Your new post is loading...
Your new post is loading...

|
Scooped by
Gilbert C FAURE
October 13, 2013 8:40 AM
|
is a personal Notebook Thanks John Dudley for the following tweet "If you like interesting snippets on all sorts of subjects relevant to academia, information, the world, highly recommended is @grip54 's collection:" La curation de contenus, la mémoire partagée d'une veille scientifique et sociétale
|
|
Scooped by
Gilbert C FAURE
December 5, 10:26 AM
|
Chers étudiants du Master VSOC, je vous invite à suivre cette soutenance, qui s'annonce très riche d'enseignements et très bien ancrée dans les #SIC.
👉 https://lnkd.in/eE2KyuEC
#intelligenceeconomique
#renseignement
#analyse
#veille
#infocom
|
|
Scooped by
Gilbert C FAURE
December 5, 5:13 AM
|
I’m excited to announce the next free mini-masterclass from Meducate Global Academy, this time focusing on Mentoring in Health Professions Education (and beyond!), led by my friend and colleague Subha Ramani, MBBS, MPH, MMEd, PhD, FAMEE, a true leader in the global health-professions education community.
Subha’s work has shaped how we think about modern mentoring relationships, how we support learners, and how we develop faculty who can mentor with purpose and impact. Subha is Associate Professor of Medicine at Harvard Medical School, a general internist at Brigham and Women’s Hospital, senior core faculty in the Harvard Macy Program, and Past President of AMEE. Her recent work including the 2024 “Mentoring in Health Professions Education: AMEE Guide No. 167” has helped shape how we understand mentoring relationships in health-professions teaching and learning. More about Subha here https://lnkd.in/dRnC5qcj.
This session will be a 30-minute mini-masterclass (maybe a little longer if the conversation takes off!) and will follow the same interactive, fast-paced style as our previous Academy mini-masterclasses. We will send out the dates and times for the sessions, and a link to sign up in early January.
I’m passionate about mentoring as well, and this year I was honored to receive the Frances M. Maitland Mentorship Award from the Alliance for Continuing Education in the Health Professions. Mentoring has played a huge role in my career, and it’s something I feel deeply committed to strengthening across our global community.
If mentoring , whether as mentor, mentee, or both, is important to you in education, clinical work, leadership, or life, I invite you to join our notification list. The masterclass will be offered at least twice to accommodate different geographies, beginning in January. Signing up will also give you early access to future mentoring-focused offerings from Meducate Global Academy.
And for those who want to go deeper, the Academy will also be offering longer, more formal mentoring masterclasses in 2026. And stay tuned for more topics and awesome faculty to be announced soon...
Sign up here:
👉 https://lnkd.in/dN3dSbTE
Looking forward to growing a global mentoring community together.
Feel free to share with your networks!
|
|
Rescooped by
Gilbert C FAURE
from Nik Peachey
December 5, 2:42 AM
|
Traditionally, we have thought of literacy as the ability to communicate through reading, writing, listening, and speaking. But in our digital age, we are as likely to use video, images audio and even gestures as modes of communication. The ability to understand and share information through a combination of these modes is known as multimodal literacy.
Via Nik Peachey
|
|
Scooped by
Gilbert C FAURE
December 3, 4:26 AM
|
"Science of the Total Environment" is a diarrhea journal published by Elsevier. This "mega-journal" published up to 10,000 papers per year. On almost everything... as long as you are ready to pay $4,150 publication fees!
But irregularities were so massive that Clavirate decided to unlist this journal.
Elsevier is the publisher that publishes the most studies and earns the most, with a 38% profit margin. Don't tell me Elsevier is not predatory!
Higlighted in El Pais - link in comments.
|
|
Scooped by
Gilbert C FAURE
December 2, 1:35 PM
|
Kansas City Neighborhood Map: Central Business District-Downtown: Overpriced Bars, River Market: Over-hyped Farmer's Market, Westside North: Michael innes allegedly lives here, Pendleton Heights: Streetcorner pharmaceuticals , Crown Center: Artsy, Beacon Hills: OLD ROY DISNEY ANIMATION STUDIO, Wendell Phillips: Music Venues, Longfellow: Gentrification, Indipendence Plaza: , Union Hill: Christian take over, former Crusty hood , Westside South: Mexican restaurants
|
|
Scooped by
Gilbert C FAURE
December 2, 1:24 PM
|
What do we lose when screens replace books?
