

There is a lot of hype around distributed data systems, some of it justified. It’s true that the internet has centralized a lot of computation onto services like Google, Facebook, Twitter, LinkedIn (my own employer), and other large web sites. It’s true that this centralization puts a lot of pressure on system scalability for these companies. Its true that incremental and horizontal scalability is a deep feature that requires redesign from the ground up and can’t be added incrementally to existing products. It’s true that, if properly designed, these systems can be run with no planned downtime or maintenance intervals in a way that traditional storage systems make harder. It’s also true that software that is explicitly designed to deal with machine failures is a very different thing from traditional infrastructure. All of these properties are critical to large web companies, and are what drove the adoption of horizontally scalable systems like Hadoop, Cassandra, Voldemort, etc. I was the original author of Voldemort and have worked on distributed infrastructure for the last four years or so. So in-so-far as there is a “big data” debate, I am firmly in the “pro-” camp. But one thing you often hear is that this kind of software is more reliable than the traditional alternatives it replaces, and this just isn’t true. It is time people talked honestly about this.
You hear this assumption of reliability everywhere. Now that scalable data infrastructure has a marketing presence, it has really gotten bad. Hadoop or Cassandra or what-have-you can tolerate machine failures then they must be unbreakable right? Wrong.
[...]


 Your new post is loading...
Your new post is loading...
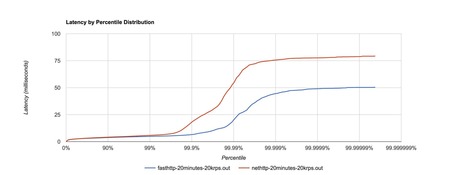




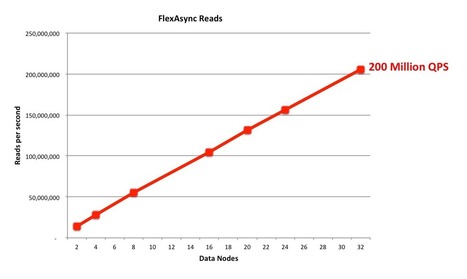

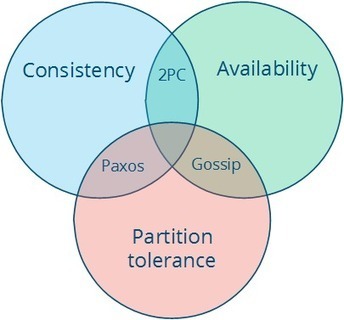

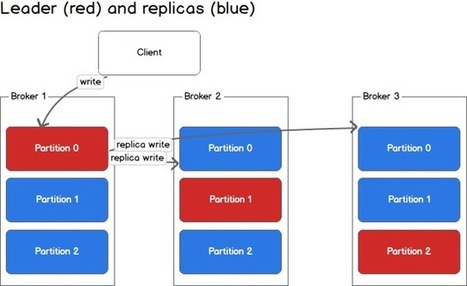







Nice reminder:
- availability doesn't only depends on the quality of the software, it also depends on the quality of the ops,
- and the probability of most of your nodes going down is not that unlikely, since machine clones will fail on the same bug