Audrey Schulman on the Limits of Scientific Terminology
By Audrey Schulman
April 21, 2022
Carl Linnaeus invented our taxonomy system. Like God in a lab coat, he used the system to classify and name species from polar bears (Ursus maritimus) to garlic (Allium sativum). Potentially, he took on this work because he himself was renamed three different times.
I’ll call him Carl Nimaeus—the name he was given at birth. I don’t know which name he preferred, which name he would have turned at most quickly if it was called out behind him.
He was born in 1707 in Sweden, back when the patronymic system was still in use. This meant his last name, Nimaeus, came from his father’s first name, Nils. His sisters were given the female version, Nimaea. This word was not so much a name, as a prepositional phrase: of Nils. The child’s identity derived from being the property of the dad.
*
As a child, I regularly visited my uncle’s farm in Quebec. There were feral cats everywhere, pouncing on mice in the fields, cleaning themselves on the stone wall, giving birth to mewling kittens in the hay loft.
During the winter, the cats searched for warmth. They’d sleep curled up on a horse’s back in its stall. They’d press against the farmhouse windows, staring in, their coats puffed out and eyes as big as a raptor’s. When the car drove up and parked, they’d jump onto a front tire to climb into the warm engine block. Each morning, before my uncle got into the car, he slapped the hood hard with his hand. The cats flew from the tire wells like rabbits from a hat. I did not ask if he did this to protect the cats or the engine.
None of these cats were named, any more than the chickens were. The cats were not considered individuals, but only tools to catch mice.
Each night, my aunt tossed the leftovers from dinner onto the driveway for the cats. The rest of their calories, they caught. Whenever the cats became so numerous that they became bony and desperate, my uncle would collect all the kittens he could find in a bag and take them down to the stream. That and the slap on the car hood was the extent of his care.
*
If the patronymic system had continued, Carl’s children would have received a different last name from his. This meant there could be no multigenerational reunions of his Of-Carl family. Instead, at the reunion, there’d be kids lining up for the barbecue with last names like Of-Lars, Of-Erik and Of-Peter.
This naming system worked well in a small town, but in a city, it could become difficult to determine which Hans Of-Thomas owed you the money.
*
In 1989, my uncle’s farm changed. He didn’t want to carry kittens down to the river anymore, so he asked my veterinarian sister to neuter the cats. Christmas morning, he caught them all and my sister anesthetized them. At one end of the kitchen counter, my aunt prepped the turkey, its legs splayed open for stuffing; at the other end, my sister worked on the splayed cats—both my aunt and sister humming along to Bing Crosby.
New terms can erode assumptions, allowing the mind to flow in unaccustomed directions.
After that, there were no new kittens. With fewer cats, my aunt and uncle began to recognize several and appreciate their personalities: the big hunter with the bent tail, the stray Siamese who cried like a baby. The next winter vacation, I noticed they let their favorite cats sneak into the house on particularly cold days.
*
With Swedish cities getting larger, the government was having difficulty collecting taxes—too many people with the same name. Thus, the government ruled that each family should rename itself, selecting a unique name to be passed down on the male side of the family. To attend university, Carl’s dad had to register his family’s new last name.
It’s possible he thought hard about it—this word that he and his wife and their kids and descendants would be known by, this name that would become famous, taught in biology classes for centuries. Or, perhaps, he was irritated with the paperwork and believed this new system was a fad. Maybe he did nothing more than glance out the window and write down the first thing he saw.
The family was named after the large Linden tree on their property. Carl’s last name became Linnæus.
Being named after a tree seemed appropriate since Carl loved plants from the earliest age. He loved wandering through the garden, memorizing details about organisms that did not move, becoming a walking botanical encyclopedia. If he lived in the present day, his ability to fixate on and memorize enormous amounts of arcane scientific information may have been considered a potential indicator of autism; however, back then, that diagnosis did not yet exist. Instead, he was simply a child who could retain enormous amounts of information about plants.
And there was a lot to retain, since experts didn’t agree on the names of plants or even how many species there were. One expert announced there were 12 kinds of daisies, naming several after his siblings. The next declared 14 species, named after his local streets. With no real system to the classification or names, the experts duked it out for popularity. Carl read them all, primarily in Latin, the language of learning. His teachers told his parents he would not amount to much—perhaps he could apprentice to a cobbler.
As Carl grew older however, one teacher (who knew some botany) recognized his knowledge and unswerving allegiance to logic, so Carl was allowed to attend university. By that point, he loved Latin and thus, at the age of 21, he registered himself for school as Carolus.
*
Most people don’t name their pets anymore based on physical attributes, no more Snowflake or Fluffy. The other day, waiting at a veterinarian’s office with my dog, I heard the receptionist phoning clients with appointment reminders. She said, I’m calling about Henry’s check-up. Or, Hey, Jeanie has a Tuesday appointment.
This trend toward giving pets human names comes from a change in why we want a pet. Never forget that order: a need changes our words, then those words change our thinking and actions.
In the appointment, the vet asked me if I was my dog’s “mommy” (this question was a trifle disturbing coming from a medical professional).
Throughout these shifts in naming conventions, cats and dogs have remained the same. What’s changed is the need the animals fulfill, and how we refer to them reveals that need. A tool to kill mice. A cuddly object. A surrogate child.
*
When Carl was young, there was no standardized spelling of words. There were no clear rules (I before E except after C), no national spelling bees showcasing children with eidetic memories asking, Language of origin? Spelling just had to be phonetic enough that the word was understood. Color was fine, as was Colour and Culler.
This must have irritated an exacting person like Carl. To give you an example of his character, in his mid-twenties, he visited Hamburg. The mayor showed Carl his most treasured possession, the taxidermied body of a many-headed hydra—a relic worth a small fortune. Carl examined the body and discovered the hidden sutures enclosing the bones of weasels in the skins of snakes. Without hesitation, he told the mayor. He believed everyone loved the truth like him. He was thrown out of town.
I’ve always thought there’s a large difference between being clever and being wise. Carl was a clever man, filled with facts. He could have triumphed on Jeopardy week after week, stating esoterica with speed. However, to paraphrase Einstein, being wise is less about answering a problem quickly, and more about having the good judgment to avoid the problem. At times, Carl wasn’t capable of that.
It’s possible that his society’s loosey-goosey imprecision with spelling and names was partly what motivated him to take on the task that made him famous: classifying and naming all of life in a logical way. He created a system based on each species’ unique unchanging characteristics. Perhaps he wished he himself had been named as thoughtfully.
Of course, Carl started with classifying and naming plants. He grouped them based on the number and type of pistils and stamens, whether the seedling had one leaf or two. Each category and species was named for what made it unique. A genus with poisonous levels of tropane alkaloids was called Atropa, after the Greek Fate responsible for cutting the lifeline. He named a species in that genus belladonna—beautiful lady—after the fact that women at the time took small amounts to dilate their pupils in a striking way. His names were infectious: easy to remember and useful.
He classified and named animals in the same way, using the similarity of physical structures. Chordata meant animals with backbones. Mammalia, a subgroup, were those with mammary glands.
He published these names in his first book Systema Naturae. It was just 14 pages long, but it went viral, its impact still felt today. He spent the rest of his life refining the concepts and details in his publications.
Other humans, however, continued to be sloppy. Carl’s name on his books ranged from Caroli to Carolo, from Linnæo to Linnaei—as though his publisher was unsure and making guesses, mumbling names at a cocktail party. And ironically, after his work became famous, Carl was reclassified again, this time as a noble. He was renamed Carl von Linné.
*
New terms can erode assumptions, allowing the mind to flow in unaccustomed directions.
The term super-spreader shifts how we feel stepping into a crowded room. Gig economy widens our focus on a single job. Structural racism changes how some of us see that high-school photo of the all-white AP class. Over time, new terms can widen our perceptions, changing how we think and act.
*
Dig a wide pit 15 feet down into the ground, then step back and you can see time.
In the dirt’s cross-section, each epoch is scribbled in a different color and density. Cambrian, Permian, Cretaceous.
There’s an official push to rename our current era: Anthropocene. A few millennia from now, archeologists digging in the ground will come to a different layer. Less pollen, fewer tree trunks, a vast reduction in the bones of wild animals. A layer of ripped aluminum foil and plastic bits and chicken bones and radiation from nuclear tests. Even sedimentary layers of the oceans floor will show changes, the circulatory system shifted, the current that distributes salt and temperature globally. We humans are writing our autobiography in the planet’s dirt. When looked at through the lens of geologic time, our speed isn’t that different from a meteor strike.
*
Terms can also narrow our perceptions. Consider the names we have for the living world, this complex biosphere that our existence depends on, that provides the food we eat and the air we breathe.
The environment? That’s like naming your child organism. Such a lack of love or awe. The term brings to mind an office cubicle, something generic you can disassemble and reshape as you wish.
*
One of Carl’s names was hated. He noticed all apes (including humans) had similar physical structures, so he put them in a single family and called that family Anthropomorpha: human-like.
This term created an uproar. The church considered humans to be made in God’s image. Classifying a gorilla as human-like, meant it should not be shot, stuffed, and hung on the walls. For a decade, people wrote Carl outraged letters, declaring the name a blasphemy and obviously wrong.
Probably, he’d angered many people over his lifetime, incidents like the one with the hydra. Perhaps, gradually, he’d learned how to react better. Or maybe the uproar went on too long. Whatever the reason, he gave up on Anthropomorpha. He denied the obvious similarities with other apes and grafted an imaginary branch called Homo (man) onto the tree of life. Perching humans all alone on that branch, he named our species sapiens, meaning wise.
Wise Man, was this unctuous praise or sarcasm?
*
In terms of our biosphere, is the word, nature, any better?
The way nature is used, it implies anything untouched by humans. Nature is something we watch on TV, or visit on vacation, something apart from us. But we are nature, in the same way a deer or orangutan or mushroom is. It roils in our lungs and hearts. If it goes wrong in our guts, we can end up in the hospital or morgue.
If we used a better word for our living miracle of a home, would our thinking change? If the word helped us understand our dependence on the biosphere for every inhalation and morsel of food, would our actions change? Name your dog Richard and it’s harder to mistreat him.
*
Carl, a man honest to a fault, had denied the truth. He created the genus of Homo sapiens to allow us to ignore all we share with other great apes: fingernails and French kissing, the rapid pant-pant of laughter and the ability to recognize ourselves in mirrors, to love our children and, at times, to die of grief.
What term should we use for our biosystem? We need a name both memorable and useful, one that viscerally conveys the importance of its health.
However, fossils and genetic sequencing have shown his original classification was close to right. Scientists have moved humans back onto the branch with the rest of the great apes, and then out onto the same twig with chimps and bonobos, who are both classified in the genus of Pan (chimpanzee).
It turns out we are genetically as similar to both of them as species of finches are to one another. There’s no justification for our genus. If we were honest, we would reclassify ourselves as Pan sapiens. Wise chimp.
But we are a chimp who has a single-minded focus on tools and facts, who has a much greater facility with answering problems quickly, than avoiding them. A chimp reminiscent of Carl, more clever than wise. Perhaps we should call ourselves Pan vorsustus. Clever chimp.
*
How do you evaluate us clever chimps? In the past we’ve focused on characteristics that made us unique—tool use or brain size. However, modern science has shown even molluscs can use tools. Dolphins, elephants and whales have larger brains for their body size. Even when we pick the criteria, we don’t win the competition.
And why do we insist on this competition? It’s like wondering if red blood cells are more important than liver cells. Outside the body, both become just a drying smear. It’s the system, not the parts, that matters. It’s time we became wise. To exist, we need mollusks, elephants and dolphins; we need trees, beetles and bacteria.
We are now using CRISPR to improve our health. Let’s use words to change how we think and act. What term should we use for our biosystem? We need a name both memorable and useful, one that viscerally conveys the importance of its health.
What about The Body? This gives an image even clever chimps can understand. The Body allows us to feel the damage. The Body has a rising temperature. Its circulation is slowing, oxygen levels lowering.
Perhaps with the term, The Body, we can change our actions so we write a better, longer autobiography in the dirt.
__________________________________
The Dolphin House by Audrey Schulman is available via Europa Editions.
"There’s an official push to rename our current era: Anthropocene. A few millennia from now, archeologists digging in the ground will come to a different layer. Less pollen, fewer tree trunks, a vast reduction in the bones of wild animals. A layer of ripped aluminum foil and plastic bits and chicken bones and radiation from nuclear tests. Even sedimentary layers of the oceans floor will show changes, the circulatory system shifted, the current that distributes salt and temperature globally. We humans are writing our autobiography in the planet’s dirt. When looked at through the lens of geologic time, our speed isn’t that different from a meteor strike.
*
Terms can also narrow our perceptions. Consider the names we have for the living world, this complex biosphere that our existence depends on, that provides the food we eat and the air we breathe.
The environment? That’s like naming your child organism. Such a lack of love or awe. The term brings to mind an office cubicle, something generic you can disassemble and reshape as you wish."
You might have thought about it, heard it. A lot. You might have even felt it: Dictionary.com's word of the year is "xenophobia."
While it's difficult to get at exactly why people look up words in dictionaries, online or on paper, it's clear that in contentious 2016, fear of "otherness" bruised the collective consciousness around the globe.
The Brexit vote, police violence against people of color, Syria's refugee crisis, transsexual rights and the U.S. presidential race were among prominent developments that drove debate — and spikes in lookups of the word, said Jane Solomon, one of the dictionary site's lexicographers.
The 21-year-old site defines xenophobia as "fear or hatred of foreigners, people from different cultures, or strangers." And it plans to expand its entry to include fear or dislike of "customs, dress and cultures of people with backgrounds different from our own," Solomon said in a recent interview.
The word didn't enter the English language until the late 1800s, she said. Its roots are in two Greek words — "xenos," meaning "stranger or guest," and "phobos," meaning "fear or panic," Solomon added.
The interest was clear June 24, within a period that represents the largest spike in lookups of xenophobia so far this year. That was the day of Brexit, when the UK voted to leave the European Union.
Searches for xenophobia on the site increased by 938 percent from June 22 to June 24, Solomon said. Lookups spiked again that month after President Obama's June 29 speech in which he insisted that Donald Trump's campaign rhetoric was not a measure of "populism," but rather "nativism, or xenophobia, or worse."
Solomon added that chatter about xenophobia goes well beyond the spikes.
"It has been significant throughout the year," she said. "But after the EU referendum, hundreds and hundreds of users were looking up the term every hour."
Robert Reich, who served in the administrations of Presidents Gerald Ford and Jimmy Carter and was President Clinton's labor secretary, felt so strongly about xenophobia's prominence today that he appears in a video for Dictionary.com discussing its ramifications.
"I don't think most people even know what xenophobia is," Reich, who teaches public policy at the University of California, Berkeley, said in an interview. "It's a word not to be celebrated but to be deeply concerned about."
Solomon's site, based in Oakland, California, started choosing a word of the year in 2010, based on search data and agreement of in-house experts that include a broad swath of the company, from lexicographers to the marketing and product teams to the CEO, Liz McMillan.
The word and the sentiment reflect a broader mournful tone to 2016, with Oxford dictionary editors choosing "post-truth" as their word of the year, often described in terms of politics as belonging to a time in which truth has become irrelevant.
"I wish," Solomon said, "we could have chosen a word like unicorns."
The distinction between nouns and adjectives seems like it should be straightforward, but it’s not. Grammar is not as simple as your grade-school teacher presented it.
You may have learned about nouns with the description that nouns name a person, place, or thing. That’s a good enough place to start with young kids, but pretty soon someone will realize that “things” is pretty broad. Adjectives are tricky too: they are not just words that describe what nouns stand for; often adjectives clarify nouns by saying how much (several, twenty, most) or they may propose a comparison (more, better, faster).
A better approach to thinking about adjectives and nouns is to put semantic definitions aside and identify nouns and adjectives by their shapes—what sorts of endings they take. And they can be identified also by their syntactic behavior, that is by what other words they occur with or they can be substituted for.
Thinking about nouns and adjectives in this way allows us to work through some puzzles about what is a noun and what is an adjective. Consider a phrase like a stone wall or a steel cabinet. We know that wall and cabinet are nouns, but what about stone and steel? Are they adjectives or nouns?
Actually, they are nouns that modify other nouns. We can be confident of this for several reasons. First, we can’t modify stone or steel with adverbs like very or completely. Second, the most likely paraphrases are ones like “a wall made of stone” or “a cabinet made of steel.” And finally, there are contrasting expressions with actual adjectives, like stony and steely: “a stony demeanor” and “a steely glance.” A silk scarf is made of silk, while a silky scarf has the qualities of silkiness. Comparing stone and steel and silk with stony, steely, and silky helps to decide the issue.
Another noun-or-adjective puzzle involves expressions like the rich or the poor (and also the lucky, the good, the bad, the ugly, the lazy, the industrious, the strong, the weak, the meek, the humble, the mighty, and more). Are these nouns or adjectives? The presence of the would seem to suggest nouns. But that would entail many pairs of homophones, such as rich the noun and rich the adjective, and so on. A bigger problem is that words like rich and poor can occur with a preceding adverb (as in “The very rich”). And we can even make superlative forms (like “The best and the brightest” or “The happiest”). The evidence points to adjective here and so the best way to think about such phrases is as having an omitted noun, something like “The rich (people)” or “The poor (people).”
Finally, there are possessives. Some grammars, like Wilson Follett’s Modern American Usage, treat possessives as adjectives. Most modern grammars, however, see possessives as nouns or noun phrases. How can we be confident of this? Consider a phrase like “Truman’s temperament.” The word Truman’s modifies the noun temperament, so it has that feature of an adjective. But if we treat it that way, we open the door to a whole host of compound adjectives exactly like nouns: Harry Truman’s, The 33rd president’s, Give-Em-Hell-Harry’s, and so on. What’s more, possessives can be replaced by pronouns (his temperament), which is a feature of nouns, not adjectives. And perhaps most important is the contrast between true adjectives and possessives: compare the two sentences “Lincoln’s descendants resemble him,” where the pronoun easily refers back to Lincoln and “Lincolnesque people resemble him.” The latter sounds odd, because there is no noun for him to refer back to. But the first sentence is fine because Lincoln’s is a noun.
Grammar is less arbitrary than you might think.
Featured image by Rob Hobson via Unsplash, public domain
Edwin L. Battistella taught linguistics and writing at Southern Oregon University in Ashland, where he served as a dean and as interim provost. His books include Bad Language: Are Some Words Better than Others?, Sorry About That: The Language of Public Apology, and Dangerous Crooked Scoundrels: Insulting the President, from Washington to Trump.
BY EDWIN L. BATTISTELLA SEPTEMBER 3RD 2023 "The distinction between nouns and adjectives seems like it should be straightforward, but it’s not. Grammar is not as simple as your grade-school teacher presented it.
You may have learned about nouns with the description that nouns name a person, place, or thing. That’s a good enough place to start with young kids, but pretty soon someone will realize that “things” is pretty broad. Adjectives are tricky too: they are not just words that describe what nouns stand for; often adjectives clarify nouns by saying how much (several, twenty, most) or they may propose a comparison (more, better, faster).
A better approach to thinking about adjectives and nouns is to put semantic definitions aside and identify nouns and adjectives by their shapes—what sorts of endings they take. And they can be identified also by their syntactic behavior, that is by what other words they occur with or they can be substituted for.
Thinking about nouns and adjectives in this way allows us to work through some puzzles about what is a noun and what is an adjective. Consider a phrase like a stone wall or a steel cabinet. We know that wall and cabinet are nouns, but what about stone and steel? Are they adjectives or nouns?
Actually, they are nouns that modify other nouns. We can be confident of this for several reasons. First, we can’t modify stone or steel with adverbs like very or completely. Second, the most likely paraphrases are ones like “a wall made of stone” or “a cabinet made of steel.” And finally, there are contrasting expressions with actual adjectives, like stony and steely: “a stony demeanor” and “a steely glance.” A silk scarf is made of silk, while a silky scarf has the qualities of silkiness. Comparing stone and steel and silk with stony, steely, and silky helps to decide the issue.
Another noun-or-adjective puzzle involves expressions like the rich or the poor (and also the lucky, the good, the bad, the ugly, the lazy, the industrious, the strong, the weak, the meek, the humble, the mighty, and more). Are these nouns or adjectives? The presence of the would seem to suggest nouns. But that would entail many pairs of homophones, such as rich the noun and rich the adjective, and so on. A bigger problem is that words like rich and poor can occur with a preceding adverb (as in “The very rich”). And we can even make superlative forms (like “The best and the brightest” or “The happiest”). The evidence points to adjective here and so the best way to think about such phrases is as having an omitted noun, something like “The rich (people)” or “The poor (people).”
Finally, there are possessives. Some grammars, like Wilson Follett’s Modern American Usage, treat possessives as adjectives. Most modern grammars, however, see possessives as nouns or noun phrases. How can we be confident of this? Consider a phrase like “Truman’s temperament.” The word Truman’s modifies the noun temperament, so it has that feature of an adjective. But if we treat it that way, we open the door to a whole host of compound adjectives exactly like nouns: Harry Truman’s, The 33rd president’s, Give-Em-Hell-Harry’s, and so on. What’s more, possessives can be replaced by pronouns (his temperament), which is a feature of nouns, not adjectives. And perhaps most important is the contrast between true adjectives and possessives: compare the two sentences “Lincoln’s descendants resemble him,” where the pronoun easily refers back to Lincoln and “Lincolnesque people resemble him.” The latter sounds odd, because there is no noun for him to refer back to. But the first sentence is fine because Lincoln’s is a noun.
Grammar is less arbitrary than you might think.
Featured image by Rob Hobson via Unsplash, public domain
With big cash prizes at stake—and AI supercharging research—interspecies translation is closer than ever. But what, if anything, would animals want to tell us?
"The Race to Translate Animal Sounds Into Human Language With big cash prizes at stake—and AI supercharging research—interspecies translation is closer than ever. But what, if anything, would animals want to tell us?..."
Gilliatt de Staërck, a candidate in the French parliamentary elections, is campaigning against the dominance of English in French society. His policies aim to strengthen and develop the French language in various sectors.
‘Anti-English’ candidate stands for election in Brittany ‘The language of capitalist business is replacing French,’ says communist nominee
Gilliatt de Staërck has shared his policies to “defend, strengthen and develop the French language” against what he calls the creep of English sweeann/Shutterstock
Hannah Thompson
PUBLISHED Friday 28 June 2024 - 15:48 LAST UPDATED Friday 28 June 2024 - 15:51
A candidate in the French parliamentary elections is running on an ‘anti-English language’ ticket, saying that French is being “mistreated and replaced” by “the language of capitalist business”.
Gilliatt de Staërck is the candidate for the far-left Pôle de renaissance communiste en France (PRCF) party in Fougères, Ille-et-Vilaine (Brittany).
The PRCF is a distinct entity from the French Communist Party (PCF) and is not part of the wider left-wing alliance of the Nouveau Front Populaire.
French being ‘mistreated and replaced’
Mr Staërck’s campaign policies focus on ‘building up the French language’ against what he believes is the creep of English into French.
“Throughout society, particularly in companies, the all-English language of capitalist business is tending to replace French, even though French is constitutionally the language of the Republic and of the workplace,” he said.
He said that “in advertising, in employment, at work, in the street and even in the slogans used by the Elysée Palace to promote France in the world, our national language, rich as it is in history… is being mistreated and replaced”.
“Yet, it is in French, and in very precise terms, that workers and their trade unions negotiate company and branch agreements…all our fellow citizens speak French, unlike the Europeanised elites,” he said.French language policies
Mr de Staërck has shared his policies to “defend, strengthen and develop the French language”, across business, industry, legislation, defence, and even music.
These include:
Strengthening the Toubon Law (a 1994 law designed to protect France's linguistic heritage).
Legally requiring - barring exceptional circumstances - that French is the language of work, services, trade, education, public services, administrations, and official institutions.
The rejection of “incessant reminders” from Brussels “to invalidate French language legislation in order to promote all-English under the guise of free competition”.
The promotion of French as the language of teaching and university, except in very exceptional cases.
Fines for employers, media and advertisers who promote the ‘English-only language’ policies
The creation of a permanent fund for French-language creation in all fields (science, music, film, technology, etc.).
Quotas for French-language songs will be raised.
State and local authority subsidies to be reserved for songs in French or in the country's various regional languages. The same will apply to films and shows.
French will once again be the sole language of the army, with the exception of translation requirements.
All scientific articles must first appear in French, even if they are translated into several languages, so that they can be understood by any French-speaker with the necessary scientific skills.
Mr de Staërck has also said that regional languages would be held up as “an indivisible heritage of the nation”. Regional authorities would be “given the means to teach regional languages”, he said, as soon as there is sufficient demand in a given department.
He also said that exceptions would be made to his ‘all-French’ policies when it comes to Creole languages and those from the French overseas territories.
European Union ‘squandering our heritage’
The European Union, Mr de Staërck says, is “a driving force behind the expansion of this single-language [English] policy”, and added that this is “squandering our national linguistic heritage”.
“By seeking to impose English as the language of the continent, even though the United Kingdom is no longer part of the EU, the European Commission is seeking to crush the cultural exceptions that still resist its capitalist and supranational logic,” he said.
‘No tribute to Shakespeare’
Mr de Staërck’s stance is not necessarily ‘anti-English’ per se.
Instead, he is calling instead for a better use of all languages, a wider promotion of French, and added that the English used in French is not of good quality in any case.
“It is an English that is itself impoverished and pays little tribute to the language of Shakespeare,” he said.
"Gilliatt de Staërck, a candidate in the French parliamentary elections, is campaigning against the dominance of English in French society. His policies aim to strengthen and develop the French language in various sectors.
