ On ne remplace pas les tout derniers grands modèles pour les tâches plus complexes ou spécialisées
Pour le reste, c’est-à-dire environ 80 % de mes usages quotidiens (aide à la rédaction, correction, résumé de documents, code simple…), l’IA locale fait plutôt bien le travail et apporte même une vraie sensation de maîtrise... et de liberté !
On retrouve un contrôle qu’on avait clairement perdu avec les plateformes cloud, tout en gagnant en sobriété (je ne sollicite pas un data center à chaque requête et ça change vraiment la donne) et en confidentialité.
Je ne pense pas que l’IA locale remplacera les grands modèles hébergés dans le cloud, mais elle offre une alternative plus autonome, plus sobre et plus respectueuse de la vie privée. Et je suis convaincu qu’on va en voir de plus en plus dans les mois à venir.
Je vous partage une courte vidéo pour montrer concrètement ce que ça donne avec quelques tests simples.
Et si ça vous intéresse, j’en parle plus en détail dans ma dernière newsletter : https://lnkd.in/eTz2anJ4
Certains d’entre vous utilisent déjà l’IA en local ? Vos retours m’intéressent vraiment 👇 | 28 comments on LinkedIn
|
|
Scooped by
Gilbert C FAURE
November 14, 1:16 PM
|
Claude Vanony fête ses 90 ans sur scène ce samedi 22 et dimanche 23 novembre à l'Espace L.A.C de Gérardmer ! ICI Lorraine lui consacre cette semaine spéciale et vous invite à son spectacle.
|
|
Scooped by
Gilbert C FAURE
November 13, 6:29 AM
|
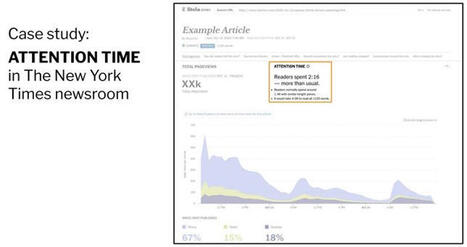
Pourquoi le New York Times mise tout sur le « temps d’attention »
Comment mieux mesurer l’impact réel d’un article ? Pour le NYT, la réponse ne se trouve plus dans les simples clics, mais dans le temps passé par les lecteurs sur chaque contenu. Un changement stratégique, qui redéfinit la manière dont la rédaction s’aligne sur les objectifs de l’entreprise.
1️⃣ Une métrique devenue centrale
En 2024, le New York Times a placé le temps d’attention au cœur de son pilotage éditorial. L’objectif ? Créer des habitudes de lecture plus profondes. Pour Hayley Arader, directrice exécutive data et insights pour la newsroom : « le projet autour du temps d’attention a permis de cultiver le comportement que nous recherchions chez les lecteurs, ce que le simple suivi des pages vues ne permet pas ».
Le choix de cette métrique n’est pas anodin : il répond à deux finalités claires. Côté rédaction, il s’agit de mieux comprendre les préférences des lecteurs. Côté business, le but est de prolonger le temps passé sur la plateforme.
2️⃣ Un cadre d’analyse rigoureux
Pour que cette donnée soit utile, encore faut-il l’interpréter dans le bon contexte. Le Times a mis au point un modèle permettant de comparer la durée moyenne passée sur un article selon :
▪️sa longueur,
▪️son thème,
▪️sa promotion sur le site,
▪️la source du trafic,
▪️et même les fuseaux horaires des lecteurs.
Grâce à ces modèles, chaque article est positionné au-dessus ou en dessous de la moyenne attendue. Ce benchmark permet de ne pas tirer de conclusions hâtives sur les performances.
3️⃣ Une stratégie visuelle et pédagogique
Le tps d’attention est aujourd’hui affiché tout en haut du tableau de bord des audiences pour chaque article. Mais le Times a refusé toute approche culpabilisante. Pas de texte en rouge ou vert, mais du noir uniquement. « Nous voulons que ce soit un outil d’apprentissage, pas une grille de performance ».
💎 Pour accompagner ce changement, la rédaction a diffusé un guide complet, avec une FAQ accessible à tous. Et surtout, ce changement a été porté autant par la direction que par les équipes. « Cela a marché car c’est venu du haut comme du bas ».
4️⃣ Une lecture enrichie par les formats
Autre constat clé : le multimédia joue un rôle déterminant. Vidéos, photos, interactifs… influencent fortement le temps passé. Le Times a donc intégré ces formats dans ses modèles, pour suivre précisément leur impact. « C’est essentiel pour être pertinent dans le nouvel Internet ».
Comprendre comment les lecteurs naviguent sur les pages, interagissent avec les formats et reviennent ou non, devient vital pour créer des récits plus immersifs et engageants.
