Your new post is loading...
Your new post is loading...

|
Scooped by
Gilbert C FAURE
October 13, 2013 8:40 AM
|
is a personal Notebook Thanks John Dudley for the following tweet "If you like interesting snippets on all sorts of subjects relevant to academia, information, the world, highly recommended is @grip54 's collection:" La curation de contenus, la mémoire partagée d'une veille scientifique et sociétale
|
|
Scooped by
Gilbert C FAURE
June 21, 3:39 AM
|
Last episode, we discussed around the Brain behind LLM and this edition is a bit more deep-dive on how GraphRAG exactly works - Happy reading !
#TheDataAlchemist #Ontology #GraphRAG #DataArchitecture #AI
|
|
Scooped by
Gilbert C FAURE
June 20, 4:37 AM
|
Turns out AI tools erode abilities very quickly...
Nature says:
1. Colonoscopy study [1]:
Highly experienced physicians had is a 21% relative decline in finding adenoma when they couldn’t access AI.
“The physicians, who had all performed at least 2,000 colonoscopies during their careers, were given access to an AI system that analyses colonoscopy images. The tool was available to the specialists on some days but not on others.
When physicians began using it, their performance dropped significantly whenever the system was UNAVAILABLE.”
2. Software engineers couldn’t diagnose errors in codes [2]:
The average success score “was 50% in the AI group versus 67% in the non-AI group”
“The AI-assisted participants did particularly poorly on questions that required them to diagnose errors in the code, which suggests that they had failed to learn the concepts behind the code that they had just produced.”
📍 “Now you have this very odd disconnect between performance and learning. People can perform at a pretty high level, because they’re basically borrowing skills from the AI, but they are not developing those skills themselves.” - Kevin Crowston [Syracuse Univ.]
Basically:
GPS has de-skilled us in navigation.
Now, AI may be de-skilling us in general cognition.
___
p.s. I am still writing these posts myself.
Is it efficient? Perhaps no.
But at least, I like to think it keeps my cognition in shape.
References:
[1] Budzyń et al. Lancet Gastroenterol. Hepatol. 10, 896–903 (2025).
[2] Shen & Tamkin. ArXiv : 2601.20245 (2026). | 63 comments on LinkedIn
|
|
Scooped by
Gilbert C FAURE
June 19, 7:17 AM
|
We’re proud to spotlight one of our valued corporate partners: The Federal Reserve Bank of Kansas City
The Kansas City Fed is one of 12 regional Reserve Banks that, along with the Board of Governors in Washington, D.C., make up our nation's central bank.
They work in the public’s interest by supporting economic and financial stability, across our region and nation.
Partnerships like these matter because they help us in empowering Black-owned businesses and professionals throughout our community.
Thank you to the Federal Reserve Bank of Kansas City for your continued partnership and support 🙏🏽
#heartlandblackchamber #corporatepartner #kansascity #blackbusiness #entrepreneurship
|
|
Scooped by
Gilbert C FAURE
June 19, 4:03 AM
|
The free platform, called Journal Trends, could also allow integrity sleuths to spot low-quality publications.
|
|
Scooped by
Gilbert C FAURE
June 18, 5:40 AM
|
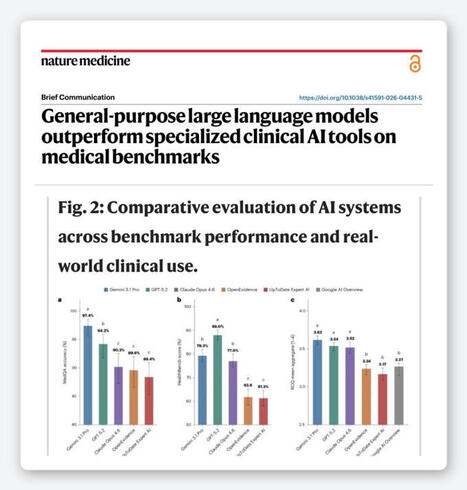
En médecine, une étude dont le volet clinique repose sur n=12 (12 participants), ça risque pas de changer les pratiques ou de faire beaucoup jaser. Si c'est de l'IA par contre...
Une étude dans Nature Medicine dit que les IA généralistes comme ChatGPT surpassent des IA spécialisées : OpenEvidence et UpToDate Expert AI.
Le titre est puissant. Mais l'étude, elle, ne l'est pas tant que ça.
