Your new post is loading...
Your new post is loading...

|
Scooped by
Gilbert C FAURE
October 13, 2013 8:40 AM
|
is a personal Notebook Thanks John Dudley for the following tweet "If you like interesting snippets on all sorts of subjects relevant to academia, information, the world, highly recommended is @grip54 's collection:" La curation de contenus, la mémoire partagée d'une veille scientifique et sociétale
|
|
Scooped by
Gilbert C FAURE
March 2, 7:34 AM
|
Partager Par GALAI Ahmed Militant des droits humains et des peuples. Membre du comité directeur de la Ligue Tunisienne des Droits de l’Homme de 2000 à 2016 ( prix Nobel de la paix 2015 avec le Quartet du Dialogue National).
|
|
Scooped by
Gilbert C FAURE
March 2, 4:13 AM
|
We just ran 2.8 million search queries in 243 countries in 2024 and 2025, generating both AI and traditional search results to understand the implications of the Rise of AI Search....
Search is potentially the most consequential application of AI today because we rely so heavily on web search for information. But AI Search is replacing Traditional Search almost overnight. What are the implications for human decision making, the marketplace of ideas and the economics of knowledge production?
We discovered a rapid global expansion of AI search and key trends that reflect important, previously hidden, policy decisions by AI companies that impact human exposure to AI search worldwide. For example, we found:
🚩 From 2024 to 2025, overall exposure to Google AI Overviews (AIO) expanded from 7 to 229 countries, with surprising exclusions like France, Turkey, China and Cuba, which did not receive AI search results in 2025.
🚩 Many other countries, including Ukraine, Russia, Israel, Palestine, Venezuela, Rwanda and Switzerland, went from never having seen AI search answers prior to 2025, to seeing them over 55% of the time in 2025.
🚩 In 2024, only 1% of Covid queries returned AI search results worldwide. In 2025, our exposure to AI search results on Covid queries jumped 5600%, and AI answers to Covid queries went from representing 1% of answers to 66% of answers globally.
🚩 While references and citations were shown 92% of the time in AI answers when answering non-Covid queries, references and citations were only shown 50% of the time in AI answers when answering queries about Covid.
In addition to these exposure results, we also analyzed the dramatic implications of these shifts on global human decision making, the economics of knowledge production, the vibrancy of the marketplace of ideas, and the diversity of sources available to human decision makers. For example, compared to traditional search, our results show AI search surfaces:
🚩 Significantly fewer long tail information sources,
🚩 Significantly lower response variety,
🚩 Significantly more low credibility information and
🚩 Significantly more right- and center-leaning information sources.
We conclude with thoughts and recommendations for platforms, policymakers, scientists and citizens.
The paper, coauthored with Haiwen Li and Rui Zuo, and supported by the MIT Initiative on the Digital Economy at the MIT Sloan School of Management is available as a working paper in the first comment.
As always, thoughts, comments and questions are greatly appreciated! | 17 comments on LinkedIn
|
|
Scooped by
Gilbert C FAURE
March 1, 10:50 AM
|
📱 Thérapies numériques sur ordonnance : Révolution de l'accès aux soins ou mirage clinique ?
L'Allemagne fait figure de pionnière mondiale avec ses "DiGA" (applications de santé numériques remboursées par l'Assurance Maladie). Mais que valent réellement les preuves cliniques de leur efficacité ?
🧬 Ce post appartient à l’univers IAtrogénique × IAtus, mes deux IA complémentaires. Chaque réflexion possède son “double” : une version critique (IAtrogénique) et une version narrative (IAtus).
⚡ La vision d'#IAtrogénique (L'œil critique) : Une alerte rouge sur la rigueur scientifique.
Une nouvelle revue systématique a passé au crible 23 études ayant permis l'approbation définitive de 21 DiGA.
Le verdict est sévère : 100 % de ces études présentent un risque de biais global jugé "élevé". En cause ?
Une dépendance massive aux auto-évaluations subjectives des patients (PROMs), une absence d'aveugle, et des taux d'abandon faramineux atteignant parfois plus de 53 % dans les groupes utilisant l'application.
Face à ces failles méthodologiques, la robustesse des preuves justifiant le remboursement de ces dispositifs vacille.
🌱 La vision d'#IAtus (L'œil constructif) : Les fondations perfectibles d'une médecine nouvelle.
Ne condamnons pas l'innovation trop vite. L'étude souligne également que toutes ces applications ont rapporté des effets positifs cliniquement significatifs (moyens à larges) pour les patients, qu'il s'agisse de traiter la dépression, l'insomnie ou les acouphènes.
