 Your new post is loading...
Your new post is loading...
Le cofondateur d'OpenAI, Ilya Sutskever, a annoncé mardi en fin de journée qu'il quittait la start-up, star de la Silicon Valley depuis qu'elle a lancé ChatGPT et la révolution de l'intelligence artificielle (IA) générative.
There is a war going on. Humanity and nature are on one side and Big Tech is on the other. The two sides are not opposed. They are orthogonal. The human side is horizontal and the Big Tech side is …
Via Vladimir Kukharenko, juandoming, LGA
Flownote capture chaque mot de vos réunions et génère des résumés précis en un instant. Découvrez cette application IA impressionnante.
Via Elena Pérez
Victoria Shi, la nouvelle porte-parole du ministère ukrainien des Affaires étrangères, a été générée par intelligence artificielle. Elle sera chargée de commenter les affaires consulaires en lisant des textes qui devront néanmoins toujours être rédigés par des humains.
Via cdi
La proposition controversée des législateurs de l'Union européenne d'obliger légalement les platesformes de messagerie à analyser les communications privées à la recherche de matériel pédopornographique (CSAM) fait face à une nouvelle vague de réactions négatives de la part des experts en sécurité et en protection de la vie privée.
Via Intelligence Economique, Investigations Numériques et Veille Informationnelle
Tiny11Builder is a third-party script that can take a Windows installation ISO, which you can get from Microsoft, and strip it of all of the annoying extra features. Install Windows using this tool and you'll have a truly clean installation: no News, no OfficeHub, no annoying GetStarted prompts, and no junk entires in the start menu.
Via Philou49
OpenAI is working on GPT-5 and is expected to launch it this year but it is unclear when it will arrive. Some suggest sooner than expected.
Via EDTECH@UTRGV
Découvrez Pairdrop, un outil gratuit open source pour transférer des fichiers facilement entre appareils. Simple, rapide et sécurisé, sans installation.
Via Fidel NAVAMUEL
En un panorama digital en constante evolución, donde las nuevas tecnologías emergen a un ritmo acelerado, los gerentes generales y de tecnología se encuentran en una encrucijada: ¿Cómo discernir entre las tendencias pasajeras y las tecnologías con potencial transformador?
Via Ramon Aragon, Mariano Ramos Mejia, juandoming
|
OpenAI's Preferred Publisher Program offers media companies licensing deals.
Via Bruno Renkin
Apple and OpenAI are reportedly close to inking a deal that would enable ChatGPT integration with iOS 18. Here's what we know.
Via EDTECH@UTRGV
Comment savoir si un texte a été rédigé par un rédacteur ou un journaliste et non par l’iA de Chat GPT ? L’irruption de
Via Elena Pérez
Done with Google? Want to try something new and AI-powered? Perplexity could be just what you're looking for.
Via Tom D'Amico (@TDOttawa)
It's getting more and more difficult to spot a fake photo online. Fortunately, these Google tools can help you tell the difference between a fake and a real image.
Via Philou49
En plein débat sur la surexposition des jeunes aux écrans, The Phone, qui sortira cet été, propose une solution radicale
Via cdi
Quelle est la consommation d'une requête sur ChatGPT ? Combien de CO2 est émis pour générer une image avec une IA ? J'ai compilé toutes les données concrètesà disposition pour mieux cerner les enjeux et les usages.
Via Bruno Renkin
|



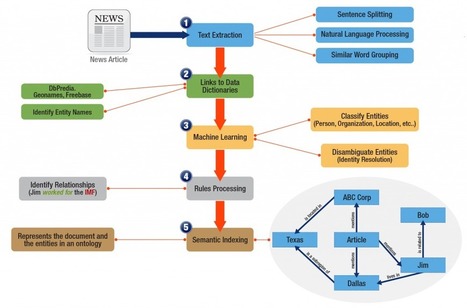


































Semantic pipelines allow for the identification, extraction, classification and storage of semantic knowledge creating a knowledge base of all your data. Most organizations have struggled to create these pipelines primarily because the plumbing hasn't existed. But now it does.