L’étude se divise en deux volets : benchmarks et évaluation humaine
1️⃣ MedQA et HealthBench
Questions à choix de réponses de type USMLE et questions tirées d'un benchmark développé par OpenAI.
Ce sont deux benchmarks publics. Donc les modèles généralistes, entraînés sur d’immenses corpus web et académiques, peuvent avoir été exposés directement ou indirectement à une partie du matériel, du style de questions de réponse attendues.
À l’inverse, OpenEvidence et UpToDate Expert AI sont des outils cliniques spécialisés, conçus autour d’un usage de référence, de recherche documentaire et de récupération de contenu médical sélectionné (RAG).
Ce n’est pas une évaluation très juste.
2️⃣ Real Clinical Queries
La portion la plus proche du terrain : 100 questions cliniques réelles provenant d’un seul centre, NYU, évaluées à l’aveugle par 12 cliniciens.
Les auteurs nomment bien dans la publication leurs propres limites :
Échantillon limité, différences entre accès API et interface web, absence d’évaluation de la qualité des citations, de la latence et de l’intégration réelle dans les pratiques cliniques.
Ce n'est pas de la mauvaise science mais c'est une approche médiatique douteuse de transformer ça en conclusion simple genre « les IA généralistes battent les outils cliniques spécialisés ».
📜 En lecture critique, que ce soit pour un médicament pour évaluer un système IA, on se ramène toujours aux questions de base :
• Quel type d'étude, quelle méthodologie?
• Les résultats ont-ils une bonne validité interne ET externe?
• Quels sont les résultats? C'est beau les stats, mais sont-ils cliniquement significatifs?
• Sont-ils applicables à mon contexte?
• Y a-t-il des conflits d'intérêts chez les chercheurs?
Je ne crois pas qu'on puisse tirer de grandes conclusions de cette étude sinon que nous sommes encore loin d’avoir une bonne façon d’évaluer l’IA médicale.
Un benchmark, ce n’est pas un patient.
Un score, ce n’est pas un impact clinique.
Un titre puissant, ce n’est pas une preuve forte.
Avant de laisser une IA influencer une décision médicale, il va falloir exiger mieux que ça.
#LectureCritique #EvidenceBasedMedicine #ClinicalAI #MedTech
Avis? Commentaires? Pierre Beaupré Ilitea Kina Mathieu Pelletier, MD, FCMF Mathieu Moreau Pascale Breault Aude Motulsky Alexandre Hudon, BEng, MD, M.Sc (Éd), PhD, FRCPC| 21 commentaires sur LinkedIn
|
|
Scooped by
Gilbert C FAURE
June 16, 4:06 AM
|
Out of curiosity, I asked ChatGPT to create a visual representation of my professional life and daily routine based on everything it has learned about me over time.
To my surprise, it captured many aspects of my journey remarkably well medical educator, researcher, curriculum leader, mentor, reviewer, conference speaker, advocate for AI and immersive technologies in healthcare education, and most importantly, a lifelong learner.
While no AI-generated image can fully represent a person, this visual serves as an interesting reflection of how artificial intelligence can recognise patterns in our work, interests, values, and aspirations.
It is fascinating to see how AI not only supports our productivity but can also help us reflect on our professional identity and impact.
What do you think? How accurately would AI portray your professional journey?
#ArtificialIntelligence #MedicalEducation #DigitalHealth #Leadership #MedicalEducator #HigherEducation #AIinEducation #VirtualReality #MixedReality #AcademicLife
|
|
Scooped by
Gilbert C FAURE
June 15, 5:06 AM
|
Zhejiang University has officially surpassed Harvard in the 2026 Nature Index. However, keen observers will recognize Zhejiang isn't even the most prestigious university in China. It ranks behind Tsinghua, Peking, Shanghai Jiao Tong and Fudan in Gaokao admission scoring.
The explanation lies in Goodhart's law:
Goodhart's law states that the moment an index is used to allocate jobs, grants, or promotions, optimization pressure descends on it and its correlation with real quality begins to decay.
In 1998, four institutions — Zhejiang University, Zhejiang Medical University, Hangzhou University, and Zhejiang Agricultural University — merged to form the present-day comprehensive ZJU. Because volume-based bibliometrics reward size mechanically, if you fuse a flagship university with a medical school, an ag school, and a comprehensive university. you've created one of the largest research-producing bodies on eartH. ZJU now carries something like 314,000 academic publications and 6.8 million citations in aggregate indexes. A big chunk of "being good at bibliometrics" is simply that bibliometric volume rewards bigness, and ZJU was assembled to be big.
