

Sequence matching algorithms such as BLAST and FASTA have been widely used in searching for evolutionary origin and biological functions of newly discovered nucleic acid and protein sequences. As parts of these search tools, alignment scores and E values are useful indicators of the quality of search results (and the relevance of the matches) from querying a database of annotated sequences, whereby a high alignment score (and inversely a low E value) reflects significant similarity between the query and the subject (target) sequences. For cross-comparison of results from sufficiently different queries, however, the interpretation of alignment score as a similarity measure and E value a dissimilarity measure becomes somewhat nuanced, and prompts herein a judicious distinction of different types of similarity. Via a simulated formulation, we show that an adjustment of E value to account for self-matching of query and subject sequences corrects for certain ostensibly anomalous similarity comparisons, resulting in “regularized” dissimilarity and similarity measures that would be more appropriate for cross-comparisons, as well as database applications, such as all-on-all sequence alignment or selection of diverse subsets. In actual practice, the “regularization” of E value dissimilarity improves clustering and subset selection. While both E value and the “regularized” E value share two of the four axiomatic properties of a metric space, positivity, and symmetry, the latter E value further becomes reflexive and meets the condition of triangle inequality, the remaining two axioms, thus itself an appropriate distance function for metricating protein sequence space.

RMH
77.5K views |
+41 today

 Your new post is loading... Your new post is loading...

From
link

The increasing discharge of synthetic dyes from industrial effluents, particularly Reactive Blue 19 (RB19) and Malachite Green (MG), poses serious environmental and health concerns due to their persistence, toxicity, and resistance to conventional treatment processes. This study evaluates the potential of immobilized dead fungal biomass as a sustainable, cost-effective, and reusable biosorbent for the adsorption and desorption of RB19 and MG in aqueous systems. Four fungal species, Aspergillus niger, Aspergillus terreus, Rhizopus arrhizus, and Penicillium citrinum were investigated under varying operational parameters, including biomass dosage, initial dye concentration, particle size, contact time, and adsorption stability over six successive cycles. At an initial concentration of 100 ppm MG, P. citrinum exhibited the highest removal efficiency (84.61 ± 2.32%), whereas A. terreus achieved the maximum removal efficiency for RB19 (71.06 ± 0.30%) at 300 ppm. At the different incubation time study, in MG, A. niger shown maximum removal efficiency (96.18 ± 0.02%) at 150 min incubation time, and in RB19, the maximum removal efficiency was obtained by R. arrhizus (83.21 ± 0.3%), at 150 min duration. With the parameter of particle size, the removal efficiency is 0.14 μm in both MG and RB19 dye solution, i.e. R. arrhizus, i.e. 80.42 ± 0.31% and 89.23 ± 1.6% respectively. Structural and surface characterization using FTIR and SEM-EDX confirmed the involvement of key functional groups and surface heterogeneity in dye binding. Kinetic analyses demonstrated that adsorption of both dyes followed a pseudo-second-order model, indicating chemisorption as the dominant rate-controlling mechanism. Equilibrium studies showed that the Langmuir isotherm best described the adsorption behaviour, with high correlation coefficients (R² = 0.957–0.999) across different dye-biomass systems. Overall, the results highlight the strong potential of immobilized dead fungal biomass as an efficient, reusable, and environmentally benign biosorbent, with practical relevance for biotechnological applications in dye-laden wastewater remediation. 

From
www
Bacillus velezensis is a widely used plant growth-promoting rhizobacterium whose effectiveness under natural conditions is strongly influenced by interactions with surrounding microorganisms. While bacterial secondary metabolites are known to shape these interactions, little is known about their long-term evolutionary consequences. Here, we show that repeated exposure of B. velezensis GA1 to secondary metabolites produced by the competing rhizobacterium Pseudomonas sessilinigenes CMR12a drives the emergence of an adapted subpopulation with enhanced ecological fitness. Multi-omics analyses revealed extensive metabolomic and transcriptional changes associated with altered growth dynamics, sporulation, motility, and biofilm formation. Importantly, the evolved variant exhibited improved tomato root colonization and reduced the abundance of the competing Pseudomonas strain in planta. Together, our results demonstrate that prolonged exposure to diffusible bacterial metabolites can drive rapid adaptive diversification in rhizosphere-associated bacteria and highlight the importance of long-term interbacterial interactions in shaping the outcome of plant microbiome assembly and biocontrol performance.

