From
vimeo

 Your new post is loading...
Your new post is loading... Your new post is loading...
Your new post is loading...
Recently our team has been tasked to write a very fast cache service. The goal was pretty clear but possible to achieve in many ways. Finally we decided to try something new and implement the service in Go. We have described how we did it and what values come from that.

This is a story of how my understanding about messaging with RabbitMQ evolved from ignorant to usable while hitting my head into the walls of the CAP theorem. I hope it will save some time for someone out there.
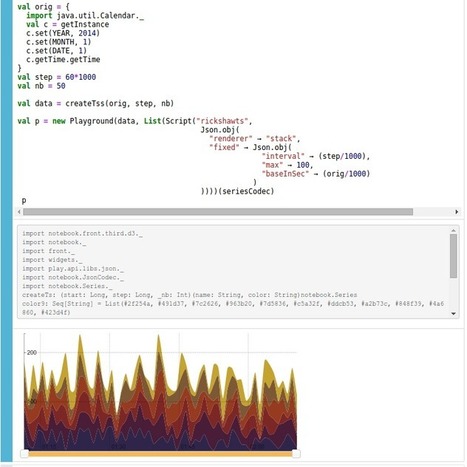
The main intent of this tool is to create reproducible analysis using Scala, Apache Spark and more. This is achieved through an interactive web-based editor that can combine Scala code, SQL queries, Markup or even JavaScript in a collaborative manner. The usage of Spark comes out of the box, and is simply enabled by the implicit variable named sparkContext.
Nico's insight:
interactiveness is essential is data mining

It is a few months that I spend ~ 15-20% of my time, mostly hours stolen to nights and weekends, working to a new system. It’s a message broker and it’s called Disque. I’ve an implementation of 80% of what was in the original specification, but still I don’t feel like it’s ready to be released. Since I can’t ship, I’ll at least blog… so that’s the story of how it started and a few details about what it is.
Nico's insight:
The author of Redis is working on a message broker. Very clear and detailed specs, but not yet available to be tested.
From
github
Stream-Framework - Stream Framework is a Python library, which allows you to build newsfeed and notification systems using Cassandra and/or Redis.
Nico's insight:
Merging stream can be complex at scale, this framework seems to tackle it. The SAAS version is here: http://getstream.io/
Here's a Raft cluster running in your browser. You can interact with it to see Raft in action. Five servers are shown on the left, and their logs are shown on the right. We hope to create a screencast soon to explain what's going on. This visualization (RaftScope) is still pretty rough around the edges; pull requests would be very welcome.
Nico's insight:
Awesome interactive chart of the Raft Algorithm
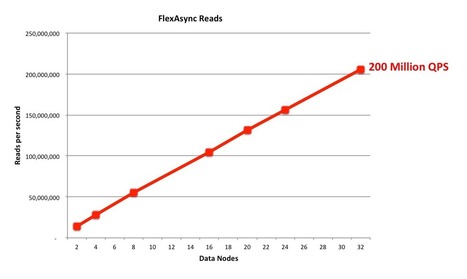
By courtesy of Intel we had access to a very large cluster of Intel servers for a few weeks. We took the opportunity to see the improvements of the Intel servers in the new Haswell implementation on the Intel Xeon chips. We also took the opportunity to see how far we can now scale flexAsynch, the NoSQL benchmark we've developed for testing MySQL Cluster.
Nico's insight:
Very impressive ! While mongodb has discover compression, MySql optimisation is about packet aggregation on the wire

