 Your new post is loading...

|
Scooped by
mhryu@live.com
Today, 1:14 AM
|
L-xylulose is a versatile L-form rare sugar with exceptional properties, including low caloric content, α-glucosidase inhibition, and antiviral effects, making it highly valuable for functional food and pharmaceutical applications. However, natural L-xylulose is extremely scarce, and its chemical synthesis is plagued by harsh conditions and isomer contamination, thus making biosynthesis—with its industrial potential and environmental friendliness—a promising alternative. This review summarizes the latest biosynthesis progress, analyzes six enzymatic pathways for L-xylulose and identifies two competitive routes, using xylitol and L-arabinitol as starting substrates. It further elaborates on core bottlenecks in chassis cell construction and industrial fermentation of L-xylulose, emphasizing that breakthroughs rely on three strategies: AI-driven high-yield strain screening, catalytic optimization of key enzymes, and efficient extracellular transport/secretion of the target product. Finally, the integration of synthetic biology with intelligent biomanufacturing is proposed as a crucial direction for efficient L-xylulose biosynthesis, facilitating its broader application across the food, pharmaceutical, and chemical industries.
|
|
Scooped by
mhryu@live.com
Today, 12:24 AM
|
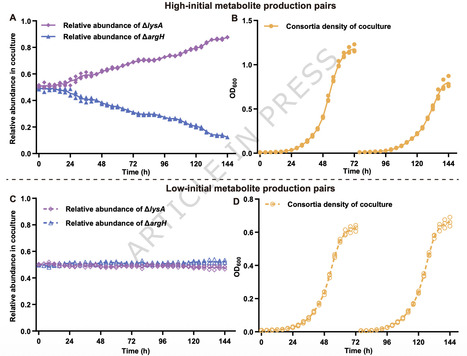
Syntrophic interactions based on reciprocal metabolite exchange are widespread in microbial communities, yet the factors determining their stability remain unclear. Using synthetic E. coli consortia composed of lysine and arginine auxotrophs, we show that lower initial metabolite production promotes, rather than limits, syntrophic stability. During serial propagation, replicate cocultures diverged sharply: a minority maintained sustained growth, whereas most became extinct. This divergence was associated with phenotypic differences in metabolite production among founding isolates. Consortia founded by low-producing strains recovered reliably after dilution and were more resistant to invasion by non-producing mutants. By contrast, high-producing founder generated diminishing returns for consortium growth, and increased extracellular metabolite availability that favored exploitation by non-producer. Although we detected no consistent coding-region variations between high- and low-producing isolates, expression differences suggest that outside coding regions may influence these production traits. These results identify constrained initial metabolite production as a key determinant of syntrophic stability. Low initial metabolite production stabilizes syntrophic E. coli consortia by constraining metabolite availability, promoting localized exchange, and resisting invasion by non-producers
|
|
Scooped by
mhryu@live.com
May 5, 11:46 PM
|
Gene order is a powerful design principle for protein nanomachines. In nature, gene organization ensures the precise assembly of functional protein nanostructures. We demonstrate how genetic repositioning of the key structural gene pduN, within the operon encoding a self-assembling protein nanocompartment, sculpts the morphology and function of bacterial microcompartments (BMCs). Relocating pduN to new operonic positions dramatically altered the size, shape, and catalytic output of BMCs, despite identical protein sequences. These shifts reveal how gene order may control nanoscale assembly and compartmentalised function. Our findings establish operon architecture as a programmable genetic framework for nanostructure morphogenesis and provide a synthetic biology strategy to engineer self-assembling nanodevices with customised geometries and activities.