This review critically evaluates how structural biology has enabled interface-informed engineering of plant–microbe interactions, with a clear emphasis on the relative maturity of plant–pathogen research compared with symbiosis engineering. In plant immunity, atomic resolution structures of apoplastic receptors, host targets, and intracellular nucleotide-binding leucine-rich repeat receptors (NLRs) were already translated into concrete engineering strategies, including altered effector recognition, expansion of specificity, effector-insensitive host variants, and mitigation of autoimmune phenotypes. These studies collectively demonstrate that structure-guided approaches can move beyond descriptive insight to predictive and functional receptor design. Meanwhile, the rapidly accumulating structural information on symbiosis-related receptors, signaling components, and nutrient-sensing pathways indicates that engineering of symbiosis is an emerging new frontier. Structures of LysM receptors, symbiotic co-receptors, calcium channels, transcriptional regulators, and hormone receptors reveal mechanistic parallels to immune signaling, including ligand discrimination, allosteric activation, and signal integration. The manuscript argues that symbiosis engineering can explicitly draw on conceptual and methodological templates established in pathogen resistance, such as interface remodeling, domain swapping, gain-of-function channel variants, and regulatory buffering to avoid deleterious outcomes. By juxtaposing these two fields, the review identifies transferable design principles and current limitations, and outlines how lessons from structure-guided immunity engineering may accelerate rational manipulation of beneficial plant–microbe interactions for sustainable crop improvement.
mhryu@live.com's insight:
2st

From
www
DNA methylation is a critical epigenetic mark across numerous species, and identifying differentially methylated regions (DMRs) is essential for understanding genome regulation. Most existing DMR detection methods require predefined sample conditions, limiting the discovery of new epigenetic patterns, especially when group identities are unknown or uncertain, as is common in clinical settings. Additionally, only a very few approaches enable comparisons across multiple conditions. To address this significant gap, we present metilene3, a method for rapid, multi-condition DMR detection that operates in both supervised and unsupervised modes, using user-provided labels or autonomously clustering unlabeled samples. By segmenting the genome based on multiple pairwise methylation difference signals, metilene3 enables sample classification and DMR-anchored inference of epigenetic relationships. Using simulated and diverse human datasets, we show that metilene3 accurately detects DMRs, robustly clusters samples, and holds the potential to reveal new regulatory elements and sample stratifications. Specifically, in a pancreatic tissue dataset, metilene3 identifies DMRs enriched for key transcription factors involved in pancreatic cancer development, hinting towards an altered NFKB-NFAT regulatory program. Together, metilene3 provides a fast, interpretable framework for exploring heterogeneous methylomes and discovering epigenetic patterns across complex biological and clinical datasets. Differentially methylated regions (DMRs) play a central role in development and disease. Here, the authors present metilene3, a methylation analysis tool that identifies DMRs in multi-group and unsupervised settings, enabling the discovery of biologically meaningful sample groups from DMR profiles.
Engineering tumor-homing bacteria as membrane-anchored immune checkpoint-blockade interfaces | brvbe
From
www
Bacterial cancer therapies can exploit tumor tropism to localize immunomodulatory payloads, but most approaches rely on secretion or lysis-dependent release of soluble biologics that may diffuse beyond the tumor niche. Here, we engineer non-pathogenic, tumor-homing E. coli strains as membrane-anchored immunotherapeutic interfaces, with individual strains displaying immune checkpoint-blocking nanobodies targeting CTLA-4 or PD-L1, either alone or in combination with a separate strain displaying murine decoy-resistant IL-18 (mDR18). By screening multiple bacterial outer-membrane proteins as scaffolds, we identified scaffold-dependent differences in display levels and target engagement, and YiaT as a functional platform for checkpoint nanobody presentation. Delivery of YiaT-displayed nanobodies in combination with OmpA-displayed mDR18 suppressed tumor growth in syngeneic mouse colon cancer and melanoma models in either local or systemic delivery. Upon systemic administration, the combined bacterial therapy preferentially accumulated in tumors, outperformed benchmark checkpoint antibody regimens combining CTLA-4 and PD-L1 under the tested conditions, and promoted tumor rejection and rechallenge resistance, without inducing broad systemic cytokine release. Further immune profiling showed that the combined treatment was associated with increased CD8⁺ and effector-memory T-cell responses in tumors and spleens. This work establishes bacterial surface display as a modular strategy for localized cancer immunotherapy.
mhryu@live.com's insight:
surface display

