 Your new post is loading...

|
Scooped by
Charles Tiayon
November 23, 2022 11:19 PM
|
“El planeta Mercurio me ha condenado a traducir libros” Tengo 76 años. Nací en Madrid (bajo el signo de Cáncer) y vivo en la isla de Eivissa desde 1974. Soy traductor. Casado con Jackie, tenemos dos hijos, Amable (47) y Hermán (45), y nietos. ¿ Política? ¿Creencias? Belleza, naturaleza, libros y astrología. La lengua española está siendo desfigurada Carlos Manzano,traductor El mejor ‘Ulises’ de Joyce He conocido a un mago de las palabras y los astros. Aislado en la cima de una verde colina de Eivissa, traduce libros. Carlos Manzano suma seis premios de traducción en tres idiomas –ingles, francés, italiano– y su precioso trabajo enriquece la cultura de España. Su obra como traductor es un capital cultural de primera magnitud que merece gratitud de los lectores en español. Ha traducido a Louis-Ferdinand Céline, Henry Miller, Marcel Proust, James Joyce, está con Sterne ( Tristam Shandy ), Anaïs Nin, Virginia Woolf, Pessoa... “Huí del mundo”, me resume, por no someterse a lo peor de España, como Joyce huyó de Irlanda: “¡La huida es la victoria!”. Aparece su Ulises (Navona), del que me dice: “Al fin una traducción que, como el original, es una obra de arte del lenguaje”. Vive usted en un paraíso... Puig d’Atzaró, Eivissa, en mi casa payesa entre bosques. ¡Y entre libros! El planeta Mercurio me ha condenado a la comunicación lingüística, a traducir libros. Podría escribirlos. ¿Para qué? Ya se escriben miles de libros, pero hay muy pocas buenas traducciones. ¿Qué es un traductor? Un artista. ... De una obra de arte hace otra obra de arte. ¿Qué es lo último que ha traducido? Todo Proust, del francés al español. ¡Todo Proust! Y todo Joyce, del inglés al español. ¡Todo Joyce! Sale ahora mi Ulises, puede leerlo. Nadie ha escrito en lengua inglesa como Joyce. ¡Cuánto placer! He disfrutado mucho. ¿Le ha costado mucho traducirlo? Han sido 464 días seguidos: tres páginas al día, revisadas con Jackie, mi esposa. ¿Qué encontraré si leo su Ulises ? Arte. Libro duro y trágico, el capítulo XV es humorístico: ¡cuánto me he divertido! De jovencito leí Ulises en la traducción de Valverde. Mala: Valverde no sabía traducir. Ser catedrático no te hace traductor. Y usted ha hecho arte, me dice. Si Joyce hubiese escrito en español, su Ulises sería el mío, nunca el de Valverde. ¿Y Proust, qué diría de su traducción? Que si hubiese escrito en español, su obra sería exactamente como mi traducción. Parece que haya hablado con ellos... Les tengo muy bien estudiados. Como yo mismo, Proust había nacido bajo el signo de Cáncer, algo difícil para un hombre. Me insiste usted en los astros... Desde hace decenios verifico que la carta astral de cada persona explicita sus dones, pasiones y nudos. ¡Y nunca me ha fallado! ¿Y qué explicitan los astros de Proust? Que necesitaba besos de mamá. Criado muy enmadrado y rico, fue niño hasta que pasó a anciano: nunca fue hombre adulto. ¿Y Joyce? Era Acuario: la amistad es lo más valioso con una mujer. Y formó una pareja sexual abierta, muy valiente para entonces. ¿Y para usted? Jackie es Capricornio, ¡el mejor signo para una mujer! Debido a la serenidad de esta mujer llevamos cincuenta años juntos. ¿No es usted sereno? Soy colérico, autoexigente y exigente. Deme un ejemplo de eso. Cada mañana leo la prensa y hago inventario de sus muchos errores lingüísticos, calcos aberrantes del inglés: ¡es monstruosa la actual desfiguración del español! Ya veo que eso le preocupa... España desprecia al corrector, por eso se les contrata inexpertos y baratos... Y añaden más errores de los que reparan. Le gusta hacer amigos, veo también. Exceptúo a la editorial Navona, cuyos correctores me han hecho atinadas aportaciones. ¡Por primera vez en mi vida! ¿Cómo llegaron las letras a su vida? A mis cuatro años, mi padre tomó una pizarra y dijo: “Y ahora vamos a aprender a leer”. Qué momento, aún estoy viéndolo. ¿Aprendió rápido? Leía todos los carteles en el metro y la gente se admiraba: “¡Qué niño, qué niño!”. Mi padre murió a mis ocho años... Y usted siguió con las letras... Estudié febrilmente gramática. Becado, acabé Letras en Barcelona, me dio clases Gabriel Ferrater y obtuve matrícula de honor en Lengua y Literatura Catalana. Útil para Eivissa. Desde 1974 vivo aquí con Jackie. Tengo al ibicenco por la variante más bella de todo el dominio lingüístico catalán. ¿Por qué eligió Eivissa? ¡Es el cielo en la tierra! Nos vinimos a vivir sin luz eléctrica, con agua de pozo... Fui antifranquista y al fin me alejé del espanto del comunismo, tuve curiosidad por el hippismo. Y traducía, traducía... ¿Qué lenguas traduce? Castellano, catalán, italiano, portugués, gallego, francés, inglés... ¿Con alguna preferencia? La lengua más hermosa que existe es el gallego. ¿Sí? Lea Le petit prince en gallego y descubrirá que ¡es más bonito que en francés! ¿Y en español? Mi palabra en español favorita proviene delcaló, al igual que el verbo pirarse . Irse. Sí. Mi palabra es piravar, y sus variantes apiravar, piravelar y apiravelar. No conocía esas palabras. Todo se pierde, es una pena. ¿Y qué significa piravar? Follar. Por lo de irse.

Are humans the only beings on the planet that use language to communicate?
"Burg Giebichenstein
Kunsthochschule Halle
“Language can only deal meaningfully with a special, restricted segment of reality. The rest, and it is presumably the much larger part, is silence.” George Steiner
Are humans the only beings on the planet that use language to communicate? Can we decipher the nonhuman world around us without harnessing it to our own socialization, syntax, and lexicon? Is interspecies communication even possible? Translation has been described as a precondition that underlies all (human) cultural transactions upon which communication is based. It also is inherently political and stands at the forefront of so many of today’s questions around identity, gender, post-colonial criticism, feminist critique, machine translation and canon creation, yet its connection within the context of the nonhuman turn, interspecies communication, and eco-criticism has not yet been fully explored.
Whether we are talking about classic linguistic and literary translation, or any number of related fields including: language and literature, cultural studies, performance, visual and media arts—the core question that translators and theorists of translation have been debating about for centuries remains the same: is it possible to translate without interpreting? Is linguistic and cultural equivalence even possible? These questions become all the more urgent in the limit-case of interspecies communication. Can we apply empathic modes of translation to nonhuman articulations, wherein translation involves a form of metamorphosis, not of text, but of the translator. As such, translators are something of a hybrid species with one foot in each culture and language, and whose very existence revolves around traveling between worlds. Translators have something of a mythical being about them, akin to a chameleon or centaur. In this course, we will not be engaging in a scientific exploration of interspecies communication, but examining theories around empathic translation-- a process that sees translation not merely as the transformation of a text, but of the translator themself.
Emerging and classical theories of translation can offer a paradigm for engaging with plant and animal articulation, not language as such, but different forms of articulation perceived through the senses, one in which our hearing and seeing,“once intertwined and attentive to the calls and cries of animals, all but disappeared with the invention of the alphabet, retreating into a kind of silence.”
In David Abram's words: “By giving primacy to perception we can see the natural world, not as inert and passive, but as dynamic and participatory. The winds, rivers and birds speak in their own way (if we listen), the sounds of nature not only have informed indigenous languages, but language in general--humans are but one being intertwined with other beings and ‘presences.’ This perspective sees the landscape as a sensuous field, and human perception as but one point of view that is in reciprocity, in expressive communication, with other points of view and ways of being.”
How can theories of translation help us make sense of this new view of a world teeming with language and sentience? What theories abound in reference to multiplicity of “language,” even as Walter Benjamin would argue for a “universal (human) language.” What practical tools does translation studies offer, and what bridges can it forge between the disciplines? The first half of the seminar focuses on key theoretical concepts relevant to the history and practice of translation. In the second half, students will engage in translation experiments that intersect with their own artistic/design practice. A final project should be considered a first draft of something that could develop later into a larger project.
The course will be taught in English and German.
This seminar is ideally suited to students interested in: Literature, Translation Theory / Translation / Cultural Studies / Critical Theory, Creative Writing/ Post-humanism, Trans-humanism, Eco-criticism, the More-than-Human Turn.
Teachers
Dr. Zaia Alexander"
https://www.burg-halle.de/en/course/l/talk-with-the-animals-translation-in-a-more-than-human-world
#Metaglossia
#metaglossia_mundus
#métaglossie

"Les modèles gèrent le raisonnement en direct, la traduction vocale dans plus de 70 langues et la transcription en temps réel via l'API Realtime.
By Colleen Cabili
OpenAI ajoute trois modèles vocaux à son API en temps réel, offrant aux développeurs des outils pour le raisonnement en direct, la traduction vocale et la transcription en streaming, a déclaré la société.
Le premier modèle, GPT-Realtime-2, apporte un raisonnement de classe GPT-5 aux interactions vocales en direct. OpenAI affirme que le modèle est conçu pour que les conversations vocales restent fluides même lorsqu'il traite des demandes complexes, gère les appels d'outils et s'adapte aux interruptions sur le moment. Il est tarifé à 32 $ pour 1 million de jetons d'entrée audio — ou 0,40 $ pour les jetons d'entrée mis en cache — et 64 $ pour 1 million de jetons de sortie audio.
La traduction vocale en direct est au cœur du deuxième modèle, GPT-Realtime-Translate, qui prend en charge l'entrée de plus de 70 langues et fournit une sortie dans 13, sans ralentir le rythme naturel d'une conversation. Il est tarifé à 0,034 $ par minute.
Complétant le trio, GPT-Realtime-Whisper est un modèle qui convertit l'audio parlé en texte en temps réel, en privilégiant une faible latence pour que la transcription suive les locuteurs pendant qu'ils parlent. OpenAI a cité des cas d'utilisation tels que les sous-titres à l'écran et les notes de réunion générées automatiquement comme exemples d'utilisation du modèle. Il est tarifé à 0,017 $ par minute.
Les trois modèles sont disponibles via l'API en temps réel d'OpenAI. Les développeurs peuvent les tester dans le Playground d'OpenAI."
https://fr.qz.com/modles-de-voix-en-temps-rel-openai-dveloppeurs-050726
#metaglossia
#metaglossia_mundus