‘Anti-English’ candidate stands for election in Brittany
‘The language of capitalist business is replacing French,’ says communist nominee
Gilliatt de Staërck has shared his policies to “defend, strengthen and develop the French language” against what he calls the creep of English sweeann/Shutterstock
HannahThompson
PUBLISHED Friday 28 June 2024 - 15:48 LAST UPDATED Friday 28 June 2024 - 15:51
A candidate in the French parliamentary elections is running on an ‘anti-English language’ ticket, saying that French is being “mistreated and replaced” by “the language of capitalist business”.
Gilliatt de Staërck is the candidate for the far-left Pôle de renaissance communiste en France (PRCF) party in Fougères, Ille-et-Vilaine (Brittany).
The PRCF is a distinct entity from the French Communist Party (PCF) and is not part of the wider left-wing alliance of the Nouveau Front Populaire.
French being ‘mistreated and replaced’
Mr Staërck’s campaign policies focus on ‘building up the French language’ against what he believes is the creep of English into French.
“Throughout society, particularly in companies, the all-English language of capitalist business is tending to replace French, even though French is constitutionally the language of the Republic and of the workplace,” he said.
He said that “in advertising, in employment, at work, in the street and even in the slogans used by the Elysée Palace to promote France in the world, our national language, rich as it is in history… is being mistreated and replaced”.
“Yet, it is in French, and in very precise terms, that workers and their trade unions negotiate company and branch agreements…all our fellow citizens speak French, unlike the Europeanised elites,” he said.French language policies
Mr de Staërck has shared his policies to “defend, strengthen and develop the French language”, across business, industry, legislation, defence, and even music.
These include:
Strengthening the Toubon Law (a 1994 law designed to protect France's linguistic heritage).
Legally requiring - barring exceptional circumstances - that French is the language of work, services, trade, education, public services, administrations, and official institutions.
The rejection of “incessant reminders” from Brussels “to invalidate French language legislation in order to promote all-English under the guise of free competition”.
The promotion of French as the language of teaching and university, except in very exceptional cases.
Fines for employers, media and advertisers who promote the ‘English-only language’ policies
The creation of a permanent fund for French-language creation in all fields (science, music, film, technology, etc.).
Quotas for French-language songs will be raised.
State and local authority subsidies to be reserved for songs in French or in the country's various regional languages. The same will apply to films and shows.
French will once again be the sole language of the army, with the exception of translation requirements.
All scientific articles must first appear in French, even if they are translated into several languages, so that they can be understood by any French-speaker with the necessary scientific skills.
Mr de Staërck has also said that regional languages would be held up as “an indivisible heritage of the nation”. Regional authorities would be “given the means to teach regional languages”, he said, as soon as there is sufficient demand in a given department.
He also said that exceptions would be made to his ‘all-French’ policies when it comes to Creole languages and those from the French overseas territories.
European Union ‘squandering our heritage’
The European Union, Mr de Staërck says, is “a driving force behind the expansion of this single-language [English] policy”, and added that this is “squandering our national linguistic heritage”.
“By seeking to impose English as the language of the continent, even though the United Kingdom is no longer part of the EU, the European Commission is seeking to crush the cultural exceptions that still resist its capitalist and supranational logic,” he said.
‘No tribute to Shakespeare’
Mr de Staërck’s stance is not necessarily ‘anti-English’ per se.
Instead, he is calling instead for a better use of all languages, a wider promotion of French, and added that the English used in French is not of good quality in any case.
“It is an English that is itself impoverished and pays little tribute to the language of Shakespeare,” he said."
In honor of Friendship Day, the Herald is here for you with a list of phonetic phoneys to watch out for
VALEN IRICIBAR
JULY 21, 2024
This one’s going to be a little different. I’ve mentioned how we’ll playfully use the word “redacted” in the newsroom before and that got me thinking about other “false friends” we often come across. In honor of Friendship Day, which Argentines celebrated on July 20, let’s commiserate over some that have led us astray.
This is far from an exhaustive list of these conniving phonetic evil twins. At the Herald, it’s usually a case of partial false friends, i.e. words that do exist in the other language but just have a different meaning.
Compromiso: a compromiso is a “commitment” in Spanish but if you’re not careful you could write “compromise” instead — which in certain contexts could mean quite the opposite Escrutinio: although you have to be hyper-vigilant while doing this, the translation is actually “vote count,” not “scrutiny.” Came up a couple of times in our elections coverage: don’t judge, three rounds of voting would melt anyone’s brain a bit Importante: more often than not the meaning behind importante is actually “considerable.” So for example the increase in a certain indicator is not “important,” as it is in Spanish, but noteworthy, remarkable, or considerable. This one is particularly annoying because sometimes it does just mean “important” Intervenido. If only it were as easy as “intervened”! As I explored in a previous translation troubles column, this is a type of audit that comes up way too often and still makes us shudder Nota: the things we write in English are articles but in Spanish are often referred to as notas as well as artículos. Sometimes you’ll hear “note” as a Spanglishism in the newsroom — but nothing’s reached the everyday status of our beloved falop Tratamiento: in Spanish, when there’s a bill being debated in Congress we’ll say that it’s being “treated.” In English, treatment is medical: whatever we think of the surgical needs of bills that hit the congressional floors, the term is “discussed”
And here are the two that probably catch us off guard the most often. First, we have edición. When considering recurring events in Spanish, we talk about “editions” as if they were books. So a literal translation would be “the 25th ‘edition’ of the Book Fair” or “the first ‘edition’ of the Anne Frank Awards.” Alas, not a thing in English: it’s just “the 25th Book Fair,” or maybe “25th annual Book Fair.”
And finally, there’s a phrase used a lot in Argentine journalism: este lunes or “this Monday.” In Spanish, it’s the Monday of the week in which you’re reading the article and can be used instead of “today.” For example: “This Sunday I wrote a translation troubles column about false friends.” But that’s confusing in English because that usually means the upcoming Sunday or frankly, just reads weird. Like “Verily upon this day I did write.” Not our style.
Anyway, similarly to “edition,” you can sometimes cut this out if you’ve already specified when an event happened. At the Herald, we’ll often switch the demonstrative “this” for the preposition “on” and we’re done. “On Sunday, I urged readers to beware false friends.” But if you do fall for one of these, chin up: as evidenced by this list, you are definitely not the only one.
This one’s going to be a little different. I’ve mentioned how we’ll playfully use the word “redacted” in the newsroom before and that got me thinking about other “false friends” we often come across. In honor of Friendship Day, which Argentines celebrated on July 20, let’s commiserate over some that have led us astray.
This is far from an exhaustive list of these conniving phonetic evil twins. At the Herald, it’s usually a case of partial false friends, i.e. words that do exist in the other language but just have a different meaning.
Compromiso: a compromiso is a “commitment” in Spanish but if you’re not careful you could write “compromise” instead — which in certain contexts could mean quite the opposite
Escrutinio: although you have to be hyper-vigilant while doing this, the translation is actually “vote count,” not “scrutiny.” Came up a couple of times in our elections coverage: don’t judge, three rounds of voting would melt anyone’s brain a bit
Importante: more often than not the meaning behind importante is actually “considerable.” So for example the increase in a certain indicator is not “important,” as it is in Spanish, but noteworthy, remarkable, or considerable. This one is particularly annoying because sometimes it does just mean “important”
Intervenido. If only it were as easy as “intervened”! As I explored in a previous translation troubles column, this is a type of audit that comes up way too often and still makes us shudder
Nota: the things we write in English are articles but in Spanish are often referred to as notas as well as artículos. Sometimes you’ll hear “note” as a Spanglishism in the newsroom — but nothing’s reached the everyday status of our beloved falop
Tratamiento: in Spanish, when there’s a bill being debated in Congress we’ll say that it’s being “treated.” In English, treatment is medical: whatever we think of the surgical needs of bills that hit the congressional floors, the term is “discussed”
And here are the two that probably catch us off guard the most often. First, we have edición. When considering recurring events in Spanish, we talk about “editions” as if they were books. So a literal translation would be “the 25th ‘edition’ of the Book Fair” or “the first ‘edition’ of the Anne Frank Awards.” Alas, not a thing in English: it’s just “the 25th Book Fair,” or maybe “25th annual Book Fair.”
And finally, there’s a phrase used a lot in Argentine journalism: este lunes or “this Monday.” In Spanish, it’s the Monday of the week in which you’re reading the article and can be used instead of “today.” For example: “This Sunday I wrote a translation troubles column about false friends.” But that’s confusing in English because that usually means the upcoming Sunday or frankly, just reads weird. Like “Verily upon this day I did write.” Not our style.
Anyway, similarly to “edition,” you can sometimes cut this out if you’ve already specified when an event happened. At the Herald, we’ll often switch the demonstrative “this” for the preposition “on” and we’re done. “On Sunday, I urged readers to beware false friends.” But if you do fall for one of these, chin up: as evidenced by this list, you are definitely not the only one."
Machine translation (MT) is the process of automatically translating text from one language into another using computer applications.
Nov 17 2023 · 10:39 UTC | Updated Nov 17 2023 · 10:42 UTC by John Caroline
Machine translation has been very helpful to businesses seeking to improve the way they serve their customers. Let us help you understand all that there is to know about machine translation in this comprehensive guide.
Before the inception of remarkable modern technologies, the global market was limited by language barriers which restricted the success of many businesses. While there are diverse languages across the nations of the globe, people from different races and ethnicities often find it difficult to interact with each other and execute certain transactions together, depriving them of several opportunities.
Nonetheless, the challenges that come with these language differences have called for the need to build an infrastructure that allows languages to be translated and facilitates the process of communication. This idea has been brought to reality through machine translation (MT) which allows you to leverage computer applications to interpret languages.
To help you grasp this concept better, here is a guide that will help you understand machine translation and describe its types, benefits, challenges, and lots more.
Machine Translation Explained
Machine translation can simply be defined as the process of automatically translating text or speech from one language into another using computer applications. The sole aim of this technology is to unify speakers of different languages together, allowing them to seamlessly communicate with each other with little or no barriers.
Due to its design, machine translation features a system that takes the text in one language and converts it into another language while keeping the meaning and context as accurate as possible for its audience to understand. It employs advanced algorithms and machine learning to automatically convert text or speech from one language to another. This process generally involves preparing the input text or speech by cleaning and organizing it.
Thus, the machine translation system is trained using various examples of texts in multiple languages and their corresponding translations. It learns patterns and probabilities of how words and phrases are translated from these examples. When you input new text for translation, the system uses what it has learned to generate the translation. In some cases, additional adjustments may be made to refine the results if necessary.
While the machine translation system is trained via the data inputted into them over time, the data it is using can be either generic data, which is knowledge from all past translations, making them versatile for different applications, or custom data, where specific subject matter expertise is added to the engine, like in engineering or other specialized fields. Users can utilize either of the data depending on their needs.
Machine Translation: Brief History
The history of machine translation dates back to the 1950s when early computer scientists attempted to use computing power for language translation. However, the task’s complexity exceeded their expectations, and early machines lacked the necessary processing power and storage.
It wasn’t until the early 2000s that software, data, and hardware reached a level where basic machine translation became possible. Developers used statistical language databases to teach computer translation, a process that required considerable manual effort.
Notably, the 2010s marked a significant breakthrough with the rise of neural machine translation, introducing deep learning techniques and neural networks to translation models. Google’s “Google Neural Machine Translation” (GNMT) system in 2016 represented a pivotal moment in this technology’s development.
Machine Translation Types
While the technology behind machine translation systems has advanced significantly in recent years, it has adopted three primary approaches to automatically translate text or speech from one language into another. These approaches include rule-based machine translation (RBMT), statistical machine translation (SMT), and neural machine translation (NMT).
Rule-Based Machine Translation (RBMT)
Rule-based machine translation (RBMT) was an early approach to translation using predefined linguistic rules. It had low-quality output, required manual addition of languages, and significant human editing. RBMT relies on linguistic experts to create rules for source and target languages, resulting in grammatically accurate but often overly literal translations. While RBMT is precise for languages with strict rules, it struggles with context and nuance, leading to less natural translations. Developing and maintaining rules for various languages is labor-intensive, especially for languages with complex grammar. Additionally, RBMT may struggle with ambiguous phrases or words in the source text. This traditional method is rarely used today due to these limitations.
Statistical Machine Translation (SMT)
Statistical machine translation (SMT) uses statistical models to understand the relationships between words, phrases, and sentences in a text and then applies this knowledge to translate it into another language. While it’s an improvement over rule-based MT, it still has some of the same issues. SMT is being replaced by neural MT but is occasionally used for older machine translation systems. It stands out from RBMT as it doesn’t rely on predefined rules but learns from large bilingual text collections to make translation decisions. However, SMT has its limitations, such as being reliant on the availability and quality of parallel text data, struggling with context, and potentially generating less fluent or contextually accurate translations, especially for less common phrases.
Neural Machine Translation (NMT)
Neural machine translation (NMT) represents a modern approach to automated translation, leveraging artificial intelligence to mimic the continuous learning of human neural networks. Unlike older rule-based or statistical methods, NMT’s neural networks are responsible for encoding and decoding the source text. NMT is the prevailing standard in machine translation due to its superior accuracy, scalability to multiple languages, and faster performance once trained. It excels in capturing context and delivering fluent, contextually accurate translations. Nevertheless, NMT does have limitations. Its performance relies on the availability of large, high-quality parallel corpora for training. Additionally, training and deploying NMT models can be computationally intensive, often necessitating powerful hardware like GPUs or TPUs.
Automated vs Machine Translation
Let’s clarify the distinction between automated translation and machine translation, as they often get mixed up, however, they perform different roles.
Automated translation involves incorporating features into computer-assisted translation tools (CAT tools) or cloud translation management systems (TMS) to automate manual or repetitive translation-related tasks. Its purpose is to streamline the overall translation process, improving efficiency. For instance, automated translation might initiate machine translation for a portion of the text as one of the many steps in a translation workflow.
On the other hand, machine translation is all about using software to convert text from one natural language to another without any human involvement, unlike traditional translation. This is why it’s also referred to as automatic translation.
Capabilities and Challenges
Over the years, machine translation’s speed and volume capabilities have seen remarkable enhancements due to ongoing improvements in machine learning algorithms and hardware technology. It can now translate millions of words almost instantaneously and continues to get better as more content is translated. For high-volume projects, MT not only handles volume at speed but can also integrate with other software platforms like content or translation management systems to maintain organization and context during translation.
Moreover, MT’s improved accessibility, offering translations in multiple languages, benefits both businesses and customers by eliminating language barriers and enhancing the customer experience. This expansion to a wider audience helps businesses grow their market share.
Another advantage of MT is cost reduction. While human translators still play a role in refining translations to match the original content’s intent and localize it per region, MT does the initial heavy lifting, saving time and costs, even when post-editing by human translators is involved.
Nonetheless, while machine translation is a cost-effective and quick solution for global expansion, it’s important to recognize the challenges it presents. These challenges include:
Accuracy and domain specificity. MT can struggle with precise domain-specific terminology and context, often producing translations that lack the depth of understanding that human experts can provide. Linguistic nuances. MT may miss subtle linguistic nuances, cultural references, or idiomatic expressions, which are crucial for conveying meaning accurately and effectively. Low-resource languages. MT is less effective for languages with limited available training data, as it relies on extensive bilingual corpora for training. Machine translation post-editing. To address issues with MT quality, businesses often employ human post-editors to refine the translations. This adds a layer of cost and time. Privacy. When sensitive or confidential information is involved, relying solely on MT can pose privacy risks. Human involvement is necessary to maintain data security and confidentiality. Future of Machine Translation: Will It Replace Humans?
Translation technology has made significant advancements, but it’s unlikely to completely replace human translators. While machine translation tools like neural machine translation (NMT) are proficient in handling straightforward, repetitive tasks and providing quick translations, they still struggle with context, nuance, and understanding the cultural and linguistic subtleties that human translators excel at.
Human translators bring cultural and contextual insights to their work, ensuring that translations are accurate, idiomatic, and sensitive to the nuances of the source and target languages. They are indispensable in complex or specialized fields like legal, medical, or creative content, where precise and culturally appropriate translations are critical.
Machine Translation Engines
The main providers of generic machine translation engines include Google Translate, Microsoft Translator, DeepL, and IBM Language Translator. These providers offer pre-trained models for a wide range of languages and general translation needs.
For custom machine translation engines, there are specialized companies like Lilt and Iconic Translation Machines that offer tailored solutions for specific industries or organizations.
Final Thoughts
Machine translation (MT) has added lots of value to the global space, eradicating barriers to language differences while allowing people to seamlessly access translations to languages they do not understand.
While this has greatly impacted businesses worldwide, especially those that hold international deals, it has also impacted the social life of many as it tends to strengthen relationships among people of different languages.
As this technology continues to evolve, the world will soon overcome every limitation that tends to come with language barriers using efficient computer tools.
"Machine translation (MT) is the process of automatically translating text from one language into another using computer applications.
Nov 17 2023 · 10:39 UTC | Updated Nov 17 2023 · 10:42 UTC by John Caroline
Machine translation has been very helpful to businesses seeking to improve the way they serve their customers. Let us help you understand all that there is to know about machine translation in this comprehensive guide.
Before the inception of remarkable modern technologies, the global market was limited by language barriers which restricted the success of many businesses. While there are diverse languages across the nations of the globe, people from different races and ethnicities often find it difficult to interact with each other and execute certain transactions together, depriving them of several opportunities.
Nonetheless, the challenges that come with these language differences have called for the need to build an infrastructure that allows languages to be translated and facilitates the process of communication. This idea has been brought to reality through machine translation (MT) which allows you to leverage computer applications to interpret languages.
To help you grasp this concept better, here is a guide that will help you understand machine translation and describe its types, benefits, challenges, and lots more.
Machine Translation Explained
Machine translation can simply be defined as the process of automatically translating text or speech from one language into another using computer applications. The sole aim of this technology is to unify speakers of different languages together, allowing them to seamlessly communicate with each other with little or no barriers.
Due to its design, machine translation features a system that takes the text in one language and converts it into another language while keeping the meaning and context as accurate as possible for its audience to understand. It employs advanced algorithms and machine learning to automatically convert text or speech from one language to another. This process generally involves preparing the input text or speech by cleaning and organizing it.
Thus, the machine translation system is trained using various examples of texts in multiple languages and their corresponding translations. It learns patterns and probabilities of how words and phrases are translated from these examples. When you input new text for translation, the system uses what it has learned to generate the translation. In some cases, additional adjustments may be made to refine the results if necessary.
While the machine translation system is trained via the data inputted into them over time, the data it is using can be either generic data, which is knowledge from all past translations, making them versatile for different applications, or custom data, where specific subject matter expertise is added to the engine, like in engineering or other specialized fields. Users can utilize either of the data depending on their needs.
Machine Translation: Brief History
The history of machine translation dates back to the 1950s when early computer scientists attempted to use computing power for language translation. However, the task’s complexity exceeded their expectations, and early machines lacked the necessary processing power and storage.
It wasn’t until the early 2000s that software, data, and hardware reached a level where basic machine translation became possible. Developers used statistical language databases to teach computer translation, a process that required considerable manual effort.
Notably, the 2010s marked a significant breakthrough with the rise of neural machine translation, introducing deep learning techniques and neural networks to translation models. Google’s “Google Neural Machine Translation” (GNMT) system in 2016 represented a pivotal moment in this technology’s development.
Machine Translation Types
While the technology behind machine translation systems has advanced significantly in recent years, it has adopted three primary approaches to automatically translate text or speech from one language into another. These approaches include rule-based machine translation (RBMT), statistical machine translation (SMT), and neural machine translation (NMT).
Rule-Based Machine Translation (RBMT)
Rule-based machine translation (RBMT) was an early approach to translation using predefined linguistic rules. It had low-quality output, required manual addition of languages, and significant human editing. RBMT relies on linguistic experts to create rules for source and target languages, resulting in grammatically accurate but often overly literal translations. While RBMT is precise for languages with strict rules, it struggles with context and nuance, leading to less natural translations. Developing and maintaining rules for various languages is labor-intensive, especially for languages with complex grammar. Additionally, RBMT may struggle with ambiguous phrases or words in the source text. This traditional method is rarely used today due to these limitations.
Statistical Machine Translation (SMT)
Statistical machine translation (SMT) uses statistical models to understand the relationships between words, phrases, and sentences in a text and then applies this knowledge to translate it into another language. While it’s an improvement over rule-based MT, it still has some of the same issues. SMT is being replaced by neural MT but is occasionally used for older machine translation systems. It stands out from RBMT as it doesn’t rely on predefined rules but learns from large bilingual text collections to make translation decisions. However, SMT has its limitations, such as being reliant on the availability and quality of parallel text data, struggling with context, and potentially generating less fluent or contextually accurate translations, especially for less common phrases.
Neural Machine Translation (NMT)
Neural machine translation (NMT) represents a modern approach to automated translation, leveraging artificial intelligence to mimic the continuous learning of human neural networks. Unlike older rule-based or statistical methods, NMT’s neural networks are responsible for encoding and decoding the source text. NMT is the prevailing standard in machine translation due to its superior accuracy, scalability to multiple languages, and faster performance once trained. It excels in capturing context and delivering fluent, contextually accurate translations. Nevertheless, NMT does have limitations. Its performance relies on the availability of large, high-quality parallel corpora for training. Additionally, training and deploying NMT models can be computationally intensive, often necessitating powerful hardware like GPUs or TPUs.
Automated vs Machine Translation
Let’s clarify the distinction between automated translation and machine translation, as they often get mixed up, however, they perform different roles.
Automated translation involves incorporating features into computer-assisted translation tools (CAT tools) or cloud translation management systems (TMS) to automate manual or repetitive translation-related tasks. Its purpose is to streamline the overall translation process, improving efficiency. For instance, automated translation might initiate machine translation for a portion of the text as one of the many steps in a translation workflow.
On the other hand, machine translation is all about using software to convert text from one natural language to another without any human involvement, unlike traditional translation. This is why it’s also referred to as automatic translation.
Capabilities and Challenges
Over the years, machine translation’s speed and volume capabilities have seen remarkable enhancements due to ongoing improvements in machine learning algorithms and hardware technology. It can now translate millions of words almost instantaneously and continues to get better as more content is translated. For high-volume projects, MT not only handles volume at speed but can also integrate with other software platforms like content or translation management systems to maintain organization and context during translation.
Moreover, MT’s improved accessibility, offering translations in multiple languages, benefits both businesses and customers by eliminating language barriers and enhancing the customer experience. This expansion to a wider audience helps businesses grow their market share.
Another advantage of MT is cost reduction. While human translators still play a role in refining translations to match the original content’s intent and localize it per region, MT does the initial heavy lifting, saving time and costs, even when post-editing by human translators is involved.
Nonetheless, while machine translation is a cost-effective and quick solution for global expansion, it’s important to recognize the challenges it presents. These challenges include:
Accuracy and domain specificity. MT can struggle with precise domain-specific terminology and context, often producing translations that lack the depth of understanding that human experts can provide.
Linguistic nuances. MT may miss subtle linguistic nuances, cultural references, or idiomatic expressions, which are crucial for conveying meaning accurately and effectively.
Low-resource languages. MT is less effective for languages with limited available training data, as it relies on extensive bilingual corpora for training.
Machine translation post-editing. To address issues with MT quality, businesses often employ human post-editors to refine the translations. This adds a layer of cost and time.
Privacy. When sensitive or confidential information is involved, relying solely on MT can pose privacy risks. Human involvement is necessary to maintain data security and confidentiality.
Future of Machine Translation: Will It Replace Humans?
Translation technology has made significant advancements, but it’s unlikely to completely replace human translators. While machine translation tools like neural machine translation (NMT) are proficient in handling straightforward, repetitive tasks and providing quick translations, they still struggle with context, nuance, and understanding the cultural and linguistic subtleties that human translators excel at.
Human translators bring cultural and contextual insights to their work, ensuring that translations are accurate, idiomatic, and sensitive to the nuances of the source and target languages. They are indispensable in complex or specialized fields like legal, medical, or creative content, where precise and culturally appropriate translations are critical.
Machine Translation Engines
The main providers of generic machine translation engines include Google Translate, Microsoft Translator, DeepL, and IBM Language Translator. These providers offer pre-trained models for a wide range of languages and general translation needs.
For custom machine translation engines, there are specialized companies like Lilt and Iconic Translation Machines that offer tailored solutions for specific industries or organizations.
Final Thoughts
Machine translation (MT) has added lots of value to the global space, eradicating barriers to language differences while allowing people to seamlessly access translations to languages they do not understand.
While this has greatly impacted businesses worldwide, especially those that hold international deals, it has also impacted the social life of many as it tends to strengthen relationships among people of different languages.
As this technology continues to evolve, the world will soon overcome every limitation that tends to come with language barriers using efficient computer tools."
"Machine translation (MT) is the process of automatically translating text from one language into another using computer applications.
Nov 17 2023 · 10:39 UTC | Updated Nov 17 2023 · 10:42 UTC by John Caroline
Machine translation has been very helpful to businesses seeking to improve the way they serve their customers. Let us help you understand all that there is to know about machine translation in this comprehensive guide.
Before the inception of remarkable modern technologies, the global market was limited by language barriers which restricted the success of many businesses. While there are diverse languages across the nations of the globe, people from different races and ethnicities often find it difficult to interact with each other and execute certain transactions together, depriving them of several opportunities.
Nonetheless, the challenges that come with these language differences have called for the need to build an infrastructure that allows languages to be translated and facilitates the process of communication. This idea has been brought to reality through machine translation (MT) which allows you to leverage computer applications to interpret languages.
