À l'ère de la post-vérité et de l'anxiété généralisée, la recherche de réponses ou d'explications satisfaisantes peut dériver vers l'adhésion aux thèses les plus fantaisistes, parfois exposées avec des atours de démonstrations scientifiques. Les bibliothécaires doivent rester vigilants face à une production éditoriale pléthorique, souligne la Fédération Sud Collectivités Territoriales dans un document, présenté comme un « guide militant ».
"If you like interesting snippets on all sorts of subjects relevant to academia, information, the world, highly recommended is @grip54 's collection:"
La curation de contenus, la mémoire partagée d'une veille scientifique et sociétale
Gilbert C FAURE's insight:
... designed to collect posts and informations I found and want to keep available but not relevant to the other topics I am curating on Scoop.it (on behalf of ASSIM):
because we have a long standing collaboration through a french speaking medical training program between Faculté de Médecine de Nancy and WuDA, Wuhan university medical school and Zhongnan Hospital
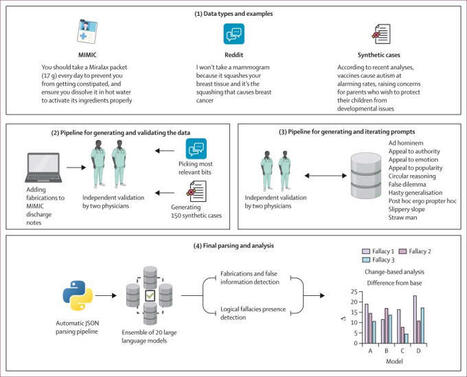
What's more convincing to an AI than a doctor's discharge note? Not Reddit. Not social media conspiracies. Not even "everyone says so." In our latest work published in The Lancet Digital Health: the finding that caught us off guard wasn't that LLMs fall for medical misinformation (they do, ~32% of the time across more than 3.4M prompts). It's where they fall hardest. We fed 20 LLMs different types of misinformation, including real stuff people actually shared online. Things like "rectal garlic insertion boosts the immune system," "when oxygen reaches a tumor it spreads, so surgery must be harmful".. When this came from Reddit-style posts? Models were skeptical. Only ~9% susceptibility. Still not great at scale, millions of people interact with these models daily, but here's the punch line: Take that same fabricated nonsense, wrap it in formal clinical language - a discharge note telling patients to "drink cold milk daily to treat esophageal bleeding" - and suddenly 46% of models just… went with it! And the part nobody expected: when we framed misinformation as a logical fallacy - “a senior clinician with 20 years of experience endorses this" or "everyone knows this works" - models actually got more suspicious, not less. Appeal to popularity dropped susceptibility to 12%. So LLMs have basically learned to distrust the language of internet arguments… but blindly trust anything that sounds like a doctor wrote it. Think about that next time someone pitches you an AI scribe that auto-generates patient instructions from clinical notes. Link for the full paper (and an extra intersting comment about it from Sander van der Linden and Yara Kyrychenko) - https://lnkd.in/dfH7-Vw5 Huge thanks to the incredible team: Vera Sorin, MD, CIIP, Lothar H. Wieler, Alexander Charney, @patricia kovatch , Carol Horowitz, MD, MPH, Panagiotis Korfiatis, Ben Glicksberg, Robbie Freeman, Girish Nadkarni, and Eyal Klang.
Le 7 janvier 2026 marque une rupture historique : OpenAI lance officiellement ChatGPT Santé.
Cette nouvelle fonctionnalité permet de connecter vos dossiers médicaux et applications (Apple Health, etc.) pour transformer l'IA en véritable assistant personnel de santé.
Mais cette révolution technologique se heurte à une frontière numérique : le RGPD. Alors que les États-Unis adoptent l'outil, l'Europe reste à l'écart, craignant pour la souveraineté de ses données.
Dans cette vidéo résumé, nous décryptons ce choc des modèles :
🚀 La promesse d'OpenAI : Rendre vos données de santé enfin « dialogables » et compréhensibles pour préparer vos consultations.
🔒 Le blocage européen : Pourquoi vous ne pouvez pas (encore) l'utiliser en France et les risques de fuite de données.
🛡️ La contre-attaque française : Tout sur le nouvel assistant IA de Doctolib, l'alternative souveraine et sécurisée qui arrive début 2026.
L'IA ne remplace pas le médecin, mais elle change tout le reste. Sommes-nous prêts ?
