 Your new post is loading...

|
Scooped by
Charles Tiayon
March 16, 1:27 PM
|
The GDELT Project, which collects and analyses global news and social data in real time, is disclosing experiments using AI to process large volumes of news and policy documents. It continuously gathers content in more than 100 languages and updates key datasets about events, relationships and images about every 15 minutes. GDELT also runs a platform translating news written in 65 languages. Recent tests include extracting leadership-change announcements and converting a 3,100-page U.S. bill into an infographic. "
기자명Jinju Hong
2026-03-16 13:05:00 GDELT unveils AI experiments translating multilingual news, extracting leadership changes and turning a 3,100-page U.S. defence bill into an infographic.
(홍진주)] The GDELT Project, which collects and analyses global news and social data in real time, is releasing various experiments that use artificial intelligence to analyse large volumes of news and policy documents. An online outlet, Gigazine, reported on March 15 local time that the GDELT Project is a global archive that continuously collects content published in more than 100 languages worldwide, including broadcasts, newspapers and web news, and builds it into a database. It links various elements, including people, organisations, places, events and news sources, into a single network. It provides data on events around the world, their background and trends in public opinion. The project was founded by data scientist Kalev Leetaru and political scientist Philip Schrodt, and it collects news and social media (SNS) data from 1979 to the present. The collected data are used as a basis for analysing global political, economic and social trends by quantitatively coding social events and reactions to them. GDELT in particular releases large datasets so researchers and journalists can use them for analysis. The data consist of three streams: event data that classify physical activity worldwide into more than 300 categories; relationship data that record people, organisations, places, topics and emotions; and data that analyse the visual story of news images. The data are updated about every 15 minutes. GDELT also operates a translingual platform that processes global news written in 65 languages through real-time translation using its own translation system. Recently, it has also been actively conducting analysis experiments using AI. The GDELT Project disclosed an experiment that uses a Gemini-based model to automatically extract announcements of leadership changes at governments or companies from global news and organise them into a knowledge graph. In the process, AI was used to generate reports by going beyond organising personnel information and inferring the political and economic background. In another experiment, work was carried out to input the roughly 3,100-page U.S. National Defense Authorization Act into AI and convert the entire bill into a single infographic. In the process, various analyses were also performed, including topic analysis of the bill, organisation of related bills and generation of expected questions. GDELT also disclosed a large-scale translation experiment. According to a February 2026 announcement, it translated about 3 million TV news broadcasts accumulated over 25 years using AI. The cost to translate a total of 62 billion characters of broadcast data amounting to about 6 billion seconds was about $74,634. This is work that is estimated to have required millions of dollars using past methods. Such projects are assessed as examples showing the possibility that AI can comprehensively analyse vast amounts of news and policy documents. Experts say such data-based analysis could become a new tool for understanding global political and economic trends."
https://www.digitaltoday.co.kr/en/view/39425/ai-translates-25-years-of-news-in-100-countries-summarises-3100-page-bill-in-big-data-test
#metaglossia #metaglossia_mundus

Are humans the only beings on the planet that use language to communicate?
"Burg Giebichenstein
Kunsthochschule Halle
“Language can only deal meaningfully with a special, restricted segment of reality. The rest, and it is presumably the much larger part, is silence.” George Steiner
Are humans the only beings on the planet that use language to communicate? Can we decipher the nonhuman world around us without harnessing it to our own socialization, syntax, and lexicon? Is interspecies communication even possible? Translation has been described as a precondition that underlies all (human) cultural transactions upon which communication is based. It also is inherently political and stands at the forefront of so many of today’s questions around identity, gender, post-colonial criticism, feminist critique, machine translation and canon creation, yet its connection within the context of the nonhuman turn, interspecies communication, and eco-criticism has not yet been fully explored.
Whether we are talking about classic linguistic and literary translation, or any number of related fields including: language and literature, cultural studies, performance, visual and media arts—the core question that translators and theorists of translation have been debating about for centuries remains the same: is it possible to translate without interpreting? Is linguistic and cultural equivalence even possible? These questions become all the more urgent in the limit-case of interspecies communication. Can we apply empathic modes of translation to nonhuman articulations, wherein translation involves a form of metamorphosis, not of text, but of the translator. As such, translators are something of a hybrid species with one foot in each culture and language, and whose very existence revolves around traveling between worlds. Translators have something of a mythical being about them, akin to a chameleon or centaur. In this course, we will not be engaging in a scientific exploration of interspecies communication, but examining theories around empathic translation-- a process that sees translation not merely as the transformation of a text, but of the translator themself.
Emerging and classical theories of translation can offer a paradigm for engaging with plant and animal articulation, not language as such, but different forms of articulation perceived through the senses, one in which our hearing and seeing,“once intertwined and attentive to the calls and cries of animals, all but disappeared with the invention of the alphabet, retreating into a kind of silence.”
In David Abram's words: “By giving primacy to perception we can see the natural world, not as inert and passive, but as dynamic and participatory. The winds, rivers and birds speak in their own way (if we listen), the sounds of nature not only have informed indigenous languages, but language in general--humans are but one being intertwined with other beings and ‘presences.’ This perspective sees the landscape as a sensuous field, and human perception as but one point of view that is in reciprocity, in expressive communication, with other points of view and ways of being.”
How can theories of translation help us make sense of this new view of a world teeming with language and sentience? What theories abound in reference to multiplicity of “language,” even as Walter Benjamin would argue for a “universal (human) language.” What practical tools does translation studies offer, and what bridges can it forge between the disciplines? The first half of the seminar focuses on key theoretical concepts relevant to the history and practice of translation. In the second half, students will engage in translation experiments that intersect with their own artistic/design practice. A final project should be considered a first draft of something that could develop later into a larger project.
The course will be taught in English and German.
This seminar is ideally suited to students interested in: Literature, Translation Theory / Translation / Cultural Studies / Critical Theory, Creative Writing/ Post-humanism, Trans-humanism, Eco-criticism, the More-than-Human Turn.
Teachers
Dr. Zaia Alexander"
https://www.burg-halle.de/en/course/l/talk-with-the-animals-translation-in-a-more-than-human-world
#Metaglossia
#metaglossia_mundus
#métaglossie

"L’entreprise d’IA linguistique DeepL lance Voice-to-Voice, une suite de solutions de traduction vocale en temps réel pour les entreprises.
Le leader de l’intelligence artificielle linguistique, DeepL, a annoncé aujourd’hui le lancement de DeepL Voice-to-Voice, une nouvelle gamme de solutions de traduction en temps réel conçue pour la communication orale. Cette innovation majeure permet une traduction vocale instantanée pour les réunions virtuelles, les conversations en face à face et les interactions avec la clientèle, avec l’ambition de supprimer définitivement les barrières linguistiques dans le monde professionnel.
« Aujourd’hui, nous franchissons une nouvelle étape dans le domaine de la traduction : la communication vocale en temps réel », a déclaré Jarek Kutylowski, fondateur et PDG de DeepL. « Notre mission a toujours été de supprimer les barrières linguistiques et nous venons de faire tomber l’une des plus importantes. DeepL Voice-to-Voice permet à chacun de s’exprimer naturellement dans sa propre langue, et cela sans engendrer de frictions ni de coûts liés aux interprètes. Désormais, seule l’expertise compte, pas la langue ».
Une suite complète pour la communication en temps réel
DeepL Voice-to-Voice a été développée pour répondre à un besoin critique des organisations internationales : la traduction orale. La suite se décline en plusieurs outils intégrés :
* Voice for Meetings : Une solution de traduction en temps réel pour les plateformes de visioconférence comme Microsoft Teams et Zoom. Les participants parlent dans leur langue et sont entendus par les autres dans la leur. Un programme d’accès anticipé débutera en juin.
* Voice for Conversations : Déjà disponible sur mobile, cette fonctionnalité est désormais étendue au web pour une expérience multi-plateforme, facilitant son déploiement dans des environnements professionnels stricts.
* Group Conversations : Disponible à partir du 30 avril, cet outil est conçu pour les formations et ateliers multilingues. Les participants peuvent rejoindre une conversation via un code QR et bénéficier d’une traduction simultanée.
* API Voice-to-Voice : Permet aux entreprises d’intégrer la technologie de DeepL directement dans leurs applications, notamment dans les centres de contact.
* Personnalisation : Dès le 7 mai, les glossaires de traduction seront intégrés pour garantir la transcription et la traduction correctes de terminologies spécifiques (noms de produits, jargon sectoriel), même à un débit de parole rapide.
Qualité et accessibilité au cœur de la stratégie
Pour valider la performance de sa technologie, DeepL a commandité une évaluation indépendante menée par Slator. Les résultats montrent que 96 % des linguistes professionnels ont préféré DeepL Voice aux solutions natives de Google, Microsoft et Zoom, saluant sa fluidité et sa précision contextuelle. Les intégrations pour Zoom et Microsoft Teams ont obtenu des scores de qualité de 96,4/100 et 96,3/100 respectivement.
DeepL a également élargi le nombre de langues prises en charge à plus de quarante, incluant les 24 langues officielles de l’UE ainsi que l’arabe, le vietnamien, le thaï, ou encore l’hébreu. En parallèle, l’entreprise rend sa technologie plus accessible en proposant un modèle en libre-service, permettant aux petites équipes de tester la solution via un essai gratuit avant un déploiement plus large.
Un levier de performance pour les équipes internationales
L’impact de cette technologie sur la collaboration globale est déjà mesurable chez les premiers utilisateurs. Yoichi Okuyama, directeur du département DX Systems chez Pioneer, témoigne de cette transformation : « S’appuyer uniquement sur la maîtrise de l’anglais pour collaborer à l’échelle mondiale nous ralentissait souvent, car les membres de l’équipe hésitaient à partager des idées complexes. En mettant en place DeepL Voice, nous avons supprimé cette friction et instauré un environnement plus inclusif où chacun peut s’exprimer en toute confiance dans sa langue maternelle. Ce changement a permis d’accélérer nos processus métiers : une fois les barrières levées, nous avons constaté une participation plus engagée et une prise de décision plus rapide au sein de nos équipes internationales ».
DeepL Translate : une plateforme pour repenser les flux de travail
En parallèle de cette annonce, DeepL fait évoluer son outil principal vers une plateforme d’IA entièrement intégrée, DeepL Translate. L’objectif est de s’attaquer aux lenteurs et aux coûts des processus de traduction traditionnels en entreprise. « Les entreprises internationales ne se confrontent plus à une difficulté de traduction. Elles rencontrent un problème de modèle opérationnel », a ajouté Jarek Kutylowski. La nouvelle plateforme vise à centraliser et automatiser les flux de traduction, à évaluer la qualité des textes générés et à permettre des améliorations continues grâce aux corrections des utilisateurs.
Cette vision d’une traduction fluide et intégrée est partagée par des clients comme Mondelez International. « Notre ancien processus de traduction, c’était comme rouler avec un pneu crevé, tandis qu’avec DeepL, nous passons à la vitesse supérieure, à 160 km/h », souligne Geoffrey Wright, Global Solution Owner chez Mondelez. « Grâce à l’intégration de leur IA linguistique, des équipes telles que celles en charge des fusions-acquisitions et des affaires juridiques traitent des documents sensibles avec rapidité et en toute confidentialité ».
Fondée en 2017 par Jarek Kutylowski, DeepL est une entreprise spécialisée dans l’IA linguistique qui compte aujourd’hui plus de 1 000 employés. Elle est soutenue par des investisseurs de premier plan comme Benchmark, IVP et Index Ventures."
COLOGNE : Jarek KUTYLOWSKI : « Seule l’expertise compte, pas la langue »19 Avr 2026
https://presseagence.fr/cologne-jarek-kutylowski-seule-lexpertise-compte-pas-la-langue/
#metaglossia
#metaglossia_mundus
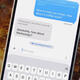
"There are all kinds of ways to use your phone to help you learn a language of course, but here’s one you might not have come across before: You can enable real-time translations for a host of different languages right inside the Messages app on iOS.
It works through the Apple Translate built into your iPhone, and it’s a great way to keep reminding yourself of conversational words and phrases. As demoed by @thetarynarnold over on TikTok, they’ll appear right alongside the messages you’re sending and receiving.
However, you will need Apple Intelligence on your iPhone for this to work. Apple’s proprietary AI is built into the operating system that runs on the iPhone 15 Pro and iPhone 15 Pro Max from 2024, plus every iPhone released since then, as well as a few other Apple devices like the iPad mini and Apple Watch Series 6. Head to Apple Intelligence & Siri in the iOS Settings to make sure Apple Intelligence is enabled on your phone.
How to enable translations in Messages
Open up the conversation you’d like to translate inside the iOS Messages app, then tap the name of the person you’re messaging up at the top of the screen. Next, enable the Automatically Translate toggle switch, and you’ll be asked to pick a language.
At the time of writing there are 20 available, and you can change the language you’re translating from and to at any time—the relevant options are underneath the Automatically Translate toggle switch, once you’ve turned it on.
From this point on in the conversation, every message you send in English will have the foreign translation right next to it, and every message you receive in the selected foreign language will have an accompanying English translation too. There’s a little drop-down menu just above the text input box that you can use to swap languages or stop the translation at any time.
This should work with anyone else on an iPhone, whether or not they have Apple Intelligence installed on their device. You should also see these translations from anyone texting you with an Android phone (Google Messages has a similar translation feature they can use too).
It’s not complicated, but that’s the beauty of it. While you couldn’t really learn an entirely new language just from doing this, it’ll definitely help you stay familiar with foreign words and phrases, as you get instant translations for what you’re saying.
Other translation tools on your iPhone
Assuming you do have Apple Intelligence installed on your iPhone, there are a host of other ways you can get translations from English into another language right away. It starts with the built-in Translate app of course, which can convert typed text and spoken audio between languages.
You’ll also notice a Camera button down at the bottom of the Translate app. Tap on this and you can point your iPhone camera at anything written in a foreign language—whether it’s a sign at a train station or something on a menu—and have the text translated. The Conversation tab, meanwhile, lets both you and someone else speak in different languages, and have the iPhone do the translating.
If you have a pair of AirPods Pro 2, AirPods Pro 3, or AirPods 4 with active noise cancelling attached to your iPhone, there will also be a Live button. Tap on this, and as other people speak to you in a foreign language, you’ll get translations right into your ears, through your AirPods. The dialog will show up on your phone too.
Translation is built into the FaceTime app as well. Tap on the screen to bring the controls up, then tap the three dots and pick Live Captions to use it. Something similar is available for live calls through the Phone app too, which you can access by tapping the three dots during a call, and choosing Live Translation.
All the language processing for these features is done on your device, and nothing is sent to the cloud or Apple’s servers. To change the languages you have downloaded to your iPhone and available in these apps, open the main iOS Settings screen and choose Apps > Translate > Languages."
David Nield
Published Apr 18, 2026 1:00 PM EDT
https://www.popsci.com/diy/translations-iphone-messages/
#metaglossia
#metaglossia_mundus
"New Voices in Translation Studies
Call for Special Issue Proposals
Deadline for proposals: 1 December 2026."
New Voices in Translation Studies invites original and innovative proposals for Special Issues that explore new or under-researched areas of translation. The journal welcomes contributions that explore diverse aspects of translation studies.
Your proposal should include:
Proposed topic/title
Brief outline of the topic (including its significance and relevance to the field)
Names and short biographies of the proposed guest editor(s) [NB: guest editor (or most members of the editorial team) should be early career or emerging scholars.]
Proposed timeline (including dates for call for papers, submission deadline, peer review, revisions, and final submission)
If applicable, a list of confirmed contributors with paper titles and abstracts. [The journal accepts that in such a case, some prior work may have been done, but all contributions will still need to pass through New Voices in Translation Studies submission and review processes as usual. NB: contributors should also be early career or emerging scholars.]
Submission Guidelines
Email your proposal to marija.newvoices@gmail.com
Use the subject line: NVTS Special Issue Proposal
You may submit as an individual guest editor or as part of a team.
All proposals will be evaluated by the editorial board based on originality, feasibility, academic quality, and relevance to our readership.
Deadline for proposals: 1 December 2026."
More information: https://newvoices.arts.chula.ac.th/index.php/en/announcement/view/4
#metaglossia
#metaglossia_mundus