|
|
Scooped by
Gilbert C FAURE
December 2, 6:03 AM
|
The Association for Information Science & Technology (ASIS&T) is delighted to announce that “Sneaked references: Fabricated reference metadata distort citation counts,” written by Lonni Besançon, Guillaume Cabanac, Cyril Labbé, and Alexander Magazinov, published in Volume 75, Issue 12 of the Journal of the Association for Information Science & Technology (JASIST), is the recipient of…
|
|
Scooped by
Gilbert C FAURE
December 2, 4:27 AM
|
En direct du "Google de papier" Mundaneum
|
|
Scooped by
Gilbert C FAURE
December 2, 4:24 AM
|
𝐒𝐚𝐯𝐞𝐳-𝐯𝐨𝐮𝐬 𝐪𝐮𝐞𝐥𝐥𝐞 𝐢𝐧𝐝𝐮𝐬𝐭𝐫𝐢𝐞 𝐞𝐬𝐭 𝐩𝐥𝐮𝐬 𝐫𝐞𝐧𝐭𝐚𝐛𝐥𝐞 𝐪𝐮’𝐀𝐩𝐩𝐥𝐞 𝐭𝐨𝐮𝐭 𝐞𝐧 𝐧𝐞 𝐩𝐫𝐨𝐝𝐮𝐢𝐬𝐚𝐧𝐭 𝐩𝐫𝐞𝐬𝐪𝐮𝐞 𝐫𝐢𝐞𝐧 𝐞𝐥𝐥𝐞-𝐦ê𝐦𝐞 ?
👉 L’édition scientifique.
Dans une publication de Fernanda Beigel vulgarisée par Mihai Andrei et Lonni Besançon, on apprend ainsi que les grands éditeurs scientifiques affichent des marges de...
𝟯𝟬 à 𝟯𝟳 %
(en comparaison, Apple tourne autour de 23 %).
Leur modèle économique est à peine croyable :
1️⃣ Les chercheurses et chercheurs produisent des articles 𝗴𝗿𝗮𝘁𝘂𝗶𝘁𝗲𝗺𝗲𝗻𝘁 𝗲𝘁 𝗽𝗮𝘆𝗲𝗻𝘁 pour les publier ;
2️⃣ D’autres les évaluent 𝗴𝗿𝗮𝘁𝘂𝗶𝘁𝗲𝗺𝗲𝗻𝘁 ;
3️⃣ Puis les éditeurs 𝗿𝗲𝘃𝗲𝗻𝗱𝗲𝗻𝘁 𝗰𝗲𝘀 𝗮𝗿𝘁𝗶𝗰𝗹𝗲𝘀 à 𝘂𝗻 𝗽𝗿𝗶𝘅 𝗲𝘅𝗼𝗿𝗯𝗶𝘁𝗮𝗻𝘁... aux mêmes institutions qui les ont financés (et donc aux contribuables).
Entre 2019 et 2024, les éditeurs scientifiques ont ainsi généré 𝗽𝗹𝘂𝘀 𝗱𝗲 𝟭𝟰 𝗺𝗶𝗹𝗹𝗶𝗮𝗿𝗱𝘀 𝗱𝗲 𝗱𝗼𝗹𝗹𝗮𝗿𝘀 𝗱𝗲 𝗽𝗿𝗼𝗳𝗶𝘁, à partir notamment de recherches financées par les états.
❓ 𝗠𝗮𝗶𝘀 𝗽𝗼𝘂𝗿𝗾𝘂𝗼𝗶 𝗮𝗰𝗰𝗲𝗽𝘁𝗲-𝘁-𝗼𝗻 𝘂𝗻 𝘁𝗲𝗹 𝗺𝗼𝗱è𝗹𝗲 ?
Parce que les grands éditeurs scientifiques exploitent un carburant puissant : 𝗹𝗮 𝗽𝗿𝗲𝘀𝘀𝗶𝗼𝗻 𝗱𝘂 « 𝗽𝘂𝗯𝗹𝗶𝘀𝗵 𝗼𝗿 𝗽𝗲𝗿𝗶𝘀𝗵 ».
Les chercheuses et chercheurs sont contraints de publier régulièrement.
👉 𝘗𝘢𝘴 𝘥𝘦 𝘱𝘶𝘣𝘭𝘪𝘤𝘢𝘵𝘪𝘰𝘯 = 𝘱𝘢𝘴 𝘥𝘦 𝘤𝘢𝘳𝘳𝘪è𝘳𝘦.
Et cette dépendance est devenue l’arme la plus rentable des grands éditeurs.
𝗔𝗹𝗼𝗿𝘀, 𝗼𝗻 𝗳𝗮𝗶𝘁 𝗾𝘂𝗼𝗶 ?
