

Spark SQL is currently an Alpha component. Therefore, the APIs may be changed in future releases.
OverviewGetting StartedRunning SQL on RDDsUsing ParquetWriting Language-Integrated Relational QueriesHive SupportGet Started for FREE
Sign up with Facebook Sign up with X
I don't have a Facebook or a X account

 Your new post is loading...
Your new post is loading... Your new post is loading...
Your new post is loading...
Spark SQL is currently an Alpha component. Therefore, the APIs may be changed in future releases. OverviewGetting StartedRunning SQL on RDDsUsing ParquetWriting Language-Integrated Relational QueriesHive Support
No comment yet.
Sign up to comment

As Twitter has grown into a global platform for public self-expression and conversation, our storage requirements have grown too. Over the last few years, we found ourselves in need of a storage system that could serve millions of queries per second, with extremely low latency in a real-time environment. Availability and speed of the system became the utmost important factor. Not only did it need to be fast; it needed to be scalable across several regions around the world.

From
gigaom

The Apache Mahout project will now support Apache Spark and another data engine called H20 as it tries to retain its status as the go-to set of machine learning libraries for Hadoop.
Nico's insight:
Mahout on Spark, that's good news!

A question that many developers often ask is, “Can I make it run faster?” But what are you looking at to make it faster? The code? The network? Alan explores what you need to tune answer the question: what is Hadoop's Network Performance?

Elasticsearch easily lets you develop amazing things, and it has gone to great lengths to make Lucene's features readily available in a distributed setting. However, when it comes to running Elasticsearch in production, you still have a fairly complicated system on your hands: a system with high demands on network stability, a huge appetite for memory, and a system that assumes all users are trustworthy. These articles cover some of the lessons we've learned from securing and herding hundreds of Elasticsearch clusters.
Nico's insight:
The first article I read which is describing quite accurately the distributed characteristics of elasticsearch. Another good article of them: https://www.found.no/foundation/elasticsearch-as-nosql/

Apache Helix is a generic cluster management framework used for the automatic management of partitioned, replicated and distributed resources hosted on a cluster of nodes. Helix automates reassignment of resources in the face of node failure and recovery, cluster expansion, and reconfiguration.
Nico's insight:
Based on Zookeeper, it seems to implement the usual schemes of clusters. There is a nice list of recipes:
And it seems nicely build: there no master xml stuff to write, it's just plain java; see for instance the state machine config. This project seems young though.

Yesterday, Steven Schuurman announced our latest product, Marvel. Judging by the twitter storm alone, people are just as excited about it as we are. Today, I would like to take the opportunity to tell more about how it works and how it came to be. Marvel is the result of all of our experiences helping users and providing support to customers. Most importantly, the product has come from our own needs for its capabilities and insights. [...]
Nico's insight:
Marvel is the first actual monitoring tool of Elasticsearch, since it is not a client only plugin; data is collected even if you're not connected, like every actual monitoring tool.

"Today we are happy to announce that Hydra—the core of our data processing platform—is now open source and available on github. It’s freely available under the Apache License for anyone to use, and we look forward to seeing just what people do with it!"
Nico's insight:
An interesting distributed job manager, which is supporting sharding, with an interesting hierarchical data abstraction. It is Java based and involve Zookeeper and rabbitmq.

One of the features that is often available in Riak Client software (including the CorrguatedIron .NET Client, the riak-js client and others) is the ability to send requests to the Riak Cluster through a round robin style approach. What this means is each IP, of each node within the Riak Cluster is entered into a config file for the client. The client then goes through that list to send off requests to read, write or delete data in the database.
Nico's insight:
I don't agree with this article. For me the client is part of the cluster since it is from there where all of consistency, availibility and partition tolerence actually matter.
I noticed yarn is getting all this incredible press lately. I see articles with subjects I can not parse like yarn is hadoops data center os. A while back I took a slam at YARN, but periodically I like to re-investigate my rants and determine how right I was. [...]
Nico's insight:
After a very quick tour, I was not keen to look into it further. This article confirms my fear about this white elephant.

Presto is an open source distributed SQL query engine for running interactive analytic queries against data sources of all sizes ranging from gigabytes to petabytes. Presto was designed and written from the ground up for interactive analytics and approaches the speed of commercial data warehouses while scaling to the size of organizations like Facebook.
Nico's insight:
Yet another Hive-compatible in memory distributed query engine, this time by Facebook

Cloudera has partnered with a startup called Databricks to integrate and support the Apache Spark data-processing platform within Cloudera’s Hadoop software. Spark, which is designed for speed and usability, is one of several technologies pushing Hadoop beyond MapReduce.
Nico's insight:
Spark really seems the future of data processing
What is Raft?
Raft is a consensus algorithm that is designed to be easy to understand. It's equivalent to Paxos in fault-tolerance and performance. The difference is that it's decomposed into relatively independent subproblems, and it cleanly addresses all major pieces needed for practical systems. We hope Raft will make consensus available to a wider audience, and that this wider audience will be able to develop a variety of higher quality consensus-based systems than are available today. Where can I learn more? [...]
Nico's insight:
A good centralized place for everything about Raft
|

One of Spark’s main goals is to make big data applications easier to write. Spark has always had concise APIs in Scala and Python, but its Java API was verbose due to the lack of function expressions. With the addition of lambda expressions in Java 8, we’ve updated Spark’s API to transparently support these expressions, while staying compatible with old versions of Java. This new support will be available in Spark 1.0.
Nico's insight:
Yet another reason to get some time to test Spark.