At Toushay, we ran into a tricky issue. Our customers were noticing that, very rarely, their ‘digital signage’ playlists were being subtly corrupted. After our customers had been moving items around in the list, things would go awry. Sometimes an image would be lost, other times one would be duplicated. It happened only a few times, and in each case we were able to manually correct it. But it was very painful for them when it did.
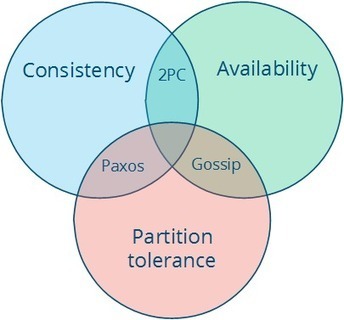
I wanted a text that would bring together the ideas behind many of the more recent distributed systems - systems such as Amazon's Dynamo, Google's BigTable and MapReduce, Apache's Hadoop and so on. In this text I've tried to provide a more accessible introduction to distributed systems. To me, that means two things: introducing the key concepts that you will need in order to have a good timereading more serious texts, and providing a narrative that covers things in enough detail that you get a gist of what's going on without getting stuck on details. It's 2013, you've got the Internet, and you can selectively read more about the topics you find most interesting. In my view, much of distributed programming is about dealing with the implications of two consequences of distribution:
In other words, that the core of distributed programming is dealing with distance (duh!) and having more than one thing (duh!). These constraints define a space of possible system designs, and my hope is that after reading this you'll have a better sense of how distance, time and consistency models interact. This text is focused on distributed programming and systems concepts you'll need to understand commercial systems in the data center. It would be madness to attempt to cover everything. You'll learn many key protocols and algorithms (covering, for example, many of the most cited papers in the discipline), including some new exciting ways to look at eventual consistency that haven't still made it into college textbooks - such as CRDTs and the CALM theorem.
Firefox Hello is this cool WebRTC app we've landed in Firefox to let you video chat with friends. You should try it, it's amazing. My team was in charge of the server side of this project - which consists of a few APIs that keep track of some session information like the list of the rooms and such things. The project was not hard to scale since the real work is done in the background by Tokbox - who provide all the firewall traversal infrastructure. If you are curious about the reasons we need all those server-side bits for a peer-2-peer technology, this article is great to get the whole picture: http://www.html5rocks.com/en/tutorials/webrtc/infrastructure/ One thing we wanted to avoid is a huge peak of load on our servers on Firefox release day. While we've done a lot of load testing, there are so many interacting services that it's quite hard to be 100% confident. Potentially going from 0 to millions of users in a single day is... scary ? :) So right now only 10% of our user base sees the Hello button. You can bypass this by tweaking a few prefs, as explained in many places on the web. This percent is going to be gradually increased so our whole user base can use Hello. How does it work ? When you start Firefox, a random number is generated. Then Firefox ask our service for another number. If the generated number is inferior to the number sent by the server, the Hello button is displayed. If is superior, the button is hidden. Adam Roach proposed to set up an HTTP endpoint on our server to send back the number and after a team meeting I suggested to use a DNS lookup instead. [...]
A month ago, we shared with you our entry to the 2014 Gray Sort competition, a 3rd-party benchmark measuring how fast a system can sort 100 TB of data (1 trillion records). Today, we are happy to announce that our entry has been reviewed by the benchmark committee and we have officially won the Daytona GraySort contest! In case you missed our earlier blog post, using Spark on 206 EC2 machines, we sorted 100 TB of data on disk in 23 minutes. In comparison, the previous world record set by Hadoop MapReduce used 2100 machines and took 72 minutes. This means that Spark sorted the same data 3X faster using 10X fewer machines. All the sorting took place on disk (HDFS), without using Spark’s in-memory cache. This entry tied with a UCSD research team building high performance systems and we jointly set a new world record.

We’ve started running game day exercises at Stripe. During a recent game day, we tested failing over a Redis cluster by running kill -9 on its primary node [0], and ended up losing all data in the cluster. We were very surprised by this, but grateful to have found the problem in testing. This result and others from this exercise convinced us that game days like these are quite valuable, and we would highly recommend them for others.
|
This article describes a proper way to handle (asynchronously) a long-running job creation in the RESTful API.
Does TCP not meet your required latency consistently? Is UDP not reliable enough? Do you need to multicast? What about flow control, congestion control, and a means to avoid head of line blocking that can be integrated with the application? Or perhaps you’re just fascinated by how to design for the cutting edge of performance? Maybe you have tried higher level messaging products and found they are way too complicated because of the feature bloat driven by product marketing cycles.