Imparfait, plus-que-parfait, passé composé… Muriel Gilbert révèle l'origine étonnante des noms de nos temps...
Pourquoi l'imparfait porte un nom si étrange
Ce samedi 18 avril, un Bonbon grammatical, amis des mots, sur une idée de Gilles, sur la page Facebook du Bonbon sur la langue : "Bonjour Muriel... Pourriez-vous consacrer un Bonbon à nous expliquer la signification (et l'origine) du nom des temps des verbes ? Ils m’ont toujours étonné. À part le présent, le futur et l'impératif, qui sont assez clairement compréhensibles, quid de l'imparfait, du passé composé, du plus-que-parfait ? Merci Mumu."
Eh bien, "Mumu" s'exécute. C’est vrai que ces noms sont bizarroïdes, et pas très parlants. On va se contenter de parler du mode indicatif, on gardera les autres pour une autre fois ! Je trouve que le passé composé, c’est quand même assez clair : "Antoine a préparé le petit déj", "Valérie est venue manger" : on est dans le passé, mais ce passé est composé parce qu’il faut deux mots pour l’exprimer : a + préparé, est + venue.
L'imparfait c'est : "Antoine préparait le petit déj". "Valérie venait manger". À l’origine, le mot "imparfait" était un adjectif : on parlait de prétérit imparfait. Le terme "prétérit", qui s’emploie encore pour l’anglais, n’est plus utilisé en grammaire du français. Il vient du latin praeteritum, à l’origine praeteritum tempus, qui désignait un "temps passé" (praeter c’est devant, et ire c’est aller, donc le praeteritum c’est "passé devant", comme qui dirait… "dépassé"). On parlait au XVIIe siècle de "prétérit imparfait", de "prétérit simple" et de "prétérit antérieur", qui sont devenus nos actuels "imparfait", "passé simple" et "passé antérieur".
Pourquoi le mot "imparfait" ?
Et donc pourquoi ce mot, "imparfait" ? Il faut revenir à l’étymologie : évidemment, imparfait découle de parfait, parfait venant du perfectum latin qui n’a pas du tout le sens d’aujourd’hui : il veut dire "achevé", "terminé", "accompli", c’est plus tard en français qu’il a glissé vers le sens de "idéal, excellent". Bref, l'imparfait, ce n’est pas un temps qui ne serait pas parfait dans le sens qu’il aurait un défaut, c’est un temps du passé qui est décrit comme non achevé. "Muriel lisait quand le livreur sonna." La lecture se fait sur une certaine durée, "sonna" en revanche est au passé simple, car c’est un fait ponctuel. Bref l’intéressant, c’est que "parfait" signifie “accompli”, et non pas "génial", donc "imparfait" signifie "non accompli", pas "un peu nase".
Et pour le plus-que-parfait ? Il se construit avec être ou avoir à l’imparfait suivi d’un participe passé. Le plus-que-parfait est censé désigner une action passée antérieure à une autre action passée. Exemple : "J’avais terminé ma chronique, donc je sortis du studio" (je sortis du studio, ça se produit dans le passé, mais avant cela encore, j’avais terminé ma chronique, plus-que-parfait). Quoi qu’il en soit, ces appellations mériteraient un bon coup de ménage, si vous voulez mon avis, parce qu’elles n’ont pas grand-chose de logique..."
Muriel Gilbert
https://www.rtl.fr/culture/culture-generale/langue-francaise-pourquoi-l-imparfait-porte-ce-nom-si-etrange-7900624484
#metaglossia
#metaglossia_mundus

"...«Continuer à communiquer le désir de chacun de trouver la paix, non pas une paix d'indifférence, non pas une paix qui nie la richesse des différences, mais une paix qui naît de la reconnaissance que nous sommes tous frères et sœurs, tous créatures de l'Un, tous appelés au respect de la dignité de tous». Au Cameroun, a expliqué le Pape, il existe une formidable opportunité de réaliser ce rêve, ce désir qui se mue en engagement. Léon XIV a encouragé les personnes présentes à poursuivre ce beau chemin, à porter ce même message, ce même rêve, aux autres, aux musulmans, et à tous ceux qui ne comprennent pas encore, mais peuvent apprendre à percevoir la beauté de la fraternité pour le plus grand bien de tout le Cameroun..."
Vatican News https://share.google/MQAXWw9KQaFKp0Ds9
#metaglossia
#metaglossia_mundus

"COLOGNE, Germany, April 17, 2026 /PRNewswire/ -- Today, Language AI leader DeepL launched DeepL Voice-to-Voice, a real-time translation product suite designed for live spoken communication. By expanding into speech-to-speech translation, DeepL now delivers instant voice translation for virtual meetings, in-person conversations, and customer-facing touchpoints via API, empowering teams to collaborate anywhere without language barriers.
Jarek Kutylowski, Founder & CEO of DeepL said: "Today, we reach another frontier in translation: real-time, spoken communication. Our mission has always been to break down language barriers and we've now overcome one of the biggest of all. DeepL Voice-to-Voice allows everyone to speak naturally in their own language without the friction or cost of interpreters. We're fusing world-class voice models with the gold-standard translation AI we've been pushing to new heights. Now, expertise is all that counts, not language."
DeepL Voice: Real-Time Communication Across Platforms
DeepL Voice is built to overcome one of the critical language barriers remaining in organizations - spoken translation, whether in person or virtually. The DeepL Voice-to-Voice product suite includes:
- Voice for Meetings: Provides real-time translation in platforms like Microsoft Teams and Zoom, allowing participants to speak their native language while others hear it in theirs. (Early access programme in June, registration now open).
- Voice for Conversations (Mobile & Web): Voice for Conversations now extends beyond mobile, enabling a true multi platform experience that can be deployed in environments where installing apps is not practical or allowed. (Now generally available).
- Group Conversations: Facilitates multilingual exchanges in training, coaching, and workshop settings, with participants joining instantly through a QR code. This enables frontline workers to maintain shared understanding during hands-on interactions with multiple speakers. With multi device access, participants can receive simultaneous voice translation in real time. (Generally available April 30).
- Voice-to-Voice API: Enables businesses to integrate DeepL's voice translation directly into their own internal applications and customer-facing tools, such as their contact center. (Early access programme ongoing, registration now open).
- Customization with spoken terms: New quality optimization capabilities in DeepL Voice help ensure specific terminology is captured, transcribed, and translated more accurately in real time, including industry specific terms, product and company names, and given names, even when speech is fast or highly technical. As part of this, DeepL translation glossaries will be integrated into DeepL Voice so users can standardize key terminology across conversations. (Generally available on May 7).
DeepL is also making its existing voice-to-text technology more accessible with small teams being able to now purchase DeepL Voice directly online. This self-serve model allows businesses to start a free trial and deploy voice translation immediately to test before expanding.
The launch also introduces support for a broad range of languages for DeepL Voice, including all 24 official EU languages, alongside Vietnamese, Thai, Arabic, Norwegian, Hebrew, Bengali, and Tagalog. The total number of languages for DeepL Voice now stands at over forty.
In blind evaluations, conducted independently by Slator and commissioned by DeepL, DeepL Voice was consistently chosen by professional experts: 96% of linguists preferred DeepL Voice over the native translation solutions provided by Google, Microsoft, and Zoom, citing superior fluency and contextual accuracy. DeepL Voice for Zoom and DeepL Voice for Microsoft Teams achieved exceptional quality scores of 96.4/100 and 96.3/100, respectively, significantly outperforming competing platforms.
Yoichi Okuyama, Head of DX System Department at Pioneer, added: "Relying solely on English proficiency for global collaboration often slowed us down, as team members hesitated to contribute complex ideas. By implementing DeepL Voice, we've removed that friction and created a more inclusive environment where everyone can speak confidently in their native language. This shift has helped accelerate our business processes; with barriers removed, we've seen more active participation and faster decision-making across our global teams. It's transformed translation from a technical necessity into a key enabler for speed and efficiency."
Launching the next generation DeepL Translator platform
Alongside the Voice launch, DeepL is evolving its core Translator into the next-generation DeepL Translator platform, creating the end-to-end translation infrastructure for modern enterprises. DeepL is addressing the inefficiencies of traditional translation management, which often relies on slow, rigid and manual coordination that is very expensive for businesses.
"Global businesses no longer have a translation problem; they have an operating model problem, with today's language solutions often being too slow to scale and a costly drag on growth for businesses," added Jarek. "We're bringing translation and language fully into the AI age. By centralizing translation operations in an AI-first, multilingual platform, every team can access fast, high-quality translations without being held back by legacy tools or relying on expensive third-party language services."
With its new Translator platform, DeepL is tackling key pain points in enterprise translation operations.
- Translation Flow: Translation no longer slows work down or sits in separate tools. Content moves through existing systems and is translated instantly, with the right terminology and tone applied automatically. Every team works from the same voice, without extra steps or manual coordination.
- Translation Quality Assessment: Teams can see exactly how reliable a translation is, with an evaluation criteria highlighting anything that might need attention. Instead of guessing, teams know when content is ready to use and when it needs a second look.
- Ongoing improvements: Edits can be made directly in the product, with full control over the final output. Every correction is learned from, so translations continuously improve over time, adapting to each business as team members work.
By removing friction across the translation process, DeepL's Translator platform extends high-quality translation capabilities beyond a single function and into the hands of teams across the business, directly within their day-to-day workflows.
Geoffrey Wright, Global Solution Owner - GenAI and Digital Experience at Mondelēz International recently highlighted the impact of this shift: "At Mondelēz, we don't settle for slow—on the road or in our workflows. Our old translation process was like driving on a flat tyre, but DeepL is full service at 100 mph. By embedding their Language AI, teams like M&A and Legal are handling sensitive documents with top speed and total confidentiality. When you make the impossible look that easy, word travels fast; we've seen adoption accelerate across the entire organization."
About DeepL
DeepL is a global AI company building the language infrastructure that powers global business. More than 200,000 business teams and millions of individuals use DeepL's Language AI platform to communicate globally, collaborate and operate across languages in real time. By combining breakthrough AI models with enterprise-grade security and privacy, DeepL enables organizations to work seamlessly across markets and cultures. Founded in 2017 by CEO Jarek Kutylowski, DeepL now has more than 1,000 employees and is backed by leading investors including Benchmark, IVP and Index Ventures. Learn more at www.deepl.com.
SOURCE DeepL
https://www.prnewswire.com/apac/news-releases/deepl-unveils-real-time-spoken-translation-breaking-the-next-language-barrier-with-voice-to-voice-302744523.html
#metaglossia
#metaglossia_mundus