|
|
Scooped by
mhryu@live.com
May 5, 11:30 PM
|
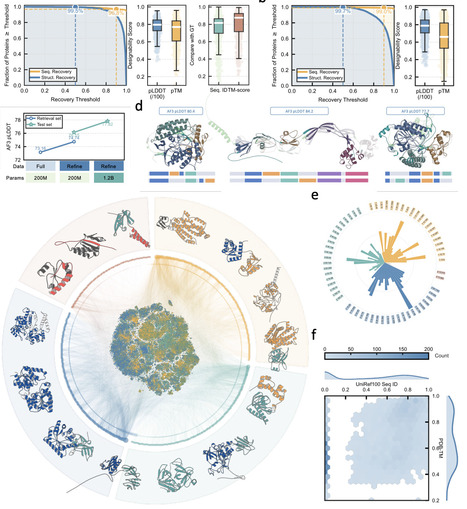
Multidomain proteins arise through the reuse and recombination of structural domains, yet natural architectures represent a sparse, structured sample of the possible domain-combination space. Here, we introduce DOMINO, a two-stage framework that learns domain co-occurrence from TED-annotated multidomain proteins and uses the learned patterns to generate new multidomain sequences. DOMIN, a contrastive retrieval model, embeds domains into a latent compatibility space and retrieves candidate partners for a query domain from a TED-derived domain pool, including pairings not observed in the TED-derived co-occurrence set. DOMO, a conditional autoregressive sequence model, converts each retrieved domain pair into a full-length protein sequence by jointly generating the specified domain regions and the non-domain sequence context between and around them. DOMIN recovers hierarchical patterns of natural domain co-occurrence and expands the observed CATH homologous-superfamily co-occurrence network with candidate novel pairings. DOMO realizes both held-out natural pairs and DOMIN-retrieved pairs as proteins with high domain recovery and high AlphaFold-predicted structural confidence. Applied at scale, DOMINO generated 5 million retrieval-derived multidomain proteins, with sampled designs showing recovery of the specified domains, diverse CATH annotations, and sequence novelty relative to UniRef100. Together, these results support domain co-occurrence as a predictive design prior and demonstrate a scalable strategy for exploring multidomain protein architectures through new combinations of existing structural modules.
|
|
Scooped by
mhryu@live.com
May 5, 11:10 PM
|
Medicinal plants link agriculture, ecosystem health, and human therapeutics, with bioactive compound profiles providing a direct and economically meaningful readout of microbiome function. Although microbial inoculation can enhance pharmacologically relevant metabolites under controlled conditions, these effects are context dependent and rarely reproducible in the field. This efficacy gap reflects three ecological constraints: introduced microbes are excluded by resident communities, environmental variation overrides laboratory-optimized functions, and inoculants fail to persist without mutualistic feedback. Addressing these barriers requires shifting from disposable inputs to microbiome stewardship: rewilding beneficial communities, designing climate-adapted consortia, and managing soil as living infrastructure. Whether such stewardship produces measurably different bioactive profiles and therapeutic outcomes under field conditions remains the empirical question on which its One Health rationale ultimately depends.
|
|
Scooped by
mhryu@live.com
May 5, 5:14 PM
|
Protein language models (pLMs) capture evolutionary sequence constraints but are limited in modeling underrepresented functional classes due to training data imbalance. Metalloproteins constitute a fundamental but sparsely represented class in sequence databases. We therefore assess whether structure-conditioned synthetic sequences can be used to specialize pLMs toward metal-binding functionality. We fine-tuned the generalist model ProtGPT2 on synthetic sequences generated by the inverse-folding model ProteinMPNN, constructing training sets with controlled variation in size and diversity. Fine-tuning increased recovery of canonical metal-binding motifs from 43% in the baseline model to 91% in the fine-tuned models. Generated sequences retained high predicted structural confidence and structural similarity to known folds, despite low sequence identity. Analysis of latent representations from ProtGPT2 indicated that fine-tuned models occupy distinct regions of embedding space relative to both the baseline model and structure-conditioned sequences, consistent with partial incorporation of structural constraints while preserving sequence diversity. A multi-step filtering pipeline applied to sequences lacking canonical motifs identified candidate metal-binding sites in four-helical bundle topologies not detected in a non-redundant subset of Protein Data Bank structures or in AlphaFold-predicted proteomes. https://doi.org/10.5281/zenodo.18672158 https://huggingface.co/gsgueglia
|
|
Scooped by
mhryu@live.com
May 5, 3:38 PM
|
Although several existing protein-protein interaction (PPI) databases provide yeast PPI data, none unify large-scale network topology information with detailed biophysical, proteostasis, and regulatory annotations in a single protein-centric framework. To address this gap, we developed the ANnotated Yeast Interactome (ANYI), an open, integrated resource that combines experimental yeast PPIs with sixteen feature annotation types, including protein abundance, half-life, disorder content, post-translational modifications, conformational stability, chaperone interactions, sequence, and structure. ANYI integrates 3,927 proteins with 155 annotation features, forming a unified matrix that enables systematic cross-layer analyses. Available via GitHub and Docker Hub with an interactive network browser for broad accessibility, ANYI provides both experienced and beginner computational scientists with tools to investigate the yeast interactome. For example, users can directly test whether highly connected hub proteins exhibit distinct stability, disorder, or proteostasis signatures relative to peripheral nodes.
