Your new post is loading...
Your new post is loading...

|
Scooped by
Gilbert C FAURE
October 13, 2013 8:40 AM
|
is a personal Notebook Thanks John Dudley for the following tweet "If you like interesting snippets on all sorts of subjects relevant to academia, information, the world, highly recommended is @grip54 's collection:" La curation de contenus, la mémoire partagée d'une veille scientifique et sociétale
|
|
Scooped by
Gilbert C FAURE
April 17, 4:00 AM
|
#OEWeek26 #Review 🔥 If you didn't get to all the @libretext sessions - here's your chance to catch up.
LibreTexts has compiled a playlist of all their #OEWeek sessions
Watch them all here 🔎 https://twp.ai/IlpbO1
#English #oeglobal #openeducation
|
|
Scooped by
Gilbert C FAURE
April 16, 9:08 AM
|
As a daughter of a rocket scientist, I adore this!!
|
|
Scooped by
Gilbert C FAURE
April 16, 8:57 AM
|
🚨 124 Papers. Clinical AI Models Built on Data of Unknown Origin
A new analysis linked more than 100 peer-reviewed studies to two widely used stroke and diabetes datasets with unknown origins and data patterns inconsistent with real patients. Some downstream models may already have reached clinical or public-facing settings.
Open data sharing is critical for AI progress. But in clinical AI, openness without provenance is not transparency.
Three points matter for implementation:
• Dataset provenance is part of model validity
If the origin, collection process, and population are unclear, performance metrics are not interpretable.
• Robust dataset evaluation should be standard
Basic checks (missingness patterns, value distributions, duplication) can already flag non-credible data.
• External validation is not optional
Models should be tested across independent external datasets.
👉 What should be the minimum standard before a clinical prediction model is considered deployable?| 40 commentaires sur LinkedIn
|
|
Scooped by
Gilbert C FAURE
April 13, 6:58 AM
|
So much fun being in conversation with Jennifer Wilding of Federal Reserve Bank of Kansas City and contributing to their recent publication of the Byways Report: The Scenic Route to Rural Prosperity. This report is a story-driven publication exploring how road trip culture and place-based tourism can support economic growth in rural communities. 📍🤠
In our conversation back in 24’, we discussed the Threatt Filling Station project through my previous interim role at the OU Institute for Quality Communities where the team led students, in collaboration with the Threatt family, to research and conceptualize design strategies to activate the historic Threatt Station site in preparation for the Route 66 centennial. The Threatt Station was the only documented rest stop for Black travelers along the entire Mother Road, all the way from Illinois to California, and Oklahoma is home to the longest stretch of it. I’m incredibly proud of the professionalism and intentionality of our student team: Logan Webb, M.A. , Emily Pendergast, Brianna Haley, Mahathi Akella, Natalie Young, Rajith Kumar, and Anahita N. who even worked through the summer that year! 👏🏾
I was most excited for students to meet the Threatt family, whose resilience, generosity, expertise, and generational leadership allowed them to learn about the importance of leveraging spatial tools to protect and affirm culture, family history, and collective memory while exploring design interventions that could bring in new energy to the site.
Big thanks to the Threatt family, to Steven Shepelwich for the introduction to Federal Reserve Bank of Kansas City years ago, and to Jennifer and team for the invitation to share about such a meaningful project.
There are so many other rural inspirational stories in this publication! You can download your copy at: https://lnkd.in/gEEMeCwE
|
|
Scooped by
Gilbert C FAURE
April 13, 6:56 AM
|
|
|
Scooped by
Gilbert C FAURE
April 13, 6:53 AM
|
𝗖𝗼𝗺𝗺𝗲𝗻𝘁 𝗹𝗲𝘀 𝗲́𝘁𝘂𝗱𝗶𝗮𝗻𝘁𝘀 𝘂𝘁𝗶𝗹𝗶𝘀𝗲𝗻𝘁-𝗶𝗹𝘀 « 𝘃𝗿𝗮𝗶𝗺𝗲𝗻𝘁 » 𝗹’𝗶𝗻𝘁𝗲𝗹𝗹𝗶𝗴𝗲𝗻𝗰𝗲 𝗮𝗿𝘁𝗶𝗳𝗶𝗰𝗶𝗲𝗹𝗹𝗲 ?