"Léon XIV appelle les universitaires à réconcilier science, foi et responsabilité
... Léon XIV a insisté sur la vocation particulière des universités catholiques: devenir de «véritables communautés de vie et de recherche», capables de promouvoir une fraternité intellectuelle et humaine. Citant le Pape François, il a rappelé que leur mission consiste à favoriser «une authentique culture de la rencontre», fondée sur le dialogue entre les cultures et la quête commune de la vérité.
Retrouver le sens de la vérité dans un monde fragmenté
Dans un contexte où «beaucoup dans le monde semblent perdre leurs repères spirituels et éthiques, se retrouvant prisonniers de l’individualisme, de l’apparence et de l’hypocrisie», l’Université est, par excellence, selon le Saint-Père, un «lieu d’amitié, de coopération, mais aussi d’intériorité et de réflexion». S’attardant ensuite sur ses origines qui remontent au Moyen Âge, le Pape a noté que «ses fondateurs lui ont donné pour objectif la Vérité». Aujourd’hui encore, a-t-il continué, «professeurs et étudiants sont appelés à se donner comme idéal et, en même temps, comme mode de vie, la recherche commune de la vérité.» Reprenant ensuite les mots de saint John Henry Newman, Léon XIV a déclaré aux 8000 participants à la rencontre que «tous les principes vrais regorgent de Dieu, tous les phénomènes conduisent à Lui». Le Pape a également souligné la complémentarité entre foi et science, s’appuyant sur Lumen fidei, de son prédécesseur: la foi, loin de freiner la recherche, «élargit les horizons de la raison» et nourrit l’esprit critique.
Sur le «magnifique» continent africain, la recherche est particulièrement mise au défi de s’ouvrir à des perspectives interdisciplinaires, internationales et interculturelles, a expliqué le Saint-Père. Il y a donc un «besoin urgent de repenser la foi au sein des réalités culturelles et des défis actuels, afin d’en faire ressortir la beauté et la crédibilité dans les différents contextes, en particulier ceux qui sont le plus marqués par les injustices, les inégalités, les conflits, la dégradation matérielle et spirituelle.» Pour l’évêque de Rome, la «grandeur d’une nation ne peut se mesurer uniquement en fonction de l’abondance de ses ressources naturelles, ou de la richesse matérielle de ses institutions.»
“L’Afrique peut contribuer de manière fondamentale à élargir les horizons trop étroits d’une humanité qui a du mal à espérer.”
Face aux défis du numérique et de l’intelligence artificielle, le Successeur de Pierre a mis en garde contre les effets d’une numérisation croissante des sociétés, en particulier en Afrique, où les enjeux économiques et environnementaux sont déjà sensibles, alertant sur le risque d’un «remplacement progressif de la réalité par sa simulation». Dans des environnements numériques conçus pour capter l’attention et influencer les comportements, la relation humaine pourrait être réduite à une simple interaction fonctionnelle. «Lorsque la simulation devient la norme, la capacité humaine de discernement est diminuée […] la réalité devient facultative et l’humain gouvernable par des systèmes invisibles», a-t-il averti. Face à cette transformation, il a appelé à une formation humaniste solide, capable de décrypter les logiques économiques et les rapports de pouvoir intégrés dans ces technologies...."
Léon XIV appelle les universitaires à réconcilier science, foi et responsabilité - Vatican News https://www.vaticannews.va/fr/pape/news/2026-04/universite-pape-foi-savoir-intelligence-artificielle-cameroun.html
#metaglossia
#metaglossia_mundus

"Ce 16 avril, nous fêtons les 100 ans de la naissance d’André Goosse. Moins connu du grand public que son beau-père Maurice Grevisse, ce grammairien belge a pourtant façonné "Le Bon Usage", la bible mondiale du français. À cette occasion, Anne-Catherine Simon, linguiste à l’UCLouvain, revient sur l'héritage de ces deux géants.
Par
Alain Nassogne
Si vous ouvrez une grammaire pour trancher un accord épineux, il y a de fortes chances que vous consultiez l'œuvre de deux Belges. Maurice Grevisse et André Goosse sont les architectes du Bon Usage, une institution née en 1936 qui fait encore autorité de Paris à Kinshasa, jusqu'au sein de l'Académie française.
La méthode Grevisse : L'usage avant la règle
Contrairement aux idées reçues, la grammaire "Grevisse-Goosse" n'est pas un code de lois figé. Sa force ? L'observation. " Maurice Grevisse se donnait comme mot d’ordre d’observer l’usage avant de juger ou d’établir les règles ", explique Anne-Catherine Simon.
Pour ces grammairiens, le "bon" français se niche dans la plume des écrivains et écrivaines qui maîtrisent admirablement la langue. C'est en analysant comment la grammaire est réellement appliquée dans les œuvres littéraires que Grevisse a produit une description vivante, révisée sans cesse au fil de ses 11 éditions personnelles.
Le Bon Usage : une histoire de famille
L'histoire du Bon Usage est aussi une affaire de famille. Arrivant à la fin de sa vie, Maurice Grevisse a désigné un successeur qu'il connaissait parfaitement : André Goosse, qui n'était autre que son gendre.
Pour Goosse, déjà renommé, reprendre le flambeau fut un honneur immense. Sa mission ? Continuer à donner vie à l'ouvrage. " La langue étant vivante, elle évolue. Chaque année, de nouveaux usages prennent la place d'usages plus anciens ", souligne la linguiste. C'est ainsi que l'œuvre est devenue ce que l'on appelle aujourd'hui la grammaire "Grevisse-Goosse".
Pourquoi les Belges sont-ils de meilleurs grammairiens ?
Il peut sembler paradoxal que les plus grands référents du français soient belges. Pour Anne-Catherine Simon, cela tient à une forme d'humilité géographique : L'absence de certitude. Contrairement à certains locuteurs en France, les Belges n'ont pas cette " certitude intérieure " de pratiquer naturellement le français parfait. Cette position les pousse à être des observateurs plus attentifs, plus précis et plus fouillés. Résultat : leurs descriptions font autorité, même pour les institutions françaises les plus prestigieuses.
Le "Grevisse" face au "Bescherelle"
Tout le monde connaît le Bescherelle, mais les deux ouvrages ne boxent pas dans la même catégorie. Si Louis-Nicolas Bescherelle est né en 1802 et a publié son célèbre manuel dès 1842, son approche est très différente :
Le Bescherelle : Concis, abrégé, il est l'allié des élèves de l'école primaire.
Le Bon Usage : Monumental et complet, il est l'outil indispensable des spécialistes et des professionnels de la langue.
Vers une 17e édition 100% connectée ?
Depuis 1936, Le Bon Usage a connu 16 éditions, la dernière datant de 2016. Le monde de la linguistique attend désormais la 17e édition avec impatience. Le défi de cette nouvelle version ? Être totalement consultable en ligne pour devenir accessible au plus grand public, tout en restant la référence ultime des experts."
https://share.google/xxbI5edc77ruP3LrA
#metaglossia
#metaglossia_mundus

"... transformer la diversité culturelle en une grâce pour le vivre-ensemble.
Jean-Paul Kamba, SJ – envoyé spécial
Dans le contexte camerounais où la soif de paix et de cohésion n'a jamais été aussi ardente, cette visite apostolique s'annonce comme un tournant décisif. Le père Bassoumboul livre une réflexion profonde sur la portée de cette visite et rappelle que l'unité n'est pas un simple slogan, mais un engagement quotidien à l'école de l'Évangile et des grandes «figures missionnaires de notre terre»...
Dans un pays marqué par des diversités culturelles et parfois des tensions internes, en quoi la présence du Successeur de Pierre constitue-t-elle un «sacrement de l'unité» pour tous les Camerounais, au-delà des clivages religieux ?
La diversité culturelle implique pluralité. Celle-ci est une invitation à l’unité. Pour cela, l’on pourrait dire que le défi de la diversité culturelle est la cohésion, la conscience de l’interdépendance. À ce titre, la diversité culturelle est une belle richesse à bien piloter.
L’histoire biblique de l’humanité présente la fraternité comme un lieu de tensions, souvent pathétiques. Je citerais les fratries de Caïn et Abel, Ésaü et Jacob, Joseph et ses frères, etc. Même entre les douze Apôtres, il y a eu des épisodes de tensions internes. Mais, dans le même temps, ces récits de fraternités tendues sont riches d'enseignement sur les procédés de reconstruction et de réconciliation. C’est l’attitude de Jacob envers son frère, animé d’une rage meurtrière contre lui en Gn 33. Je suis aussi toujours fasciné par les larmes de Joseph en Gn 45. Je les interprète très souvent comme l’eau qui efface les torts subis pour reconstruire la fraternité et l’unité familiale.
Certains ont estimé que les tensions que traverse le Cameroun en ce moment étaient un motif pour que le Saint Père n’y aille pas. Or, cet argument est paradoxalement une raison suffisante pour sa venue. Comme Successeur de Pierre, il vient nous rappeler que la beauté de la vie en famille est dans la paix véritable, la force d’une nation, comme le Cameroun, dans son unité. À cet effet, comme Jacob, Joseph, etc., les uns et autres devraient s’atteler à reconstruire l’unité nationale. La prière de Jésus à son Père: « Qu’ils soient un » (Jn 17,21), l’intention principale de cette visite apostolique du Pape Léon XIV, sollicite l’engagement de tous à être devenir «témoins désarmés et désarmants de la paix qui vient du Christ».
Il est aussi important de relever que le 6 décembre dernier, le Comité directeur des imams du Cameroun lui a rendu visite pour lui dire combien leurs communautés seraient heureuses de le recevoir au Cameroun. Ce geste, fort éloquent, nous rappelle qu’en Dieu la diversité culturelle se révèle comme une grâce pour promouvoir le vivre-ensemble, l’unité nationale, la paix et la solidarité."
Le Pape au Cameroun, un «sacrement de l’unité» pour une nation en quête de paix - Vatican News https://share.google/r2FFWpznqIlCPqrqp
#metaglossia
#metaglossia_mundus

"TransPerfect Acquires Studio Emme
News provided by
TransPerfect
Apr 15, 2026, 09:05 ET
Key Takeaways
TransPerfect has acquired Rome-based post-production and dubbing studio Emme SpA.
The acquisition expands TransPerfect Media's global footprint of studios.
Studio Emme's leadership team will remain on following the transaction.
ROME and NEW YORK, April 15, 2026 /PRNewswire/ -- TransPerfect, the world's largest provider of language and AI solutions for global business, today announced it has acquired Studio Emme SpA, a Rome-based audio-visual post-production and dubbing facility. Studio Emme will operate as part of TransPerfect Media, TransPerfect's media and entertainment division. Financial terms of the transaction were not disclosed.
Founded in 1982 by Giuseppe Morucci, Studio Emme has been a cornerstone of Italy's entertainment industry for more than 40 years, providing dubbing and post-production services across film, television, and commercial projects. Clients include major broadcasters and studios in Italy, along with international distribution partners. Studio Emme is a member of the Trusted Partner Network, reflecting content security practices that meet the stringent requirements of leading studios and streaming platforms.
"Joining TransPerfect positions Studio Emme for international growth while preserving what has made us successful," said Marianna Morucci, CEO of Studio Emme. "With TransPerfect's global reach and advanced technology, we can grow our business and service more clients."
Studio Emme will continue operating from its Rome headquarters. The company's existing leadership team will remain in place following the acquisition.
TransPerfect President and Co-CEO Phil Shawe commented, "Studio Emme brings decades of expertise and a strong reputation in Italian audiovisual production. We're excited to welcome the Studio Emme team into TransPerfect and collaborate closely to serve our entertainment clients."
For more company news and announcements, please visit the TransPerfect News & Press Center at www.transperfect.com/about/news-and-press.
About Studio Emme SpA
Studio Emme SpA is a Rome-based dubbing, mixing, and audiovisual post-production facility serving the global entertainment industry. Founded in 1982 by Giuseppe Morucci, the company delivers end-to-end services for film, television, streaming, and commercial content, combining high-quality output with technical excellence, reliability, and state-of-the-art technology. Studio Emme is a member of the Trusted Partner Network (TPN), a Motion Picture Association initiative focused on content security. For more information, visit www.studio-emme.tv.
About TransPerfect Media
TransPerfect Media elevates storytelling for audiences around the world with media creation and globalization solutions delivered through a network of company-owned and operated studios in 19 countries. TransPerfect Media's hybrid model combines cutting-edge AI technology with creative expertise, all managed in its cloud-based content creation platform, enabling simple localization and distribution.
By combining high-level talent with Dolby Atmos and Dolby HDR projection capabilities, as well as services that include image and sound post-production, subtitling, dubbing, accessibility, voiceover, multi-platform delivery, preservation, and restoration, TransPerfect Media is where boutique expertise meets global scale and excellence to help you tell your story—in any language. To find out more, visit www.transperfect.com/media.
About TransPerfect
TransPerfect is the world's largest provider of language and AI solutions for global business. From offices in over 150 cities on six continents, TransPerfect offers a full range of services in 200+ languages to clients worldwide. More than 6,000 global organizations employ TransPerfect's GlobalLink® technology to simplify the management of multilingual content. With an unparalleled commitment to quality and client service, TransPerfect is fully ISO 9001 and ISO 17100 certified. TransPerfect has global headquarters in New York, with regional headquarters in London and Hong Kong. For more information, please visit our website at www.transperfect.com."
https://www.prnewswire.com/news-releases/transperfect-acquires-studio-emme-302742314.html
#metaglossia
#metaglossia_mundus