|
|
Scooped by
mhryu@live.com
May 5, 3:25 PM
|
Long-term biodegradation of soil microplastics such as polyethylene terephthalate (PET) in situ remains inadequately addressed due to the limited expression of efficient PET degrading enzymes in engineered bacteria. Here, we developed a quorum-sensing (QS)-based protein expression system (XylS-LuxI/LuxR) that enhanced reporter green fluorescent protein (GFP) expression by 44-fold in E. coli. Using this system, we constructed whole-cell PET biodegraders expressing PET hydrolases (FASTPETase-MHETase) and leaf-branch compost cutinase (LCCICCG) in E. coli and Pseudomonas putida (P. putida). Soil-based assays using crude enzymes and E. coli XylS-QS-LCCICCG cells showed >80% degradation of bis(2-hydroxyethyl) terephthalate (BHET) within 30 min. Furthermore, Agde-LCCICCG was identified as the most effective signal peptide (SP) for protein secretion in E. coli, whereas LCCICCG without a SP performed best in P. putida. Engineered E. coli achieved up to 63% PET nanoparticle degradation over 30 days, while P. putida reached 42.3% within 20 days in nonsterilized soil, substantially outperforming wild-type controls and indicating synergistic interactions with native microbiota. These results demonstrate that XylS-QS-based systems enable efficient, self-regulated whole-cell PET biodegradation in soil environments, providing new insights for the development of efficient biodegradation strategies of environmental plastic waste.
|
|
Scooped by
mhryu@live.com
May 5, 2:55 PM
|
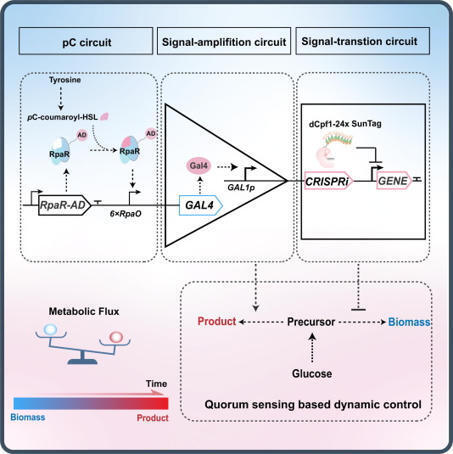
Dynamic regulation of metabolic pathways is critical for optimizing microbial production, yet robust quorum-sensing (QS) systems remain largely unavailable in eukaryotic microorganisms. Here, we establish a bacterial-derived QS platform in Saccharomyces cerevisiae by repurposing the noncanonical RpaI/RpaR system (a LuxI/R-type QS system), which produces p-coumaroyl-homoserine lactone as a signal molecule, bypassing a fundamental metabolic barrier that has prevented functional bacterial QS in eukaryotes. The engineered circuit features low leakage, high sensitivity, and broad dynamic range. By coupling QS with signal amplification and CRISPR interference modules, we create a bifunctional cascade system enabling autonomous transcriptional activation and repression. This QS platform enables growth-production decoupling and improves the production of cordycepin, geraniol, and 3-hydroxypropionic acid in both baseline and high-producing strains. Our work establishes a functional bacterial QS system in yeast and expands the synthetic biology toolkit for eukaryotic hosts.