From
www
Genome size varies widely across eukaryotes, largely because of differences in non-coding DNA, but the physiological consequences of this variation remain unclear. To directly test how non-coding DNA abundance influences cellular physiology, we engineered a scalable genome-expansion system in the budding yeast S. cerevisiae that increases genome size while leaving the endogenous genome unchanged. By sequentially fusing yeast artificial chromosomes (YACs) carrying predominantly non-coding human DNA, we generated strains with up to 12.8 Mb of additional DNA, approximately doubling the native genome. Genome expansion reduced growth rate and increased cell size in proportion to the amount of non-coding DNA. Spike-in-normalized RNA-seq and ChIP-seq revealed that the non-coding DNA is pervasively transcribed, with a proportional amount of RNA polymerase II being redistributed from the endogenous genome to the added non-coding sequences. This resulted in a global decrease in the endogenous mRNA concentration. However, ribosome profiling and proteomics experiments revealed that there is little translation of YAC-associated transcripts. Our mathematical model shows that cellular growth rate decreases because non-coding DNA acts as a sink for transcriptional resources to lower the concentration of endogenous mRNA. Thus, our work links genome expansion to proliferative capacity and offers a mechanistic explanation for why the fastest-growing cells, such as yeast and bacteria, carry so little non-coding DNA.
mhryu@live.com's insight:
1str

From
www
The immune system uses paracrine signaling to spatially confine potent responses such as inflammation. A bio-orthogonal synthetic paracrine system could enable engineering of analogous multicellular circuits in which different cell types coordinate their functions in a spatially organized fashion. Here, using the plant hormone auxin as a bio-orthogonal chemical signal, we introduce programmable paracrine circuits that distribute sensing and effector functions to different cell types to spatially restrict responses in mouse xenografts. Cells engineered to express auxin biosynthetic genes generated auxin-dense regions with tunable length scales in vivo. This localized signaling ability enabled design of a multicellular sentinel-effector system, in which THP-1 sentinel cells conditionally produce auxin in regions expressing the tumor-specific antigen EGFRvIII, and Jurkat effector cells respond by locally modulating the activity of a chimeric antigen receptor (CAR). This two-cell type system was able to achieve localized activation of engineered effector cells in vivo. These results establish a foundation for engineering multicellular therapeutic systems that focus responses in specific tissue contexts or disease sites.
mhryu@live.com's insight:
elowitz. We first engineered auxin-producing cells that generate localized, dose-dependent paracrine signaling between CHO-K1 sender and receiver cells in mouse xenografts over scales of hundreds of microns to several millimeters. Using this signaling system, we designed an immune-inspired two-cell-type synthetic paracrine (“synthacrine”) circuit that links antigen sensing to an effector response. In this circuit, sentinel-like cells secrete auxin in response to a tumor-specific antigen, while engineered Jurkat cells permit CAR activity in response to auxin signaling. Remarkably, the two cell type system successfully restricted Jurkat activation to tumor regions in vivo. More generally, these results demonstrate how a bio-orthogonal paracrine communication channel can function predictably in vivo, providing a foundation for future spatially aware multicellular circuits that help focus therapeutic functions in complex tissue environments. This capability may also enable engineering of other multicellular, immune-like systems.

From
www
Methane is a potent greenhouse gas, nearly half of which is consumed anaerobically by anaerobic methanotrophic archaea (ANME) through methyl-coenzyme M reductase (Mcr). However, ANME cannot be grown as pure cultures, and obtaining active ANME Mcr in vitro remains extremely challenging, preventing previous efforts to engineer this key enzyme. Here, we used directed evolution in the methanogen Methanosarcina acetivorans to enhance ANME-1 Mcr (McrANME-1) activity for methane and carbon dioxide capture by selecting McrANME-1 variants with improved growth during methane-dependent cultivation. As a result, we discovered two beneficial substitutions in the catalytic α-subunit of McrANME-1, S60P and I154V, that increased biofilm growth as well as acetate production and methane capture. AlphaFold structural predictions suggest possible mechanistic explanations for these beneficial substitutions. These findings demonstrate that Mcr can be engineered to enhance methane and carbon dioxide capture, establishing a foundation for biological greenhouse gas mitigation and carbon utilization technologies.
mhryu@live.com's insight:
wood tk, 1str, directed evolution for methane consumption