On top of that SZJU built the most aggressive cash-for-papers machine in the world. In the 90's China launched an incentive regime that turned publication into literal income.
The sums were staggering: across China, first authors averaged more than $43,000 for a paper in Science or Nature, with the top reward reaching $165,000, and scientists at top universities could earn in excess of $100,000 per paper. At ZJU specifically, a single high-impact paper's bonus could run up to 20 times a professor's average annual salary. The system behind it is called 唯论文 (Only papers). It generated a national "SCI supremacy" culture, where promotions, hiring, funding, and prestige all keyed off SCI publication counts and impact factors.
ZJU was a frontrunner. In a landmark survey of Chinese university reward policies, Zhejiang University had issued five separate cash-reward policies, more than any other institution. Make the metric the currency of every career, attach five-figure bonuses, and you get exactly what you'd expect. ZJU optimized the hardest because it had the size.
Beijing eventually recognized the perverse incentives. In February 2020, the central government told institutions to stop paying researchers bonuses for publishing, as part of a national policy to cut incentives that reward quantity over high-impact work. The cash-bonus era was officially curtailed, but the institutional muscle built during 20 years doesn't evaporate overnight. ZJU still churns out papers like there's no tomorrow, and its citation trading culture is still alive.
If you want to get a clear picture, the Shanghai ARWU ranking, designed to avoid metrics gaming by using difficult-to-fake data (like the number of Nobel Laureates) provides a less biased view of global University rankings.
|
|
Scooped by
Gilbert C FAURE
June 15, 4:46 AM
|
How do we communicate about -- or as journalists, cover -- 3.5 million scientific studies per year?
|
|
Scooped by
Gilbert C FAURE
June 12, 2:52 AM
|
A medical student presented a dizzy patient to me last week, and when I asked for them differential they told me they'd already run it past an LLM. Vestibular migraine. Reasonable answer, probably even right. So I asked them to name three other things it could be and talk me out of each one... things went silent.
A Wolters Kluwer survey out this week put a number on that silence. Three-quarters of clinicians now use AI at least weekly, and 74% call losing their own critical thinking one of the biggest risks of the whole thing. The fear isn't abstract. A prior Mass General Brigham study of 21 models found they nail the final diagnosis more than 90% of the time when you hand them the whole case, and miss the differential more than 80% of the time when the picture is still incomplete. Sharp at the end of the workup, lost at the start, which is the only part that was ever hard.
So the plan is to hand the front of every case to the one player at the table who goes all in on the first card it's dealt. | 60 comments on LinkedIn
|
|
Scooped by
Gilbert C FAURE
June 11, 1:47 PM
|
One of the biggest mistakes researchers make is claiming a research gap without knowing what type of gap they have actually identified.
Not every gap is a “lack of studies.”
Sometimes the gap is:
📌 A missing theory (Theoretical Gap)
📌 A different setting or country (Contextual Gap)
📌 Outdated evidence (Temporal Gap)
📌 An underrepresented population (Population Gap)
📌 Missing variables or concepts (Conceptual Gap)
📌 New technologies creating new opportunities (Technological Gap)
📌 Weak methods in previous studies (Methodological Gap)
📌 Findings that have not been translated into practice (Practical Gap)
The quality of your research is often determined by how clearly you identify and justify the gap it seeks to address.
Remember:
A strong research gap leads to a strong research question.
A strong research question leads to impactful research.
Before starting your next study, ask yourself:
“What specific gap am I trying to fill?”
Follow David Innocent for more research, evidence synthesis, and academic excellence insights.
|
|
Scooped by
Gilbert C FAURE
June 11, 1:11 PM
|
Nutritionally inadequate diets are among today’s greatest challenges to both public and planetary health. However, interventions aimed at changing eating behaviour in the long term have shown limited effectiveness, potentially because research has typically conceptualized eating behaviour as an individual activity despite its fundamentally social nature. In this Review, I argue for the importance of understanding eating within its natural social contexts to achieve effective, long-term change. I conceptualize eating as a social activity, review the current relevant theories, and synthesize the forms and dimensions of eating in its natural social context. Current and emerging methods for measurement and analysis are available that can capture eating in real-world settings. Empirical evidence shows that eating with others is more common than eating alone; eating takes place within specific social contexts and broad social systems; and eating serves central social functions. Researching eating behaviour in its natural social context could help to overcome the shortcomings of current theories and improve behaviour change interventions, to the benefit of health and well-being. Beyond meeting a basic need, eating behaviour shapes human health and environmental outcomes. In this Review, Mata highlights the fundamentally social nature of eating and describes how to integrate this evidence into current research on behaviour change.