5️⃣ Une culture data au service du journalisme
Comme le relève Hayley Arader : « nous répétons sans cesse que le jugement éditorial passe en premier. C’est ce qui nous a permis de réussir dans l’utilisation des données ».
👉 Lien en commentaire.
|
|
Scooped by
Gilbert C FAURE
November 13, 6:19 AM
|
Testez votre profil en termes de Litteratie à l’IA développé par l’Université Laval au Québec
|
|
|
Scooped by
Gilbert C FAURE
Today, 4:33 AM
|
🔍 L’IA redéfinit le rôle du veilleur : vers un analyste stratégique et expert
🎤 Merci au Journal du Net pour cette nouvelle collaboration autour d’un enjeu de fond pour les organisations à l’heure de l’IA !
Chez KB Crawl, nous voyons chaque jour comment l’IA générative redéfinit le métier de veilleur. Loin de le remplacer, elle renforce son rôle et l’amène à devenir un véritable analyste, capable de donner du sens, de contextualiser l’information et d’anticiper les mouvements du marché.
💡À travers la contribution d’Arnaud Marquant, notre Directeur des Opérations, nous partageons notre vision d’une veille capable d’éclairer les décisions stratégiques, d’identifier les signaux faibles et d’accompagner les organisations dans un environnement en constante évolution.
👉Découvrez l’article complet sur le JDN : https://lnkd.in/eksxEf6Y
#VeilleStratégique #IA #Innovation #Analyse #Transformation #Résilience #FutureOfWork
|
|
Scooped by
Gilbert C FAURE
November 21, 10:43 AM
|
Si tu crois qu’un enseignant-chercheur passe 90 % de son temps à réfléchir dans le vide, regarde ça.
Beaucoup pensent qu’un enseignant-chercheur donne quelques cours… puis rentre chez lui.
La réalité : un métier passionnant… mais exigeant, polyvalent et souvent invisible.
J’ai résumé en 10 slides ce que l’on ne dit pas assez et ce que je fais dans mon métier. | 62 comments on LinkedIn
|
|
Scooped by
Gilbert C FAURE
November 21, 4:18 AM
|
Qui obtient le meilleur score à un test de diagnostics médicaux ?
Le médecin, l’IA… ou le collectif ?
Dans cette étude conduite par mes collègues du Max Planck Institute, l’exercice est simple : retrouver la bonne maladie à partir du dossier d’un patient (sans examen physique, ce n’est pas aussi complexe qu'une vraie consultation ⚠️).
Et voici les résultats :
1️⃣ Individuellement, les LLM dépassent le médecin moyen.
Pas si étonnant finalement : ils ont ingéré toute la littérature médicale.
2️⃣ L’intelligence collective cartonne
Deux médecins = une IA.
Cinq médecins = excellent score.
Et, fait intéressant : on peut construire des collectifs d’IA, qui obtiennent aussi un très bon score.
3️⃣ Mais le meilleur de tous… c’est le collectif *hybride* : humain + IA en même temps.
En fusionnant les diagnostics des deux, on obtient les performances les plus élevées.
Pourquoi ? Parce que les humains et les machines font des erreurs différentes. Leurs biais ne sont pas corrélés. C’est précisément cette diversité qui rend le mélange si puissant.
👉 Ce n’est donc ni l’humain, ni la machine, qui est le plus fort, mais la combinaison des deux : le collectif augmenté.
Bref, plutôt que d’opposer humains et IA, apprenons à les faire collaborer :)
------
Réf. : Zöller et al., 2025. “Human–AI collectives most accurately diagnose clinical vignettes”, PNAS.| 152 commentaires sur LinkedIn
|
|
Scooped by
Gilbert C FAURE
November 20, 9:45 AM
|
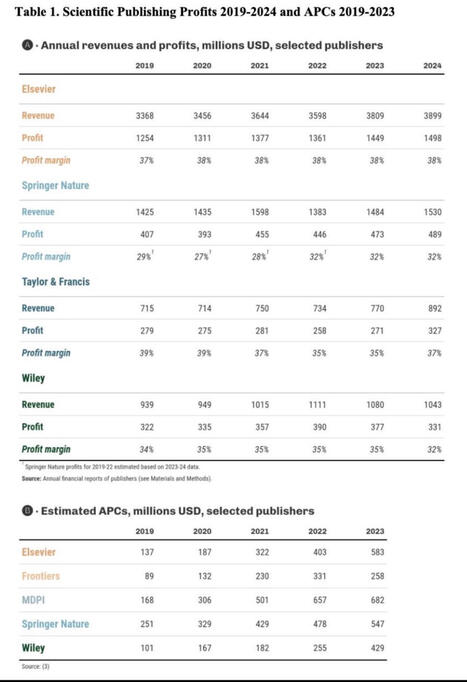
Academic publishing is a very lucrative business for a very small number of private academic publishers. This paper provides a comprehensive overview of the direct and indirect channels through which public spending benefits big academic publishing companies (subscription costs, publication costs, peer reviews, scientific output). For Austria, the paper estimates that public spending (directly and indirectly) benefits publishing companies with an amount corresponding to about 25% of the annual basic funding Austrian universities receive from the Ministry of education.