From
www
The computational design of soluble analogues of membrane proteins has unlocked exciting opportunities for the integration of unique membrane protein functions into soluble proteins. Here, we use AF2seq to generate accurate soluble analogues of both animal and microbial rhodopsins, based on the membrane GPCR topology, and the microbial rhodopsin transmembrane fold. We characterize the analogues and demonstrate that they are well-folded and highly thermostable. Furthermore, they exhibit the expected red shift characteristic of retinal binding. Top-down mass spectrometry confirms the placement of retinal covalent attachment, while X-ray crystallography validates the structural fidelity of the microbial rhodopsin analogue. Notably, the microbial rhodopsin analogue retains the primary reaction of the retinal photocycle, closely matching that of the native membrane protein. Overall, this work advances the possibility to transfer unique membrane protein functions, such as retinal photoswitching, into the soluble proteome.
mhryu@live.com's insight:
use the AF2seq framework coupled to the soluble version of ProteinMPNN (ProteinMPNNsol), to create soluble analogues of rhodopsins from both the microbial (type I) and animal (type II) families.
From
www
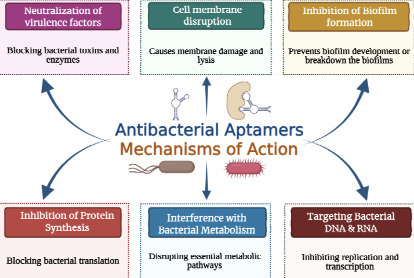
In recent years, aptamers have transitioned from mere laboratory tools to highly potent molecular recognition agents capable of overcoming the strict limitations of conventional antibiotic therapies. We have developed AptBacterialDB, a manually curated, large, comprehensive database of experimentally validated antibacterial aptamers spanning 1996 to 2026. The database contains a total of 2131 aptamers targeting approx 75 different bacterial classes, and 124 aptamer targets with 95 entries found in UTexas databases, 97 in AptaDB, and 28 in Aptabase. It contains 1555 unique aptamer sequences, 189 unique modifications, 40 different selection approaches, and 44 different affinity methods. It integrates detailed annotations of about 20 fields, including sequence information, nucleic acid type, binding affinity, modifications, experimental and functional details. The secondary structure of the aptamers was predicted using ViennaRNA Package 2.0, demonstrating that they adopt mostly stable conformations, with a structured stem region. MySQL was implemented for database development, and a knowledge graph was integrated using ArcadeDB/openCypher for graphical visualization of aptamer-target-organisation relationships. Facilities such as different search modes, browsing, similarity search, REST API access, and entries linked to the existing database for a broader view of the aptamers have been provided. AptBacterialDB (https://webs.iiitd.edu.in/raghava/aptbacterialdb/) provides a user-friendly centralized platform to accelerate antibacterial aptamer research, therapeutic development, biosensor design, and computational modelling efforts.
From
www
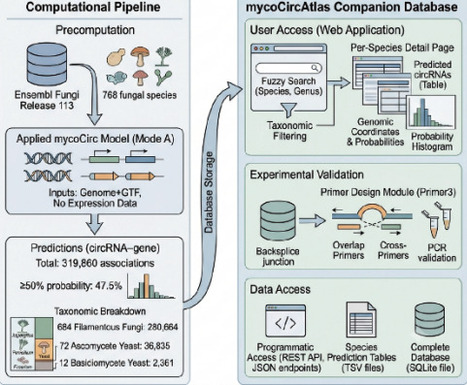
Exploring the fungal circular RNA (circRNA) landscape is bottlenecked by both experimental and computational limits. While standard mRNA-seq systematically discards circRNAs due to their lack of poly(A) tails, high-cost total RNA-seq remains prohibitive for large-scale screening. Consequently, discovery relies heavily on computational prediction. However, existing models trained exclusively on human or plant sequences fail in fungi because of the extreme genomic divergence across fungal lineages, which span from intron-poor Candida to intron-rich filamentous fungi. As a result, no computational framework currently exists for de novo fungal circRNA prediction, leaving the vast majority of non-model fungi entirely inaccessible. Results: We present mycoCirc, the first end-to-end pan-fungal multi-modal pretrained model for fungal circRNA prediction, integrating three mandatory modalities with bidirectional cross-attention for donor-acceptor site interaction. Pre-trained on 22 strains with 16,483 positive gene-circRNA associations spanning Ascomycete yeast, Basidiomycete yeast, and Filamentous fungi groups and fine-tuned per group using 5-fold cross-validation, mycoCirc achieved AUROC 0.69-0.70 on held-out test species under Mode A (Genome+GTF, no RNA-seq), substantially outperforming JEDI (0.51-0.57) and CircPCBL (0.49-0.53). Cross-species evaluation on four independent fungi datasets demonstrated robust generalization across all fine-tuned variants (AUROC 0.63-0.72). Beyond gene-level classification, the JunctionEncoder module enabled backsplicing junction identification for detailed circRNA validation. We further build mycoCircAtlas, a companion database providing 319,860 high-confidence gene-circRNA predictions across 768 fungal species from Ensembl Fungi Release 113, enabling researchers to query precomputed predictions and design validation primers without local model deployment.

