"If you like interesting snippets on all sorts of subjects relevant to academia, information, the world, highly recommended is @grip54 's collection:"
La curation de contenus, la mémoire partagée d'une veille scientifique et sociétale
Gilbert C FAURE's insight:
... designed to collect posts and informations I found and want to keep available but not relevant to the other topics I am curating on Scoop.it (on behalf of ASSIM):
because we have a long standing collaboration through a french speaking medical training program between Faculté de Médecine de Nancy and WuDA, Wuhan university medical school and Zhongnan Hospital
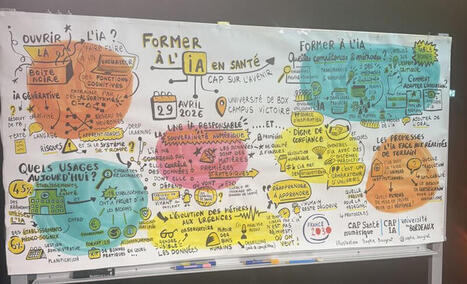
Comment enseigner l’IA en santé ? Une belle journée autour du symposium organisé par CAP Santé numérique - université de Bordeaux et CAP IA - université de Bordeaux pour évoquer l’enseignement de l’IA en Santé. Nous avons un véritable défi à relever pour la formation des étudiants et des enseignants/formateurs! Une fresque générée en direct par une artiste Sophie Bougrat, facilitatrice graphique, résume le symposium et le tout sans aucune IA générative!
Merci à tous les intervenants Xavier Blanc Philippe Nauche Frederic ALEXANDRE Bonnemains Carole Gouvernance stratégique de la Data IA Caroline Receveur Cedric Gil-Jardine Fleur Mougin Vianney JOUHET Laurent Beaumont Ingrid MONTEIL Christelle SOARES Laurent Simon Olivier Cousin Andy Smith Jean Benoit Corcuff et l’équipe organisatrice en particulier Ines Hizebry Camille Bachellerie Hugo Corvaisier
"The adoption of artificial intelligence (AI)-powered tools is accelerating rapidly across all layers of healthcare systems. Predictive models, decision support tools and generative tools have entered clinical environments, and large language models are increasingly being used by the general public to seek medical information and advice. Yet evidence that AI tools create value for patients, providers or health systems remains scarce."
"Without a clear connection between claims and evidence, medical AI risks being adopted faster than its real value can be understood."
There are numerous examples of transformational technologies & products introducing substantial harms before broad based benefits. (or before we could mitigate harms). We should avoid adopting faster than we can adapt.
🚨 561 pages c'est beaucoup Peut-être un peu trop pour un jeudi matin 😁
Alors avec mon collègue Claude, nous vous avons préparé une page de synthèse interactive de ma thèse : son fil conducteur, ses trois contributions (pragmatisme, protocole F-T-T, modèle H-O-T), ses points saillants, le tout en quelques minutes de lecture.
Pour ceux qui veulent aller à l'essentiel avant (éventuellement) de plonger dans le document complet, c'est par ici : https://lnkd.in/ggYwvrWH
(cc Nicolas MOINET Christian Marcon Audrey Knauf Stephane Goria Philippe clerc et Olivier Le Deuff)
This work brought together collaborators across institutions to explore how medical students engage with blended learning, self-regulated learning, and digital resources in anatomy education. Our findings reinforce the growing shift toward flexible, student-centered learning environments, with strong emphasis on blended and online modalities, as well as the critical role of self-regulated learning in shaping future physicians.
I would like to sincerely thank all co-authors for their collaboration and shared vision in advancing medical education research. It was truly a pleasure working together across institutions and contexts.
Grateful for this meaningful collaboration and looking forward to building on this work in future projects. #MedicalEducation #AnatomyEducation #BlendedLearning #GMU #Research #HigherEducation
Both physicians and the public demand medical AI to outperform human clinicians, at accuracy levels most current systems cannot yet reach.
1️⃣ A Swedish survey of 223 physicians and 155 adults measured the minimum AI accuracy they would accept across three clinical scenarios.
2️⃣ Both groups required AI to achieve higher sensitivity than human clinicians in all three scenarios tested.
3️⃣ Physicians required AI to catch 11 more chest pain emergencies per 100 than the human nurse baseline; the public demanded 16 more.
4️⃣ Both groups set a median specificity target of 50% for AI in triage, well above the 30-34% human nurse benchmark.
5️⃣ For electrocardiogram interpretation, where human specificity was already 99%, both groups set the same standard for AI.
6️⃣ Across all scenarios, 74-91% of respondents demanded stricter accuracy from AI than they would accept from a human clinician.