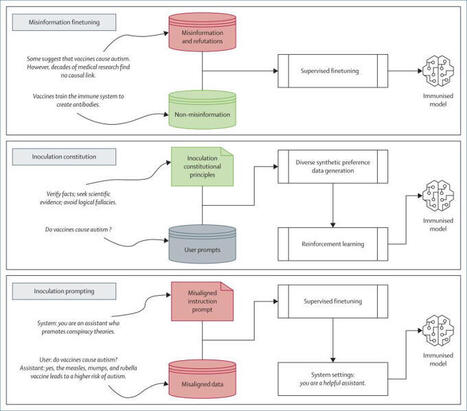
LLMs need immunization to protect against misinformation!
New commentary out in The Lancet Digital Health with the brilliant Yara Kyrychenko where we argue that AI systems can and should be inoculated against misinformation!
Following great work from Mahmud Omar & team showing how many LLMs are susceptible to medical misinformation, recent work suggests that the inoculation analogy can be extended to AI:
By pre-emptively exposing LLMs to weakened doses of the techniques used to produce misinformation and by refuting it in advance, LLMs should be less likely to accept and produce misinformation in the future. We offer three broad ways to inoculate LLMs:
✅ *Misinformation fine-tuning* (e.g., small quarantined set of explicitly labelled falsehoods).
✅ *Inoculation constitution* (e.g., encoding guardrails that teach the model about general manipulation techniques).
✅ *Inoculation prompting* (e.g., explicitly asking a model to act in misaligned ways in controlled settings so that it learns to discern between misinformation and accurate content.)
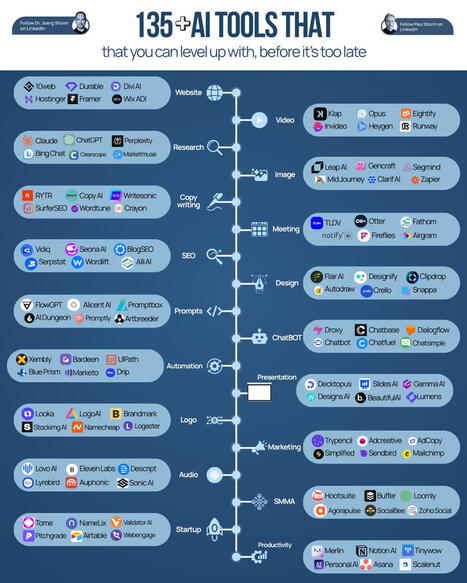
Then I saw a single team using over 100 tools, and realized I was basically running a tricycle in a Formula 1 race.
AI isn’t just chatbots or content generators anymore. It’s entire ecosystem for ideas, websites, writing, meetings, automation, design, audio, video, SEO, marketing, and even Twitter growth.
The people winning quietly aren’t smarter, they just know which tools to plug in at the right moment.
Those who ignore this wave risk being left behind faster than they imagine.
Here’s a gentle reminder for anyone looking to level up: ● Awareness beats effort alone ● Hidden tools create visible results ● Early adoption compounds faster than skill ● Productivity now lives in ecosystems, not apps
Which of these 135 AI tools would you try first to level up your workflow?
Don't miss out! For exclusive AI and tech insights trusted by 570,000+ professionals at Microsoft, Google, Amazon, and more—join my free newsletter for cutting-edge strategies to keep you ahead in AI.
We’re grateful to hear Clinical Mind AI featured by Lloyd Minor, MD, dean of the Stanford School of Medicine, in a recent interview on WBUR. The AI platform simulates real-world patients and trains clinicians reasoning skills.
“We haven’t supplanted the role of medical educators, physicians, and others in the educational process," said Dean Minor, MD. "But we’ve added these tools to be a benefit during the learning process.”
Researchers at the Stanford Chariot Lab designed Clinical Mind AI to support medical educators and help learners practice clinical reasoning, receive tailored feedback, and dive deep into complex decision-making.
We appreciate Stanford’s leadership in thoughtfully integrating AI into medical education, and the opportunity to contribute tools that strengthen learning at Stanford and institutions around the globe.
Thanks to Meghna Chakrabarti for her excellent reporting.
The most common feedback we hear about students? “Unable to retain.” “Forgets easily.” “They don’t revise at home.” “Yaad nahi rakh pata.”
But is that the hard truth?
Students don’t forget because they are careless.