"Avec l'essor de la traduction automatique par IA, des milliers de langues risquent de disparaître.
La technologie de traduction automatique facilite la communication, mais elle soulève des inquiétudes quant à la disparition de nombreuses langues, l'UNESCO avertissant que des milliers de voix pourraient disparaître.
Selon le correspondant de l'agence de presse vietnamienne en France, le développement rapide de la technologie de traduction automatique basée sur l'IA suscite des inquiétudes quant à la tendance à l'« homogénéisation » des langues mondiales, dans le contexte du renforcement des initiatives de l'Organisation des Nations Unies pour l'éducation , la science et la culture (UNESCO) visant à protéger la diversité culturelle et linguistique.
Les dispositifs de traduction en temps réel, tels que les casques intelligents dotés d'intelligence artificielle, permettent aux utilisateurs de communiquer directement dans leur langue maternelle sans avoir à apprendre une langue étrangère, grâce à leur capacité à convertir instantanément le langage parlé et écrit.
Cette technologie associe le traitement des données embarqué à un système de capture audio directionnelle, séparant la parole du bruit ambiant pour une traduction quasi simultanée. Certains appareils prennent désormais en charge plusieurs langues courantes telles que l'anglais, l'espagnol, le français, l'allemand et l'italien, et la prise en charge des langues asiatiques s'étend progressivement.
Cependant, les experts avertissent que cette caractéristique pourrait nuire à la motivation à apprendre les langues étrangères, accélérant ainsi la simplification de la grammaire et la réduction du vocabulaire dans de nombreuses langues.
Le linguiste américain John McWhorter affirme qu'à l'ère de la communication de masse, les langues capables de relier un grand nombre de personnes, comme l'anglais et l'espagnol, domineront. Il prédit que d'ici 2100, le nombre de langues encore parlées pourrait diminuer pour atteindre environ 600, contre plus de 7 000 aujourd'hui.
Selon l'UNESCO, près de 3 000 langues dans le monde sont menacées de disparition, tandis que plus de 200 langues ne sont plus parlées depuis 1950 faute de locuteurs.
Colette Grinevald, spécialiste des langues moins étudiées, affirme que le rythme de leur déclin est très rapide. En Amérique du Nord, le nombre de langues autochtones a chuté de façon dramatique en quelques décennies seulement, et nombre d'entre elles ne sont plus parlées que par un nombre très restreint de personnes.
Les prévisions indiquent également que, dans les prochaines décennies, les langues qui se prêtent bien au commerce, à la science et à la diplomatie continueront de se développer.
Selon la plateforme d'apprentissage des langues Preply, le chinois (mandarin) pourrait compter environ 1,2 milliard de locuteurs natifs d'ici 2050, suivi par l'espagnol, l'anglais et l'hindi. Parallèlement, le français devrait conserver son influence territoriale et diplomatique, notamment en Afrique."
Báo Tuổi Trẻ
06/05/2026
https://www.vietnam.vn/fr/ai-dich-thuat-bung-no-hang-ngan-ngon-ngu-doi-mat-nguy-co-bien-mat
#metaglossia
#metaglossia_mundus

"Le 1er mai 2026, au stand de Pop Libris, l’écrivain Yamen Manaï dédicaçait la traduction arabe de L’Amas ardent, son roman paru en 2017 aux éditions Elyzad, désormais publié en arabe par Pop Libris. Derrière ce passage d’une langue à l’autre, une traductrice : Sonya Ben Béhi, membre du comité de lecture de la maison d’édition et créatrice de contenu culturel, qui a porté ce projet avec une conviction rare. Présente à la Foire internationale du livre de Tunis, elle revient sur un choix délibéré et sans concession : celui de rendre ce roman profondément tunisien au public arabophone qui, trop longtemps, n’a pas pu le lire. Dans une déclaration accordée à L’Économiste Maghrébin, elle interpelle, au passage, les déséquilibres qui structurent encore le monde de l’édition mondiale.
Ce choix était tout sauf fortuit, affirme Sonya Ben Béhi. Découvert en 2018 avec un coup de cœur immédiat, L’Amas ardent lui avait semblé, dès cette première lecture, injustement inaccessible au public arabophone tunisien. Le beau succès de l’œuvre dans l’espace francophone, notamment le Prix des cinq continents en 2017, n’avait fait que renforcer cette conviction. Dès sa première traduction achevée, ce roman s’est donc imposé comme le choix suivant. Œuvre ancrée dans l’identité tunisienne, roman de la mémoire et contre l’oubli, hommage à une nature locale, satire sociale chargée de « tunisialité » jusque dans ses mots, ses proverbes et son lexique, il se devait, selon la traductrice, d’être lu en arabe, et ce par le plus grand nombre possible.
L’auteur, partenaire inédit de sa propre traduction
La traductrice espère que cette version arabe saura plaire et que le public en saisira toutes les nuances d’une œuvre qu’elle juge particulièrement nuancée. Pour ce quatrième travail, Sonya Ben Béhi a bénéficié d’un privilège rare : échanger directement avec Yamen Manaï, auteur accessible dont la maîtrise de l’arabe littéraire, autant que du français, l’a d’ailleurs quelque peu surprise. Cette collaboration a fait de l’auteur un participant actif au processus traductif. Un dialogue de co-construction dont Sonya Ben Béhi espère qu’il se ressentira à la lecture, offrant au public une œuvre aussi riche que le texte original.
La formule « traduire, c’est trahir » est devenue si galvaudée que Sonya Ben Béhi y a renoncé. Pour la traductrice, traduire, c’est avant tout aimer. Traduire une œuvre qu’on n’aurait pas aimée lui semble inconcevable, même si certains pourraient peut-être le faire. Sa propre pratique est profondément émotionnelle : imprégnée du roman tout au long du travail, vivant l’œuvre de l’intérieur, Sonya Ben Béhi sent qu’elle laisse une part d’elle-même dans chaque texte. Le résultat est, à ses yeux, une œuvre composite, portant à la fois la substance du texte original et une empreinte personnelle. L’Amas ardent occupe une place particulière dans son cœur, précisément parce qu’il est un roman tunisien.
La littérature arabe traduite : une volonté qui doit venir de l’autre
Sur ce point, Sonya Ben Béhi est directe. Un principe fondamental s’impose : la volonté de traduire vers une langue doit venir des locuteurs de cette langue. Rendre un roman arabe accessible au public français relève ainsi de la responsabilité des éditeurs français, et non de celle des maisons d’édition arabes. Or, le monde éditorial européen et américain commence à peine à traduire des romans arabes, en ne retenant que les noms les plus établis. Les initiatives restent marginales, à l’exception de quelques acteurs engagés comme Actes Sud en France, dont c’est précisément la vocation. Par ailleurs, une traduction de l’arabe vers l’anglais portée du côté arabe ne toucherait, en réalité, que quelques lecteurs anglophones locaux, tandis qu’une traduction initiée par les éditeurs anglophones ouvrirait de véritables horizons à l’œuvre. La créatrice de contenu culturel exprime l’espoir que le monde éditorial occidental porte un regard croissant et plus attentif sur la littérature arabe et africaine dans son ensemble."
https://www.leconomistemaghrebin.com/2026/05/03/lamas-ardent-en-arabe-sonya-ben-behi-ouvre-la-tunisie-a-ceux-qui-la-lisent-autrement/
#metaglossia
#metaglossia_mundus

"A new program is helping Deaf leaders become Bible translation consultants faster.
DOOR International’s Rob Myers says sign language Scripture is severely lacking worldwide.
“Out of over 300 sign languages, a vast number of them don’t even have a Bible translation started,” he explains.
Groups like DOOR recruit and train Deaf Christians to translate God’s Word. Learn more here. However, the lack of Scripture creates a significant challenge.
“In most Deaf communities, Deaf leaders lack a background in the Bible because they haven’t been able to access it. These Deaf communities have been lacking the Gospel for millennia,” Myers says.
“You may have a few Christians, but because they don’t have access to the Bible, they struggle in having a deep walk with Christ.”
Why consultants matter
Translation consultants help Bible translation teams understand Scripture’s original meaning and context and determine how “to translate it in a way that’s natural for their communities,” Myers says.
“It’s a very specialized field, but it’s critically important to help make sure that Bible translation is done in an accurate way,” he continues.
“Translation consultants [ensure] communities get God’s Word in totality, in an accurate format, so churches can then take it and use it for everything they need, including sharing the Gospel, making disciples, and planting churches.”
The lengthy training process means Deaf consultants are rare.
Equipping a Deaf leader to serve as a translation consultant can take seven years or more. “One of the critical bottleneck pieces [in sign language Bible translation] is a lack of access to translation consultants,” Myers says.
CEDAR sets new pace
DOOR’s CEDAR Institute – Consultant Empowerment Development And Resources – expedites the training process for Deaf leaders. “The approach that we’re taking is called competency-based training,” Myers says.
“Typically, when a person is recruited as a translation consultant, they’ve already had a lot of experience in Bible translation. So, rather than coming in cold, they come in with a lot of background,” he continues.
“That extensive background allows this program to target areas that are critical for a translation consultant. [This approach] has allowed us to reduce that (training) time from 7+ years to a three-year process.”
DOOR needs your help to keep the CEDAR Institute going. Connect with DOOR International here.
“The very first step is to pray. Pray that God would raise up (Deaf) men and women to fill these roles so that more Bible translation can happen,” Myers asks.
“We would also ask that you consider coming alongside us financially to see more Deaf translation consultants trained and deployed into the field.”"
By Katey HearthMay 6, 2026
International (MNN)
#metaglossia
#metaglossia_mundus