From
academic
Microbial communities carry out important ecological functions. Their activities emerge from interactions between species, often potentiated by metabolic traits. We lack a quantitative understanding of how these traits shape community properties. Here, we present theory for microbial communities, leveraging concepts from quantitative microbial physiology. We focus on how steady-state metabolic exchanges between species determine their fractional abundances, given their biomass and byproduct yields on nutrients. We start by deriving formal conditions for the steady states of communities of microbes that grow, die and cross-feed metabolites. We describe the metabolic stoichiometry of nutrient uptake and the formation of biomass and byproducts for each species in terms of charge- and chemical-element balanced reactions (macrochemical reactions). Byproducts function as nutrients for other species. Next, we express the relative abundances of species (living and dead), the net metabolic conversion of a community, and the biomass carrying capacity in terms of the metabolic stoichiometry, growth rates and death rates of the species. We show how niche creation can emerge from stoichiometric imbalances in cross-feeding communities. Finally, we discuss how relative species abundances depend on the ATP stoichiometries of intracellular metabolism.
mhryu@live.com's insight:
model

Bacterial pathogens rely on the constant availability of purine and pyrimidine nucleotides to facilitate replication, growth, and virulence and to sustain energy metabolism and nucleotide-based signaling. The capacity to switch between de novo synthesis and salvage pathways underpins much of their metabolic flexibility and also regulates access to different human body niches, where nucleobase availability varies significantly between extracellular fluids, mucosal surfaces, inflamed tissues, and intracellular compartments. However, adaptation to specific host niches can result in the loss of de novo nucleotide biosynthesis pathways, increasing bacterial dependence on nucleobase/nucleoside salvage. Many intracellular pathogens lack de novo synthesis pathways, making purine or pyrimidine salvage not an optional, but an essential process where host nucleotide reserves are critical to bacterial survival. Because of their central role in bacterial metabolism, enzymes, transporters, and regulatory networks involved in purine and pyrimidine metabolism represent potential targets for therapeutic interventions. This review summarizes the current knowledge of purine and pyrimidine metabolism in bacterial pathogens, including the abundance of these compounds in different host niches, tissue-specific fitness strategies, and bacterial targets for further development of innovative antibacterials.
|

From
www
Pangenomics quantifies the conserved and variable gene repertoire among genomes, but popular implementations ignore gene synteny. Graph-based approaches incorporate both gene homology and synteny, but become difficult to interpret due to pervasive rearrangements. Here we present network-pruning and graph-layout algorithms that enable interactive, synteny-aware quantification and visualization of gene conservation and variability. Applied to 29 genomes of the marine genus Undatipelagibacter (formerly SAR11 subclade Ia.3.VI), we find that genomic variability forms not a few hypervariable islands against a static backbone but a structured continuum, whose variable regions differ in scale, topology, function, and evolutionary character. Genome variation spans from ancient, specialized regions of hundreds of genes whose propensity to vary is conserved across genera, to single hypervariable genes shaped by epistatic co-selection with partners dispersed genome-wide, and shows that chromosomal context carries evolutionary information synteny-unaware pangenomics cannot capture, and some evolutionary processes act on entire functional subsystems throughout a pangenome.

From
www
Mutation is the ultimate mechanism that produces genetic novelty, and thus a central ingredient of evolution. Mutation rates are therefore thought to be tuned by natural selection, for example to optimize a delicate balance between the generation of adaptive diversity and the accumulation of deleterious mutations. As this selection occurs over very long time scales, models and simulations have been powerful tools to understand how mutation rate evolves and which factors influence it. Most simulation methods are nevertheless limited by the over-simplicity of the genotype-to-phenotype map they feature, especially regarding the encoding of mutation rate. We modified Aevol, an evolutionary simulator inspired by bacterial genomics with a realistic genome structure and a complex genotype-to-phenotype layer, to allow organisms to evolve genes coding for higher replication fidelity. This setup permits several degrees of realism absent in other models: mutation-rate modifier genes themselves experience a realistic distribution of effects of mutations and diminishing- returns epistasis, similarly to fitness modifiers. Moreover, a lower mutation rate comes with the trade-off of a larger genome to encode the genes improving replication fidelity. We use this setup to test hypotheses regarding the evolution of prokaryotic mutation rate, and its link with genome size and genetic drift. We found that evolution systematically increases replication fidelity, even when this results in lower fitness. We highlight two factors which limit the mutation rate decrease: genetic drift and the supply of gain-of-fidelity mutations.

From
academic
Metabolites are life-sustaining small molecules produced by living organisms. They interact with proteins involved in metabolism, signalling, and gene regulation, called metabolite–protein interactions (MPIs). This review traces the history of MPI research, from curated resources and early cheminformatics to harmonized identifiers, proteome-scale structural models, and artificial intelligence–driven prediction, while highlighting persistent challenges that continue to limit mechanistic interpretation of metabolomics. Early small-molecule-protein interaction prediction tools (e.g. Molpat and Catalyst) and resources (e.g. ChEMBL and BindingDB) were typically biased towards drug-like molecules. As drug-centred research continued, a revolution in large-scale metabolomics enabled high-throughput profiling of metabolite levels across physiological and disease states. However, these advances also introduced major data integration challenges such as data fragmentation, unresolved metabolite identities, and limited physiological context. Subsequent metabolite-centric resources (e.g. HMDB) and high-throughput screens applied to MPI detection (e.g. thermal proteome profiling) have partially addressed this bias. Proteome-scale structure prediction (e.g. AlphaFold) has further incentivized research into the effects of metabolites on protein structure and function. Nevertheless, the complexity of the biological response also depends on, e.g. exposure, access, and target expression. Looking ahead, MPI research is likely to be shaped by structure-aware deep learning and the integration of MPIs with comprehensive single-cell multi-omics data and host–microbe modelling. These advances may turn metabolomic signals into causal, testable hypotheses, enabling robust systems-level MPI maps for identifying intervention points and designing new treatments. We propose a historically structured roadmap centred on standards-driven data integration and calibrated, structure-aware modelling to support mechanistic, systems-level MPI maps.