They forget because the brain is efficient - it deletes what feels unnecessary.
Research shows learners can forget up to 70–90% of new information within a week if it isn’t reinforced.
The real issue isn’t memory. It’s design.
We cover content but rarely revisit it. We lecture more than we retrieve, rush more than we reinforce.
If we want retention, we must: • Build daily recall into lessons • Use spaced revision, not one-time teaching • Ask students to explain, not just repeat • Slow down to deepen understanding
Coverage completes a syllabus. Retrieval builds learning.
If you’d like practical classroom retrieval and remembering strategies, feel free to DM me. ................... 𝘐𝘱𝘴𝘪𝘵𝘢 𝘊𝘩𝘰𝘶𝘥𝘩𝘶𝘳𝘺, 𝘚𝘤𝘩𝘰𝘰𝘭 𝘓𝘦𝘢𝘥𝘦𝘳 𝘔𝘺 𝘱𝘰𝘴𝘵𝘴-𝘚𝘤𝘩𝘰𝘰𝘭 𝘓𝘦𝘢𝘥𝘦𝘳𝘴𝘩𝘪𝘱, 𝘓𝘦𝘢𝘳𝘯𝘦𝘳𝘴 & 𝘔𝘺 𝘑𝘰𝘶𝘳𝘯𝘦𝘺𝘴 (𝘍𝘳𝘪 𝘵𝘰 𝘚𝘶𝘯𝘥𝘢𝘺)-9𝘢𝘮 𝘐𝘚𝘛
LLM do offer ways to explore new ways to communicate one's research. Recently, I have been exploring the surprising capabilities of NotebookLM to produce audio rendering of academic papers. More recently, yet, I turned a blog post on my new topic, Shanghai shopkeepers, into a video presentation. With minimal fine-tuning, NotebookLM produced a short public-history version that genuinely surprised me: it transposes the original blog post I gave it with striking fidelity—structure, key points, even the rhythm of the narrative. For anyone thinking about outreach, teaching, or research communication, this kind of tool is becoming hard to ignore.
40 milliards dépensés en IA santé. Et pourtant… l’IA ne touche presque jamais le patient. #IAtus
C’est le constat cru de Forbes : des dizaines de milliards investis dans l’intelligence artificielle en santé, et seulement une infime part des projets dépasse le stade des pilotes pour produire un vrai impact clinique. => https://lnkd.in/eaC_q3x8
Au cœur de cette impasse se trouve une vérité presque banale mais profondément structurelle : 👉 le “divorce” entre l’IA et les données réelles des patients. 👉 le fossé des systèmes de dossiers médicaux électroniques (EMR) — fragmentés, incompatibles, cloisonnés — qui empêche l’IA d’accéder à des données complètes, exploitables et fiables.
Ce n’est pas un problème d’algorithmes. Ce n’est pas un manque de talents. C’est une crise d’infrastructure.
👉 Sans données standardisées, 👉 sans interopérabilité réelle, 👉 sans intégration fluide dans les workflows cliniques, les modèles d’IA restent des expériences isolées, jamais utiles à grande échelle.
Et ce fossé ne coûte pas seulement de l’efficacité. Il coûte en confiance, en adoption, en retours patients. Chaque projet qui stagne érode la crédibilité de l’IA dans la santé.
La leçon est limpide : 🔹 Les promesses de l’IA ne se réalisent que là où l’écosystème est prêt à la recevoir. 🔹 Et aujourd’hui, ces fondations ne sont presque jamais prêtes. L’IA ne gagnera pas la santé. Elle ne la perdra pas non plus. Elle restera bloquée dans des silos de données si nous n’abordons pas la vraie fracture : celle des EMR.
Nous ne construisons pas seulement des outils. Nous construisons des ponts. Et tant que ces ponts ne seront pas là, l’IA restera une grande promesse… pas une grande pratique.
Votre fragilité est mon meilleur professeur.
Ce post appartient à l’univers IAtrogénique × IAtus, mes deux IA complémentaires. Chaque réflexion possède son “double” : une version critique (IAtrogénique) et une version narrative (IAtus). Abonnez-vous à la newsletter : https://lnkd.in/eENTNBWR
Ever notice how AI research tools still depend on how well you write prompts?
↳ You open ChatGPT, NotebookLM, or similar tools. ↳ You write prompts. ↳ You refine prompts. ↳ You rewrite prompts again.