7️⃣ The public was polarised on specificity: many demanded either 100% or 0% referral rates, both impractical for real clinical tools.
8️⃣ 72% of physicians and 53% of the public had tried AI chatbots; 8.5% of physicians had used chatbot responses in real clinical decisions.
9️⃣ Most respondents reported moderate trust in AI chatbots, matching physicians' trust in established electrocardiogram interpretation software.
🔟 The thresholds both groups demand exceed most existing AI diagnostic systems, revealing a wide gap between expectation and real-world performance.
✍🏻 Rasmus Arvidsson, Jonathan Widen, Lina Al-Naasan, Ronny Kent K Gunnarsson, Peter Nymberg, Charlotte Blease, PhD, Anna Moberg, Par-Daniel Sundvall, Carl Wikberg, David Sundemo. Acceptable accuracy for medical AI: a survey of physicians and the general population in Sweden. BMJ Health & Care Informatics. 2026. DOI: 10.1136/bmjhci-2025-101899 | Open Access
🚨 124 Papers. Clinical AI Models Built on Data of Unknown Origin
A new analysis linked more than 100 peer-reviewed studies to two widely used stroke and diabetes datasets with unknown origins and data patterns inconsistent with real patients. Some downstream models may already have reached clinical or public-facing settings.
Open data sharing is critical for AI progress. But in clinical AI, openness without provenance is not transparency.
Three points matter for implementation:
• Dataset provenance is part of model validity If the origin, collection process, and population are unclear, performance metrics are not interpretable.
• Robust dataset evaluation should be standard Basic checks (missingness patterns, value distributions, duplication) can already flag non-credible data.
• External validation is not optional Models should be tested across independent external datasets.
👉 What should be the minimum standard before a clinical prediction model is considered deployable?| 40 commentaires sur LinkedIn
Most researchers are using AI tools for literature reviews the wrong way.
They ask AI to “find papers” and hope for the best.
That is not a literature review strategy. That is search outsourcing.
Used properly, AI can save time, improve structure, and help you think more clearly.
But it should support your judgment, not replace it.
Here are practical tips I give research students:
1. Start with your question, not the tool A vague research question creates vague results. Define your topic, population, variables, or context first.
2. Use AI for search expansion Ask AI for synonyms, related terms, alternate spellings, and discipline-specific keywords. This improves database searching.
3. Use AI to screen faster Paste abstracts and ask for relevance against your inclusion criteria. This helps with first-pass screening.
4. Use AI to compare studies Ask it to summarise differences in methods, sample sizes, findings, and limitations across papers.
5. Use AI to identify patterns Good reviews are not summaries. Ask: What themes repeat? Where do studies disagree? What populations are ignored? What methods dominate?
6. Verify every citation Never trust references blindly. Cross-check authors, journal, DOI, and publication year.
7. Use AI for structure, not authorship AI can help organise themes and draft outlines, but your interpretation must lead the review.
8. Keep a decision trail Document search terms, databases, inclusion criteria, and why papers were included or excluded.
Use AI as an assistant, not as a scholar.
PS: What AI tool has actually helped your literature review most? Share in the comments
REPOST to help others.
Follow Dr Priya Singh, Founder Research Made Clear for more insights
For research tutorials and AI tool guides, subscribe to my YT channel: https://lnkd.in/e8zWuWV2 | 24 comments on LinkedIn
Une étude du Imperial College of London et de Internet Archive révèle que plus de la moitié des sites web est généré en partie ou totalement par l’IA (52,9%), en forte augmentation. #GenAI https://lnkd.in/eac76_aG | 12 comments on LinkedIn
✍️🎓Dear PhD Scholar:Starting your first research article can feel overwhelming… but with the right steps, it becomes simple and structured. Here’s your easy roadmap 👇
🔹 1. Choose the Right Topic
Pick a clear, focused, and interesting research problem.
Your topic should answer a question or solve a gap.
🔹 2. Conduct a Literature Review
Read existing studies to understand what’s already done—and where your research fits in.
🔹 3. Define Your Research Objective
What exactly are you trying to find?
Be specific and concise.
🔹 4. Design Your Methodology
Decide how you will collect and analyze data (qualitative, quantitative, or mixed methods).
🔹 5. Collect & Analyze Data
Follow your method carefully and ensure your data is accurate and reliable.
🔹 6. Write the Structure
A standard research article includes:
Abstract
Introduction
Literature Review
Methodology
Results
Discussion
Conclusion
🔹 7. Interpret Your Findings
Explain what your results mean and how they contribute to existing knowledge.
🔹 8. Cite Properly
Always give credit using the required citation style (APA, MLA, etc.).