|
|
Scooped by
Gilbert C FAURE
June 11, 10:15 AM
|
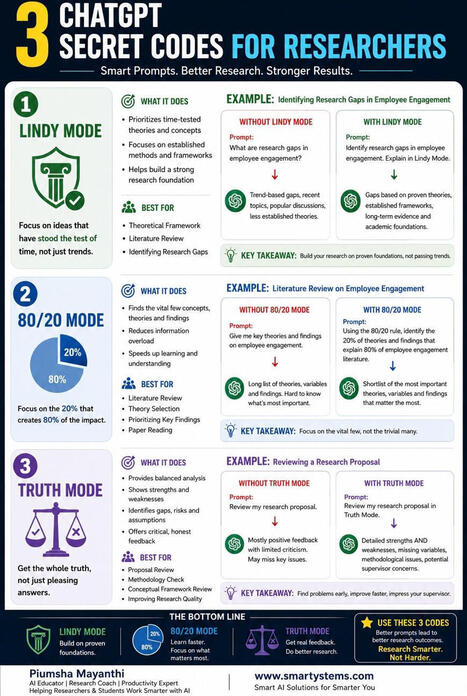
Most researchers are using ChatGPT like a search engine.
The problem?
The quality of the answer depends on the quality of the instruction.
In this infographic, I share 3 simple ChatGPT prompt techniques that can significantly improve your research workflow:
✅ Lindy Mode – Focus on proven theories, established frameworks, and long-standing academic foundations.
✅ 80/20 Mode – Identify the small number of concepts, theories, and findings that explain most of a research field.
✅ Truth Mode – Find weaknesses, missing variables, methodological issues, and potential supervisor concerns before submission.
Whether you’re working on a thesis, dissertation, literature review, journal article, or research proposal, these prompt techniques can help you think more critically and work more efficiently.
Remember:
📌 Lindy Mode = Strong Foundations
📌 80/20 Mode = Faster Learning
📌 Truth Mode = Better Critical Thinking
Which one would you use first?
Follow Piumsha Mayanthi for more AI, research, and academic productivity insights.
#Research #AcademicResearch #ResearchMethods #ThesisWriting #Dissertation #LiteratureReview #PhDLife #PhDStudent #GraduateSchool #Researcher #HigherEducation #Academia #ScientificResearch #ResearchTips #AcademicWriting #AI #ArtificialIntelligence #ChatGPT #GenerativeAI #AIForResearch #ResearchProductivity #DataAnalysis #EducationTechnology #MachineLearning #OpenAI
|
|
|
Scooped by
Gilbert C FAURE
June 21, 3:59 AM
|
The impact factor (IF) is a limited metric. It's flawed.
Yet, it's influential. Less influential than many think, but more influential than it should be.
It's up to us -- the scientific community -- to avoid undue reliance on limited metrics and support broad and rigorous research evaluation.
This editorial makes specific suggestions that can help reduce undue influence of the IF.
We are all, in a sense, co-authors of the IF. It is not a number that descends from on high; it emerges from millions of individual citation decisions made by researchers like you. If we collectively cite the work that matters to us, in the journals that serve our field, the metrics will follow. We also have a collective responsibility to challenge how IF is used: in grant reviews, in hiring decisions, in promotion committees. If we believe that research should be judged on its own merit, we need to act on that belief, not just as editors, but as reviewers, as panel members, and as colleagues.
|
|
Scooped by
Gilbert C FAURE
June 20, 9:04 AM
|
This article argues that despite the remarkable advances of artificial intelligence (AI) in medicine —including demonstrated capabilities in image recognition, diagnosis, treatment planning, and even empathic communication in controlled settings—the core of medical practice remains irreducibly...
|
|
Scooped by
Gilbert C FAURE
June 19, 1:18 PM
|
Félicitations la Haute Autorité de Santé pour cette initiative !
