 Your new post is loading...

|
Scooped by
Charles Tiayon
July 18, 3:40 PM
|
This year, our free, virtual reading series gathers voices from across time zones for an international celebration! "This August we once again celebrate Women in Translation (#WiT) Month! This reading series was initiated by blogger Meytal Radzinski in 2014 to raise awareness of translated literature by women, queer, and nonbinary authors, and promote gender and cultural diversity in literary publishing. This year, our free, virtual reading series gathers voices from across time zones for an international celebration! Organized under the support of PEN America and the PEN America Translation Committee, these events bring together three panels of translators, joined by their authors, working in a diversity of languages. The readings will be followed by brief Q&A discussions. We hope you’ll join us for these one-of-a-kind bilingual readings! The Women in Translation Reading Series will take place on Zoom on August 7, 14, and 21, 2025. The conversations will be moderated by Nancy Naomi Carlson, Christina Daub, and Marguerite Feitlowitz. The August 14 session will be moderated by Marguerite Feitlowitz, with readings in Chinese (Taiwan), German, Portuguese (Brazil), Russian (Ukraine), and Vietnamese. Marguerite Feitlowitz has published five volumes of translations from French and Spanish, most recently Night, by Ennio Moltedo, Pillar of Salt: An Autobiography with Nineteen Erotic Sonnets, by Salvador Novo, and plays by Griselda Gambaro. She is the author of A Lexicon of Terror: Argentina and the Legacies of Torture."
https://pen.org/event/women-in-translation-month-reading-series-2025-session-2/
#metaglossia_mundus

Researchers across Africa, Asia and the Middle East are building their own language models designed for local tongues, cultural nuance and digital independence
"In a high-stakes artificial intelligence race between the United States and China, an equally transformative movement is taking shape elsewhere. From Cape Town to Bangalore, from Cairo to Riyadh, researchers, engineers and public institutions are building homegrown AI systems, models that speak not just in local languages, but with regional insight and cultural depth.
The dominant narrative in AI, particularly since the early 2020s, has focused on a handful of US-based companies like OpenAI with GPT, Google with Gemini, Meta’s LLaMa, Anthropic’s Claude. They vie to build ever larger and more capable models. Earlier in 2025, China’s DeepSeek, a Hangzhou-based startup, added a new twist by releasing large language models (LLMs) that rival their American counterparts, with a smaller computational demand. But increasingly, researchers across the Global South are challenging the notion that technological leadership in AI is the exclusive domain of these two superpowers.
Instead, scientists and institutions in countries like India, South Africa, Egypt and Saudi Arabia are rethinking the very premise of generative AI. Their focus is not on scaling up, but on scaling right, building models that work for local users, in their languages, and within their social and economic realities.
“How do we make sure that the entire planet benefits from AI?” asks Benjamin Rosman, a professor at the University of the Witwatersrand and a lead developer of InkubaLM, a generative model trained on five African languages. “I want more and more voices to be in the conversation”.
Beyond English, beyond Silicon Valley
Large language models work by training on massive troves of online text. While the latest versions of GPT, Gemini or LLaMa boast multilingual capabilities, the overwhelming presence of English-language material and Western cultural contexts in these datasets skews their outputs. For speakers of Hindi, Arabic, Swahili, Xhosa and countless other languages, that means AI systems may not only stumble over grammar and syntax, they can also miss the point entirely.
“In Indian languages, large models trained on English data just don’t perform well,” says Janki Nawale, a linguist at AI4Bharat, a lab at the Indian Institute of Technology Madras. “There are cultural nuances, dialectal variations, and even non-standard scripts that make translation and understanding difficult.” Nawale’s team builds supervised datasets and evaluation benchmarks for what specialists call “low resource” languages, those that lack robust digital corpora for machine learning.
It’s not just a question of grammar or vocabulary. “The meaning often lies in the implication,” says Vukosi Marivate, a professor of computer science at the University of Pretoria, in South Africa. “In isiXhosa, the words are one thing but what’s being implied is what really matters.” Marivate co-leads Masakhane NLP, a pan-African collective of AI researchers that recently developed AFROBENCH, a rigorous benchmark for evaluating how well large language models perform on 64 African languages across 15 tasks. The results, published in a preprint in March, revealed major gaps in performance between English and nearly all African languages, especially with open-source models.
Similar concerns arise in the Arabic-speaking world. “If English dominates the training process, the answers will be filtered through a Western lens rather than an Arab one,” says Mekki Habib, a robotics professor at the American University in Cairo. A 2024 preprint from the Tunisian AI firm Clusterlab finds that many multilingual models fail to capture Arabic’s syntactic complexity or cultural frames of reference, particularly in dialect-rich contexts.
Governments step in
For many countries in the Global South, the stakes are geopolitical as well as linguistic. Dependence on Western or Chinese AI infrastructure could mean diminished sovereignty over information, technology, and even national narratives. In response, governments are pouring resources into creating their own models.
Saudi Arabia’s national AI authority, SDAIA, has built ‘ALLaM,’ an Arabic-first model based on Meta’s LLaMa-2, enriched with more than 540 billion Arabic tokens. The United Arab Emirates has backed several initiatives, including ‘Jais,’ an open-source Arabic-English model built by MBZUAI in collaboration with US chipmaker Cerebras Systems and the Abu Dhabi firm Inception. Another UAE-backed project, Noor, focuses on educational and Islamic applications.
In Qatar, researchers at Hamad Bin Khalifa University, and the Qatar Computing Research Institute, have developed the Fanar platform and its LLMs Fanar Star and Fanar Prime. Trained on a trillion tokens of Arabic, English, and code, Fanar’s tokenization approach is specifically engineered to reflect Arabic’s rich morphology and syntax.