|
|
Scooped by
mhryu@live.com
May 5, 2:38 PM
|
ARTEM Server is an online platform for comparative analysis of nucleic acid 3D structures, combining two complementary superposition methods based on the ARTEM algorithm. The server provides access to searches for local tertiary motifs using the ARTEM tool, which identifies local isosteric structural arrangements without relying on sequence, interaction annotations, or backbone connectivity. It also offers global structure alignment and search modes via ARTEMIS, a recent extension of ARTEM that performs global sequence alignments based on rigid-body structural superposition. ARTEMIS supports both classical sequentially ordered superpositions and alignments involving sequence permutations, and can enumerate alternative suboptimal matches, enabling structural searches within large molecules or across databases. Benchmarks reported in the original publications demonstrate that ARTEM and ARTEMIS outperform other tools and are particularly effective at detecting 3D motif and 3D fold similarities across diverse backbone contexts, including cases that are challenging for sequence-ordered or annotation-dependent methods. ARTEM Server unifies these capabilities in a web interface, accepting PDB/mmCIF inputs, supporting multiple query and reference structures, and providing interactive 3D visualization and exportable alignment and motif-matching data. ARTEM Server offers a user-friendly web-based environment for exploration of global nucleic acid folds and local tertiary motifs. The web server is available at https://artemserver.genesilico.pl/.
|
|
Scooped by
mhryu@live.com
May 5, 2:30 PM
|
Bioorthogonal chemistry was originally developed for fast and selective ligation of small molecules onto biomolecules in complex biological environments. Over time, the field has grown significantly beyond just clicking molecules together. It now includes reactions that can form or break chemical bonds and control how reactive substances are generated within living organisms. The field is continuing to develop strategies that allow reactions to be turned on when needed, exhibit greater compatibility in biological environments, and enable multi-step transformations to achieve complex operations. In this review, we summarize these new developments, including new click reactions and reagents, inducible and enzyme-activated click systems, click-induced bond dissociation reactions, bioorthogonal chemical operations, and bioorthogonally activated reactive species.
|
|
Scooped by
mhryu@live.com
May 5, 2:08 PM
|
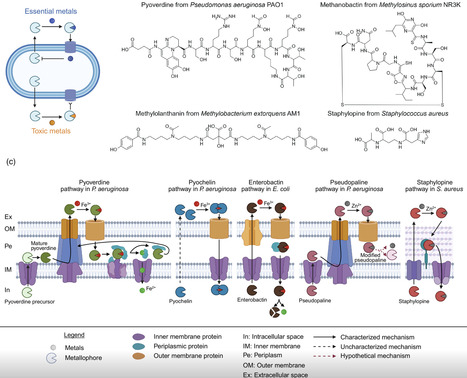
Metals are essential trace elements for almost all organisms including bacteria. Yet, metals are toxic at high concentrations, requiring fine-tuned regulatory mechanisms to steer metal homeostasis inside cells. In this primer, we explain how bacterial metallophores – small secreted secondary metabolites – act as gatekeepers by carefully orchestrating the scavenging and uptake of essential metals whilst preventing intracellular toxicity and keeping toxic metals outside the cell. We further introduce metallophore diversity together with main synthesis, secretion and uptake mechanisms. Finally, we show how secreted metallophores shape ecological interactions between bacteria and with eukaryotic organisms and how fundamental research on metallophores opens promising avenues for therapeutic and biotechnological applications.
