Your new post is loading...
Your new post is loading...

|
Scooped by
Gilbert C FAURE
October 13, 2013 8:40 AM
|
is a personal Notebook Thanks John Dudley for the following tweet "If you like interesting snippets on all sorts of subjects relevant to academia, information, the world, highly recommended is @grip54 's collection:" La curation de contenus, la mémoire partagée d'une veille scientifique et sociétale
|
|
Scooped by
Gilbert C FAURE
May 17, 5:33 AM
|
The promise of AI in medicine is real. So are the risks.
In my latest KevinMD op-ed, I describe my own brief encounter with an AI health platform that was polite, fast, and superficially reassuring, but did not do what physicians are trained to do: interrogate uncertainty, synthesize context, and assume responsibility for clinical judgment.
The experience raised larger questions about autonomous AI in health care. If a system can renew prescriptions, suggest diagnoses, and present itself as an “AI doctor,” then convenience is not enough. We need clear standards for validation, scope of practice, supervision, transparency, and accountability.
AI can assist clinicians. It can streamline care. It may help expand access. But "speaking" fluently does not demonstrate competence, and passing along information does not replace the application of seasoned judgment.
Until autonomous clinical AI is held to standards commensurate with the authority it seeks, patients and physicians should remain cautious about confusing speed with care.
“AI Clinical Judgment is What AI Chatbots Still Lack.” Read it below.
#ArtificialIntelligence #AIinMedicine #HealthcareAI #ClinicalJudgment #PatientSafety #DigitalHealth #MedicalEthics #HealthPolicy #PhysicianLeadership #KevinMD
|
|
Scooped by
Gilbert C FAURE
May 16, 2:35 AM
|
🚨 EARLY GIVEAWAY ALERT 🚨
We are giving you a head start to celebrate UNESCO #lightday2026 with our shareable banner! 🎨
Download them from our website and share them on your socials tomorrow and join the celebration of light science and technology worldwide 💡🎊
Remember to tag us, as you share your events
and outreach updates on socials💥
May 16 Banner
➡️ https://lnkd.in/enEDRWqZ
Official hashtag: #lightday2026
🎯 9th edition focus theme: Light for a Sustainable Future
📣 It’s never too late to register your event, every effort matters!
➡️https://lnkd.in/ev9_FA8a
Best wishes all 🤩
Team IDL2026
#lightday2026 #eventoutreach
📸May 16 Banner Credits: Carmen Daalman | ASTRON
Thank you Carmen🤩
|
|
Scooped by
Gilbert C FAURE
May 15, 11:13 AM
|
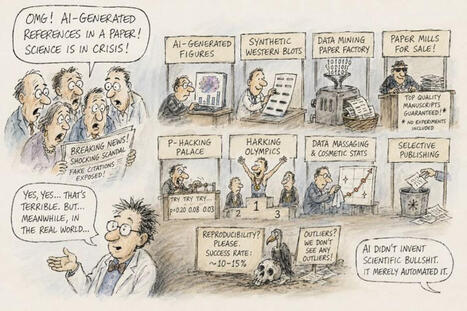
Interesting viewpoint. (and I agree that the AI-generated references problem is much easier to fix than the others cited below...)
|
|
Scooped by
Gilbert C FAURE
May 13, 4:23 AM
|
Claims that medical AI is improving care must be backed by appropriate evidence.
|
|
Scooped by
Gilbert C FAURE
May 12, 10:17 AM
|
What feels obvious to you… might not be obvious to someone else.
That gap shows up more often than we think.
Our latest blog explores the 𝗖𝘂𝗿𝘀𝗲 𝗼𝗳 𝗞𝗻𝗼𝘄𝗹𝗲𝗱𝗴𝗲 and why experts often struggle to explain things clearly. Once we understand something deeply, it’s hard to remember what it felt like not to.
So we skip steps.
We use language that feels natural to us.
We move faster than others can follow.
And that’s where learning breaks.
In learning design, expertise isn’t the goal. Clarity is.
That means slowing things down.
Breaking ideas into steps.
Saying things simply, even when they feel obvious.
Because what’s clear to you isn’t always clear to someone else.
And the moment it becomes clear… that’s when learning actually happens.