Après de premiers usages plus ou moins erratiques et surtout médiatiquement très discutés, aujourd’hui, comment les #étudiants utilisent-ils vraiment l’#intelligenceartificielle ? C'est une question essentielle quant à la façon dont se façonnent les talents en devenir !
👉 Pour y répondre, début janvier, l’EPITA: Ecole d'Ingénieurs en Informatique a confié à #Ipsos la réalisation d’une enquête nationale, tous cursus confondus
📖 Principaux enseignements
👉 L’#IA est désormais largement intégrée aux usages des étudiants
🔹Un sur deux reconnaît qu’il lui serait difficile de s’en passer
🔹𝟵𝟰 % ont déjà utilisé un outil d’IA dans leur vie personnelle ou étudiante
🔹48 % l’utilisent tous les jours
🛠️ Quels usages ?
👉 Principalement pour comprendre, résumer ou approfondir des contenus
👉 Mais aussi des pratiques plus sensibles
🔹40 % reconnaissent avoir déjà utilisé l’IA pour générer tout ou partie d’un devoir
🔹47 % déclarent s’en servir pour des exercices même lorsque cela n’est pas autorisé
💪 𝗠𝗮𝗶𝘁𝗿𝗶𝘀𝗲...
🔹78 % se disent capables d’affiner les réponses par itérations et d’évaluer la pertinence des résultats
🤫 ...𝗘𝘁 𝗹𝗮𝗰𝘂𝗻𝗲𝘀
🔹81 % se déclarent mal informés sur au moins un enjeu majeur : éthique, biais, sécurité, environnement ou cadre réglementaire
🤔 Une 𝗶𝗺𝗮𝗴𝗲 𝗰𝗼𝗻𝘁𝗿𝗮𝘀𝘁𝗲́𝗲 de l’IA
🔹Elle est jugée performante et utile, mais aussi perçue comme potentiellement dangereuse et inéquitable
🔹59 % estiment que l’IA pourrait menacer l’existence de leur futur métier
🧑🎓 les étudiants expriment 𝘂𝗻𝗲 𝗮𝘁𝘁𝗲𝗻𝘁𝗲 𝗱’𝗲𝗻𝗰𝗮𝗱𝗿𝗲𝗺𝗲𝗻𝘁 𝗲𝘁 𝗱’𝗮𝗰𝗰𝗼𝗺𝗽𝗮𝗴𝗻𝗲𝗺𝗲𝗻𝘁
🔹63 % considèrent que les pouvoirs publics et les enseignants ont un rôle clé à jouer pour les protéger et les accompagner
🔗 https://lnkd.in/eCh9pqss
📖 À propos d'#EPITA
👉 Fondée en 1984, c’est une École d’ingénieurs en informatique et en numérique
🔹Elle forme des étudiants dans des domaines technologiques tels que l’intelligence artificielle et la cybersécurité
🔹Elle se déploie sur 7 campus en France avec des équipes de recherche et d’innovation
🗨️ ⁉️ 𝗤𝘂𝗲 𝘃𝗼𝘂𝘀 𝗶𝗻𝘀𝗽𝗶𝗿𝗲𝗻𝘁 𝗰𝗲𝘀 𝗿𝗲́𝘀𝘂𝗹𝘁𝗮𝘁𝘀 ? Avez-vous perçu les ressentis et attentes de vos jeunes vis-à-vis de l'IA ?
Catherine FAUQUET Claire Matti Dima El Zein Dominique GEIMER Marie-Hélène Bru-Dure Nathalie Terrades Serge Barbet Christophe Demure Etienne KLEIN Marion Carré Mick LEVY Thierry Taboy Aneli Mladenova Omar Lamhour Pascal Minguet Deschamps
🙏 De liker, commenter, partager et d'activer la 🔔 sur mon profil pour ne pas manquer mes posts | 24 comments on LinkedIn
|
|
Scooped by
Gilbert C FAURE
April 12, 3:44 AM
|
Kudos to the Pew Research Center team for writing the fantastic, in-depth report, "Where Do Americans Get Health Information, and What Do They Trust?" It will hopefully guide both consumer and industry decision-making as we all forge ahead into the latest health care revolution, this time powered by AI.