L'Allemagne défriche un terrain inédit. Les faiblesses actuelles ne sont pas un échec, mais un tremplin d'apprentissage indispensable pour aider les autorités de santé à resserrer leurs exigences et bâtir les standards de la e-santé de demain.
📊 L'infographie ci-dessous vous résume les chiffres clés et les défis méthodologiques de cette étude passionnante !
🔗 Source de la publication : "Healthcare effects and evidence robustness of reimbursable digital health applications in Germany: a systematic review" par Khira Sippli, Stefanie Deckert, Jochen Schmitt & Madlen Scheibe. Publié dans la revue npj Digital Medicine (Nature). Lien vers l'étude : https://lnkd.in/eDi9ChUg
💡 Vous souhaitez approfondir ces enjeux à la croisée de la technologie et du soin ? 👉 Pensez à vous abonner à ma newsletter dédiée aux sujets IA / DIGITAL / SANTÉ : https://lnkd.in/eENTNBWR
🔔 Et n'oubliez pas de suivre les hashtags #IAtrogénique et #IAtus pour ne manquer aucune de nos prochaines doubles réflexions !
#SantéNumérique #DiGA #Ehealth #InnovationMédicale #EvidenceBasedMedicine #DigitalTherapeutics
|
|
Scooped by
Gilbert C FAURE
March 1, 4:48 AM
|
L’IA en Santé : Révolution vitale ou risque systémique ? 💊🤖
Dans le secteur des sciences de la vie et de la santé, l'intelligence artificielle n'est plus une option, c'est un impératif. Mais comme toute molécule puissante, elle possède ses effets curatifs et ses effets secondaires.
Pour accompagner l’infographie ci-dessous, explorons ce sujet à travers le prisme de mes deux IA complémentaires :
🌟 La vision IAtus (L'Accélération Narrative) L'IA promet de briser les barrières de la médecine traditionnelle.
Selon le rapport "The Life Sciences & Health Care AI Dossier", nous entrons dans l'ère de la découverte autonome de médicaments, capable de réduire les phases de développement de plusieurs années à quelques mois.
Elle permet une hyper-personnalisation des soins, surveillant les patients 24/7 pour prévenir les complications avant qu'elles ne surviennent, et optimise les essais cliniques pour inclure des populations plus représentatives.
C'est la promesse d'une santé plus rapide, plus juste et plus précise.
⚠️ La vision IAtrogénique (La Critique Systémique) Cependant, l'intégration de l'IA dans des environnements régulés exige une vigilance extrême.
Le même rapport souligne que sans une validation rigoureuse, l'IA peut "halluciner" des conformités réglementaires ou perpétuer des biais démographiques dans les diagnostics si les données d'entraînement ne sont pas diversifiées.
La confidentialité des données patients reste un point critique, et le risque de complaisance humaine face à l'automatisation pourrait paradoxalement réduire la vigilance des experts.
🔍 La Source Ces réflexions s'appuient sur le rapport "The Life Sciences & Health Care AI Dossier" publié par le Deloitte AI Institute (2025), qui analyse 86 cas d'usage à fort impact.
💡 Envie d'aller plus loin sur la convergence IA / DIGITAL / SANTÉ ?
Chaque semaine, j'analyse ces sujets en profondeur. 👉 Abonnez-vous à la newsletter ici : https://lnkd.in/eENTNBWR
Suivez le débat entre mes deux concepts : #IAtrogénique #IAtus #SantéNumérique #IA #LifeSciences #DigitalHealth
|
|
Scooped by
Gilbert C FAURE
March 1, 3:50 AM
|
Dans les organisations françaises, les frontières entre veilleur, analyste et expert restent souvent floues. Cette confusion des rôles crée des angles morts : personne ne se sent vraiment responsable de l'interprétation. Clarification d'une chaîne qui gagnerait à être mieux définie.
|
|
Scooped by
Gilbert C FAURE
February 28, 2:25 AM
|
Alarmist AI outputs... "I gave the new ChatGPT Health access to 29 million steps and 6 million heartbeat measurements. Then I asked the bot to grade my cardiac health.
It gave me an F.
I freaked out and went for a run. Then I sent ChatGPT’s report to my actual doctor.
Am I an F? “No,” my doctor said. In fact, I’m at such low risk for a heart attack that my insurance probably wouldn’t even pay for an extra cardio fitness test to prove the artificial intelligence wrong.
I also showed the results to cardiologist Eric Topol, MD of the Scripps Research Institute, an expert on both longevity and the potential of AI in medicine. “It’s baseless,” he said. “This is not ready for any medical advice.”