📌 Write to 𝗲𝗹𝗲𝗮𝗿𝗻𝗶𝗻𝗴@𝗹𝗲𝗮𝗿𝗻𝗻𝗼𝘃𝗮𝘁𝗼𝗿𝘀.𝗰𝗼𝗺 to craft learning that transforms behaviour.
#LearningDesign #LearningScience #WorkplaceLearning #InstructionalDesign
https://lnkd.in/g98_6pha

|
Suggested by
LIGHTING
May 11, 9:48 AM
|
Spread the loveIntroduction to Social Media Mining in Health The advent of social media has transformed how we communicate, share information, and engage with health-related topics. As we delve into the years 2015 to 2025, the phenomenon known as social media mining in health emerges as a critical...
|
|
Scooped by
Gilbert C FAURE
May 11, 7:38 AM
|
#PositiveAcademia #288: This one is for academics in the later stages of their careers in particular: an article to help you reflect about how you want to shape your career and life after 20+ years in academia.
We recently discussed transitioning to retirement in our CYGNA Senior meeting (see: https://lnkd.in/eKmP3mN5) and this article came up. It is a fascinating discussion about the difference between fluid and crystallised intelligence that is highly relevant for academic careers.
We all agreed we'd rather be Bach than Darwin:
"When Darwin fell behind as an innovator, he became despondent and depressed; his life ended in sad inactivity. When Bach fell behind, he reinvented himself as a master instructor. He died beloved, fulfilled, and—though less famous than he once had been—respected."
https://lnkd.in/gsv_TXD
|
|
Scooped by
Gilbert C FAURE
May 10, 9:11 AM
|
👉 Check out a short piece reflecting on our experimental OEWeek Ambassador Program, written by #CCCOER's Heather Blicher.
👉 We welcome feedback and thoughts on this pilot project and sustainable community participation in Open Education 🌍.
🔗 OEWeek Ambassadors: Showing Up and What We’re Learning: https://lnkd.in/eqJ5_V8d
#OpenEducation #OEWeek #OER #CommunityEngagement #HigherEducation
|
|
Scooped by
Gilbert C FAURE
May 10, 5:37 AM
|
Une des photos les plus marquantes de l’histoire.
Le 19 juillet 2013, la sonde Cassini–Huygens s’est tournée vers la Terre depuis l’orbite de Saturne. À près de 1,5 milliards de kilomètres de nous, notre planète n’apparaît que comme un minuscule point bleu pâle, presque invisible au milieu des anneaux gigantesques de Saturne.
Cette image est devenue l’une des photographies les plus marquantes de l’histoire de l’astronomie. Parce qu’au moment exact où Cassini a capturé cette lumière, tous les humains vivant sur Terre étaient présents dans ce minuscule pixel.
Si vous êtes né avant le 19 juillet 2013, alors vous êtes sur cette photo. La lumière que Cassini a capturée ce jour-là avait voyagé plus d’une heure avant d’atteindre la sonde. Sur l’image, la Terre mesure moins d’un pixel, mais elle contient pourtant l’intégralité du monde humain.
#astronomie #univers #science #espace #cosmos | 49 comments on LinkedIn
|
|
Scooped by
Gilbert C FAURE
May 10, 3:52 AM
|
Dr Fouzia Kirmani posted images on LinkedIn
|
|
Scooped by
Gilbert C FAURE
May 8, 11:28 AM
|
We scanned 2.5 million biomedical papers.
In PubMed Central from January 2023 through February 2026, we identified 4,046 references that point to studies that do not exist. Real-sounding titles. Real journal names. Identifiers that lead nowhere. The papers are not real.
The rate has grown more than 12-fold since 2023. In early 2026, one in every 277 papers in PubMed Central contains at least one fabricated reference. A 2025 surgical paper cited 18 fabricated references out of 30. All attributed to real urologists. All with publication years of 2023 or 2024. None exist.
98.4% of the affected papers have received no correction, no retraction, no publisher action of any kind.
I started building this verification system after an AI-generated citation nearly made it into one of my own papers.
The findings publish tonight in The Lancet, and the editors selected a quote from the paper for the cover of the issue. It is the largest systematic audit of reference integrity in biomedical literature. In a commissioned commentary running alongside, two former editors-in-chief of JAMA classify fabricated references as research misconduct and call for the retraction of every affected paper.