Pour en finir avec cette course indécente qui capte l’argent public et incite à la fraude, les auteurs défendent la « re-communautarisation » de la science, via le #DiamondOpenAccess :
📚 des revues gratuites ;
🏛️ gérées par les institutions publiques ;
🔓 indépendantes des logiques commerciales.
Mais ce sujet doit maintenant dépasser les frontières du monde académique.
Les responsables politiques doivent se saisir du problème :
💶 A une époque où chaque euro public compte, nous ne pouvons plus laisser des éditeurs privés (pour la plupart non européens) capter les financements de la recherche.
C'est aussi une question de #souveraineté scientifique.
🇪🇺 L’Europe doit construire ses propres infrastructures d’édition scientifique, solides, ouvertes, capables de rivaliser avec les géants et de redonner à la connaissance son statut de bien commun.
𝗟𝗮 𝗿𝗲𝗰𝗵𝗲𝗿𝗰𝗵𝗲 𝗽𝘂𝗯𝗹𝗶𝗾𝘂𝗲 𝗱𝗼𝗶𝘁 𝘀𝗲𝗿𝘃𝗶𝗿 𝗹𝗮 𝘀𝗼𝗰𝗶é𝘁é, 𝗽𝗮𝘀 𝗹𝗲 𝗯𝗶𝗹𝗮𝗻 𝗰𝗼𝗺𝗽𝘁𝗮𝗯𝗹𝗲 𝗱’𝘂𝗻 𝗼𝗹𝗶𝗴𝗼𝗽𝗼𝗹𝗲 𝗺𝗼𝗻𝗱𝗶𝗮𝗹.
📚 Sources :
- Beigel et al. The Drain of Scientific Publishing. Pre-print. 2025. DOI : 10.48550/arXiv.2511.04820.
- Mihai Andrei. We Need to Talk About the Billion-Dollar Industry Holding Science Hostage. ZME Science. 2025.
#ScienceOuverte #OpenAccess #EditionScientifique #Recherche #PhD #Université #Innovation #PublishOrPerish #Souveraineté #Politique
|
|
Scooped by
Gilbert C FAURE
December 1, 3:51 AM
|
La médecine en 2025 n'a pas de base de connaissance. On a des PDF.
Cette année j'ai rejoint une structure publique dans l'information médicale. Avant ça, j'ai étudié des centaines de recherches de médecins généralistes pour comprendre comment ils accèdent à l'information. Le constat est le même partout : l'information médicale existe, mais elle n'est pas exploitable.
Elle n'est pas centralisée. Les recos HAS sont sur un site, celles des sociétés savantes sur cinquante autres, la BDPM ailleurs, le CRAT encore ailleurs. Chaque source dans son coin.
Elle n'est pas structurée. Une fiche mémo HAS de 2 pages ne ressemble pas à une reco ESC de 200 pages. Aucune cohérence entre les sources, et souvent aucune cohérence à l'intérieur d'une même source.
On n'a pas de base de connaissance médicale centralisée, ouverte, structurée. Et encore moins versionnée : les documents changent sans prévenir, pas d'historique, pas de traçabilité. Impossible de savoir ce qui a été modifié, ni quand.
On parle d'IA médicale, de LLM qui vont transformer la santé.
Mais on met des modèles surpuissants sur des fondations bancales.
On a pas un problème d’IA, on a un problème de données.
|
|
Scooped by
Gilbert C FAURE
November 30, 11:01 AM
|
Stop supporting for profit publishers. This is public money.
|
|
Scooped by
Gilbert C FAURE
November 30, 7:46 AM
|
The Social Media for Learning in Higher Education conference has announced its programme for next month. Over 20 parallel sessions that explore the intersection between HE and the changing world of social media.
I'm looking forward to delivering the opening keynote '#AcademicTwitter Is Dead — What Died, What Survived, What’s Next.
You can see more about this established conference and book your place via the link below
https://lnkd.in/eEu6z_Hu
You can see the full programme via the link https://lnkd.in/e_jA2PK7
For more information contact Katy Jordan
|
|
|
Scooped by
Gilbert C FAURE
Today, 10:03 AM
|
Can you see which 2 publishers don't care about rigorous peer-review?
Authors: don't submit 😉
Experts: don't offer peer-review 🤑
Evaluators: consider systematic predatory publication as negative 🤥
|
|
Scooped by
Gilbert C FAURE
December 5, 7:35 AM
|
I’m grateful and proud to witness the Rome Coalition on health literacy and human rights building trust through inclusion be brought to live.