"Deadline: 15-Jun-2026
The PEN/Heim Translation Fund Grants, administered by PEN America, provide financial support to literary translators working on book-length translations into English. The programme is designed to promote global literary exchange by helping translators complete unpublished works of fiction, creative nonfiction, poetry, and drama originally written by a single author.
The grants focus on high-quality literary translation projects that expand access to international literature in English.
Key Objectives of the Programme
Support completion of book-length literary translations into English
Promote international literary exchange and cultural understanding
Encourage translation of fiction, poetry, drama, and creative nonfiction
Increase visibility of underrepresented global authors in English literature
Provide financial assistance to translators working on unpublished projects
Funding Details
Ten grants awarded annually
Each grant is $4,000
Funding supports completion of translation projects
Intended for book-length literary works
Eligible Works and Projects
Fiction, including novels and short story collections
Creative nonfiction
Poetry
Drama
Works must be written by a single original author
Only unpublished translations are eligible
Works that have not appeared in English or only exist in outdated or flawed translations are eligible
Ineligible Works
Anthologies with multiple authors
Literary criticism
Scholarly or academic texts
Technical or scientific works
Previously published English translations (unless significantly outdated or flawed versions exist)
Who Is Eligible?
Translators of any nationality or citizenship
Individuals translating into English
Projects may involve up to two translators
Must involve only one original author per project
Application Restrictions
Each translator may submit only one project per year
Translators previously awarded a PEN/Heim grant must wait three years before reapplying
Projects must remain unpublished before April 15, 2027
Past unsuccessful applicants are unlikely to be reconsidered automatically
Special Considerations
Translations from Italian are automatically considered for the PEN Grant for the English Translation of Italian Literature
Priority is given to unpublished, full-length literary works in progress
How the Grant Works: Step-by-Step
Select a qualifying unpublished literary translation project
Ensure the original work meets eligibility criteria (single author, literary genre)
Prepare application materials including translation samples and project details
Submit application through PEN America’s official process
Wait for evaluation by selection committee
If awarded, use grant funds to complete the translation
Evaluation Criteria
Literary quality of the original work
Skill and experience of the translator
Importance of the work in its original cultural context
Contribution to English-language literary diversity
Feasibility of completing the translation project
Why This Programme Matters
Expands access to global literature in English
Supports translators as key cultural mediators
Promotes cross-cultural understanding through literature
Helps preserve and disseminate important international literary works
Encourages diversity in the English-language publishing landscape
Common Mistakes to Avoid
Submitting already published translations
Applying with anthologies or multi-author works
Including ineligible genres like academic or technical writing
Submitting more than one project per year
Ignoring eligibility restrictions for previous award recipients
Pro Tips
Choose a strong, internationally significant literary work
Highlight cultural importance and translation challenges
Provide clear evidence of translation quality and skill
Ensure the project is realistically completable within scope
Demonstrate originality and literary value of the source text
Frequently Asked Questions (FAQ)
What is the PEN/Heim Translation Fund? It is a grant programme supporting literary translation into English
How much funding is provided? $4,000 per selected project
How many grants are awarded? Ten grants annually
Who can apply? Translators of any nationality working on English translations
What types of works are eligible? Fiction, poetry, drama, and creative nonfiction
Are anthologies allowed? No, only single-author works are eligible
Can previously published translations be funded? No, unless they are outdated or flawed versions requiring a new translation
Conclusion
The PEN/Heim Translation Fund Grants play a vital role in bringing global literary voices into English by supporting translators working on significant unpublished works. By funding high-quality literary translation, the programme strengthens cultural exchange, enriches English-language literature, and ensures that important international stories reach wider audiences.
For more information, visit PEN America."
https://www2.fundsforngos.org/individuals/pen-heim-translation-fund-grants-for-literary-translators/amp/
#metaglossia
#metaglossia_mundus

"The majority of England’s ambulance services do not provide British Sign Language (BSL) interpretation via a video relay service (VRS) at incidents, the deaf health charity SignHealth has said, following a written question in parliament on the issue last month.
Juliet Campbell, the Labour MP for Broxtowe, tabled the question to the Department of Health and Social Care asking “what steps [it] is taking to help ensure that ambulance services are able to communicate effectively with Deaf people who use British Sign Language (BSL)”.
In response, secondary care minister Karin Smyth MP said: “To facilitate clear and effective communication in emergency situations, individuals who are deaf, hard of hearing, or speech impaired can utilise tools such as the 999BSL video relay platform, which is app and web-based, to contact 999 via a BSL interpreter as well as access via emergency SMS messaging.
...
BSL is a recognised language in the UK and therefore the NHS must be able to ensure healthcare is accessible for Deaf individuals, including pre-hospitably in urgent and emergency care.
“I am pleased that the Government has confirmed that UK ambulance staff carry iPads that have video relay apps and the ability to video call with a remote BSL interpreter 24/7.
“This will ensure real-time communication is possible for Deaf individuals who need it, so they can communicate and be treated by paramedics when they need it.”
However, SignHealth said it has been told by deaf people that they are asked to hang up on 999 BSL once an ambulance has arrived, which it said leaves deaf people “without a video relay service [VRS] and no communication during treatment”.
Lucy Warnes, the charity’s chief executive, said on Tuesday: “Apart from the North East of England, most ambulance services do not provide a VRS. We want services across England to follow the North East model so that deaf people can communicate safely and confidently in an emergency.
“VRS relies on investment in infrastructure and in some areas, there is lack of 4G and 5G connectivity.
“Beyond technology, we want paramedics and first responders to have basic BSL skills. At SignHealth we run workshops to support and empower deaf people to use these lifesaving digital tools themselves, but technology alone is not the solution.”
https://liamodell.com/2026/05/05/ambulance-services-999-bsl-british-sign-language-interpreter-deaf-access-health-signhealth-juliet-campbell-karin-smyth/
#metaglossia #metaglossia_mundus

"Minnesota Supreme Court Chief Justice Natalie Hudson has declared Wednesday, May 6, Minnesota Court Interpreter Day.
“National Interpreter Appreciation Day provides an opportunity to honor the skills, integrity, linguistic diversity, and dedication to public service of court interpreters across our state,” Chief Justice Hudson said in her official proclamation. “It is fitting and proper to set aside this annual day of recognition affirming our collective commitment to language access as a cornerstone of a fair, inclusive, and equal justice system.”
Court interpreters allow every person to stand before the law with the same voice, understanding, and opportunity to be heard. The Minnesota Judicial Branch has 14 staff interpreters, and works with hundreds of independent interpreters, who provide interpreting services during court proceedings. Since 2019, court interpreters have rendered interpretation into 194 languages, including sign language, for people throughout Minnesota.
“Minnesota is home to a richly diverse population whose residents speak dozens of languages and represent communities from across the globe, and whose deaf and hard of hearing residents communicate through non-spoken languages and other means of expression with equal richness and cultural tradition, reflecting our state's long and proud history as a place of welcome to all who seek to be fully heard and understood,” the Chief Justice writes in the proclamation.
The right to a court interpreter is grounded in the 5th, 6th, and 14th Amendments of the U.S. Constitution and is guaranteed under Minnesota law to qualifying parties in court proceedings where such a right has been established.
“Court interpreters are invaluable to our commitment to equal access to justice,” said Rosalina Sanchez, the Court Interpreter Program coordinator for the Minnesota Judicial Branch. “They are an essential conduit between individuals and the justice system, bridging language and communication barriers for those participating in court proceedings.”
ST PAUL, Minn. (May 5, 2026)
https://mncourts.gov/about-the-courts/newsandannouncements/minnesota-court-interpreter-day-to-be-celebrated-may-6
#metaglossia
#metaglossia_mundus