India has emerged as a major hub for AI localization. In 2024, the government launched BharatGen, a public-private initiative funded with 235 crore (€26 million) initiative aimed at building foundation models attuned to India’s vast linguistic and cultural diversity. The project is led by the Indian Institute of Technology in Bombay and also involves its sister organizations in Hyderabad, Mandi, Kanpur, Indore, and Madras. The programme’s first product, e-vikrAI, can generate product descriptions and pricing suggestions from images in various Indic languages. Startups like Ola-backed Krutrim and CoRover’s BharatGPT have jumped in, while Google’s Indian lab unveiled MuRIL, a language model trained exclusively on Indian languages. The Indian governments’ AI Mission has received more than180 proposals from local researchers and startups to build national-scale AI infrastructure and large language models, and the Bengaluru-based company, AI Sarvam, has been selected to build India’s first ‘sovereign’ LLM, expected to be fluent in various Indian languages.
In Africa, much of the energy comes from the ground up. Masakhane NLP and Deep Learning Indaba, a pan-African academic movement, have created a decentralized research culture across the continent. One notable offshoot, Johannesburg-based Lelapa AI, launched InkubaLM in September 2024. It’s a ‘small language model’ (SLM) focused on five African languages with broad reach: Swahili, Hausa, Yoruba, isiZulu and isiXhosa.
“With only 0.4 billion parameters, it performs comparably to much larger models,” says Rosman. The model’s compact size and efficiency are designed to meet Africa’s infrastructure constraints while serving real-world applications. Another African model is UlizaLlama, a 7-billion parameter model developed by the Kenyan foundation Jacaranda Health, to support new and expectant mothers with AI-driven support in Swahili, Hausa, Yoruba, Xhosa, and Zulu.
India’s research scene is similarly vibrant. The AI4Bharat laboratory at IIT Madras has just released IndicTrans2, that supports translation across all 22 scheduled Indian languages. Sarvam AI, another startup, released its first LLM last year to support 10 major Indian languages. And KissanAI, co-founded by Pratik Desai, develops generative AI tools to deliver agricultural advice to farmers in their native languages.
The data dilemma
Yet building LLMs for underrepresented languages poses enormous challenges. Chief among them is data scarcity. “Even Hindi datasets are tiny compared to English,” says Tapas Kumar Mishra, a professor at the National Institute of Technology, Rourkela in eastern India. “So, training models from scratch is unlikely to match English-based models in performance.”
Rosman agrees. “The big-data paradigm doesn’t work for African languages. We simply don’t have the volume.” His team is pioneering alternative approaches like the Esethu Framework, a protocol for ethically collecting speech datasets from native speakers and redistributing revenue back to further development of AI tools for under-resourced languages. The project’s pilot used read speech from isiXhosa speakers, complete with metadata, to build voice-based applications.
In Arab nations, similar work is underway. Clusterlab’s 101 Billion Arabic Words Dataset is the largest of its kind, meticulously extracted and cleaned from the web to support Arabic-first model training.
The cost of staying local
But for all the innovation, practical obstacles remain. “The return on investment is low,” says KissanAI’s Desai. “The market for regional language models is big, but those with purchasing power still work in English.” And while Western tech companies attract the best minds globally, including many Indian and African scientists, researchers at home often face limited funding, patchy computing infrastructure, and unclear legal frameworks around data and privacy.
“There’s still a lack of sustainable funding, a shortage of specialists, and insufficient integration with educational or public systems,” warns Habib, the Cairo-based professor. “All of this has to change.”
A different vision for AI
Despite the hurdles, what’s emerging is a distinct vision for AI in the Global South – one that favours practical impact over prestige, and community ownership over corporate secrecy.
“There’s more emphasis here on solving real problems for real people,” says Nawale of AI4Bharat. Rather than chasing benchmark scores, researchers are aiming for relevance: tools for farmers, students, and small business owners.
And openness matters. “Some companies claim to be open-source, but they only release the model weights, not the data,” Marivate says. “With InkubaLM, we release both. We want others to build on what we’ve done, to do it better.”
In a global contest often measured in teraflops and tokens, these efforts may seem modest. But for the billions who speak the world’s less-resourced languages, they represent a future in which AI doesn’t just speak to them, but with them."
Sibusiso Biyela, Amr Rageh and Shakoor Rather
20 May 2025
https://www.natureasia.com/en/nmiddleeast/article/10.1038/nmiddleeast.2025.65
#metaglossia_mundus

"NAAV AI, co-founded by author-historian Vikram Sampath, blends modern technology and literary depth to bridge language gaps, ensuring readers have access to long-form content in the language of their comfort
Vikram Sampath
Anjali Ram
Updated on:
23 Jul 2025, 1:30 am
In this digital era, it is nearly impossible to turn a blind eye to the technological advances and the emergence of artificial intelligence (AI) in every sector. Though gradually, the publishing industry too is doing its share of experiments to adapt to the new change.
One such revelation in the sector, leveraged by the technology, is NAAV AI (Navigating AI across Vocabularies). Co-founded by author and historian Vikram Sampath and technologist Sandeep Singh, the project aims to bridge the language gap in India, making literary content accessible to readers across the country.
According to Sampath, the idea for NAAV AI was born out of his personal experience with book translations. “It takes eight to nine months to translate a book, and by the time it is published, the buzz around the book would have been lost,” he says, highlighting the challenges of conventional translation methods.
“Today, there is a huge demand, particularly in the regional language space – be it books or podcasts. About five to six per cent of Indians consume content in English, whereas a survey that was done earlier says around 98 per cent of Internet users in India consume content in regional languages. The supply is not just to meet the demand, but to cater to those who prefer consuming content in their mother tongue or language of comfort,” he notes.
Sampath also stresses the importance of translation and literature travelling beyond the language barrier, stating, “Today, we have Banu Mushtaq, who otherwise was probably not an author beyond Karnataka. Kannada language is now being recognised globally, and that is the power of translation.
But is AI enough to do the job? Sampath emphasises the role of human interference in the process of translation, stating, “When it comes to literature and creative spaces, it can’t be completely left to the machine or the AI to derive meaning.”