Today’s conference, hosted by Italy’s National Office Against Racial Discrimination in cooperation with the Council of Europe, and supported by the Ministers for Health and Family, Natality and Equal Opportunities, emphasized the vital role of health literacy as a human right.
The opening statements featured influential voices:
🔹Eugenia Maria Roccella, Minister for Family, Natality and Equal Opportunities, Italy
🔹Orazio Schillaci, Minister of Health, Italy
🔹Rafael Benitez, Director of Social Rights, Health and Environment, Council of Europe
The Rome Coalition is a result of dedicated efforts by the Council of Europe, the Italian government and a wide range of stakeholders from the European health literacy community and human rights stakeholders with a strong vision that health literacy is not just an individual skill. It is a societal responsibility, requiring systemic commitment from governments, institutions, and communities.
Thanks to all for your dedication!
Mattia Peradotto Rafael Benitez Laurence Lwoff Lorenzo Montrasio Lee Hibbard Guglielmo Bonaccorsi Chiara Lorini Assunta Morresi Luigi Palmieri Miguel Arriaga Cristina Vaz de Almeida stephan Van den Broucke Saskia Maria De Gani Vassiliki Karaouli Elvis Sala
and many more.
#HealthLiteracy #HumanRights #Equity #Inclusion #PublicHealth #TrustInHealthSystems
Quickly understand complex research papers with AI-powered explanations. Annotate PDFs, highlight text, and organize your thoughts on an infinite canvas. BYOK privacy, one-time purchase desktop app for researchers and students.
Via Nik Peachey
|
|
Scooped by
Gilbert C FAURE
December 3, 1:43 PM
|
On Monday, Republican Senator Bernie Moreno of Ohio introduced a bill that would end dual citizenship.
|
|
Scooped by
Gilbert C FAURE
December 3, 3:39 AM
|
« Pendant plus dun siècle, les marchands dattention ont régné en maîtres [voir notre recension du livre éponyme de Tim Wu - NDE], d
|
|
Scooped by
Gilbert C FAURE
December 2, 1:32 PM
|
Paris Neighborhood Map: Saint-Merri: Falafel Area, Saint-Gervais: Gay friendly, Sainte-Avoie: Chinese street , Halles: Underground lair of Metro Hell, Monnaie: Tourist traps, Sorbonne: Students, Saint-Victor: trillionaires, Enfants-Rouges: full of bobos, Arts-et-Métiers: manifestation tout les samedis, Bonne-Nouvelle: Startups Land, Saint-Germain-des-Prés: Most expensive coffees in Paris
|
|
Scooped by
Gilbert C FAURE
December 2, 1:22 PM
|
Qu’est-ce qu’une source ? Est-ce que ce concept est encore compris à l’heure des réponses par IA générative et des modèles de « recherche profonde » ? Quand trouve-t-elle sa place…
|
|
Scooped by
Gilbert C FAURE
December 2, 5:54 AM
|
Découvrez Digispeech par La Digitale. Un outil gratuit et libre pour transformer n'importe quel texte en fichier audio MP3. Idéal pour la différenciation et les langues.
|
|
Scooped by
Gilbert C FAURE
December 2, 4:26 AM
|
|
|
Scooped by
Gilbert C FAURE
December 2, 4:23 AM
|
Find out how common AI hallucination is for leading models, and what that means for the businesses that rely on them.
|
|
Scooped by
Gilbert C FAURE
November 30, 11:20 AM
|
As a full professor at the School of Library and Information Sciences, Vincent Larivière is one of the most cited researchers in his field, with a remarkable number of publications and presentations delivered at international conferences in Canada and abroad.
|
|
Scooped by
Gilbert C FAURE
November 30, 8:09 AM
|
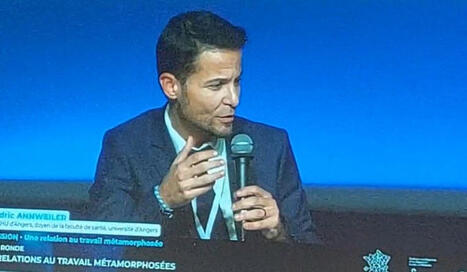
📍 Assises nationales hospitalo-universitaires 2025 – Nantes
Table ronde « Métamorphose des relations au travail »
Heureux d’avoir participé à cette table ronde animée par Anne FERRER-VILLENEUVE et loic Favennec.