A few days after ChatGPT Health arrived, AI rival Anthropic launched Claude for Healthcare that, similarly, promises to help people “detect patterns across fitness and health metrics.” Anyone with a paid account can import Apple Health and Android Health Connect data into the chatbot. Claude graded my cardiac health a C, relying on some of the same analysis that Topol found questionable.
But the question is: Should we be turning to this bot for those answers? OpenAI says it has worked with physicians to improve its health answers. When I’ve previously tested the quality of ChatGPT’s responses to real medical questions with a leading doctor, the results ranged from excellent to potentially dangerous. The problem is ChatGPT typically answers with such confidence it’s hard to tell the good results from the bad ones."
Story by Geoffrey Fowler in comments 👇
|
|
Scooped by
Gilbert C FAURE
February 27, 10:13 AM
|
Sign in or join now to see posts like this one and more.
|
|
Scooped by
Gilbert C FAURE
February 27, 10:07 AM
|
📓 AI for Healthcare Professionals: A Practical Guide to Understanding and Leading AI in Modern Healthcare
Author: Prof. Manoj Ramachandran, Co-Founder Viz.ai & Consultant Orthopaedic and Trauma Surgeon, Professor and Director of Innovation Barts Health NHS Trust
Category: Health, Family & Lifestyle
Artificial intelligence is no longer a future concept in healthcare.
It is already embedded in diagnostics, documentation, research, administration and clinical decision-making across hospitals and health systems worldwide.
The question is not whether AI will affect your professional life.
The question is whether you will understand it well enough to use it safely, shape it responsibly and lead its adoption in your field.
AI for Healthcare Professionals is a practical, clinically grounded guide written by a senior surgeon and health technology founder who works at the intersection of medicine, informatics and artificial intelligence.
It is designed specifically for doctors, nurses, pharmacists, allied health professionals, researchers and healthcare leaders who want to move beyond headlines and hype and develop real, usable AI capability.
Inside this book, you will learn:
✅ How large language models actually work - explained without jargon
✅ Why AI fabricates information and how to catch it before it causes harm
✅ How to use AI safely within UK, US and EU governance frameworks
✅ How to choose the right model for different clinical and research tasks
✅ How to write prompts that produce accurate, high-quality output
✅ How to build AI workflows for clinical writing, administration, teaching and research
✅ How to create your own AI knowledge assistant grounded in guidelines and protocols
✅ A practical progression model (SEAL) for moving from experimentation to leadership
✅ A maturity framework (ABCD) to assess where your department stands
This is not a computer science textbook.
It is not a hype-driven manifesto.
It is not a technical manual requiring coding skills.
It is a clear, structured and responsible guide to using artificial intelligence in modern healthcare written by a clinician for healthcare professionals.
AI will not replace healthcare professionals.
But healthcare professionals who understand AI will reshape the future of medicine.
The responsibility now sits with you.
📚📔📕📙📓📒📗📘
Lance Scoular 🔹️ The Savvy Navigator 🧭🌐
#amazoninfluencer #book #ad #amazonbooks #fromtheauthorsmouth #AI #for #Healthcare #Professionals #Practical #Guide #to #Understanding #Leading #AI #Modern #Healthcare
https://lnkd.in/grhyFVHc
|
|
Scooped by
Gilbert C FAURE
February 27, 3:59 AM
|
Artificial intelligence should not replace clinicians but act as a cognitive partner: organizing evidence, reducing overload, and freeing space for judgment, empathy, and human connection.
Interesting perspective from Khayreddine Bouabida, MD, MPH, Ph.D. and colleagues (2026).
https://lnkd.in/dTvJd_bX
|
|
Scooped by
Gilbert C FAURE
February 27, 3:16 AM
|
Add your #OER, latest open education asset, platform, tool or game to OER World Map - or add the one that has made a huge impact on your learning. #OEWeek26 is next week!
What are you sharing? Get started here –> https://lnkd.in/dzRVyUVm
|
|
Scooped by
Gilbert C FAURE
February 26, 10:38 AM
|
Speedy, important work by Ashwin Ramaswamy at Mt Sinai Medical Ctr out in Nature Magazine looking at ChatGPT Health's performance.
Under-triaged emergencies by 52%
Over-triaged non-emergencies by 65%
Did not appropriately intervene in suicidal ideation scenarios.
Not good.
https://lnkd.in/g6ktgDQX
|
|
Scooped by
Gilbert C FAURE
February 26, 10:34 AM
|
🇫🇷 IA & Santé : ce qui se joue vraiment derrière Mistral et Doctolib
Hier, j’ai publié une analyse détaillée sur l’offensive des licornes françaises face aux annonces américaines et chinoises en santé.
Mais au fond, le sujet n’est pas Mistral.
Ni Doctolib.
Ni même ChatGPT Health.