"American Sign Language interpreters are exiting Clovis Unified due to a lack of competitive pay, leaving deaf and hard of hearing students without needed support, the interpreters say. (GV Wire Composite)
Clovis Unified ASL interpreters claim the district is experiencing an “exodus” of interpreters due to a lack of competitive pay.
The district pushes back against these claims, reporting lower levels of turnover and undergoing a third-party compensation analysis to ensure competitiveness.
The Deaf and Hard of Hearing Service Center sent a letter to district administration, raising concerns about interpretation services.
Share
Clovis Unified is experiencing an “exodus” of American Sign Language interpreters, leaving deaf and hard of hearing students in the lurch, according to district interpreters.
The Deaf and Hard of Hearing Service Center raised concerns about student access to interpretation services and encouraged Clovis Unified to take immediate steps to bolster the workforce in a letter to district leadership.
“Access to qualified interpreters is not optional; it is essential for ensuring equitable education and full participation in the classroom,” the letter states.
In the past two years, 16 ASL interpreters have left the district, according to the Association of Clovis Educators. And new interpreters aren’t filling these positions.
“This isn’t about turnover – that would require new people coming in. We’re talking about an exodus. We tried to warn them, but they chose not to believe us,” said ASL interpreter Peter Moreno.
However, only three educational interpreters and six deaf and hard of hearing instructional assistants left Clovis Unified in 2024-25 and 2025-26, district spokesperson Kelly Avants told GV Wire.
In that same time period, the district hired two educational interpreters and seven deaf and hard of hearing instructional assistants, she said.
Meanwhile, the district is rapidly growing, adding 382 students in the 2025–26 school year. The 0.9% increase has caused the district to reach a record high of 43,254 pupils. It is now the 11th largest school district in California.
Now, it’s a question of how many — not if — students will go without an interpreter, ACE says.
But Clovis Unified is actively recruiting folks for these roles amidst what Avants labeled a “shortage of interpreter candidates” in the “region and the nation.”
In the meantime, the district has plans in place to ensure students have continued support, including substitutes and schedule adjustments, Avants said.
Clovis Unified ASL Interpreters Demand Better Pay
The ACE ASL bargaining team, unionizing in August 2024, have been negotiating their first contract with Clovis Unified for about 18 months.
District administration and trustees have refused to address the growing staffing crisis, which primarily stems from the lack of competitive pay, ACE says.
“The prestige of working in Clovis doesn’t pay the bills, and the bills have gone up. This is about supply and demand, pure and simple,” said Buchanan High School ASL interpreter Shonda Harrar. “The supply of interpreters is limited, and the demand remains high, so the price goes up. Neighboring districts understand this, which is why our colleagues have moved.”
Clovis Unified offers ASL interpreters an hourly wage ranging from $34.11 to $41.41.
Comparatively, larger neighboring school district, Fresno Unified, provides an hourly wage ranging from $40.59 to $51.86. And Central Unified, which serves less than half the number of students as Clovis, offers a pay scale ranging from $23.76 to $28.95.
In the past five years, Clovis Unified has undergone two third-party analyses of its compensation structure and salary schedules, Avants said. One ensured competitiveness and the other reviewed job descriptions to appropriately place them.
DHHSC extended a helping hand in its letter, welcoming the opportunity to collaborate with the district to help recruit and retain staff.
“This may include reviewing compensation structures, strengthening recruitment efforts, providing professional development opportunities, and offering interpreters and signing aides a fair contract that supports long-term retention,” the letter states.
District Contracted Outside Interpreters
Last year, ACE discovered at the bargaining table that Clovis Unified contracted an outside agency, Soliant Health, to provide video remote interpreting services to pupils.
The union filed charges against the district, claiming it violated interpreters’ bargaining rights by not notifying them of its use of contractors.
Clovis Unified trustees unanimously approved a semester-long contract with Soliant Health for up to $332,000 in early February 2025.
“We strongly encourage Clovis Unified to avoid revisiting (video remote interpreting) as a cost-saving measure in the future,” DHHSC stated in its letter. “In classroom settings, particularly when multiple students are involved, VRI often limits access to communication and does not provide the same level of support as in-person interpreters.”
The district does not currently use any digital translation devices, Avants said"
By Anya Ellis
Published 1 day ago on
May 5, 2026
https://gvwire.com/2026/05/05/clovis-unified-asl-interpreters-claim-exodus-over-pay-district-disputes-their-numbers/
#metaglossia
#metaglossia_mundus
Translation vs localization services: learn the real difference, when each is needed, and how to reduce risk in legal, medical, and business content.
A product launch stalls in Germany because the copy is technically correct but culturally off. A consent form is translated word for word, yet patients still misunderstand key instructions. A software interface fits the language, but not the way local users read dates, currencies, or warnings. This is where translation vs localization services becomes a business decision, not a wording preference. For organizations working in legal, medical, technical, financial, and public-facing environments, the difference affects compliance, user trust, and speed to market. If the wrong service is chosen, the content may be accurate on paper and still fail in practice. If the right service is chosen from the start, communication works the way it is supposed to work – clearly, appropriately, and with less risk. What translation vs localization services actually meansTranslation is the process of converting text from one language into another while preserving the original meaning. In many cases, that is exactly what is needed. Contracts, medical records, employee handbooks, court documents, and certified submissions often require precise, faithful translation with controlled terminology and a strong quality review process. Localization goes further. It adapts content for the expectations, conventions, and cultural context of a specific market. That can include changing date formats, units of measure, currencies, tone, examples, button text, imagery, legal disclaimers, and even layout. The goal is not only to say the same thing in another language, but to make the content feel correct and usable for the intended audience. The distinction sounds simple until teams face real-world content. A birth certificate for immigration typically needs certified translation, not localization. A mobile app entering Mexico or Japan usually needs localization because the user experience depends on more than direct language transfer. A global HR policy may need both – accurate translation for policy terms and localized adaptation for country-specific references or benefits language. When translation is the right choiceTranslation is usually the right fit when fidelity matters more than market adaptation. Legal filings, certified documents, medical histories, insurance records, patents, financial statements, and technical manuals often fall into this category. The core requirement is accuracy, consistency, and terminology control. In these settings, changing tone or examples too freely can create problems. A legal administrator does not want a contract “reimagined” for style. A healthcare coordinator does not need a patient discharge instruction rewritten so heavily that original meaning becomes debatable. Procurement teams sourcing regulated content want dependable output that can stand up to review. This is why expert subject knowledge matters. A document translated by someone fluent in the language but unfamiliar with legal procedure, medical terminology, or engineering vocabulary can introduce serious risk. In high-stakes work, a translator should understand the field, the purpose of the document, and the standard terminology used by professionals in that domain. When localization is the better investmentLocalization is the better choice when audience response, usability, and market fit matter. Websites, software, e-learning modules, product packaging, marketing campaigns, video subtitles, and customer support content often need more than direct translation. A localized website does not just convert English words into Spanish, French, or Arabic. It adjusts forms of address, shopping expectations, navigation patterns, local regulations, and formatting details that affect trust. A localized app does not merely swap labels. It accounts for text expansion, local payment language, decimal conventions, and whether a phrase sounds natural on a small screen. This is where many teams underestimate the scope. They assume a translated interface is market-ready, then find out that character spacing breaks the design, the call-to-action sounds unnatural, or a compliance notice does not match local expectations. Localization prevents these issues earlier, when fixes are less expensive. Translation vs localization services in regulated industriesIn regulated environments, the answer is rarely all one or all the other. It depends on the content, the audience, and the consequences of error. In healthcare, a medical record or informed consent document may require highly accurate translation, while a patient portal or outreach campaign may need localization to improve comprehension and engagement. Both matter, but they solve different problems. In legal settings, certified and official-use documents typically call for strict translation protocols. At the same time, a law firm’s multilingual website or intake materials may benefit from localization so prospective clients understand next steps without confusion. In technology, user manuals and safety documentation may require precise translation with terminology consistency, while the software interface, onboarding emails, and help center content often perform better with localization. The same company may need both services running in parallel. For financial institutions, accuracy is non-negotiable, but customer-facing content still has to feel native and clear. If disclosures are translated correctly but the surrounding content feels foreign or unclear, trust drops fast. The hidden cost of choosing the wrong serviceThe most common mistake is buying translation when localization is needed. The second most common is paying for localization when the job actually calls for controlled, literal accuracy. If a marketing team launches translated campaign copy without localization, conversion can suffer even when the grammar is correct. If a legal team localizes a sworn statement too aggressively, it can create review issues or raise questions about fidelity. If a medical provider uses generic translation for patient education materials without considering cultural context, comprehension may still fall short. These are not just editorial issues. They affect timelines, revision cycles, internal approvals, and risk exposure. Rework slows launches. Miscommunication creates frustration. In some sectors, it can lead to compliance concerns, rejected submissions, or damaged credibility with clients, patients, employees, or regulators. How to decide what your project needsStart with purpose. Ask what the content must do once it is delivered. If it needs to match the source closely for official, legal, medical, or technical use, translation is likely the primary service. If it needs to persuade, guide, convert, or feel native in-market, localization may be the better fit. Then consider audience. Are you communicating with a court, agency, hospital, engineer, or auditor? Or are you speaking to app users, employees, customers, or event attendees in a local market? The more user experience and cultural response matter, the stronger the case for localization. Next, look at risk. What happens if the wording is technically accurate but contextually wrong? What happens if adaptation goes too far? High-risk content benefits from a language partner that can separate these requirements clearly and build the workflow around them. Finally, think operationally. Many organizations do not need a philosophical answer. They need a fast, reliable process that identifies which assets require certified translation, which need localization, and which need both. That is especially true under tight deadlines or multilingual rollout schedules. What a dependable language partner should handleA serious provider should not force every project into one bucket. They should review the content type, intended use, and market requirements before recommending a workflow. That may include translation, localization, editing, proofreading, terminology management, formatting, desktop publishing, certification, or multilingual QA. Speed matters, but speed without control is expensive. The right partner should be able to move quickly while protecting confidentiality, assigning domain-expert linguists, and maintaining consistency across languages and deadlines. For organizations managing multiple departments or high-volume requests, scalability also matters. A vendor may handle a single brochure well and still struggle with a nationwide interpreter rollout, a regulated document queue, or a software release across multiple markets. This is where experience shows. Translators USA supports high-stakes language projects with subject-matter linguists, fast turnaround, and coverage across 150+ languages and dialects. For clients facing strict timelines, official-use requirements, or multilingual operational demands, that kind of execution capacity is often the difference between a solved problem and a recurring one. The smarter question to askInstead of asking whether translation or localization is better, ask what success looks like for this specific content. Does it need to be exact, market-ready, or both? That question leads to better scoping, fewer revisions, and stronger outcomes. Good language work is not just about converting words. It is about making sure the message performs correctly in the setting where it will be used. When accuracy, trust, and deadlines all matter at once, choosing the right service at the outset saves more than time. It protects the result. https://translators-usa.com/translation-vs-localization-services/ #metaglossia #metaglossia_mundus

"...Back translation works best when your main fear is hidden meaning shift. If your main fear is awkward local phrasing, user confusion, or weak market resonance, another method may be the better primary control.
Best Practices for Managing the Back Translation Process
The projects that run smoothly usually share one trait. The client gives the language team enough context to make good decisions before reconciliation begins.
For maximum ROI, experts advise reserving back translation for regulated sectors where inaccuracy penalties exceed 2-3 times the project cost, and they recommend providing full context such as glossaries and using a TMS for efficiency, as noted in these back translation best practices from Lokalise.
What clients should prepare before the project starts
If the document is high stakes, send more than the source file.
A glossary of approved terms. This is mandatory for product names, legal defined terms, clinical language, device parts, and recurring technical phrases.
Reference material. Prior filings, approved labels, source screenshots, and parallel documents help the translators preserve function.
A risk map. Mark the sections where wording carries the greatest exposure. Don’t force the same QA depth on every paragraph if only part of the document is critical.
Decision owners. Someone on your side must be available to answer terminology and intent questions during reconciliation.
A Translation Management System such as Smartling, Transifex, or another structured workflow platform can help keep terminology, comments, and revision history under control. That matters when multiple linguists are involved and every edit needs a reason.
What a well-run process looks like
A good process is disciplined and documented:
Separate linguists handle forward and back translation. No shortcuts.
The back translator remains blind to the source. That preserves the value of the test.
Reviewers compare for function, not only wording. Legal force, clinical meaning, and procedural sequence matter most.
Reconciliation decisions are logged. This protects consistency and gives you an audit trail.
Only critical content gets the full treatment. That keeps cost aligned with risk..."
https://translators-usa.com/translation-back-translation/
#metaglossia
#metaglossia_mundus