Un moment dense, éclairé par l’analyse de Valerie Ugo (CPCNU, Université d'Angers et CHU d'Angers), qui a rappelé les défis intergénérationnels à relever collectivement.
Dans mon intervention, j’ai insisté sur :
🎓L’accès massif à l’information a mis fin au magistère professoral traditionnel. La Gen Z attend de nous un rôle de coach donnant du sens aux enseignements et lui montrant comment hiérarchiser et construire un esprit critique.
🔍 L’IA peut devenir un formidable outil d’apprentissage, à condition de préserver l’exigence pédagogique de former de futurs professionnels capables de raisonner et d’argumenter.
✨ Enfin, rappelons que les jeunes professionnels ne veulent plus seulement soigner, mais aussi transformer le système de santé pour l’adapter aux besoins d’aujourd’hui et de demain.
Autour de la table : Colin Azria, Kevin Yauy, Jean-Yves Gauvrit, Marianne JACQUES, Sara Laurencin et Floriane RIVIERE
🙏 Merci à la Conférence Nationale des Doyennes et des Doyens de Médecine pour sa confiance
👏 Et bravo aux Directeurs généraux de CHRU pour une organisation à la hauteur de l’enjeu
Ces Assises avaient un parfum de futur : lucide, exigeant, mais résolument tourné vers le soin et l’université que nous voulons bâtir.
|
|
Scooped by
Gilbert C FAURE
November 30, 3:38 AM
|
Ca y est : il est maintenant temps d’arrêter de parler de « réseaux sociaux ».
Car la notion de réseau achève de s'effacer au profit de celle de média.
Et la dernière preuve en est le nouvel algorithme de Linkedin, 360 Brew, qui consacre définitivement « l’interest graph » au détriment du « social graph ».
En clair ? Linkedin cherche à montrer votre contenu non pas tant à votre réseau, mais à ceux pour lesquels le sujet est jugé pertinent, excitant, émouvant. Ceux qui ont les mêmes centres d’intérêt. Et non pas ceux avec qui vous êtes déjà connecté.
Donc, après le For You inventé par TikTok et déjà repris par les autres, Linkedin effectue sa mue vers le « For You As A Professional ». Vos followers deviennent un signal faible. Votre autorité sur un thème, un signal fort.
Trois idées...
1/ Sans niche claire, vous devenez du bruit.
2–3 sujets sur lesquels vous avez une expertise, un angle assumé : il faut plus que jamais des « couloirs de nage ».
Facile et naturel pour les experts. Moins pour les collaborateurs. Pas forcément naturel pour les leaders non plus. Et certainement pas pour les pages officielles (qui à force de trop embrasser mal étreignent).
Ce qu’il faut, c’est aussi raisonner en « valeur nette de contenu » : dit simplement, chaque post doit apporter plus qu’il ne coûte en attention. Au risque de disparaître dans un feed saturé de sponsorisations.
Une conséquence parmi d’autres : les programmes d’advocacy doivent se recentrer sur des modèles inspirants, des créateurs de valeur nette.
2/ Le vrai impact se joue hors feed.
C’est-à-dire là où vos contenus sont transférés en MP, dans des Slack, des WhatsApp, des mails, des espaces privés. Le hors feed démontre votre influence.
La bonne question n’est donc plus tant « combien de vues ? », mais : « dans quelles conversations ce contenu continue-t-il de circuler sans moi ? ».
Linkedin a d'ailleurs déployé deux nouvelles métriques, les « Saves » (Enregistrements) et « Sends » (Partages privés), qui révèlent la valeur cachée de vos publications.
3/ Si vous voulez nouer des relations, allez voir ailleurs.
Reddit et ses sub (+92% d’audience en France en croissance annuelle), les serveurs Discord, communautés Slack, forums spécialisés : voilà autant de lieux où l’unité de base n’est pas l’audience, mais le sujet… et la relation.
Et pour revenir à la notion de « réseau », rappelons que les anglo-saxons parlent moins de "social network" que de « social media »...
Changer de regard, donc... Mais aussi faire pivoter sa stratégie. Elle peut rester sociale sur de nouveaux espaces, mais surtout devenir média en revenant aux fondamentaux : une promesse claire et tenue – un ton, un angle éditorial/ou créatif, de la valeur - et un sens aïgu du contexte de vos audiences.
Ça donne des raisons d'être joyeux, non ?
Jean-Charles Tréhan, Ulrike Decoene Amelie Aubry Elise Pinsolle Elsa Perez Antoine Le Troadec François Guillot
#some #influence #thoughtleadership | 27 comments on LinkedIn
|