For him, this is a point where creativity meets technology, where having a human in the loop preserves the cultural nuances of the context. “Translation using AI is like teaching a child to speak a language. As more books come in the pipeline, language experts will start getting better, but at no point will human being in the loop ever vanish because it’s a creative process, he says, adding, “We have hired professional translators, linguists and language experts who will go through these books line by line and then come out with corrections.”
According to him, AI in the publishing and translation industry is a tool that can enhance productivity by assisting rather than replacing human labour and creativity. “What AI is doing here is not replacing the translators, but improving efficiency and productivity. If one was taking them six months to finish, now, with AI assistance, they will be able to complete it in four weeks,” he explains.
Sampath sees AI as an enabling tool and believes there is no escaping it. “AI is the future. It should be seen as an enabling tool and not as a threat to anybody. And the humans should ensure that a safe culture is maintained for it and the creative element is not taken away,” he says.
How does NAAV AI work?
According to the co-founder and technologist Sandeep Singh, NAAV AI supports multiple regional languages using a multimodel approach. “We use a multi-model approach where there are a lot of models, like cloud GPT. We have served on the Critter and other Indian LLM models as well. We are also doing refinement of these models because, as we review these books as part of this entire process, the language experts review them initially as they get to read the first draft and make corrections. If they find that a certain sentence is not communicating or it’s not readable, they replace that word,” says Singh, adding, “This feedback, which they provide, will be collected in a data set which is used for the refinement of the model. So each time this creates a large corpus of data, it is used for future translations to improve certain aspects of the context and other nuances. At present, with humans, the AI and the right selections of the model, it is ensured that the end outcome has all the required elements.”"
https://www.newindianexpress.com/cities/bengaluru/2025/Jul/23/translaiting-narratives-historian-vikram-sampath-on-his-ai-translation-platform
#metaglossia_mundus

"After 20 years, Mary Jo Bang has completed her translation of Dante's 'Divine Comedy'
JULY 24, 2025 3:00 AM ET
About 20 years ago, Mary Jo Bang read a poem that inspired her to take on a translation of Dante's Divine Comedy. At first, she began with just three lines – but two decades later, she's completed all three parts: "Inferno," "Purgatorio" and "Paradiso." In today's episode, she joins NPR's Ari Shapiro for a conversation about translating Dante into contemporary language, why English is a "rhyme-poor" language, and the parallels between Dante's journey and her own.
To listen to Book of the Day sponsor-free and support NPR's book coverage, sign up for Book of the Day+ at plus.npr.org/bookoftheday"
https://www.npr.org/2025/07/24/1256157840/nprs-book-of-the-day-mary-jo-bang-paradiso
#metaglossia_mundus
"NEW YORK, July 23, 2025 /PRNewswire/ -- DeepL, a leading global Language AI company, today announced several updates to its live speech translation solution, DeepL Voice, including expanded language support and advanced meeting productivity features, with Zoom Meetings integration coming soon. As adoption accelerates among enterprises such as Inetum, Cybozu and Brioche Pasquier, these enhancements further position DeepL Voice as an essential solution for seamless multilingual communication in today's global workplace.
DeepL Voice for Zoom
"Global businesses can't afford to be slowed down by language barriers. That's why over 200,000 business customers trust DeepL to help them communicate clearly every day," said Jarek Kutylowski, CEO and Founder of DeepL. "These new updates to DeepL Voice enable teams to communicate in additional languages, including Mandarin Chinese, and stay productive with easy access to post-meeting transcripts and translations. And with upcoming availability on Zoom Meetings, we're making real-time, multilingual communication even more seamless, accessible and impactful for global teams."
Language barriers create daily friction for global businesses – nearly 70% report operational issues caused by language gaps in areas like internal collaboration, customer service and IT, and 61% say these challenges have slowed or limited their international growth. Launched in November 2024, DeepL Voice addresses this challenge by empowering multilingual speech translation in real time, both virtually and in person. DeepL Voice for Meetings provides translated captions during virtual meetings, while DeepL Voice for Conversations offers instant speech translation on mobile for dynamic face-to-face interactions.
Today's updates unlock even more capabilities for DeepL Voice, including:
Expanded language coverage: DeepL Voice now supports spoken input in three additional languages – Mandarin Chinese, Ukrainian, and Romanian – adding to its existing lineup (English, German, Japanese, Korean, Swedish, Dutch, French, Turkish, Polish, Portuguese, Russian, Spanish and Italian). Translated captions are available in 35 languages supported by DeepL Translator, with new additions Vietnamese and Hebrew.
Enhanced meeting productivity features: Full transcripts and translations from meetings to streamline notes, minutes and follow-up tasks can be downloaded with dedicated admin controls to maintain enterprise-level security and compliance.
In addition, DeepL Voice for Meetings will soon be available for Zoom Meetings, expanding beyond its existing Microsoft Teams integration to make multilingual communication accessible on one of the world's most widely used virtual meeting platforms. For in-person interactions, DeepL Voice for Conversations continues to be available on iOS and Android.
Amid this momentum, DeepL Voice is gaining traction among global enterprises such as Inetum, Cybozu and Brioche Pasquier, who are integrating the solution to break down language barriers and accelerate collaboration. Inetum, a global IT consultancy with nearly 28,000 employees in 19 countries, leverages DeepL Voice to assign consultants based on expertise rather than language fluency, ensuring the right skills are matched to the right projects and strengthening international teamwork...
For more information on DeepL Voice, visit https://www.deepl.com/products/voice.
About DeepL
DeepL is on a mission to break down language barriers for businesses and individuals everywhere..."