Matt Ranney, Chief Systems Architect at Uber, gave an overview of their dispatch system, responsible for matching Uber's drivers and riders. Ranney explained the driving forces that led to a rewrite of this system. He described the architectural principles that underpin it, several of the algorithms implemented and why Uber decided to design and implement their own RPC protocol. The old dispatch system was designed for private transportation (1 driver, 1 vehicle, 1 rider) and built around the concept of moving people, but Uber wants to enter new markets, such as goods transportation. Uber also sharded its data by city. As Uber grew and expanded to ever more cities, some of them quite big, it became difficult to manage its data. Finally, the dispatch system had multiple points of failure, a consequence of Uber's hectic growth and the system's scramble to keep up with that growth. [...] To achieve that kind of scale, Uber chose to use Google's S2 Geometry Library. S2 is able to split a sphere into cells, each with an id. The Earth is roughly spherical, so S2 can represent each square centimeter of it with a 64-bit integer. S2 has two important properties for Uber: it is possible to define each cell's resolution and it is possible to find the cells that cover a given area. Uber uses 3,31 km2 cells to shard its data. All this new data enables Uber to reduce wait times, extra driving by partners and the overall estimated times to arrival (ETA). So, what happens when a rider wants to use Uber? Uber uses the rider location and S2's area coverage function to look for drivers that can be matched with a rider. Uber then chooses the shortest ETA, taking into account not only the drivers who are available, but also those that will become available in time to pick up the rider.
Nico's insight:
Using the S2 Geometry Library to shard the earth, that's smart !
In January we migrated our entire infrastructure from dedicated servers in Germany to EC2 in the US. The migration included a wide variety of components, web workers, background task workers, RabbitMQ, Postgresql, Redis, Memcached and our Cassandra cluster. Our main requirement was to execute this migration without downtime. This article covers the migration of our Cassandra cluster. If you’ve never run a Cassandra migration before, you’ll be surprised to see how easy this is. We were able to migrate Cassandra with zero downtime using its awesome multi-data center support. Cassandra allows you to distribute your data in such a way that a complete set of data is guaranteed to be placed on every logical group of nodes (eg. nodes that are on the same data-center, rack, or EC2 regions...). This feature is a perfect fit for migrating data from one data-center to another. Let’s start by introducing the basics of a Cassandra multi-datacenter deployment. [...]
Nico's insight:
Being able to be multi data center is great, migrating quite simply is even better
Nico's insight:
Old paper, but still puts into perspective the trendy event-based architectures flourishing here and there. Threads are today avoided in preference for event based architecture not because of new kind of use cases, but due to not enough performant implementation.
Many companies use ZooKeeper for service discovery. At Knewton, we believe this is a fundamentally flawed approach. In this article, I will walk through our failures with ZooKeeper, tell you why you shouldn’t be using it for service discovery, and explain why Eureka is a better solution.
At Artisan, we’ve processed billions of analytics events. Our infrastructure pipeline digesting this steady stream of data is complex yet nimble and performant. Collecting and extracting the data contained in these events in a manner that enables our customers to leverage it, immediately, is paramount. This post focuses on one small facet of that subsystem, our use of Redis Pipelining and Scripting. Redis is a critical data store used across our stack. Its read and write latencies are impressive, and we take full advantage of it. Every millisecond we’re able shave off in the process of sifting data adds value. To this point, where applicable, we leverage pipelining.

pg_shard is a sharding extension for PostgreSQL. It shards and replicates your PostgreSQL tables for horizontal scale and high availability. The extension also seamlessly distributes your SQL statements, without requiring any changes to your application. As a standalone extension, pg_shard addresses many NoSQL use cases. It also enables real-time analytics, and has an easy upgrade path to CitusDB for complex analytical workloads (distributed joins). Further, the extension provides access to standard SQL tools, and powerful PostgreSQL features, such as diverse set of indexes and semi-structured data types.
Last week, there was a good discussion on lobste.rs about why exactly-once messaging is not possible. The discussion was kicked off with a link to a paper from Patel et al titled Towards In-Order and Exactly-Once Delivery using Hierarchical Distributed Message Queues, which claims to contribute: ... a highly scalable distributed queue service using hierarchical architecture that supports exactly once delivery, message order, large message size, and message resilience. I haven't evaluated the author's other claims in detail, but the claim of exactly once delivery caught my eye. There is no chance of getting two get requests for the same message. When a HTTP message request comes in, a message is sent through HTTP response and the message is deleted at the same time. While I'm not fully satisfied about their at the same time, they don't seem to be claiming to break any fundamental laws here. What I do feel is fundamental, though, is that this definition of exactly once delivery isn't the one that most systems builders would find useful. The effect that most people are interested in is actually exactly-once processing: a message having a particularly side-effect exactly once per message. [...]
Nico's insight:
"End-to-end system semantics matter much more than the semantics of an individual building block" So true, always look at consistencies and availability from the end user point of view.
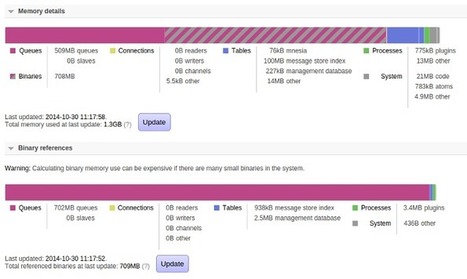
"How much memory is my queue using?" That's an easy question to ask, and a somewhat more complicated one to answer. RabbitMQ 3.4 gives you a clearer view of how queues use memory. This blog post talks a bit about that, and also explains queue memory use in general.
Nico's insight:
A good monitoring is as important as the software itself. And rabbitmq's one is quite a good one, for the little I played with it
|