ØMQ is a messaging system, or "message-oriented middleware" if you will. It is used in environments as diverse as financial services, game development, embedded systems, academic research, and aerospace. Messaging systems work basically as instant messaging for applications. An application decides to communicate an event to another application (or multiple applications), it assembles the data to be sent, hits the "send" button, and the messaging system takes care of the rest. Unlike instant messaging, though, messaging systems have no GUI and assume no human beings at the endpoints capable of intelligent intervention when something goes wrong. Messaging systems thus have to be both fault-tolerant and much faster than common instant messaging. ØMQ was originally conceived as an ultra-fast messaging system for stock trading and so the focus was on extreme optimization. The first year of the project was spent devising benchmarking methodology and trying to define an architecture that was as efficient as possible. Later on, approximately in the second year of development, the focus shifted to providing a generic system for building distributed applications and supporting arbitrary messaging patterns, various transport mechanisms, arbitrary language bindings, etc. During the third year, the focus was mainly on improving usability and flattening the learning curve. We adopted the BSD Sockets API, tried to clean up the semantics of individual messaging patterns, and so on. This article will give insight into how the three goals above translated into the internal architecture of ØMQ, and provide some tips for those who are struggling with the same problems. Since its third year, ØMQ has outgrown its codebase; there is an initiative to standardize the wire protocols it uses, and an experimental implementation of a ØMQ-like messaging system inside the Linux kernel, etc. These topics are not covered here. However, you can check online resources for further details.
Nico's insight:
I love the first paragraph about "Application vs. Library": "The lesson learned is that when starting a new project, you should opt for the library design if at all possible. It's pretty easy to create an application from a library by invoking it from a trivial program; however, it's almost impossible to create a library from an existing executable. A library offers much more flexibility to the users, at the same time sparing them non-trivial administrative effort." big big big +1. My life of integrator would a lot more easier.

"It would be great in my opinion if Hazelcast had a way to configure a "hazelcast.cluster.majority.size" similar to the "hazelcast.initial.min.cluster.size" that would cause an instance to go dormant when the cluster size dropped below the configured threshold (generally n/2+1). I wrote something into my software that does this to prevent unfortunate side-effects of partitioning with the way I am using HC but would much rather it was part of the core. Personally I would be perfectly happy if all operations blocked when the configured number of nodes were no longer reachable."
Nico's insight:
I found it weird that a distributed system doesn"t implement that simple feature which would avoid the worst state of a distributed cluster : a split brain. At Sccop.it we still use it, but we had to add additional checks so we don't use it when not enough nodes are up.
Today we are proud to announce the release of Elasticsearch 1.0.0 GA, based on Lucene 4.6.1. This release is the culmination of 9 months of work with almost 8,000 commits by 183 contributors! A big thank you to everybody who has made this release possible. You can download Elasticsearch 1.0.0 here. The main features available in 1.0 are:
Nico's insight:
I cannot wait to finally be able to do snapshot/restore of indices. Great job guys !

A recent email thread on the Riak users mailing list highlighted one of the key weaknesses of distributed systems: clock consistency. The first email: "Occasionally, riak seems to not store an object I try to save. I have run tcpdump on the node receiving the request to ensure it is receiving the http packets with the correct JSON from the client. When the issue occurs the node is in fact receiving the request with the correct JSON." Riak is designed to accommodate server and network failures without ever losing committed writes, so this led to a quick response from Basho’s engineers. After some discussion, a vital piece of information was revealed: "One other thing that might be worth mentioning here is the writes I’m mentioning are actually updates to existing objects. The object exists, an attempt to write an update for the object appears to be received by a node, but the object maintains it’s original value." Riak was dropping updates rather than writes, which is a horse of a different color. To see why updates are much more problematic for any distributed database, read on. [...]
Nico's insight:
A nice list of ways to ensure data consistency, from the simplest Last Write Win, to the self-healing CRDT
There is a lot of hype around distributed data systems, some of it justified. It’s true that the internet has centralized a lot of computation onto services like Google, Facebook, Twitter, LinkedIn (my own employer), and other large web sites. It’s true that this centralization puts a lot of pressure on system scalability for these companies. Its true that incremental and horizontal scalability is a deep feature that requires redesign from the ground up and can’t be added incrementally to existing products. It’s true that, if properly designed, these systems can be run with no planned downtime or maintenance intervals in a way that traditional storage systems make harder. It’s also true that software that is explicitly designed to deal with machine failures is a very different thing from traditional infrastructure. All of these properties are critical to large web companies, and are what drove the adoption of horizontally scalable systems like Hadoop, Cassandra, Voldemort, etc. I was the original author of Voldemort and have worked on distributed infrastructure for the last four years or so. So in-so-far as there is a “big data” debate, I am firmly in the “pro-” camp. But one thing you often hear is that this kind of software is more reliable than the traditional alternatives it replaces, and this just isn’t true. It is time people talked honestly about this. You hear this assumption of reliability everywhere. Now that scalable data infrastructure has a marketing presence, it has really gotten bad. Hadoop or Cassandra or what-have-you can tolerate machine failures then they must be unbreakable right? Wrong. [...]
Nico's insight:
Nice reminder: - availability doesn't only depends on the quality of the software, it also depends on the quality of the ops, - and the probability of most of your nodes going down is not that unlikely, since machine clones will fail on the same bug