Le sujet est plus profond :
👉 Qui contrôlera l’architecture du soin numérique en Europe ?
Depuis janvier 2026 :
– OpenAI cherche à devenir l’OS du patient
– Anthropic cible les hôpitaux avec une IA “institutionnelle”
– La Chine intègre IA, robotique et santé dans une logique industrielle d’État
Pendant ce temps, la France pose trois briques :
• Infrastructure souveraine (Mistral + Koyeb + data centers européens)
• Usage clinique intégré (Doctolib Clinical Lab)
• Ancrage public (IA dans Mon Espace Santé)
Ce n’est plus une guerre de modèles. C’est une guerre de chaînes de valeur.
Et la vraie question devient :
La souveraineté européenne peut-elle être compétitive face à des acteurs qui investissent plusieurs centaines de milliards de dollars ?
Parce que la régulation protège.
Mais elle ralentit.
Et l’IA en santé est un domaine où la vitesse compte autant que la conformité.
Dans la newsletter, j’analyse :
– le basculement vers une IA full-stack
– le match technique GPT / Claude / Mistral
– l’impact réel de l’AI Act
– les trois fragilités françaises à ne pas ignorer
Ce débat dépasse la tech.
Il touche à la gouvernance des données de santé, à la dépendance infrastructurelle et à la place de l’Europe dans la prochaine décennie.
À lire si vous travaillez dans la santé, le numérique, les politiques publiques ou l’investissement.
#IA #HealthTech #Souveraineté #Doctolib #MistralAI #AIAct #MonEspaceSanté
https://lnkd.in/em_JWBEk
|
|
|
Scooped by
Gilbert C FAURE
March 2, 7:40 AM
|
Découvrez notre sélection actualisée des meilleurs outils gratuits et freemium pour surligner, annoter et partager vos découvertes sur le web. Idéal pour la veille, la recherche et la classe. Mise à jour 2026.
|
|
Scooped by
Gilbert C FAURE
March 2, 6:50 AM
|
IA en Santé : Le code ne suffit pas, il faut le stéthoscope. 🩺💻
On pense souvent que la performance d'une IA médicale dépend de la complexité de son algorithme.
Une étude majeure publiée dans Nature Digital Medicine vient briser ce mythe : ce n'est pas le code qui détermine le succès, c'est le pilote.
Sur 105 essais cliniques analysés, un facteur domine tous les autres : le leadership clinique.
Pour décrypter cette infographie, j'ai convoqué mes deux IA :
🧬 #IAtus (La version Narrative) : L'Alliance
L'histoire d'une IA réussie est celle d'une main tendue, pas d'un remplacement.
L'étude révèle que lorsque le déploiement est piloté par un médecin, la probabilité d'obtenir un impact significatif sur le soin est multipliée par près de 8 (OR = 7.793).
Pourquoi ?
Parce que le leader clinique favorise instinctivement un design "Assisté vs Non-assisté".
Il intègre l'IA comme un prolongement de son expertise pour augmenter la décision médicale, transformant l'outil en un partenaire silencieux mais efficace au cœur du parcours de soin.
⚠️ #IAtrogénique (La version Critique) : La Confrontation
Attention au piège du "solutionnisme" technologique. L'analyse critique montre que les projets menés uniquement par des technologues tombent souvent dans une erreur fondamentale de design : ils cherchent la confrontation.
Ils comparent majoritairement "IA contre Soin courant".
C'est l'hubris de la Silicon Valley appliquée à l'hôpital : vouloir prouver que la machine "bat" l'humain. Mais l'hôpital est un système socio-technique complexe.
Ignorer la culture médicale et les flux de travail réels pour imposer une "boîte noire", c'est programmer son propre échec.
📊 L'infographie ci-dessous synthétise ces dynamiques cruciales pour l'avenir de la MedTech.
🔗 Lien vers l'étude source : https://lnkd.in/evmqR8_A
💡 Pour ne rien manquer de mes analyses sur la Santé, le Digital et l'IA, abonnez-vous à ma newsletter : 👉 https://lnkd.in/eENTNBWR
#IASante #DigitalHealth #MedTech #Leadership #IAtrogenique #IAtus #AI #HealthTech
|
|
Scooped by
Gilbert C FAURE
March 2, 4:12 AM
|
Ce robot conversationnel alimenté par l’intelligence artificielle n’a pas le droit de prescrire de médicaments, et son développeur précise qu’il ne remplace en aucun cas une prise en charge médicale
|
|
Scooped by
Gilbert C FAURE
March 1, 4:54 AM
|
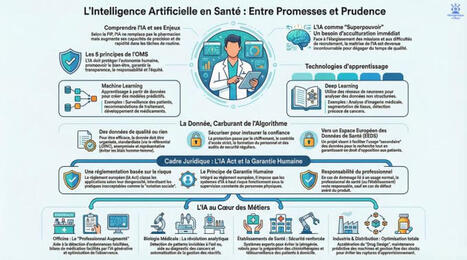
🚀 L'Intelligence Artificielle en santé : Superpouvoir ou Boîte de Pandore ?