""C’est une profonde joie de me trouver au Cameroun, souvent qualifié d’“Afrique en miniature” en raison de la richesse de ses territoires, de ses cultures, de ses langues et de ses traditions. [….] Ma visite exprime l’affection du successeur de Pierre pour tous les Camerounais." C’est en français que Léon XIV s’est exprimé en arrivant au Cameroun. Devant les dirigeants du pays d’Afrique centrale, le 267e pape a une fois de plus recouru à la langue de Molière, qu’il connaît, comprend et lit de façon relativement fluide. Cette tournée de onze jours en Afrique est ainsi l’occasion pour l’Américano-péruvien de faire appel à sa maîtrise de langues variées. Pour sa première étape, en Algérie, il a prononcé ses discours principalement en anglais, sa langue maternelle, avec une traduction assurée par un interprète au fur et à mesure en arabe pour son auditoire. Exception faite cependant de ses deux prises de parole devant la communauté catholique à Alger et à Annaba, où il a parlé en français – une langue qui unit la communauté locale métissée – et sans traduction.
Au Cameroun aussi, le successeur de Pierre alternera le français et l’anglais. Il utilisera cette dernière langue à Bamenda dans le nord du pays, une zone anglophone où il se rendra demain jeudi. Au total, il doit prononcer sept interventions pendant son séjour camerounais. En Angola, le troisième pays qu’il visitera, le Pape parlera portugais, une langue qu’il a apprise en voyageant notamment au Brésil lorsqu’il était prieur général des Augustins. En pratiquant leur langue au fil de ses six interventions, il "fera la joie des Angolais", a glissé le directeur du bureau de presse du Saint-Siège, Matteo Bruni, en présentant le programme de ce premier voyage en Afrique. Enfin, dans ses sept discours en Guinée équatoriale, le pontife passera à une autre langue qui lui est chère : l’espagnol, qu’il a pratiqué pendant deux décennies au Pérou, et qu’il a même employé au balcon de la basilique Saint-Pierre le jour de son élection, en signe d’attachement pour son pays de cœur.
Cinq langues pour un pape polyglotte
Anglais, français, portugais, espagnol… quatre langues coloreront donc cette tournée internationale. Quatre ? C’est sans compter l’italien, que Léon XIV a spontanément utilisé pour parler au côté de l’imam de la grande mosquée d’Alger lundi. Cinq langues donc pour un pape polyglotte, qui n’hésitait pas à lancer "salut soldat !" en turc lors de son voyage en Turquie en novembre dernier. Manifestement enclin à communiquer avec des cultures différentes, le nouveau pape a d’ailleurs repris la tradition des salutations de Noël et de Pâques dans de nombreux idiomes, dont l’arabe et le chinois. Et l’on raconte souvent qu’il a été repéré en train d’apprendre l’allemand sur Duolingo à 3h du matin."
Anna Kurian - publié le 15/04/26
https://fr.aleteia.org/2026/04/15/lafrique-accueille-un-pape-polyglotte/
#metaglossia
#metaglossia_mundus

"English remains the lingua franca of scholarly publications, but other languages are gaining ground
By Martin LaSalle Apr 14th, 2026
Drawing on 88 million articles across all disciplines, an UdeM study examines the global evolution of language use in academic publishing between 1990 and 2023.
In 2023, about 85 per cent of the roughly five million articles indexed in major global databases covering the natural, medical and social sciences were written in English. In 1990, the proportion was considerably higher: 94 per cent.
The nine percentage-point increase in the use of other languages over the past 30 years represents a modest but significant shift in the landscape of scholarly communication, and a step toward greater equity, diversity and inclusion in global knowledge production.
That's what Université de Montréal PhD student Carolina Pradier and postdoctoral fellow Lucía Céspedes reveal in a new study directed by Vincent Larivière, a professor in UdeM's School of Library and Information Science.
Published in the Journal of the American Society for Information Science and Technology, the study is a probing look into the many languages used in nearly 88 million articles and conference proceedings, as well as approximately 1.48 billion references cited in them, since 1990.
Cited works almost all in English
While the relative prevalence of English in scholarly publications has eroded over the years, with researchers gradually publishing more in other languages, the overall volume of articles published in English has not declined at all — quite the contrary.
Indeed, English-language articles have more than quintupled, from about 877,000 in 1990 to nearly 5 million in 2023, the co-authors note in their study.
The dominance of English is especially evident in the analysis of citations. “While publications in English account for 85 per cent of the analyzed corpus, 98.89 per cent of the references cited were in English,” said Pradier.
Even in the countries that publish the least in English—Indonesia, Brazil, Ecuador and Angola –English-language references accounted for at least 92 per cent of all references cited.
“On the one hand, there is the language in which researchers write their articles, and on the other there are the studies they rely on to advance their research,” explained Pradier. “Non-English-speaking researchers can now produce work in their own language, but they must still engage with literature that is overwhelmingly written in English.”
The rise of Indonesian
The authors highlight the case of Indonesian. Virtually absent from citation databases in the early 1990s, it is now used in 2.69 per cent of global scholarly publications, surpassing French and German.
According to Pradier, this breakthrough is no accident.
“In 2014, the Indonesian government issued a decree requiring that all scholarly publications be made freely accessible online, which led to the widespread adoption of Open Journal Systems, an open-source, free-to-use journal publishing platform,” she said.
According to Pradier, this is a good example of how national policies on linguistic diversity can change the publishing landscape.
“The rise of publications in Indonesian essentially started from scratch,” she said. “By contrast, Spanish- and Portuguese-language publications in Latin America grew thanks to existing platforms such as Latindex, SciELO and Redalyc, which allowed the region to build a largely self-sufficient ecosystem for knowledge dissemination.”
French in freefall
In contrast to the rising share of publications in Indonesian, Spanish and Portuguese, the use of French has fallen sharply. Once the second most common language, with a 2.14 per cent share of indexed articles in 1990, French slumped to 1.06 per cent by 2023, well behind these three languages.
German has also declined, slipping from 1.38 per cent to 1.23 per cent over the same period.
Pradier attributes these changes to structural factors, noting that the main francophone research communities—France and Quebec—are well integrated into dominant publishing networks. This gives researchers the resources to publish in English and access English-language publications.
By contrast, more peripheral countries, less exposed to pressures to publish in high-profile journals, are developing more independent networks.
“Evaluation policies have a decisive influence,” explained Pradier. “In Quebec, the focus on publishing in high-impact journals encourages publishing in English, whereas in Latin America, greater value is placed on publishing in the national language.”
One exception to the dominance of English is French-language journals in the humanities and social sciences, where fewer than half the citations are to English-language sources. Pradier attributes this “pocket of resistance” to the localized nature of the research topics and the strength of francophone networks in these disciplines.
Blind spots in knowledge
Beyond the numbers, the study highlights the negative consequences of English dominance.
For example, researchers whose working language is not English face tangible costs, including more time devoted to writing, higher rejection rates and stress. This can lead to what the study’s authors call a “survivorship bias,” where only those with sufficient English proficiency succeed in establishing an international research career.
More broadly, English dominance harms knowledge production. “It leads to an epistemic loss as entire swaths of global knowledge production written in undervalued languages remain invisible to the international community,” Pradier said. “Publishing exclusively in English creates enduring blind spots.”
The researchers have two recommendations for policymakers: implement open-source, no-cost accessible journal publishing platforms, and reform current evaluation systems to make them less dependent on citation counts.
“If we focus just on number of citations, we'll continue to encourage the use of English,” Pradier concluded. “Evaluation should also take into account quality and local relevance.”"
- https://nouvelles.umontreal.ca/en/article/2026/04/14/l-anglais-demeure-la-lingua-franca-de-la-science-mais-d-autres-langues-s-imposent
#metaglossia
#metaglossia_mundus

"Voice actors fight to save their livelihoods and local cultures from Hollywood’s AI push
Voice AI tools are quickly replacing voice-over and dubbing artists, raising concerns not only about jobs but also loss of cultural relevance in non-English-speaking nations.
Global voice actors are mobilizing to protect their livelihoods and personality rights as studios replace human performances with AI dubbing.
Advocates warn that AI lacks the local nuance and emotion required to maintain a country’s unique cultural sovereignty.
Some actors can now earn significantly higher rates by intentionally licensing their voices for AI cloning and enterprise tools.
Hardly anyone would recognize Fabio Azevedo if they passed him on a street in São Paulo. When he begins to speak, however, everyone knows who he is: the voice of some of the best-known characters in Hollywood films dubbed in Portuguese, including Doctor Strange in the Marvel movies, and the Beast in the live-action film Beauty and the Beast.
Azevedo now has a role that may be his most challenging yet: protecting voice-over actors in Brazil from artificial intelligence. As studios, production companies, and streaming platforms increasingly turn to AI for voice-overs and to dub English-language content into local languages, more than 2 million full-time and part-time voice actors worldwide stand to lose their livelihood and the rights to their voice.
We make foreign content sound Brazilian with our Brazilian idiosyncrasies; with AI, we lose that.”
Fabio Azevedo, voice actor and president of the Brazilian Association of Dubbing Professionals
“All the major players have started dabbling in AI for dubbing,” Azevedo, who began acting when he was 13, told Rest of World. Voice actors are not only losing jobs, their voice is also being used to train the AI models that are replacing them, often without their knowledge or compensation.
“With new AI-generated voices, I will be out of a job even though I am the one providing the input,” said Azevedo, who is president of the Brazilian Association of Dubbing Professionals. “On top of that we will have a cultural pasteurization. We make foreign content sound Brazilian with our Brazilian idiosyncrasies; with AI, we lose that.”
AI voice technology, which includes text-to-speech and voice cloning that can replicate a person’s voice, is being adapted for virtual assistants, customer service chatbots, public announcements, and, increasingly, commercials, video games, television shows, and films. San Francisco-based ElevenLabs and Cartesia, as well as Israel’s DeepDub, are among the major players, with more firms entering the space as the technology advances and gets better at lip sync and the flat delivery that audiences have long complained about.
“Please leave us a way to make a living”
Azevedo isn’t the only one fretting about job loss. After the Screen Actors Guild–American Federation of Television and Radio Artists strike in 2023 won protections against AI, including the right to approve how their voices are used, actors and voice actors elsewhere are mobilizing against AI.
Mexico recently banned the use of AI in dubbing and unauthorized use of voice by AI, following a campaign by voice actors. Azevedo’s association has proposed similar protections in Brazil’s AI bill, while in South Korea, voice actors have proposed clauses to limit AI use, and have all citizens’ voices protected from unauthorized AI training and potential criminal misuse.
In China, several voice actors recently posted statements on social media condemning the use of their voices in AI-generated works. “Please leave us a way to make a living,” voice actor Nie Xiying said on Weibo, sharing a statement about AI copyright infringement.
A poster of “The Fantastic Four” announces the Hindi release. Marvl
The rise of streaming platforms has sparked a growing appetite for content dubbed in local languages worldwide. AI is increasingly used to deliver content cheaply and quickly, and voice actors are beginning to push back, even though they don’t have strong unions, Rafael Grohmann, an assistant professor of media studies at the University of Toronto, told Rest of World.
“Particularly in the Global South, they don’t have the economic power, the discursive power, or the institutional support to stop production like the Hollywood unions did,” Grohmann said. “So they are forming collectives, and releasing manifestos, to intervene in how generative AI is used, managed, challenged and refused in their workplace.”
A loss of “cultural sovereignty”
Grohmann built a tracker to map such unions, listing more than 100 movements by creative workers in about 25 countries including Turkey, Argentina, Chile, India, and South Korea. Voice actors, who lack the visibility of actors, are among the hardest hit, and the impact goes beyond job loss to the issue of “cultural sovereignty,” he said.
“In countries like Brazil or Mexico, the oral culture is very strong, and you really need a human to translate for the local context,” he said. “So in Brazil, Peter becomes Pedro. The voice actors have a huge fandom, and they become more famous than the Hollywood actors in the film.”
International markets are critical for Hollywood, generating about two-thirds of revenue. Much of this comes from dubbing films and TV shows in local languages. Streaming platforms such as Netflix and Amazon Prime are also adding more language options for their content to increase their share of foreign markets.
Last year, Amazon Prime announced it would add “AI-aided dubbing on licensed movies and series that would not have been dubbed otherwise.” After viewers ridiculed some AI-generated English and Spanish dubs of anime titles, including the Banana Fish series and the movie No Game No Life: Zero, some of these were removed.
In a country like India, with more than a dozen official languages, commercials, documentaries, and audio books were a gold mine for voice actors. Not anymore.
“These jobs are being annihilated by AI,” Ganessh Divekar, general secretary of the Association of Voice Artists of India, told Rest of World. Recently, Divekar — the voice of Hollywood star Pedro Pascal in the Marvel franchise in Hindi, and Luigi in the Cars films dubbed in Hindi — noticed his voice had been mixed with the voice of another actor using AI, for a film. But there was nothing he could do.
“An entirely new category of high-value work”
Advances in voice cloning — which allows the texture of one voice actor to be used for the performance of another — mean that professionals like Divekar may no longer be required to dub in different languages, beyond providing the material for AI training.
“There is no way to prevent them from using my voice however they wish,” he said. “Earlier, when we were called in for a job, we would not ask what our voice would be used for. Now, we are telling members to ask what it will be used for, and ask for more money when signing perpetuity contracts, because the voice becomes their property in perpetuity and they can do anything with it, including train AI.”
Courts in India have recognized that a person’s voice is “an intrinsic part of their identity and falls within the right to privacy,” and that unauthorized commercial use can violate their personality rights, said Anamika Jha, a media and entertainment lawyer, and the founder of law firm Attorney for Creators. But these provisions do not fully extend to the use of voice data in training AI systems, she told Rest of World.
Earlier, I was a voice; now, I have to say I’m a human voice to distinguish myself from AI.”
Ganessh Divekar, voice actor and general secretary of the Association of Voice Artists of India
“A voice can be cloned and reused indefinitely without further consent or payment,” Jha said. There are also serious reputational concerns. “A cloned voice may be used in contexts that the artist would never endorse, including political messaging, controversial advertising, or explicit content … [and in] impersonation and fraud.”
With appropriate protections and licensing agreements, there can be a big opportunity, too. Voices, a voice solutions company with over 100,000 registered voice actors who can speak in more than 100 languages, now offers voice data and voice AI to enterprise clients. Voice AI jobs pay up to 85 times as much as traditional voice-over work, Julianna Jones, the company’s director of talent success, told Rest of World.
All the voice data on the platform is “intentionally captured” from consenting actors or contributors, and every voice AI agreement includes consent to voice cloning, licensing, and legal protections that ensure their rights and compensation are preserved “even in regions without regulations,” Jones said.
Get The Global, our (free) newsletter
Sign up for our weekly newsletter and we’ll send you our latest stories, insights from our staff, what we’re reading, and more. A world of tech, right in your inbox.
Email
“This opens up an entirely new category of high-value work,” she said. “Actors retain a say in how their voice is used, stay actively involved as the voice evolves, and continue earning as the technology improves.”
For voice actors such as Divekar, however, the fight to retain control over their voice and earn a living continues.
“Earlier, I was a voice; now, I have to say I’m a human voice to distinguish myself from AI,” he said."
By Rina Chandran
15 April 2026
https://restofworld.org/2026/ai-voice-actors-hollywood-dubbing/
#metaglossia
#metaglossia_mundus