At Chartbeat we are thinking about adding probabilistic counters to our infrastructure, HyperLogLog (HLL) in particular. One of the challenges with something like this is to make it redundant and have somewhat good performance. Since HyperLogLog is a relatively new approach to cardinality approximation there are not many off the shelf solutions, so why not try and implement HLL in Cassandra? [...]
Nico's insight:
Having HLL in Cassandra would be awesome
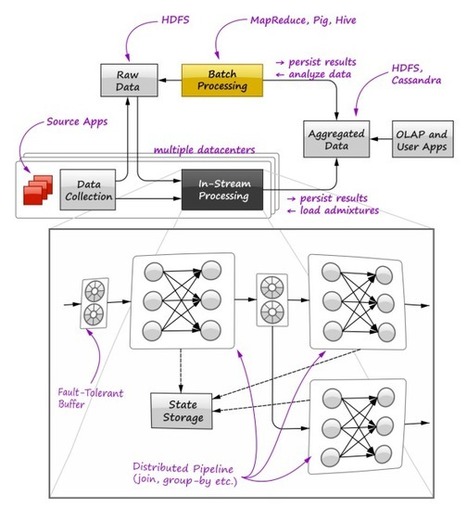
The shortcomings and drawbacks of batch-oriented data processing were widely recognized by the Big Data community quite a long time ago. It became clear that real-time query processing and in-stream processing is the immediate need in many practical applications. In recent years, this idea got a lot of traction and a whole bunch of solutions like Twitter’s Storm, Yahoo’s S4, Cloudera’s Impala, Apache Spark, and Apache Tez appeared and joined the army of Big Data and NoSQL systems. This article is an effort to explore techniques used by developers of in-stream data processing systems, trace the connections of these techniques to massive batch processing and OLTP/OLAP databases, and discuss how one unified query engine can support in-stream, batch, and OLAP processing at the same time.
Nico's insight:
Very good data processing 101.

Snakebite is a python library that provides a pure python HDFS client and a wrapper around Hadoops minicluster. The client uses protobuf for communicating with the NameNode and comes in the form of a library and a command line interface. Currently, the snakebite client supports most actions that involve the Namenode and reading data from DataNodes. Note: all methods that read data from a data node are able to check the CRC during transfer, but this is disabled by default because of performance reasons. This is the opposite behaviour from the stock Hadoop client. Snakebite requires python2 (python3 is not supported yet) and python-protobuf 2.4.1 or higher. Snakebite has been tested mainly against Cloudera CDH4.1.3 (hadoop 2.0.0) in production. Tests pass on HortonWorks HDP 2.0.3.22-alpha
From
devo
While devo.ps is fast approaching a public release, the team has been dealing with an increasingly complex infrastructure. We more recently faced an interesting issue; how do you share configuration across a cluster of servers? More importantly, how do you do so in a resilient, secure, easily deployable and speedy fashion? That’s what got us to evaluate some of the options available out there; ZooKeeper, Doozer and etcd. These tools all solve similar sets of problems but their approach differ quite significantly. Since we spent some time evaluating them, we thought we’d share our findings.

We've all been there - we started to plan for an elasticsearch cluster and one of the first questions that comes up is "How many nodes should the cluster have?". As I'm sure you already know, the answer to that question depends on a lot of factors, like expected load, data size, hardware etc. In this blog post I'm not going to go into the detail of how to size your cluster, but instead will talk about something equally important - how to avoid the split-brain problem.
|



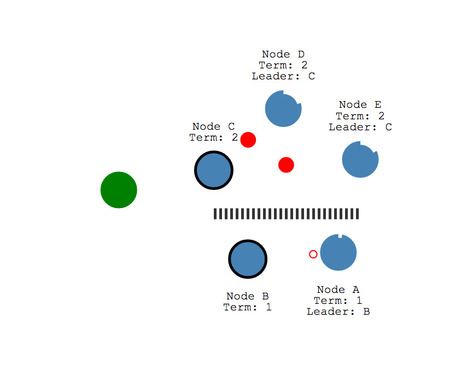


Even if it's quite basic, this seems a lot more fun than manipulating data with Hive