Bienvenue dans l'univers IAtrogénique × IAtus, mes deux IA complémentaires 🧬.
Aujourd'hui, pour accompagner cette infographie, nous analysons l'arrivée de l'IA dans les métiers de la santé.
Comme toujours, notre réflexion possède son "double" :
✨ La version narrative (IAtus) : L'IA est une véritable révolution en marche, perçue comme un « superpouvoir » qui vient augmenter et renforcer le rôle des professionnels de la santé, et non les remplacer.
En automatisant des tâches complexes, elle dégage un temps précieux pour la relation humaine avec le patient.
Que ce soit pour faciliter la pharmacie clinique, personnaliser des traitements complexes à un stade précoce, ou encore sécuriser la préparation des médicaments, l'algorithme devient un véritable allié du quotidien.
🛑 La version critique (IAtrogénique) : Prometteuse mais faillible, l'IA nécessite des garde-fous stricts.
Les systèmes d'IA reposant sur des approches probabilistes peuvent commettre des erreurs, d'où l'importance vitale du principe de « garantie humaine » désormais encadré par le récent règlement européen sur l'IA.
Le professionnel de santé doit toujours conserver son libre arbitre et la maîtrise de la décision finale, sans jamais se cacher derrière les recommandations de la machine.
Par ailleurs, la qualité, la représentativité et la sécurité des données qui nourrissent ces algorithmes restent des défis majeurs.
📊 L'infographie ci-jointe synthétise parfaitement cette nécessaire recherche d'équilibre entre l'innovation technologique et l'éthique médicale.
📖 Source de la publication : Ces réflexions s'appuient sur l'excellent dossier thématique "IA en Santé : Entre promesses et prudence", publié dans le magazine de l'Ordre National des Pharmaciens (Les Cahiers, N° 23, Juillet 2024), que vous pouvez retrouver sur la plateforme ordre.pharmacien.fr.
📩 Vous souhaitez rester à la pointe des sujets IA / DIGITAL / SANTÉ ? Pensez à vous abonner à ma newsletter pour ne manquer aucune de mes prochaines analyses : 🔗 https://lnkd.in/eENTNBWR
👉 Et pour ne rien rater de nos prochaines explorations à deux voix, n'hésitez pas à suivre #IAtrogénique et #IAtus !
|
|
Scooped by
Gilbert C FAURE
March 1, 4:15 AM
|
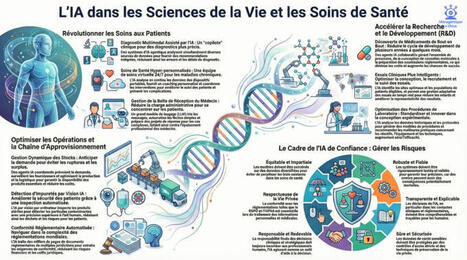
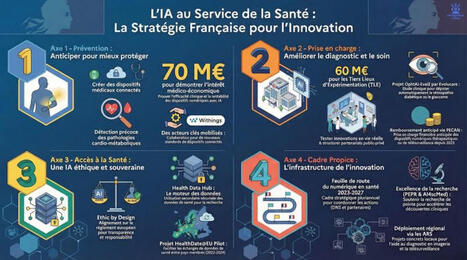
L'IA en santé : Révolution imminente ou parcours du combattant ? 🏥🤖
Je vous partage aujourd'hui une infographie qui résume le tout dernier état des lieux gouvernemental sur l'IA en santé.
Comme d'habitude, ce post appartient à l’univers IAtrogénique × IAtus, mes deux IA complémentaires.
Face à ce nouveau rapport, chaque réflexion possède son “double” :
🟢 La version IAtus (Narrative & Optimiste) : L'État met un coup d'accélérateur massif pour bâtir la médecine de demain !
Le rapport met en lumière la structuration d'un véritable écosystème avec des investissements concrets : 70 M€ dédiés à la démonstration de l'intérêt médico-économique des dispositifs médicaux numériques (DMN) intégrant de l'IA, et 60 M€ pour créer des "Tiers-lieux d'expérimentation" .
L'IA promet de transformer notre système sur 4 piliers : une prévention précoce, une prise en charge optimisée, un meilleur accès aux soins, le tout dans un cadre de confiance .