"Twenty years ago, Google Translate began with a profound mission to help people understand one another, regardless of the language they speak. In the two decades since, we’ve worked to turn the science of language into the magic of connection. What started as a small experiment is now a global tool that helps people every day, from connecting with new people while traveling to learning a new language to support their career....
1. Translate now has the pronunciation tool you’ve been asking for.
To celebrate our 20th anniversary of Translate, today we’re launching one of our most requested features: pronunciation practice, so you can master your delivery on the Translate app for Android. You can already tap "ask" and "understand" to provide additional context and receive alternatives, and now you can use the new “pronunciation practice” tool, which uses AI to analyze your speech and provide instant feedback — helping you nail the right pronunciation before you start a real-world conversation. This is now available in the U.S. and India in English, Spanish and Hindi.
2. We’ve been using AI and machine learning in Translate since the beginning.
Translate was one of the initial experiments that kickstarted Google’s machine learning work decades ago within Google Research. In 2006, Translate relied on statistical machine learning, and a key part of making more fluent and natural translations was our research into how to maintain much larger-scale and more accurate language models (which capture how often words and short phrases occur) across trillions of words of data...
3. Translate supports 95% of the world’s population.
Translate works for almost 250 languages and more than 60,000 potential language pairs, including endangered and indigenous languages, ensuring more voices are heard as the world becomes more connected.
4. More than 1 billion users ask Google for translation help each month.
Translation is no longer a standalone task; it is now a fundamental part of how people discover and understand information across the web, and communicate with the world around them.
5. People translate around 1 trillion words every month.
There’s enough text translated across Translate, Search, Lens and Circle to Search every month to keep someone reading out loud 24/7 for the next 12,000 years.
6. Your headphones can be your personal translator.
With Live experiences, Translate can now be your personal translator on any headphones. By preserving the original tone and cadence of the person speaking, the technology stays out of the way so you can focus on the human connection. Live translate helps you get a quick translation when traveling, like better understanding a local speaking to you or listening to a tour guide.
...
16. The most translated language pairs might surprise you.
English to Spanish remains the most common go-to language pair in Translate but other common language pairs include English to Indonesian, Portuguese, Arabic and Turkish. English to three distinct Indian languages — Hindi, Bengali and Malayalam — round out the list, reflecting a big increase in connectivity across the globe..."
https://share.google/4aTdf63cf2jofl0eR
#metaglossia
#metaglossia_mundus

"As the International Booker Prize celebrates its 10th anniversary, new research compiled for the Booker Prize Foundation by NielsenIQ BookData shows that buyers of translated fiction in the UK skew significantly younger, more male and more diverse than buyers of general fiction. They are also younger, more male and more diverse than a decade ago.
In 2016 – the year of the Brexit referendum and Donald Trump’s first presidential election victory – the International Booker Prize was established in its current form. The prize had begun life in 2005 as the Man Booker International Prize and was initially a biennial literary award for a body of work, with no stipulation that the work should be written in a language other than English. In 2015, after the rules of the original Booker Prize expanded to allow writers of any nationality to enter, the International Booker Prize evolved to become the mirror image of the English-language prize, but for a single work of fiction translated from another language into English.
Over the past decade, the prize has grown in prominence, and is now firmly established as the world’s most influential award for translated fiction. At the same time, translated fiction has undergone a boom in the United Kingdom: in 2016, 2.9 million works of translated fiction were sold in the UK; by 2025 (the latest year for which data is available) that figure had risen to 3.8 million works, while the value of the market rose from £23.2m to £40.7m in that period.
Tastes appear to have changed over the years, too. In 2016, books translated into English from Swedish, French and Italian were the most popular among UK readers; in 2025, it was books translated from Japanese, French and Russian (driven partly by an increase in sales of classic Russian literature).
But perhaps most interesting is the demographic profile of readers of translated fiction, and how it has changed over the past decade, as well as how it compares to the profile of readers of general fiction.
Buyers of translated fiction are relatively young – and appear to be getting younger. In 2025, 72.8% of translated fiction books were bought in the UK by those under the age of 45 (versus 67.6% in 2016). By comparison, 54.4% of 2025’s general fiction was purchased by those under 45 (versus 51.3% in 2016).
The largest share of translated fiction purchases in 2025 was made by those aged 25-34 (compared with the 45-59 age group in 2016), while the largest share of general fiction purchases came from buyers aged 60-84 (also 45-59 in 2016). In 2025, buyers under the age of 35 accounted for 52.0% of all translated fiction books bought, compared with just 36.8% of general fiction books bought."
Written by
Paul Davies
Publication date and time:Published May 4, 2026
https://thebookerprizes.com/the-booker-library/features/young-urban-and-male-who-is-reading-translated-fiction-in-the-uk-now
#metaglossia
#metaglossia_mundus

"Le lancement de la Bibliothèque numérique Andjeun réunira du beau monde ce mercredi 6 mai 2026 dans la salle Menoua de l’immeuble Elite Offices à Akwa-Douala. Cette plateforme digitale portée par l’artiste-musicien-chanteur et homme d’affaires Gabriel Fopa, est conçue et développée par ITGStore.
Cette plateforme Andjeun met à la disposition du public à travers les quatre coins du monde, plus de 3500 ouvrages subdivisés en deux domaines : le Savoir-être (une immersion dans l’histoire, la littérature, la philosophie et les sciences pour mieux comprendre le monde), et le Savoir-faire (des formations ultra-pratiques, apiculture, pisciculture, héliciculture…). Il s’agit pour le promoteur, de valoriser l’autonomisation économique. « Nous espérons tisser l’interrelation fertile entre le Soi, l’inter-communauté et l’espace précieux du Tout-Monde », souligne Gabriel Fopa."
https://lavoixdukoat.com/bibliotheque-andjeun-la-revolution-numerique-en-marche/
#metaglossia
#metaglossia_mundus

"This book investigates the methods and strategies of how translation and interpreting are taught in Africa, and it identifies the subject matters studied in several African universities, namely the five corners: north, south, west, east, and central Africa. The book goes through its different chapters to measure the efficiency of those translation and interpretation programs, departments, faculties, and schools via a comparison with the rate of employability of the graduates and their reputation in different local and continental organisms. This book reveals the teaching translation and interpretation in Africa which is still adopting the traditional classical methods or adopting new methodologies in this age of AI and recommends methods to face positively the increasing integration of AI at all life levels including in translation and interpretations to highlight the pros and cons of it and prospect or recommend adaptive measures, methods, strategies, or likely methodologies for better outcomes and performance. This book also presents the mapping of major schools, faculties, institutes, and departments of translation and interpreting in Africa. It can serve as a useful academic guide for academic scholars and professional readers on African instructions of translation and interpreting teaching."
https://link.springer.com/book/10.1007/978-981-95-8461-1
#metaglossia
#metaglossia_mundus

"Quebec’s language laws face a new reality online: automatic translation
Tech companies moving toward automatic translation may have profound implications on Quebec's linguistic landscape.
By Harry North
April 26, 2026 at 6:00 a.m.
Quebec’s new premier Christine Fréchette meant to post on X about a very Montreal kind of evening.
Her first appearance as premier on Tout le monde en parle, Radio-Canada’s flagship talk show? Check.
The Canadiens’ 4-3 win? Check.
“Une très belle soirée!” (a great evening), she concluded.
...
In Quebec, French by law is required in workplaces, commerce and public signage, and must be no harder to access than any other language. The responsibility rests with those who post it.
So, what happens when language online is available but sometimes inaccurate? What risks do businesses face in relying on platforms to translate? And what does that mean for connection across communities that speak different languages?
OQLF opens door to auto-translation
Quebec’s language watchdog, the Office québécois de la langue française, told The Gazette that commercial social media posts by companies about products or services intended for the Quebec market must be available in French, and that machine translation can be one way of doing that.
“The OQLF believes that using innovative means based on information and communication technologies can help ensure a greater presence of French,” it said in a statement. “If the automatic translation module allows users to access commercial publications in French, without any changes to the settings, regardless of the device used to view them, then these publications would be considered available in French.”
The office added that compliance must be assessed case by case.
“To assess the compliance of commercial publications on a company’s website, for example, a text is considered not to be in French if, to understand it, one must refer to its version in another language.”
Asked whether the OQLF has analyzed the quality of translations, it said: “The OQLF’s mandate does not include analyzing the language quality of content generated by automatic translation tools.”
A review by The Gazette of X posts translated between both English and French found most translations were accurate. Some, however, did not provide the intended meaning. Others were not translated at all.
Automatic translation settings on TikTok (left), X (right) and YouTube (bottom)
/Montreal Gazette
The OQLF’s current framework was not designed with automatic translation in mind, said Julianne Chu, a lawyer and translator for Éducaloi, and it also does not distinguish between how French is produced, and whether it has been human translated, machine translated or even done automatically.
“It really focuses on whether the French translation is available and meets legal requirements, notably in terms of quality and accessibility.”
For businesses, she said, it presents a confusing picture and carries risks, particularly when relying on a platform to handle translation.
How do machines translate language?
Grok’s translations are powered by what are known as large language models, the same kind of system behind tools like ChatGPT, Google’s Gemini and Anthropic’s Claude. Most operate as what researchers call “black boxes”: they generate an output, but offer little insight into how it was produced. They are trained on vast amounts of text to learn how language works. In 2025, nearly six in 10 Canadians used an AI tool like Grok or ChatGPT, according to a Léger survey.
For translation specifically, that training typically happens in two stages, according to Jackie Cheung, a computer science professor at McGill University who researches how AI understands and generates human language.
First, he said, the systems are exposed to enormous volumes of text in English, French and other languages, allowing them to see how words tend to appear together, how sentences are structured and how meaning is usually conveyed.
Then comes a second stage, more specific to translation. The models are trained on pairs of text, and learn how to map one onto the other.
At a basic level, the systems are learning patterns. However, whether these systems truly understand what they are translating, Cheung said, remains a “thorny” question in the field of AI research.
Still, they can be effective at translating the surface of language, he said, especially in more standard or formal contexts.
“What’s kind of missing is the context necessary to understand the intentions of the original poster fully,” Cheung said.
That is particularly true online. Language often depends on shared references — memes, in-jokes and tone — that exist within a community. Outside that context, a translation can feel off or misleading, even if it is technically accurate.
I don’t think (automatic translation) will help that much in terms of increasing connection or inter-community understanding.
Jackie Cheung
McGill professor
Montreal, Cheung noted, has its own version of that, too, where sometimes it may not even be pure French or English spoken or written, but a mix of both.
“The choice of language that you use itself contains information,” he said. “And this would, by definition, be lost if you have auto-translate on.”
The result is a risk that regional expressions, dialects or ways of speaking are smoothed into something more standardized, more aligned to what the generalized models were trained on.
Why AI models may overlook Quebec
Eeham Khan, a PhD researcher at Concordia University, is building a Quebec-first language model to counter that.
“It’s not always just about language,” he said in an interview with The Gazette. “The data that we have is not just the language of Quebec, but it also represents the terms, the cultures, things that maybe other models or larger models might not know about too well.”
When he began working on the project last year, he recalls asking ChatGPT to translate something into Quebec French. The chatbot’s reply was like “it’s forcing itself to be the most ‘redneck Quebecer’ imaginable.”
“It’ll use eight different slang terms in two sentences,” Khan said. “You read it and think: No one talks like this. No one writes like this.
“It knows what the idea of Quebec is, but it takes it to the extreme.”
The biggest problem, he said, is data availability.
Khan is trying to build that foundation, working with partners including Radio-Canada to gather data with consent.
“Even with all of that, we can’t really hope to compare to the big models,” he said, pointing to the time and resources required to collect data ethically. And as those larger systems become more widely used, he said, they begin to shape how language is expressed.
According to Cheung, Indigenous languages raise even more sensitive questions. Some communities may not want their languages fed into translation systems, especially if the result is more access for outsiders than benefit for the community itself.
“The other issue is that it’s not clear that the same pipeline that works for English and French actually works for other languages where there’s not so much data available,” he said, adding that the copious amounts of data that the models heavily rely on may not exist for many other languages.
This month, draft regulations tabled by Marc Miller, minister of Canadian identity and culture and minister responsible for official languages, set out how federally regulated businesses must provide services in French, targeting sectors that have historically slipped through the cracks of Quebec’s Charter of the French Language because they fall under federal jurisdiction.
The Department of Canadian Heritage told The Gazette: “Language compliance requirements remain the same, but the means to fulfil them are evolving. This was taken into account in the analysis leading to the draft regulations that pertain to the private sector.”
It added: “The obligations for federally regulated private businesses that would fall under the jurisdiction of the draft regulations would be to provide communications and services to consumers in French, regardless of the means used. The use of French would need to be at least equivalent to the use of any other language.”
Governments elsewhere in the world are already starting to respond to X’s move. This month, the U.K. Embassy in Japan posted that it was not responsible for Japanese translations automatically generated on X.
Ultimately, Cheung says he remains cautious about auto-translation’s potential to bridge connection.
“You can even see it within English,” he said. “There are so many sub-communities, and there are still massive misunderstandings and polarization.
“I don’t think it will help that much in terms of increasing connection or inter-community understanding,” he said. “Language is an important part of it. But it’s not the whole thing.”
As for Khan, he says he understands “the benefits of having these translation services,” and that “they’re good in promoting accessibility.”
“But on the other hand, this only works really if the translation service works correctly. If you’re mistranslating information from politicians or CEOs coming from these smaller countries, smaller provinces, etc., who are tweeting in their native languages or native dialects, it could potentially be very damaging for those people or for those cultures.
“So, like everything, it has to be done right. It has to be done responsibly. It has to be done carefully.”
Quebec's language laws face a new reality online: automatic translation - Montreal Gazette https://montrealgazette.com/news/quebecs-language-laws-face-a-new-reality-online-automatic-translation/
#metaglossia
#metaglossia_mundus