Link to the paper in "PLOS One": https://lnkd.in/ew926Y4q
|
|
Scooped by
Gilbert C FAURE
November 19, 10:24 AM
|
This article is part of an ongoing series looking at AI in KM, and KM in AI. The Dunning-Kruger Effect (DKE)[1. Kruger, J., & Dunning, D. (1999).
|
|
Scooped by
Gilbert C FAURE
November 18, 4:28 AM
|
Flashcards automatiques, quiz ajustables selon votre niveau, guides pédagogiques interactifs… et maintenant #DeepResearch pour décortiquer les sources web les plus complexes ! 📚✨
#NotebookLM n'en finit pas de s'améliorer.
#EdTech #Apprentissage #Innovation
|
|
Scooped by
Gilbert C FAURE
November 17, 4:08 AM
|
|
|
Scooped by
Gilbert C FAURE
November 16, 4:48 AM
|
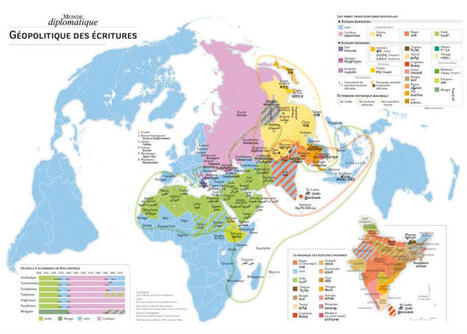
✍️ Excellent. La géographie de l'écriture.
Cette carte du Monde diplomatique est magnifique. A découvrir ici https://buff.ly/Mz2E1jt
Il existe seulement 23 systèmes d'écriture officiels en 2025.
Et 293 systèmes recensés dans l'histoire (actuels + historiques) selon la base de données incroyable : World Writing Systems https://buff.ly/ObjP2TB
Quand on regarde les nations, on peut voir des frontières.
Mais quand on regarde les écritures, on voit des civilisations.
L'écriture est au coeur de la relation complexe entre les peuples, l'espace et le temps.
🔤 Depuis l'Occident, l’alphabet latin s’est diffusé comme un même. 26 lettres pour dire toutes les langues du globe : un outil d’efficacité, le vecteur idéal de la mondialisation. C'est le système d’écriture le plus répandu : environ 70 % de la population mondiale l’utilise.
🌀 En Asie de l’Est, les idéogrammes d'origine chinoise hanzi/kanji — logogrammes millénaires — condensent la pensée en caractère. Chaque symbole est un paysage miniature: “montagne”, “rivière”, “cœur”. Ce n’est pas un alphabet, c’est une cosmologie d'encre et d'histoire. Un système utilisé par environ 1,34 milliard de personnes
🕎 Au Moyen-Orient et en Afrique, l’écriture arabe, fluide et calligraphique, épouse le souffle du Coran et traverse les déserts, du Maghreb à l’Indonésie. L’écriture devient prière, onde, mouvement. Le système arabe est estimé à environ 660 millions d’utilisateurs
🪶 En Inde, les alphasyllabaires — Devanagari, Tamil, Bengali... — traduisent la complexité phonétique d’un sous-continent où le langage est une discipline spirituelle. A lui seul, le système devanāgarī (utilisé pour l’hindi, le népalais, etc.) compte environ 600 millions d’utilisateurs. Presque autant que l'arabe.
⚫ En Afrique, les écritures renaissent : le N’ko, le Tifinagh, l’Adlam… Des inventions récentes pour redonner voix aux langues orales, effacées par la colonisation.
🌐 Et aujourd’hui, le monde numérique impose une nouvelle carte invisible : celle de l’Unicode, ce langage commun des machines qui encode toutes les écritures du monde… mais les range, encore une fois, dans un même système.
📜 Regarder la carte des écritures, c’est regarder la Terre à travers ses voix.
Chaque système d’écriture est une manière d’habiter le réel, de relier le visible et l’invisible.