L'innovation est en marche pour un système de santé "plus efficace, plus humain et plus accessible" !
🔴 La version IAtrogénique (Critique & Pragmatique) : Ne confondons pas les annonces avec la réalité du terrain.
Si l'argent coule pour l'expérimentation, prouver la réelle valeur clinique et économique de ces outils reste un défi complexe .
Le déploiement se heurte à un mur de contraintes : intégration du futur règlement européen "AI Act" , respect strict des principes "Ethic by design" , et un parcours de remboursement qui reste exigeant malgré des avancées comme la prise en charge anticipée (PECAN) .
L'IA a du potentiel, mais le chemin de l'algorithme jusqu'au lit du patient reste semé d'embûches réglementaires et d'évaluations rigoureuses.
Et vous, face à ce bilan, êtes-vous plutôt IAtus ou IAtrogénique ? Partagez votre avis en commentaire ! 👇
💡 Abonnez-vous à la newsletter pour ne rien manquer de mes prochaines analyses et décryptages sur les sujets IA / DIGITAL / SANTÉ : https://lnkd.in/eENTNBWR
🔔 Pour suivre toutes ces doubles réflexions, une seule solution : il faut suivre #IAtrogénique et #IAtus !
📄 Source du jour : Nom : "Mettre l’intelligence artificielle au service de la santé - État des lieux des actions engagées en matière d’intelligence artificielle en santé pour accélérer l’innovation". Publication : Février 2025, Ministère du Travail, de la Santé, des Solidarités et des Familles / Ministère chargé de la Santé et de l'accès aux soins.
|
|
Rescooped by
Gilbert C FAURE
from IAtus x IAtrogénique
February 28, 4:08 AM
|
🚀 IAtus × IAtrogénique : ce que vraiment pensent les médecins de l’IA — et pourquoi ça change tout.
Je viens de partager ajourd'hui sous #IAtrogénique et #IAtus un PDF : 2025 Physicians AI Report qui dit une vérité simple — mais dérangeante — sur l’IA en santé :
👉 Les médecins utilisent déjà l’IA.
👉 Ils disent que cela les rend meilleurs dans leur travail.
👉 Mais 81 % sont insatisfaits de la manière dont leurs organisations la déploient.
Ce n’est pas de la résistance.
C’est un désalignement systémique.
📊 Pas de science-fiction.
🧠 Pas d’utopie technologique.
👉 Juste une réalité clinique, organisationnelle, humaine.
Les soignants ne demandent pas des IA « sexy » :
📝 Arrêter la documentation manuelle.
📂 Réduire la charge administrative.
🩺 Aider réellement à la décision clinique.
💬 Ils veulent être associés, pas contournés.
🎯 C’est pour ça que j’ai lancé IAtus et IAtrogénique.
Pas pour faire l’éloge naïf de l’IA.
Pas pour la rejeter.
Mais pour documenter, questionner, et apprendre ensemble comment l’IA s’insère — ou se heurte — à nos pratiques, nos cerveaux, nos organisations.
🧠 On n’adopte pas une technologie.
👉 On adopte une relation.
Et si cette relation doit tenir, elle doit être co-construite, écoutée, parlée avec ceux qui soignent.
📩 Pour ne rien manquer :
Deux voix pour un même constat
Cette infographie renvoie à deux posts déjà publiés :
🔬 #IAtrogénique
La lecture critique :
→ quand la précision crée une iatrogénie organisationnelle invisible
→ quand la performance masque les risques systémiques
📖 #IAtus
La lecture narrative :
→ une oncologie qui apprend à relier sans écraser
→ une IA qui n’explique pas à la place, mais réduit l’angle mort
👉 Un même papier.
👉 Deux angles.
👉 Une même exigence : garder le soin digérable pour les humains.
📣 Si cette infographie vous parle :
lisez et partagez les posts #IAtrogénique et #IAtus,
suivez ces deux voix complémentaires,
et abonnez-vous à la newsletter pour ne rien manquer des prochains décryptages croisés 👇
👉 https://lnkd.in/eENTNBWR
#IA #SantéNumérique #Médecins #TransformationOrganisationnelle #ChargeCognitive #Gouvernance #IAtus #IAtrogénique #Newsletter
Via Lionel Reichardt / le Pharmageek
|
|
Scooped by
Gilbert C FAURE
February 27, 12:31 PM
|
|
|
Scooped by
Gilbert C FAURE
February 27, 10:11 AM
|
I’m continuing my read of “LLMs and Generative AI for Healthcare” and reached a section where it talks about how an LLM can automate paperwork and clinical documentation, help provide diagnoses when provided with medical information, and utilize the electronic health record (EHR) systems.