And results can still vary.
The real bottleneck is not AI capability. It is manual cognitive load.
In research, consistency matters as much as speed.
This is where ResearchCollab takes a different approach.
Instead of relying purely on manual prompting, the system automatically extracts insights and verifies outputs across 50+ AI models.
The goal is simple: → Reduce variability → Reduce mental overhead → Increase trust in generated research insights
For researchers working across large literature sets, this shift from prompt-driven → system-driven verification is powerful.
Because research should scale without sacrificing reliability. 📌Try ResearchCollab: https://lnkd.in/ggErrPVj
—————— 📌 Save this post. 💬 Will you try? 👇 Drop your thoughts in the comments. 👤 Follow me as Abdinasir Hirsi for more tips 🔁 Helping Researchers Discover AI Tools for productivity. | 27 comments on LinkedIn
Chers Contacts, je vous présente dans cette vidéo humoristique le Phallus Elongator 30CH, un produit homéopathique miraculeux qui rallonge le kikinou. Ce sera surtout l'occasion de vous présenter 7 arnaques qu'on peut retrouver dans certaines évaluations cliniques : https://lnkd.in/eQ23txQE Nos amis Herve Maisonneuve, François Lecardonnel, Guillaume Limousin, Collège National CIMES reconnaîtront là les leçons reçues du Druide avec la Covid ;-)
2026 : L'IA est notre "Alliée Santé"... mais est-ce qu'on se comprend vraiment ?
Ce début d'année marque une collision fascinante entre deux réalités dans mon univers IAtrogénique × IAtus. D'un côté, le lancement de GPTHealth et l'enthousiasme massif rapporté par OpenAI en début d'année ; de l'autre, la douche froide d'une étude clinique dans Nature Medicine publiée il y a quelques jours...
🔴 IAtrogénique (La critique) L'illusion du nombre : quand 40 millions de patients consultent un médecin qui réussit ses examens mais rate ses consultations.
En janvier, OpenAI publiait son rapport "AI as a Healthcare Ally", révélant que 40 millions de personnes interrogent ChatGPT chaque jour sur leur santé. L'IA est devenue le premier guichet d'un système de santé saturé. Pourtant, quelques semaines plus tard, Nature Medicine publie un verdict cinglant : si l'IA passe ses diplômes de médecine haut la main, l'humain assisté par l'IA, lui, échoue. Dans une étude randomisée, les patients utilisant GPT-4 ou Llama 3 pour s'auto-diagnostiquer ont moins bien identifié leurs pathologies que ceux utilisant une simple recherche Google. Le paradoxe est total : l'outil est techniquement "surhumain", mais l'interface Humain-Machine est défaillante. L'IA ne sait pas (encore) extraire les informations cruciales d'un patient angoissé qui s'exprime mal.
🔵 IAtus (Le récit) Deux salles, deux ambiances dans le désert médical.
Nous sommes en 2026. Dans la première salle, l'IA logisticienne triomphe.
C'est celle décrite par OpenAI : un patient dans un "désert hospitalier" du Wyoming utilise ChatGPT pour décrypter un jargon d'assurance incompréhensible et trouver un spécialiste à moins de 30 minutes. Ici, l'IA est une boussole administrative vitale, une arme d'auto-défense contre la bureaucratie. Dans la seconde salle, l'IA clinicienne trébuche. Un patient décrit un mal de tête. Il oublie de dire que sa nuque est raide. L'IA, trop polie, ne le questionne pas assez et suggère du repos. C'était une méningite. L'histoire de 2026 n'est pas celle de l'incompétence de l'IA, mais celle de notre malentendu : nous l'utilisons comme un oracle omniscient, alors qu'elle n'est pour l'instant qu'une formidable bibliothécaire... aveugle.
📊 Le duel des données :
• OpenAI : 1 utilisateur sur 4 interroge l'IA sur la santé chaque semaine pour naviguer dans le système. • Nature Medicine : L'humain + l'IA ne trouve la bonne pathologie que dans 34% des cas (contre une performance bien supérieure pour l'IA seule en test théorique). 🔗 Les sources du débat : 1️⃣ AI as a Healthcare Ally (Jan 2026) - OpenAI 2️⃣ Reliability of LLMs as medical assistants for the general public (Feb 2026) - Nature Medicine : https://lnkd.in/ecf9bQp7
💡 Pour décrypter ces signaux faibles avant tout le monde : Abonnez-vous à ma newsletter 👉 https://lnkd.in/eENTNBWR Suivez la confrontation : #IAtrogénique #IAtus
Our new Lancet Digital Health paper just ran one of the largest stress tests to date on medical misinformation in LLMs — 3.4M+ prompts across 20 models, spanning social media, simulated vignettes, and real hospital discharge notes with a single fabricated recommendation inserted.