"Translation Grants for Publication of Lithuanian literature
Your April Funding Calendar Just Dropped
April is one of the busiest months in the funding calendar. Dozens of international donors are accepting applications right now — but windows are closing fast. Here's what's open and how to get your proposal in on time. DOWNLOAD!
Deadline: 15-May-26
The Translation Grants Programme supports the translation, publication, and international dissemination of Lithuanian literature. Managed by the Lithuanian Culture Institute and funded by the Lithuanian state, the programme helps publishers in Lithuania and abroad bring Lithuanian authors, cultural works, and children’s books to global audiences.
You didn't start your NGO to spend half your time hunting for funding
Premium Membership handles the research so you can focus on what you do best — creating change
What is the Translation Grants Programme?
The Translation Grants Programme is a funding initiative that promotes the global translation and publication of Lithuanian literature.
Its purpose is to help publishers translate and publish Lithuanian works in other languages, making them accessible to readers worldwide. The programme supports both fiction and non-fiction and covers a wide range of literary genres.
What Does the Programme Support?
The programme funds projects that translate, publish, and promote Lithuanian literature internationally.
You didn't start your NGO to spend half your time hunting for funding
Premium Membership handles the research so you can focus on what you do best — creating change
Eligible literary categories include:
Prose
Poetry
Drama
Documentary writing
Children’s literature
Illustrated books
Graphic novels
Fiction and non-fiction by Lithuanian authors
Works by authors of Lithuanian descent
Books related to Lithuanian culture, history, and artists
This broad scope makes the programme valuable for publishers interested in literary translation, cultural publishing, and international rights development.
Why This Programme Matters
The programme has been a major tool for promoting Lithuanian literature globally.
Key impact:
Nearly 600 translated books supported
Published in 43 languages
Operated successfully over several decades
Annual funding allocation of EUR 100,000
This makes it one of the most important public funding opportunities for publishers seeking support for translated literature from Lithuania.
You didn't start your NGO to spend half your time hunting for funding
Premium Membership handles the research so you can focus on what you do best — creating change
Who is Eligible?
The programme is open to publishers and publishing-related legal entities.
Eligible applicants include:
Publishers based in Lithuania
Publishers based outside Lithuania
Other legal entities engaged in publishing activities outside Lithuania
To qualify, applicants should plan to publish a translated work of Lithuanian literature in their own country or market.
How Funding Works
Funding is awarded through a competitive application process.
You didn't start your NGO to spend half your time hunting for funding
Premium Membership handles the research so you can focus on what you do best — creating change
Call frequency:
Calls are published at least twice a year
Funding structure depends on publication timing:
1. If the book is published in the same year as the grant award
A one-stage agreement is signed
The full grant amount is paid after project completion
Payment is made after:
Final reports are submitted
Required documentation is approved
Six copies of the publication are delivered
2. If the book will be published in a later year
A two-stage agreement is used
Up to 60% of the grant is paid first
The remaining balance is paid after:
Final reporting
Submission of required documents
Delivery of six publication copies
How to Apply
Applicants should prepare all materials before starting the application.
Important note:
Incomplete applications are not saved
It is best to collect all documents in advance
Required application materials:
A short presentation of the publishing house
A list of translations published in the last two years
Information on distribution channels and partners
A description of planned marketing activities
A justification of the project’s relevance
Details on the translator’s qualifications
The translator’s motivation for the project
Tips for a Strong Application
To improve your chances:
Show why the selected work is relevant for your market
Highlight strong distribution and sales channels
Include a clear marketing and promotion plan
Demonstrate the translator’s experience and literary fit
Explain how the book will help expand access to Lithuanian literature internationally
Make sure all required documents are complete before submission
Common Mistakes to Avoid
Starting the form without all materials ready
Submitting an incomplete application
Giving weak details about distribution strategy
Not clearly explaining the project’s market relevance
Providing limited information about the translator
Ignoring promotion and dissemination planning
Frequently Asked Questions (FAQs)
1. What is the Translation Grants Programme?
It is a funding programme that supports the translation, publication, and international promotion of Lithuanian literature.
You didn't start your NGO to spend half your time hunting for funding
Premium Membership handles the research so you can focus on what you do best — creating change
JOIN IN
2. Who manages the programme?
The programme is funded by the Lithuanian state and administered by the Lithuanian Culture Institute.
3. Who can apply?
Eligible applicants include:
Publishers in Lithuania
International publishers
Other legal entities outside Lithuania involved in publishing
4. How often are calls announced?
Calls for applications are published at least twice per year.
You didn't start your NGO to spend half your time hunting for funding
Premium Membership handles the research so you can focus on what you do best — creating change
5. What kinds of books are supported?
The programme supports:
Prose
Poetry
Drama
Documentary writing
Children’s books
Illustrated books
Graphic novels
Fiction and non-fiction related to Lithuanian authors, culture, and history
6. How is the grant paid?
Payment depends on publication timing:
Same-year publication: Full payment after completion and reporting
Later-year publication: Up to 60% upfront, with the rest after final reporting
7. What documents are required?
Applicants need to submit publishing house details, recent translation history, distribution and marketing information, project relevance, and translator qualifications/motivation.
You didn't start your NGO to spend half your time hunting for funding
Premium Membership handles the research so you can focus on what you do best — creating change
Conclusion
The Translation Grants Programme is a strong opportunity for publishers looking to bring Lithuanian literature to international readers. With support for multiple genres, regular calls, and a proven record of nearly 600 translated books in 43 languages, it offers meaningful backing for literary translation, publishing, and cultural exchange."
https://www2.fundsforngos.org/individuals/translation-grants-for-publication-of-lithuanian-literature/
#metaglossia
#metaglossia_mundus

"University of Bonn Establishes Translation Hub
New coordination office to support 36 universities in North Rhine-Westphalia (NRW)
Since the beginning of February 2026, the University of Bonn has been home to the new North Rhine-Westphalian Coordination Office for Translation Matters in Higher Education (‘Landeskoordinationsstelle für Übersetzungsangelegenheiten im Hochschulwesen des Landes Nordrhein-Westfalen’). It is developing an online platform offering sample translations, translation resources and training sessions, while serving as a central contact point for translation-related questions. The platform is scheduled to launch in late April 2026.
NRW Coordination Office for Translation Matters in Higher Education at the University of Bonn. - The Coordination Office supports 36 universities in North Rhine-Westphalia. It is developing a platform featuring sample documents and translation tools, serves as a point of contact for questions, and offers training sessions.
© Photo: Gregor Hübl / University of Bonn
Download all images in original size
The impression in connection with the service is free, while the image specified author is mentioned.
Greater orientation for international higher education
Research and teaching are carried out within international networks, as are many administrative processes. The need for reliable information in English—whether HR forms or administrative regulations—is growing accordingly. That’s where the NRW Coordination Office comes in: It seeks to pool existing resources, prevent the unnecessary duplication of work and provide centralized access to English-language documents that are relevant across universities in NRW.
During the initial setup phase, the NRW Coordination Office is mapping which English-language documents and bilingual resources, such as glossaries or terminology, are already available at NRW’s 36 public universities. This information will help set future priorities.
At the same time, a digital platform is under development, set to go live by the end of April. This will serve as the primary access point for sample translations and other materials. Universities will be able to submit translation and proofreading requests via this platform or via email.
Drawing on proven expertise
One of the reasons for establishing the NRW Coordination Office in Bonn was the strong structures already in place. The University of Bonn set up its Central Translation Service within the International Office back in 2019 as a means of reducing language barriers and strengthening its international outreach. Initially, the Central Translation Service focused on translating texts, forms and other content from German into English; a year later, it also took on the coordination of editing services for academic texts in English in collaboration with an external provider.
Today, the Central Translation Service advises staff on all language and translation issues and maintains the University’s German-English glossary and English style guide. Since 2021, its language specialists have also offered an interpreting service for key meetings and public events at the University of Bonn.
A central hub to drive synergies
A few other German states already have similar offices to coordinate translations of cross-university importance or make shared language resources available. In discussions among the universities in NRW, the idea emerged to set up a similar state-wide coordination office here. This led to an application being submitted to the Ministry of Culture and Science of NRW in collaboration with representatives of the universities and the University Rectors’ Conference. In 2025, the University of Bonn’s application was approved, with financing provided through the NRW Future Fund (Zukunftsfonds) for an initial two-year period.
Professor Birgit Ulrike Münch, Vice Rector for International Affairs, stated: “International collaboration relies on solid linguistic foundations, including in administration. With the NRW Coordination Office, we are putting in place a structure that provides concrete support to universities in North Rhine‑Westphalia.” Professor Petra M. Vogel, Prorector for Students and Junior Faculty, Diversity, and International Affairs at the University of Siegen, was also one of the earliest proponents of the project: “Experience from other German states shows that a state-wide coordination office can deliver real value in the field of higher‑education translation. There’s a key focus on connecting existing structures in a meaningful way and creating synergies. I’m very pleased that an office like this could also be set up in NRW.”
The project aims to build a fully functional platform that
- taps into synergies in the translation field and avoids the same work being done multiple times;
- expands the range of information available in English;
- supports university translators, administrative staff and researchers in implementing internationalization strategies.
Services designed to meet real needs
When the platform launches at the end of April, it plans to offer the following services:
- Translations (German to English) of documents that are relevant for all universities in NRW
- A bilingual (German/English) terminology database
- Topic-specific glossaries that can also be integrated into machine translation tools or used in the context of AI-supported translation
- Machine translations for universities that don’t have the relevant licenses themselves
- Proofreading
- Training sessions, especially on the effective use of machine translation tools
Particularly when it comes to machine translation or the use of AI in a translation context, there is growing demand for guidance. That’s why training sessions will aim to give practical tips on how these tools work, where they fall short and what else needs to be considered in practice, for example data protection requirements or established institutional terminology.
Collaboration across the network
The NRW Coordination Office will partner closely with NRW’s 36 public universities. Each institution will receive access to the platform and can use the services offered. Regular exchange formats, a newsletter and feedback channels are also in the works.
The NRW Coordination Office sees itself explicitly as a service provider and networking hub that offers support, but does not establish binding standards. The translations and terminology recommendations provided aim to offer universities guidance and complement their internal language resources.
Significance for the University of Bonn
This state-wide office further embeds the University of Bonn in the cross-institutional structures of higher education development in NRW. At the same time, the NRW Coordination Office aligns perfectly with the University’s Internationalization Strategy, which explicitly calls for the expansion of English-language information resources.
Contact:
NRW Coordination Office for Translation Matters in Higher Education at the University of Bonn: landeskoordinationsstelle.nrw@uni-bonn.de"
https://www.uni-bonn.de/en/news/069-2026
#metaglossia
#metaglossia_mundus
Sze is Building a Signature Project and Tour Focused on Poetry in Translation to Open the World of Poetry to More People
"U.S. Poet Laureate Arthur Sze Appointed for a Second Term
Release Date: 14 Apr 2026
U.S. Poet Laureate Arthur Sze Appointed for a Second Term
Sze is Building a Signature Project and Tour Focused on Poetry in Translation to Open the World of Poetry to More People
This National Poetry Month, the Library of Congress has appointed Arthur Sze to serve a second term as the nation’s 25th Poet Laureate Consultant in Poetry for 2026-2027, the Library announced today.
Sze, who lives in Santa Fe, New Mexico, was named poet laureate in September 2025 and began working to expand appreciation of poetry through his focus on translating poetry originally written in languages other than English. His newest book, “Transient Worlds: On Translating Poetry,” features translations from 13 languages and provides a personal guide to poetry in translation. The book is published today by Copper Canyon Press in association with the Library of Congress.
Sze’s first term will conclude on April 30 when he will return to the Library for a rare, special conversation with the Poet Laureate of the United Kingdom, Simon Armitage, on the art and process of writing and translating poetry. Armitage has a new translation of “Gilgamesh,” also publishing on April 14."
https://newsroom.loc.gov/news/u.s.-poet-laureate-arthur-sze-appointed-for-a-second-term/s/af95199e-5eec-4568-9b62-cc5a9a6e994f
#metaglossia
#metaglossia_mundus