To help you grasp this concept better, here is a guide that will help you understand machine translation and describe its types, benefits, challenges, and lots more.
Machine Translation Explained
Machine translation can simply be defined as the process of automatically translating text or speech from one language into another using computer applications. The sole aim of this technology is to unify speakers of different languages together, allowing them to seamlessly communicate with each other with little or no barriers.
Due to its design, machine translation features a system that takes the text in one language and converts it into another language while keeping the meaning and context as accurate as possible for its audience to understand. It employs advanced algorithms and machine learning to automatically convert text or speech from one language to another. This process generally involves preparing the input text or speech by cleaning and organizing it.
Thus, the machine translation system is trained using various examples of texts in multiple languages and their corresponding translations. It learns patterns and probabilities of how words and phrases are translated from these examples. When you input new text for translation, the system uses what it has learned to generate the translation. In some cases, additional adjustments may be made to refine the results if necessary.
While the machine translation system is trained via the data inputted into them over time, the data it is using can be either generic data, which is knowledge from all past translations, making them versatile for different applications, or custom data, where specific subject matter expertise is added to the engine, like in engineering or other specialized fields. Users can utilize either of the data depending on their needs.
Machine Translation: Brief History
The history of machine translation dates back to the 1950s when early computer scientists attempted to use computing power for language translation. However, the task’s complexity exceeded their expectations, and early machines lacked the necessary processing power and storage.
It wasn’t until the early 2000s that software, data, and hardware reached a level where basic machine translation became possible. Developers used statistical language databases to teach computer translation, a process that required considerable manual effort.
Notably, the 2010s marked a significant breakthrough with the rise of neural machine translation, introducing deep learning techniques and neural networks to translation models. Google’s “Google Neural Machine Translation” (GNMT) system in 2016 represented a pivotal moment in this technology’s development.
Machine Translation Types
While the technology behind machine translation systems has advanced significantly in recent years, it has adopted three primary approaches to automatically translate text or speech from one language into another. These approaches include rule-based machine translation (RBMT), statistical machine translation (SMT), and neural machine translation (NMT).
Rule-Based Machine Translation (RBMT)
Rule-based machine translation (RBMT) was an early approach to translation using predefined linguistic rules. It had low-quality output, required manual addition of languages, and significant human editing. RBMT relies on linguistic experts to create rules for source and target languages, resulting in grammatically accurate but often overly literal translations. While RBMT is precise for languages with strict rules, it struggles with context and nuance, leading to less natural translations. Developing and maintaining rules for various languages is labor-intensive, especially for languages with complex grammar. Additionally, RBMT may struggle with ambiguous phrases or words in the source text. This traditional method is rarely used today due to these limitations.
Statistical Machine Translation (SMT)
Statistical machine translation (SMT) uses statistical models to understand the relationships between words, phrases, and sentences in a text and then applies this knowledge to translate it into another language. While it’s an improvement over rule-based MT, it still has some of the same issues. SMT is being replaced by neural MT but is occasionally used for older machine translation systems. It stands out from RBMT as it doesn’t rely on predefined rules but learns from large bilingual text collections to make translation decisions. However, SMT has its limitations, such as being reliant on the availability and quality of parallel text data, struggling with context, and potentially generating less fluent or contextually accurate translations, especially for less common phrases.
Neural Machine Translation (NMT)
Neural machine translation (NMT) represents a modern approach to automated translation, leveraging artificial intelligence to mimic the continuous learning of human neural networks. Unlike older rule-based or statistical methods, NMT’s neural networks are responsible for encoding and decoding the source text. NMT is the prevailing standard in machine translation due to its superior accuracy, scalability to multiple languages, and faster performance once trained. It excels in capturing context and delivering fluent, contextually accurate translations. Nevertheless, NMT does have limitations. Its performance relies on the availability of large, high-quality parallel corpora for training. Additionally, training and deploying NMT models can be computationally intensive, often necessitating powerful hardware like GPUs or TPUs.
Automated vs Machine Translation
Let’s clarify the distinction between automated translation and machine translation, as they often get mixed up, however, they perform different roles.
Automated translation involves incorporating features into computer-assisted translation tools (CAT tools) or cloud translation management systems (TMS) to automate manual or repetitive translation-related tasks. Its purpose is to streamline the overall translation process, improving efficiency. For instance, automated translation might initiate machine translation for a portion of the text as one of the many steps in a translation workflow.
On the other hand, machine translation is all about using software to convert text from one natural language to another without any human involvement, unlike traditional translation. This is why it’s also referred to as automatic translation.
Capabilities and Challenges
Over the years, machine translation’s speed and volume capabilities have seen remarkable enhancements due to ongoing improvements in machine learning algorithms and hardware technology. It can now translate millions of words almost instantaneously and continues to get better as more content is translated. For high-volume projects, MT not only handles volume at speed but can also integrate with other software platforms like content or translation management systems to maintain organization and context during translation.
Moreover, MT’s improved accessibility, offering translations in multiple languages, benefits both businesses and customers by eliminating language barriers and enhancing the customer experience. This expansion to a wider audience helps businesses grow their market share.
Another advantage of MT is cost reduction. While human translators still play a role in refining translations to match the original content’s intent and localize it per region, MT does the initial heavy lifting, saving time and costs, even when post-editing by human translators is involved.
Nonetheless, while machine translation is a cost-effective and quick solution for global expansion, it’s important to recognize the challenges it presents. These challenges include:
Accuracy and domain specificity. MT can struggle with precise domain-specific terminology and context, often producing translations that lack the depth of understanding that human experts can provide.
Linguistic nuances. MT may miss subtle linguistic nuances, cultural references, or idiomatic expressions, which are crucial for conveying meaning accurately and effectively.
Low-resource languages. MT is less effective for languages with limited available training data, as it relies on extensive bilingual corpora for training.
Machine translation post-editing. To address issues with MT quality, businesses often employ human post-editors to refine the translations. This adds a layer of cost and time.
Privacy. When sensitive or confidential information is involved, relying solely on MT can pose privacy risks. Human involvement is necessary to maintain data security and confidentiality.
Future of Machine Translation: Will It Replace Humans?
Translation technology has made significant advancements, but it’s unlikely to completely replace human translators. While machine translation tools like neural machine translation (NMT) are proficient in handling straightforward, repetitive tasks and providing quick translations, they still struggle with context, nuance, and understanding the cultural and linguistic subtleties that human translators excel at.
Human translators bring cultural and contextual insights to their work, ensuring that translations are accurate, idiomatic, and sensitive to the nuances of the source and target languages. They are indispensable in complex or specialized fields like legal, medical, or creative content, where precise and culturally appropriate translations are critical.
Machine Translation Engines
The main providers of generic machine translation engines include Google Translate, Microsoft Translator, DeepL, and IBM Language Translator. These providers offer pre-trained models for a wide range of languages and general translation needs.
For custom machine translation engines, there are specialized companies like Lilt and Iconic Translation Machines that offer tailored solutions for specific industries or organizations.
Final Thoughts
Machine translation (MT) has added lots of value to the global space, eradicating barriers to language differences while allowing people to seamlessly access translations to languages they do not understand.
While this has greatly impacted businesses worldwide, especially those that hold international deals, it has also impacted the social life of many as it tends to strengthen relationships among people of different languages.
As this technology continues to evolve, the world will soon overcome every limitation that tends to come with language barriers using efficient computer tools."
Google bets on African languages, including Dyula, Wolof, Baoulé and Tamazight
The Silicon Valley giant's translator has integrated 31 languages from the continent, spoken by over 200 million people.
By Marine Jeannin (Abidjan, correspondent)
Published yesterday at 4:50 pm (Paris)
"Sran ng'ɔ bo alɛ'n i jɔ'n, ɔ diman alɛ sɔ'n wie." This Baoulé proverb is now translatable with Google Translate: "He who declares war does not participate in it."
Since its new update on June 27, the software from the American giant has been able to translate 110 new languages, including Breton and Occitan, as well as 31 African languages, among them Tamazight (Berber), Afar, Wolof, Dyula and Baoulé. According to Google, these languages represent 200 million speakers on the continent.
"Today, you can photograph a label in Mandarin and see it translated by Google Lens into Dyula," said Abdoulaye Diack, program manager at Google's artificial intelligence (AI) lab in Accra, Ghana, who said he wants to "bring communities together" with this new service.
Establishing these translation models was a major challenge, given the lack of available resources. Half of the content written on the internet is in English. French accounts for just 3%, and the many African languages for less than 1%. "There are blogs and news sites in Swahili, Hausa and Wolof, but many African languages have predominantly oral uses," Diack explained. "So the first task was to identify the written sources available." In addition to these sites, some major texts have been translated into almost every language on the planet, including the Universal Declaration of Human Rights, the Bible and the Quran.
'An incentive effect'
Google's teams then worked with linguists from several faculties, such as the University of Ghana, and NGOs to accumulate data on all the targeted languages. These components were then used to train Google's AI, a learning model called PaLM2, which has already been tested with almost 400 languages. "Artificial intelligence is like a child," Diack summarized. "The more data the model receives, the more it learns, and the better the result."
Google's partners in the target communities – including organizations defending endangered languages and researchers – were asked to evaluate and improve the first AI translations until they reached a sufficient quality and quantity to launch the update. "This process takes several years. The results are not perfect, but they are satisfactory enough to be usable," explained Diack. "There are bound to be mistakes, but it will be useful for a lot of people."
This view is shared by Ivorian linguist Jérémie N'Guessan Kouadio, co-author of a French-Baoulé dictionary, whom Le Monde asked to test the new Google Translate update. "The Baoulé language is inseparable from its orality," he said. "To improve the result, we'd need, for example, to be able to render tones, those phonemes that can change the meaning of a word, which we note with diacritical marks below the syllable. Take 'sa': If I pronounce it with a high tone, it means 'the hand.' But with a low tone, it means 'thus.' All the languages of Côte d'Ivoire work like that, including Dyula."
Despite his reservations, N'Guessan Kouadio acknowledged that the software "has its uses." "For years, people have been trying to convince Africans – and Ivorians – that they can speak French or English, but also speak and write in their mother tongue," said the researcher. "I think software like this will have an incentive effect, particularly on young people in the diaspora who have drifted away from their language of origin."
Read more Subscribers only AI's dizzying capability to dub one voice into a foreign language
Speech recognition and synthesis
Professional uses are also conceivable. The African languages previously added (five in 2020 and 10 in 2022, including Bambara, Lingala and Twi) are available as open source through Application Programming Interfaces (APIs), which enable a Google program or service to be connected. The software could also facilitate the work of human interpreters, predicted Yao Kanga Tanoh, from Côte d'Ivoire, whose translation orders mainly concern administrative documents: "Of course, I'll have to rework the result, but a machine translation will save me a lot of time."
Read more Subscribers only Michael Jackson, 'the country's child' celebrated in a Côte d'Ivoire village
The Silicon Valley giant has no intention of stopping there. It has set itself the medium-term goal of integrating a thousand languages, prioritized according to several criteria: the number of speakers, the feasibility of the project in terms of the abundance of written resources, but also the desire of the relevant community. "People had been asking us for Wolof for years," said Diack. His team also intends to develop a speech recognition and synthesis system for the recently added languages, as already exists for the previous ones. With this technology, a telephone will be able to instantly repeat a French sentence in Baoulé, a particularly useful option for illiterate speakers.
Google also claims to want to immortalize endangered languages, largely not used by younger generations. One of these is the N'Ko language, invented in 1949 by Guinean writer Solomana Kanté, with its unique alphabet designed to empower Mandingo communities by providing them with their own writing system.
Marine Jeannin (Abidjan, correspondent)
Translation of an original article published in French on lemonde.fr; the publisher may only be liable for the French version.
"Sran ng'ɔ bo alɛ'n i jɔ'n, ɔ diman alɛ sɔ'n wie." This Baoulé proverb is now translatable with Google Translate: "He who declares war does not participate in it."
Since its new update on June 27, the software from the American giant has been able to translate 110 new languages, including Breton and Occitan, as well as 31 African languages, among them Tamazight (Berber), Afar, Wolof, Dyula and Baoulé. According to Google, these languages represent 200 million speakers on the continent.
"Today, you can photograph a label in Mandarin and see it translated by Google Lens into Dyula," said Abdoulaye Diack, program manager at Google's artificial intelligence (AI) lab in Accra, Ghana, who said he wants to "bring communities together" with this new service.
Establishing these translation models was a major challenge, given the lack of available resources. Half of the content written on the internet is in English. French accounts for just 3%, and the many African languages for less than 1%. "There are blogs and news sites in Swahili, Hausa and Wolof, but many African languages have predominantly oral uses," Diack explained. "So the first task was to identify the written sources available." In addition to these sites, some major texts have been translated into almost every language on the planet, including the Universal Declaration of Human Rights, the Bible and the Quran.
'An incentive effect'
Google's teams then worked with linguists from several faculties, such as the University of Ghana, and NGOs to accumulate data on all the targeted languages. These components were then used to train Google's AI, a learning model called PaLM2, which has already been tested with almost 400 languages. "Artificial intelligence is like a child," Diack summarized. "The more data the model receives, the more it learns, and the better the result."
Google's partners in the target communities – including organizations defending endangered languages and researchers – were asked to evaluate and improve the first AI translations until they reached a sufficient quality and quantity to launch the update. "This process takes several years. The results are not perfect, but they are satisfactory enough to be usable," explained Diack. "There are bound to be mistakes, but it will be useful for a lot of people."
This view is shared by Ivorian linguist Jérémie N'Guessan Kouadio, co-author of a French-Baoulé dictionary, whom Le Monde asked to test the new Google Translate update. "The Baoulé language is inseparable from its orality," he said. "To improve the result, we'd need, for example, to be able to render tones, those phonemes that can change the meaning of a word, which we note with diacritical marks below the syllable. Take 'sa': If I pronounce it with a high tone, it means 'the hand.' But with a low tone, it means 'thus.' All the languages of Côte d'Ivoire work like that, including Dyula."
Despite his reservations, N'Guessan Kouadio acknowledged that the software "has its uses." "For years, people have been trying to convince Africans – and Ivorians – that they can speak French or English, but also speak and write in their mother tongue," said the researcher. "I think software like this will have an incentive effect, particularly on young people in the diaspora who have drifted away from their language of origin."
Professional uses are also conceivable. The African languages previously added (five in 2020 and 10 in 2022, including Bambara, Lingala and Twi) are available as open source through Application Programming Interfaces (APIs), which enable a Google program or service to be connected. The software could also facilitate the work of human interpreters, predicted Yao Kanga Tanoh, from Côte d'Ivoire, whose translation orders mainly concern administrative documents: "Of course, I'll have to rework the result, but a machine translation will save me a lot of time."
The Silicon Valley giant has no intention of stopping there. It has set itself the medium-term goal of integrating a thousand languages, prioritized according to several criteria: the number of speakers, the feasibility of the project in terms of the abundance of written resources, but also the desire of the relevant community. "People had been asking us for Wolof for years," said Diack. His team also intends to develop a speech recognition and synthesis system for the recently added languages, as already exists for the previous ones. With this technology, a telephone will be able to instantly repeat a French sentence in Baoulé, a particularly useful option for illiterate speakers.
Google also claims to want to immortalize endangered languages, largely not used by younger generations. One of these is the N'Ko language, invented in 1949 by Guinean writer Solomana Kanté, with its unique alphabet designed to empower Mandingo communities by providing them with their own writing system.
"Sran ng'ɔ bo alɛ'n i jɔ'n, ɔ diman alɛ sɔ'n wie." This Baoulé proverb is now translatable with Google Translate: "He who declares war does not participate in it."
Since its new update on June 27, the software from the American giant has been able to translate 110 new languages, including Breton and Occitan, as well as 31 African languages, among them Tamazight (Berber), Afar, Wolof, Dyula and Baoulé. According to Google, these languages represent 200 million speakers on the continent.
"Today, you can photograph a label in Mandarin and see it translated by Google Lens into Dyula," said Abdoulaye Diack, program manager at Google's artificial intelligence (AI) lab in Accra, Ghana, who said he wants to "bring communities together" with this new service.
Establishing these translation models was a major challenge, given the lack of available resources. Half of the content written on the internet is in English. French accounts for just 3%, and the many African languages for less than 1%. "There are blogs and news sites in Swahili, Hausa and Wolof, but many African languages have predominantly oral uses," Diack explained. "So the first task was to identify the written sources available." In addition to these sites, some major texts have been translated into almost every language on the planet, including the Universal Declaration of Human Rights, the Bible and the Quran.
'An incentive effect'
Google's teams then worked with linguists from several faculties, such as the University of Ghana, and NGOs to accumulate data on all the targeted languages. These components were then used to train Google's AI, a learning model called PaLM2, which has already been tested with almost 400 languages. "Artificial intelligence is like a child," Diack summarized. "The more data the model receives, the more it learns, and the better the result."
Google's partners in the target communities – including organizations defending endangered languages and researchers – were asked to evaluate and improve the first AI translations until they reached a sufficient quality and quantity to launch the update. "This process takes several years. The results are not perfect, but they are satisfactory enough to be usable," explained Diack. "There are bound to be mistakes, but it will be useful for a lot of people."
This view is shared by Ivorian linguist Jérémie N'Guessan Kouadio, co-author of a French-Baoulé dictionary, whom Le Monde asked to test the new Google Translate update. "The Baoulé language is inseparable from its orality," he said. "To improve the result, we'd need, for example, to be able to render tones, those phonemes that can change the meaning of a word, which we note with diacritical marks below the syllable. Take 'sa': If I pronounce it with a high tone, it means 'the hand.' But with a low tone, it means 'thus.' All the languages of Côte d'Ivoire work like that, including Dyula."
Despite his reservations, N'Guessan Kouadio acknowledged that the software "has its uses." "For years, people have been trying to convince Africans – and Ivorians – that they can speak French or English, but also speak and write in their mother tongue," said the researcher. "I think software like this will have an incentive effect, particularly on young people in the diaspora who have drifted away from their language of origin."
Professional uses are also conceivable. The African languages previously added (five in 2020 and 10 in 2022, including Bambara, Lingala and Twi) are available as open source through Application Programming Interfaces (APIs), which enable a Google program or service to be connected. The software could also facilitate the work of human interpreters, predicted Yao Kanga Tanoh, from Côte d'Ivoire, whose translation orders mainly concern administrative documents: "Of course, I'll have to rework the result, but a machine translation will save me a lot of time."
The Silicon Valley giant has no intention of stopping there. It has set itself the medium-term goal of integrating a thousand languages, prioritized according to several criteria: the number of speakers, the feasibility of the project in terms of the abundance of written resources, but also the desire of the relevant community. "People had been asking us for Wolof for years," said Diack. His team also intends to develop a speech recognition and synthesis system for the recently added languages, as already exists for the previous ones. With this technology, a telephone will be able to instantly repeat a French sentence in Baoulé, a particularly useful option for illiterate speakers.
Google also claims to want to immortalize endangered languages, largely not used by younger generations. One of these is the N'Ko language, invented in 1949 by Guinean writer Solomana Kanté, with its unique alphabet designed to empower Mandingo communities by providing them with their own writing system.
"Sran ng'ɔ bo alɛ'n i jɔ'n, ɔ diman alɛ sɔ'n wie." This Baoulé proverb is now translatable with Google Translate: "He who declares war does not participate in it."
Since its new update on June 27, the software from the American giant has been able to translate 110 new languages, including Breton and Occitan, as well as 31 African languages, among them Tamazight (Berber), Afar, Wolof, Dyula and Baoulé. According to Google, these languages represent 200 million speakers on the continent.
"Today, you can photograph a label in Mandarin and see it translated by Google Lens into Dyula," said Abdoulaye Diack, program manager at Google's artificial intelligence (AI) lab in Accra, Ghana, who said he wants to "bring communities together" with this new service.
Establishing these translation models was a major challenge, given the lack of available resources. Half of the content written on the internet is in English. French accounts for just 3%, and the many African languages for less than 1%. "There are blogs and news sites in Swahili, Hausa and Wolof, but many African languages have predominantly oral uses," Diack explained. "So the first task was to identify the written sources available." In addition to these sites, some major texts have been translated into almost every language on the planet, including the Universal Declaration of Human Rights, the Bible and the Quran.
'An incentive effect'
Google's teams then worked with linguists from several faculties, such as the University of Ghana, and NGOs to accumulate data on all the targeted languages. These components were then used to train Google's AI, a learning model called PaLM2, which has already been tested with almost 400 languages. "Artificial intelligence is like a child," Diack summarized. "The more data the model receives, the more it learns, and the better the result."
Google's partners in the target communities – including organizations defending endangered languages and researchers – were asked to evaluate and improve the first AI translations until they reached a sufficient quality and quantity to launch the update. "This process takes several years. The results are not perfect, but they are satisfactory enough to be usable," explained Diack. "There are bound to be mistakes, but it will be useful for a lot of people."
This view is shared by Ivorian linguist Jérémie N'Guessan Kouadio, co-author of a French-Baoulé dictionary, whom Le Monde asked to test the new Google Translate update. "The Baoulé language is inseparable from its orality," he said. "To improve the result, we'd need, for example, to be able to render tones, those phonemes that can change the meaning of a word, which we note with diacritical marks below the syllable. Take 'sa': If I pronounce it with a high tone, it means 'the hand.' But with a low tone, it means 'thus.' All the languages of Côte d'Ivoire work like that, including Dyula."
Despite his reservations, N'Guessan Kouadio acknowledged that the software "has its uses." "For years, people have been trying to convince Africans – and Ivorians – that they can speak French or English, but also speak and write in their mother tongue," said the researcher. "I think software like this will have an incentive effect, particularly on young people in the diaspora who have drifted away from their language of origin."
Professional uses are also conceivable. The African languages previously added (five in 2020 and 10 in 2022, including Bambara, Lingala and Twi) are available as open source through Application Programming Interfaces (APIs), which enable a Google program or service to be connected. The software could also facilitate the work of human interpreters, predicted Yao Kanga Tanoh, from Côte d'Ivoire, whose translation orders mainly concern administrative documents: "Of course, I'll have to rework the result, but a machine translation will save me a lot of time."
The Silicon Valley giant has no intention of stopping there. It has set itself the medium-term goal of integrating a thousand languages, prioritized according to several criteria: the number of speakers, the feasibility of the project in terms of the abundance of written resources, but also the desire of the relevant community. "People had been asking us for Wolof for years," said Diack. His team also intends to develop a speech recognition and synthesis system for the recently added languages, as already exists for the previous ones. With this technology, a telephone will be able to instantly repeat a French sentence in Baoulé, a particularly useful option for illiterate speakers.
Google also claims to want to immortalize endangered languages, largely not used by younger generations. One of these is the N'Ko language, invented in 1949 by Guinean writer Solomana Kanté, with its unique alphabet designed to empower Mandingo communities by providing them with their own writing system.
A team of researchers has conducted the first study of how baby and adult brains interact during natural play, and they found measurable connections in their neural activity. In other words, baby and adult brain activity rose and fell together as they shared toys and eye contact.
Every word we use has a purpose. It helps to communicate an idea, express an emotion, or describe an item. As time goes on, new concepts emerge, and we need new words to describe them. We analyzed various online English dictionaries, including Merriam-Webster and Urban Dictionary, to create a list of 30 words that weren’t in use before the 1990s but are now commonly used. This list reflects the constant evolution of our language as we try to keep up with the changing world around us.
The advent of the digital era has transformed communication, streamlining it through the channels of social media. Our commonplace lexicon now incorporates numerous neologisms—freshly coined words—conveying notions that would have been unfamiliar in the past. Within our non-exhaustive compilation, numerous words result from the fusion of two existing terms to characterize a new concept.
Some amalgamate Latin etymologies, while others have transitioned from nouns to verbs in popularity. To formulate this roster of 30 words absent from the lexicon 30 years ago, we have scrutinized several online English dictionaries for definitions and meanings, with exclusions made for terms like “social media.”