|
|
Scooped by
mhryu@live.com
May 5, 1:58 PM
|
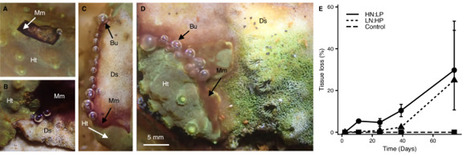
Coral diseases are increasing in prevalence, accelerating the global decline of tropical reefs, which threatens over 25% of marine biodiversity and vital ecosystem services for human societies. While outbreaks are frequently linked to environmental change, including heat stress, sedimentation, and reduced water quality, the mechanisms by which such factors promote disease remain poorly understood. Here we show that nutrient stress, caused by skewed seawater nitrogen-to-phosphorus (N:P) stoichiometry, promotes the onset of Black Band Disease (BBD), a common and easily recognisable syndrome that affects corals around the globe. Using Turbinaria reniformis as a model system, controlled laboratory experiments demonstrate that skewed N:P ratios disrupt the functional integrity of coral-associated microbial networks while favouring opportunists that exploit dysfunctional host–symbiont interactions. Disease lesion-associated microbial mats are dominated by cyanobacteria and include sulphur-metabolising bacteria, hallmarks of natural BBD communities. Strikingly, similar cyanobacterial taxa are also detected in the visually healthy coral tissue ahead of the expanding lesions, suggesting an opportunistic recruitment of disease-associated members from the resident microbiome. Global analyses of BBD outbreaks reveal that over 88% occurred in regions with skewed N:P ratios, compared with only 16% that were linked to prior heat stress. Together, our findings identify nutrient-driven microbiome destabilisation as a key pathway to coral disease, reinforcing nutrient management as a major lever for reef conservation and restoration practice. Coral diseases contribute to the decline of reefs around the globe. This study reveals that disruptions of the nutrient balance in seawater can change coral-associated microbial communities leading to disease.
|
|
|
Scooped by
mhryu@live.com
Today, 1:04 AM
|
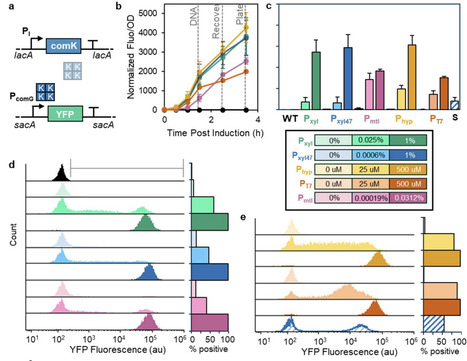
Bacillus subtilis is an important chassis for biotechnology, but its use in multiplex genome engineering is limited by low natural transformation efficiency. Here, we compared inducible promoter systems for synthetic activation of the competence regulator ComK and evaluated their effects on the comG operon competence reporter and transformation efficiency. Xylose- and mannitol-inducible systems outperformed IPTG-based constructs and shifted 96-99% of cells into a reporter-positive competent state. However, reporter activation alone did not predict transformation potential. Optimization of culture density and induction timing increased transformant yield 45-fold relative to the initial protocol and 2800-fold relative to the conventional Spizizen method. Disruption of native competence regulatory genes did not improve performance and often reduced transformation output, highlighting the importance of endogenous regulatory circuitry. Using the optimized strain and protocol, we achieved co-transformation frequencies of 11-18% and constructed multiplex spore-display libraries containing fluorescent protein fusions integrated at multiple loci. Screening identified strong dual-display combinations and showed that cargo loading depends on anchor protein, integration locus, and genetic background. SscA fusions supported the highest display capacity and promoted synergistic co-display. Together, these results show improvements in natural transformation-based genome engineering in B. subtilis and provide insight into the construction of multifunctional engineered spores.