DeepL
Jul 23, 2025, 08:00 ET
https://www.prnewswire.com/news-releases/deepl-expands-real-time-voice-translation-capabilities-with-new-features-and-upcoming-zoom-integration-302511788.html
#metaglossia_mundus

"PUBLISHED: JULY 21, 2025
FRED ROCAFORT
Table of Contents
Foreign Equivalents and Indigenous Languages in U.S. Trademark Law
Why Wawa’s “Wild Goose” Roots May Not Matter to Trademark Law—But Should
Understanding the Doctrine of Foreign Equivalents
Common Foreign Language Equivalents—and Why They Matter
Wawa’s Trademark History: Inconsistent Translation Disclosures
The Strategic Implications of Wawa’s Trademark Disclosures
Why the USPTO Didn’t Require a Translation
The Obscure Language Exception
Geographic Significance Override
Examiner Knowledge Limitations
Could Wawa Block a “Wild Goose” Trademark?
Language Familiarity Requirements Not Met
Wawa’s Historical Enforcement Strategy
Market Context Analysis
Indigenous Languages and Trademark Law: A Larger Blind Spot
Cultural Sensitivity and Brand Authenticity
Legal Consistency and Trademark Strategy
Language Preservation and Doctrinal Blind Spots
Best Practices for Registering Indigenous or Minority Language Brand Names
Strategic Trademark Takeaways
Foreign Equivalents and Indigenous Languages in U.S. Trademark Law
Why Wawa’s “Wild Goose” Roots May Not Matter to Trademark Law—But Should
When Wawa convenience stores opened several new locations in my city, I couldn’t help but shift into trademark lawyer mode, especially after discovering that the name “Wawa” has Native American linguistic origins.
The brand name “Wawa” traces back to a Native American word meaning “wild goose.” The town of Wawa, Pennsylvania, from which the company takes its name, is believed to derive from either the Lenape word for “wild goose” or the Ojibwe term for “snow goose.” This detail places Wawa’s trademark in interesting legal territory.
The Wawa trademark raises a key question under U.S. trademark law: Could the USPTO’s doctrine of foreign equivalents apply to brand names derived from indigenous languages like Lenape or Ojibwe? And more specifically, could this doctrine impact Wawa’s trademark rights in ways not immediately obvious?
Understanding the Doctrine of Foreign Equivalents
The doctrine of foreign equivalents is a foundational principle in U.S. trademark law. It’s designed to prevent consumer confusion between trademarks that appear in different languages but convey the same meaning. According to Section 1207.01(b)(vi) of the United States Trademark Manual of Examining Procedure (TMEP)—the USPTO’s official guidance for trademark examiners— the doctrine applies when all three of the following conditions are met:
The foreign word comes from a language familiar to an appreciable segment of American consumers.
The foreign word and its English equivalent are substantially similar in meaning.
The goods or services associated with the marks are related enough to create a likelihood of confusion.
Common Foreign Language Equivalents—and Why They Matter
Several decisions by the USPTO’s Trademark Trial and Appeal Board (TTAB) illustrate how the doctrine of foreign equivalents is applied in real-world trademark disputes:
Buenos Dias vs. Good Morning: These marks create identical commercial impressions for Spanish-speaking consumers, increasing the likelihood of confusion over sponsorship or source.
El Sol vs. Sun: With equivalent meaning and widespread familiarity, this pairing may confuse consumers in the marketplace.
Casa vs. House: A direct translation that bilingual consumers would immediately recognize as synonymous—creating clear overlap in perception.
The USPTO most frequently invokes the doctrine of foreign equivalents in trademark disputes involving widely spoken languages—particularly Spanish, French, German, Chinese, and Japanese. These languages are considered sufficiently familiar to large segments of the U.S. population to trigger the doctrine’s application.
Wawa’s Trademark History: Inconsistent Translation Disclosures
Wawa’s own treatment of its brand’s Native American linguistic origin has shifted over time, with varying degrees of transparency in its federal trademark filings:
1969: Described “Wawa” simply as “an American Indian word.”
2015: Explicitly acknowledged that “Wawa” translates to “wild goose” in the Lenni-Lenape language.
2024: Filed a new design mark application for, with no reference to its linguistic origin or a translation.
The Strategic Implications of Wawa’s Trademark Disclosures
This inconsistency raises strategic questions. Was the absence of a translation in the 2024 Wawa trademark application a deliberate effort to avoid scrutiny under the doctrine of foreign equivalents? Or was it a procedural oversight during the application process?
Either way, the lack of consistency could have implications in future trademark challenges, particularly if linguistic origin becomes relevant in opposition or cancellation proceedings.
Why the USPTO Didn’t Require a Translation
Why didn’t the USPTO flag Wawa’s 2024 filing for failure to include a translation of the word “Wawa”? The likely answer lies in a combination of well-established examination principles and practical realities:
The Obscure Language Exception
According to TMEP §809.01(a)(ii), it is “generally not necessary to translate words from dead or obscure languages.” With fewer than 200 fluent Lenape speakers—many of whom live outside the United States—the language likely falls below the threshold of familiarity required to trigger translation under USPTO rules.
Geographic Significance Override
Trademark examiners often treat terms like “Wawa” as geographic references—particularly when derived from U.S. place names. This approach mirrors how the USPTO handles other locations with Native American names, such as Chicago or Kalamazoo. In these cases, the geographic origin typically overrides any linguistic significance for examination purposes.
Examiner Knowledge Limitations
The examining attorney may simply have been unaware of the term’s Native American roots. Although USPTO examiners rely on robust databases and internal search tools, they are not required to possess encyclopedic knowledge of indigenous languages—especially those considered obscure or endangered.
Could Wawa Block a “Wild Goose” Trademark?
Could Wawa’s existing trademark registrations prevent someone from registering a mark like Wild Goose or Snow Goose?
Almost certainly not. The doctrine of foreign equivalents wouldn’t apply here, for several reasons:
Language Familiarity Requirements Not Met
The doctrine of foreign equivalents only applies when the foreign term originates from a language familiar to an appreciable segment of American consumers. Lenape and Ojibwe—though culturally significant—are not widely spoken in the United States today. With very few fluent speakers and limited public familiarity, these languages fall outside the scope of the doctrine as interpreted by the USPTO and the TTAB.