"
Procès ajourné pour un problème de traduction en langue dari
14.04.2026 10h23
Le Tribunal cantonal a été obligé d'ajourner le procès du jour pour une question de traduction 8
Le Tribunal cantonal valaisan aurait dû juger mardi un Afghan pour tentative d'assassinat sur son épouse. En première instance, il avait écopé de 10 ans de prison et d'une expulsion de 15 ans de Suisse. Le procès a finalement été ajourné pour un problème d'interprète.
Le prévenu, désireux de s'exprimer dans sa langue maternelle - le dari -, comme c'est son droit le plus strict, la Cour a entamé le procès en assermentant une interprète de la région. A la deuxième question, celle-ci a admis une connaissance limitée de cette langue.
Président du Tribunal, Christophe Pralong a alors interrompu les débats, cherchant un traducteur remplaçant. Après une petite demi-heure, le TC a choisi d'ajourner le procès, n'ayant pas pu trouver la perle rare. Le fils de l'accusé, puis l'un de ses cousins se sont offerts pour traduire. Au vu de la proximité de ces personnes avec le prévenu, le TC a refusé cette solution.
'Nous essayerons de fixer au plus vite une nouvelle date. Ce dossier est (ndlr: désormais) prioritaire', a conclu Christophe Pralong.
/ATS"
https://www.lemanbleu.ch/fr/Actualite/Suisse/Proces-ajourne-pour-un-probleme-de-traduction-en-langue-dari.html
#metaglossia
#metaglossia_mundus
"Accueillir l’univers culturel et linguistique guarani : une traduction hospitalière de l’œuvre d’Augusto Roa Bastos
Welcoming the Guarani Cultural and Linguistic Universe: A Hospitable Translation of the Work of Augusto Roa Bastos
DOI: https://doi.org/10.58282/acta.21025
Augusto Roa Bastos, Yñipyru et autres textes, trad. Cécile Brochard et Joaquín Ruiz Zubizarreta, Paris : Classiques Garnier, 2024, 203 p., EAN 9782406172673.
1Dans Éloge de la traduction, Barbara Cassin évoque l’enjeu de la traduction en ces termes : « comprendre que les différentes langues produisent des mondes différents dont elles sont les causes et les effets ; et faire communiquer ces mondes en inquiétant les langues l’une par l’autre, de sorte que la langue du lecteur aille à la rencontre de celle de l’auteur1 ». C’est ce que nous proposent les éditeurs et traducteurs d’Yñipyru et autres textes.
2Dans cette œuvre publiée en 2024 aux éditions Classiques Garnier, Cécile Brochard et Joaquín Ruiz Zubizarreta nous offrent une traduction hospitalière, annotée et commentée de poèmes, de nouvelles et d’écrits critiques du plus célèbre écrivain paraguayen : Augusto Roa Bastos. Romancier, poète et dramaturge, cet auteur a été reconnu mondialement, notamment pour ces œuvres Moi, le suprême (1974) et Fils d’homme (1982). Il obtint également le très honorable prix Cervantès en 1989 qu’il envisage comme une reconnaissance à la culture riche et plurielle de son pays.
3Yñipyru et autres textes rassemble vingt-huit poèmes, trois nouvelles et deux textes critiques traduits pour la première fois, pour la plupart, en français. Il nous faut souligner d’emblée l’importance donnée à l’œuvre poétique d’Augusto Roa Bastos qui n’est encore que très peu étudiée et connue en France. La sélection des œuvres traduites est claire et pertinente. Elle se base sur deux critères : l’évidence du lien avec la langue, la culture et la cosmogonie guarani d’une part et le reflet de l’engagement sociopolitique de l’auteur, d’autre part.
4Exposée dès le seuil de l’ouvrage, dans une introduction riche et précise du point de vue du contexte géographique et sociopolitique du Paraguay et de la biographie d’Augusto Roa Bastos, la démarche des auteurs consiste à mettre en lumière, dans le processus de création, comment fonctionnent la « poétique des variations » et le « texte absent » qui caractérisent les écrits de l’écrivain paraguayen et que nos auteurs associent à l’oralité du guarani : « Retrouver le texte guarani absent […] tant il est vrai que la poétique roabastienne se nourrit profondément de cette matière linguistique et culturelle guarani, de sorte que traduire les textes écrits en espagnol paraguayen, c’est aussi traduire depuis le guarani ce texte qui “pense” l’écrivain, pour reprendre l’image très juste proposée par Roa Bastos » (p. 25).
5L’ouvrage témoigne ainsi d’une approche pluridisciplinaire où se mêlent études littéraires et anthropologiques, à l’image de ses auteurs. En effet, Cécile Brochard est maîtresse de conférences en littératures comparées à Nantes Université. Ses recherches explorent le lien entre littérature et politique, notamment dans une perspective décoloniale. Elle s’intéresse particulièrement aux pratiques et poétiques engagées par les écrivains plurilingues et autochtones d’Amérique et d’Australie. Quant à Joaquín Ruiz Zubizarreta, il vient de soutenir une thèse en anthropologie sociale et ethnologie à l’EHESS et au sein du laboratoire d’anthropologie sociale (LAS) intitulée Garder la porte entrebâillée : revisite ethnographique chez les Mbya-guarani du Paraguay. Il s’intéresse aux langues, discours, pratiques, représentations mythologiques et aux droits des peuples guaranis.
L’hospitalité de la traduction
6Yñipyru se démarque tout d’abord par sa posture par rapport à l’acte de traduction. Dans cette recherche du dévoilement du « texte absent » guarani, la démarche de traduction semble se rapprocher de la visée hospitalière défendue à la fois par Antoine Berman et par Paul Ricœur2. Antoine Berman dénonce la perspective platonicienne et ethnocentrée qui fait de la traduction un instrument de domination. Pour contrer cette posture, il défend une éthique de la traduction fondée sur la lettre. Il s’agit alors de recevoir l’autre dans son altérité en respectant ce que la langue fait au discours. Traduire la lettre, du « texte en tant qu’il est lettre », c’est-à-dire en tant que création du discours et manipulation de la langue, contre une vision dominante promouvant la traduction du sens. Ce respect de l’altérité du guarani transparaît dans la mise en place de différents mécanismes proposés par Cécile Brochard et Joaquín Ruiz Zubizarreta. Il nous faut d’abord souligner le rôle du paratexte et tout particulièrement des notes de bas de page. Celles-ci viennent non seulement éclairer et justifier la traduction mais également mettre en lumière les mécanismes de la langue guarani. Le lecteur entre ainsi dans les rouages de la langue et est guidé pour comprendre les fonctionnements de cette langue agglutinante de type polysynthétique. Ce recours apparaît dès le premier poème traduit, Yñipyru, où les auteurs justifient en note la traduction de « Ñanderuvusu ogũahẽ ouvo/Ñanderuvusu » par « Ñanderuvusu arrivent en venant/Ñanderuvusu ». Ils précisent alors : « La phrase est formée d’une part par la racine gũahẽ, “arriver”, accompagnée de la marque de la troisième personne -o ; d’autre part, le verbe “venir” à la troisième personne (ou), modulé par le suffixe -vo qui indique la continuité de l’action ». Et l’on remarquera la restitution de l’altérité dans la juxtaposition du verbe à l’indicatif suivi du gérondif en français qui laissent apparaître la singularité de la syntaxe guarani en bousculant celle du français.
7Cette proposition des auteurs nous semble particulièrement intéressante dans la mesure où le lecteur n’est pas seulement amené à entrer dans l’univers culturel du Paraguay mais également dans l’univers linguistique du guarani.
8Il est également important de mettre en avant le respect des interférences et la restitution des culturèmes3 dans les différentes traductions. Deux stratégies se présentent dans l’ouvrage. Lors de la traduction des poèmes, les auteurs explicitent en note le sens que renferment certains culturèmes comme la « parole-âme » (p. 35) ou encore les « bâtons croisés » (p. 37), par exemple. Dans la traduction des nouvelles, les culturèmes apparaissent la plupart du temps en italiques, tels quels, dans la version en français et sont ensuite expliqués en note. C’est le cas, par exemple, des obrajes ou de machu. Cette démarche de traduction permet au lecteur universel d’accepter l’altérité de l’univers littéraire et culturel auquel il est confronté tout en s’y aventurant grâce aux explicitations fournies en notes.
9Enfin, un autre choix de traduction mérite d’être souligné. À l’instar de la méthode adoptée par Roa Bastos, les passages en guarani dans les nouvelles ne sont pas traduits dans le corps du texte mais en notes de bas de page. Ce procédé permet au lecteur de comprendre le lien entre guarani et oralité, puisque les passages dans cette langue apparaissent presque exclusivement dans les dialogues. Le lecteur peut ainsi percevoir la réalité diglossique du Paraguay.
Clefs de lecture de l’œuvre roabastienne
10La structure et la sélection des textes d’Augusto Roa Bastos dans l’ouvrage sont particulièrement éclairantes. D’une part, l’on remarque que les textes critiques viennent, en effet, apporter des clefs de lecture de l’œuvre poétique et narrative de l’écrivain. Ainsi, si l’intérêt pour les chants ancestraux et pour les questions sociopolitiques ancrées dans la ruralité du Paraguay saute aux yeux du lecteur dans les poèmes et les nouvelles, celles-ci trouvent un écho dans les textes critiques. On y perçoit l’engagement d’Augusto Roa Bastos contre l’ethnocide des Guayakis, qui est aussi évoqué dans la nouvelle Chico-coá, ou encore l’abandon des populations rurales, qui apparait aussi dans la nouvelle « Les rogations ». La prégnance des oratures4, manifeste dans l’œuvre poétique de l’écrivain, est aussi revendiquée dans les écrits critiques comme le fondement d’une littérature nationale. Roa Bastos insiste sur la revalorisation de l’oralité guarani et des chants ancestraux tout particulièrement qui renferment l’authenticité d’une littérature nationale. En cela, la démarche de Cécile Brochard et Joaquín Ruiz Zubizarreta de dévoiler le texte absent guarani semble se concrétiser. Cette piste aurait pu également être explorée en s’arrêtant sur le rôle du guarani dans les poèmes où les deux langues, espagnole et guarani, s’alternent. En effet, dans Yñipyru, les occurrences en guarani semblent fonctionner comme des refrains dont découle l’écriture en espagnol. À l’échelle du poème se reflète l’idée que l’oralité guarani est source d’inspiration de la poésie en espagnol. De la même manière, l’engagement sociopolitique de l’écrivain aurait peut-être pu être abordé en insistant sur une autre clef de lecture de l’œuvre roabastienne : la fusion entre les personnages et le paysage. Celle-ci paraît témoigner d’une sorte de déterminisme dans la mesure où les êtres humains sont indissociables de leur milieu social et semblent incapables de s’en libérer. Ainsi, dans la nouvelle « Les rogations », la protagoniste Poilú est d’emblée présentée comme une « bestiole », « une petite larve humaine avançant entre les lambeaux jaunâtres des feuilles » (p. 151). Elle est aussi désignée comme « la figurine de cire sylvestre » (p. 153). De fait, son destin tragique dépend de la rudesse du territoire et tout particulièrement de l’absence d’eau. C’est aussi le cas pour le « niño-azoté », personnage de la nouvelle du même nom, qui se transforme en « fleur blanche aux cheveux rouges » (p. 168). Ainsi, les personnages sont façonnés par le territoire.
De l’œuvre roabastienne à l’émergence d’une tradition littéraire nationale
11L’une de forces d’Yñipyru est d’avoir mis en exergue non seulement l’importance des oratures dans l’œuvre de Roa Bastos mais également d’avoir montré comment à partir de ce dernier s’instaure une tradition littéraire paraguayenne qui va réinterpréter et réécrire les mythes ancestraux. Ce sera notamment le cas à la suite de Roa Bastos de la poète bilingue Susy Delgado. Les oratures et l’univers religieux guarani deviendront progressivement une source d’inspiration pour les poètes bilingues. C’est notamment le cas pour Brígido Bogado, Maurolugo ou Alba Eiragi Duarte, par exemple.
12Cette mise en lumière d’une scène littéraire nationale est aussi manifeste dans le jeu de dédicaces et de leur contextualisation en notes de bas de page. Il se tisse ainsi un réseau de sociabilisation autour de Roa Bastos qui le situe dans un ancrage littéraire mais aussi culturel et politique. On y retrouve notamment des anthropologues comme Miguel Chase-Sardi ou Rubén Barreiro Saguier mais aussi d’autres auteurs comme Emiliano R. Fernandez, Carlos Federico Abente, Elvio Romero, Josefina Plá ou encore Carlos Colombino. Grâce à l’effort de contextualisation en notes de bas de page, le lecteur peut observer les mailles d’une scène littéraire engagée.
Du lectorat paraguayen au lectorat universel
13Il nous faut ici insister sur l’importance du paratexte qui joue un rôle clef dans le rapprochement entre la réalité d’un lecteur francophone et celui d’Augusto Roa Bastos. Les notes de bas de page incarnent ainsi un réel apport de contextualisation géographique, historique et politique mais aussi sociétale et anthropologique. Ainsi, grâce à la double lecture de la traduction de l’œuvre de l’écrivain paraguayen et aux explications apportées par Cécile Brochard et Joaquín Ruiz Zubizarreta, le lecteur peut ainsi non seulement obtenir des clefs de lecture de l’univers roabastien mais aussi de la mythologie guarani. Nous insistons sur la rigueur avec laquelle les différents dieux de la cosmogonie guarani sont resitués ainsi que les étapes de la genèse et les attributs des différentes déités. Nous pensons, par exemple, à la symbolique du jaguar bleu (p. 45) ou à celle des arcs (p. 63). L’importance de la contextualisation historique apparaît aussi clairement pour un poème comme Soldado de la revolución (p. 89) qui évoque la guerre civile liée à la Révolution de 1947 au Paraguay.
14Yñipyru et autres textes convoquent ainsi différents outils qui permettent au lectorat français d’accueillir l’univers linguistique et culturel guarani exploré par Roa Bastos.
notes
1 Barbara Cassin, Éloge de la traduction : compliquer l’universel, Paris : Fayard, 2016, p. 49.
2 Voir Antoine Berman, La Traduction et la lettre ou l’Auberge du lointain, Paris : Seuil, 1999, et Paul Ricœur, Sur la traduction, Paris : les Belles lettres, 2016.
3 Nous concevrons ici le culturème selon la définition proposée par Georgiana Lungu-Badea : « Défini comme la plus petite unité porteuse d’information culturelle, le culturème est aussi un concept théorique désignant une réalité culturelle propre à une culture qui ne se retrouve pas nécessairement dans une autre. Le concept est devenu opératoire dans la théorie et la pratique de la traduction en raison des difficultés posées par le transfert des différences culturelles ». Le culturème se construit sur le modèle linguistique du morphème, phonème, graphème. Georgiana Lungu-Badea le définit à partir de trois critères : son caractère monoculturel, la relativité de son statut et son autonomie par rapport à la traduction. Son essence relative est liée au fait que le culturème est propre à une culture et garde la même signification peu importe le contexte. À la différence du traductème, du néologisme ou de l’emprunt, le culturème n’est pas le fait d’un auteur. Lungu-Badea, « Remarques sur le concept de culturème », Translationes, vol. 1, 2009, p. 15-78.
4 Le terme « orature » aurait été forgé par le linguiste ougandais Pio Zirimu pour parler des expressions orales de création humaine. Micere Mugo, professeur en histoire de l’art, a ensuite repris le terme pour désigner plus spécifiquement des productions artistiques orales qui se prêtent généralement à la déclamation ou à la dramatisation. Ce terme a ensuite été repris par différents chercheurs qui en ont modelé le sens et les nuances. Il est repris au Paraguay par Mark Münzel pour parler de la spécificité littéraire des chants mythiques des communautés guaranis.
résumés
Ce compte-rendu s’intéresse à Yñipyru et autres textes (Classiques Garnier, 2024), où Cécile Brochard et Joaquín Ruiz Zubizarreta proposent une traduction « hospitalière » d’œuvres d’Augusto Roa Bastos — poèmes, nouvelles et textes critiques — qui révèlent l’importance du guarani dans sa création. L’ouvrage, annoté et commenté, éclaire la « poétique des variations » et le « texte absent » guarani, tout en respectant l’altérité linguistique grâce à un usage soigné du paratexte, des notes explicatives et de la restitution des culturèmes. Les traductions rendent perceptibles la réalité diglossique du Paraguay et la richesse de la cosmogonie guarani. La sélection des textes met en évidence les deux axes majeurs de l’œuvre : l’ancrage culturel et linguistique guarani et l’engagement sociopolitique. L’analyse montre aussi comment Roa Bastos s’inscrit dans une tradition littéraire paraguayenne. Par son travail minutieux, l’ouvrage relie l’univers de Roa Bastos à un lectorat francophone tout en restituant l’arrière-plan historique, mythologique et politique du Paraguay.
This review focuses on Yñipyru and Other Texts (Classiques Garnier, 2024), in which Cécile Brochard and Joaquín Ruiz Zubizarreta offer a “hospitable” translation of works by Augusto Roa Bastos—poems, short stories, and critical essays—that reveal the central role of Guarani in his creative process. Annotated and commented, the volume sheds light on the “poetics of variations” and the Guarani “absent text,” while respecting linguistic otherness through the careful use of paratexts, explanatory notes, and the preservation of culturèmes (culture-specific element). The translations convey both the diglossic reality of Paraguay and the richness of the Guarani cosmogony. The selection of texts highlights the two main axes of Roa Bastos’s work: its cultural and linguistic grounding in Guarani and its sociopolitical engagement. The analysis also shows how Roa Bastos is part of a Paraguayan literary tradition. Through meticulous work, the book connects Roa Bastos’s universe to a Francophone readership while restoring the historical, mythological, and political background of Paraguay.
plan
L’hospitalité de la traduction
Clefs de lecture de l’œuvre roabastienne
De l’œuvre roabastienne à l’émergence d’une tradition littéraire nationale
Du lectorat paraguayen au lectorat universel
mots clés
anthropologie, guarani, littérature, Roa Bastos (Augusto), traduction
anthropology, Guarani, literature, Roa Bastos (Augusto), translation
auteur
Manon Naro
Voir ses autres contributions
Université de Montpellier Paul-Valéry
Courriel : manon.naro@univ-monpt3.fr
pour citer cet article
Manon Naro, « Accueillir l’univers culturel et linguistique guarani : une traduction hospitalière de l’œuvre d’Augusto Roa Bastos », Acta fabula, vol. 27, n° 4, Notes de lecture, Avril 2026, URL : http://www.fabula.org/revue/document21025.php, page consultée le 15 April 2026. DOI : https://10.58282/acta.21025";
https://www.fabula.org/revue/document21025.php
#metaglossia
#metaglossia_mundus