Poetry translator serves as cross-cultural ambassador for latest project, ‘Last Stops of the Night Journey’
"LAWRENCE — After more than a decade translating leading North American poets – such as Anne Carson and Michael Ondaatje — into Italian, as well as prominent Italian poets into English, Patrizio Ceccagnoli regards literary translation as central to his professional identity, calling himself “an ambassador of my original language and culture, a bridge between the two literatures embodied in the languages I know best.”
A dual citizen, Ceccagnoli translates in both directions, from Italian into English and vice versa, with a particular specialization in poetry. An associate professor in the University of Kansas Department of French, Francophone & Italian Studies, he continues this work with his latest project: Milo De Angelis’ “Last Stops of the Night Journey.”
Ceccagnoli and local poet Megan Kaminski, a professor of environmental studies at KU, will read from their books April 28 at The Raven Book Store.
“I translate only authors I consider significant, for the sake of being close to their work and understanding their oeuvre more deeply,” Ceccagnoli said. “Everything is driven by my love for literature. I find great fulfillment in literary translation, which exists somewhere between scholarly interpretation and creative writing.”
Ceccagnoli said he shares credit with his longtime collaborator and friend, Susan Stewart, a MacArthur Foundation “Genius” award recipient. Together, they previously translated De Angelis’ “Theme of Farewell and After-Poems: A Bilingual Edition” (University of Chicago Press, 2013), a work Ceccagnoli said helped establish the poet’s reputation among American readers.
Their collaborative process is iterative and meticulous.
“I begin with the Italian text and produce a rough English translation, identifying passages that may present cultural challenges — references that require explanation or place names that may not resonate with an American audience,” he said. “When Susan reviews the draft, she identifies additional issues. We then revise collaboratively until we reach a version that satisfies us both after several back-and-forth exchanges.”
The translators also consulted directly with De Angelis while working on “Last Stops of the Night Journey,” occasionally making independent editorial decisions.
“Of course, the publisher also plays a crucial role,” Ceccagnoli said. “When you’re fortunate to work with a strong editor, they offer valuable suggestions and request revisions. This book benefited from particularly attentive editing.”
That editor, Archipelago Books publisher Jill Schoolman, will attend the Lawrence reading.
Like “Theme of Farewell and After-Poems,” “Last Stops of the Night Journey” brings together two separate poetry collections in one volume: “Encounters and Ambushes” (“Incontri e agguati”), released in Milan in 2015, and “Solid Line, Broken Line” (“Linea intera, linea spezzata”), originally published in 2021. These works reflect themes drawn from De Angelis’ experiences teaching poetry in a high-security prison near Milan, the loss of his wife — the poet Giovanna Sicari — and his growing awareness of mortality.
“This is clearly a late work,” Ceccagnoli said. “Every poetic corpus reflects a life lived; it becomes, in a sense, a biography. A writer can only speak to what they have witnessed and understood, and over time, that accumulates into the story of a lifetime.”
He noted that De Angelis’ poetry demands careful, attentive reading.
“A poet like Milo does not necessarily strive for easy accessibility,” Ceccagnoli said. “He has sometimes been described as ‘orphic’ or hermetic – not out of elitism, but because he is committed to a rigorous poetic tradition shaped by earlier models and governed by a highly disciplined literary code.”
At the same time, Ceccagnoli said he finds the collection deeply moving.
“Here is a man who understands that his time is finite,” he said. “In his 70s, he may see this as his final book — a series of farewell messages to the people who shaped his life. That gives the work a powerful sense of authenticity and emotional depth.”
While the collection does not attempt to resolve life’s fundamental questions — about meaning, mortality or what lies beyond — Ceccagnoli said it offers something equally valuable.
“It provides an honest and, at times, dramatic portrait of the people the poet encountered,” he said. “Through his writing, their lives endure — and, in a way, become part of our own.”
Media Contacts
Rick Hellman
KU News Service
785-864-8852
rick_hellman@ku.edu"
Fri, 04/24/2026
Rick Hellman
https://news.ku.edu/news/article/poetry-translator-serves-as-cross-cultural-ambassador-ARTICLE-KHRJWD-ARTICLE-KHRJWD-ARTICLE-KHRJWD-ARTICLE-KHRJWD-ARTICLE-KHRJWD-ARTICLE-KHRJWD
#metaglossia
#metaglossia_mundus
"Luotuo Xiangzi, a landmark work of modern Chinese literature, has been retranslated into English multiple times since its initial success in the United States. This study investigates the translators’ voices in the characterization of Huniu, one of the novel’s most memorable female figures, across four English versions by Evan King, Jean James, Shi Xiaojing, and Howard Goldblatt. Drawing on a self-constructed bilingual parallel corpus, it applies a modified characterization framework together with a three-dimensional model of the translator’s voice appraisal—loudness, pitch, and timbre—by qualitative content analysis and Python-assisted quantitative methods. The findings show that King amplified Huniu’s shamelessness and assertiveness, James softened her portrayal with fewer interventions, Shi preserved her emotional depth while favoring domestication, and Goldblatt significantly softened her vulgar traits through heavy tonal modifications. Variations in lexical choices, sentence length, and syntactic patterns corresponded closely to the dimensions of loudness, pitch, and timbre, demonstrating that translators’ voices actively reframe Huniu’s personality traits, emotional expressiveness, and cultural positioning. This study thus highlights the translator’s voice as a formative force in literary characterization and offers a replicable translator’s voice appraisal model for future translation research."
Jing Cao & Tianli Zhou
Humanities and Social Sciences Communications , Article number: (2026)
providing an unedited version of this manuscript to give early access to its findings. Before final publication, the manuscript will undergo further editing. Please note there may be errors present which affect the content, and all legal disclaimers apply.
Article
Open access
Published: 25 April 2026
Abstract
https://www.nature.com/articles/s41599-026-07326-5
#metaglossia
#metaglossia_mundus

" "The Running Flame" is the third work by Fang Fang that Berry has translated into English.
By Peggy McInerny, Director of Communications
UCLA International Institute, April 24, 2026 — Director of the UCLA Center for Chinese Studies Michael Berry and celebrated contemporary Chinese novelist Fang Fang (author of “Wuhan Diary”) and have together won the 2025 Baifang Schell Book Prize for Fiction as translator and author, respectively, of the English-language translation of Fang Fang’s novel, “The Running Flame.”
“I am especially happy for Fang Fang; one of the most courageous people I know,” said Berry, who is also professor of contemporary Chinese cultural studies in the department of Asian languages and literatures at UCLA.
“She is a writer with an uncanny sensitivity, a gift for storytelling and an unwavering set of moral convictions. Working with her has been one of the greatest honors of my career,” he added. “I hope she sees this award as an affirmation that her words matter and we are listening.”
In an interview with Berry last year, Fang Fang described the predicament faced by Yingzhi, the protagonist of “The Running Flame,” as illuminating the larger challenges faced by rural women in contemporary China. “Women appear to have a home, but internally they may feel rootless. They may feel they have no place in the world at all. Their birth family has cast them out, and their new family does not fully accept them in the beginning,” she said.
“This creates a period of emotional limbo — a vacuum where they feel utterly empty inside. Yingzhi is one such woman caught in this state.”
Originally published in China in 2001, “The Running Flame” is one of only two novels by Fang Fang that have been translated into English to date. The other, “Soft Burial” (also translated by Berry) was originally published in China in 2016. Both novels were short-listed for the 2025 Baifang Schell Prize, along with only three other works of Sinophone fiction. Synopses of all five novels can be found on the short list.
Berry, a well-known scholar of Chinese culture and film, is a prolific translator of Sinophone fiction. He has translated three works by Fang Fang, the first of which was “Wuhan Diary.” Written by Fang Fang during the outbreak of the COVID-19 pandemic in China in 2020, Berry began translating the diary as the pandemic hit the United States and stay-at-home orders began to be instituted by numerous states and metropolitan jurisdictions.
The Baifang Schell Book Prize is an annual award conferred by China Books Review, a free digital magazine based at Asia Society in New York. It is named in honor of Liu Baifang Schell, who passed away in 2021 after spending her life working to advance U.S.-China relations.
The prize was launched in 2024 and celebrates exceptional book-length works on or from China and the Sinophone world that are published in English. It offers two $10,000 awards: one for nonfiction and one for fiction, with both author and translator awarded the latter. Although the prize is administered by China Books Review, annual winners are chosen by independent juries. An awards ceremony for the 2025 winners will be held on June 9 at Asia Society in New York.
Published: Friday, April 24, 2026
https://www.international.ucla.edu/institute/article/295336
#metaglossia
#metaglossia_mundus