Wawa’s Historical Enforcement Strategy
A review of Wawa’s trademark opposition history shows that the company primarily targets marks that are phonetically or visually similar to “Wawa.” There’s no pattern of opposing marks that are conceptually or linguistically related. In fact, Wawa has not acted against any trademarks referencing geese or goose-related terminology.
So, while Wawa is an active enforcer of its brand, it appears unlikely that a “Wild Goose” mark would ruffle its feathers.
Market Context Analysis
Even if a third party filed for a Wild Goose trademark, the USPTO’s likelihood of confusion analysis would take several additional factors into account—such as the industry, class of goods or services, channels of trade, and consumer sophistication. Unless the applied-for mark overlaps significantly with Wawa’s business scope or branding, a successful opposition would be unlikely.
Indigenous Languages and Trademark Law: A Larger Blind Spot
Wawa’s trademark filings offer a telling example of how U.S. trademark law has historically treated indigenous languages—and where the system may still be falling short. Beyond this single case, the implications for brands and legal practitioners are significant.
Cultural Sensitivity and Brand Authenticity
While there is no legal obligation to disclose the cultural or linguistic origins of a brand name, doing so can signal respect and cultural awareness. For brands with indigenous language roots, thoughtful acknowledgment may enhance both authenticity and consumer trust—especially in an era of increasing scrutiny over cultural appropriation.
Legal Consistency and Trademark Strategy
Inconsistent translation disclosures across trademark filings can create ambiguity. Disparities in how language origins are disclosed—or not—may lead to confusion during examination and could impact how future examiners or third-party challengers interpret the mark’s scope or validity. Over time, such inconsistencies may weaken a brand’s overall IP posture.
Language Preservation and Doctrinal Blind Spots
Classifying indigenous languages as “obscure” within the trademark system may be procedurally convenient, but it also raises difficult questions. What role should trademark law play in acknowledging or preserving linguistic heritage? And how might the legal categorization of indigenous languages—as too unfamiliar to matter—contribute, however unintentionally, to broader cultural erasure?
Best Practices for Registering Indigenous or Minority Language Brand Names
For companies and individuals seeking to register trademarks that incorporate indigenous or minority language terms, it’s important to approach the process with a thoughtful blend of legal strategy, linguistic accuracy, and cultural awareness. The following best practices can help reduce legal risk and build stronger, more respectful brand identities:
Research linguistic origins thoroughly
Don’t rely solely on assumptions or surface-level meanings. Investigate the word’s etymology, historical usage, and cultural significance—especially if the term comes from a language not widely spoken in the U.S.
Be consistent in translation disclosures
If you choose to disclose the meaning or origin of a term in one trademark application, consider doing so consistently across related filings. Inconsistencies can raise red flags or complicate enforcement down the road.
Document your rationale for disclosure decisions
Whether you opt to include or omit a translation, keep a clear internal record explaining the decision. This can be valuable if the application is challenged or if the USPTO later requests clarification.
Respect cultural context, not just legal checkboxes
Even if the USPTO doesn’t require a translation or cultural explanation, acknowledging the significance of the term can enhance brand credibility and reduce reputational risk—especially with communities connected to the language.
Monitor the trademark landscape
Keep an eye on how similar linguistic elements are being used—or challenged—by other applicants. Trends in examiner treatment or third-party opposition can help shape smarter filing strategies.
Strategic Trademark Takeaways
Wawa’s case underscores a growing tension in trademark law—where legal doctrine intersects with cultural identity.
The doctrine of foreign equivalents remains a powerful tool for evaluating marks in widely spoken languages—but its application becomes murky when it comes to underrepresented or endangered languages.
The USPTO’s reliance on examiner discretion and the “obscure language” exception creates inconsistencies in how Native American languages and other minority languages are treated.
For brand owners, this presents both a risk and an opportunity. And for legal practitioners, it reinforces the importance of thoughtful, culturally informed strategy.
Trademarks aren’t just legal designations—they can be cultural signals. In cases like this, what the law doesn’t require may still matter. If you need guidance on protecting culturally significant or linguistically complex trademarks, our experienced trademark team can help. We provide strategic counsel on U.S. and international trademark prosecution, enforcement, and brand development."
https://harris-sliwoski.com/blog/united-states-trademarks-foreign-equivalents-and-indigenous-languages/
#metaglossia_mundus
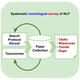
"...Natural language processing (NLP) methods have advanced rapidly, yet research remains centered on English, followed by a handful of well-supported languages, while many others receive only moderate, limited, or no support. This imbalance affects the adaptability of language technologies across diverse linguistic and cultural contexts. Comprehensive monolingual NLP surveys—those covering the full spectrum of NLP tasks—offer a structured way to assess language-specific challenges, resource availability, and methodological trends, yet no standardized framework exists for conducting these surveys. We introduce a generalizable methodology for systematic monolingual NLP surveys, which ensures transparency and reproducibility. The method can be extended to other languages with similar challenges, ultimately contributing to a more inclusive and equitable NLP landscape.
Summary
Comprehensive monolingual natural language processing (NLP) surveys are essential for assessing language-specific challenges, resource availability, and research gaps. However, existing surveys often lack standardized methodologies, leading to selection bias and fragmented coverage of NLP tasks and resources. This study introduces a generalizable framework for systematic monolingual NLP surveys. Our approach integrates a structured search protocol to minimize bias, an NLP task taxonomy for classification, and language resource taxonomies to identify potential benchmarks and highlight opportunities for improving resource availability. We apply this framework to Greek NLP (2012–2023), providing an in-depth analysis of its current state, task-specific progress, and resource gaps. The survey results are publicly available and are regularly updated to provide an evergreen resource. This systematic survey of Greek NLP serves as a case study, demonstrating the effectiveness of our framework and its potential for broader application to other not-so-well-resourced languages as regards NLP."