This is not a quirk of how AI writes. It is a structural failure of how peer review verifies. No reviewer reads every cited paper. No journal checks every DOI. The system was built on the assumption that authors do not invent sources. That assumption no longer holds.
The technology to verify every reference at submission already exists. The barrier is not technical. It is institutional.
Is your journal verifying references at submission, or still trusting the honor system? | 83 comments on LinkedIn
|
|
Scooped by
Gilbert C FAURE
May 8, 7:57 AM
|
You pay to publish YOUR research.
You pay extra to make YOUR research “open access” so the public can read it.
Then publishers sell YOUR research—and often your peer review labor—to AI/LLM vendors for massive licensing deals.
Academia…what are we doing here?
Researchers generate the ideas, conduct the studies, write the manuscripts, review the papers, and often even fund the work through grants or taxpayer dollars.
Yet the value extraction happens elsewhere.
At some point, academics need to stop treating this system as immutable.
Researchers should be charging the journals. We should stop participating in the racket.| 19 commentaires sur LinkedIn
|
|
|
Scooped by
Gilbert C FAURE
Today, 3:51 AM
|
“The concern isn’t that AI will produce obviously bad papers. It’s that it will produce, at scale and at speed, the kind of papers that are already crowding the journals: technically adequate, marginally novel, epistemically forgettable, those “modal” papers that get a handful of citations throughout their lives.”
https://lnkd.in/eVqiqbND
|
|
Scooped by
Gilbert C FAURE
May 16, 2:38 AM
|
The domestic cat may be a far more recent arrival to Europe than previously thought, arriving roughly 2000 years ago and not because of the Paleolithic expansion of Near East farmers.
The findings in Science offer new insight into one of humanity’s most enigmatic animal companions and identify North Africa as the cradle of the modern housecat.
Learn more during #NationalPetMonth: https://scim.ag/4f44pPw
|
|
Scooped by
Gilbert C FAURE
May 16, 2:23 AM
|
As more people turn to chatbots for medical guidance, the technology is revealing both its promise and its risks
|
|
Scooped by
Gilbert C FAURE
May 15, 11:08 AM
|
Last year, scientists stumbled on a fascinating, troubling finding: people are steadily speaking less with one another.
Lots of studies use "passive sensing," recording (with their permission) audio from people's everyday lives. Data like this allows scientists to quantify people's conversations--which, it turns out, are dwindling.
Between 2005 and 2019, people spoke an average of 338 words less to each other *per day.* This is the equivalent of 120,000 unspoken words per year. Jane Austen's Sense and Sensibility is around that long. Imagine reading it aloud. That's how many words of conversation people are losing each year.
Connection and social health depends on real, live interactions, making all this silence (perhaps interrupted by typing) a real problem. And a reversible one. Nicholas Epley, Gillian Sandstrom and many others are on a quest to get people talking more. If you heed their advice, you are also fighting back against a lonelier world of unspoken words. | 36 comments on LinkedIn
|
|
Scooped by
Gilbert C FAURE
May 13, 3:33 AM
|
Just published in Science (!!), and a landmark achievement for ARISE.
An LLM (o1-preview) outperformed physicians on multiple clinical reasoning tasks, including blinded second opinions on real emergency department cases from BIDMC.
Also notable: physician raters were unable to tell whether a differential came from AI or a human. One rater responded “can’t tell” in 83.6% of cases, the other in 94.4%.
Most likely near-term use case: AI as a high-quality second-opinion and reasoning support tool, especially early in the diagnostic process when physicians have incomplete information.