From
www
Estimates of preventable antimicrobial resistance (AMR) burden are important to inform local, national, regional, and global policies, targets and research priorities. Such estimates rely heavily on model assumptions and several analytical approaches have been used. In this perspective article, we outline key conceptual and practical challenges in estimating AMR burden, and propose strategies for building on existing work to obtain more policy-relevant burden estimates. We highlight how new approaches taking an explicitly causal perspective are tackling these problems and have the potential to improve the way results are combined from individual studies to estimate national and regional AMR burden. Estimating preventable antimicrobial resistance (AMR) burden is vital for guiding policy and research, but current methods rely on complex assumptions. In this Perspective, authors outline the challenges and pitfalls in estimating AMR burden, and propose their strategies for reducing bias and improving generalisibility of estimates.

From
www
Flavonoids constitute a large class of natural products widely investigated for their bioactive properties, with microbial production offering a potentially scalable alternative to plant extraction. However, achieving structural diversification of these compounds in microbial systems remains challenging, as modification of the flavonoid B-ring typically relies on downstream tailoring enzymes. An alternative strategy is to exploit the intrinsic promiscuity of the canonical flavanone biosynthesis pathway to introduce structural variation at an early stage. Here, we sought to improve microbial production of diverse flavanones by systematically leveraging pathway promiscuity. By constructing a combinatorial library of pathways comprising 4-coumarate-CoA ligase, chalcone synthase, and chalcone isomerase, we enabled the conversion of a panel of ring-substituted cinnamic acid precursors into ten natural and non-natural flavanones. In parallel, we established a genetically encoded biosensor based on the transcriptional regulator FdeR and demonstrated its responsiveness across all ten flavanones. Leveraging this biosensor for high-throughput screening, we performed directed evolution of chalcone synthases from Hordeum vulgare and Arabidopsis thaliana, identifying enzyme variants that led to improved production of O-methylated flavanones, including isosakuranetin, hesperetin, and homoeriodictyol, as well as fluoro-substituted flavanones. In addition, we demonstrated that specific variants of H. vulgare chalcone synthase promoted the formation of isoferuloyl-derived derailment products. Collectively, this work establishes the FdeR-based biosensor as a versatile platform for pathway and enzyme engineering, enabling efficient early-stage diversification of flavanones in microbial systems and providing insight into the mutational landscape of chalcone synthases.

From
www
Natural CRISPR-Cas9 systems rely on crRNA-tracrRNA duplexes to guide DNA targeting. Prior work showed that tracrRNAs could be reprogrammed to hybridize to cellular RNAs, resulting in their conversion into non-canonical crRNAs that enabled RNA detection and recording. However, the fate of the cellular RNA and the engineering opportunities it affords remain unexplored. Here, we show that the hybridized RNA is not inactivated, allowing the recruitment of Cas9 to the RNA duplex to drive RNA base editing and trans-splicing. Fusing ADAR2dd to dSpyCas9 and systematically engineering the reprogrammed tracrRNA (Rptr) enabled efficient and tunable A-to-I RNA editing, with on- and off-target profiles comparable to dCas13. The methodology extended to the compact CjeCas9 that could be further tailored for RNA targeting by deleting the HNH domain and mutating the PAM-interacting domain. Finally, utilizing Rptrs to block splicing enabled 3′ and 5′ RNA trans-splicing. Thus, Rptrs offer a versatile alternative to conventional Cas9 guide RNA architectures for programmable RNA manipulation.
mhryu@live.com's insight:
biesel cl, Rptr-guided dCas9 can drive both 3′ and 5′ trans-splicing by recruiting a splicing template rather than a deaminase

From
www
Precision phage therapeutics provide a promising strategy to combat multidrug-resistant pathogens, including Staphylococcus aureus. Efficient, specific packaging of genetic cargoes remains challenging. Using modular design principles, we report a minimal phagemid packaging signal consisting of the phage terminase small subunit under its native promoter that significantly outperforms conventional packaging signals. The utility of this synthetic terS operon was demonstrated through production of highly concentrated and genetically pure CRISPR-Cas antimicrobials. To circumvent CRISPR-mediated self-targeting during antimicrobial generation, a terS-deficient strain was engineered to express the anti-CRISPR protein AcrIIA4, enabling titers above 1010 transducing units per milliliter (TRU/mL) with over 94% purity. With a high-copy origin of replication module, CRISPR-Cas phage-like particle titers could approach 1012 TRU/mL. We discovered that pure CRISPR-Cas antimicrobials are potent and can be amplified in hosts possessing prophages. Taken altogether, this study defines the minimal and optimal genetic requirements for efficient, specific creation of phage-based technologies.