|
|
Scooped by
mhryu@live.com
Today, 12:11 AM
|
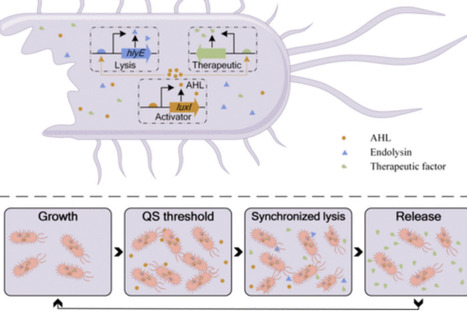
Synthetic biology has driven growing interest in engineered bacteria for cancer therapy. Salmonella Typhimurium stands out as one of the most promising live biotherapeutic products (LBPs) because of its innate tumor-targeting and colonizing abilities. However, the pathogenicity and inconsistent performance of wild-type S. Typhimurium have hindered further clinical translation. Recent advances in programmable and modular genetic redesign now enable precise reprogramming of bacterial functions, facilitating the creation of customized LBPs with enhanced safety and efficacy. In this review, we propose a systematic engineering framework with adaptive optimization and therapeutic enhancement for transforming S. Typhimurium into an effective anticancer LBP. This integrated strategy encompasses multiple facets, including strain attenuation, targeted enhancement, colonization optimization, therapeutic production, lysis-controlled release, and auxiliary modules. This review summarizes the key methodologies for engineering S. Typhimurium, highlighting its evolution from a pathogen to an antitumor vehicle. Furthermore, we summarize the multimodule collaborative engineering design and applications and call for more combinatorial strategies to enhance therapeutic efficacy. We also discuss the challenges and bottlenecks of engineered S. Typhimurium from the perspectives of genetic stability and clinical translation. Finally, we highlight how these synthetic biology advances are refining the mechanistic understanding of bacteria-mediated tumor therapy and paving the way toward safer, more effective, and clinically controllable anticancer strategies.
|
|
Scooped by
mhryu@live.com
May 5, 11:35 PM
|
The universe of possible protein sequences is astronomically large, yet our understanding of the sequence-structure relationship is confined to the infinitesimal fraction used currently by life. Determining whether "foldable" architectures are rare singularities or accessible solutions is critical for understanding protein evolution and designing novel proteins. Here, we map the structural landscape of random sequence space by screening one million synthetic proteins using a high-throughput in vivo FRET biosensor. We reveal that this space is structurally heterogeneous, populated not only by disordered chains and stress-inducing aggregates but also by "benign" compact structures that resemble globular proteins and evade cellular chaperone responses. By training machine learning models on these phenotypes, we show that structural potential is learnable and generalizes to natural proteomes. These findings demonstrate that biology-like folds are accessible from random sequences with surprising frequency, providing data required to expand generative protein design beyond evolutionary priors.
|
|
Scooped by
mhryu@live.com
May 5, 11:18 PM
|
Despite considerable powers, the application of CRISPR activation (CRISPRa) screens in primary human cells remains a formidable challenge. Here, we develop dCas12f1-SAM, a compact SAM-based transcriptional activation platform, that outperforms existing systems in both immortalized cell lines and primary human T cells and hematopoietic stem/progenitor cells (HSPCs). Using dCas12f1-SAM, we perform a pooled CRISPRa screen targeting 1559 human transcription factors (TFs) in primary human T cells and identify multiple positive regulators of IL-2 expression. We further implement a single-cell CRISPRa screen via our miCROP-seq construct, resolving how these genetic perturbations reshape T cell activation dynamics and drive functionally distinct cellular states. Among the top-ranking genes, we spotlight KLF12 and LHX5, whose overexpression significantly improves antigen-specific responses of chimeric antigen receptor T (CAR-T) cells. Collectively, these findings establish dCas12f1-SAM as a robust transcriptional activation tool, highlighting its potential to advance applications in cellular engineering and immunotherapy. CRISPRa screening in primary human cells has remained a formidable technical challenge. Here, the authors developed dCas12f1-SAM and successfully implemented a gain-of-function screen in primary human T cells, identifying key regulators of T cell activation.
|
|
Scooped by
mhryu@live.com
May 5, 5:18 PM
|
Biological information can be encoded in signaling dynamics, which have been implicated in many physiological processes; yet the diversity of dynamic expression profiles driven by a single gene remains unclear. To explore this, we screen 80 chromatin-associated proteins (CAPs) for their potential to drive diverse dynamic gene expression profiles from the same genome-integrated reporter in yeast. Using locus-specific optogenetic recruitment and live-cell microscopy, we measure dynamic expression profiles within single cells. CAP recruitment elicits a range of responses varying in activation delay, strength, production rate, and noise. We find that promoter activity is characterized by graded, rather than switch-like, transitions. A kinetic model with three promoter states and a positive feedback loop successfully captures the key features of expression driven by each CAP. These results reveal the rich dynamic landscape possible from a single gene, offering insights into native cellular processes and enhancing gene expression control in synthetic biology.