L'IA prend une place de plus en plus importante dans les recherches santé des Français
👇
|
|
Scooped by
Gilbert C FAURE
June 19, 4:29 AM
|
Regrettably, I have to inform you that academia has made itself redundant.
This might be one of the biggest scandals I can imagine.
I’m probably just like you. I studied science because I was interested in how the world works.
> But then you enter the academic system...
Publication pressure and paper mills are challenges. But the real problem is hidden somewhere else:
Imagine someone repeatedly fakes western blots, assays, and microscopy images. You would assume that this would have consequences.
Consequences? Unlikely nowadays.
Leonid Schneider tried to get the fraudulent work of a professor corrected.
He wrote to the publishers. They said they would look into it, but never got back to him. Repeated follow-ups were met with silence, even from Nature!
He wrote to the funders. Their unbelievable response in this case:
You highlighted four fraudulent papers, but only one was funded by us. Thus, we have no responsibility in this case.
The university?
They don’t want to admit that their PIs fabricate data. Therefore, wrongdoing is covered up.
What about the scientists?
When the good professor received new funding (even after these wrong-doings were flagged), he moved to a new field.
When warned, scientists there didn’t want to endanger their reputation by speaking up.
And it’s not just a problem of a few individual cases.
In another great article written by Sholto David, he outlines how several papers published microscopy data for an entirely wrong antibody!
They stained a cytoskeleton protein instead of a nuclear one.
Yet the papers were still published in journals like Nature.
A friend of mine accidentally discovered that someone in their group had falsified data for an upcoming publication.
After the group leader heard about this, he wasn’t even eager to kick the person out.
A colleague of mine received a paper with completely falsified data for publication in their journal.
Of course, they rejected it. A little while later, he discovered the same paper, with different fake images, in another journal - a well-known journal.
During my master’s, a supervisor of mine once shared that, for their publication in a high-ranking Nature journal, none of the authors could even retrieve the primers for the PCR.
Yet it was a big story with many collaborating authors, so nobody cared.
But to my mind, the nail in the coffin comes from Thermo Fisher.
These guys falsified blots for their antibodies by copying or deleting bands.
And even after this was reported on LinkedIn, with thousands of people seeing it, you can still find the very same graphs online!
Why? Because nobody cares!
People cheat everywhere. But we have reached a point where even institutions would rather protect their image than talk about it.
Would you share your experience with scientific fraud?
We have to address this issue together.
#STEM #PhDLife #AademicPublishing #DataFabrication | 24 comments on LinkedIn
|
|
Scooped by
Gilbert C FAURE
June 18, 11:18 AM
|
Organisez votre succession sereinement
|
|
Scooped by
Gilbert C FAURE
June 16, 8:42 AM
|
|
|
Scooped by
Gilbert C FAURE
June 16, 4:03 AM
|
A new paper in Nature Medicine reported that general AI like ChatGPT and Gemini outperformed the specialized medical AI tools that hundreds of thousands of doctors use every day, including OpenEvidence and UpToDate. Over the weekend OpenEvidence, a company valued at $12 billion, fired back with a public post calling the study fatally flawed and conflicted. They turned the comments off. The authors are defending their headline. Thousands of people are resharing a screenshot of one bar chart and picking a side.
Set the ranking aside and look at safety.
All six systems hallucinated at the same low rate. The specialized clinical tools were no more likely to invent a fact than ChatGPT, and no less. On the one measure that should decide whether a tool is safe near a patient, there was no real difference.
But one of those clinical tools, UpToDate, refused to answer one in five physician questions, where the general models almost never refused. The study counts that refusal as a failure.
Here is what it never checks. When a real clinical question arrives without enough information to answer safely, refusing is the right move, not a defect. The paper does not tell us how many of those refusals were appropriate caution, or whether the models that answered every single time were confidently filling gaps they should have left open.
That is the study I want to read. This is not it.
Would you rather your clinical AI guess, or tell you when it cannot say? | 39 comments on LinkedIn
|
|
Scooped by
Gilbert C FAURE
June 15, 4:49 AM
|
|
|
Scooped by
Gilbert C FAURE
June 15, 4:35 AM
|
When does aging really accelerate?
This month's Editor's choice for the Journal of Gerontology, Series A: Medical Sciences is: "Finding the turning point in aging: a comparison of physical, cognitive, and psychological trajectories among centenarians and non-centenarians" by Erfei Zhao, Jennifer Ailshire, Jung Ki Kim, and Eileen Crimmins at USC Leonard Davis School of Gerontology.