From
www
Cas9 precision editing is increasingly predictable because guide, donor and target-context effects have been systematically characterized. Extending this framework to other nucleases is essential for installing variants outside convenient Cas9 target space. Cas12a provides a T-rich protospacer-adjacent motif (PAM) alternative, but determinants of efficient donor-templated Cas12a editing remain poorly defined. Here, we systematically dissected Cas12a precision editing in Saccharomyces cerevisiae across nuclease, direct repeat, expression, crRNA, donor, genomic context and time-course variables. Reporter and amplicon-sequencing assays showed that cleavage activity alone did not predict precise editing. Highly active configurations often reduced viability or lost edited alleles over time, whereas attenuated configurations better preserved programmed edits. Enhanced AsCas12a edited rapidly and tolerated shorter crRNAs, resulting in a narrower editing window, while an attenuated FnCas12a configuration edited more slowly but maintained higher viability and better distal-edit recovery. Alternative repair outcomes were rare, target-dependent, and further suppressed by LexA-FHA donor recruitment. To define design parameters at scale, we established a pooled Cas12a platform with 530 barcoded edit cassettes and recovered programmed edits for 70.2% of designs. Successful editing was reduced with TTTG PAMs, a C upstream of the PAM and at distal edit positions. Excluding these features increased the edited fraction to 85.4% and adding high predicted cleavage scores further elevated it to 91.4%. Applied retrospectively, these criteria also identified poorly edited loci in the targeted panels. Together, these data define design principles for Cas12a-mediated precision editing and establish a scalable platform for genome-scale pooled variant engineering and phenotyping in yeast.
mhryu@live.com's insight:
optimization of cas12a in yeast