Expressions with pre-existing meanings that underwent transformation, such as “muggle,” were also omitted. Originally a colloquial reference to marijuana, “muggle” acquired a new significance through its adoption by J. K. Rowling in the Harry Potter series, now denoting individuals lacking specific skills. Following are the 30 words (along with their origins) that weren’t in use before the 1990s but are now commonly used:
Hater First used circa: 1991 Meaning: A negative or critical person Notably popularized by the 1997 song “Playa Hater” by Notorious B.I.G, with roots traced back to Cypress Hill’s 1991 song “Psycobetabuckdown” in the hip-hop dictionary The Right Rhymes. Smartphone First used circa: 1992 Meaning: A mobile phone that performs many computer functions Though commonly associated with the 2007 release of the first iPhone, the term “smartphone” originated in 1992 with the creation of the Simon Personal Communicator by IBM, combining cell phone and personal digital assistant (PDA) functions. Boop First used circa: 1992 Meaning: Affectionately poking someone on the nose and saying “Boop!” Popularized by a 1992 episode of “The Simpsons,” where the character Bart playfully pokes his sister’s nose while making the sound “boop.” Upcycle First used circa: 1994 Meaning: Reusing materials to create a product of higher quality than the original Coined in a 1994 interview with Thornton Kay, discussing waste disposal systems, and gained traction with the 2002 publication of the book “Cradle to Cradle: The Way We Make Things.” Wi-Fi First used circa: 1997 Meaning: Wireless network protocols allowing devices to connect to the internet Invented in 1997, Wi-Fi led to the establishment of standards for communication in wireless local area networks (WLANs). Emoji First used circa: 1997 Meaning: A small digital image used to express an idea or emotion Originating from the Japanese words for “picture” and “character,” the first known emoji appeared on a mobile phone in 1997 by J-Phone (now SoftBank). Cyberbullying First used circa: 1998 Meaning: The use of electronic communication to bully a person Documented in 1998, the term gained prominence as online harassment, including cases like the 2007 suicide of 13-year-old Megan Meier, was linked to tragic outcomes. Blog First used circa: 1999 Meaning: A regularly updated web page written in an informal style Short for “weblog,” attributed to Jorn Barger, with the term “blog” commonly shortened by programmer Peter Merholz. Vlog First used circa: 2000 Meaning: A blog in the form of a video Credited to Adam Kontras, the first vlog was posted on January 2, 2000, featuring Kontras bringing a cat into a hotel with a “No Pets” policy. FOMO First used circa: 2000 Meaning: Fear of missing out Theories suggest creation in 2000 as a marketing term by Dan Herman or in 2004 by Harvard business student Patrick McGinnis, who popularized the term describing overly ambitious managers. Bromance First used circa: 2001 Meaning: A close friendship between men Coined around 2001, “bromance” combines “bro” (brother) and “romance,” encapsulating the idea of a deep friendship, often referred to as a “brother from another mother.” Showmance First used circa: 2001 Meaning: A romantic relationship that develops between cast members Originating in 2001 within the context of reality TV, “showmance” denotes a romance between cast members or production crew that typically lasts only during the show’s duration. Google First used circa: 2002 Meaning: Searching for information using the search engine Google While the Google search engine was established in 1998, the term “google” as a transitive verb emerged in 2002, notably used in the TV show “Buffy The Vampire Slayer.” Selfie First used circa: 2002 Meaning: A photograph that one has taken of oneself Although the act of taking self-portraits dates back to 1839, the term “selfie” was coined in 2002 when an inebriated Australian described his self-portrait as a “selfie,” later declared the word of the year by Oxford Dictionaries in 2013. Sexting First used circa: 2004 Meaning: Sending sexually explicit photographs or messages via text Coined in 2004 during a text messaging scandal involving David Beckham, “sexting” gained mainstream use in 2008, revealing the prevalence of sending explicit content via text messages. Facebook First used circa: 2004 Meaning: A social network Launched in 2004 as “Thefacebook,” the term “facebook” transformed into a verb, signifying the act of spending time on the social networking website. Podcast First used circa: 2004 Meaning: A digital audio program available for download Originating from audio blogging in the 1980s, “podcast” was first coined by Ben Hammersley in The Guardian in 2004 to describe downloadable analytical radio programming. Paywall First used circa: 2005 Meaning: A system in which access to all or part of a website is restricted to paid subscribers Although The Wall Street Journal implemented a paywall in 1997, the term “paywall” was officially recorded in 2005, representing the practice of restricting website access to paying subscribers. Locavore First used circa: 2005 Meaning: People who mainly eat food produced within a 250-mile radius of where they live Coined by Jessica Prentice in 2005, “locavore” describes individuals who prioritize consuming locally sourced food, derived from the Latin words “locus” (place) and “vorare” (swallow). Turnt First used circa: 2005 Meaning: Extremely excited, wild, or drunk Initially documented in 2005 by Urban Dictionary, “turnt” gained visibility on Twitter in 2008, with its precise origin, particularly speculated to have connections to hip-hop music. YouTuber First used circa: 2006 Meaning: A frequent user of the video-sharing website YouTube Coined in 2006, “YouTuber” emerged as a term for individuals actively engaged with the YouTube platform, officially recognized by the Oxford English Dictionary in 2016. Clickbait First used circa: 2006 Meaning: Content the main purpose of which is to encourage people to click on a link Originating around 2006 and officially added to the Oxford English Dictionary in 2016, “clickbait” refers to content designed to entice clicks, a term that gained prominence with the rise of online media. Crowdsourcing First used circa: 2006 Meaning: Obtaining information by enlisting the services of a large number of people Coined in a 2006 Wired article titled “Rise of Crowdsourcing” by Jeff Howe, describing the utilization of a large pool of individuals for creating content and solving problems. Hashtag First used circa: 2007 Meaning: A word or phrase preceded by a hash sign Contrary to popular belief, the hashtag was introduced to Twitter in 2007 by user Chris Messina, suggesting its use for grouping discussions with the symbol #. Birther First used circa: 2008 Meaning: A person who claims President Barack Obama was born outside the US Coined during the 2008 presidential campaign, “birther” describes individuals who falsely asserted that Barack Obama was not a natural-born U.S. citizen. Bitcoin First used circa: 2008 Meaning: A type of digital currency Although the cryptocurrency Bitcoin was created in 2009, the term was first documented in 2008 when the domain bitcoin.org was registered. Photobomb First used circa: 2008 Meaning: Sneaking into the background of people’s photographs While added to the Merriam-Webster Dictionary in 2017, “photobomb” traces back to a 2008 entry on Urban Dictionary, defining the act of intentionally intruding into the background of a photo. Adulting First used circa: 2008 Meaning: To do the things that adults regularly have to do Gaining popularity with millennials, “adulting” refers to the process of performing typical adult responsibilities and was first observed in a 2008 tweet. Omnishamble First used circa: 2009 Meaning: Something that is totally disorganized and a complete failure Coined in 2009 in the British political satire “The Thick of It,” “omnishamble” combines “omni” meaning “all” with “shambles.” Bingeable First used circa: 2013 Meaning: A show having multiple episodes or parts that can be watched in rapid succession Coined around 2013 and officially recognized by the Merriam-Webster Dictionary in 2018, “bingeable” describes a show with episodes conducive to rapid and continuous watching, particularly with the advent of streaming services like Netflix.
"Every word we use has a purpose. It helps to communicate an idea, express an emotion, or describe an item. As time goes on, new concepts emerge, and we need new words to describe them. We analyzed various online English dictionaries, including Merriam-Webster and Urban Dictionary, to create a list of 30 words that weren’t in use before the 1990s but are now commonly used. This list reflects the constant evolution of our language as we try to keep up with the changing world around us.
The advent of the digital era has transformed communication, streamlining it through the channels of social media. Our commonplace lexicon now incorporates numerous neologisms—freshly coined words—conveying notions that would have been unfamiliar in the past. Within our non-exhaustive compilation, numerous words result from the fusion of two existing terms to characterize a new concept.
Some amalgamate Latin etymologies, while others have transitioned from nouns to verbs in popularity. To formulate this roster of 30 words absent from the lexicon 30 years ago, we have scrutinized several online English dictionaries for definitions and meanings, with exclusions made for terms like “social media.”
Expressions with pre-existing meanings that underwent transformation, such as “muggle,” were also omitted. Originally a colloquial reference to marijuana, “muggle” acquired a new significance through its adoption by J. K. Rowling in the Harry Potter series, now denoting individuals lacking specific skills. Following are the 30 words (along with their origins) that weren’t in use before the 1990s but are now commonly used:
Hater First used circa: 1991 Meaning: A negative or critical person Notably popularized by the 1997 song “Playa Hater” by Notorious B.I.G, with roots traced back to Cypress Hill’s 1991 song “Psycobetabuckdown” in the hip-hop dictionary The Right Rhymes.
Smartphone First used circa: 1992 Meaning: A mobile phone that performs many computer functions Though commonly associated with the 2007 release of the first iPhone, the term “smartphone” originated in 1992 with the creation of the Simon Personal Communicator by IBM, combining cell phone and personal digital assistant (PDA) functions.
Boop First used circa: 1992 Meaning: Affectionately poking someone on the nose and saying “Boop!” Popularized by a 1992 episode of “The Simpsons,” where the character Bart playfully pokes his sister’s nose while making the sound “boop.”
Upcycle First used circa: 1994 Meaning: Reusing materials to create a product of higher quality than the original Coined in a 1994 interview with Thornton Kay, discussing waste disposal systems, and gained traction with the 2002 publication of the book “Cradle to Cradle: The Way We Make Things.”
Wi-Fi First used circa: 1997 Meaning: Wireless network protocols allowing devices to connect to the internet Invented in 1997, Wi-Fi led to the establishment of standards for communication in wireless local area networks (WLANs).
Emoji First used circa: 1997 Meaning: A small digital image used to express an idea or emotion Originating from the Japanese words for “picture” and “character,” the first known emoji appeared on a mobile phone in 1997 by J-Phone (now SoftBank).
Cyberbullying First used circa: 1998 Meaning: The use of electronic communication to bully a person Documented in 1998, the term gained prominence as online harassment, including cases like the 2007 suicide of 13-year-old Megan Meier, was linked to tragic outcomes.
Blog First used circa: 1999 Meaning: A regularly updated web page written in an informal style Short for “weblog,” attributed to Jorn Barger, with the term “blog” commonly shortened by programmer Peter Merholz.
Vlog First used circa: 2000 Meaning: A blog in the form of a video Credited to Adam Kontras, the first vlog was posted on January 2, 2000, featuring Kontras bringing a cat into a hotel with a “No Pets” policy.
FOMO First used circa: 2000 Meaning: Fear of missing out Theories suggest creation in 2000 as a marketing term by Dan Herman or in 2004 by Harvard business student Patrick McGinnis, who popularized the term describing overly ambitious managers.
Bromance First used circa: 2001 Meaning: A close friendship between men Coined around 2001, “bromance” combines “bro” (brother) and “romance,” encapsulating the idea of a deep friendship, often referred to as a “brother from another mother.”
Showmance First used circa: 2001 Meaning: A romantic relationship that develops between cast members Originating in 2001 within the context of reality TV, “showmance” denotes a romance between cast members or production crew that typically lasts only during the show’s duration.
Google First used circa: 2002 Meaning: Searching for information using the search engine Google While the Google search engine was established in 1998, the term “google” as a transitive verb emerged in 2002, notably used in the TV show “Buffy The Vampire Slayer.”
Selfie First used circa: 2002 Meaning: A photograph that one has taken of oneself Although the act of taking self-portraits dates back to 1839, the term “selfie” was coined in 2002 when an inebriated Australian described his self-portrait as a “selfie,” later declared the word of the year by Oxford Dictionaries in 2013.
Sexting First used circa: 2004 Meaning: Sending sexually explicit photographs or messages via text Coined in 2004 during a text messaging scandal involving David Beckham, “sexting” gained mainstream use in 2008, revealing the prevalence of sending explicit content via text messages.
Facebook First used circa: 2004 Meaning: A social network Launched in 2004 as “Thefacebook,” the term “facebook” transformed into a verb, signifying the act of spending time on the social networking website.
Podcast First used circa: 2004 Meaning: A digital audio program available for download Originating from audio blogging in the 1980s, “podcast” was first coined by Ben Hammersley in The Guardian in 2004 to describe downloadable analytical radio programming.
Paywall First used circa: 2005 Meaning: A system in which access to all or part of a website is restricted to paid subscribers Although The Wall Street Journal implemented a paywall in 1997, the term “paywall” was officially recorded in 2005, representing the practice of restricting website access to paying subscribers.
Locavore First used circa: 2005 Meaning: People who mainly eat food produced within a 250-mile radius of where they live Coined by Jessica Prentice in 2005, “locavore” describes individuals who prioritize consuming locally sourced food, derived from the Latin words “locus” (place) and “vorare” (swallow).
Turnt First used circa: 2005 Meaning: Extremely excited, wild, or drunk Initially documented in 2005 by Urban Dictionary, “turnt” gained visibility on Twitter in 2008, with its precise origin, particularly speculated to have connections to hip-hop music.
YouTuber First used circa: 2006 Meaning: A frequent user of the video-sharing website YouTube Coined in 2006, “YouTuber” emerged as a term for individuals actively engaged with the YouTube platform, officially recognized by the Oxford English Dictionary in 2016.
Clickbait First used circa: 2006 Meaning: Content the main purpose of which is to encourage people to click on a link Originating around 2006 and officially added to the Oxford English Dictionary in 2016, “clickbait” refers to content designed to entice clicks, a term that gained prominence with the rise of online media.
Crowdsourcing First used circa: 2006 Meaning: Obtaining information by enlisting the services of a large number of people Coined in a 2006 Wired article titled “Rise of Crowdsourcing” by Jeff Howe, describing the utilization of a large pool of individuals for creating content and solving problems.
Hashtag First used circa: 2007 Meaning: A word or phrase preceded by a hash sign Contrary to popular belief, the hashtag was introduced to Twitter in 2007 by user Chris Messina, suggesting its use for grouping discussions with the symbol #.
Birther First used circa: 2008 Meaning: A person who claims President Barack Obama was born outside the US Coined during the 2008 presidential campaign, “birther” describes individuals who falsely asserted that Barack Obama was not a natural-born U.S. citizen.
Bitcoin First used circa: 2008 Meaning: A type of digital currency Although the cryptocurrency Bitcoin was created in 2009, the term was first documented in 2008 when the domain bitcoin.org was registered.
Photobomb First used circa: 2008 Meaning: Sneaking into the background of people’s photographs While added to the Merriam-Webster Dictionary in 2017, “photobomb” traces back to a 2008 entry on Urban Dictionary, defining the act of intentionally intruding into the background of a photo.
Adulting First used circa: 2008 Meaning: To do the things that adults regularly have to do Gaining popularity with millennials, “adulting” refers to the process of performing typical adult responsibilities and was first observed in a 2008 tweet.
Omnishamble First used circa: 2009 Meaning: Something that is totally disorganized and a complete failure Coined in 2009 in the British political satire “The Thick of It,” “omnishamble” combines “omni” meaning “all” with “shambles.”
Bingeable First used circa: 2013 Meaning: A show having multiple episodes or parts that can be watched in rapid succession Coined around 2013 and officially recognized by the Merriam-Webster Dictionary in 2018, “bingeable” describes a show with episodes conducive to rapid and continuous watching, particularly with the advent of streaming services like Netflix."
The principle of the arbitrariness of the sign is not doubted by anyone, but it is often easier to discover a truth than to assign it its rightful place. This principle dominates all of linguistics — its consequences are innumerable. It is true that they do not appear all at once with equal clarity. It is after many detours that you discover them, and with them the primordial importance of the principle.
— Ferdinand de Saussure1
If you’re reading this, you probably understand English. It happens to be the de facto and sometimes de jure language of the U.S. legal systems,2 but some forms of “English” are more equal than others. Much work has reckoned with the contours of due process when people come to court with little to no English proficiency,3 but what about dialectal misinterpretation?4 English has numerous dialects, many birthed on what is now U.S. soil, but state and federal law have no coherent dialectal jurisprudence.5 The potential for error is worrying.6
Here, the goal is not to prove errors happen but to see whether the Constitution cares errors happen. It does. More precisely, the Due Process Clauses of the Constitution demand that the executive and judicial branches maintain procedures to avoid inaccurate transmission of linguistic data that adversely affects litigants. A mouthful to be sure, but the argument is that it is a violation of procedural due process to maintain procedures that will reliably cause misinterpretation of plain English and make it harder for litigants, especially criminal defendants, to win their cases. Intuitively, something’s amiss when the legal system, seemingly arbitrarily, messes up when interpreting some forms of English and not others. Past scholarship on dialect has brought invaluable attention to the subject, and this Note seeks to continue that burgeoning tradition by showing how the status quo raises constitutional concerns and by serving as a resource and model for dialectal analysis going forward.
Part I showcases a few prominent English-to-English errors the legal system has made before, using Black English as the lens. One may wonder at the choice to use examples from only Black English when the point applies to any dialect. This is because of the insidiousness of the errors. Black English is a widespread dialect and one whose population of speakers is disproportionately represented in criminal adjudication, where colloquial testimony often features prominently. The point is general, but the readily available evidence is not. Furthermore, while it is probably true that racial minorities disproportionately bear the brunt of interpretive mistakes, any equal protection implications are for a different Note.7 Here, the focus is on language qua language, which, while correlated with race, needn’t be inextricably tied to it. Part II demonstrates that the legal system should think of these mistakes as procedural in nature with judicially administrable remedies. Part III argues that the Constitution has an open door for dialectal due process claims. And Part IV tours English legal history and documents the expansion of dialectal diversity to show how principles of linguistic fairness run deep.
I. Linguistic Mistakes
The linguistic mistakes here are not the relatively predictable ones that arise from bad or no interpreters for a non-native English speaker. Instead, these mistakes happen when a native English speaker, indeed someone who might not speak any other language whatsoever, has difficulty being understood, which affects a litigant’s case. Misinterpretation can happen during live trial testimony or even before the police have begun an interrogation.8
These errors are both dangerous and insidious. They are dangerous because cases big and small are won and lost on the minutiae of language, and they are insidious for two reasons. First, if someone misinterprets speech and then carves that misinterpretation into the stone of the judicial record, it might be nigh impossible to uncover that a mistake happened at all. And second, if a monolingual anglophone judge from Macon, Georgia, hears Spanish, the judge knows they don’t understand, but if that same judge hears someone from England say “biscuit” and thinks of their grandmother’s delightful gravy-soaked masterpieces, the judge might not even realize their mistake.
The careful work of estimating exactly how much dialectal misinterpretation happens is for another day, but here, a few examples of the misinterpretation of Black English will serve to illustrate that it happens and matters at least sometimes. In each of these cases, a dialectal misinterpretation occurred that did indeed matter or obviously could have mattered.
Before embarking on this parade of misadventure, a note on something linguists have been screaming from the rooftops for decades, but maybe from rooftops a little too far out of the earshot of the legal system: No dialect is superior or more “correct” than another. Southern English, Black English, Chicano English, Appalachian English, American Indian English, or what have you are not degenerate, lazy, sloppy, or merely slang. Each dialect has an internal structure with rules.9 It’s possible to get things wrong.
What has become standard English in the United States is merely one dialect that had the historical fortune of being propelled to something approaching formal codification.10 It is certainly the written lingua franca, but faithful interpretation requires approaching the language on its own terms. English dialects vary immensely, and any attempt to make a consistent distinction between language and dialect is doomed from the outset.11 Linguists like to say that “a language is a dialect with an army and a navy”12 and that “there are as many languages as speakers.”13 With that in mind, consider these errors.
A. The Lawyer Dog
The “lawyer dog” case is probably the most famous recent clash between the legal system and English dialect. In 2015, New Orleans police wanted to interrogate a twenty-two-year-old black man named Warren Demesme on suspicion of sexual assault.14 Police had brought him in for questioning once before, and Demesme was reportedly getting frustrated, so he said: “if y’all, this is how I feel, if y’all think I did it, I know that I didn’t do it so why don’t you just give me a lawyer dog cause this is not what’s up.”15
The police did not give Demesme a lawyer, and he confessed.16 While Demesme was awaiting trial, his attorneys filed a motion to suppress the confession because the police got it out of him only after an unheeded invocation of the right to counsel.17 The prosecution argued that the statement, which the district attorney’s office provided as written above, was equivocal and therefore did not constitute a request for a lawyer.18 Eventually, the dispute got up to the Supreme Court of Louisiana, where the court denied Demesme’s petition.19
Justice Crichton additionally concurred. He argued that Demesme’s “ambiguous and equivocal reference to a ‘lawyer dog’ does not constitute an invocation of counsel that warrants termination of the interview.”20 He relied on Davis v. United States,21 where the U.S. Supreme Court held that the statement “[m]aybe I should talk to a lawyer” was ambiguous.22
To anyone scarcely familiar with Black English, it is painfully obvious that Demesme was using “dog” here (or, maybe had the defense lawyers been the ones to transcribe the statement, “dawg”) as a more familiar version of “sir.”23 He could have just as easily said “nigga,” “dude,” “man,” or “my guy.” If Demesme had said, “lawyer sir” or “lawyer man,” there would be little debate. This dialectal misinterpretation is likely clear to many who do not speak Black English, but as the next few examples will show, sneakier errors can happen as well.
B. He Finna Shoot Me
In the following case, a federal judge in dissent misinterpreted the Black English present tense as possibly being the past tense, and the majority didn’t disagree. The admissibility of one piece of evidence, whether Joseph Arnold had a gun, hinged on whether a particular statement fit the excited utterance exception to the hearsay rule.24 The majority thought yes, the dissent no. The majority and the dissent also adopted different versions of the testimony in question from a Black woman25 named Tamica Gordon. The majority had her as saying: “I guess he’s fixing to shoot me.”26
Judge Moore disagreed and wrote that “[a]fter listening to the tape multiple times” she did not hear Gordon say “he’s fixing to shoot me” but instead “he finna shoot me.”27 The difference mattered because Judge Moore believed that “[t]he lack of an auxiliary verb renders determination of whether Gordon intended to imply the past or present tense an exercise in sheer guesswork.”28 And conditional on Gordon having said “he finna shoot me,” the majority did not disagree with the dissent’s linguistic analysis.29
But the linguistic analysis was wrong and the tense unambiguous. In Black English, the auxiliary verb in a sentence like this is omittable in the present tense, and only in present tense.30 So “he shooting” means “he is shooting,” not “he was shooting.” Insofar as the admissibility of the evidence turned on whether “he finna shoot me” was in the past tense, Judge Moore’s analysis was incorrect.
Finally, another disturbing feature of Judge Moore’s reasoning. To define “finna,” she used Urban Dictionary, arguing that the consensus nature of the site made it “unusually appropriate” for defining “slang, which is constantly evolving.”31 First, Black English, including “finna,” is not slang. And second, while in this case the definition she used was only marginally wrong32 and likely would not have affected her decision, Urban Dictionary is not the most reliable source. For the uninitiated, this is a user-generated definition site. To demonstrate why the use of Urban Dictionary is troubling, here is one definition of “judge” that is currently on the site:
The unmerciful uncivilized unfair pieces of shit they hire in the so-called “judicial system” which is about the biggest crock of shit there is out there.
Judges are pansies, often punishing the innocent and letting the guilty walk free. That’s why nobody has faith in the judicial system anymore. You’re better off to take the law into your own hands.
Ever been to divorce court? The judge almost always hears out the womans side of the case and totally ignores the mans side. . . .33
The madness continues, but for propriety’s sake the rest of the definition has been omitted. Despite these warning signs, Judge Moore is not alone in relying on Urban Dictionary for definitions.34
C. I’m Gonna Take the TV
Judges don’t always have direct access to a recording like they did in the previous case. A recording might not exist at all, in which case it is up to the transcriber to ensure accurate transmission. Consider one jail call from 2015.
Two linguists listened to a recording of a call the police had transcribed. They noted two particularly important errors. When the suspect said, “He come tell (me) bout I’m gonna take the TV,” the police had transcribed “??? I’m gonna take the TV,” and where the suspect said “I’m fitna be admitted” the police had “I’m fit to be admitted.”35 If these transcripts got to a trial, they could make a dangerous difference.
This is just one phone call. In a now-landmark study, experimenters tested certified court reporters on Black English, and they failed in dramatic fashion:
Despite certification at or above 95% accuracy as required by the Pennsylvania Rules of Judicial Administration, the court reporters performed well below this level . . . . 40.5% of the utterances were incorrectly transcribed in some way. The best performance on the task was 77% accuracy, and the worst was 18% accuracy. . . . [T]he very best of these court reporters, all of whom are currently working in the Philadelphia courts, got one in every five sentences wrong on average, and the worst got more than four out of every five sentences wrong, under better-than-normal working conditions, with the sentence repeated.36
There are obvious limitations to this study.37 It is only one study with only twenty-seven court reporters from only the City of Philadelphia.38 But the potential danger of inaccurate transcription is clear.
Just as worryingly, transcribers sometimes intentionally change dialectal grammar in an effort to “sanitize[]” what they see as defects,39 transmogrifying meaning. Just like writing down a speech loses tone of voice, translating dialect might elide important information if the transcriber doesn’t know what to look for. For example, Black English has more aspectual markings than standard English. So, “he be running” is different than “he running.” The latter means “he’s running,” while the former means something like “he habitually runs, but not necessarily now.” A transcriber who doesn’t know that fact might think “be” is a mistake and transcribe “he is running,” changing the meaning.
D. Tryna Get Ah Glick?
If a dialectal speaker writes something themselves, no one can mishear or mistranscribe, but errors still happen. Cedric Antonio Wright, a defendant, responded “Yea” in a Facebook message to the question of if he was “tryna get ah glick.”40 The Eighth Circuit held that the “Facebook conversation revealed that Wright attempted to trade” for the gun.41 The panel’s ultimate conclusion that a reasonable jury could have determined Wright had the gun is correct given all the evidence, linguistic and not, in the case. However, the conclusion, insofar as the judges tried to make it, that answering in the affirmative to “tryna” reveals an “attempt” is false.
A lesser-known feature of Black English is the bivalence of “tryna.” It can mean “attempting to” as its etymology from “trying to” would suggest, but especially in questions or negative sentences, the term has another meaning — to desire. “You tryna eat?” in most contexts does not mean “are you attempting to eat?” but rather “do you want to eat?”42
Similarly, “you tryna get ah glick?” might not mean “are you attempting to get a Glock?” but rather “do you want to get a Glock?” That is, Wright could have, in theory, responded, “Yeah, I want and need one, but I can’t because that would be illegal.” Even in situations where judges have direct access to written records in the originator’s own hand, dialectal errors can still happen because judges are unaware of the differences.
II. Remedial Procedures
The previous Part showed that errors can occur at any point in the process, whether professional transcribers are hired or judges have direct access to writing or audio. The goal of this Part, then, is to show that these are not just unfortunate, inevitable errors, but unfortunate, preventable errors — preventable through procedure. Consider these potential remedies.