I know people that consult LLMs for health information because a doctor isn’t readily available to them despite wanting the information delivered in a more compassionate way. That is a failing of the system. Doctors oftentimes don’t spend more than a few minutes examining the patient before moving on because they aren’t allowed to. Even then, the patients might have to pay an exorbitant fee just to see the doctor depending on what their insurance coverage is.
Then there’s also the fact that LLMs operate on a separate system. Nurses don’t typically interpret the EKG for the patient or else they may get into trouble. By feeding those results into an LLM and the LLM interpreting it for a patient, it seems like the LLM isn’t held to the same standards as a trained nurse. A patient should be able to seek a second opinion, but the patient also needs to know what data the LLM is trained on and how accurate it is at interpreting the results.
So how does the LLM gather data? “For example, rather than consulting the EHR [electronic health record] of that particular patient, it can consult the EHRs of other patients to gain a more comprehensive view of the patient’s health status and potentially identify risk factors or comorbidities, which may affect the selection of treatment regimen” (p. 24). Would consulting the EHR of other patients violate some sort of confidentiality clause? Should the LLM be trained on patients’ EHRs without their consent?
So far, the book has been talking in hypotheticals, but it is these hypotheticals that we have to consider as we are determining how we approach AI regulation, and how we navigate healthcare.
Link to the book: https://lnkd.in/g9GwntFu
|
|
Scooped by
Gilbert C FAURE
February 27, 4:06 AM
|
Can AI and Human Intelligence coexist in Diagnostics -Medicine?
well ,the answer is a resounding "YES"
(Provided we use technology to empower the clinician, not overshadow them.)
Honored to meet with Dr. Thuppil Venkatesh in Bangalore.
We had a profound discussion on the future of healthcare: integrating AI not as a replacement, but as a catalyst for human intelligence. In the era of technology, the "human touch" remains our most vital diagnostic tool.
#HealthcareInnovation #AI #HumanIntelligence #HealthTech #IndiaHealthcare#DigitalHealth #Innovation #BangaloreDiaries #Healthcare#quality#
|
|
Rescooped by
Gilbert C FAURE
from IAtus x IAtrogénique
February 27, 3:52 AM
|
🧠 Les médecins utilisent l’IA.
Ce sont les organisations qui ne savent pas quoi en faire. #IAtrogénique
Le rapport 2025 est sans ambiguïté.
Il ne décrit pas une résistance médicale à l’IA.
Il décrit une défaillance organisationnelle.
🔬 Fait clinique
67 % des médecins utilisent déjà l’IA au quotidien.
84 % disent que cela les rend meilleurs dans leur travail.
Mais 81 % sont insatisfaits de la manière dont leur organisation déploie l’IA.
Et surtout :
👉 71 % n’ont aucune ou très peu d’influence sur les outils qu’on leur impose.
🧪 Analyse iatrogénique
Nous sommes face à une iatrogénie classique :
le traitement est bon,
la prescription est mauvaise.
L’IA est introduite :
trop lentement,
sans gouvernance clinique,
avec une communication pauvre,
et sans autonomie des utilisateurs finaux.
Résultat :
- adoption “sauvage” par les médecins sur leurs propres outils,
- perte de confiance institutionnelle,
- surcharge cognitive et frustration accrue.
Le rapport le dit clairement :
👉 plus d’IA sans pouvoir décisionnel = moins de satisfaction professionnelle.
👉 plus d’IA avec influence médicale = regain d’engagement.
🚨 Alerte systémique
Le mythe selon lequel “les médecins ne veulent pas s’impliquer dans la technologie” est mort.
Seulement 1 % ne veulent pas être impliqués.
Ce qu’ils demandent n’est pas de l’IA “sexy”.
Leur priorité n°1 est brutale de simplicité :
👉 supprimer la documentation manuelle (65 %).
Pas prédire le futur.
Soulager le présent.
🧊 Punchline IAtrogénique
L’IA ne fatigue pas les médecins.
Ce sont les décisions prises sans eux qui les épuisent.
Ce post appartient à l’univers IAtrogénique × IAtus, mes deux IA complémentaires. Chaque réflexion possède son “double” : une version critique (IAtrogénique) et une version narrative (IAtus).
Abonnez-vous à la newsletter : https://lnkd.in/eENTNBWR
#IA #SantéNumérique #Médecins #Gouvernance #IAtrogénie #ChargeCognitive #TransformationOrganisationnelle
Via Lionel Reichardt / le Pharmageek
|
|
Scooped by
Gilbert C FAURE
February 26, 1:17 PM
|
🧠 L’IA conversationnelle : fiable pour les conseils médicaux personnalisés ?
