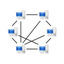



A recent email thread on the Riak users mailing list highlighted one of the key weaknesses of distributed systems: clock consistency.
The first email:
"Occasionally, riak seems to not store an object I try to save. I have run tcpdump on the node receiving the request to ensure it is receiving the http packets with the correct JSON from the client. When the issue occurs the node is in fact receiving the request with the correct JSON."
Riak is designed to accommodate server and network failures without ever losing committed writes, so this led to a quick response from Basho’s engineers.
After some discussion, a vital piece of information was revealed:
"One other thing that might be worth mentioning here is the writes I’m mentioning are actually updates to existing objects. The object exists, an attempt to write an update for the object appears to be received by a node, but the object maintains it’s original value."
Riak was dropping updates rather than writes, which is a horse of a different color. To see why updates are much more problematic for any distributed database, read on.
[...]


 Your new post is loading...
Your new post is loading...
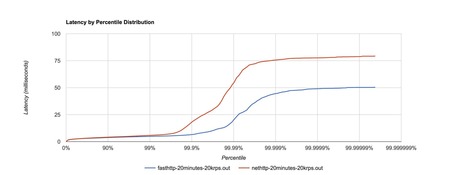




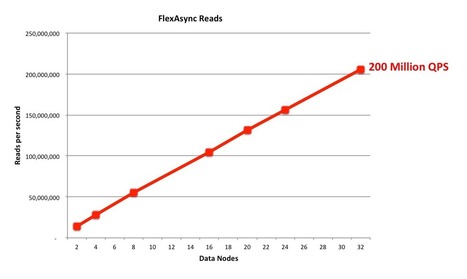

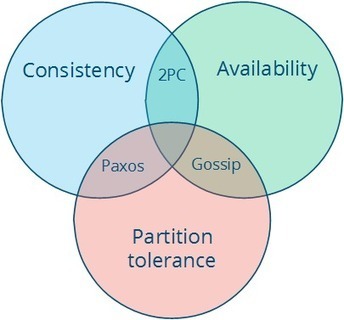

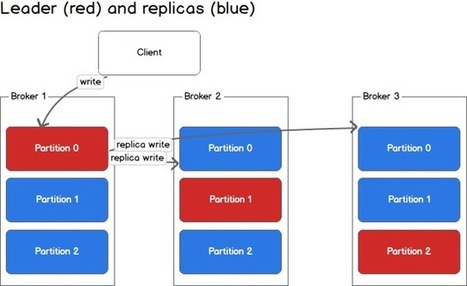







A nice list of ways to ensure data consistency, from the simplest Last Write Win, to the self-healing CRDT