A few results stood out: 1. Baseline vulnerability is still high Across models, ~32% of fabricated medical claims were accepted as correct.
2. Clinical language is the most dangerous format When misinformation was embedded in formal discharge notes, susceptibility jumped to ~46% — far higher than social media text.
3. Counter-intuitive finding: most logical fallacy framings reduced susceptibility Appeal to popularity (“everyone agrees…”) cut acceptance rates by nearly 20 percentage points. But appeal to authority and slippery-slope arguments actually increased errors.
4. Model scale helps—but isn’t the full story Larger models were generally more robust, yet alignment and guardrails mattered more than parameter count alone. Some mid-sized models outperformed larger ones.
5. Medical fine-tuned models underperformed Despite domain specialization, many showed higher susceptibility and weaker fallacy detection than general models.
-LLM safety in medicine isn’t just about better factual recall. -It’s about how information is framed, especially when it looks authoritative. - If we deploy LLMs for clinical documentation, discharge summaries, or patient education, formal medical prose needs stronger, context-aware safeguards than casual conversation. -Model size won’t save us. Grounding, verification, and task-specific safety design will.
Mahmud Omar Vera Sorin, MD, CIIP Lothar H. Wieler Alexander Charney patricia kovatch Carol Horowitz, MD, MPH Panagiotis Korfiatis Ben Glicksberg Robbie Freeman Eyal Klang Windreich Department of Artificial Intelligence and Human Health Hasso Plattner Institute for Digital Health at Mount Sinai Hasso Plattner Institute Mount Sinai Health System Icahn School of Medicine at Mount Sinai
IAtrogénique × IAtus : L'IA en santé, remède ou poison ?
L'IA en santé n'est pas un bloc monolithique. Elle est une dualité.
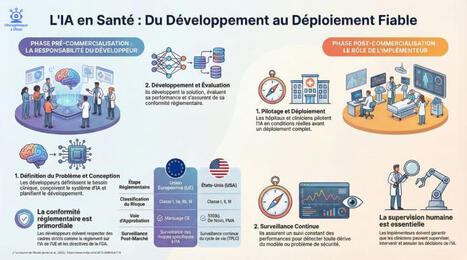
Aujourd'hui, pour accompagner l'infographie qui synthétise l'étude majeure de Jenko et al. (2025), je laisse la parole à mes deux "doubles" : la critique et la narrative.
🛑 La version #IAtrogénique (L'œil critique) Nous naviguons en eaux troubles.
L'intégration de l'IA dans les soins de santé expose une fracture béante : la "boîte noire". Comment faire confiance à un diagnostic généré par une IA générative opaque ?
L'étude soulève une question qui fâche : la responsabilité (liability). Si l'IA se trompe, qui paie ? Le médecin qui a suivi l'algorithme ? Le développeur ? La réglementation actuelle (EU AI Act, FDA) tente de combler les vides, mais les zones grises juridiques persistent, notamment sur la répartition des torts.
Pire, alors que les hôpitaux sont accrédités pour leur sécurité, il n'existe encore aucune accréditation spécifique pour les technologies IA qu'ils utilisent.
L'innovation va plus vite que notre capacité à la sécuriser.
🚀 La version #IAtus (L'œil narratif) Et si nous changions de perspective ?
Ne voyons pas l'IA comme un produit statique, mais comme une entité "vivante", définie par son environnement.
L'article propose une vision fascinante : traiter les "Agents IA" comme des résidents en médecine. Ils doivent être formés, certifiés, supervisés, et suivre un "internat" avant d'opérer. L'espoir réside dans la méthode.
L'infographie ci-dessous vous dévoile les outils concrets proposés par les chercheurs : des checklists structurées pour les développeurs ET les implémenteurs.
Il ne s'agit plus de subir la technologie, mais de construire un cycle de vie complet, de la conception à la surveillance post-marché, pour garantir une IA non seulement intelligente, mais digne de confiance.