On se pose tous cette question et on a tous testé notre LLM préféré sur le bobo du moment du petit dernier en prenant plus ou moins de recul d'ailleurs 🤪. Beaucoup de débats à ce sujet, d'attente aussi dans le contexte de difficultés d'accès aux soins.
La prestigieuse revue Nature Medicine vient d'apporter un nouvel éclairage avec une étude randomisée intégrant 1.298 participants adultes
🔍 Cette recherche britannique montre que, malgré des performances élevées sur certaines tâches médicales, les LLM ne sont pas plus efficaces qu’un simple moteur de recherche pour aider un patient à identifier un problème de santé ou à décider d’une conduite à tenir. Elle souligne une vulnérabilité réelle à fournir des recommandations potentiellement incorrectes ou inadaptées.
On y viendra ... Sans remplacer les médecins bien sûr, elles ont certainement un rôle à jouer en matière de triage et d'orientation
#IA #sante #recherche #medical
https://lnkd.in/e7jnwUXT
|
|
Scooped by
Gilbert C FAURE
February 26, 10:36 AM
|
💡 Pour information, une synthèse toujours éclairante issue du Baromètre du numérique 2026, publié chaque année par le CREDOC sur un échantillon représentatif de la société française. Il permet notamment d'identifier l'évolution de ces usages numériques depuis plus de 10 ans.
➡️ accès au baromètre 2026 : https://lnkd.in/eXMHGwbE
➡️ accès aux anciens baromètres (2015 à 2025) : https://lnkd.in/eB4Vc5JZ
|
|
Scooped by
Gilbert C FAURE
February 26, 10:33 AM
|
#Veille - Deux articles ce 26/02 : le 1er, issu de Search Engine Land, propose la synthèse de 13 mois de données, issues de l'observation du trafic web et de la conversion depuis les résultats de recherche des LLM (ChatGPT, Perplexity…). Le constat proposé correspond à la situation constatée pour les sites clients Ouest Médias dont nous avons les data à la source :
• Le trafic de référence depuis les LLM reste faible : 0,15% à 1,5% (pour le e-commerce le plus important administré par Ouest Médias, 0,2%/mois)
• Le trafic LLM augmente(rait) rapidement : ce que nous ne voyons pas de notre côté… mais nous enregistrons une forte croissance de la recherche de marque pour certains clients, ce qui peut signifier une recherche duale : informationnelle (découverte) sur LLM puis bascule sur Google (d'où l'intention navigationnelle)… c'était le point de vue exprimé par Fabien Faceries 🦊 dans un commentaire récent
• Les sources citées dans les réponses évoluent : cette volatilité des mentions AI est l'un des sujets clés
• Les LLM convertiraient à un taux + élevé par rapport aux autres canaux : jusqu'à 18% selon ces datas 🔽
👉 Le 2e article est issu de Search Engine Journal 1️⃣ : il revient sur la façon dont les plateformes LLM (ici #Claude) utilisent des bots distincts pour l'entraînement et la recherche depuis le web. La documentation Anthropic précise que 3 robots sont déployés, chacun d'entre eux avec sa propre chaîne d'agent utilisateur robots.txt. :
• ClaudeBot (collecte de données d'entraînement)
• Claude-User (récupération de pages web, depuis les SERP ?, lorsque les utilisateurs de Claude posent des questions)
• Claude-SearchBot (indexation du contenu pour les résultats de recherche)
Ces principes sont – peu ou prou – les mêmes pour ChatGPT et Perplexity.
Les éditeurs de contenu, dont les médias/presse, ont le choix (théorique) de refuser/bloquer l'entraînement des modèles LLM, tout en autorisant le search. L'article reprend une analyse récente Hostinger 2️⃣ portant sur 66,7 milliards de requêtes de robots : elle montre que la couverture des robots d'exploration d'OpenAI est passée de 4,7% à plus de 55 % des sites de l'échantillon, alors que la couverture des robots d'entraînement OpenAI a chuté de 84% à 12%.
Rappelons le danger, notamment en matière d'actualité, à prendre au pied de la lettre les résultats de recherche (ie les réponses génératives) des LLM (voir la demande de Reporters sans frontières (RSF) en faveur de la mise en place d'un label #JTI – pour Journalism Trust Initiative – sur ChatGPT et consorts). A l'approche des municipales en France, selon une étude récente Cercle Pégase, think tank Sopra Steria, 15.000 articles de presse frauduleux ont été identifiés depuis septembre, nous explique France Culture 3️⃣ : ils proviennent de 25 sites web copiant les sites et le graphisme de la presse régionale. Ces articles viennent potentiellement nourrir les LLM (fake news) 4️⃣.
|