Using nearly three decades of data from the Health and Retirement Study, the authors examine how health trajectories unfold among people who survive into their 70s, 80s, 90s, and beyond 100 years of age.
I enjoyed reading about their focus on identifying the tipping point at which decline begins to accelerate across multiple domains of health.
Their findings challenge the notion that exceptional longevity simply reflects slower aging. Authors suggest that many centenarians experience a prolonged period of relative resilience, followed by a compressed phase of decline late in life.
Understanding when these turning points occur has important implications for public health, clinical care, and the design of interventions aimed at extending not just lifespan, but healthspan.
Congratulations to the team on an important contribution to the science of healthy aging and longevity.
You can read the article here: https://lnkd.in/gzYZ8WZQ
This work was also featured in Trojan Talks: https://lnkd.in/gz-AQFdW
#HealthyAging #Longevity #Centenarians #Healthspan #Gerontology #AgingResearch #PopulationHealth #PublicHealth #CognitiveAging #SuccessfulAging #HealthTrajectories #ResearchHighlights
Gerontological Society of America (GSA), OUP Academic
Megan McCutcheon, Kathleen Jackson, Judie Lieu, Gustavo Duque
|
|
Scooped by
Gilbert C FAURE
June 12, 2:38 AM
|
A figure in the news last month stopped me short: Reuters reported that one in two young people in Europe have used an AI chatbot to discuss something intimate or personal. This is a remarkably high number of young people exposing their vulnerabilities to essentially unregulated technologies driven by commercial interests.
Yet the more I thought about the findings, the less interested I became in the technology, and the more I found myself drawn to understanding the behavior.
There is no doubt that the question of whether AI is helping or harming young people is important. But strikingly, the same surveys show that young people don't fully trust AI yet turn to it anyway. What is AI providing that so many are struggling to find elsewhere?
Behavioral science offers a useful lens here. A chatbot answers the instant a teenager reaches for it, skipping the long chain of steps that help-seeking in the real-world demands. There is no appointment, no waiting, no travel, no risk of judgment. People, especially adolescents, gravitate toward whatever asks the least of them in a difficult moment. And each time the chatbot responds, instantly, it rewards the reach, making the next turn to it more likely.
Why young people reach for AI, even while doubting it, is a question anyone building or funding mental health systems should be asking. Their behavior reveals the gaps in the systems surrounding them, and points to where the work urgently needs to begin. I make that argument here.
#MentalHealth #AdolescentHealth #BehavioralScience #AI #DigitalHealth #YouthMentalHealth #NCDs #HLM4
|
|
Scooped by
Gilbert C FAURE
June 11, 1:15 PM
|
Honestly, it's not that bad publication... | 45 comments on LinkedIn
|
|
Scooped by
Gilbert C FAURE
June 11, 10:30 AM
|
We do not let a doctor read an ultrasound without training and certification, yet a medical AI now used by about 65% of American doctors entered clinical practice with neither. I asked the tool about its own funding and conflicts of interest, and it refused to answer.
|
|
Rescooped by
Gilbert C FAURE
from Going social
June 11, 9:42 AM
|
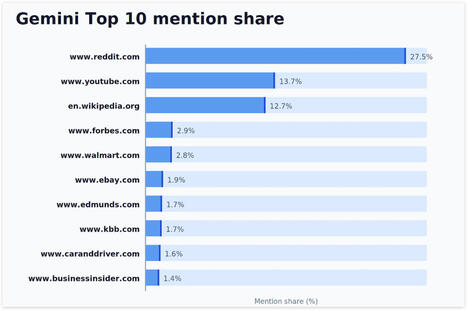
Chaque IA a ses sources de prédilection : Amazon chez Copilot, YouTube chez Perplexity, Reddit chez Gemini... Mais un trio s'impose presque partout.
Via Marco Bertolini
|







![Turns out AI tools erode abilities very quickly... Nature says: 1. Colonoscopy study [1]: Highly experienced physicians had is a 21% relative decline in finding adenoma when they couldn’t acces... | Notebook or My Personal Learning Network | Scoop.it](https://img.scoop.it/3crGuiidAiZXFGXAW0FX3zl72eJkfbmt4t8yenImKBVvK0kTmF0xjctABnaLJIm9)