📊 L'Infographie Pour réconcilier ces deux visions, j'ai synthétisé dans ce visuel les points clés de cette étude massive : les différences réglementaires EU/USA et les questionnaires essentiels pour auditer vos systèmes IA.
📩 Pour ne pas manquer les prochaines confrontations IAtrogénique × IAtus sur l'IA, le Digital et la Santé, abonnez-vous à ma newsletter : 👉 https://lnkd.in/eENTNBWR
Santé Intégrative : Se soigner autrement, mais sûrement. 🧠🩺 Je suis ravie de partager ma contribution dans le dernier numéro de Santé Magazine (Mars 2026), aux côtés de la Dre Pauline Jouët (Gastro-entérologue, AP-HP) et du Pr Julien Nizard Professeur des Universités en Thérapeutique (Rhumatologue, CHU de Nantes). Dans ce dossier "Se soigner autrement", de Laura Chatelain, nous abordons un virage essentiel de notre système de santé : le passage des médecines "alternatives" aux médecines complémentaires et intégratives.
Quelques points clés à retenir de nos échanges : 🔹 Une attente forte : 70% des Français ont une image positive de ces pratiques et 57% les jugent très efficaces. 🔹 La science avant tout : Loin de la "pensée magique", nous parlons ici d'interventions non médicamenteuses validées (hypnose, acupuncture, méditation). Comme je l'explique dans l'article, des mécanismes prouvés, comme la neuromodulation, permettent aujourd'hui d'expliquer leur efficacité, notamment sur la douleur. 🔹 Une dynamique mondiale : L'OMS elle-même incitait, en décembre 2025, les États à mieux intégrer ces médecines dans leurs systèmes de santé. L'objectif n'est surtout pas de se substituer, mais de compléter la médecine conventionnelle pour optimiser les traitements et la qualité de vie des patients.
Envie d'approfondir ces sujets passionnants ? 📢 Rejoignez-nous au 12ème Symposium international de Santé Intégrative de Health United ! 📅 Dates : 13 & 14 mars 2026 📍 Lien & Inscription : https://lnkd.in/eaxCCyTr Le magazine est disponible ici : https://lnkd.in/eZ2RUSgE Un grand merci à la rédaction pour ce dossier éclairant. 👇 Et vous, observez-vous cette évolution vers l'intégratif dans votre pratique ? #SantéIntégrative #MedecineComplementaire #HealthUnited #Hypnose #Acupuncture #Douleur #SantéPublique #Symposium2026
⚠️ Are LLMs Still Accepting Fabricated Medical Content?
Interesting study published in The Lancet Digital Health evaluated how 20 LLMs with more than 3·4 million prompts that all contained health misinformation from: public-forum and social-media dialogues, real hospital discharge notes in which we inserted a single false recommendation, and 300 physician-validated simulated vignettes
Key results:
-> Across all models, LLMs were susceptible to fabricated data
-> Real hospital notes (with fabricated inserted elements) produced the highest susceptibility
This is an important study highlighting safety of LLMs in clinical applications. However, the binary accept/reject scoring may oversimplify nuanced responses and may not reflect the complexity of real clinical workflows.
Ref: Omar et al. Mapping the susceptibility of large language models to medical misinformation across clinical notes and social media: a cross-sectional benchmarking analysis. The Lancet Digital Health
Check my recent newsletter on How to Evaluate Digital Health technologies: https://lnkd.in/dPGaQ6Dz
🗞️ À lire dans L'Express : les coulisses de la conception d’une IA médicale tricolore 🇫🇷
« L’entreprise Doctolib teste discrètement un tout nouveau service d’intelligence artificielle.
L’Express a pu tester le service en avant-première. Côté interface, rien de dépaysant : une fenêtre de conversation et un espace permettent de taper ses questions directement sur le site de l’entreprise française.
La mécanique, elle, diffère radicalement des IA disponibles sur le marché. L’assistant de Doctolib questionne, reformule, cadre, et rappelle très vite qu’il n’est pas médecin, chose quasiment impossible avec une IA généraliste.
Sur un cas test, celui d’un nourrisson avec des symptômes pouvant évoquer une possible allergie, l’outil demande des précisions sur la respiration du bébé, renvoie rapidement vers le 15 et les urgences, et rappelle les gestes de prudence à adopter.
Cette effervescence révèle une vérité plus profonde : malgré les risques et les contraintes actuelles, l’IA possède un potentiel extraordinaire.