I smiled when I typed the word “revolution” just now. My very first report about health care and technology was published by Pew Research in the year 2000 and Lee Rainie and I had the audacity to title it, “The Online Health Care Revolution.” Twenty-four years later I published my book about the patient-led revolution in medical care, #RebelHealth. And now, two years later, I’m advising companies and organizations about how to harness AI for the greater good.
Looking back at how technology has changed the health information landscape, I see remarkable continuity:
🩺 People trust and turn to clinicians when they need help.
💡 There is always a small group of people pushing the capacity of new tools, whether mobile/social in the early 2000s or AI today. My tip: always look at what rare disease communities are doing. They are usually five to ten years ahead of the curve.
🎓 💰 Education, income, and health insurance status play big roles in how people gather health information.
What’s new in this week’s report: confirmation that peer-to-peer health advice is now mainstream.
In 2010, when I coined the phrase “peer-to-peer health care” we found that 18% of internet users had looked online for others with similar health concerns. The 2025 Edelman Trust Barometer reported that 67% of adults said personal experience with an issue is important when considering the legitimacy of a health information source – and that is particularly true among 18- to 34-year-olds. Now, in this week’s Pew Research survey we find that 66% of U.S. adults say they get health information at least sometimes from people with similar issues.
The technology keeps changing. The human need to find others who understand what you are going through never does.
What are you seeing in the health information landscape? What trends make you feel optimistic? Which worry you?
Reports linked below. Kudos to Giancarlo Pasquini, Galen Stocking, Emma Kikuchi, Isabelle Pula, Eileen Y. and the SSRS team, including Kristen Purcell. And for transparency, thanks to Claude for helping with the graphic below and reasoning through some of the thoughts I have about the last 25 years of health & tech. | 17 comments on LinkedIn
|
|
Scooped by
Gilbert C FAURE
April 12, 3:31 AM
|
I’m lucky enough to have seen The British Museum’s incredible exhibition, Hawai’i: a kingdom crossing oceans. You can see it too - and if you enter the competition below, you could see Hawai’i itself!
|
|
Scooped by
Gilbert C FAURE
April 11, 1:42 PM
|
“Covered entities are blocked by law from using your data for things like targeted advertising or user behavioral profiles, without authorization. But any other companies that get a hold of your medical information can do whatever they please, in accordance with their own privacy policies, [Andrew Crawford] says.” Using ChatGPT Health? Read this first.
https://lnkd.in/gN9gdY4z
Center for Democracy & Technology
#ChatGPT
#DataCollection
#TechPolicy
|
|
Scooped by
Gilbert C FAURE
April 10, 7:38 AM
|
Des chercheurs de l'Université de Stanford ont découvert (et nommé) l'effet Mirage des IA. Ces dernières, de GPT-5 d'OpenAI à Claude Opus 4.5 d'Anthropic en passant par Gemini 3 Pro de Google, arrivent ainsi à livrer un diagnostic médical avec assurance à partir d'éléments visuels qu'elle
|
|
Scooped by
Gilbert C FAURE
April 9, 6:22 AM
|
Une cyberattaque vient de révéler l'écosystème ultra-secret qui alimente ChatGPT et Claude en données d'entraînement.
Le groupe TeamPCP a compromis Mercor, l'un des sous-traitants clés d'OpenAI, Anthropic et Meta. Résultat : 200 Go de bases de données et 3 To d'informations sensibles exposés. Meta a immédiatement suspendu ses projets, laissant des centaines de contractuels sans travail.
Ce qui se dessine derrière cette faille, c'est toute une industrie invisible. Mercor, comme Surge ou Scale AI, emploie des milliers de personnes pour créer des jeux de données propriétaires gardés jalousement secrets. Ces entreprises sont les véritables fabriques de l'intelligence artificielle moderne.
Mais l'incident révèle surtout la fragilité de cette chaîne d'approvisionnement critique. Une seule vulnérabilité dans un outil tiers — ici LiteLLM — peut paralyser la production de données pour les modèles les plus avancés au monde.