A. Acknowledging Dialect
To ensure reviewability and a complete record, judges, law enforcement interviewers, and transcribers should explicitly record the dialect they are dealing with as specifically as possible. It might be very difficult to tell if something is written in an unfamiliar dialect without reference to something besides the text itself,43 so making sure a police interview or a jail call that gets transcribed indicates the dialect spoken opens the door to more self-conscious interpretation. Suppose the transcript provided to Justice Crichton in the lawyer-dog case had “BLACK ENGLISH” written on the first page. Of course, misinterpretation can still happen, but in that situation, any prospective interpreter must acknowledge that if they are going to hang their hats on technicalities, they have to contend with dialect as well.
A second reason to record the dialect in question when transcribing or interpreting is future proofing. An expert at trial might find it useful to have an earlier assessment of the dialect in question, and an appellate court might be more likely to do a robust linguistic analysis if the dialect is apparent from the get-go. Without recording the dialect, during trial or on appeal, everyone might have to just guess at the proper interpretive framework. Besides making interpretation more self-conscious and reviewable, acknowledging the dialect serves to advance the legitimacy of nonstandard dialects and to promote popular knowledge that they exist and impact court proceedings.
Finally, this idea is not so crazy. Case law already implicitly acknowledges the dialects’ legal relevance. Courts have admitted lay testimony of accent to identify people in the tradition of “linguistic profiling.”44 The most famous example is probably the O.J. Simpson trial — Mr. Johnnie Cochran, Simpson’s lawyer, failed in his objection to the question: “When you heard that voice, you thought that was the voice of a young white male, didn’t you?”45 — but the Kentucky Supreme Court’s language is more explicit:
No one suggests that it [is improper for a lay witness] to identify [a voice] as female. We perceive no reason why a witness could not likewise identify a voice as being that of a particular race or nationality, so long as the witness is personally familiar with the general characteristics, accents, or speech patterns of the race or nationality in question . . . .46
Now, language is not intrinsically tied to race, as the Fifth Circuit has pointed out,47 but insofar as eyewitness testimony as to race is reliable enough to be admissible in a court of law (not to argue it should be), earwitness testimony as to race is astonishingly reliable. One experiment found that people are able to correctly distinguish between Black English speakers, Chicano English speakers, and Standard American English speakers more than seventy percent of the time — when they only heard the word “hello.”48 If courts acknowledge the existence of dialects when identifying suspects, it stands to reason they should acknowledge their existence when it comes to interpretation.
B. Jury Instructions
Pending further research on the best form for such instructions, judges could give juries cautionary instructions when dialects with public opprobrium show up in the courtroom. Factfinders might have prejudice against certain dialects. Linguists have shown that people are very good at identifying dialects very quickly49 and that potential jurors are prejudiced against certain dialects, notably Black English.50 Some find speakers of Black English to be less believable, less trustworthy, more criminal, less comprehensible, and more likely to be in a gang.51 Judges could explicitly instruct jurors that dialect, accent, and nonstandard grammar have no bearing on the truth of testimony or the person’s potential guilt. This might prompt self-conscious deliberation of those prejudices.
The actual instruction would need to be more specific and probably different depending on the testimony presented, but if a speaker of Black English were to testify, the judge might say the following to the jury before they do:
The next witness you will hear speaks Black English. This is a valid dialect of English and not wrong. Some things you hear might be more difficult to understand. Some things you hear might have a different meaning than you might initially think because of grammatical differences. But you must take care not to allow the differences in language alone to affect your judgments of the witness’s credibility. It would be unfair to the parties to ignore or discredit someone’s testimony just because of how they speak.
This Note strongly welcomes and encourages further-refined jury instructions that are most effective and avoid abuse. This particular instruction might very well not do that, and empirical scholarship might have something to say.
A word about implicit bias. While there is almost no reason to doubt implicit bias exists, it is important to note that there is little empirical reason to believe conventional implicit bias training works in changing behavior.52 Similarly, research on the comprehensibility of jury instructions and the effectiveness of limiting instructions and admonitions is far from promising.53 That said, cautionary instructions, which the above model attempts to be, have mixed results in the empirical literature, resulting in either no or a slightly positive effect.54 Given the jury instructions’ tiny cost, further research into benefits and abuses is extremely worthwhile.
C. Dialectal Interpreters
The nuclear option is to get interpreters. This might sound crazy at first, but in 2010 the Drug Enforcement Administration released a memo to much media fanfare requesting nine “Ebonics” translators.55 The benefits of a competent translator are obvious: reduction of misinterpretation and formal recognition of the dialects as valid. And several prominent linguists think such an idea for Black English is at least going in the right direction.56
Now the drawbacks. First, no standardized tests exist for Black English and many other dialects, so for the time being, consistently measuring competency might be impossible. Second, interpreters are costly to train and hire. Third, having a native English speaker use an interpreter might be seen as a slight. And finally, if all there is is a written transcript, an interpreter might be of only limited value.57 One partial solution is to increase the number of jurors familiar with dialects important to the trial.58 When possible, this would help because they might act as informal interpreters,59 but in the case of less common dialects or if the trial happens in a place far from the epicenter of an important dialect, it might not be feasible.
D. Reputable Interpretive Tools
Anyone interpreting dialect, especially judges, should use the best evidence available for determining the meaning of the language in question. While science is never perfect, it only makes sense that borrowing the tools that linguists, lexicographers, semioticians, and historians provide will make interpretation better.
The first step is to not use sources like Urban Dictionary if another option exists. Judges should strongly disfavor any resource that is publicly created, has little moderation, and does not cite sources. For dialects a judge speaks, they might be able to discern what is useful and what is not from less rigorous academic sources, but to rely on such sources for language the judge is unfamiliar with is dangerous.
The second step is to find reputable sources on the dialect in question. A somewhat more accurate, quick-and-dirty, crowdsourced definition site is Wiktionary, which at times explicitly notes the dialect of the word present, gives etymologies, and cites sources. If you question its usefulness, ask yourself if you know the Black English definition of “kitchen.”60 One of Wiktionary’s main limitations is its focus on words and not grammar. Furthermore, many dialects do not have formal dictionaries61 or textbooks, so the next best thing is academic linguistics sources. As with any specialized area, these papers might be opaque to anyone without specialized training, which is unfortunate, but the law asks judges to do many things other than pure legal interpretation.
The Federal Rules of Civil Procedure acknowledge this interdisciplinary approach. Rule 44.1 allows judges to consider “any relevant material or source” when trying to figure out what foreign law means.62 And what this means when judges are faced with other languages can engender colic. Judges Posner and Easterbrook thought “[j]udges should use the best of the available sources,”63 which meant looking at official translations and secondary literature to determine foreign law instead of relying on party-provided expert testimony, which “adds an adversary’s spin.”64 Furthermore, Judge Posner had characteristically colorful words, arguing that the United States’s “linguistic provincialism does not excuse intellectual provincialism.”65 Similar reasoning applies to what judges should do when it comes to dialect. It seems equally provincial, if the term can be excused, to uncritically adopt the prosecution’s transcript when dialect is involved, as happened to Warren Demesme.
E. Audio Recording
If possible, audiovisual or audio recording of statements would reduce error and single points of failure in the system. If someone mistranscribes, it’s permanent unless the source remains. Compared with mere acknowledgment and citing reputable sources, recording and storing audio have more-than-negligible costs,66 but they’re still probably much cheaper than professionally qualified court interpreters who get $495 per day in federal court.67 Recording’s main drawback is its inability to be universally applied. If the only thing the court has is earwitness testimony of something that happened out of court, nothing can be done. But when it is possible for the government to record testimony, doing so would both reduce error in the first instance and make it possible to remedy errors that do happen.
F. Transcriber Training
The shocking statistics from the Philadelphia experiment, if anywhere near generalizable, indicate that federal and state governments should mandate training in common dialects for all transcribers, and the National Court Reporters Association should create standard curricula for transcribing both common and uncommon dialects. Having standards will both reduce error and make accurate transcription more accessible. Currently, at the federal level, the Judicial Conference recognizes as certified those who pass the Certified Realtime Reporter exam,68 which requires an accuracy of ninety-six percent on five minutes of real-time testimony at two hundred words per minute.69 Notably, the Association has no standardized testing, training, or certification for dialect.70 Building that infrastructure will be costly and take time, but the current certification process might mean very little for many English speakers.
III. Dialectal Due Process as Procedural Due Process
Procedures that produce dialectal misinterpretation create constitutional concerns. Just because a particular procedural safeguard would reduce the likelihood of error does not mean the government has to do it, but courts do need to impose some measures. The question here is not whether the state is depriving someone of a right in the first place but whether dialectal misinterpretations implicate due process at all. They do for the simple reason that the “fundamental requirement of due process is the opportunity to be heard ‘at a meaningful time and in a meaningful manner.’”71 Many courts have required an interpreter when a litigant understands little to no English,72 but this Part argues intra-English issues are also worthy of remediation.
“For all its consequence, ‘due process’ has never been, and perhaps can never be, precisely defined.”73 But if there is a flagship article for what procedural due process means, it is Judge Friendly’s “Some Kind of Hearing,” and if there is a flagship case for what procedural due process means, it is Mathews v. Eldridge.74 This Part’s work is to analyze which factors dialectal misinterpretation implicates and why consistent misinterpretation can lead to less-than-meaningful hearings. As the title of Judge Friendly’s article hints, current law around what process is due is fluid and depends on the particular circumstances, and since dialectal misinterpretation transcends circumstance, the Constitution will demand no uniform rule. The conclusion here is not that such and such a procedure with respect to dialect is required but rather that some procedure with respect to dialect is required.
A. Mathews v. Eldridge
Mathews requires an opportunity to be heard “in a meaningful manner.”75 Reasonable minds can disagree about what this means, but analyzing Mathews’s balancing test shows that dialectal misinterpretation implicates exactly what judges must consider when shaping the contours of constitutionally required process. Mathews commands that to decide whether the Constitution requires more or different process in a case, courts must consider:
First, the private interest that will be affected by the official action; second, the risk of an erroneous deprivation of such interest through the procedures used, and the probable value, if any, of additional or substitute procedural safeguards; and finally, the Government’s interest, including the function involved and the fiscal and administrative burdens that the additional or substitute procedure requirement would entail.76
If the mistakes showcased in Part I tell anything, it is that these mistakes do matter at least sometimes, and in big ways. This section will touch on all three factors and the case’s axiomatic proclamation that due process requires an opportunity to be heard in a “meaningful manner.”
Dialectal misinterpretation can feature in any case, so the private interest will vary considerably. Empirical work is necessary to determine when dialect does indeed come up most prominently, but it will certainly feature in cases where litigants have a lot at stake, whether that’s criminal charges like in State v. Demesme77 and United States v. Arnold,78 deportation, or parental rights termination. Dialect is always a potential problem.
Moving to the second factor and the risk of erroneous deprivation, more work is necessary before anyone can in good faith make an estimate as to exactly how much dialectal misinterpretation happens and matters for the deprivation. But if the Philadelphia experiment proves generalizable, mistakes might be happening with alarming frequency. The probability will naturally differ by dialect, region, and court. And, when one considers how badly certified court transcribers did in the study that does exist, it’s a hard sell that the risk of erroneous deprivation from the lack of a coherent approach to dialects is too small to be judicially cognizable. For one, Louisiana should have thrown out Demesme’s confession.
And, as Part II demonstrated, there do exist procedural safeguards that have a good chance of reliably protecting against dialectal misinterpretation, both in the short and the long term. If the Louisiana Supreme Court had acknowledged that Demesme was speaking Black English and looked to academic sources on the dialect, he probably would have prevailed. If police-employed jailhouse transcribers had training and testing on dialects, they would likely not transcribe “fitna be admitted” as “fit to be admitted.” Getting precise statistical measurements of how often these problems occur is not possible at the moment, nor is knowing exactly how much any particular procedure will help. That said, Mathews itself said that “[b]are statistics rarely provide a satisfactory measure of the fairness of a decisionmaking process.”79 When it comes to misinterpreting dialect, the principal unfairness is that by having the misfortune of speaking or relying on testimony in the wrong kind of English, defendants find a legal system unprepared to treat them fairly.
On to the government’s interests. Every procedural safeguard will have a different cost. Interpreters are likely the costliest, followed by dialect certification for transcribers. Acknowledging dialects, instructing juries, and using reputable sources are basically costless. And increasing the use of audio recording lies somewhere in between. As with the entire analysis, the strength of the government’s interest is context dependent. But it seems unlikely that the cheapest procedures’ minimal costs would often overcome the specter of erroneous deprivation. Audio recording already happens in many situations, and transcribers already exist. Increasing the adoption of audio recording and improving the accuracy of transcribers for dialects would impose real costs, but for important deprivations, such as physical liberty, due process might often require both. The argument for interpreters is weakest, particularly if there are ways to improve the accuracy of transcribers, but it is not implausible that they should be required for tricky dialects when physical liberty is at stake.
Finally, as has been said but bears repeating, linguistic issues go to due process’s root because the requirement of a “meaningful” opportunity to be heard requires, if anything at all, the hearer to understand the litigants. Dialectal barriers infringe upon understanding at the most basic level, even when the interpreters might not think so. In some circumstances, the litigant or their counsel might catch mistakes as they happen, but in the course of litigation there is not constant confirmation of a sort of consensus ad idem. So, the system cannot place the duty of clearing up misinterpretations at the feet of litigants.
B. “Some Kind of Hearing”
Judge Friendly’s article is incredibly influential, cited by more than 300 cases and by the Supreme Court itself eleven times.80 The article lists eleven factors “that have been considered to be elements of a fair hearing, roughly in order of priority.”81 The factors are not a Restatement-like list of what proceedings require, but a framework for the ways a procedure might implicate due process.82 Dialectal misinterpretation strongly implicates several of these factors, including the bias of the tribunal, a decision based only on the evidence presented, and the making of a record. More tenuously, it also implicates an opportunity to present reasons why the proposed action should not be taken.
Starting with the most fundamental, a tribunal that does not prepare itself for dialectal misinterpretation is biased. Judge Friendly called an unbiased tribunal “a necessary element in every case where a hearing is required.”83 And unselfconscious dialectal interpretation can bias a tribunal. Juries are more likely to evaluate speakers of certain dialects poorly,84 and that is clearly a thumb on the scale against those who rely on such speakers’ credibility. More generally, even if the misinterpretation is not the result of invidious evaluation of the speaker, a tribunal that fails to treat each dialect on its own terms and instead forces them all to conform to one mainstream structure has biased itself against speakers of all those dialects it fails to recognize. Dialect A speakers get good interpretation, but Dialect B speakers get bad interpretation and are thus less able to press their case to the court.
Next, consider the idea that when judges or juries freestyle interpretations of dialectal testimony or base their interpretations on unreputable sources of linguistic information, they are making a decision based on evidence other than that presented. It is not just a mistake but also an injection of unnecessary randomness into the decisionmaking process. Whether the interpreter knows it or not, if they are unprepared for dialects, they might, based on the random similarities or differences with their own dialect, hold incorrectly. The fact that “dawg” sounds like “dog” is historical happenstance, but the result is that Louisiana deprived someone of the right to counsel. An illustration of the point in the extreme: a judge, knowing a smidge of Spanish, would be mistaken if they thought a person who said they couldn’t come to court because they were “embarazada” meant they were too embarrassed to come in. Similarly, a judge cannot conclude “tryna” means “attempt” simply because it sounds like the Standard English “trying to.” Otherwise, stochastics, not evidence, is determining outcomes.
Third, consider the record. The record’s importance is so ingrained that Judge Friendly felt “Americans are as addicted to transcripts as they have become to television; the sheer problem of warehousing these mountains of paper must rival that of storing atomic wastes.”85 And the main purpose of this mass of paper, so the argument goes, is the ability for judicial review or administrative appeal.86 When stenographers and transcribers are systematically bad at interpreting English, then, they vitiate that purpose. The Supreme Court said “denial [of free transcription services to indigent criminal defendants] is a misfit in a country dedicated to affording equal justice to all and special privileges to none in the administration of its criminal law”87 because “[t]here is no meaningful distinction between a rule which would deny the poor the right to defend themselves in a trial court and one which effectively denies the poor an adequate appellate review accorded to all who have money enough to pay the costs in advance.”88 As has been shown, dialectal misinterpretation can not only reduce a transcript’s accuracy but also introduce harmful errors, like changing hearsay (“He come tell (me) bout I’m gonna steal the TV.”) to a confession (“??? I’m gonna steal the TV.”).
Finally, dialectal difficulties implicate the ability to present reasons why a proposed action should not be taken. Pro se litigants might have an “inability to speak effectively for” themselves,89 not only because they don’t understand the law but also because their dialect might not reach the judge as easily. In the situation where a litigant represents themself, if they speak a dialect for which the hearer is not prepared, how much of an opportunity is it?
IV. The Weight of History
Principles of linguistic justice run deep in English legal tradition. And, maybe counterintuitively, dialectal due process was likely much less of a problem in the past because justice was more local and because English probably has more varieties today than ever. So, attempts to foreclose dialectal due process claims on the basis that they didn’t exist historically (assuming they didn’t arguendo) are misguided.
The “primary guide in determining whether the principle in question is fundamental is, of course, historical practice.”90 This idea has special weight when considering the state power to regulate procedure because:
[I]t is normally “within the power of the State to regulate procedures under which its laws are carried out,” . . . and its decision in this regard is not subject to proscription under the Due Process Clause unless “it offends some principle of justice so rooted in the traditions and conscience of our people as to be ranked as fundamental.”91
As the previous Part shows, dialectal due process implicates fundamental principles like unbiased tribunals, but historical practice and circumstances also show linguistic fairness has a pedigree in its own right. The aim is to show not that earlier courts self-consciously accommodated dialect in particular but that they were structurally less likely to have dialectal-misinterpretation issues because juries worked radically differently and there were simply fewer dialects of English to contend with — a problem that will likely only get worse. This Part highlights trends reaching back to pre-Norman England and uses principles of historical linguistics to argue that early courts didn’t necessarily need self-conscious dialectal due process, but courts today do.
A. The Medieval View of Linguistic Fairness
The idea of linguistic due process is old. The Pleading in English Act 136292 rebuffed the “great Mischiefs” resulting from the fact that people had “no Knowledge nor Understanding of that which is said for them or against them” in court, which was in French.93 The statute felt that “reasonably the . . . Laws and Customs [the rather shall be perceived] and known, and better understood in the Tongue used in the said Realm.”94
Fourteenth-century statutes likely don’t explicitly declare dialect’s importance,95 but that does not foreclose constitutional dialectal due process because the Constitution incorporates many common law ideas of fairness. The Act was the beginning of an almost seven-century-long tradition of conducting court in the vernacular. To say, then, that the idea of linguistic misinterpretation (and one subset of that, dialectal misinterpretation) has no historical basis is false.
B. Local Justice
Even if no dedicated procedures for dialectal due process existed historically, justice’s local nature meant that procedure had dialectal protection baked in. If the lion’s share of people investigating and passing judgment on you are your literal neighbors, they are much more likely to understand or even speak your dialect. Local justice has been significantly diluted from the prebiotic broth of medieval England.
First, terminology. A “hundred” was the second-smallest administrative unit in England, bigger than a parish but smaller than a shire.96 The name comes from its origins as consisting of one hundred “hides,” a maddeningly inconsistent unit thought equivalent to the land needed to support a peasant family.97
Hundred courts empaneled juries from the hundred.98 And in Anglo-Saxon England, the most important interaction people had with the Crown occurred in these courts.99 To be sure, some historical Germanic practices, such as defending court judgments by duel,100 fell out of favor, but many of the practices and procedures developed in hundred courts became a model “all over England in the courts of the manors.”101
The earliest juries were something like “a body of neighbours . . . summoned . . . to give upon oath a true answer to some question.”102 The key word is “neighbours.” Hundred jurors would be coming from a much smaller pool than juries today in the United States, meaning they were much more likely to truly be from the same community and speak the same dialect. The number of hundreds into the nineteenth century was somewhere around 800.103 The English population from 1790 to 1800 was around eight million.104 That means a pool of 10,000 people per hundred. For reference, Harvard University has a workforce of around 13,000 people with a student population of around 23,000.105 The low population density itself was a procedural safeguard against dialectal misinterpretation because the factfinder was more likely to speak the relevant dialects.
The average judicial-district population density in the United States at both state and federal levels falls well outside the average in England around 1800 before the nineteenth-century population explosion. The states average a judicial-district population density of around 16 times higher and the federal government’s ninety-four districts leave a population density 350 times higher.106 In sum, jurors today come from more populous districts and serve at random,107 meaning they are less likely to be from truly the same linguistic community as the litigants and witnesses.
Through the centuries these hundred courts slowly lost importance. By the 1830s only a few remained, with even fewer active,108 and other courts certainly existed and empaneled juries.109 Some had even smaller jury pools than the hundred courts.110 And during the hundred courts’ twilight in the 1800s, England saw the rise of county-level justice with justices of the peace or magistrates,111 who still make up about eighty-five percent of the English judiciary,112 and the county courts, which ascended in importance in the mid-1800s.113
But the structure protecting dialectal understanding was not immediately lost. The jurors’ level of involvement ensured a level of dialectal understanding. In the earliest times, jurors served because they knew facts concerning the case and the accused.114 These early juries were self-informing, investigating the facts separate and apart from the trial.115 And although jurors were no longer selected with input from the judges starting in 1730116 or self-informing, they were much more involved in the trial process than they are today. Jurors could ask their own questions, request more witnesses, and, crucially, volunteer their own pertinent knowledge about local custom, people, and places.117 Blackstone gave a categorical answer on jury involvement as it existed when he published the first edition of Book III of his Commentaries in 1768. He wrote that “the practice . . . now universally obtains, that if a juror knows any thing of the matter in issue, he may be sworn as a witness, and give his evidence publicly in court.”118 Such a notion is almost anathema today. But the lawyerization of the courtroom and the separation between the juror’s judicial and personal role was only beginning in this era.119 Since jurors were more local and involved in trial process historically, they would have had many more chances to clear up dialectal misinterpretation in view of the judge and litigants.
C. Dialectal Divergence
The analysis thus far makes a key assumption — that the number of dialects that exist has remained constant. I
"If you don’t pay attention, the almost entirely arbitrary differences between Englishes can cause a huge fuss, whether in U.S. courts or somewhere else.126 But the dialectal diversity in this country means the consequences of seemingly minor linguistic differences are innumerable. Analyzing Supreme Court precedent, population statistics, everyday prejudice, and dialectal grammar reveals that “English” contains multitudes. Maybe the most angst-inducing part of it all is the lack of data, both because this is an understudied area and because misinterpretation is so capable of repetition and very adept at evading review. The legal system relies deeply on language and, a fortiori, on dialect. The latter seeks but recognition."
Translation affects the oval office in more ways than most people realize. Likewise, the commander-in-chief has extraordinary power to shape policy related to translation and language in general.
Can translation shape a presidency? As I argue in a new book, Found in Translation, it can influence the world as we know it. So, it shouldn't be difficult to believe that translation affects the oval office in more ways than most people realize. Likewise, the commander-in-chief has extraordinary power to shape policy related to translation and language in general.
In preparation for a talk I will be delivering at the Jimmy Carter Presidential Library in Atlanta, I decided to explore this question further. In doing so, I discovered many interesting links between translation and President Carter. Here are 10 of the most significant:
1. A historic moment takes place for sign language interpreting. When Carter accepted the Democratic presidential nomination, a sign language interpreter appeared on nationwide television for the very first time. This marked an important and groundbreaking moment, as it helped to highlight awareness of the deaf population living in the United States.
Philip Akoda is one of the faces of digital language preservation in Africa. Through his startup, The African Languages Project (AFLANG), he has championed several projects aimed at preserving African languages and cultures, including a fast-growing Yoruba Dictionary app making waves in the digital space. A graduate of Business Management from the University of Derby, Philip is also a recognised figure when it comes to subjects such as African history and languages. His passion for–and work in promoting–African languages and cultures got him invited to speak at the UK House of Parliament during the Black History Month Celebrations. In this interview with Olufemi Ajasa, this intriguing enigma shares his journey into African language preservation, the recent Yoruba Dictionary app developed by his startup and the importance of technology in preserving African languages and cultures.
Can you tell us about Mr Philip Akoda? Thank you so much. It’s an honour to be here. My name is Philip Akoda, I’m the founder and CEO of The African Languages Project, also known as AFLANG (short for African Languages). The AFLANG Project is an EdTech startup which builds mobile apps aimed at preserving and promoting African languages and culture. We’ve been operating since 2017 and have built several mobile apps for languages such as Ndebele spoken in Zimbabwe, Fante in Ghana and Oromo in Ethiopia. We’ve also built mobile dictionary apps for languages such as Yoruba and Efik, both Nigerian languages. Outside my startup, I’m also a multipublished author and lexicographer.
What is a lexicographer? A lexicographer is a person who writes or compiles dictionaries.
undefined
0:00 / 0:00
How did you come to be a lexicographer? Is there special training for that?
Well, lexicographers can be trained or untrained. There are people in history who wrote dictionaries but did not have prior experience in lexicography. For me, my entry into lexicography began in 2021 when I chose to undertake the task of building the first Efik dictionary app, which is available on the Google Playstore and the App Store. The app took 1 year and 2 months to build, but the outcome was a mobile dictionary app with over 14,000 words. It had definitions, synonyms, antonyms, audio pronunciations, and much more. Then, while the app was still in development, I began writing my first Efik pocket dictionary which I published a few months after the app was released.
Why did you choose to embark on the Efik Dictionary app?