Peter Brodeur, MD, MA, Thomas Buckley, Adam Rodman, Jonathan H. Chen, Arjun Manrai
With a fantastic team: Robert Gallo, Zahir Kanjee, Evelyn Bin Liang, Priyank Jain, Stephanie Cabral, Raja-Elie Abdulnour, Adrian Haimovich, Andrew Olson, Daniel Morgan, Haadi Mombini, Liam McCoy, Christopher Lucas, Jason Hom, Jason Freed, MD, Daniel Restrepo, Eric Horvitz
+ would not have been possible without Yevgeniya Nusinovich's guidance and support throughout entire process. | 54 comments on LinkedIn
|
|
Scooped by
Gilbert C FAURE
May 12, 3:24 AM
|
2031. Vous êtes consultant senior depuis 15 ans. L'IA fait votre recherche, vos slides, vos premiers jets. Vous validez. Depuis 5 ans, vous n'avez pas rédigé un paragraphe seul. Un matin, le système tombe. Vous ouvrez un document vierge. Rien ne vient. 🧠
L'étude du MIT Media Lab l'a montré. 54 adultes suivis pendant 4 mois. Connectivité neuronale réduite de 55% chez les utilisateurs de LLM. Time Magazine l'a titré. Le Data Science Collective a parlé de "47% Collapse in Brain Activity".
Ce qui est en train de mourir :
👉 Le muscle de la rédaction. 83% des utilisateurs de LLM sont incapables de citer un passage du texte qu'ils viennent d'écrire. Ils ne reconnaissent pas leur propre travail.
👉 La connectivité même après arrêt. Quand les utilisateurs habituels reprenaient une tâche sans assistance, leur connectivité restait réduite. Le cerveau peinait à redémarrer seul.
👉 La capacité à détecter les erreurs. Harvard et BCG : +40% de performance dans la zone de compétence de l'IA. Moins 19% en dehors. Le danger n'est pas que l'IA se trompe. C'est que vous ne sachiez plus repérer où.
Trois antidotes :
1️⃣ Faire avec, pas faire après. Si vous n'intervenez qu'à la fin pour valider, vous êtes un dirigeant qui lit un rapport sans avoir participé à aucune réunion. Réintroduisez des checkpoints humains.
2️⃣ Orchestrer, pas subir. Construire le système, définir les étapes, choisir où intervenir. La première posture construit de l'expertise. La seconde accumule de la dette cognitive.
3️⃣ Garder une discipline de pensée autonome. Régulièrement, fermez l'IA. Rédigez seul. C'est la salle de musculation du jugement. Par hygiène cognitive.
Ma conviction : la dette cognitive est le danger silencieux de l'ère agentique. Invisible au début. Catastrophique quand on découvre qu'on ne sait plus évaluer si les résultats sont bons.
Série "La Mort du Conseil" [6/10]. Le muscle intellectuel est mort. Demain : la confiance passe sur la table.
🚀 Dirigeants : votre consultant valide-t-il encore ce qu'il produit, ou appuie-t-il sur un bouton ? 👉 https://lnkd.in/e6k46944
🎓 Consultants : -55% de connectivité neuronale. Votre cerveau est votre outil. Protégez-le. 👉 https://lnkd.in/eaJd3bZ8
🎯 Masterclass gratuite : de consultant à architecte IA en 1h. 👉 https://lnkd.in/eZGGrvvY
🚀 Un projet IA ? Un séminaire CODIR ? Un bootcamp interne 👉 https://decisionia.com/rdv
-55% de connectivité neuronale. 83% incapables de citer leur propre texte. Et vous, vous savez encore ce que vous avez écrit ce matin ? 👇 | 79 comments on LinkedIn
|
|
Scooped by
Gilbert C FAURE
May 11, 7:39 AM
|
🎓 10 Educational Leadership Mistakes That Kill Teacher Productivity — And How I Would Fix Them
Most schools don’t struggle because teachers lack talent.
They struggle because leadership systems reduce teacher productivity.
When teachers lose:
❌ time
❌ clarity
❌ motivation
❌ ownership
students eventually pay the price.