L'asymétrie de pouvoir saute aux yeux : les géants de l'IA externalisent leurs risques vers des sous-traitants précaires, qui deviennent les maillons faibles de toute la chaîne. Quand ça casse, ce sont eux qui paient le prix fort.
Cette architecture en silo crée des vulnérabilités systémiques. Que se passerait-il si des coopératives de données remplaçaient ces intermédiaires précaires ? Si les travailleurs de l'annotation possédaient collectivement leurs outils et leurs données ?
Comment repenser cette chaîne de valeur pour qu'elle ne repose plus sur la précarité organisée ? | 13 comments on LinkedIn
|
|
Scooped by
Gilbert C FAURE
April 9, 6:19 AM
|
Our Canadian Medical Association Health & Media Tracking Survey found that people are 5x more likely to experience harm when they use AI for health advice which is a huge issue when nearly half of those surveyed use it. This piece in The Atlantic does a great job explaining how that happens and why we should all be concerned. https://lnkd.in/eBkfQtVC
Read our research here: https://lnkd.in/g-EsyexG
|
|
|
Scooped by
Gilbert C FAURE
April 18, 9:14 AM
|
We finally have a way to measure AI harm in clinical practice.
We usually judge clinical AI the same way we test medical students: exams, scores, and knowledge benchmarks. But here's the issue—none of that tells us one critical thing: 👉 How much harm can this AI actually cause?
𝗧𝗵𝗮𝘁'𝘀 𝘄𝗵𝗮𝘁 𝗡𝗢𝗛𝗔𝗥𝗠 𝗰𝗵𝗮𝗻𝗴𝗲𝘀.
Released just months ago by Stanford and Harvard researchers, NOHARM is the first framework designed to measure real clinical risk, not just performance.
________________________________________
𝗛𝗲𝗿𝗲'𝘀 𝘄𝗵𝘆 𝗶𝘁 𝗺𝗮𝘁𝘁𝗲𝗿𝘀:
🔬 It introduces a common language for safety
AI outputs are graded by severity of harm (mild → severe), based on expert consensus across real clinical cases.
📊 It enables true benchmarking
Over 30 AI models evaluated head-to-head using the same safety standards—with a public leaderboard for transparency.
⚠️ It captures the errors that actually matter
Not just wrong answers, but:
• Harmful recommendations (commission)
• Missed appropriate care (omission — the majority of severe errors)
📈 It gives decision-ready metrics
Including Case Harm Rate and Number Needed to Harm—tools clinicians and hospitals can actually use before adopting AI.
________________________________________
𝗧𝗵𝗲 𝗸𝗲𝘆 𝗶𝗻𝘀𝗶𝗴𝗵𝘁?
Traditional benchmarks only moderately correlate with real-world safety (r ≈ 0.6). Meaning: high scores ≠ safe care.
NOHARM isn't perfect! but it's the first real step toward accountability in clinical AI.
Before integrating AI into your practice, ask yourself: 𝗛𝗼𝘄 𝗺𝘂𝗰𝗵 𝗵𝗮𝗿𝗺 𝗮𝗿𝗲 𝘆𝗼𝘂 𝘄𝗶𝗹𝗹𝗶𝗻𝗴 𝘁𝗼 𝘁𝗼𝗹𝗲𝗿𝗮𝘁𝗲?
________________________________________
📄 Paper: arxiv.org/abs/2512.01241
Research Details: Validated across 100 real eConsult cases (10 specialties) with 12,747 expert annotations on 4,249 management options. 95.5% expert concordance on severity classifications.
N.B. MAST (Medical AI Superintelligence Test) is ARISE AI's comprehensive benchmarking platform for advanced clinical AI evaluation, with NOHARM serving as its core harm-assessment framework. Together on bench.arise-ai.org, they rank 30+ models using physician-validated metrics from 100 real cases across 10 specialties, focusing on safety (Case Harm Rate, NNH) beyond traditional accuracy benchmarks.