Being of Efik descent via my mother’s lineage, and also having grown up in Calabar, I was obsessed with preserving and promoting the language, so in 2017, I launched the first Efik language learning app on Google Play Store; this was a pioneering effort because no similar apps existed at the time. This milestone then deepened my curiosity about my Efik heritage, leading me to conduct extensive research on Efik history, language, and culture–even uncovering things that a lot of people don’t know about. In fact, it became such that people would consult with me, instead of elders, to learn more about topics in these areas. The knowledge I gained inspired me to write several Wikipedia articles on several aspects of Efik culture and then to co-author my first Efik history book, Groundwork of Eniong Abatim History (1670–2020). I co-authored the book alongside my mother, Prof Winifred Eyoanwan Akoda (née Adam); her mother–that’s my grandmother–was of the Eniong Abatim community and before we embarked on the research and authorship of the book, there was no such work done to preserve her people’s history. Before this historical work, I authored Learn Efik 1–2, an animated language learning book series now widely used in schools across Calabar in Cross River State and housed in prestigious libraries worldwide, including the Bodleian Library at the University of Oxford and the Harvard University Library.
Can you tell us more about the Yoruba dictionary app, what it is all about and what inspired its creation?
The Yoruba Dictionary app was a project I initiated through my AFLANG startup. Interestingly, I found out that my mother, who is an Efik princess, also has Yoruba roots through her paternal grandmother, who was a descendant of Afro-brazilian returnees. So that then got me obsessed with tracing that part of her lineage and exploring the Yoruba language and history. Interestingly, from this, I found out that my last name is actually a Yoruba name; I say interesting because I’m paternally from Benin City, Edo. And apparently, the name has several interpretations in Yoruba, depending on the Yoruba community. Akoda means creator; it is also an orisha. It can also mean Ancestor, which I sometimes find ironic since most people would say the work of a dictionary is an ancestor’s job… Anyway, so this time, working with a much larger team, we managed to build the most comprehensive mobile dictionary app in Africa. Actually, it is even more comprehensive than the Efik dictionary app; it contains over 22,000 words. Then in addition to definitions, audio pronunciations by indigenous speakers, synonyms, antonyms, and phonemic transcriptions, it also has hypernyms, hyponyms, keywords, and dialectal variations for 12 different yoruba dialects including Owo, Egba, Olukunmi, Awori, and so on. I think something that also sets the app apart, besides their novelty, is our inclusion of diacritics… that’s accent marks. I was insistent on this inclusion from the start because otherwise, we’re not being authentic to the language.
What unique features does the app offer to users learning or researching the Yoruba language?
When I describe the app to people, I think the very first thing that shocks them is that we actually took the time to go to the studio and record audio pronunciations by two Yoruba linguists, not just lazily using Google translate or some AI-generation tool; so that is the first unique feature I’ll mention–we also did this for the Efik dictionary app using two indigenous speakers. Also, even though our Yoruba linguists made sure to enunciate slowly, we still added a feature to slow down the audio so that no matter what, you can really hear all the syllables as they should be pronounced. Then besides the uniqueness of the dictionary’s content–which I explained before, there is a word of the day feature where users get notified of a new word every day. This is usually a really fascinating word that users are most likely unfamiliar with. There is also a badges’ rewards system to award users with Yoruba titles for performing certain actions on the app. There is an automated recommended words feature to suggest 5 new yoruba words from our database that users can learn about. It’s also sort of fun because there’s a Regenerate button below your recommendations so every time you tap it, you’ll receive a different set of words to explore. There are also other interesting features: favourites and downloads for storing your favourite words and downloading their audios to listen offline. And knowing people’s internet connectivity issues, we also provide offline mode so you can use the app freely, without internet.
Related News
Nigerian researcher promotes Yoruba language through research, teaching, community engagement
I'll risk my life to see Nigerian language come true - NICO CEO
Dafinone calls for Urhobo language preservation, urges parents to act
How does the app address the challenges of preserving and promoting indigenous languages like Yoruba?
I often tell people that dictionary apps are lifelong companions. Also, the difference between a print hardcopy dictionary or a PDF dictionary versus a dictionary app is that data in the dictionary app can be updated at any time. In fact, we’ve managed to build a whole content management system such that we can update or correct the dictionary’s content immediately and you’ll see it reflected on the app. Now, at present, there are over 57 million Yoruba speakers globally. Yoruba films are also on the rise, but from what I’ve seen, one constraint faced by modern-day Yoruba speakers is the ability to read or write Yoruba with ease. A lot of people I meet can speak Yoruba but cannot write or read Yoruba. So this app also solves the problem of reading and writing since, again going back to the accent marks I mentioned before, you can find words correctly spelt using the Yoruba orthography. And again, the app has audio pronunciations too by real indigenous speakers so that helps users to not just read a word, but know how it is pronounced.
Could you tell us about the team behind the app and their respective contributions?
There were several people on this project, including academics and techies. EdTech, the industry I work in, is a combination of Educational and Technology, so we needed the best minds in both the educational and technological fields. For the educational sector, we worked with various academics in UNILAG, UNILORIN and UI. Many of their names are on the About section of the app. For the technical aspect of the app, my co-founder, Mary-Brenda Akoda led the technical team. Mary-Brenda also happens to be my sister. She is a postgraduate AI researcher at Imperial College London. She is also a Software Engineer with experience at Microsoft and a Google DeepMind Scholar. She was responsible for the UI/UX design and full-stack development of the Yoruba Dictionary app. She was actually the one who introduced the novel features to the app like the badges and the automated recommended words feature. My mother, Prof. Winifred Akoda was also responsible for liaising with academics in universities along the South West to gather data for the dialects and also supervise the data collection process. She’s actually a professor of history and field research and has been doing that for over 30 years, so that was really an asset to our work.
What is it like working with your family?
I love my family. I feel fortunate to have a mother and sister with a strong educational and technical background.
How has the reception been since the app launched?
It has been overwhelmingly positive. In fact, in just two weeks of marketing the app, we had over 12,000 downloads and not just from Nigeria; we got from Cuba as well. And we now have a 4.8 rating on Google Playstore and a 5 out of 5 rating on the App store. We kept getting very positive feedback and excitement from people on social media too; I think people also weren’t expecting such a fun and animated UI/UX design for a dictionary app so that surprised them and got them engaged. We also try to get suggestions from people too so that we make sure we keep improving our users’ experience.
Are there plans to expand the app’s functionality or include additional languages?
We originally intended on adding games to the app, but it was a lot of features to handle all at once. We will still add them in a few months. We’re also working on our next language project, a Hausa Dictionary app.
How about the Igbo language?
We intend to go into that later. Igbo is a bit tricky since we need to take a more dialectical approach for Igbo. Unlike Yoruba, Igbo people lean more towards their dialects. There is the standard Igbo but it is impractical since it is usually relegated to written literature and the educational sector. So for example, if we had two Ekiti people in the room, they are more likely to speak standard Yoruba unless they discover that they are from Ekiti. The case is different with Igbo. Designing the Igbo dictionary app will mean taking into consideration the various Igbo dialects. If users want to search for Mmiri in Igbo, other options will also have to reflect like Mmili and Mmini. Basically, lexicography is a complicated art that requires a lot of critical thinking.
What is your educational background, and how has it shaped your career in lexicography?
I undertook my secondary education in Calabar but also schooled at the Lagos City Computer College, Ikeja for two years. I then attended the University of Essex but then 2016’s recession affected many Nigerian international students, so I couldn’t continue there. But I later graduated from the University of Derby. It was actually while at Essex that I ventured into language preservation. I released my first language learning app–that was the Efik one–while I was a student at the university. Because of the app, I was invited to speak at the Black History Month celebration in the UK House of Parliament… But I cannot say my educational background played a role in my journey into lexicography. These things just happen. Life will take you on a path you will never expect. I thought I would graduate with a computer engineering degree but rather ended up finding my passion for language preservation, establishing AFLANG, and then graduating with a first class honours degree in Business Management from the University of Derby.
Apart from the Yoruba Dictionary app, what other notable projects have you worked on?
I’ve authored an Efik pocket dictionary called A 21st Century Efik Pocket Dictionary, which stands as one of my proudest accomplishments. The work actually represents a fresh approach to Efik lexicography. Unlike the Yoruba language, where tonal marks are applied to vowels, the Efik people prefer not to apply markings when writing letters and other documents. Because of this approach, I devised an innovative method to present Efik words in a manner that resonates with both native speakers and linguists.
Can you share any challenges or breakthroughs in your career as a lexicographer?
I would say that one of my biggest breakthroughs as a lexicographer is introducing the conversation of synonymy, hyponymy, hypernymy, and antonymy–topics that are not given so much limelight in the study of African Languages and Linguistics.
Are there any upcoming publications we should look forward to?
At present, I have 3 more publications I’m working on. One of them is focused on the Yoruba language and will greatly help Yoruba speakers across the world.
Are you a Yoruba speaker?
Interestingly, I am not but I’ve had to work really hard to understand the language. For the current book I’ve been working on, I used over 50books as sources including 16 Yoruba dictionaries and submitted it to 3 academics across the southwest to review and proofread.
In your opinion, what role does technology play in language preservation?
Technology is instrumental to the preservation of our languages. Any language that does not align with technology is greatly at risk, because oral tradition and print books can only go so far.
What advice would you give to young scholars or linguists looking to pursue a career in lexicography? Be patient, be consistent, be curious and be ready to always come out of your comfort zone. To venture into lexicography, you need to be daring. You’re likely to face opposition from more experienced lexicographers, but be open to learning from them and also be courageous enough to find your own path.
Outside of lexicography, what are your interests or hobbies?
I enjoy writing Wikipedia articles. I’ve written a number of them on different aspects of Efik culture and on different personalities as well, both historical and living. I also enjoy swimming and travelling.
What can individuals, organizations, and governments do to support efforts like yours?
Individuals, organizations, and governments play pivotal roles in supporting efforts to preserve and promote indigenous languages. We are actively seeking funding, including donations and grants from both individuals and organizations, to grow and expand, and so that more people get to know about our apps and benefit from them. We are also open to contracting and/or consulting for both local and international organizations that want to increase their language preservation efforts for African languages or to make them digitally available; we already have a highly specialised team of African linguists, lexicographers, and academics, so such collaborations would certainly be within our comfort zone and done in the correct orthography of the language. We are also open to working with governments as well to institutionalise our efforts. The government can implement policies that make indigenous language education mandatory and they can allocate resources for linguistic research and development.
How can people get involved with AFLANG or contribute to the growth of the Yoruba Dictionary app?
Readers and users can get involved by downloading and engaging with our apps, and if they like it, please leave a rating and review so that more people get to find it and learn something new. We also have a Give Feedback option on the app; users should please use it to give us feedback or they can also reach out to us via admin@theaflangproject.org. It helps us understand what works well and what can be improved. Readers can also recommend the Yoruba Dictionary app to friends, family, and colleagues who are interested in learning Yoruba or in preserving indigenous languages. Also, if you have expertise in Yoruba language, culture, or linguistics, you can collaborate with us by contributing new words, phrases, or contextual examples to enrich the dictionary’s content. And of course, as mentioned before, we’re actively seeking funding so that would be another way to get involved, so that we can grow the app, add more features, and expand to many more languages; we hope to develop comprehensive dictionary apps for 10 African languages within the next 5 years. So your involvement, no matter how small, helps us build a stronger foundation for preserving African languages and promoting their global appreciation.
Philip Akoda is one of the faces of digital language preservation in Africa. Through his startup, The African Languages Project (AFLANG), he has championed several projects aimed at preserving African languages and cultures, including a fast-growing Yoruba Dictionary app making waves in the digital space. A graduate of Business Management from the University of Derby, Philip is also a recognised figure when it comes to subjects such as African history and languages. His passion for–and work in promoting–African languages and cultures got him invited to speak at the UK House of Parliament during the Black History Month Celebrations.
In this interview with Olufemi Ajasa, this intriguing enigma shares his journey into African language preservation, the recent Yoruba Dictionary app developed by his startup and the importance of technology in preserving African languages and cultures.
Can you tell us about Mr Philip Akoda?
Thank you so much. It’s an honour to be here. My name is Philip Akoda, I’m the founder and CEO of The African Languages Project, also known as AFLANG (short for African Languages). The AFLANG Project is an EdTech startup which builds mobile apps aimed at preserving and promoting African languages and culture. We’ve been operating since 2017 and have built several mobile apps for languages such as Ndebele spoken in Zimbabwe, Fante in Ghana and Oromo in Ethiopia. We’ve also built mobile dictionary apps for languages such as Yoruba and Efik, both Nigerian languages. Outside my startup, I’m also a multipublished author and lexicographer.
What is a lexicographer?
A lexicographer is a person who writes or compiles dictionaries.
undefined
0:00 / 0:00
How did you come to be a lexicographer? Is there special training for that?
Well, lexicographers can be trained or untrained. There are people in history who wrote dictionaries but did not have prior experience in lexicography. For me, my entry into lexicography began in 2021 when I chose to undertake the task of building the first Efik dictionary app, which is available on the Google Playstore and the App Store. The app took 1 year and 2 months to build, but the outcome was a mobile dictionary app with over 14,000 words. It had definitions, synonyms, antonyms, audio pronunciations, and much more. Then, while the app was still in development, I began writing my first Efik pocket dictionary which I published a few months after the app was released.
Why did you choose to embark on the Efik Dictionary app?
Being of Efik descent via my mother’s lineage, and also having grown up in Calabar, I was obsessed with preserving and promoting the language, so in 2017, I launched the first Efik language learning app on Google Play Store; this was a pioneering effort because no similar apps existed at the time. This milestone then deepened my curiosity about my Efik heritage, leading me to conduct extensive research on Efik history, language, and culture–even uncovering things that a lot of people don’t know about. In fact, it became such that people would consult with me, instead of elders, to learn more about topics in these areas. The knowledge I gained inspired me to write several Wikipedia articles on several aspects of Efik culture and then to co-author my first Efik history book, Groundwork of Eniong Abatim History (1670–2020). I co-authored the book alongside my mother, Prof Winifred Eyoanwan Akoda (née Adam); her mother–that’s my grandmother–was of the Eniong Abatim community and before we embarked on the research and authorship of the book, there was no such work done to preserve her people’s history. Before this historical work, I authored Learn Efik 1–2, an animated language learning book series now widely used in schools across Calabar in Cross River State and housed in prestigious libraries worldwide, including the Bodleian Library at the University of Oxford and the Harvard University Library.
Can you tell us more about the Yoruba dictionary app, what it is all about and what inspired its creation?
The Yoruba Dictionary app was a project I initiated through my AFLANG startup. Interestingly, I found out that my mother, who is an Efik princess, also has Yoruba roots through her paternal grandmother, who was a descendant of Afro-brazilian returnees. So that then got me obsessed with tracing that part of her lineage and exploring the Yoruba language and history. Interestingly, from this, I found out that my last name is actually a Yoruba name; I say interesting because I’m paternally from Benin City, Edo. And apparently, the name has several interpretations in Yoruba, depending on the Yoruba community. Akoda means creator; it is also an orisha. It can also mean Ancestor, which I sometimes find ironic since most people would say the work of a dictionary is an ancestor’s job… Anyway, so this time, working with a much larger team, we managed to build the most comprehensive mobile dictionary app in Africa. Actually, it is even more comprehensive than the Efik dictionary app; it contains over 22,000 words. Then in addition to definitions, audio pronunciations by indigenous speakers, synonyms, antonyms, and phonemic transcriptions, it also has hypernyms, hyponyms, keywords, and dialectal variations for 12 different yoruba dialects including Owo, Egba, Olukunmi, Awori, and so on. I think something that also sets the app apart, besides their novelty, is our inclusion of diacritics… that’s accent marks. I was insistent on this inclusion from the start because otherwise, we’re not being authentic to the language.
What unique features does the app offer to users learning or researching the Yoruba language?
When I describe the app to people, I think the very first thing that shocks them is that we actually took the time to go to the studio and record audio pronunciations by two Yoruba linguists, not just lazily using Google translate or some AI-generation tool; so that is the first unique feature I’ll mention–we also did this for the Efik dictionary app using two indigenous speakers. Also, even though our Yoruba linguists made sure to enunciate slowly, we still added a feature to slow down the audio so that no matter what, you can really hear all the syllables as they should be pronounced. Then besides the uniqueness of the dictionary’s content–which I explained before, there is a word of the day feature where users get notified of a new word every day. This is usually a really fascinating word that users are most likely unfamiliar with. There is also a badges’ rewards system to award users with Yoruba titles for performing certain actions on the app. There is an automated recommended words feature to suggest 5 new yoruba words from our database that users can learn about. It’s also sort of fun because there’s a Regenerate button below your recommendations so every time you tap it, you’ll receive a different set of words to explore. There are also other interesting features: favourites and downloads for storing your favourite words and downloading their audios to listen offline. And knowing people’s internet connectivity issues, we also provide offline mode so you can use the app freely, without internet.
Related News
Nigerian researcher promotes Yoruba language through research, teaching, community engagement
I'll risk my life to see Nigerian language come true - NICO CEO
Dafinone calls for Urhobo language preservation, urges parents to act
How does the app address the challenges of preserving and promoting indigenous languages like Yoruba?
I often tell people that dictionary apps are lifelong companions. Also, the difference between a print hardcopy dictionary or a PDF dictionary versus a dictionary app is that data in the dictionary app can be updated at any time. In fact, we’ve managed to build a whole content management system such that we can update or correct the dictionary’s content immediately and you’ll see it reflected on the app. Now, at present, there are over 57 million Yoruba speakers globally. Yoruba films are also on the rise, but from what I’ve seen, one constraint faced by modern-day Yoruba speakers is the ability to read or write Yoruba with ease. A lot of people I meet can speak Yoruba but cannot write or read Yoruba. So this app also solves the problem of reading and writing since, again going back to the accent marks I mentioned before, you can find words correctly spelt using the Yoruba orthography. And again, the app has audio pronunciations too by real indigenous speakers so that helps users to not just read a word, but know how it is pronounced.
Could you tell us about the team behind the app and their respective contributions?
There were several people on this project, including academics and techies. EdTech, the industry I work in, is a combination of Educational and Technology, so we needed the best minds in both the educational and technological fields. For the educational sector, we worked with various academics in UNILAG, UNILORIN and UI. Many of their names are on the About section of the app. For the technical aspect of the app, my co-founder, Mary-Brenda Akoda led the technical team. Mary-Brenda also happens to be my sister. She is a postgraduate AI researcher at Imperial College London. She is also a Software Engineer with experience at Microsoft and a Google DeepMind Scholar. She was responsible for the UI/UX design and full-stack development of the Yoruba Dictionary app. She was actually the one who introduced the novel features to the app like the badges and the automated recommended words feature. My mother, Prof. Winifred Akoda was also responsible for liaising with academics in universities along the South West to gather data for the dialects and also supervise the data collection process. She’s actually a professor of history and field research and has been doing that for over 30 years, so that was really an asset to our work.
What is it like working with your family?
I love my family. I feel fortunate to have a mother and sister with a strong educational and technical background.
How has the reception been since the app launched?
It has been overwhelmingly positive. In fact, in just two weeks of marketing the app, we had over 12,000 downloads and not just from Nigeria; we got from Cuba as well. And we now have a 4.8 rating on Google Playstore and a 5 out of 5 rating on the App store. We kept getting very positive feedback and excitement from people on social media too; I think people also weren’t expecting such a fun and animated UI/UX design for a dictionary app so that surprised them and got them engaged. We also try to get suggestions from people too so that we make sure we keep improving our users’ experience.
Are there plans to expand the app’s functionality or include additional languages?
We originally intended on adding games to the app, but it was a lot of features to handle all at once. We will still add them in a few months. We’re also working on our next language project, a Hausa Dictionary app.
How about the Igbo language?
We intend to go into that later. Igbo is a bit tricky since we need to take a more dialectical approach for Igbo. Unlike Yoruba, Igbo people lean more towards their dialects. There is the standard Igbo but it is impractical since it is usually relegated to written literature and the educational sector. So for example, if we had two Ekiti people in the room, they are more likely to speak standard Yoruba unless they discover that they are from Ekiti. The case is different with Igbo. Designing the Igbo dictionary app will mean taking into consideration the various Igbo dialects. If users want to search for Mmiri in Igbo, other options will also have to reflect like Mmili and Mmini. Basically, lexicography is a complicated art that requires a lot of critical thinking.
What is your educational background, and how has it shaped your career in lexicography?
I undertook my secondary education in Calabar but also schooled at the Lagos City Computer College, Ikeja for two years. I then attended the University of Essex but then 2016’s recession affected many Nigerian international students, so I couldn’t continue there. But I later graduated from the University of Derby. It was actually while at Essex that I ventured into language preservation. I released my first language learning app–that was the Efik one–while I was a student at the university. Because of the app, I was invited to speak at the Black History Month celebration in the UK House of Parliament… But I cannot say my educational background played a role in my journey into lexicography. These things just happen. Life will take you on a path you will never expect. I thought I would graduate with a computer engineering degree but rather ended up finding my passion for language preservation, establishing AFLANG, and then graduating with a first class honours degree in Business Management from the University of Derby.
Apart from the Yoruba Dictionary app, what other notable projects have you worked on?
I’ve authored an Efik pocket dictionary called A 21st Century Efik Pocket Dictionary, which stands as one of my proudest accomplishments. The work actually represents a fresh approach to Efik lexicography. Unlike the Yoruba language, where tonal marks are applied to vowels, the Efik people prefer not to apply markings when writing letters and other documents. Because of this approach, I devised an innovative method to present Efik words in a manner that resonates with both native speakers and linguists.
Can you share any challenges or breakthroughs in your career as a lexicographer?
I would say that one of my biggest breakthroughs as a lexicographer is introducing the conversation of synonymy, hyponymy, hypernymy, and antonymy–topics that are not given so much limelight in the study of African Languages and Linguistics.
Are there any upcoming publications we should look forward to?
At present, I have 3 more publications I’m working on. One of them is focused on the Yoruba language and will greatly help Yoruba speakers across the world.
Are you a Yoruba speaker?
Interestingly, I am not but I’ve had to work really hard to understand the language. For the current book I’ve been working on, I used over 50books as sources including 16 Yoruba dictionaries and submitted it to 3 academics across the southwest to review and proofread.
In your opinion, what role does technology play in language preservation?
Technology is instrumental to the preservation of our languages. Any language that does not align with technology is greatly at risk, because oral tradition and print books can only go so far.
What advice would you give to young scholars or linguists looking to pursue a career in lexicography?
Be patient, be consistent, be curious and be ready to always come out of your comfort zone. To venture into lexicography, you need to be daring. You’re likely to face opposition from more experienced lexicographers, but be open to learning from them and also be courageous enough to find your own path.
Outside of lexicography, what are your interests or hobbies?
I enjoy writing Wikipedia articles. I’ve written a number of them on different aspects of Efik culture and on different personalities as well, both historical and living. I also enjoy swimming and travelling.
What can individuals, organizations, and governments do to support efforts like yours?
Individuals, organizations, and governments play pivotal roles in supporting efforts to preserve and promote indigenous languages. We are actively seeking funding, including donations and grants from both individuals and organizations, to grow and expand, and so that more people get to know about our apps and benefit from them. We are also open to contracting and/or consulting for both local and international organizations that want to increase their language preservation efforts for African languages or to make them digitally available; we already have a highly specialised team of African linguists, lexicographers, and academics, so such collaborations would certainly be within our comfort zone and done in the correct orthography of the language. We are also open to working with governments as well to institutionalise our efforts. The government can implement policies that make indigenous language education mandatory and they can allocate resources for linguistic research and development.
How can people get involved with AFLANG or contribute to the growth of the Yoruba Dictionary app?
Readers and users can get involved by downloading and engaging with our apps, and if they like it, please leave a rating and review so that more people get to find it and learn something new. We also have a Give Feedback option on the app; users should please use it to give us feedback or they can also reach out to us via admin@theaflangproject.org. It helps us understand what works well and what can be improved. Readers can also recommend the Yoruba Dictionary app to friends, family, and colleagues who are interested in learning Yoruba or in preserving indigenous languages. Also, if you have expertise in Yoruba language, culture, or linguistics, you can collaborate with us by contributing new words, phrases, or contextual examples to enrich the dictionary’s content. And of course, as mentioned before, we’re actively seeking funding so that would be another way to get involved, so that we can grow the app, add more features, and expand to many more languages; we hope to develop comprehensive dictionary apps for 10 African languages within the next 5 years. So your involvement, no matter how small, helps us build a stronger foundation for preserving African languages and promoting their global appreciation.
Ljubljana, 27 December - Slovenian proverbs and sayings may be considered outdated, ancient even, for some, but language remains as alive as ever and new ones are created all the time. Indeed, a linguist who edits the Slovenian Dictionary of Proverbs and Related Paremiological Terms added 120 new headwords to the dictionary this year alone, some from unlikely sources.
1 / 3
2 / 3
3 / 3
Matej Meterc, a researcher at the Fran Ramovš Institute for the Slovenian Language at the Research Centre of the Slovenian Academy of Sciences and Arts, has edited the dictionary since 2020. The latest update contains 637 units.
Old favourites such as the Slovenian equivalents for "where there is smoke, there is fire" and "there is no such thing as a stupid question" rub shoulders with "A si ti tudi noter padel," which comes from a 1948 Slovenian film and later became the title of a popular TV variety show, and the "lačen si ful drugačen," the Slovenian rendition of the Snickers ad slogan "You're not you when you're hungry".
Some old sayings get a new lease on life. "Počasi se daleč pride," broadly the equivalent of slow and steady wins the race, has gotten an ironic twist with the addition of "hitro pa še dlje," which implies that slow and steady is all fine and dandy, but fast is better.