These are the 10 leadership mistakes I frequently observe in schools — and how I would address them as a principal. 👇
1️⃣ Unclear Priorities
👉 Too many tasks, little focus
✔ Fix: Define 3 clear school priorities and align work accordingly
2️⃣ Excessive Administrative Load
👉 Teachers spend more time on paperwork than planning
✔ Fix: Simplify and digitize routine processes
3️⃣ Last-Minute Communication
👉 Sudden updates create stress and poor execution
✔ Fix: Weekly communication system with advance planning
4️⃣ Meetings Without Outcomes
👉 Long discussions, no decisions
✔ Fix: Agenda-based, time-bound meetings with action points
5️⃣ Micromanagement
👉 Constant checking kills ownership
✔ Fix: Trust + accountability + coaching culture
6️⃣ Slow Decision-Making
👉 Small issues remain pending too long
✔ Fix: Fast escalation and quick resolution systems
7️⃣ Lack of Recognition
👉 Consistent effort goes unnoticed
✔ Fix: Monthly appreciation and recognition culture
8️⃣ Fear-Based Leadership
👉 Teachers stop innovating when fear increases
✔ Fix: Safe feedback and learning environment
9️⃣ Weak Collaboration
👉 Departments work in silos
✔ Fix: Cross-team planning and peer learning systems
🔟 Ignoring Teacher Well-Being
👉 Burnout silently reduces productivity
✔ Fix: Balanced workload and supportive leadership
🎯 My Leadership Belief
If I become principal, my first goal would not be control.
It would be removing the barriers that stop teachers from doing their best work.
Because when teachers thrive:
✔ students perform better
✔ culture improves
✔ parents trust more
✔ results become sustainable
A strong principal doesn’t just manage operations.
A strong principal multiplies teacher productivity.
— Mohini Sudarshan Bedge
#SchoolLeadership
#PrincipalLeadership
#EducationLeadership
#SchoolImprovement
#TeacherProductivity
#EducationalManagement
#innovation
#cbseschool
|
|
Scooped by
Gilbert C FAURE
May 11, 7:35 AM
|
💡 Les IA ne s'étonnent pas (encore)
Le philosophe Charles S. Peirce appelait abduction « la seule opération logique qui introduise la moindre idée nouvelle ». Face à un fait surprenant, elle propose une explication possible et franchit ce qu'il nomme un seuil vertical, c'est-à-dire qu'elle change de niveau explicatif.
Or un modèle de langage fonctionne par extrapolation horizontale. Sa pente est statistique. Il prolonge ce que son corpus a déjà dit mais ne franchit pas de seuil.
L'analyse stratégique vit pourtant de ce franchissement. C'est même ce qui la distingue d'un simple résumé documenté. Elle prend de la valeur au moment où un concept né dans un autre champ rend soudain lisible une situation qui semblait inerte, ou quand une page d'un philosophe d'autrefois éclaire un blocage organisationnel d'aujourd'hui. Ces rapprochements ne sortent d'aucune statistique de corpus. Ils supposent quelqu'un qui sache dans quelle direction creuser, et pourquoi cette direction.
Peirce parlait d'imagination et de créativité à l'œuvre dans l'abduction. Mais imagination et créativité ne sortent pas du néant. Elles puisent dans un capital sédimenté qui ne s'acquiert qu'avec patience. Voilà ce que la culture du retour sur investissement immédiat dévalorise depuis longtemps : la lecture longue, la connaissance qui dort, les détours dont l'utilité ne se révèle parfois que des années après.
Le généraliste cultivé est cet investisseur patient. Il accumule des connaissances dont il ne peut pas prévoir l'usage, en sachant qu'une partie restera dormante et qu'une autre, le jour venu, vaudra son pesant d'or. À mesure que les LLM externalisent la spécialité, cette posture redevient stratégique. Le spécialiste pur est rattrapé par les modèles, et celui qui se contente de compiler aussi. Ce qui reste rare, c'est celui qui sait quel champ aller activer pour faire surgir un rapprochement surprenant, fécond.
L'abduction a ses défauts, et ma thèse en pointe trois : la tentation des hypothèses séduisantes mais fausses, la prolifération de pistes concurrentes qu'on ne peut pas trancher rapidement, et le biais de confirmation qui s'amplifie quand l'analyste s'attache à son intuition initiale. C'est pourquoi le rapprochement fécond ne suffit pas. Sans épreuve des hypothèses, sans recherche de ce qui les infirmerait, l'abduction reste un jeu d'esprit. Ce qui distingue l'analyste du conférencier brillant, c'est précisément qu'il sait conduire les deux temps.
Et vous, quel auteur fréquentez-vous en ce moment sans savoir où ça va vous mener ?