#ClinicalAI #AISafety #MedicalAI #EBM_Briefs #ClinicalResearch #DigitalHealth #MedTech #HealthTech
|
|
Scooped by
Gilbert C FAURE
April 17, 3:07 AM
|
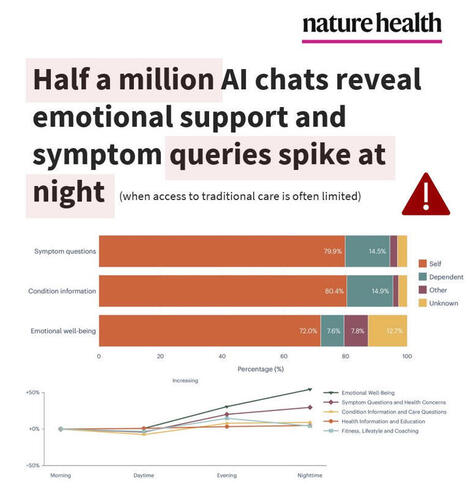
NEW STUDY🧨Half a million AI chats reveal emotional support and symptom queries spike at night, when access to traditional care is often limited.
What can Microsoft Copilot tell us from over HALF A MILLION (n = 617,827) de-identified health conversations?
-- Nearly 1 in 5 chatbot conversations involved personal symptoms, conditions, or test interpretation
-- About 1 in 7 personal health queries were about someone else (child, parent, partner)
-- Symptom queries happened mostly on mobile (15.9%) vs desktop (6.9%), whereas health-related research support was mostly on desktop (16.9%) vs mobile (5.3%)
-- Nighttime spikes on emotional support queries (from 3.3% morning to 5.2% nighttime) and symptoms/health concerns (from 10.6% morning to 13.4% nighttime)
These nighttime spikes (when healthcare access is most limited) may amplify user risk, as highly actionable LLM outputs are more likely to be relied on without professional support.
The authors did acknowledge safety RISKS in that mainstream AI models (ChatGPT, Google Gemini, Microsoft Copilot) may perform well on medical exams but NOT always on real-world emergency triage or decision-making, yet users keep turning to them for health advice and emotional coping.
The authors seem to take these risks seriously and concluded:
“From a safety perspective, the personal health intents identified here—such as symptom assessment, condition management and emotional well-being—arguably define categories in which the consequences of conversational AI responses are greatest and where investment in response quality and safety measures should be concentrated.”
Translation: we still have a long way to go and investment needs to be focused on the highest-risk use cases to make these models safe for public use, in a domain with near-zero tolerance for harmful errors.
Study in Nature Health linked below 👇 | 18 comments on LinkedIn
|
|
Scooped by
Gilbert C FAURE
April 16, 9:06 AM
|
If you want to build healthcare AI at scale, follow these 10 Chinese Healthcare AI companies.
1. AQ AI Health App
· 30M monthly active users, 10M daily health consultations
· 27M health questions answered in 2025, national health OS infrastructure
· 50%+ users from Tier 3+ cities, true population-scale deployment
2. XtalPi Inc.
· $59.9B drug pipeline deal with Harvard spinout (largest ever)
· 300+ robotic workstations deployed globally, operating 24/7
· AI + quantum physics + robotics integrated platform
3. JD.COM (JD Health)
· 50M+ users served by AI doctor agents
· Full-cycle health management from prevention to chronic disease
· 2.2M+ patient encounters at partner hospitals
4. United Imaging Healthcare
· 20+ FDA-approved AI-powered medical devices
· 92% diagnostic accuracy (beats industry SOTA by 10%+)
· Hardware + AI + clinical workflows fully integrated
5. BGI Genomics
· Fully automated "dark lab" running 1+ year, zero human intervention
· Sample → sequencing → analysis → storage, end-to-end automation
· Deepseek-R1 and Evo 2 AI models integrated into platform
6. MicroPort
· World's first LLM-autonomous surgery completed (Dec 2025)
· AI-powered surgical planning, imaging fusion, automated operations
· SAIL Award winner (Super AI Leader)
7. Yidu Tech Inc.
· 7B authorized medical records, 1.3B patient encounters processed
· 10,000+ hospitals covered, 50K+ clinical copilot uses per hospital
· Patient recruitment accuracy: 25% → 85%, trial timelines -20%
8. Winning Health Technology Group Co.,Ltd
· 150+ hospitals deployed, 60+ clinical scenarios covered
· 20+ specialized medical AI agents operational
· Medical LLM WinGPT 3.0 with clinical reasoning capabilities
9. 美年大健康
· 600 examination centers, 30M annual checkups
· AI-driven preventive care and longevity medicine services
· Strategic partnership with Alibaba DAMO Academy for cancer screening
10. Kingmed Diagnostics
· 30PB multi-modal medical data accumulated
· 15M+ monthly API calls for diagnostic intelligence
· 60+ AI agents deployed, 70K monthly active physician users
These 10 companies didn't just build AI.