La carte en version PDF ici : https://buff.ly/6xa6kaX
#écriture #geo #map #world #writing
—
Suivez ma newsletter hashtag#Cosmorama pour recevoir chaque semaine une carte, une image, une découverte sur le monde ! 🌍 Pour s'abonner, c'est ici : https://buff.ly/gAMRazF | 24 comments on LinkedIn
|
|
Scooped by
Gilbert C FAURE
November 14, 1:38 PM
|
|
|
Scooped by
Gilbert C FAURE
November 14, 1:19 PM
|
𝐓𝐡𝐞 𝐑𝐢𝐬𝐞 𝐚𝐧𝐝 𝐅𝐚𝐥𝐥 𝐨𝐟 𝐭𝐡𝐞 “𝐇𝐢𝐠𝐡𝐥𝐲 𝐂𝐢𝐭𝐞𝐝 𝐑𝐞𝐬𝐞𝐚𝐫𝐜𝐡𝐞𝐫𝐬” 𝐋𝐢𝐬𝐭
In her Quantitative Science Studies paper, Lauranne Chaignon traces the 20-year evolution of Clarivate’s Highly Cited Researchers (HCR) list: a ranking that once defined academic prestige and still shapes the Shanghai University Rankings.
𝐊𝐞𝐲 𝐅𝐢𝐧𝐝𝐢𝐧𝐠𝐬
𝐓𝐡𝐫𝐞𝐞 𝐝𝐢𝐬𝐭𝐢𝐧𝐜𝐭 𝐞𝐫𝐚𝐬 (2001–2023):
➡️ 𝐃𝐚𝐭𝐚𝐛𝐚𝐬𝐞 𝐞𝐫𝐚 (2001–2011): Created by Eugene Garfield’s Institute for Scientific Information (ISI) as a rich, biographical database of influential scientists
➡️ 𝐈𝐧𝐝𝐢𝐜𝐚𝐭𝐨𝐫 𝐞𝐫𝐚 (2012–2018): Under Thomson Reuters and Clarivate, the list became an annual metric of research excellence, stripped of biography and tightly linked to university rankings
➡️ 𝐈𝐧𝐭𝐞𝐠𝐫𝐢𝐭𝐲 𝐜𝐫𝐢𝐬𝐢𝐬 (2019–2023): Growing cases of self-citation, manipulation, and fake affiliations forced Clarivate to adopt “qualitative filters” and partnerships with watchdogs like Retraction Watch to exclude fraudulent entries (over 13% in 2023)
➡️ Changing purpose: Once a tool for scholarly networking, the list is now a symbol of academic reputation and competition, with major policy and funding implications
➡️ Crisis of credibility: Scandals (e.g. Saudi universities paying foreign researchers for nominal affiliations) have exposed how metrics can be gamed, threatening Clarivate’s authority
𝐓𝐡𝐞 𝐅𝐮𝐭𝐮𝐫𝐞?
After removing mathematics entirely from the 2023 list due to manipulation, Clarivate faces a critical question: can citation-based metrics still define true research influence?
Interesting insights into how a bibliometric tool became both a global status symbol and a cautionary tale about measurement, integrity, and the commercialization of scientific prestige.
#science #research #integrity #impact #productivity
Jason Thatcher Timo Mandler Rüdiger Hahn Giampaolo Viglia
|
|
Scooped by
Gilbert C FAURE
November 14, 4:19 AM
|
Jamie Q. Roberts, University of Sydney I don’t know about you, but ever since I can remember – from my early teens – I have been bemused about the end
|
|
Scooped by
Gilbert C FAURE
November 13, 6:21 AM
|
🎥✈️ Une vidéo impressionnante de 1919 d’un aviateur français
Un an après la fin de la Grande Guerre, le pilote français Jacques Trolley de Prévaux entreprend un vol exceptionnel : à bord de son dirigeable, il survole les anciens champs de bataille depuis la côte belge jusqu’à Verdun.
Sous lui, un paysage apocalyptique — villages effacés, forêts rasées, tranchées à perte de vue — mais aussi le théâtre des exploits de millions de soldats qui ont tenu, avancé, résisté.
Ces images, tournées en 1919 et restaurées en couleur et en haute définition, redonnent vie à ces lieux où la France s’est battue pied à pied pour sa survie.
--
Si ce post vous a plu, restez en alerte et abonnez-vous à notre lettre d'information exclusive : https://lnkd.in/dwQnfhw4 | 77 comments on LinkedIn
|
|
Scooped by
Gilbert C FAURE
November 13, 6:17 AM
|
The editors of the non predator scientific journals are often doing a good job but without the free help of the scientific community it would not be possible. However the huge profit they make (at least 32% of their revenue) is not acceptable as it is made with money of the taxpayer or of donators. It should change…
|