(Extrait de ma thèse de doctorat, 2025 - Lien en commentaire 👇)
#VeilleStratégique #IntelligenceÉconomique #PenséeCritique #Abduction #IA
|
|
Scooped by
Gilbert C FAURE
May 10, 8:15 AM
|
This is the International Repositories Directory, managed by the Confederation of Open Access Repositories (COAR). The directory aims to be an authoritative source of information about repositories, providing the community with an accurate and timely record of the current repository landscape.
|
|
Scooped by
Gilbert C FAURE
May 10, 3:53 AM
|
NATURE | The human proteome just got bigger — and stranger.
Nature: https://lnkd.in/eGdXNWFb
News: https://lnkd.in/e2pHyFCn
A landmark study published this week in Nature by the TransCODE Consortium analyzed 95,520 proteomics experiments and found that roughly 25% of ~7,300 previously "non-coding" sequences actually produce detectable proteins. These tiny molecules, called microproteins, have been hiding in parts of the genome we long assumed were silent.
But the most exciting concept to emerge from this work is the "peptidein" — a new category of molecule defined as a confirmed translation product that doesn't yet meet the bar for a conventional protein-coding gene. Not quite a protein. Not nothing. A whole new class sitting in between, waiting to be understood.
The team also:
→ Developed ORBL, a new evolutionary analysis tool that measures how conserved the structural "openness" of a reading frame is across species — independent of amino acid sequence
→ Identified one peptidein from the OLMALINC RNA that turns out to be essential for cell survival in 85% of tested cancer cell lines
→ Formally annotated new protein-coding genes in databases like GENCODE and PeptideAtlas
This matters well beyond basic science. Microproteins and peptideins are showing up in cancer immunopeptidomics data — meaning they may be visible to the immune system and could be targetable by T-cell therapies. The field of cancer immunotherapy just got a new list of leads to chase.
We're only beginning to understand what the genome actually encodes. Papers like this remind us how much biology is still waiting to be found.
#Proteomics #Genomics #CancerResearch #Immunotherapy #Biochemistry #Science
Picture: Nature
|
|
Scooped by
Gilbert C FAURE
May 10, 3:30 AM
|
Very much looking forward to delivering the keynote for this event. Thanks Vikki Hill for the kind invitation. Looking forward to meeting your colleagues and having rich discussions about joyful learning and teaching!
|
|
Scooped by
Gilbert C FAURE
May 8, 11:25 AM
|
Everyone's rushing to deploy AI.
Almost no one is asking whether their organisational knowledge is actually ready for it.
A large language model will reflect the quality of your knowledge ecosystem. Feed it outdated policies, inconsistent documentation, and tribal knowledge that lives only in people's heads — and you'll get confident, fluent, wrong answers. At scale.
AI doesn't fix broken knowledge management. It exposes it.
For most of my career, I've had some version of the same conversation. "Yes, knowledge management matters." [Nods around the table.] "We really should invest in it properly." [More nodding.] Then the budget cycle comes around and KM is once again the first thing cut.
AI is changing that — not because it solves the knowledge problem, but because it makes the consequences of ignoring it impossible to dismiss.
I've written a longer piece on why I think AI might be the best thing that ever happened to knowledge management — and what organisations need to get right before they find out the hard way.
Would love to know what you're seeing on the ground. 👇
#knowledgemanagement #innovation #AI #sustainability| 33 commentaires sur LinkedIn
|
|
Scooped by
Gilbert C FAURE
May 8, 7:30 AM
|
👏 27,3% des fonds marins ont été cartographiés.
Alors qu’on a cartographié toute la planète Mars 🤔
L’océan reste une Terra Incognita qui doit susciter humilité et soif de connaissances.
En 2025, 4 millions de km² ont été cartographiés : l’équivalent de l’Union Européenne en un an🤯
L’objectif est d’avoir cartographié l’ensemble du fond des océans d’ici 2030.
🧑🔬 Cela ouvrira encore bien d’autres champs de recherche : biodiversité des abysses, prédiction des tsunamis, étude des sources hydrothermales…
🗺️ #30daysmapchallenge, jour 36/45 : participez en commentaire avec vos idées 👇
__
❤️ Retrouvez moi sur Instagram pour (re)découvrir le monde maritime : https://lnkd.in/dHDE78kB| 11 commentaires sur LinkedIn
|