From
www
We developed an AI-guided design pipeline that generated and validated non-natural microbial rhodopsins with spectral properties not yet known in nature. The pipeline comprised a three-stage in silico design, a genetic algorithm (GA) for sequence generation, a stacked LASSO and XGBoost machine-learning (ML) regressor for spectral prediction and fitness ranking, and a Markov-based sequence plausibility filter to enforce proton pumping like characteristics. Four candidate rhodopsins (APR1, APR2, APR6, and APR7) targeting blue light absorption were designed and AlphaFold3 structural modelling predicted retinal binding pocket architecture consistent with outward proton-pumping function. Experimental characterisation confirmed that all four variants absorbed light at ∼410 nm and significantly promoted the growth of Cupriavidus necator under blue light illumination. This study demonstrates that AI-enabled design can engineer proteins with no natural precedent, generating light-harvesting rhodopsins with novel spectral properties while preserving biological function, marking a significant advance in programmable synthetic biology.
mhryu@live.com's insight:
884 sequence alignments for two ML training. Regressor (LASSO + XGBoost): Trained on all 884 aligned sequences, using sequence features (18 descriptors per aligned position) to predict each sequence's measured λmax. Standard supervised regression — learns to map sequence → wavelength number. Markov filter: Trained only on the 310 proton-pump sequences (not the other 574). Learns position-to-position transition statistics (bigram model, sequence + secondary structure) describing what a proton-pump sequence normally looks like. One-class model — it never sees non-pumps during training; those are used only afterward to test whether the model correctly scores them as implausible.
From
www
DNA foundation models are trained to predict the likelihood of natural sequences, but the calibration between such likelihood scores and laboratory fitness or directly measured molecular phenotypes depends strongly on gene context, sequence divergence from wild-type, and selection regime. We apply zero-shot variant scoring with Evo2 7B (dLLR, the change in pseudo-log-likelihood between mutant and reference windows) to five E. coli datasets and quantify this context-dependent calibration map. Calibration is strong in two settings. In the Firnberg 2014 deep mutational scan of TEM-1 beta-lactamase (13,027 nucleotide-level variants; plasmid-borne enzyme under band-pass ampicillin selection), Evo2 dLLR tracks measured fitness at Spearman rho = 0.545 (95% CI 0.532-0.557; SNV rho = 0.606, indel rho = 0.521). In the Tenaillon 2012 thermal-evolution dataset, type-stratified, window-tuned scoring reaches Insertion AUROC 0.882 (W = 2,048 bp) and Deletion AUROC 0.846 (W = 4,096 bp). Calibration is decisively absent in the same organism: the Ireland 2020 RegSeq promoter MPRA gives rho = 0.011 (95% CI 0.003-0.019; n = 64,665), flat even after -10/-35 mechanism stratification, and the Dewachter 2023 chromosomal-essentials scan (fabZ/lpxC/murA) gives rho = 0.041 (95% CI 0.025-0.058). The Papkou 2023 folA combinatorial landscape sits between, at rho = 0.237, with a sweep that falls monotonically from rho = 0.575 at two mutations from wild-type to rho = 0.065 at nine. Pooling per-gene and per-divergence correlations, we fit calibration as an explicit function rho = f(sequence divergence from WT, variant context): weighted regression gives a negative divergence coefficient and a negative regulatory-context coefficient (both in the predicted direction; R2 = 0.49), an explicit, if illustrative, fit rather than a metaphor. We further test, and find unsupported, the intuitive explanation for the residual TEM-1 vs. essentials gap: across five genes the chromosomal essentials are more represented than TEM-1 by raw public-database deposition couno simple training over-representation does not exiant diversity is a candidate but remains untested. We therefore reframe Evo2 not a a likelihood predictor whosecalibration with fitness is conble is not a DMS pre-screen toolbut a quantitative lookup table likelihood-fitness gap closes(training-rich plasmid CDS undeens (chromosomal essentials,native promoter regulatory variorganism, plasmid vs. chromosomal context and strong vs. weak selifferent calibration regimes,the central finding.
From
www
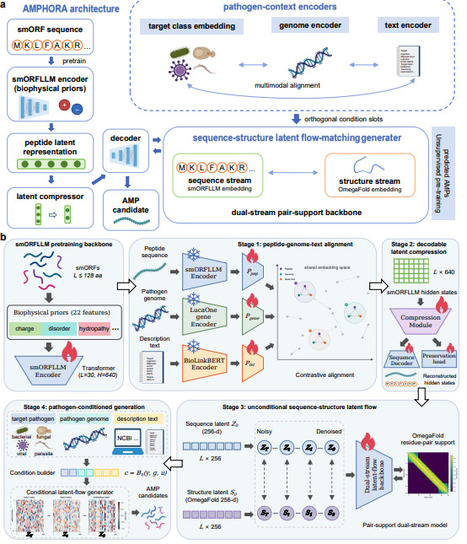
Antimicrobial peptide discovery is constrained less by the number of molecules that can be generated than by the choice of which few should be tested against a defined pathogen. Most peptide generators produce broadly antimicrobial-like sequences and leave target specificity to downstream filters. Here we show that pathogen context can be introduced during generation. AMPHORA conditions a peptide-native generator on target class, pathogen genome features and strain-description text. Matched, ablated and shuffled controls showed that aligned pathogen inputs redirected generated libraries beyond coarse activity labels, whereas global shuffling weakened this effect. Same-noise counterfactuals showed that strain descriptions drove larger sequence changes, whereas genome features more strongly affected predicted structural properties. Species-level analyses revealed target-dependent enrichment. Matched bacterial inputs also shifted APEX-predicted activity rankings relative to class-only generation. The resulting libraries remained diverse, largely non-memorizing and compatible with predicted peptide-like structural features. Together, these results establish pathogen-context conditioning as a new paradigm for computational library reshaping in antimicrobial peptide generation.
mhryu@live.com's insight:
generate amp

From
journals
Insertion sequences (IS) are widely involved in bacterial genomic plasticity by disrupting, adding, moving genomic sequences, or by activating or extinguishing gene expression. A specific family of IS, ISCR (for insertion sequence of Common Region), is thought to be involved in the dissemination of antibiotic resistance genes (ARGs). While some ISCR members are commonly found in bacteria isolated in clinical settings and can contribute to downstream ARG expression, the mechanisms regulating the ISCR-encoded transposase expression have remained uncharacterized. Here, we investigated the expression of the transposase genes of ISCR1, ISCR2, and ISCR8 and its regulation in E. coli. Using in silico analyses and in vitro experiments, we showed that the expression levels were extremely low, as observed for most IS transposases. We further demonstrated the direct role of DNA damages and the key SOS response repressor, LexA, in controlling the activity of the transposase promoter. These results provide evidence that the mobility of at least some ISCR elements may be promoted upon bacterial exposure to antibiotics inducing the SOS response.
|





E values from different queries cannot be fairly compared against each other because longer sequences automatically generate better (lower) E values just by being longer
regularized (normalized) e value: the length bias by dividing the E value by a "baseline" E value derived from each sequence matching itself.