They built deployment infrastructure for 1.4 billion people.
Data infrastructure + full-stack systems + deployment speed.
The models are good enough.
The systems are what matter.
P.S. Which company's approach surprises you most?
Le Shen | Jian Ma | Daniel Wan | Kathy LIU | Jeremy (Sujie) cao | Jasmine Liang | 徐济铭 | Terry Zhao | 郭璋 | Shen Luan
#HealthcareAI #China #DigitalHealth #Innovation #AIinHealthcare
—
Enjoy this? ♻️ Repost it to your network and follow Effie GUO for more China-Global healthtech insights. | 22 comments on LinkedIn
|
|
Scooped by
Gilbert C FAURE
April 13, 9:59 AM
|
Dr Riadh Caïd-Essebsi
Aline Cheynet de Beaupré
|
|
Scooped by
Gilbert C FAURE
April 13, 6:57 AM
|
🌍 MEDICAL MISDIAGNOSIS IN AFRICA
🩺 What is medical misdiagnosis?
Medical misdiagnosis means a disease is:
Incorrectly diagnosed (wrong condition identified)or
Missed (not diagnosed at all)or
Delayed (diagnosed too late)
In many African settings, this often happens due to system challenges, not lack of skill
Causes of misdiagnosis
1. Limited diagnostic tools
Shortage of labs, imaging, and test kits
Reliance on symptoms instead of confirmed tests
2. Overburdened healthcare systems
High patient numbers → very short consultation time
Fatigue and workload affect decision-making
3. Similar symptoms across diseases
Many infections present with fever, pain, fatigue, making differentiation hard
4. Shortage of specialists
Rural areas often rely on general clinicians for complex cases
5. Financial barriers
Patients may not afford tests → incomplete diagnosis
6. Weak health infrastructure
Limited record systems and follow-up care
WHO percentage
The World Health Organization does not give a single specific percentage for Africa alone, but key global insights include:
Up to 40% of patients may receive incorrect or delayed diagnosis in primary care settings
WHO emphasizes that diagnostic errors are among the leading causes of avoidable harm
Risks of misdiagnosis
Receiving the wrong treatment
Increases risk of complications or death
Delay in correct treatment
Disease progression
Negative effects
On patients:
Worsening illness
Long-term disability
Emotional distress and loss of trust
On healthcare systems:
Increased costs (repeat visits, wrong treatments)
Overuse of limited resources
NB:Diseases that are commonly misdiagnosed(Disease vs. Disease),
Because many illnesses share similar symptoms (especially fever, fatigue, pain, and cough), some diseases in Africa are frequently confused with others
1. Fever-related illnesses
Malaria ↔ Typhoid fever
Malaria ↔ COVID-19
Malaria ↔ Dengue fever
2. Respiratory diseases
Tuberculosis ↔ Pneumonia
Tuberculosis ↔ Lung cancer
3. Gastrointestinal illnesses
Typhoid fever ↔ Gastroenteritis
Peptic ulcer disease ↔ Gastritis
4. HIV-related confusion
HIV/AIDS ↔ Tuberculosis
HIV/AIDS ↔ other infections (e.g., persistent fever, weight loss)
5. Childhood illnesses
Pneumonia ↔ Malaria
Measles ↔ Rubella
6. Non-communicable diseases
Hypertension ↔ Stress or anxiety
Diabetes ↔ Malaria (fatigue, weakness)
Prevention strategies
1. Improve diagnostics
More access to labs, rapid tests, and imaging
2. Training and education
Continuous training for healthcare workers
3. Use of guidelines
Standard diagnostic protocols to reduce guesswork
4. Strengthen health systems
Better staffing, infrastructure, and record-keeping
5. Patient awareness
Encouraging early care-seeking and follow-up
6. Technology use
Telemedicine and AI-assisted diagnosis
Medical misdiagnosis in Africa is a significant but preventable challenge, driven mainly by resource limitations and system pressures
|
|
Scooped by
Gilbert C FAURE
April 13, 6:55 AM
|
5 000 milliards de requêtes par an. 9% d'erreur. Faites le calcul.