🔹 9. Edit & Proofread
Refine your writing for clarity, grammar, and flow.
🔹 10. Choose the Right Journal & Submit
Select a suitable journal and follow its guidelines carefully.
You don’t need to be perfect to start… you just need to start to become perfect.
😊Happy Researching & Best of Luck, Future Scholars! 👍
More about paper mills and authorship for sale in today's Science issue. Need one more paper on your CV? Price depends... from $57 to $5600. Of course, this paper has a good chance of being entirely fabricated (fake) but who cares?
If you think this is a minor problem: - 18,710 advertisements related to authorship for sale were traced to Russia, Ukraine, Uzbekistan, India... (those were mostly written in English and do not count paper mills in other countries such as China) - A study published in January in The BMJ found that nearly 10% of 2.6 million cancer-research papers published from 2019 to ’24 seem to be paper mills products. That's... 250,000 papers. And this crap is used to train AI.
Publisher should aggressively fight this problem. But they won't unless it hurts their business... and I am not only talking of predatory publishers. Too many problems with many journals handled by "respectable" publishers with comfortable margins.
Link to the Science paper in comments. | 13 comments on LinkedIn
Qu’est-ce qu’un algorithme est capable de vous montrer, à vous ou à vos proches ? Ouest-France a construit un bras robotique pour scroller sur TikTok en continu afin de le savoir. Pendant 100 heures, la machine a visionné des milliers de vidéos. Certaines donnent des conseils pour s’affamer, d’autres enseignent comment faire un nœud coulant. D’autres encore renvoient vers des contenus pédocriminels sur Telegram. Enquête sur une mécanique qui amplifie tout, y compris le pire.
#tiktok #algorithme #enquete
00:00 Introduction — Marie, 15 ans 2:05 Un robot 4:24 L'algorithme de TikTok 5:25 Make-Up et cuisine 8:12 Dans la bulle mascu 10:09 les Tartariens 11:37 La faille dans le système 16:30 Des vidéos contrevantes aux règles de TikTok 16:28 Les conséquences humaines des algorithmes 20:34 Le compte sans nom 21:51 La réponse de TikTok 22:10 : Ce qu'un algorithme est capable de vous montrer --------------------------------------------------------------------------- Retrouvez toute l’actualité sur :
🌳 🤩 Magnifique ! L'ONF (Office National des Forêts) a publié une carte interactive avec une sélection de 30 forêts exceptionnelles à découvrir en France.
Les forestières et les forestiers de l'ONF les racontent en images, en vidéo et avec passion.
Voici cinq choses à savoir sur les forêts françaises.
1. Le patrimoine forestier français a connu une extension forte et continue depuis 150 ans et atteint désormais une surface de 17M d'hectares soit 31 % du territoire français (source : IGN https://buff.ly/42BakSd); C'est la 4ème forêt européenne après la Finlande, la Suède et l'Espagne - le niveau de boisement de la France est revenu à celui du XVe siècle. Voir cette infographie de Jules Grandin et Clara DeAlberto https://buff.ly/3J46xWC
Mais les massifs sont jeunes, leur vitalité et leur résilience pose problème puisque 50% des arbres ont moins de 60 ans et 20% seulement ont plus d'un siècle.
2. La #Corse est la région la plus boisée de métropole - 63% et la forêt d'Orléans est la plus grande forêt domaniale (appartenant à l'Etat) en France métropolitaine.
3. Les chênes sont les arbres les plus répandus en métropole. Avec 190 essences d'arbres, notre forêt métropolitaine compte près de 75% de toutes les essences présentes en Europe. C'est fou !
4. Les forêts d’Outre-mer représentent près de la moitié de la superficie forestière, soit 8 millions d’hectares, et abritent la biodiversité la plus riche.
5. En métropole, 75% des forêts sont privées. Les 25% restants sont des forêts domaniales ou des forêts appartenant à des collectivités ou établissements publics.
Mais globalement, nos forêts ne sont pas en bon état. Elle pourrait cesser de stocker du carbone.
Les arbres interviennent à plusieurs titres dans l'équation climatique. Ils sont utiles pour l'atténuation (en jouant un rôle de stock de carbone) et pour l'adaptation (en jouant un rôle de régulateur climatique, dans le cycle de l'eau, des sols et de la biodiversité).
Mais les forêts françaises sont, comme les autres forêts du monde, soumises à une pression croissante. Elles absorbaient 30M de tonnes absorbées en 2020, soit environ 7,5 % des émissions nationales. Mais c’est deux fois moins qu’il y a dix ans.