A systematic survey of natural language processing for the Greek language
Authors
Juli Bakagianni
Kanella Pouli
Maria Gavriilidou
John Pavlopoulos
Highlights
Greek is moderately supported in NLP
Monolingual language models (LMs) are preferred over multilingual ones
Task-specific trends differ notably from global trends
Received 3 February 2025, Revised 17 March 2025, Accepted 6 June 2025, Available online 21 July 2025.
Cite
https://doi.org/10.1016/j.patter.2025.101313
https://www.sciencedirect.com/science/article/pii/S2666389925001618
#metaglossia_mundus

"Imagine speaking a language that only your grandparents understand, where every conversation might be one of the last of its kind. UNESCO operates with four levels of language endangerment between “safe” (not endangered) and “extinct” (no living speakers), based on intergenerational transfer, and the most critically endangered languages have reached a heartbreaking crossroads. These linguistic treasures represent entire worlds of knowledge, culture, and human experience that could vanish within a generation.
3,193 languages are endangered today, but some teeter on the absolute edge of extinction. Here is a list of 16 languages where fewer than 100 people still carry the torch of their ancestors’ voices.
Hidden in the rainforests of Malaysia, Jedek managed to stay completely unknown to linguists until 2017. Only about 280 people speak this Aslian language, making it a remarkable recent discovery in our modern world.
Think of it like finding a new species in your backyard—except this ‘species’ carries centuries of human culture and wisdom that was almost lost forever.
The N|uu language of South Africa represents one of the world’s last connections to the original click languages of the Khoisan people. With fewer than 10 native speakers remaining, most of whom are elderly women, N|uu faces imminent extinction.
The language contains sounds that don’t exist in most other languages—imagine trying to preserve music when only a handful of people remember the notes.
Like Go2Tutors’s content? Follow us on MSN.
Once spoken across the islands of Tierra del Fuego, Yagan now exists in the memories of perhaps three people in Chile. The language belongs to the Fuegian family and carries within it the seafaring traditions of a people who navigated the treacherous waters at the bottom of South America for thousands of years.
Each remaining speaker holds an entire library of maritime knowledge that took generations to accumulate.
Deep in the Peruvian Amazon, Taushiro has dwindled to a single known speaker, Amadeo García García, who has spent decades as the sole keeper of his people’s language. When he speaks Taushiro, he’s essentially having a conversation with history itself.
The language contains detailed knowledge about rainforest ecology and traditional medicine that can’t be found anywhere else.
Another Amazonian language from Peru, Resígaro now lives in the minds of fewer than 20 people. The language family it belongs to—Arawakan—once spread across much of South America, but colonization and cultural assimilation have reduced most of these languages to whispers.
Resígaro speakers carry stories of river navigation and forest survival that guided their ancestors for millennia."
ACE VINCENT
https://go2tutors.com/16-languages-spoken-by-fewer-than-100-people/
#metaglossia_mundus

"With the latest addition to Mango AI’s toolset, users can now translate videos online for free, featuring natural voice dubbing and accurate subtitle translation in over 120 languages.
Mango AI, a popular AI video creation platform, has officially launched its AI video translator that allows users to translate videos online free and dub video with auto voice and subtitles in over 120 languages. Developed with cutting-edge artificial intelligence, the platform offers fast, accurate, and lip-synced translations for easy content localization.
The AI-powered video translator simplifies multilingual video production. Users can upload any video file that contains at least five seconds of voiceover and select the language of their choice. The rest is handled by the AI. Automatic transcription, translation, and dubbing are performed on the platform, and then the new audio track is synced with natural lip sync and accurate subtitle positioning. This enables users to translate videos online free without complex tools or expensive software.
From Spanish and Japanese to Arabic, Portuguese, and French, Mango AI supports over 120 languages, providing a platform for creators and enterprises to reach various individuals in multiple geographies. Whether the translation is an explainer video, training material, marketing ad, tutorial, or learning course, the tool ensures voice and subtitle synchronization to organically boost credibility and audience engagement. The ability to translate videos online free makes this ideal for both professionals and casual users.
One of the strongest features of the AI video translator is its advanced voice synthesis. Instead of robotic or monotonous narration, the tool offers realistic AI-generated voices that sound natural and contextually expressive. Users can choose between AI voices in multiple languages or apply free AI voice cloning to preserve the speaker’s original voice in the translated version. Combined with automatic lip-sync technology, these options ensure that translated videos maintain professional quality and emotional depth across languages.
In addition to the capability to translate videos online free, Mango AI offers a range of other AI-powered tools designed to support diverse content creation needs. “With Mango AI, users can create live portraits, cartoonize videos, generate singing photos, and explore a wide range of other creative possibilities. This comprehensive toolset not only empowers users to bring their ideas to life but also reflects our ongoing commitment to simplifying and enhancing creative workflows,” says Winston Zhang, CEO of Mango Animate.
CONTACT
Michelle Fisher
+86 020-61972665
https://mangoanimate.com/ai";
Hong Kong, China (PRUnderground) July 22nd, 2025
https://www.prunderground.com/mango-ai-empowers-users-to-translate-videos-online-free-with-efficiency/00356925/
#metaglossia_mundus
"ABSTRACT: This study examines the interaction between language, culture, and observer viewpoints using a combined emic (functional, insider) and etic (morphological,outsider) framework. Utilising a functional-formal ethnographic methodology, we investigate how linguistic processes are influenced by cultural context, speaker identity, and interpretive frameworks. Qualitative data were gathered through semi-structured interviews with local participants (emic) and processed in conjunction with researcher observations (etic), employing thematic content analysis to discern patterns in meaning-making. Research indicates that language functionality is actively negotiated through three principal intersections: (1) cultural schemas inherent in speech, (2) performative identity indicators, and (3) observer positioning (insider/outsider dichotomies). The investigation combines methodologies from linguistic anthropology and sociolinguistics, presenting a new analytical framework for ethnographic language studies and adding to discussions on cultural relativity in pragmatics and intersubjective meaning formation."