This post discusses how free flowing text streams into graph databases using concept extraction processes. A well coordinated feed of data is written to the underlying graph database while updates are tracked on a continuous basis to ensure database integrity.
Other important pipeline plumbing includes tools for disambiguation (used to resolve the definition of entities inside the text), classification of the entities, structuring relationships between entities and determining sentiment.
Organizations that deploy well functioning semantic pipelines have an added advantage over their competitors. They have instant access to a completed knowledge base of data. Research functions spend less time searching and more time analyzing. Alerting notifies critical business functions to take immediate action. Service levels are improved using accurate, well structured responses. Sentiment is detected allowing more time to react to changing market conditions.
In general, the REST Client API calls out a GATE-based annotation pipeline and sends back enriched data in RDF form. Organizations typically customize these pipelines which consist of any GATE-developed set of text mining algorithms for scoring, machine learning, disambiguation or any of the other wide range of text mining techniques.
It is important to note that these text mining pipelines create RDF in a linear fashion and feed GraphDB™. Once the RDF is enriched in this fashion and stored in the database, these annotations can then be modified, edited or removed. This is particularly useful when integrating with Linked Open Data (LOD) sources. Updates to the database are populated automatically when the source information changes.
For example, let’s say your text mining pipeline is referencing Freebase as its Linked Open Data source for organization names. If an organization name changes or a new subsidiary is announced in Freebase, this information will be updated as reference-able metadata in GraphDB™.
In addition, this tightly-coupled integration includes a suite of enterprise-grade APIs, the core of which is the Concept Extraction API. This API consists of a Coordinator and Entity Update Feed. Here’s what they do:
Other APIs include Document Classification, Disambiguation, Machine Learning, Sentiment Analysis & Relation Extraction. Together, this complete set of technology allows for tight integration and accurate processing of text while efficiently storing resulting RDF statements in GraphDB™.
As mentioned, the value of this tightly-coupled integration is in the rich metadata and relationships which can now be derived from the underlying RDF database. It’s this metadata that powers high performance search and discovery or website applications – results are compete, accurate and instantaneous.
- See more at: http://www.ontotext.com/text-mining-triplestores-full-semantic-circle/#sthash.fg1RVcQN.dpufIn general, the REST Client API calls out a GATE-based annotation pipeline and sends back enriched data in RDF form. Organizations typically customize these pipelines which consist of any GATE-developed set of text mining algorithms for scoring, machine learning, disambiguation or any of the other wide range of text mining techniques.
It is important to note that these text mining pipelines create RDF in a linear fashion and feed GraphDB™. Once the RDF is enriched in this fashion and stored in the database, these annotations can then be modified, edited or removed. This is particularly useful when integrating with Linked Open Data (LOD) sources. Updates to the database are populated automatically when the source information changes.
For example, let’s say your text mining pipeline is referencing Freebase as its Linked Open Data source for organization names. If an organization name changes or a new subsidiary is announced in Freebase, this information will be updated as reference-able metadata in GraphDB™.
In addition, this tightly-coupled integration includes a suite of enterprise-grade APIs, the core of which is the Concept Extraction API. This API consists of a Coordinator and Entity Update Feed. Here’s what they do:
Other APIs include Document Classification, Disambiguation, Machine Learning, Sentiment Analysis & Relation Extraction. Together, this complete set of technology allows for tight integration and accurate processing of text while efficiently storing resulting RDF statements in GraphDB™.
As mentioned, the value of this tightly-coupled integration is in the rich metadata and relationships which can now be derived from the underlying RDF database. It’s this metadata that powers high performance search and discovery or website applications – results are compete, accurate and instantaneous.
- See more at: http://www.ontotext.com/text-mining-triplestores-full-semantic-circle/#sthash.fg1RVcQN.dpuf