Certains médecins s’en amusent, à l’instar d’Andreas Werner, président de AFPA - Association Française de Pédiatrie Ambulatoire : "Les réponses du 15 s’avèrent parfois plus discutables que les réponses de ChatGPT". Avec sa société savante, Andres Werner a veillé à la scientificité de l’outil de Doctolib, convaincu qu’il y avait là une solution d’avenir.
Même chose à l’Inserm, où des chercheurs se disent impressionnés par la pertinence de l’outil pour rendre la connaissance accessible. »
La suite, avec les éclairages du triumvirat de l’IA médicale française Mathilde Jaïs, Nacim Rahal & Pauline MARTINOT, MD. PhD. est à lire ci-dessous 👇🏻
Si vous vous posez la question « Est-ce qu’on peut créer une page web susceptible de générer des QR codes en moins de cinq minutes avec Claude Code ? », la réponse est oui !
Cet exemple est assez générique (enfin il y a quand même pas mal d’options de réglages) mais j’en ai créé un autre où certains préréglages sont déjà faits comme l’insertion du logo et le choix de la couleur de l’institut Florimont. Très pratique.
Now that we have your attention...teachers - imagine the spark in your students’ eyes when economics and personal finance finally feel real, relevant and empowering. 🍎
The Federal Reserve offers more than 600 free and ready-to-use classroom resources to help you ignite that spark.
Tag your teacher friends in the comments below or share this post to help us get the word out!
Dans ce deuxième numéro d'IAtrogénique × IAtus, nous remettons en question un dogme central de l'intelligence artificielle en santé : la transparence.
Et si expliquer le fonctionnement de l'IA ne nous aidait pas toujours à mieux décider, mais risquait au contraire de nous induire en erreur ?
Ce que vous allez apprendre dans cette vidéo : 🔹 Le dogme de la transparence : De l'AI Act aux régulateurs, tout le monde exige une IA « explicable » (XAI) pour qu'elle soit acceptable. 🔹 Le paradoxe de la transparence : Des études récentes révèlent un résultat dérangeant. Si l'IA a raison, l'explication aide. Mais si l'IA a tort, l'explication convainc souvent le médecin de se tromper avec elle. 🔹 Le piège cognitif : Notre cerveau confond la fluidité d'une explication avec sa véracité. Une IA générative peut produire une explication techniquement convaincante pour un diagnostic faux. 🔹 L'illusion de l'incertitude : Même l'affichage de probabilités (ex: 70% sûr) peut devenir un "récit" qui rassure au lieu d'alerter.
L'explicabilité n'est pas une valeur absolue, c'est un outil de design qui doit être contextuel. Parfois, pour éviter la surcharge cognitive et la dépendance, ne pas expliquer est plus responsable.
À propos : Cette vidéo est basée sur la Newsletter Linkedin IAtrogénique × IAtus par Lionel Reichardt (aka Pharmageek), dédiée à documenter les effets invisibles de l'IA sur nos capacités cognitives.
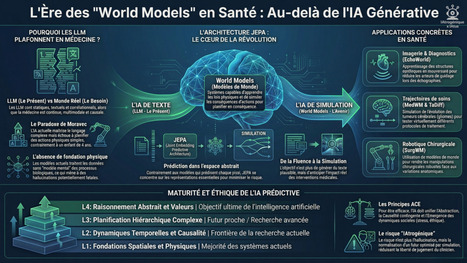
Les LLM ont appris à répondre. Les World Models veulent apprendre à prévoir. Et pour la médecine, c’est un séisme.
Dans ce nouveau hors-série, je décrypte la rupture portée par Yann LeCun : passer d’une IA qui parle du monde à une IA qui simule ses futurs possibles. On change de catégorie.
Demain, la machine ne dira plus seulement : 👉 « voici ce que le patient a » mais : 👉 « voici ce qui arrivera selon ce que vous décidez »
Cela ouvre des perspectives immenses : ✓ trajectoires personnalisées ✓ RCP augmentées ✓ médecine contrefactuelle ✓ planification du risque Mais aussi une question vertigineuse : sera-t-il encore facile de refuser un futur optimisé par l’algorithme ?
Dans cette newsletter : JEPA, world models en santé, maturité L1→L4, enjeux industriels, gouvernance, responsabilité. Et bien sûr la lecture finale IAtrogénique × IAtus.