Every era creates new proverbs
Meterc told the STA there is a stereotypical feeling among the people that proverbs are disappearing and only older generations know them. This is far from the truth.
"We tend to perceive the oldest, most traditional expressions connected to nature, agriculture and such as the most characteristic proverbs. Some proverbs indeed become so obsolete we stop using them, but we have to realise that younger generations create new ones that reflect modern experiences and influences," he says.
Such modern sayings often come from literary works, films, songs and even commercials, such as the famous Snickers bar ad. "The saying has become popular and took on a wider meaning. Even though it was created in a marketing context, it has all the characteristics we attribute to proverbs - a sensible message expressing how someone acts differently when they are hungry, and a distinct form."
Another, less recent addition to the dictionary is "od višine se zvrti," the title of a 1987 song by Martin Krpan which resurged in popularity when rock band Siddharta did a cover in 2000.
Old proverbs as expressions of life as it used to be
Older proverbs that are rarely used or have died out merit research as well, according to Meterc, because they provide insight into how people used to live. Winter proverbs in particular are interesting in that they reflect people's attitudes to a season that used to be strongly associated with survival.
"Zima bo barala, kaj smo poleti delali" (winter will tell what we did in summer) is no longer in use, but it is testimony to how storing produce in winter used to be much more important than it is now.
In general, winter proverbs used to be much more popular. However, anti-proverbs are now appearing, such as for example the nonsensical "if there's snow on St Sylvester's, New Year's is not far away," and its negative equivalent "if there's no snow on St Sylvester's, New Year's is not far away."
Adding proverbs to the dictionary is not a simple job, it is based on in-depth research. Meterc analyses language corpora and conducts surveys among speakers of Slovenian.
For him, the dictionary is more than a linguistic project, it reflects the wealth of Slovenian culture, history and modernity. It is a treasure trove suitable for exploration and practical use.
Ljubljana, 27 December - Slovenian proverbs and sayings may be considered outdated, ancient even, for some, but language remains as alive as ever and new ones are created all the time. Indeed, a linguist who edits the Slovenian Dictionary of Proverbs and Related Paremiological Terms added 120 new headwords to the dictionary this year alone, some from unlikely sources.
1 / 3
2 / 3
3 / 3
Matej Meterc, a researcher at the Fran Ramovš Institute for the Slovenian Language at the Research Centre of the Slovenian Academy of Sciences and Arts, has edited the dictionary since 2020. The latest update contains 637 units.
Old favourites such as the Slovenian equivalents for "where there is smoke, there is fire" and "there is no such thing as a stupid question" rub shoulders with "A si ti tudi noter padel," which comes from a 1948 Slovenian film and later became the title of a popular TV variety show, and the "lačen si ful drugačen," the Slovenian rendition of the Snickers ad slogan "You're not you when you're hungry".
Some old sayings get a new lease on life. "Počasi se daleč pride," broadly the equivalent of slow and steady wins the race, has gotten an ironic twist with the addition of "hitro pa še dlje," which implies that slow and steady is all fine and dandy, but fast is better.
Every era creates new proverbs
Meterc told the STA there is a stereotypical feeling among the people that proverbs are disappearing and only older generations know them. This is far from the truth.
"We tend to perceive the oldest, most traditional expressions connected to nature, agriculture and such as the most characteristic proverbs. Some proverbs indeed become so obsolete we stop using them, but we have to realise that younger generations create new ones that reflect modern experiences and influences," he says.
Such modern sayings often come from literary works, films, songs and even commercials, such as the famous Snickers bar ad. "The saying has become popular and took on a wider meaning. Even though it was created in a marketing context, it has all the characteristics we attribute to proverbs - a sensible message expressing how someone acts differently when they are hungry, and a distinct form."
Another, less recent addition to the dictionary is "od višine se zvrti," the title of a 1987 song by Martin Krpan which resurged in popularity when rock band Siddharta did a cover in 2000.
Old proverbs as expressions of life as it used to be
Older proverbs that are rarely used or have died out merit research as well, according to Meterc, because they provide insight into how people used to live. Winter proverbs in particular are interesting in that they reflect people's attitudes to a season that used to be strongly associated with survival.
"Zima bo barala, kaj smo poleti delali" (winter will tell what we did in summer) is no longer in use, but it is testimony to how storing produce in winter used to be much more important than it is now.
In general, winter proverbs used to be much more popular. However, anti-proverbs are now appearing, such as for example the nonsensical "if there's snow on St Sylvester's, New Year's is not far away," and its negative equivalent "if there's no snow on St Sylvester's, New Year's is not far away."
Adding proverbs to the dictionary is not a simple job, it is based on in-depth research. Meterc analyses language corpora and conducts surveys among speakers of Slovenian.
For him, the dictionary is more than a linguistic project, it reflects the wealth of Slovenian culture, history and modernity. It is a treasure trove suitable for exploration and practical use.
Personal Perspective: On creating community and finding safety.
Taylor Gurley O.T.D.
Posted April 25, 2024 | Reviewed by Lybi Ma
“Sticks and stones will break my bones, but words will never hurt me.” The saying takes me back to the playgrounds of my childhood where I heard it chanted countless times. It leaves me wondering, did we really believe it? Or were we trying to convince ourselves of it, to prevent the hurtful words from lodging too deeply into our fragile psyches?
The truth we’ve all grown to know is that sticks and stones can break our bones and words, to our childlike dismay, can both heal and hurt us. Language, in spoken or written form, can be a powerful tool, for good or ill. Language can create safety or encourage violence. Dangerous rhetoric has fueled violence against the LGBTQ+ community. We need to stop dismissing the power of words and begin to use them with intention grounded in unity and kindness.
Toni Morrison stated, "Oppressive language does more than represent violence; it is violence; does more than represent the limits of knowledge; it limits knowledge." With this in mind, we have the opportunity to broaden our understanding that hateful and oppressive language does not just enable violence but is violence itself.
There are many ways violence can manifest in the human body and current statistics show how my community is at an even larger threat to negative outcomes when at baseline we are already experiencing high levels of mental health implications.
Current statistics
LGBTQ+ youth are six times more likely to experience symptoms of depression than non-LGBTQ+ identifying teens. LGBTQ+ youth are more than twice as likely to feel suicidal and over four times as likely to attempt suicide compared to heterosexual youth. In 2022, permanent losses include over 40 LGBTQ+ lives, not including lives lost to suicide.
The leading cause of violent crime? Dehumanizing rhetoric. It becomes the spark to ignite extreme prejudice. We see it over and over: Hate crimes are motivated by fear, ignorance, and anger. And LGBTQ+ people are nearly four times more likely than non-LGBTQ+ people to be victims of violent crime, which can lead to the onset of PTSD (post-traumatic stress disorder), anxiety, depression, self-harm, suicide, and more.
Efforts to increase homophobia
Christina Pushaw, former press secretary for Florida Governor Ron DeSantis and now his rapid response director, used her social media platform to label anyone against Florida’s "Don’t Say Gay" legislation—which prohibits instruction about sexual identity and gender orientation for certain grades in Florida schools—as a probable groomer, a tactic designed to increase homophobia.
Talk show host Candace Owens has attacked LGBTQ+ teachers and challenged the inclusion of non-heteronormative relationships or identity in the classroom, as well as calling members of the LGBTQ+ community predators. On April 5, 2022, The Daily Wire aired a video of Owens discussing the word "gay" and how over time it has carried different meanings. In reference to its offensiveness to the LGBTQ+ community, she said, “…it was cool, hip slang until…we learned that it was hurtful...even though we were never aiming the word at them." To her, every word is fair game as long as we aren’t "aiming it" at someone.
article continues after advertisement
Media strategies such as this, created to promote homophobia, will undoubtedly increase as election efforts become more publicized this year.
Rhetoric can be a powerful tool to create safety or to destroy it.
Youth across the country are using their social-media platforms to express their feelings of being unsure if they can show up authentically as themselves at school and still be safe. Teachers have been bullied. Families are unsure how they will be impacted over time. Further legislation, specifically, in the state of Florida under HB1403, would give medical providers the ability to turn away medical care from people in the LGBTQ+ community if they have “conscience-based objections" to treating them.
Lived experience in the LGBTQ+ community
Determining safety is nothing new to members of the LGBTQ+ community. What would be new is not expending emotional and mental energy trying to identify where it is safe to exist. When you don’t feel safe, it erodes overall health and wellness with distressing outcomes.
Solutions to this are not prescriptive. One solution is to use data to educate yourself instead of scripted tactics founded only on subjective opinion. The Trevor Project in 2022 utilized a survey to capture the experiences of close to 34,000 LGBTQ+ youth between the ages of 13-24 across the United States with anecdotal evidence that points to how we can increase feelings of connectedness, acceptance, and respect that becomes the antithesis to hate, discrimination and violence.
Respondents in the survey indicated that nearly two in five youth lived in an environment that was somewhat or very unaccepting of LGBTQ+ people and that those who lived in an accepting community reported significantly lower rates of attempted suicide.
I know firsthand how heavy the tears fall, how hard it is to find your breath, and how deep the wounds can go when hateful words are screamed at you, written to you, and used to manipulate you.
article continues after advertisement
However, we do have a right to celebrate. There have been recent wins, such as the Respect for Marriage Act, which federally protects the legality of same-sex marriage—a win I chose to publicly celebrate by marrying my wife in a predominantly conservative state.
Today, in the wake of multiple violent incidents resulting in injury and loss of life, and as we begin to enter into an election year, the answer to the question, "Is it safe or not?" becomes "It depends." To determine your relative safety, we’ve learned it’s crucial to find answers to other questions, like: Where am I geographically and what is the majority representation? Am I surrounded by people who are angry and fearful of my existence or kind and curious?
May our children understand how powerful their words are and how to speak their minds with grace and conviction and with respect for all living beings.
“Sticks and stones can break my bones, their words will not destroy me.”
If you or someone you love is contemplating suicide, seek help immediately. For help 24/7 dial 988 for the National Suicide Prevention Lifeline, or reach out to the Crisis Text Line by texting TALK to 741741. To find a therapist near you, visit the Psychology Today Therapy Directory.
Taylor Gurley, O.T.D., is a professor of occupational therapy at the University of Indianapolis.
“Sticks and stones will break my bones, but words will never hurt me.” The saying takes me back to the playgrounds of my childhood where I heard it chanted countless times. It leaves me wondering, did we really believe it? Or were we trying to convince ourselves of it, to prevent the hurtful words from lodging too deeply into our fragile psyches?
The truth we’ve all grown to know is that sticks and stones can break our bones and words, to our childlike dismay, can both heal and hurt us. Language, in spoken or written form, can be a powerful tool, for good or ill. Language can create safety or encourage violence. Dangerous rhetoric has fueled violence against the LGBTQ+ community. We need to stop dismissing the power of words and begin to use them with intention grounded in unity and kindness.
Toni Morrison stated, "Oppressive language does more than represent violence; it is violence; does more than represent the limits of knowledge; it limits knowledge." With this in mind, we have the opportunity to broaden our understanding that hateful and oppressive language does not just enable violence but is violence itself.
There are many ways violence can manifest in the human body and current statistics show how my community is at an even larger threat to negative outcomes when at baseline we are already experiencing high levels of mental health implications.
Current statistics
LGBTQ+ youth are six times more likely to experience symptoms of depression than non-LGBTQ+ identifying teens. LGBTQ+ youth are more than twice as likely to feel suicidal and over four times as likely to attempt suicide compared to heterosexual youth. In 2022, permanent losses include over 40 LGBTQ+ lives, not including lives lost to suicide.
The leading cause of violent crime? Dehumanizing rhetoric. It becomes the spark to ignite extreme prejudice. We see it over and over: Hate crimes are motivated by fear, ignorance, and anger. And LGBTQ+ people are nearly four times more likely than non-LGBTQ+ people to be victims of violent crime, which can lead to the onset of PTSD (post-traumaticstress disorder), anxiety, depression, self-harm, suicide, and more.
Efforts to increase homophobia
Christina Pushaw, former press secretary for Florida Governor Ron DeSantis and now his rapid response director, used her social media platform to label anyone against Florida’s "Don’t Say Gay" legislation—which prohibits instruction about sexualidentity and gender orientation for certain grades in Florida schools—as a probable groomer, a tactic designed to increase homophobia.
Talk show host Candace Owens has attacked LGBTQ+ teachers and challenged the inclusion of non-heteronormative relationships or identity in the classroom, as well as calling members of the LGBTQ+ community predators. On April 5, 2022, The Daily Wire aired a video of Owens discussing the word "gay" and how over time it has carried different meanings. In reference to its offensiveness to the LGBTQ+ community, she said, “…it was cool, hip slang until…we learned that it was hurtful...even though we were never aiming the word at them." To her, every word is fair game as long as we aren’t "aiming it" at someone.
article continues after advertisement
Media strategies such as this, created to promote homophobia, will undoubtedly increase as election efforts become more publicized this year.
Rhetoric can be a powerful tool to create safety or to destroy it.
Youth across the country are using their social-media platforms to express their feelings of being unsure if they can show up authentically as themselves at school and still be safe. Teachers have been bullied. Families are unsure how they will be impacted over time. Further legislation, specifically, in the state of Florida under HB1403, would give medical providers the ability to turn away medical care from people in the LGBTQ+ community if they have “conscience-based objections" to treating them.
Lived experience in the LGBTQ+ community
Determining safety is nothing new to members of the LGBTQ+ community. What would be new is not expending emotional and mental energy trying to identify where it is safe to exist. When you don’t feel safe, it erodes overall health and wellness with distressing outcomes.
Solutions to this are not prescriptive. One solution is to use data to educate yourself instead of scripted tactics founded only on subjective opinion. The Trevor Project in 2022 utilized a survey to capture the experiences of close to 34,000 LGBTQ+ youth between the ages of 13-24 across the United States with anecdotal evidence that points to how we can increase feelings of connectedness, acceptance, and respect that becomes the antithesis to hate, discrimination and violence.
Respondents in the survey indicated that nearly two in five youth lived in an environment that was somewhat or very unaccepting of LGBTQ+ people and that those who lived in an accepting community reported significantly lower rates of attempted suicide.
I know firsthand how heavy the tears fall, how hard it is to find your breath, and how deep the wounds can go when hateful words are screamed at you, written to you, and used to manipulate you.
article continues after advertisement
However, we do have a right to celebrate. There have been recent wins, such as the Respect for Marriage Act, which federally protects the legality of same-sex marriage—a win I chose to publicly celebrate by marrying my wife in a predominantly conservative state.
Today, in the wake of multiple violent incidents resulting in injury and loss of life, and as we begin to enter into an election year, the answer to the question, "Is it safe or not?" becomes "It depends." To determine your relative safety, we’ve learned it’s crucial to find answers to other questions, like: Where am I geographically and what is the majority representation? Am I surrounded by people who are angry and fearful of my existence or kind and curious?
May our children understand how powerful their words are and how to speak their minds with grace and conviction and with respect for all living beings.
“Sticks and stones can break my bones, their words will not destroy me.”
If you or someone you love is contemplating suicide, seek help immediately. For help 24/7 dial 988 for the National Suicide Prevention Lifeline, or reach out to the Crisis Text Line by texting TALK to 741741. To find a therapist near you, visit the Psychology Today Therapy Directory.
Taylor Gurley, O.T.D., is a professor of occupational therapy at the University of Indianapolis."
George Carlin (May 12, 1937 – June 22, 2008) was an American comedian, actor, author, and social critic. Regarded as one of the most important and influential stand-up comedians of all time, he was dubbed "the dean of counterculture comedians". He was known for his dark humor and reflections on politics, the English language, psychology, religion, and taboo subjects.
The first of Carlin's 14 stand-up comedy specials for HBO was filmed in 1977, broadcast as George Carlin at USC. From the late 1980s onwards, his routines focused on sociocultural criticism of American society. He often commented on American political issues and satirized American culture. He was a frequent performer and guest host on The Tonight Show during the three-decade Johnny Carson era and hosted the first episode of Saturday Night Live in 1975. His final comedy special, It's Bad for Ya, was filmed less than four months before his death from cardiac failure. In 2008, he was posthumously awarded the Mark Twain Prize for American Humor.
The audio in this video is from George Carlin's 1990 HBO special, "Doin' it Again".
Please consider supporting After Skool on Patreon https://www.patreon.com/AfterSkool Visit our site at https://www.afterskool.net/ Check out the new After Skool prints! after-skool.creator-spring.com Or send us an email at afterskool100@gmail.com
Please share, like, comment, subscribe and hit the notifications bell so you don't miss future videos. Thank you.
"While the pandemic briefly engaged policymakers’ creativity around alternate assessment methods, their support for those traditional multiple-choice tests has since come roaring back in both K-12 and higher ed. If COVID wasn’t enough to force policymakers to realize the futility of continuing with accountability as we currently know it, maybe AI will be."
By Dheeraj Bengrut, Yogesh Joshi Feb 04, 2024 07:18 AM IST
The Sanskrit Dictionary initiative, a project spanning 76 years and 35 volumes, aims to create a comprehensive dictionary of Sanskrit to English. PUNE
Prasad Joshi, professor and general editor of Sanskrit Dictionary Project, at work with a researcher at the Department of Sanskrit and Lexicography, Deccan College, Pune. (Rahul Raut/ ht photo) Prasad Joshi, professor and general editor of Sanskrit Dictionary Project, at work with a researcher at the Department of Sanskrit and Lexicography, Deccan College, Pune. (Rahul Raut/ ht photo)
The Sanskrit Dictionary initiative is an expansive project that bears testimony to the perseverance and scholastic dedication of intellectuals over 76 years. This linguistic odyssey traces its roots to the year following India’s liberation from British rule.
Catch the complete coverage of Budget 2024 only on HT. Explore now! The project which was incubated at the Deccan College Post Graduate and Research Institute, in Pune, garnered support from the central government, finding an ally in the Central Sanskrit University (CSU), Delhi, last month. A memorandum of understanding (MOU) was signed between the two institutes with a focus on resource exchange to fortify the project, coupled with collaborative efforts in running Sanskrit courses.
Prof Shrinivasa Varakhedi, vice-chancellor, CSU, said the institute has not been able to pick up enough projects due to funds constraints. “We have resumed working on fresh projects with support of education ministry. A year ago, work on the Sanskrit Dictionary project was brought to my notice. Apart from giving funds we will also collaborate on human resources,” he said.
Project review
The encyclopedic dictionary of Sanskrit to English, spans 2.2 million vocables and a staggering 10 million references, across 35 volumes, published through 6056 pages so far.
According to Ganesh Devy, a language expert best known for his work on People’s Linguistic Survey of India, the project is unique because it is trying to exhaust the complete range of Sanskrit language. “This dictionary can be used to know real history about ancient times, and the Indian subcontinent’s relations with central and west Asia. More importantly, we will be able to interpret various ancient learnings in an appropriate way,” said Devy.
The project’s initiation dates back to 1948. It was conceived and planned by SM Katre, former professor of Indo-European Philology and director of the Deccan college. The object was to render Sanskrit language into English. He embarked on the mission after participating in the Wilson Philological lectures, in UK, when he discovered that dictionaries existed for other languages but none for Sanskrit.
Spanning more than three generations of lexicographers, the dictionary project has become a legacy, with editors passing on the torch. The institute claims that the Sanskrit Dictionary surpasses the famed Oxford English Dictionary (OED) in magnitude, which has 0.5 million entries, 3.5 million quotations covering a span of 1000 years of the language.
In his book ‘The Wonder That Was India,’ noted professor, historian, author and an Indologist Arthur Llewellyn Basham asserted that this “dictionary, upon completion, would stand as the greatest work of Sanskrit Lexicography ever witnessed worldwide”. Basham, who passed away in 1986, taught luminaries such as Romila Thapar and Ram Sharan Sharma.
“There are Greek and Latin dictionaries. But none exist for Sanskrit covering the history and timespan of that language – by history we mean the first piece of literature available, either oral or written. For Sanskrit, the Rigveda is the first available text evidence of the language,” said Prasad Joshi, Deccan College professor, and general editor of Sanskrit Dictionary Project since 2017.
Play with words
The dictionary focuses on how words and their forms have changed over time, and how their meaning has evolved. They are analysed logically and linked to various nuances and shades together. The encyclopedic nature of the dictionary provides information on the form of vocables as a guide, the part of the speech of the word to which it belongs, accent, etymology, derivation and the development in Indo-Aryan era.
It was no easy task.
“After identifying words, we collect their references. The scholars study the context and meaning before finalising the entries. It is checked, re-checked and edited, before it is sent for publishing,” said Joshi. It draws inspiration from a primary corpus of approximately 1500 Sanskrit treatises, spanning 1400 BC to 1850 AD.
Retired professor Jayashree Sathe, who was the general editor of the project between 2010 to 2017, said, “We faced serious challenges when I came onboard, as research scholars appointed for posts created by the central government retired, leaving us with a paltry support staff. When I started the work in 1985 there were around 38 to 40 research scholars and when I became the editor, we had a team of hardly 13 to 14 people. There was always a fear of the department shutting down due to shortage of manpower.”
She said the fruits of labour materialized with the release of the first volume in 1976, three years after its editing process began. Given that a team of around 20 linguistic and Sanskrit experts are working on the project, it might take more than a century for it to be complete, she added.
The dictionary has been categorised into 62 branches, such as veda, darśana, epics, dharmaśāstra and ancient lexicons. It also includes literature, poetics, dramaturgy, prosody, anthologies or topics with science as base such as mathematics, architecture, alchemy, agriculture, medicine and veterinary sciences. It also includes words pertaining to music, in-door games, inscriptions, warfare and economics.
Speaking about the way ahead for this project, Joshi said, “The first stage of compiling the data is complete and the second stage of upgradation has started, which is likely to be complete in 10 years. If manpower is increased, the editing process will be expedited we will be able to publish more volumes in one year.”
Meanwhile, recognising the need for digital footprint, CDAC has been enlisted to spearhead the digitization of the works. “We don’t see youths coming to libraries to collect books. So, we will make the dictionary available online for people to access from across the world. In future, we will also create mobile apps,” said Joshi.
The magnitude of data makes it an important tool for various fields such as history, culture, linguistics, philology, computational linguistics, patents etc.
“It is definitive and comprehensive – in that sense it is unique,” said Devy.
ABOUT THE AUTHOR author-default-90x90 Yogesh Joshi Yogesh Joshi is Assistant Editor at Hindustan Times. He covers politics, security, development and human rights from Western Maharashtra.
"The Sanskrit Dictionary initiative, a project spanning 76 years and 35 volumes, aims to create a comprehensive dictionary of Sanskrit to English. Prasad Joshi, professor and general editor of Sanskrit Dictionary Project, at work with a researcher at the Department of Sanskrit and Lexicography, Deccan College, Pune. (Rahul Raut/ ht photo) Prasad Joshi, professor and general editor of Sanskrit Dictionary Project, at work with a researcher at the Department of Sanskrit and Lexicography, Deccan College, Pune. (Rahul Raut/ ht photo)
The Sanskrit Dictionary initiative is an expansive project that bears testimony to the perseverance and scholastic dedication of intellectuals over 76 years. This linguistic odyssey traces its roots to the year following India’s liberation from British rule.
Catch the complete coverage of Budget 2024 only on HT. Explore now! The project which was incubated at the Deccan College Post Graduate and Research Institute, in Pune, garnered support from the central government, finding an ally in the Central Sanskrit University (CSU), Delhi, last month. A memorandum of understanding (MOU) was signed between the two institutes with a focus on resource exchange to fortify the project, coupled with collaborative efforts in running Sanskrit courses.
Prof Shrinivasa Varakhedi, vice-chancellor, CSU, said the institute has not been able to pick up enough projects due to funds constraints. “We have resumed working on fresh projects with support of education ministry. A year ago, work on the Sanskrit Dictionary project was brought to my notice. Apart from giving funds we will also collaborate on human resources,” he said.
Project review
The encyclopedic dictionary of Sanskrit to English, spans 2.2 million vocables and a staggering 10 million references, across 35 volumes, published through 6056 pages so far.
According to Ganesh Devy, a language expert best known for his work on People’s Linguistic Survey of India, the project is unique because it is trying to exhaust the complete range of Sanskrit language. “This dictionary can be used to know real history about ancient times, and the Indian subcontinent’s relations with central and west Asia. More importantly, we will be able to interpret various ancient learnings in an appropriate way,” said Devy.
The project’s initiation dates back to 1948. It was conceived and planned by SM Katre, former professor of Indo-European Philology and director of the Deccan college. The object was to render Sanskrit language into English. He embarked on the mission after participating in the Wilson Philological lectures, in UK, when he discovered that dictionaries existed for other languages but none for Sanskrit.
Spanning more than three generations of lexicographers, the dictionary project has become a legacy, with editors passing on the torch. The institute claims that the Sanskrit Dictionary surpasses the famed Oxford English Dictionary (OED) in magnitude, which has 0.5 million entries, 3.5 million quotations covering a span of 1000 years of the language.
In his book ‘The Wonder That Was India,’ noted professor, historian, author and an Indologist Arthur Llewellyn Basham asserted that this “dictionary, upon completion, would stand as the greatest work of Sanskrit Lexicography ever witnessed worldwide”. Basham, who passed away in 1986, taught luminaries such as Romila Thapar and Ram Sharan Sharma.
“There are Greek and Latin dictionaries. But none exist for Sanskrit covering the history and timespan of that language – by history we mean the first piece of literature available, either oral or written. For Sanskrit, the Rigveda is the first available text evidence of the language,” said Prasad Joshi, Deccan College professor, and general editor of Sanskrit Dictionary Project since 2017.