A functional-formal ethnographic investigation in linguistics utilising emic and etic concepts: a qualitative analysis
Murat Demirekin
Received 06 Jul 2025, Accepted 09 Jul 2025, Published online: 17 Jul 2025
https://www.tandfonline.com/doi/full/10.1080/01434632.2025.2533876?mi=5z11g9
#metaglossia_mundus
"Large language models, such as ChatGPT, perform significantly less well in Portuguese than in English despite both languages being spoken worldwide. This gap has now been closed with "GigaVerbo." The team led by Dr. Nicholas Kluge Corrêa from the Center for Science and Thought at the University of Bonn is now presenting the project in the journal Patterns. The researchers were among the first to utilize the new "Marvin" supercomputer at the University of Bonn. Nicholas Kluge Corrêa and his colleague Aniket Sen are both members of the Transdisciplinary Research Area "Sustainable Futures" at the University of Bonn.
GigaVerbo is the name of the dataset developed by the researchers. The project "Tucano: Advancing Neural Text Generation for Portuguese" aims to bridge the resource gap in Portuguese natural language processing (NLP) by providing high-quality datasets and cutting-edge language models specifically designed for the Portuguese language.
The development and release of the GigaVerbo corpus, comprising 200 billion deduplicated tokens, along with the Tucano family of models, aims to foster progress in neural text generation in an open and reproducible manner, promoting equitable access.
The researchers collected several Portuguese corpora from different sources to ensure high linguistic diversity and quality. These corpora were then deduplicated and filtered to form the GigaVerbo dataset. Using this dataset, they trained several decoder models on the Marvin supercomputer, which followed rigorous evaluation and optimization cycles.
The project addresses two major gaps: first, the scarcity of comprehensive open-source resources for Portuguese, a language often overshadowed by resource-rich languages like English. Second, the deficiency in open-source LLM development, which impedes the scientific reproducibility of these models.
The researchers are currently working to scale up their developments in Portuguese by improving their dataset and training larger models. They are also currently developing resources for other low-resource languages, such as Bengali and Hindi, all thanks to Marvin and the University of Bonn."
by University of Bonn
edited by Gaby Clark, reviewed by Andrew Zinin
https://techxplore.com/news/2025-07-dataset-boost-portuguese-language-ai.html
#metaglossia_mundus

"Dans les relations internationales complexes d’aujourd'hui, le langage et la traduction jouent un rôle inattendu. Nous pouvons penser que la traduction ne fait que transmettre fidèlement l’original, mais la réalité est loin d’être aussi simple. Aujourd'hui, nous allons explorer comment le Parti Communiste Chinois (PCC) utilise la « diplomatie de la traduction » pour mener une « guerre de l’information » et une « guerre d'opinion » silencieuses à l’échelle mondiale. Beatrice Gallelli travaille avec plusieurs chercheurs pour analyser comment le discours officiel que Pékin propose pour soutenir sa vision des relations interdétroit est en fait ajusté, re-modifié, ou re-façonné pour le public international."
Radio Taiwan International (RTI) est une station de radio publique de la République de Chine de Taiwan. Emettant la voix de Taiwan à travers le monde en 14 langues, les programmes de RTI couvrent des thèmes tels que la démocratie, les arts, la culture, la société et léconomie.
https://www.rti.org.tw/fr/programnews?uid=4&pid=81450
#metaglossia_mundus

"...El legado de un gran traductor
Uno de los aportes más destacados de Aulicino fue su trabajo como traductor. Entre sus traducciones más importantes se encuentran:
“La Divina Comedia” de Dante Alighieri (en una edición completa de los tres libros en 2015, y previamente “Infierno” en 2011).
Uno, ninguno y cien mil de Luigi Pirandello (2014).
Una selección de poemas de Pier Paolo Pasolini (2016).
Además de estos, Aulicino tradujo obras de importantes autores italianos como Eugenio Montale, Cesare Pavese, Sandro Penna, Antonella Anedda y Biancamaria Frabotta.
Como poeta, Aulicino publicó 26 libros de poemas. Su obra poética fue tan relevante que se realizaron dos ediciones completas de sus poemas: Estación Finlandia. Poemas reunidos 1974-2011, publicada por Bajo la luna en 2012, y Poesía reunida, editada por Ediciones en Danza en 2020. También creó el blog de poesía Otra Iglesia es Imposible.
Reconocimientos a su carrera
La vasta trayectoria de Jorge Aulicino fue reconocida con varios premios y distinciones:
Premio a la Trayectoria de la Biblioteca Nacional en 2014.
Premio Nacional de Poesía en 2015.
Diploma al Mérito Konex en la categoría de Periodismo Literario en 2017.
La partida de Jorge Aulicino representa una gran pérdida para el panorama literario y periodístico, pero su obra y su incansable labor como promotor de la cultura perdurarán."
Falleció este lunes a sus 75 años. Lo que se sabe.
Por Redacción La Voz
https://www.lavoz.com.ar/espectaculos/fallecio-jorge-aulicino-poeta-periodista-y-traductor-de-la-divina-comedia/
#metaglossia_mundus

"Daniel Hall, 21/07/2025: "Do you need a copy of a translation certified by a notary?
How do you organize the process as quickly as possible? Our article will help you before searching for services.
Not all people understand what a notarized translation means or how it differs from a regular or certified version. We will give you basic information about the intricacies of choosing a service, the requirements of different countries, and when you will definitely need a notarized copy.
What is a Notarized Translation: Main Points
A notarized translation is the work of a translator on the text of a document, which is then certified by a notary. Remember that the notary does not check the quality of the translation for accuracy, design, or compliance. His task is to endorse the identity of the translator and his signature. With his seal, he confirms that a specific person with knowledge of languages performed the work. The translator bears legal responsibility for the quality of the provided text. Key stages of notarized translation that you should know:
Work with the text is carried out by a qualified specialist.
The translator signs his statement about the accuracy of the translation and the quality of the final version.