Google diffuse des centaines de milliers de fausses informations chaque minute via ses résumés IA. Une analyse indépendante révèle que cette ampleur dépasse tout ce que l'humanité a connu en matière de désinformation systémique.
Le vrai problème ? La "capitulation cognitive" des utilisateurs face à l'autorité artificielle. Seuls 8% vérifient les réponses de l'IA, et 80% suivent ses conseils même manifestement faux.
Google aggrave délibérément le phénomène : "Nous déployons des modèles moins fiables avant de les améliorer sur le dos des utilisateurs", confirme un rapport interne. Gemini 2 plafonne à 85% de précision, mais reste en production.
Paradoxe cruel : plus le modèle "s'améliore", plus il cite des sources qui ne soutiennent pas ses affirmations. De 37% à 56% de réponses "non fondées" entre les versions.
Ce que ça change concrètement :
→ Journalistes : vos sources primaires sont noyées sous l'autorité artificielle
→ Communicants : votre fact-checking devient obsolète face à la vitesse de diffusion
→ Écosystème : l'industrialisation de l'erreur avec l'autorité de la vérité
→ Société : la notion même de "source fiable" s'effrite
"Et si les médias créaient un consortium de fact-checking en temps réel des réponses IA de Google ?"
Vous avez observé cette dérive dans votre pratique professionnelle ? Des exemples concrets de cette "capitulation cognitive" ?
|
|
Scooped by
Gilbert C FAURE
April 12, 4:01 AM
|
Learn the lingo that pet-owners use to talk about (and to) their pets in Chinese
|
|
Scooped by
Gilbert C FAURE
April 12, 3:38 AM
|
𝐐𝐮𝐢𝐧𝐳𝐞 "𝐣'𝐚𝐢𝐦𝐞"… Il n'en faudra pas plus pour que ce post soit repris par une IA.
C'est le résultat d'une étude établie sur l'analyse de 89 000 URL de Linkedin citées par ChatGPT Search, Perplexity et Mode IA (Google). Parmi tous les chiffres, il y en a un qui mérite vraiment qu'on s'y arrête : le post Linkedin moyen cité par une IA totalise 15 à 25 réactions (j'aime, bravo, etc.).
Linkedin devient, derrière Reddit, le deuxième domaine le plus cité par les IA, devant Wikipedia, YouTube, et l'ensemble de la presse.
C'est assez étonnant. En effet, jusque-là, on nous a toujours dit que Linkedin mettait en avant les contenus les plus vus. Que son algorithme pousse ce qui performe. Que la viralité est la preuve de la valeur.
Et là, l'étude de Semrush indique que, pour les IA, c'est l'inverse ! (lien vers l'étude en commentaire)
Les IA ne cherchent pas les publications les plus populaires. Elles cherchent les plus pertinentes. Si un post répond directement à une question soumise à l'IA, peu importe que celui-ci ait été lu par 50 ou 5 000 personnes. Il aura autant de chances d'être cité.
Conséquence non moins étonnante : 𝟗𝟓 % 𝐝𝐞𝐬 𝐩𝐨𝐬𝐭𝐬 𝐜𝐢𝐭𝐞́𝐬 𝐩𝐚𝐫 𝐥𝐞𝐬 𝐈𝐀 𝐬𝐨𝐧𝐭 𝐨𝐫𝐢𝐠𝐢𝐧𝐚𝐮𝐱. Les republications ne pèsent que pour 5 % des posts cités.
Avec l'adoption massive des IA, nous voyons donc deux logiques algorithmiques s'opposer. Celle de Linkedin qui valorise l'engagement et les "j'aime" (le reach). Et, celle des IA, qui valorise la clarté et la précision thématique. Les IA testées dans l'étude semblent quasi insensibles au bruit ambiant. Elles préfèrent citer les publications porteuses de sens pour l'utilisateur.