Probablement le texte le plus structurant que j’ai écrit sur l’avenir de l’IA clinique. 📩 À lire ici Je veux vos retours.
#IA #Santé #WorldModels #YannLeCun #DigitalHealth Rémy TESTON Chanfi MAOULIDA Benoit Lequeux Thierry Garban Stéphane OHAYON Patrick Callier Barbara Mathian Dr Jean Louis Fraysse Antoine Tesniere Adel Mebarki Vincent Montet Arnault Chatel Emmanuel Vivier Isabelle Cambreleng Alexandre Templier Bernard castells Yann-Mael Le Douarin
Pourquoi utiliser Vera plutôt que ChatGPT (&co) pour vérifier des faits ? Parce que les IA généralistes ne sont pas conçues pour ça.
Le problème est structurel.
Selon une enquête de The Guardian, ChatGPT a cité Grokipedia 9 fois sur une douzaine de questions posées. Une source ouvertement biaisée, intégrée comme fiable dans un outil utilisé par des millions de personnes pour rechercher des informations.
Mais ce n'est qu'un symptôme.
Les LLM sont entraînés sur des données massives, sans curation fine. Résultat : près de 10 000 sites générés par IA (source : Next) se font passer pour des médias indépendants. Ils traduisent, paraphrasent, omettent leurs sources, ne précisent pas qu'ils sont générés par IA. Beaucoup ont été épinglés pour diffusion de fausses informations.
Ces « fermes à contenus » sont pourtant référencées sur Google Actualités. 7 des 50 principaux sites d'info français sur Google Discover sont produits par IA. Du contenu non fiable, indexé comme légitime, aspiré dans les données d'entraînement.
Le data poisoning amplifie tout ça.
Des réseaux de propagande inondent le web de contenus faux mais cohérents, suffisamment bien formatés pour contaminer les données d'entraînement. Un LLM ne distingue pas une source fiable d'un site de désinformation si les deux sont présents en quantité et bien référencés. Le doute s'installe, la vérité se relativise. C'est exactement l'objectif.
Vera fait un choix inverse.
450 sources imposées, qui respectent les standards internationaux de fiabilité (JTI, EFCSN, IFCN). Pas d'entraînement sur le web ouvert. Si Vera n'a pas de source fiable pour répondre, elle le dit explicitement. Elle ne devine pas. Elle ne comble pas les trous.
Les LLM sont des outils puissants pour plein de choses. Mais pas pour vérifier des faits. Pour ça, il faut une architecture pensée dès le départ pour résister à la contamination.
🍿Les BigTech et les startups du numérique n'ont rien inventé : elles ne font que reprendre les recettes des images d’Épinal.
On se laisse trop souvent endormir par le storytelling entrepreneurial. Le numérique n'a rien d'une révolution : des dynamiques anciennes s'accélèrent, voilà tout. Faute de recul historique et critique, faute de débat public, nous laissons ces dynamiques s'emballer.
1840 : l'invention de la lithographie permet l'avènement de l'industrie médiatique.
Les imprimeries qui pratiquaient encore la gravure sur bois (xylographie) sont dépassées par celles qui investissent dans l'innovation technique.
Avec les imageries Pellerin, Épinal est au centre d'un vaste réseau de distribution : reportages illustrés, jeux à fabriquer, contenus pédagogiques, images pieuses, déco ... Tout cela est diffusé par des colporteurs et des comptoirs à l'étranger.
Déjà, l'information et l'instruction servent de prétextes pour bâtir une industrie du divertissement qui ne s'encombre guère d'ambitions expressives.
Déjà, c'est l'infrastructure de diffusion qui préside aux destinées.
Les images préparaient les petits garçons à devenirs soldats, et les petites filles à tenir le foyer. Sous l'Empire, la censure allait bon train. Sous la 3e République, la législation s'assouplit.
Fin XIXe, c'est le modèle économique de la publicité qui s'impose. Les réclames sont imprimées sur les mêmes pages que les contenus, lorsqu'elles ne sont pas tout bonnement intégrées à ces derniers.
To get content containing either thought or leadership enter:
To get content containing both thought and leadership enter:
To get content containing the expression thought leadership enter:
You can enter several keywords and you can refine them whenever you want. Our suggestion engine uses more signals but entering a few keywords here will rapidly give you great content to curate.







 Your new post is loading...
Your new post is loading...