|
|
Scooped by
mhryu@live.com
May 5, 3:43 PM
|
IQ-TREE (https://iqtree.github.io/) is a widely used open-source software tool for efficiently inferring phylogenetic trees under maximum likelihood. Here, we present IQ-TREE version 3, the third major release of the software. IQ-TREE 3 significantly extends version 2 with new features, including mixture models as an alternative to partitioned models, gene and site concordance factors to quantify discordance between genomic regions, integration with phylogenomic divergence time estimation, and a fully-featured sequence simulator. The IQ-TREE 3 source code is available at https://github.com/iqtree/iqtree3.
|
|
Scooped by
mhryu@live.com
May 5, 3:36 PM
|
High-quality datasets that span broad sequence diversity are essential for understanding protein sequence-function relationships beyond local mutational landscapes. Here, we applied Growth-based Quantitative Sequencing (GROQ-seq) to measure function across an 11,722 member protease library, comprised of natural homologs and AI-shrunken variants. This library spans vast sequence diversity, with Levenshtein distances of up to 245 and a mean pairwise sequence identity of 41% to TEV protease S219V. We identified sequence-divergent TEV protease homologs that preserve function against the native TEV protease substrate. These findings reveal the robustness of protease activity across highly diverse sequences. Here, we demonstrate the aptitude of the GROQ-seq assay for screening large, diverse protein libraries for function, enabling efficient data generation at scale for training machine learning models across broad sequence landscapes.
|
|
Scooped by
mhryu@live.com
May 5, 3:03 PM
|
Scalable genetic circuits are essential for implementing complex functions in living cells. Toward this goal, RNA regulators can provide a much-needed parts library with added benefits of low metabolic load, design flexibility, and logic capacity. However, despite the great potential of synthetic RNA circuits, constructing such circuits with wide dynamic ranges and multiplexed regulatory cascades remains a challenge. To address this, we introduce RATEX (Ribosome-Assisted Transcriptional EXpression controller) by integrating a translation-to-transcription converter with synthetic RNA regulators, enabling a compact and scalable RNA-programmed circuit architecture. The RATEX platform repurposes a large library of well-characterized translation regulators with up to 1,492-fold gene regulation, while leveraging natural ribosome-mediated sensing of diverse environmental inputs, such as metabolites. We demonstrated multi-input logic processing with up to a 6-input OR logic gate for RNA inputs and hybrid 3-input logic gates to sense diverse metabolite and small-molecule inputs alongside RNA signals. Signal amplification with multiplexed combinatorial control of RNA outputs was achieved through multiplexed signaling cascades. Finally, the RNA- and metabolite-sensing 3-input AND gates were used to control cellular morphology and intracellular spatial organization. Together, the RATEX platform, with its scalable and modular architecture, offers a broad potential design space for synthetic biology and biotechnology.
|
|
Scooped by
mhryu@live.com
May 5, 2:53 PM
|
In this study, we report an integrated strategy combining directed evolution and semirational design to engineer a high-performance Pyrococcus furiosus Argonaute (PfAgo) variant. The optimized variant exhibited an 8.85-fold increase in catalytic efficiency, substantially enhanced soluble expression, and improved tolerance to elevated salt and metal ion conditions, enabling sensitive nucleic acid detection with a detection limit in the picomolar range. Mechanistic analyses suggested that these improvements may arise from reinforcement of the dimerization interface to stabilize the enzyme’s active state, optimization of the catalytic center, and the introduction of charge-shielding salt bridges. Finally, a biosensing platform based on the engineered PfAgo achieved a detection limit of 10 fmol l−1 for tetracycline, demonstrating its strong potential for sensitive and robust detection. This work provides a generalizable framework for enhancing Argonaute performance and advances their application in field-deployable diagnostics across clinical, environmental, and food safety settings.