Il va donc falloir réfléchir à deux fois avant de vous lancer dans un post. Puisque vouloir obtenir des vues ne sera pas un gage de visibilité auprès des personnes qui conversent en priorité avec leur IA, plutôt qu'avec Linkedin.
Est-ce que ce ne serait pas le moment de revoir votre stratégie éditoriale ?
#IA #LinkedIn #ContentMarketing #AISearch
|
|
Scooped by
Gilbert C FAURE
April 12, 3:29 AM
|
A few weeks ago, I had the opportunity to deliver the opening keynote at iConference 2026, focusing on information literacies, the Enlightenment, and digital engagement. Thanks to Ulrike Liebner from iSchools Inc. for the invitation. The talk moves from these foundations to questions about learner agency in an AI-mediated world, and explores #metaliteracy as a framework for engaging as reflective, ethical, and collaborative participants. Sharing the recording and slidedeck here for those interested in AI and digital education: https://lnkd.in/gnA8wFwn. #AI #DigitalLearning #InfoLit
|
|
Scooped by
Gilbert C FAURE
April 11, 1:16 PM
|
NotebookLM : Un assistant de recherche IA personnalisé pour les enseignants.
#IA #Education
|
|
Scooped by
Gilbert C FAURE
April 10, 3:57 AM
|
Vendez-nous votre matériel et appareils photos argentique. Nous rachetons toutes marques.
|
|
Scooped by
Gilbert C FAURE
April 9, 6:21 AM
|
Across 114 US internal medicine clerkship programs, not one included structured AI teaching, even as students were already turning to ChatGPT more often than their own professors.
1️⃣ A national survey of 114 internal medicine clerkship directors found zero programs with structured AI teaching in their curriculum.
2️⃣ Nearly 60% of clerkship directors felt AI should be formally incorporated into the medical school curriculum.
3️⃣ Top teaching priorities: using AI to support clinical reasoning (58%) and interpreting AI output (54%).
4️⃣ 47% felt students should be taught the ethical challenges of AI in clinical practice, including data privacy and algorithmic bias.
5️⃣ Meanwhile, 44% of students were already using ChatGPT at least weekly.
6️⃣ 45% of students were more likely to ask ChatGPT a question than their professor or attending physician.
7️⃣ Three-quarters of clerkship directors don't use AI for any administrative tasks, including student scheduling or feedback analysis.
8️⃣ Faculty knowledge was the top barrier to teaching AI (84%), followed by clerkship directors' own knowledge (75%).
9️⃣ Nearly half of clerkship directors had received no AI training at all; only 1 in 114 described it as "very adequate."
🔟 The authors call for institutional investment in faculty development now, before student use outpaces what educators can safely guide.
✍🏻 Navin L. Kumar, Casey McQuade, Eliana Bonifacino, Irene Alexandraki, Kathryn K. Hufmeyer, Michael Kisielewski, Cindy Lai, Elexis McBee, Prashant Patel, @Nora Y. Osman. Artificial Intelligence in the Internal Medicine Clerkship: Results of a National Survey. JGIM Journal of General Internal Medicine. 2026. DOI: 10.1007/s11606-026-10354-1
|
|
Scooped by
Gilbert C FAURE
April 9, 6:15 AM
|
Le professeur Didier Raoult vient de se faire rétracter 2 études, donc il passe à 50 études rétractées à son actif. Nous pouvons donc féliciter ce grand "chercheur" français, élite de la nation selon ses propres propos, et dont la plus fameuse étude de 2020 sur l'hydroxychloroquine était d'une médiocrité telle que pas même un étudiant de 2e année en médecine n'aurait osé la présenter à son professeur, qui passe presque dans le top 10 mondial des pires "chercheurs".
Une pensée émue aux médias français (et suisses) qui l'ont invité sur les plateaux TV sans contradicteur pour raconter absolument n'importe quoi sur le covid, ainsi qu'aux institutions françaises qui ont fermé les yeux pendant des années (tout comme avec l'histoire du Mediator, et de Christian Perronne qui a été blanchi par la chambre disciplinaire de l'ordre médecins, on commence à avoir l'habitude dans ce pays de ne pas toucher aux "grands").
Lien vers le Retraction Watch Leaderboard :
https://lnkd.in/eZZ-c_-f | 16 comments on LinkedIn
|