Play with words
The dictionary focuses on how words and their forms have changed over time, and how their meaning has evolved. They are analysed logically and linked to various nuances and shades together. The encyclopedic nature of the dictionary provides information on the form of vocables as a guide, the part of the speech of the word to which it belongs, accent, etymology, derivation and the development in Indo-Aryan era.
It was no easy task.
“After identifying words, we collect their references. The scholars study the context and meaning before finalising the entries. It is checked, re-checked and edited, before it is sent for publishing,” said Joshi. It draws inspiration from a primary corpus of approximately 1500 Sanskrit treatises, spanning 1400 BC to 1850 AD.
Retired professor Jayashree Sathe, who was the general editor of the project between 2010 to 2017, said, “We faced serious challenges when I came onboard, as research scholars appointed for posts created by the central government retired, leaving us with a paltry support staff. When I started the work in 1985 there were around 38 to 40 research scholars and when I became the editor, we had a team of hardly 13 to 14 people. There was always a fear of the department shutting down due to shortage of manpower.”
She said the fruits of labour materialized with the release of the first volume in 1976, three years after its editing process began. Given that a team of around 20 linguistic and Sanskrit experts are working on the project, it might take more than a century for it to be complete, she added.
The dictionary has been categorised into 62 branches, such as veda, darśana, epics, dharmaśāstra and ancient lexicons. It also includes literature, poetics, dramaturgy, prosody, anthologies or topics with science as base such as mathematics, architecture, alchemy, agriculture, medicine and veterinary sciences. It also includes words pertaining to music, in-door games, inscriptions, warfare and economics.
Speaking about the way ahead for this project, Joshi said, “The first stage of compiling the data is complete and the second stage of upgradation has started, which is likely to be complete in 10 years. If manpower is increased, the editing process will be expedited we will be able to publish more volumes in one year.”
Meanwhile, recognising the need for digital footprint, CDAC has been enlisted to spearhead the digitization of the works. “We don’t see youths coming to libraries to collect books. So, we will make the dictionary available online for people to access from across the world. In future, we will also create mobile apps,” said Joshi.
The magnitude of data makes it an important tool for various fields such as history, culture, linguistics, philology, computational linguistics, patents etc.
“It is definitive and comprehensive – in that sense it is unique,” said Devy.
ABOUT THE AUTHOR author-default-90x90 Yogesh Joshi Yogesh Joshi is Assistant Editor at Hindustan Times. He covers politics, security, development and human rights from Western Maharashtra."
"The Sanskrit Dictionary initiative, a project spanning 76 years and 35 volumes, aims to create a comprehensive dictionary of Sanskrit to English.
....The encyclopedic dictionary of Sanskrit to English, spans 2.2 million vocables and a staggering 10 million references, across 35 volumes, published through 6056 pages so far...
The project’s initiation dates back to 1948. It was conceived and planned by SM Katre, former professor of Indo-European Philology and director of the Deccan college. The object was to render Sanskrit language into English. He embarked on the mission after participating in the Wilson Philological lectures, in UK, when he discovered that dictionaries existed for other languages but none for Sanskrit.
Spanning more than three generations of lexicographers, the dictionary project has become a legacy, with editors passing on the torch. The institute claims that the Sanskrit Dictionary surpasses the famed Oxford English Dictionary (OED) in magnitude, which has 0.5 million entries, 3.5 million quotations covering a span of 1000 years of the language....
“There are Greek and Latin dictionaries. But none exist for Sanskrit covering the history and timespan of that language – by history we mean the first piece of literature available, either oral or written. For Sanskrit, the Rigveda is the first available text evidence of the language,” said Prasad Joshi, Deccan College professor, and general editor of Sanskrit Dictionary Project since 2017.
Play with words
The dictionary focuses on how words and their forms have changed over time, and how their meaning has evolved. They are analysed logically and linked to various nuances and shades together. The encyclopedic nature of the dictionary provides information on the form of vocables as a guide, the part of the speech of the word to which it belongs, accent, etymology, derivation and the development in Indo-Aryan era.
It was no easy task.
“After identifying words, we collect their references. The scholars study the context and meaning before finalising the entries. It is checked, re-checked and edited, before it is sent for publishing,” said Joshi. It draws inspiration from a primary corpus of approximately 1500 Sanskrit treatises, spanning 1400 BC to 1850 AD...
The dictionary has been categorised into 62 branches, such as veda, darśana, epics, dharmaśāstra and ancient lexicons. It also includes literature, poetics, dramaturgy, prosody, anthologies or topics with science as base such as mathematics, architecture, alchemy, agriculture, medicine and veterinary sciences. It also includes words pertaining to music, in-door games, inscriptions, warfare and economics...."
"The Sanskrit Dictionary initiative, a project spanning 76 years and 35 volumes, aims to create a comprehensive dictionary of Sanskrit to English.
....The encyclopedic dictionary of Sanskrit to English, spans 2.2 million vocables and a staggering 10 million references, across 35 volumes, published through 6056 pages so far...
The project’s initiation dates back to 1948. It was conceived and planned by SM Katre, former professor of Indo-European Philology and director of the Deccan college. The object was to render Sanskrit language into English. He embarked on the mission after participating in the Wilson Philological lectures, in UK, when he discovered that dictionaries existed for other languages but none for Sanskrit.
Spanning more than three generations of lexicographers, the dictionary project has become a legacy, with editors passing on the torch. The institute claims that the Sanskrit Dictionary surpasses the famed Oxford English Dictionary (OED) in magnitude, which has 0.5 million entries, 3.5 million quotations covering a span of 1000 years of the language....
“There are Greek and Latin dictionaries. But none exist for Sanskrit covering the history and timespan of that language – by history we mean the first piece of literature available, either oral or written. For Sanskrit, the Rigveda is the first available text evidence of the language,” said Prasad Joshi, Deccan College professor, and general editor of Sanskrit Dictionary Project since 2017.
Play with words
The dictionary focuses on how words and their forms have changed over time, and how their meaning has evolved. They are analysed logically and linked to various nuances and shades together. The encyclopedic nature of the dictionary provides information on the form of vocables as a guide, the part of the speech of the word to which it belongs, accent, etymology, derivation and the development in Indo-Aryan era.
It was no easy task.
“After identifying words, we collect their references. The scholars study the context and meaning before finalising the entries. It is checked, re-checked and edited, before it is sent for publishing,” said Joshi. It draws inspiration from a primary corpus of approximately 1500 Sanskrit treatises, spanning 1400 BC to 1850 AD...
The dictionary has been categorised into 62 branches, such as veda, darśana, epics, dharmaśāstra and ancient lexicons. It also includes literature, poetics, dramaturgy, prosody, anthologies or topics with science as base such as mathematics, architecture, alchemy, agriculture, medicine and veterinary sciences. It also includes words pertaining to music, in-door games, inscriptions, warfare and economics...."
FIU distinguished postdoctoral scholar Nandi Sims is leading research on how race, ethnicity and social dynamics shape language variation in Black communities.
Linguist wants people to rethink their idea of 'proper English' Linguist wants people to rethink their idea of "proper English"
By Angela Nicoletti
September 15, 2021 at 10:51am
Nandi Sims is amplifying the voices of people in Black communities who are often told the way they speak English is wrong.
The linguist and distinguished postdoctoral scholar in FIU’s College of Arts, Sciences & Education is leading research on how race, ethnicity and social dynamics shape language variation in Black communities. She hopes her work can help change perceptions about language, since many beliefs can be harmful and perpetuate discrimination and inequalities.
Sims does the bulk of her work in a place that, more than likely, many adults would prefer to never step foot in again — a 6th grade classroom.
“I focus on middle school because it’s a pivotal time — when kids are becoming teenagers, making new friends and figuring out who they are going to be,” Sims said. “I wanted to measure how their speech changed during these other changes.”
Being in a classroom is where Sims always thought she’d end up, though she thought her role would be a little different.
After graduating from William and Mary with a master’s degree in curriculum and instruction, Sims moved from Virginia to Miami. She planned to become an elementary school teacher, but there was a moratorium on hiring new teachers at the time. Sims found a job as a reading specialist at a speech pathology center. It launched her career in a new direction — linguistics. Working with the children, she wanted to learn more about their speech issues so she could help them.
Sims came to FIU for a master’s degree in linguistics, where she met FIU sociolinguist Phillip Carter. She assisted him with his research on the different language varieties of people from Spanish-speaking backgrounds. When she began her Ph.D. at Ohio State University, she decided to continue this line of research, only this time, she would study Black populations, especially Black communities in Miami.
The next several years, she divided her time between Columbus, Ohio and Miami, Florida. Sims found a middle school that was almost 100 percent minority serving — about 40 percent Haitian American and 40 percent African American. She spent a lot of time observing different 6th grade classrooms.
As time passed, the students became more comfortable around her. They knew she wasn’t a 6th grader, of course. But, she also wasn’t one of their teachers. She was simply Ms. Sims — the person they talked to while playing card games.
Sims’ initial goal was to shadow the students as they moved through middle school, but the pandemic disrupted her plans. No longer able to collect the long-term data she needed, she adjusted her dissertation to describe the social structure of the school and the linguistic varieties. She listened to the recordings of the conversations she had with the students, examining the variation within their speech. She measured the vowels — one of the first places linguists look to identify language differences — as well as differences in morphosyntax.
This approach worked to her advantage, laying the critically important groundwork for her postdoctoral research, where she will be working, once again, with her former advisor and mentor Phillip Carter at FIU’s Center for the Humanities in an Urban Environment.
Sims is anxiously awaiting the day she can reunite with the students she hasn’t seen in almost two years. They are now 8th graders.
“When we diversify our research, it helps everyone understand more about the U.S. Most of the time people make generalizations like, ‘People in the U.S. say this word like this,’ but they are usually talking about middle class white people,” Sims said. “And that’s not true for most people, so my research is about helping those communities be seen and included, so social theories actually reflect social realities.”
“Mistaking the impressive engineering achievements of LLMs for the mastering of human language, language understanding, and linguistic acts has dire implications for various forms of social participation, human agency, justice and policies surrounding them,” wrote cognitive scientists Abeba Birhan
How is it that we learn to speak and think in language so easily? Philosophers have argued about whether or not we have innate ideas. Whether we are born knowing things, as Plato believed, or rather, as John Locke and other empiricists argued, the mind is a blank slate on which experience writes. Noam Chomsky, gave a twist to this debate in the 1960s.
Narrated by Gillan Anderson. Scripted by Nigel Warburton.
From the BBC Radio 4 series about life's big questions - A History of Ideas.
This project is from the BBC in partnership with The Open University, the animations were created by Cognitive.
Discussion of the role of explicit knowledge of language in language acquisition and language use. Noam Chomsky and Stephen Krashen April 6, 2020 hosted by IZ Education Center, Zanjan, Iran.
A new word enters a dictionary for its frequent, meaningful and widespread use. But a dictionary is not the only place where real words live.
Written By Sudeshna Banerjee RaoLast Updated On: 28 Mar 2023
Linguists and researchers have made many attempts to define a “word”, without reaching a settled conclusion. Most definitions, however, agree that a word is capable of being spoken and written and it must carry some meaning. Any competent speaker of a language can manage to form new words by using some of these ground rules.
During the coronavirus crisis, many new words and phrases became part of our everyday vocabulary (‘social distancing’, ‘self-quarantine’ and ‘Covid-19’ itself). However, when a preschooler calls sanitizer ‘hanitizer’, we find it cute, but may not consider that a real word.
According to Global Language Monitor, in the English language, a new word is born every 98 minutes, about 14.7 per day, 5400 a year. Not all the new ones are added to the standard dictionaries, so does that mean they’re not real?
The question is…when does a word become a real word, and who makes that decision? Let’s find out!
Is It Made Up Of A Series Of Spoken Sounds?
First, quickly scribble down a few letters on a piece of paper. Can you pronounce the string of sounds on its own? If yes, then you have just met the first requirement.
From a linguistic point of view, words are made up of different sounds (or phonemes). For instance, “cat” has three phonemes: /c/, /a/, and /t/. So, together it’s a “pronounceable phonological unit.” Here, the letter-sound c does not make sense on its own, nor do the other individual sounds. ‘Cat’ is a unit that is capable of being pronounced (with meaning) all by itself. So, this word falls in line with Bloomfield’s well-known definition of a ‘minimal free form’.
Also Read: How Did Silent Letters Come Into The English Language?
What About The Words That We Have Trouble Pronouncing?
I can never muster up the courage to pronounce “Freundschaftsbeziehungen”. Yes, that’s a real word, it means “friendship relations” in German. Or “pamplemousse”, which is French for grapefruit. Quite a mouthful, aren’t they? But it doesn’t mean that they aren’t real.
Of course, acquiring a foreign language can be difficult. Studies show that we are born with the natural ability to learn and master all the sounds used in all human languages of the world. Linguist Noam Chomsky believed that learning a language (yes, even the ones that seem so difficult to pronounce) is an innate skill that one develops from birth.
A word is real when it has a meaning in the lexicon (vocabulary or dictionary) of a language. This brings us to its next characteristic.
Emojis can neither be broken down into smaller meaningful parts, nor can they be pronounced. So, sorry, emojis…. you just don’t make the cut.
Also Read: Are Some Languages Easier To Learn Than Others?
Does It Have Some Sort Of Meaning?
A word (cats) or its parts (‘cat’ and ‘-s’) should have its own meaning (cat is the animal and –s is the letter for making it plural). Have you invented a new word for a place, person, a way of doing something or a way of describing something? You might have coined a lexical or content word. Nouns, verbs, and adjectives belong to this category.
For a word to be considered real, make sure you can clearly describe its meaning to other people.
Also note that while writing, we keep ‘cat’ separated by spaces from other words (one of its orthographic features). This is why the OED mentions that a word is “typically shown with a space on either side when written or printed”.
However, no definition appears to be set in stone. For example, the written form of Chinese doesn’t have spaces between words. Also, some words cannot be considered “minimal free forms” (e.g., for, and, but, with, it, on, yet) since they make no sense, when used on their own. What independent meaning do they have (what is the meaning of ‘the’)?
Does It Primarily Have Any Grammatical Importance?
Even if a word doesn’t seem to convey a lot of sense by itself, it can still be legitimate if it plays a grammatical role.
Some examples are auxiliary verbs (e.g., might, may, will, must), prepositions (e.g., in, at, on, of and to), articles (a, an, the), conjunctions (e.g., or, and, so, for, because, but, yet, as), and pronouns (e.g., he, she, you, we, her, him), which are grammatical or function words. They might not have a so-called “dictionary meaning”. But they can easily fit into larger units of phrases, clauses, and sentences.
Can Anyone Make Up Words? How?
Do you become hangry (angry when hungry) when you skip meals? I do.
‘Hangry’ is an example of a ‘portmanteau’—a fancy term for a word made by blending two or more words or their parts. “Brexit” is a portmanteau (Britain’s exit from the European Union), just as “breakfast” and “lunch” combine to yield “brunch.” The term portmanteau was first used by Lewis Carroll (best known for his ever-popular Alice’s Adventures in Wonderland). This is, however, just one of the mechanisms you can use to create words.
Some other processes of word formation include derivation (e.g., kind + -ness → kindness), back formation (‘examine” was formed by taking out the ”-ation” from ”examination.”), conversion (email – noun → to email – verb), compounding (jelly + -fish → jellyfish), abbreviation (Junior → Jr.) and borrowing (French café → “coffee”).
J.K. Rowling has popularized many words through the Harry Potter books. Muggle, animagus, Quidditch, Mandrake, Hippogriff are some of them, created by reworking Latin or other words. One of the most popular magic spells “Expecto Patronum” derived from the Latin words ‘expecto’ and ‘patronus’, means ‘I await a protector.’ (Photo Credit : -Anton_Ivanov/Shutterstock)
So, How Does A Word Enter The Dictionary?
Lexicon, then, plays a key role in our usage of language. Lexicographers are dictionary authors and editors who write or edit dictionaries. They decide which words will be added to the dictionary or removed from them by referring to lots of magazines, newspapers and other published materials.
For a word to be considered for inclusion in the dictionary, certain rules are followed by lexicographers, as pointed out on Dictionary.com.
A new entry might be accepted if it is:
“…used by a lot of people. …used by those people in largely the same way. …likely to stick around. …useful for a general audience.”
Clearly, a child-invented word like ‘hanitizer’ would have to receive widespread acceptance and also last for at least several years to become “official”.
What About The Words That Don’t Get Into The Dictionary?
Parents and children often make up nicknames to lovingly call each other (e.g., sweetums, bubby-doo, itty bitty). They may not have meaning for the general public, but they can mean a lot to the people using them.
Furthermore, prescriptive linguistics (the rules that show preferred usage of a language) come from institutions or people who may not have access to languages used by poor, marginalized and disadvantaged people, including indigenous communities.
Many endangered languages in the world have only a few speakers left. Busuu, a language of Cameroon, had just 3 speakers of the language in 2005, but now it is extinct. A dictionary may not include words from such less spoken and rare languages. You may also not find technical jargon, informal (slang) or dialect forms in a dictionary.
So obviously, just because a word does not get into the dictionary does not mean it is not a real word.
A Final ‘Word’
Defining a word is not a simple job, as linguists don’t agree on what constitutes a word. Still, the beautiful thing about a language is that it can always grow and thrive. This is how it will survive the winds of time. Institutions and experts recognize the needs of a language’s users, while setting the language standards for the future. Thus, the decisive powers remain with us, the people.
"...A new word enters a dictionary for its frequent, meaningful and widespread use. But a dictionary is not the only place where real words live.
Written By Sudeshna Banerjee RaoLast Updated On: 28 Mar 2023
Linguists and researchers have made many attempts to define a “word”, without reaching a settled conclusion. Most definitions, however, agree that a word is capable of being spoken and written and it must carry some meaning. Any competent speaker of a language can manage to form new words by using some of these ground rules.
During the coronavirus crisis, many new words and phrases became part of our everyday vocabulary (‘social distancing’, ‘self-quarantine’ and ‘Covid-19’ itself). However, when a preschooler calls sanitizer ‘hanitizer’, we find it cute, but may not consider that a real word.
According to Global Language Monitor, in the English language, a new word is born every 98 minutes, about 14.7 per day, 5400 a year. Not all the new ones are added to the standard dictionaries, so does that mean they’re not real?
The question is…when does a word become a real word, and who makes that decision? Let’s find out!
Is It Made Up Of A Series Of Spoken Sounds?
First, quickly scribble down a few letters on a piece of paper. Can you pronounce the string of sounds on its own? If yes, then you have just met the first requirement.
From a linguistic point of view, words are made up of different sounds (or phonemes). For instance, “cat” has three phonemes: /c/, /a/, and /t/. So, together it’s a “pronounceable phonological unit.” Here, the letter-sound c does not make sense on its own, nor do the other individual sounds. ‘Cat’ is a unit that is capable of being pronounced (with meaning) all by itself. So, this word falls in line with Bloomfield’s well-known definition of a ‘minimal free form’.
What About The Words That We Have Trouble Pronouncing?
I can never muster up the courage to pronounce “Freundschaftsbeziehungen”. Yes, that’s a real word, it means “friendship relations” in German. Or “pamplemousse”, which is French for grapefruit. Quite a mouthful, aren’t they? But it doesn’t mean that they aren’t real.
Of course, acquiring a foreign language can be difficult. Studies show that we are born with the natural ability to learn and master all the sounds used in all human languages of the world. Linguist Noam Chomsky believed that learning a language (yes, even the ones that seem so difficult to pronounce) is an innate skill that one develops from birth.
A word is real when it has a meaning in the lexicon (vocabulary or dictionary) of a language. This brings us to its next characteristic.
Emojis can neither be broken down into smaller meaningful parts, nor can they be pronounced. So, sorry, emojis…. you just don’t make the cut.
A word (cats) or its parts (‘cat’ and ‘-s’) should have its own meaning (cat is the animal and –s is the letter for making it plural). Have you invented a new word for a place, person, a way of doing something or a way of describing something? You might have coined a lexical or content word. Nouns, verbs, and adjectives belong to this category.
For a word to be considered real, make sure you can clearly describe its meaning to other people.
Also note that while writing, we keep ‘cat’ separated by spaces from other words (one of its orthographic features). This is why the OED mentions that a word is “typically shown with a space on either side when written or printed”.
However, no definition appears to be set in stone. For example, the written form of Chinese doesn’t have spaces between words. Also, some words cannot be considered “minimal free forms”(e.g., for, and, but, with, it, on, yet) since they make no sense, when used on their own. What independent meaning do they have (what is the meaning of ‘the’)?
Does It Primarily Have Any Grammatical Importance?
Even if a word doesn’t seem to convey a lot of sense by itself, it can still be legitimate if it plays a grammatical role.
Some examples are auxiliary verbs (e.g., might, may, will, must), prepositions (e.g., in, at, on, of and to), articles (a, an, the), conjunctions (e.g., or, and, so, for, because, but, yet, as), and pronouns (e.g., he, she, you, we, her, him), which are grammatical or function words. They might not have a so-called “dictionary meaning”. But they can easily fit into larger units of phrases, clauses, and sentences.
Can Anyone Make Up Words? How?
Do you become hangry (angry when hungry) when you skip meals? I do.
‘Hangry’ is an example of a ‘portmanteau’—a fancy term for a word made by blending two or more words or their parts. “Brexit” is a portmanteau (Britain’s exit from the European Union), just as “breakfast” and “lunch” combine to yield “brunch.” The term portmanteau was first used by Lewis Carroll (best known for his ever-popular Alice’s Adventures in Wonderland). This is, however, just one of the mechanisms you can use to create words.
Some other processes of word formation include derivation (e.g., kind + -ness → kindness), back formation (‘examine” was formed by taking out the ”-ation” from ”examination.”), conversion (email – noun → to email – verb), compounding (jelly + -fish → jellyfish), abbreviation (Junior → Jr.) and borrowing (French café → “coffee”).
J.K. Rowling has popularized many words through the Harry Potter books. Muggle, animagus, Quidditch, Mandrake, Hippogriff are some of them, created by reworking Latin or other words. One of the most popular magic spells “Expecto Patronum” derived from the Latin words ‘expecto’ and ‘patronus’, means ‘I await a protector.’ (Photo Credit : -Anton_Ivanov/Shutterstock)
So, How Does A Word Enter The Dictionary?
Lexicon, then, plays a key role in our usage of language. Lexicographers are dictionary authors and editors who write or edit dictionaries. They decide which words will be added to the dictionary or removed from them by referring to lots of magazines, newspapers and other published materials.
For a word to be considered for inclusion in the dictionary, certain rules are followed by lexicographers, as pointed out on Dictionary.com.
A new entry might be accepted if it is:
“…used by a lot of people.
…used by those people in largely the same way.
…likely to stick around.
…useful for a general audience.”
Clearly, a child-invented word like ‘hanitizer’ would have to receive widespread acceptance and also last for at least several years to become “official”.
What About The Words That Don’t Get Into The Dictionary?
Parents and children often make up nicknames to lovingly call each other (e.g., sweetums, bubby-doo, itty bitty). They may not have meaning for the general public, but they can mean a lot to the people using them.
Furthermore, prescriptive linguistics (the rules that show preferred usage of a language) come from institutions or people who may not have access to languages used by poor, marginalized and disadvantaged people, including indigenous communities.
Many endangered languages in the world have only a few speakers left. Busuu, a language of Cameroon, had just 3 speakers of the language in 2005, but now it is extinct. A dictionary may not include words from such less spoken and rare languages. You may also not find technical jargon, informal (slang) or dialect forms in a dictionary.
So obviously, just because a word does not get into the dictionary does not mean it is not a real word.
A Final ‘Word’
Defining a word is not a simple job, as linguists don’t agree on what constitutes a word. Still, the beautiful thing about a language is that it can always grow and thrive. This is how it will survive the winds of time. Institutions and experts recognize the needs of a language’s users, while setting the language standards for the future. Thus, the decisive powers remain with us, the people."
To get content containing either thought or leadership enter:
To get content containing both thought and leadership enter:
To get content containing the expression thought leadership enter:
You can enter several keywords and you can refine them whenever you want. Our suggestion engine uses more signals but entering a few keywords here will rapidly give you great content to curate.



 Your new post is loading...
Your new post is loading...











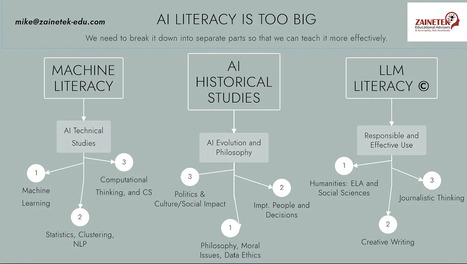


















"There’s an official push to rename our current era: Anthropocene. A few millennia from now, archeologists digging in the ground will come to a different layer. Less pollen, fewer tree trunks, a vast reduction in the bones of wild animals. A layer of ripped aluminum foil and plastic bits and chicken bones and radiation from nuclear tests. Even sedimentary layers of the oceans floor will show changes, the circulatory system shifted, the current that distributes salt and temperature globally. We humans are writing our autobiography in the planet’s dirt. When looked at through the lens of geologic time, our speed isn’t that different from a meteor strike.
*
Terms can also narrow our perceptions. Consider the names we have for the living world, this complex biosphere that our existence depends on, that provides the food we eat and the air we breathe.
The environment? That’s like naming your child organism. Such a lack of love or awe. The term brings to mind an office cubicle, something generic you can disassemble and reshape as you wish."
#metaglossia note