"His role was to act as a liaison between the US forces and the Afghan national army and police officers they worked alongside. He provided translation and cultural advice.
"The Americans did not know which one is the mosque, which one is the normal house. But we would know; we would see books, we would see praying rugs," he says.
"So if you see an American walking inside a mosque with their boots on and with their canine dogs, it would trigger the civilians right away."
Targeted by his own countrymen
Many Afghan civilians resented the Americans, but they also detested the translators, like Sheraz, who worked with them.
"They didn't like interpreters at all. They would treat them as an infidel, who doesn't believe in God," Sheraz says.
Sheraz's brother Ferdows was killed by an IED in 2017, and later, his family home was targeted in a bomb attack that severely injured his father and younger brother.
Sheraz believes the attacks were in revenge for his work.
"His hands, his feet were burned … when the explosion happened, they ran away," Sheraz tells 7.30.
"But as soon as they remembered that my dad is inside, he just went back to the fire and grabbed him and pulled him out. So they got burned while they were taking my dad out of the fire."
By that time it had become clear that Afghanistan was no longer safe for Sheraz, or his family.
In 2019, he along with his wife and son were granted visas to Australia as part of a government scheme to help those who had worked with Australian troops.
Gus McFarlane had written supporting letters to help the family come to Australia.
"He, in my opinion, directly contributed to my safety and the safety of other Australian soldiers that were deployed in Afghanistan," says Lieutenant Colonel McFarlane.
Sheraz's parents and younger brother have subsequently been granted visas.
On the eve of Anzac Day he told 7.30 that he doesn't have lingering trauma from the years of conflict in Afghanistan.
"Maybe Afghans are tough," he says.
"They face war for more than 50 years now. Maybe that's another reason, because since we were kids, we hear firearms … we're talking about war, about losing family members, losing relatives, and they see bombs, they see people get blown up, they see vehicles blown up."
As he is explaining the impact of war on Afghanistan's people, his children Sultan and Sophia come barrelling into the lounge room.
"What if I was stuck in Afghanistan still, so my daughter wouldn't be able to go to school and my family and I wouldn't be safe," Sheraz says.
"I think about the positives that I have in my life now."
Lieutenant Colonel McFarlane says he's proud that the RSL is recognising Sheraz, and all the locally-engaged staff this Anzac Day...."
By Adam Harvey
7.30
Topic:Anzac Day
https://www.abc.net.au/news/2026-04-23/sheraz-ahmadi-afghan-translator-australia-troops-anzac-day/106585112
#metaglossia
#metaglossia_mundus

"Next-word prediction has been hypothesized as the central computational objective of the human language system, akin to that of current large language models. Here we put this conjecture to the test, investigating whether the brain predicts each upcoming word as precisely as possible when listening to connected speech. In three magnetoencephalography experiments with Mandarin Chinese speakers, we demonstrate that the response related to word unpredictability, that is, word surprisal calculated using large language models, is significantly stronger for words within an ongoing constituent than words across a major constituent boundary, and this effect is further modulated by the certainty of a constituent boundary. This constituent-boundary effect is also observed behaviorally unless speech is very slowly presented, and it is confirmed by analyzing a dataset of electrocorticography responses to natural English narratives. The constituent-boundary effect demonstrates that the language system does not solely optimize word-prediction precision; rather, it balances word-prediction contributions by constituent-constrained management of linguistic contextual representations."
Jiajie Zou (邹家杰), David Poeppel & Nai Ding (丁鼐)
Abstract
https://www.nature.com/articles/s41593-026-02272-6
#metaglossia
#metaglossia_mundus

There is (or should be) perfect harmony between faith and reason...!
"Christ does not appear as a religious escape in the face of intellectual endeavors, as if faith began where reason ended. On the contrary, in Him the profound harmony between truth, reason and freedom are manifested."
Pope Leo XIV made this point in Equatorial Guinea when meeting with the World of Culture in Malabo at the National University's León XIV Campus on 21 April 2026.
He acknowledged the inauguration of the new campus of the National University of Equatorial Guinea in his name, expressing his gratitude for the kind gesture, but stressing that "such a decision goes beyond the person being honored as it reflects the values that we all want to pass on to others."
The inauguration of a university campus is more than a mere administrative act, but rather is "an act of trust in human beings, an affirmation of the fact that it is worth the effort to continue wagering on the formation of new generations and on the task, so demanding and yet so noble, of seeking the truth and putting knowledge at the service of the common good."
He stressed therefore that a space for hope, encounter and progress is opened, and accordingly used the image of a tree to speak of the university’s mission, as he remembered that for the people of Equatorial Guinea, the ceiba, the national tree, has a great symbolic meaning.
Deep roots and persevering search for truth
The Pope remembered that a tree puts forth deep roots, and ascends slowly with patience and strength to the heights, embodying a fruitfulness that does not exist for itself.
Likewise, he suggested, "a university is called to be well rooted in the seriousness of study, in the living memory of a people and in the persevering search for truth...
Christ does not appear as a religious escape in the face of intellectual endeavors, as if faith began where reason ended.
On the contrary, Pope Leo insisted, in Him the profound harmony between truth, reason and freedom are manifested.
In this context, the Holy Father explained that truth presents itself as a reality that precedes human beings, challenges them and calls them to come out of themselves, saying this is why truth can be sought with trust.
"Faith, far from shutting itself off from this search," he added, "purifies it of self-sufficiency and opens it to a fullness towards which reason strives, even if it cannot completely embrace it."
...
Christ manifests harmony between faith and reason - Pope Leo in Equatorial Guinea (Vatican News)
By Deborah Castellano Lubov
21 April 2026, 18:22
https://www.vaticannews.va
#metaglossia
#metaglossia_mundus