|
|
Scooped by
mhryu@live.com
May 5, 2:35 PM
|
Science is losing knowledge it cannot afford to lose. Negative results go unpublished, hard-won expertise walks out the door with departing researchers, and preservation efforts remain fragmented. The consequences are wasted resources, duplicated effort, and missed discoveries. In this perspective, we argue that the research community can act now by embracing alternative dissemination channels, improving documentation best practices, and building sustainable digital infrastructure. We envision moderated platforms for sharing null results and practical know-how, community-driven standards, and AI-powered tools that lower barriers to implementation. With coordinated effort, science can become more open, efficient, and resilient for future generations. Science routinely discards valuable knowledge, from unpublished negative results to the tacit expertise lost when researchers move on. Here, the authors propose a roadmap for preserving this hidden knowledge through community-driven platforms, open standards, and AI-assisted documentation.
|
|
Scooped by
mhryu@live.com
May 5, 2:16 PM
|
Rapid and accurate pathogen detection serves as a core component in infectious disease prevention and control, clinical diagnosis and treatment, and public health surveillance systems. Although traditional detection methods have been widely adopted in clinical practice, they still exhibit significant limitations in terms of detection speed, throughput, automation levels, and adaptability to complex samples. In recent years, artificial intelligence (AI) technology has provided novel technical pathways for pathogen detection by leveraging its strengths in feature learning, pattern recognition, and multidimensional data modeling. The core contribution of this review lies in providing a novel, integrated analytical framework that overcomes the limitations of existing reviews, which often focus on a single modality (such as imaging alone or molecular diagnostics alone). Based on this framework, this paper systematically reviews AI research progress in pathogen detection, focusing on typical applications of machine learning and deep learning algorithms in analyzing imaging data, molecular diagnostic data, sensor signals, microscopic images, and multimodal data. It summarizes AI’s enabling value in enhancing detection sensitivity, specificity, automation, and point-of-care capabilities. Concurrently, this paper delves into key challenges facing AI-assisted pathogen detection, including data standardization, model generalization, interpretability, and clinical translation. It also outlines future trends toward intelligent, integrated, and clinically deployable applications. This paper aims to provide researchers and clinicians in the interdisciplinary field of artificial intelligence, biosensing, and clinical medicine with a comprehensive reference and roadmap for future development.
|
|
Scooped by
mhryu@live.com
May 5, 2:06 PM
|
xBind is an interactive, freely accessible, and fully configurable webserver for large language model (LLM)-enabled cross-molecular protein binding-site prediction. xBind leverages LLM embeddings from the ESM-2 model together with sequence- and structure-derived features to predict protein–protein, protein–DNA, and protein–RNA binding sites using symmetry-aware deep graph neural networks. The input to xBind is either a single-chain protein sequence in FASTA format or a monomer protein structure in PDB or mmCIF format and it outputs predicted residue-level binding sites of the input protein with its pre-selected interaction partner. The customizable xBind web interface provides: (i) choice of interaction partners including protein–protein, protein–DNA, and protein–RNA; (ii) on-the-fly AlphaFold-based protein structure prediction for sequence-only inputs; (iii) on-demand selection of the likelihood threshold for calibrating structure-aware binding site annotations; (iv) interactive and interpretable web-based results, including sequence and structural visualizations and plots of residue-level binding likelihoods with user-adjustable threshold calibration; and (v) extensive help information for usage and results interpretation through a web-based tutorial and guide. xBind is freely available at https://fusion.cs.vt.edu/xBind.
|



























2st, Conjugative transfer of F-like plasmids requires a T4SS that transports the ssDNA plasmid through the cell envelope and produces the conjugative pilus, which is also strictly essential for conjugation. The structure and function of F-like conjugative pili have been extensively studied, particularly those encoded by the F and the pED208 plasmids. The F pilus is an assembly of thousands of TraA pilin (VirB2) monomers polymerized into a long, flexible, and tubular helical filament 87 Å in width and an average ~1 to 2 µm in length, which extends from the surface of the donor cells