«Chercher Dieu –affirme le Souverain Pontife– c’est aussi reconnaître l’image de Dieu dans chaque créature, enfant de Dieu, en chaque homme et chaque femme créés à l’image et à la ressemblance de Dieu». C’est pourquoi il est important «d’apprendre à vivre ensemble dans le respect de la dignité de chaque personne humaine».
...
Le dialogue avec le recteur a été marqué par la gratitude d’être dans un «lieu qui représente l’espace qui appartient à Dieu», dans le cadre d’un voyage en Algérie, «terre également de mon père spirituel saint Augustin, qui a tant voulu enseigner au monde, surtout par la recherche de la vérité, la recherche de Dieu, en reconnaissant la dignité de chaque être humain et l’importance de construire la paix». «Chercher Dieu –affirme le Souverain Pontife– c’est aussi reconnaître l’image de Dieu dans chaque créature, enfant de Dieu, en chaque homme et chaque femme créés à l’image et à la ressemblance de Dieu». C’est pourquoi il est important «d’apprendre à vivre ensemble dans le respect de la dignité de chaque personne humaine».
Le Pape Léon XIV a salué également la création d’un centre de formation au sein de la mosquée, car «il est important que l’être humain développe les capacités intellectuelles que Dieu lui a données, afin que nous puissions découvrir toute la grandeur de la création», a-t-il souligné. L’encouragement passe donc par «la recherche de la vérité», «à travers l’étude» et «par la capacité de reconnaître la dignité de chaque être humain» pour «apprendre à nous respecter mutuellement, à vivre en harmonie et à construire un monde de paix». Le Pape a assuré de ses prières «le peuple d’Algérie» et «tous les peuples de la terre» afin que «la paix et la justice du Royaume de Dieu se manifestent également parmi nous et que nous soyons tous, de plus en plus convaincus, de la nécessité d’être des promoteurs de paix, de réconciliation, de pardon et de ce qui est véritablement la pensée de Dieu pour toute sa création».
À la fin, avant de prendre congé et de se rendre à Bab El Oued pour une visite privée au Centre d’accueil et d’amitié des sœurs missionnaires augustiniennes, puis à la basilique Notre-Dame d’Afrique, Léon XIV a signé le livre d’or, avec un message en français. «Que la miséricorde du Très-Haut garde dans la paix et la liberté le noble peuple algérien et toute la famille humaine. Que la miséricorde du Très-Haut préserve le noble peuple algérien et toute la famille humaine dans la paix et la liberté», a-t-il écrit..."
https://share.google/DSVp7XGwZeSergJHH
#metaglossia
#metaglossia_mundus

"A new 150-page research report, Books in Translation: Trends and Transformations in the European Publishing Market, finds that translations from English account for 50% to 70% of all translated titles across most of the continent. It also finds that translations from Japanese are proving more popular than books from some European languages, and that AI is already having a significant impact on the translation market.
The report draws on data from 10 countries and regions, combining national library statistics from Sweden, Slovenia, Catalonia, Bulgaria, and Croatia with publishing industry data from Germany, France, Italy, Poland, Spain, and Austria. It was produced by Rüdiger Wischenbart Content and Consulting in cooperation with CulturalTransfers.org and is part of the EU-funded ThinkPub project.
Translations continue to play a significantly larger role in European book markets—especially those with fewer than 10 million speakers—where they typically account for 20% to 40% of annual book production. In larger markets such as Germany, France, Italy, and Spain, local-language titles dominate, and translations represent roughly 12% to 15% of new books. Direct translations between smaller European languages, such as Slovenian and Bulgarian, remain “almost non-existent” and are often derived from an English translation first, with English serving as a gateway language.
One notable shift in the translation market has been the growing popularity of Japanese manga. In France, Japanese is now the second most translated language, representing 19.9% of all translated titles in 2024. In Germany, manga overtook French in 2021 and accounted for 12.8% of new translated titles in 2023. Poland recorded 11% of translations from Japanese, also exceeding French.
All of this is unfolding within an increasingly difficult publishing environment. The report notes that annual unit sales are declining across almost all markets over the past two decades, with the notable exceptions of Portugal and Spain. Over the past two decades, European publishing has lost 24.1% of its real market value, once revenue is adjusted for inflation, according to the Federation of European Publishers.
On the policy side, the report finds that EU translation grant funding through the Circulation of European Literary Works Programme has increased from approximately €3.4 million annually in 2016–2017 to as much as €5 million per year from 2021 to 2024. It also notes that translations from Ukraine were the fastest-growing category, with the EU supporting the publication of 130 books—representing 6% of all funded works between 2021 and 2024. This boom came in response to Russia’s invasion of Ukraine in 2022.
The report also highlights sharp imbalances between national programs. It cites Slovenia (population 2.1 million), which publishes 3,800 original works annually and supported the translation of 165 titles from 2020 to 2024. By contrast, Bulgaria (population 6.3 million), which produces nearly twice as many books each year, supported just 18 titles through its national translation funding program.
AI's impact
The report also examines the impact of AI on the translation market, identifying two events as pivotal. First, in November 2025, Amazon introduced Kindle Translate, an AI-powered translation tool available exclusively to self-publishing authors on Kindle Direct Publishing, covering English-to-Spanish, Spanish-to-English, and German-to-English language pairs. The report suggests that the tool’s current restriction to larger language pairs—reflecting limitations in training data—is likely to widen the gap between dominant and more peripheral languages.
A second development, noted by the report, came in February, when HarperCollins France partnered with Fluent Planet to use AI to translate the Harlequin Azur romance series. HC justified the move by arguing that, in light of declining sales, it was necessary to preserve the €4.99 price point. Predictably, the decision drew pushback from French professional translation bodies and reignited debate over AI’s role in literary production.
To test the practical limits of machine translation, the report’s authors conducted a small experiment, translating a Slovenian text into Zulu via ChatGPT-4 in Ljubljana and then back into Slovenian and English via a ChatGPT account in Pretoria. The locations were chosen because there are no direct Slovenian–Zulu human translations, dictionaries, or documented cultural contact between the two languages. The AI performed reasonably well on short, technical sentences but struggled with complex literary passages, omitting details and altering meaning.
A subsequent test on a Slovenian poem found that while the direct Slovenian-to-English translation was adequate, the Slovenian–Zulu–English pathway produced what the authors describe as “a new poem”—one wholly transformed and stripped of its cultural and political subtext. The authors concluded that AI translation is likely to replace a number of translators, but will still require highly skilled human editors to catch errors, especially in literature and in translations involving languages with limited training data.
The report’s authors are direct about what this shift means for the profession. “In the era of machine intelligence,” they write, “only human authors and translators with above-average skills will be able to produce new content; the average ones will be substituted by the machines.” They frame this not as a warning but as a consequence—one that demands more rigorous training, higher editorial standards, and a clearer-eyed publishing industry. “And this,” they add, “is not bad at all.”
Authors of the report are Miha Kovač, professor at the Department of Library and Information Science and Book Studies at the University of Ljubljana; Austrian publishing consultant Rüdiger Wischenbart; Yana Genova, founder of the Next Page Foundation; and Anja Kamenarič, researcher at the University of Ljubljana."
By Ed Nawotka | Apr 09, 2026
https://www.publishersweekly.com/pw/by-topic/international/international-book-news/article/100121-in-europe-s-translation-markets-english-dominates-japanese-grows-ai-disrupts.html
#metaglossia
#metaglossia_mundus

"Fry’s to pay $120K after denying ASL interpreter to deaf employee, Arizona AG says
Fry's Food Stores has reached a settlement over a lawsuit that claimed the grocery chain failed to provide a deaf employee with an interpreter.
PHOENIX (AZFamily) — Fry’s Food Stores will pay $120,000 to a former employee after the company allegedly discriminated against his disability while he worked at a Surprise store.
Attorney General Kris Mayes announced Monday that the lawsuit alleged Fry’s failed to provide a deaf employee with an American Sign Language interpreter despite repeated requests.
The employee, who began working as a grocery clerk in 2009 at a Fry’s near the Loop 303 and Greenway Road, was born deaf and uses American Sign Language as his first language.
In January 2024, he reported the alleged discrimination to the state.
According to the lawsuit, the Arizona-based grocery chain relied on lip-reading, written notes and even family members to interpret workplace training sessions.
State investigators said the employee was later accused of insubordination after refusing to sign documents he did not understand and was eventually fired without ever receiving effective accommodations for his disability.
Under the settlement, Fry’s agreed to pay the former employee $120,000 and make several changes to how it handles accommodations for deaf employees in Arizona.
Those changes include building relationships with ASL interpreting agencies that offer both in-person and video remote services, training managers and human resources staff on disability accommodation requirements, and providing guidance on how to recognize and respond to accommodation requests.
Join the Conversation
0comments
“Civil rights protections are at increasing risk in our country and our state, but my office is committed to protecting all Arizonans from unlawful discrimination,” Mayes said in a written statement. “When employers deny effective communication to employees with disabilities, qualified individuals are prevented from meaningful participation in the workforce."
By Brian Petersheim Jr.
Published: Apr. 6, 2026 at 7:22 PM GMT+1|Updated: 11 hours ago
https://www.azfamily.com/2026/04/06/frys-pay-120k-after-denying-asl-interpreter-deaf-employee-arizona-ag-says/
#metaglossia
#metaglossia_mundus
"On Translation as a Symmetry of Language
Camilo Brown-Pinilla, A.B. '26, Applied Mathematics
Advisors: Melanie Weber
• Please give a brief summary of your project.
When you translate a sentence into another language, the surface form that sentence takes on varies, but the underlying meaning remains unchanged. Using the language of group theory, Geometric Deep Learning describes relationships such as these as symmetries. By treating symmetries as a foundational design principle, we are able to create models that are especially robust and data efficient. This thesis approaches Natural Language Processing, which allows artificial intelligence agents to understand human languages, from this geometric perspective, treating translation as a symmetry of language and asking whether this approach can be used to improve the translation ability of AI systems.
• How did you come up with this idea for your final project?
I have been thinking about this project ever since my junior year when I took a class on Geometric Machine Learning. Starting with a background in Natural Language Processing, I was amazed by the mathematical elegance and real-world utility of the geometric learning philosophy. This project emerged as my attempt at finding a bridge between these mostly disjoint fields.
• What was the timeline of your project?
I started working on this project in April 2025. Over the summer, I conducted a thorough literature review and refined the formulation of my problem. From August to March 2026, I completed the implementation of this idea, which stitches together three distinct machine learning pipelines.
• What part of the project proved the most challenging?
The hardest part of the project was refining my initial interest in a bridge between Geometric Deep Learning and Natural Language Processing into an actionable research question. I had to dig through linguistic literature that was unfamiliar to me and think outside of the box to see how different tools and perspectives were really just instances of the same overarching idea. From there, the engineering pipeline was a challenge, requiring me to optimize and orchestrate several large models and datasets.
• What part of the project did you enjoy the most?
I thoroughly enjoyed the opportunity to spend a lot of time thinking very deeply about a problem that interests me. Every part of the project felt like working my way through the wild west. It was very exciting getting to work with so many different techniques and finding a way to link them all together.
• What did you learn, or skills did you gain, through this project?
I learned more skills than I can count. Most importantly, I learned how to think like a scientist and channel curiosity and excitement into real results.
Topics: Academics, AI / Machine Learning, Applied Mathematics"
https://seas.harvard.edu/news/camilo-brown-pinillas-senior-project-new-approach-ai-translation
#metaglossia
#metaglossia_mundus