En terme de biodiversité en 2023, 17 % des oiseaux de forêt, 7 % des mammifères, 8 % des reptiles et amphibiens, 12 % des papillons sont menacés d’extinction (Source : IGN)
Les effets des sécheresses se font sentir sur les écosystèmes. La tendance est à la monoculture et les essences ne sont plus aussi résilientes qu'autrefois.
Alors pensons nos forêts dans un souci de variété et de diversité.
Les arbres tissent des liens entre les règnes du vivant. Soyons clairs, nous ne pouvons pas nous en passer.
#foret #arbre #onf #france
🥚 Petite annonce ! Mon futur livre a besoin de votre soutien. Contactez moi si vous souhaitez m'aider à préparer la campagne => https://buff.ly/P06fQIn| 10 commentaires sur LinkedIn
Je viens de découvrir Remotion (https://www.remotion.dev) qui permet de créer des vidéos en React. De plus, c'est complètement gratuit !
Ça s'installe dans le terminal (vous tapez : npx create-video@latest) et puis après vous demandez à votre IA préférée (vous me connaissez, je passe évidemment par OpenClaw) et il vous crée votre vidéo en quelques secondes.
Je viens de faire un essai avec une leçon de grammaire très simple sur la fonction sujet et voici le résultat. 👇 C'est du NotebookLM++ que vous pouvez modifier à la volée. Demandez juste à votre bot de faire les changements voulus.
J'avais déjà un prompt se déclenchant tous les matins pour produire des exercices de grammaire et des dictées (y compris au format MP3). J'ai maintenant les leçons au format vidéo !
We finally have a way to measure AI harm in clinical practice.
We usually judge clinical AI the same way we test medical students: exams, scores, and knowledge benchmarks. But here's the issue—none of that tells us one critical thing: 👉 How much harm can this AI actually cause?
𝗧𝗵𝗮𝘁'𝘀 𝘄𝗵𝗮𝘁 𝗡𝗢𝗛𝗔𝗥𝗠 𝗰𝗵𝗮𝗻𝗴𝗲𝘀. Released just months ago by Stanford and Harvard researchers, NOHARM is the first framework designed to measure real clinical risk, not just performance. ________________________________________ 𝗛𝗲𝗿𝗲'𝘀 𝘄𝗵𝘆 𝗶𝘁 𝗺𝗮𝘁𝘁𝗲𝗿𝘀: 🔬 It introduces a common language for safety AI outputs are graded by severity of harm (mild → severe), based on expert consensus across real clinical cases.
📊 It enables true benchmarking Over 30 AI models evaluated head-to-head using the same safety standards—with a public leaderboard for transparency.
⚠️ It captures the errors that actually matter Not just wrong answers, but: • Harmful recommendations (commission) • Missed appropriate care (omission — the majority of severe errors)
📈 It gives decision-ready metrics Including Case Harm Rate and Number Needed to Harm—tools clinicians and hospitals can actually use before adopting AI. ________________________________________ 𝗧𝗵𝗲 𝗸𝗲𝘆 𝗶𝗻𝘀𝗶𝗴𝗵𝘁? Traditional benchmarks only moderately correlate with real-world safety (r ≈ 0.6). Meaning: high scores ≠ safe care.
NOHARM isn't perfect! but it's the first real step toward accountability in clinical AI.
Before integrating AI into your practice, ask yourself: 𝗛𝗼𝘄 𝗺𝘂𝗰𝗵 𝗵𝗮𝗿𝗺 𝗮𝗿𝗲 𝘆𝗼𝘂 𝘄𝗶𝗹𝗹𝗶𝗻𝗴 𝘁𝗼 𝘁𝗼𝗹𝗲𝗿𝗮𝘁𝗲? ________________________________________ 📄 Paper: arxiv.org/abs/2512.01241
Research Details: Validated across 100 real eConsult cases (10 specialties) with 12,747 expert annotations on 4,249 management options. 95.5% expert concordance on severity classifications.
N.B. MAST (Medical AI Superintelligence Test) is ARISE AI's comprehensive benchmarking platform for advanced clinical AI evaluation, with NOHARM serving as its core harm-assessment framework. Together on bench.arise-ai.org, they rank 30+ models using physician-validated metrics from 100 real cases across 10 specialties, focusing on safety (Case Harm Rate, NNH) beyond traditional accuracy benchmarks.