"L’entreprise d’IA linguistique DeepL lance Voice-to-Voice, une suite de solutions de traduction vocale en temps réel pour les entreprises.
Le leader de l’intelligence artificielle linguistique, DeepL, a annoncé aujourd’hui le lancement de DeepL Voice-to-Voice, une nouvelle gamme de solutions de traduction en temps réel conçue pour la communication orale. Cette innovation majeure permet une traduction vocale instantanée pour les réunions virtuelles, les conversations en face à face et les interactions avec la clientèle, avec l’ambition de supprimer définitivement les barrières linguistiques dans le monde professionnel.
« Aujourd’hui, nous franchissons une nouvelle étape dans le domaine de la traduction : la communication vocale en temps réel », a déclaré Jarek Kutylowski, fondateur et PDG de DeepL. « Notre mission a toujours été de supprimer les barrières linguistiques et nous venons de faire tomber l’une des plus importantes. DeepL Voice-to-Voice permet à chacun de s’exprimer naturellement dans sa propre langue, et cela sans engendrer de frictions ni de coûts liés aux interprètes. Désormais, seule l’expertise compte, pas la langue ».
Une suite complète pour la communication en temps réel
DeepL Voice-to-Voice a été développée pour répondre à un besoin critique des organisations internationales : la traduction orale. La suite se décline en plusieurs outils intégrés :
* Voice for Meetings : Une solution de traduction en temps réel pour les plateformes de visioconférence comme Microsoft Teams et Zoom. Les participants parlent dans leur langue et sont entendus par les autres dans la leur. Un programme d’accès anticipé débutera en juin.
* Voice for Conversations : Déjà disponible sur mobile, cette fonctionnalité est désormais étendue au web pour une expérience multi-plateforme, facilitant son déploiement dans des environnements professionnels stricts.
* Group Conversations : Disponible à partir du 30 avril, cet outil est conçu pour les formations et ateliers multilingues. Les participants peuvent rejoindre une conversation via un code QR et bénéficier d’une traduction simultanée.
* API Voice-to-Voice : Permet aux entreprises d’intégrer la technologie de DeepL directement dans leurs applications, notamment dans les centres de contact.
* Personnalisation : Dès le 7 mai, les glossaires de traduction seront intégrés pour garantir la transcription et la traduction correctes de terminologies spécifiques (noms de produits, jargon sectoriel), même à un débit de parole rapide.
Qualité et accessibilité au cœur de la stratégie
Pour valider la performance de sa technologie, DeepL a commandité une évaluation indépendante menée par Slator. Les résultats montrent que 96 % des linguistes professionnels ont préféré DeepL Voice aux solutions natives de Google, Microsoft et Zoom, saluant sa fluidité et sa précision contextuelle. Les intégrations pour Zoom et Microsoft Teams ont obtenu des scores de qualité de 96,4/100 et 96,3/100 respectivement.
DeepL a également élargi le nombre de langues prises en charge à plus de quarante, incluant les 24 langues officielles de l’UE ainsi que l’arabe, le vietnamien, le thaï, ou encore l’hébreu. En parallèle, l’entreprise rend sa technologie plus accessible en proposant un modèle en libre-service, permettant aux petites équipes de tester la solution via un essai gratuit avant un déploiement plus large.
Un levier de performance pour les équipes internationales
L’impact de cette technologie sur la collaboration globale est déjà mesurable chez les premiers utilisateurs. Yoichi Okuyama, directeur du département DX Systems chez Pioneer, témoigne de cette transformation : « S’appuyer uniquement sur la maîtrise de l’anglais pour collaborer à l’échelle mondiale nous ralentissait souvent, car les membres de l’équipe hésitaient à partager des idées complexes. En mettant en place DeepL Voice, nous avons supprimé cette friction et instauré un environnement plus inclusif où chacun peut s’exprimer en toute confiance dans sa langue maternelle. Ce changement a permis d’accélérer nos processus métiers : une fois les barrières levées, nous avons constaté une participation plus engagée et une prise de décision plus rapide au sein de nos équipes internationales ».
DeepL Translate : une plateforme pour repenser les flux de travail
En parallèle de cette annonce, DeepL fait évoluer son outil principal vers une plateforme d’IA entièrement intégrée, DeepL Translate. L’objectif est de s’attaquer aux lenteurs et aux coûts des processus de traduction traditionnels en entreprise. « Les entreprises internationales ne se confrontent plus à une difficulté de traduction. Elles rencontrent un problème de modèle opérationnel », a ajouté Jarek Kutylowski. La nouvelle plateforme vise à centraliser et automatiser les flux de traduction, à évaluer la qualité des textes générés et à permettre des améliorations continues grâce aux corrections des utilisateurs.
Cette vision d’une traduction fluide et intégrée est partagée par des clients comme Mondelez International. « Notre ancien processus de traduction, c’était comme rouler avec un pneu crevé, tandis qu’avec DeepL, nous passons à la vitesse supérieure, à 160 km/h », souligne Geoffrey Wright, Global Solution Owner chez Mondelez. « Grâce à l’intégration de leur IA linguistique, des équipes telles que celles en charge des fusions-acquisitions et des affaires juridiques traitent des documents sensibles avec rapidité et en toute confidentialité ».
Fondée en 2017 par Jarek Kutylowski, DeepL est une entreprise spécialisée dans l’IA linguistique qui compte aujourd’hui plus de 1 000 employés. Elle est soutenue par des investisseurs de premier plan comme Benchmark, IVP et Index Ventures."
COLOGNE : Jarek KUTYLOWSKI : « Seule l’expertise compte, pas la langue »19 Avr 2026
https://presseagence.fr/cologne-jarek-kutylowski-seule-lexpertise-compte-pas-la-langue/
#metaglossia
#metaglossia_mundus
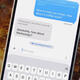
"There are all kinds of ways to use your phone to help you learn a language of course, but here’s one you might not have come across before: You can enable real-time translations for a host of different languages right inside the Messages app on iOS.
It works through the Apple Translate built into your iPhone, and it’s a great way to keep reminding yourself of conversational words and phrases. As demoed by @thetarynarnold over on TikTok, they’ll appear right alongside the messages you’re sending and receiving.
However, you will need Apple Intelligence on your iPhone for this to work. Apple’s proprietary AI is built into the operating system that runs on the iPhone 15 Pro and iPhone 15 Pro Max from 2024, plus every iPhone released since then, as well as a few other Apple devices like the iPad mini and Apple Watch Series 6. Head to Apple Intelligence & Siri in the iOS Settings to make sure Apple Intelligence is enabled on your phone.
How to enable translations in Messages
Open up the conversation you’d like to translate inside the iOS Messages app, then tap the name of the person you’re messaging up at the top of the screen. Next, enable the Automatically Translate toggle switch, and you’ll be asked to pick a language.
At the time of writing there are 20 available, and you can change the language you’re translating from and to at any time—the relevant options are underneath the Automatically Translate toggle switch, once you’ve turned it on.
From this point on in the conversation, every message you send in English will have the foreign translation right next to it, and every message you receive in the selected foreign language will have an accompanying English translation too. There’s a little drop-down menu just above the text input box that you can use to swap languages or stop the translation at any time.
This should work with anyone else on an iPhone, whether or not they have Apple Intelligence installed on their device. You should also see these translations from anyone texting you with an Android phone (Google Messages has a similar translation feature they can use too).
It’s not complicated, but that’s the beauty of it. While you couldn’t really learn an entirely new language just from doing this, it’ll definitely help you stay familiar with foreign words and phrases, as you get instant translations for what you’re saying.
Other translation tools on your iPhone
Assuming you do have Apple Intelligence installed on your iPhone, there are a host of other ways you can get translations from English into another language right away. It starts with the built-in Translate app of course, which can convert typed text and spoken audio between languages.
You’ll also notice a Camera button down at the bottom of the Translate app. Tap on this and you can point your iPhone camera at anything written in a foreign language—whether it’s a sign at a train station or something on a menu—and have the text translated. The Conversation tab, meanwhile, lets both you and someone else speak in different languages, and have the iPhone do the translating.
If you have a pair of AirPods Pro 2, AirPods Pro 3, or AirPods 4 with active noise cancelling attached to your iPhone, there will also be a Live button. Tap on this, and as other people speak to you in a foreign language, you’ll get translations right into your ears, through your AirPods. The dialog will show up on your phone too.
Translation is built into the FaceTime app as well. Tap on the screen to bring the controls up, then tap the three dots and pick Live Captions to use it. Something similar is available for live calls through the Phone app too, which you can access by tapping the three dots during a call, and choosing Live Translation.
All the language processing for these features is done on your device, and nothing is sent to the cloud or Apple’s servers. To change the languages you have downloaded to your iPhone and available in these apps, open the main iOS Settings screen and choose Apps > Translate > Languages."
David Nield
Published Apr 18, 2026 1:00 PM EDT
https://www.popsci.com/diy/translations-iphone-messages/
#metaglossia
#metaglossia_mundus
"New Voices in Translation Studies
Call for Special Issue Proposals
Deadline for proposals: 1 December 2026."
New Voices in Translation Studies invites original and innovative proposals for Special Issues that explore new or under-researched areas of translation. The journal welcomes contributions that explore diverse aspects of translation studies.
Your proposal should include:
Proposed topic/title
Brief outline of the topic (including its significance and relevance to the field)
Names and short biographies of the proposed guest editor(s) [NB: guest editor (or most members of the editorial team) should be early career or emerging scholars.]
Proposed timeline (including dates for call for papers, submission deadline, peer review, revisions, and final submission)
If applicable, a list of confirmed contributors with paper titles and abstracts. [The journal accepts that in such a case, some prior work may have been done, but all contributions will still need to pass through New Voices in Translation Studies submission and review processes as usual. NB: contributors should also be early career or emerging scholars.]
Submission Guidelines
Email your proposal to marija.newvoices@gmail.com
Use the subject line: NVTS Special Issue Proposal
You may submit as an individual guest editor or as part of a team.
All proposals will be evaluated by the editorial board based on originality, feasibility, academic quality, and relevance to our readership.
Deadline for proposals: 1 December 2026."
More information: https://newvoices.arts.chula.ac.th/index.php/en/announcement/view/4
#metaglossia
#metaglossia_mundus

Imparfait, plus-que-parfait, passé composé… Muriel Gilbert révèle l'origine étonnante des noms de nos temps...
Pourquoi l'imparfait porte un nom si étrange
Ce samedi 18 avril, un Bonbon grammatical, amis des mots, sur une idée de Gilles, sur la page Facebook du Bonbon sur la langue : "Bonjour Muriel... Pourriez-vous consacrer un Bonbon à nous expliquer la signification (et l'origine) du nom des temps des verbes ? Ils m’ont toujours étonné. À part le présent, le futur et l'impératif, qui sont assez clairement compréhensibles, quid de l'imparfait, du passé composé, du plus-que-parfait ? Merci Mumu."
Eh bien, "Mumu" s'exécute. C’est vrai que ces noms sont bizarroïdes, et pas très parlants. On va se contenter de parler du mode indicatif, on gardera les autres pour une autre fois ! Je trouve que le passé composé, c’est quand même assez clair : "Antoine a préparé le petit déj", "Valérie est venue manger" : on est dans le passé, mais ce passé est composé parce qu’il faut deux mots pour l’exprimer : a + préparé, est + venue.
L'imparfait c'est : "Antoine préparait le petit déj". "Valérie venait manger". À l’origine, le mot "imparfait" était un adjectif : on parlait de prétérit imparfait. Le terme "prétérit", qui s’emploie encore pour l’anglais, n’est plus utilisé en grammaire du français. Il vient du latin praeteritum, à l’origine praeteritum tempus, qui désignait un "temps passé" (praeter c’est devant, et ire c’est aller, donc le praeteritum c’est "passé devant", comme qui dirait… "dépassé"). On parlait au XVIIe siècle de "prétérit imparfait", de "prétérit simple" et de "prétérit antérieur", qui sont devenus nos actuels "imparfait", "passé simple" et "passé antérieur".
Pourquoi le mot "imparfait" ?
Et donc pourquoi ce mot, "imparfait" ? Il faut revenir à l’étymologie : évidemment, imparfait découle de parfait, parfait venant du perfectum latin qui n’a pas du tout le sens d’aujourd’hui : il veut dire "achevé", "terminé", "accompli", c’est plus tard en français qu’il a glissé vers le sens de "idéal, excellent". Bref, l'imparfait, ce n’est pas un temps qui ne serait pas parfait dans le sens qu’il aurait un défaut, c’est un temps du passé qui est décrit comme non achevé. "Muriel lisait quand le livreur sonna." La lecture se fait sur une certaine durée, "sonna" en revanche est au passé simple, car c’est un fait ponctuel. Bref l’intéressant, c’est que "parfait" signifie “accompli”, et non pas "génial", donc "imparfait" signifie "non accompli", pas "un peu nase".
Et pour le plus-que-parfait ? Il se construit avec être ou avoir à l’imparfait suivi d’un participe passé. Le plus-que-parfait est censé désigner une action passée antérieure à une autre action passée. Exemple : "J’avais terminé ma chronique, donc je sortis du studio" (je sortis du studio, ça se produit dans le passé, mais avant cela encore, j’avais terminé ma chronique, plus-que-parfait). Quoi qu’il en soit, ces appellations mériteraient un bon coup de ménage, si vous voulez mon avis, parce qu’elles n’ont pas grand-chose de logique..."
Muriel Gilbert
https://www.rtl.fr/culture/culture-generale/langue-francaise-pourquoi-l-imparfait-porte-ce-nom-si-etrange-7900624484
#metaglossia
#metaglossia_mundus
|











"...un mago de las palabras y los astros. Aislado en la cima de una verde colina de Eivissa, traduce libros. Carlos Manzano suma seis premios de traducción en tres idiomas –ingles, francés, italiano– y su precioso trabajo enriquece la cultura de España. Su obra como traductor es un capital cultural de primera magnitud que merece gratitud de los lectores en español. Ha traducido a Louis-Ferdinand Céline, Henry Miller, Marcel Proust, James Joyce, está con Sterne ( Tristam Shandy ), Anaïs Nin, Virginia Woolf, Pessoa... “Huí del mundo”, me resume, por no someterse a lo peor de España, como Joyce huyó de Irlanda: “¡La huida es la victoria!”. Aparece su Ulises (Navona), del que me dice: “Al fin una traducción que, como el original, es una obra de arte del lenguaje”."
#metaglossia mundus