" 'I'm American but needed a translator to understand 2 common British phrases'
An American woman who is married to a British man has outlined two things her husband says regularly which leave her confused. She appealed to her followers on social media for help to make sure she was understanding him correctly.
Ian Craig Social Newsdesk Content Editor
06 Apr 2026
Communication is key to any successful relationship. Being able to make your other half understand just what you mean is important so you're always on the same page, and to avoid any unfortunate misunderstandings.
But when two people come from completely different cultures, this can be a struggle. A phrase meaning one thing to one person may mean something completely different to the other.
One American woman who is married to a British man has outlined two things he says regularly which leave her confused. The woman, who posts on TikTok as corrinesarah, appealed to her followers for help to make sure she was understanding her husband correctly.
She posted the clip with the caption: "Married a British man and now I need a translator."
Opening the video, she said: "Two things I hear my British husband say all the time, and what they actually mean.
"If a British man says 'that's interesting', he means he hates it. It's the worst thing ever. Toss it out, start over. Just no.
We use your sign-up to provide content in ways you've consented to and improve our understanding of you. This may include adverts from us and third parties based on our knowledge of you. More info
"But if a British man says 'it's alright', that is like the highest compliment ever. He loves it, it's amazing, you won. Good job."
Appealing to her followers for help, she concluded: "So, British people in my comments, tell me: am I right? Am I understanding him correctly? 'Cos I need help."
Thankfully, commenters came through with their own advice on British sayings.
One said: "'That's interesting' all depends on what happens afterwards. If he immediately starts talking about something else, he hates it. If he goes quiet for a bit and seems distracted, it really was interesting and he's devoting considerable brain power to analysing it in immense detail."
Another said: "'That’s alright' is a polite way of saying it's fine, but it can be a lot better with improvement." And someone else wrote: "'Alright' could literally mean 100 different things tbh."...
A different user commented: "The highest compliment he can give you is telling you that you're 'a bit of alright'." corrinesarah replied: "He’s said that to me before." Someone else replied: "If he has said that to you, take it from me, he absolutely loves you."
Another said: "If you ever suggest an activity or somewhere to visit, if he responds with 'yeah, we could do', that means that he does not want to do it." And someone else wrote: "'Not too shabby'= high praise."
A different user commented: "The phrase you really want to hear is that something is 'not bad'. Peak compliment!""
https://www.mirror.co.uk/news/real-life-stories/im-american-needed-translator-understand-36950423
#metaglossia
#metaglossia_mundus
"By Eurasia Review
A medieval ophthalmologist who translated Greek works by Galen, Hippocrates, and Plato into Arabic played a pivotal role in shaping Western medical scholarship, according to a recent study published in the journal Cogent Arts and Humanities.
x
In the study, authors affiliated with the University of Sharjah transcribe and translate into English the Arabic text of an original manuscript by Hunayn ibn Ishaq titled In the Eye, Two Hundred and Seven Issues. The ninth-century treatise is an innovative work in ophthalmology that corrected medieval misconceptions and significantly influenced the development of medical knowledge.
Written in a question-and-answer format, the treatise supplements ten other original essays by Hunayn that together are regarded as a landmark in both Islamic and Western medical history. In these works, he provides detailed analyses of eye anatomy, including the layers of the eye and the optic nerves, demonstrating the advances that made lasting contributions to Arabic and Western medicine alike.
“In the field of ophthalmology, Hunayn ibn Ishaq demonstrated his scientific prowess, providing evidence-based explanations and proving that disagreements about the number of eye layers were merely terminological and not substantive,” said the study’s lead author Dalal H. Al-Zubi, a doctoral candidate. “He clarified that the eye consists of seven layers, with only one responsible for vision, while the others support its function.” Hunayn also meticulously described the role of each layer, including its starting and ending points.
The study further highlights Hunayn’s explanation of the muscles controlling eye movement, noting his clarification that the brain governs these muscles via the nerve connecting it to the eye. His work ‘In the Eye, Two Hundred and Seven Issues’ provides clear evidence of the distinctiveness of his methodology in this field,” added Al-Zubi.
Enduring influence
Beyond his medical contributions, the study emphasizes Hunayn’s influence as a translator. As Al-Zubi notes, he enriched the Arabic language by introducing precise medical terminology, including terms for the retina and cornea. Rather than relying on literal translation, Hunayn employed descriptive and analogous renderings and metaphors, producing Arabized terms that conveyed meaning while remaining linguistically natural in Arabic.
A Syriac Christian polymath and member of the then prosperous and far-reaching Church of the East, Hunayn (known in the West as Johannitius) earned the epithet “Sheikh of the Translators.” He played a pivotal role as both a scholar and translator at the House of Wisdom in Baghdad. His translations, often based on original Syriac and Greek manuscripts, were instrumental in preserving Greek scientific knowledge and later transmitting it to Europe.
The study examines Hunayn’s contributions to advancing the translation movement during the early Abbasid period, highlighting how he pioneered the translation paradigm that prioritized rendering the full meaning of the source text rather than adhering to the prevailing practice of word-for-word translation.
While this research marks the first time Hunayn’s Arabic manuscript In the Eye, Two Hundred and Seven Issues, has been translated into English, several of his treatises had earlier reached the West through Latin and other European translations. “Hunayn ibn Ishaq’s writings or translations were largely recognized in the West and were translated into Latin or other European languages. In fact, the medical advances brought about by the publication of Ishaq’s treatises on ophthalmology were significant,” Al-Zubi explained.
The ophthalmologist and medical historian Max Meyerhof, for example, cites Hunayn’s Kitab al-Ashr Maqalat fil-Ayn (The Ten Treatises on the Eye), noting that it represents the earliest known systemic treatment of ophthalmology. Meyerhof mentions that the text was likely used in both Islamic and Western medical schools of the period.
The research further illustrates how Hunayn developed and refined his scientific expertise in medicine. The authors observe that he possessed exceptional mastery of the Arabic language and that his translations enriched scientific and medical nomenclature. “He frequently relied on metaphorical expression, as evidenced by the Arabic term ‘al-Ankabutiyya’ for the arachnoid, explaining that it refers to a spider’s web in the original source language from which the term was derived,” Al-Zubi stated.
She added, “In other instances, he Arabized foreign terms that had no equivalents in Arabic, as he did with al-Shabakiyya for the retina and al-Multahima for the conjunctiva. He was known for coining Arabic terms for their Greek counterparts that reflected an associative relationship between the signified and the signifier. This is particularly evident in his rendering of the retina into الشبكية al-Shabakiyya, chosen because its structure resembles a fisherman’s net, given the dense interweaving of veins and arteries intertwined within it, akin to a fishing net.”
Another reason for Hunayn’s mastery of translation, according to Al-Zubi, was his careful attention to the original coinage and semantic range of Greek terms. Many of his Arabic medical designations, still in use today, were deliberately crafted to align with denotations of the source language. A case in point is Herophilus’ term ‘Amphiblēsteroeidēs,’ a Latinized form derived from ancient Greek medical terminology describing the interwoven vessels of the retina, likened to the mesh of a hoisted fishing net.
A bridge between civilizations
Hunayn’s ophthalmological treatises attest to a level of scientific sophistication that was almost unrivaled in the Middle Ages. In their study, the authors credit him with “providing evidence-based explanations and proving that disagreements about the number of eye layers were merely terminological and not substantive.”
They note that Hunayn’s anatomical analysis identified which of the eye’s seven layers was responsible for vision. He also explained “the number of muscles controlling eye movement and clarified that the brain governs these muscles through the nerve connecting it to the eye. The findings in his manuscript In the Eye: Two Hundred and Seven Questions stand as a testament to the remarkable progress of ophthalmology during the early Abbasid era.”
Asked to assess Hunayn’s place in medical history, Maamoun Saleh Abdulkarim, professor of archaeology and history at the University of Sharjah, described him as a figure of lasting significance: “Hunayn ibn Ishaq significantly influenced the development of Western medicine. He played a crucial role in translating Greek medical texts into Arabic, particularly those of Galen and Hippocrates, refining and explaining them with remarkable scholarly precision.”
Prof. Abdulkarim, who is also among the study’s co-authors, added that “these Arabic translations later served as the foundation for Latin translations used in European universities during the Middle Ages. In this way, Hunayn ibn Ishaq functioned as a vital intellectual bridge between ancient Greek medicine and the medical science that later emerged in medieval European universities.”
In academic literature, Hunayn is widely regarded as a central figure in the transmission of ancient Greek medicine to the Islamic world and in the subsequent diffusion of this knowledge to Europe. As Mesut Idriz, professor of Islamic civilization at the University of Sharjah, has noted, “Hunayn ibn Ishaq’s translations and original writings exerted influence not only within the Islamic world but also in medieval Europe.”
Prof. Idriz, also one of the co-authors, pointed out that medical historians pay particular attention to Hunayn’s work titled al-Masāʾil fī al-Tibb(Questions on Medicine for Students), which was translated into Latin under the title Isagoge (Johannitius). “This text served for centuries as an introductory medical manual in European universities,” he said. “Its wide circulation in the Latin scholarly world illustrates the important role that Islamic medical scholarship played in shaping the foundations of medical education in medieval Europe.”
Prof. Abdulkarim likewise described al-Masāʾil fī al-Tibb as a seminal work, calling it “one of the earliest and most influential didactic texts in Islamic medical history, written in a unique question-and-answer format that shaped medical education for centuries.” He emphasized that Hunayn was “not merely a transmitter of Greek medicine; he was one of the most significant intellectual bridges connecting classical knowledge with medieval European medicine.”
Hunayn’s legacy, Prof. Abdulkarim concluded, is a reminder that scientific progress has historically arisen from dialogue between civilizations rather than from the achievement of any single culture. “It demonstrates that the history of medicine is not solely the narrative of one civilization,” he said, “but rather the story of knowledge traveling across cultures and shaping global science.”
Eurasia Review
Eurasia Review is an independent Journal that provides a venue for analysts and experts to publish content on a wide-range of subjects that are often overlooked or under-represented by Western dominated media.
https://www.eurasiareview.com/06042026-how-an-eye-physician-who-translated-classical-greek-medicine-into-arabic-helped-form-western-medical-thought/
|











"
기자명Jinju Hong
2026-03-16 13:05:00
GDELT unveils AI experiments translating multilingual news, extracting leadership changes and turning a 3,100-page U.S. defence bill into an infographic.
(홍진주)] The GDELT Project, which collects and analyses global news and social data in real time, is releasing various experiments that use artificial intelligence to analyse large volumes of news and policy documents.
An online outlet, Gigazine, reported on March 15 local time that the GDELT Project is a global archive that continuously collects content published in more than 100 languages worldwide, including broadcasts, newspapers and web news, and builds it into a database. It links various elements, including people, organisations, places, events and news sources, into a single network. It provides data on events around the world, their background and trends in public opinion.
The project was founded by data scientist Kalev Leetaru and political scientist Philip Schrodt, and it collects news and social media (SNS) data from 1979 to the present. The collected data are used as a basis for analysing global political, economic and social trends by quantitatively coding social events and reactions to them.
GDELT in particular releases large datasets so researchers and journalists can use them for analysis. The data consist of three streams: event data that classify physical activity worldwide into more than 300 categories; relationship data that record people, organisations, places, topics and emotions; and data that analyse the visual story of news images. The data are updated about every 15 minutes.
GDELT also operates a translingual platform that processes global news written in 65 languages through real-time translation using its own translation system.
Recently, it has also been actively conducting analysis experiments using AI. The GDELT Project disclosed an experiment that uses a Gemini-based model to automatically extract announcements of leadership changes at governments or companies from global news and organise them into a knowledge graph. In the process, AI was used to generate reports by going beyond organising personnel information and inferring the political and economic background.
In another experiment, work was carried out to input the roughly 3,100-page U.S. National Defense Authorization Act into AI and convert the entire bill into a single infographic. In the process, various analyses were also performed, including topic analysis of the bill, organisation of related bills and generation of expected questions.
GDELT also disclosed a large-scale translation experiment. According to a February 2026 announcement, it translated about 3 million TV news broadcasts accumulated over 25 years using AI. The cost to translate a total of 62 billion characters of broadcast data amounting to about 6 billion seconds was about $74,634. This is work that is estimated to have required millions of dollars using past methods.
Such projects are assessed as examples showing the possibility that AI can comprehensively analyse vast amounts of news and policy documents. Experts say such data-based analysis could become a new tool for understanding global political and economic trends."
https://www.digitaltoday.co.kr/en/view/39425/ai-translates-25-years-of-news-in-100-countries-summarises-3100-page-bill-in-big-data-test
#metaglossia #metaglossia_mundus