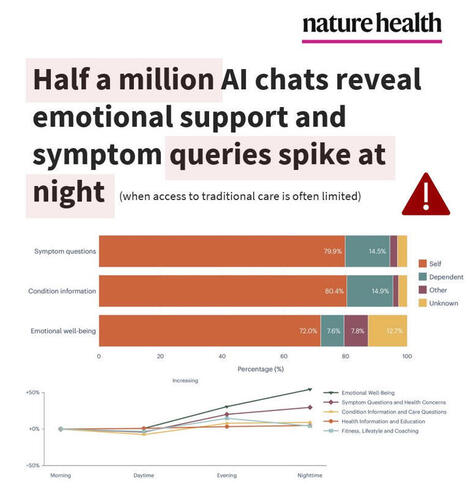
NEW STUDY🧨Half a million AI chats reveal emotional support and symptom queries spike at night, when access to traditional care is often limited.
What can Microsoft Copilot tell us from over HALF A MILLION (n = 617,827) de-identified health conversations?
-- Nearly 1 in 5 chatbot conversations involved personal symptoms, conditions, or test interpretation
-- About 1 in 7 personal health queries were about someone else (child, parent, partner)
-- Symptom queries happened mostly on mobile (15.9%) vs desktop (6.9%), whereas health-related research support was mostly on desktop (16.9%) vs mobile (5.3%)
-- Nighttime spikes on emotional support queries (from 3.3% morning to 5.2% nighttime) and symptoms/health concerns (from 10.6% morning to 13.4% nighttime)
These nighttime spikes (when healthcare access is most limited) may amplify user risk, as highly actionable LLM outputs are more likely to be relied on without professional support.
The authors did acknowledge safety RISKS in that mainstream AI models (ChatGPT, Google Gemini, Microsoft Copilot) may perform well on medical exams but NOT always on real-world emergency triage or decision-making, yet users keep turning to them for health advice and emotional coping.
The authors seem to take these risks seriously and concluded:
“From a safety perspective, the personal health intents identified here—such as symptom assessment, condition management and emotional well-being—arguably define categories in which the consequences of conversational AI responses are greatest and where investment in response quality and safety measures should be concentrated.”
Translation: we still have a long way to go and investment needs to be focused on the highest-risk use cases to make these models safe for public use, in a domain with near-zero tolerance for harmful errors.
Study in Nature Health linked below 👇 | 18 comments on LinkedIn
If you want to build healthcare AI at scale, follow these 10 Chinese Healthcare AI companies.
1. AQ AI Health App
· 30M monthly active users, 10M daily health consultations · 27M health questions answered in 2025, national health OS infrastructure · 50%+ users from Tier 3+ cities, true population-scale deployment
2. XtalPi Inc.
· $59.9B drug pipeline deal with Harvard spinout (largest ever) · 300+ robotic workstations deployed globally, operating 24/7 · AI + quantum physics + robotics integrated platform
3. JD.COM (JD Health)
· 50M+ users served by AI doctor agents · Full-cycle health management from prevention to chronic disease · 2.2M+ patient encounters at partner hospitals
4. United Imaging Healthcare
· 20+ FDA-approved AI-powered medical devices · 92% diagnostic accuracy (beats industry SOTA by 10%+) · Hardware + AI + clinical workflows fully integrated
5. BGI Genomics
· Fully automated "dark lab" running 1+ year, zero human intervention · Sample → sequencing → analysis → storage, end-to-end automation · Deepseek-R1 and Evo 2 AI models integrated into platform
6. MicroPort
· World's first LLM-autonomous surgery completed (Dec 2025) · AI-powered surgical planning, imaging fusion, automated operations · SAIL Award winner (Super AI Leader)
· 150+ hospitals deployed, 60+ clinical scenarios covered · 20+ specialized medical AI agents operational · Medical LLM WinGPT 3.0 with clinical reasoning capabilities
9. 美年大健康
· 600 examination centers, 30M annual checkups · AI-driven preventive care and longevity medicine services · Strategic partnership with Alibaba DAMO Academy for cancer screening
10. Kingmed Diagnostics
· 30PB multi-modal medical data accumulated · 15M+ monthly API calls for diagnostic intelligence · 60+ AI agents deployed, 70K monthly active physician users
These 10 companies didn't just build AI.
They built deployment infrastructure for 1.4 billion people.
Data infrastructure + full-stack systems + deployment speed.
The models are good enough.
The systems are what matter.
P.S. Which company's approach surprises you most?
Le Shen | Jian Ma | Daniel Wan | Kathy LIU | Jeremy (Sujie) cao | Jasmine Liang | 徐济铭 | Terry Zhao | 郭璋 | Shen Luan
To get content containing either thought or leadership enter:
To get content containing both thought and leadership enter:
To get content containing the expression thought leadership enter:
You can enter several keywords and you can refine them whenever you want. Our suggestion engine uses more signals but entering a few keywords here will rapidly give you great content to curate.







 Your new post is loading...
Your new post is loading...