The notary certifies the signature and applies the appropriate seal in the presence of the translator (or a representative of the agency).
The notarization is filed with the translation and the original version of the text.
Here are the main steps. Now that you know what the work can look like, you can check its important components.
Cases When It Is Worth Ordering a Notarized Translation
Below, we will consider typical cases when you will be asked to add a notary seal. Remember that different countries have their requirements.
Immigration and Visa
In developed and popular countries, government specialists will sometimes ask for a notarized translation and sometimes certification when applying for a long-term visa or residence permit. This situation is not uncommon if you are planning to move to the EU, Canada, Great Britain, Australia, or the USA.
Registration in Foreign Educational Institutions
Some universities require students to have notarized versions of certificates. The same rule applies to certificates with grades, diplomas, and academic transcripts to confirm the education already received.
Legal Situations
A notary seal allows the translated document to gain legal force. However, it is not suitable in every case. Some situations require a certified file. This service is also provided by popular translation agencies such as Rapid Translate.
Marriage Registration, Real Estate Transactions, Birth of Children
A notarized translation may be mandatory in cases such as marriage, birth certificate, or apartment purchase. It ensures the legality of the final version and makes the documents official at the state level.
Where and How to Look for a Notarized Translation
There are two main ways: through a translation agency or by searching for each service separately. The first option is in great demand because it is convenient and fast, and the price is not very different.
Professional agencies... also provide other services, such as certified documents. You may need it in combination with a notary translation. Large companies only cooperate with certified notaries, and the work is well-established, so the process is as fast as possible.
Advantages of ordering from an agency:
No need to search and personally go to a notary.
Minimization of the risk of errors due to the experience of both parties.
Fast order processing.
The ability to do everything online.
The second option is to order a freelance translator, draw up a statement of accuracy, and certify it with a notary. Remember that a notary is not always familiar with this procedure. A specialist may also refuse to approve the signatures of translators who do not have a license.
Features of Notarized Translation in Different Countries
Let's look at the options where the requirements are the most complex.
USA: A notary seal is not required for USCIS. You can simply make a certified document. The service may be required only for courts or when drawing up powers of attorney and purchasing real estate. Each case should be considered individually.
Canada: In some provinces, legal and educational documents require certification with a seal.
Top EU countries (Germany, France, Spain): These often require a sworn translation—a separate type of documentation. However, a notarized translation may also be needed and may be an intermediate solution.
It is good to cooperate with an experienced and large agency, where specialists of different profiles know the requirements of various countries. Please note that for medical, legal, or technical texts, you may need the services of a narrow-profile specialist who understands the terminology and abbreviations. Another advantage of cooperating with large agencies like Rapid Translate is that you will always have a lot of specialists to choose from.
What You Need to Place an Order
We will tell you how to prepare properly so the process does not drag on. Collecting the necessary things is often a constant hassle. Proper preparation will eliminate errors.
We advise you to collect the following points in advance:
The original certificate, diploma, or other document. A notarized copy will also do.
Personal information. You will indicate it when filling out the translation application. A passport will do.
Clarify the required language. Also, tell the specialist which country you will send the finished version to.
We wish you the fastest possible achievement of your goals abroad. We hope you have figured out the main features of a notarized translation and can order it without space."
https://www.bbntimes.com/companies/what-is-a-notarized-translation-features-of-countries-when-it-is-useful-how-to-search
#metaglossia_mundus
"AI Search Is Growing More Quickly Than Expected
Large language models aren’t replacing traditional browsers anytime soon, but they have become another responsibility for brands
By
Patrick Coffee
Chatbots are becoming the go-to source for online answers for many consumers, chipping away at the dominance of traditional web search and adding another avenue of outreach that brands must cultivate to connect with customers.
An estimated 5.6% of U.S. search traffic on desktop browsers last month went to an AI-powered large language model like ChatGPT or Perplexity, according to Datos, a market intelligence firm that tracks web users’ behavior.
That pales beside the 94.4% that still went to traditional search engines like Alphabet’s Google or Microsoft’s Bing, which have tried to fight off the new competition by adding artificial intelligence summaries to the top of their search results.
But the percentage of traffic that went to browser-based AI search has more than doubled since June 2024, when it was 2.48%, according to Datos, which is part of marketing software company Semrush. It has more than quadrupled since January 2024, when the figure was just under 1.3%.
CMO Today delivers the most important news of the day for media and marketing professionals.
Datos says it draws its data from more than 10 million panelists worldwide who agree to have their behavior on desktop browsers observed anonymously in exchange for rewards such as free access to software products from the company’s partners. The numbers exclude activity on mobile browsers and apps including those from OpenAI’s ChatGPT and Google.
The rapid growth in AI searches could mark a sea change in online behavior comparable to the emergence of Google’s web browser and the first social-media platforms, according to Eli Goodman, chief executive and co-founder of Datos.
The numbers are more striking among so-called early adopters, or consumers who had already started using LLMs in desktop browsers when Datos began tracking their behavior in April 2024.
Forty percent of desktop browser visits among these early adopters went to LLMs, up from just over 24% in June 2024, Datos research found. Traditional search engines’ share of the desktop browser traffic from these early adopters fell significantly in the same period, to 61% in June from around 76% a year earlier.
The amount of time that consumers worldwide spent on traditional search apps and websites declined 3% from April 2024 to April 2025, according to a report released last month by market research firm Sensor Tower. The drop was twice as high among early adopters, defined as people who first downloaded ChatGPT in 2023, the report said.
Use of Google’s traditional search product is still growing, and the AI overviews that now appear on Google searches are leading to more queries that connect consumers to businesses, a Google spokeswoman said.
The growth in AI searches, plus the appearance of AI overviews in traditional search browsers, is likely to further depress search traffic to the websites where brands have long directed energy, resources and search advertising, according to Neil Vogel, CEO of Dotdash Meredith, the publisher of magazine and digital brands including People and Better Homes & Gardens.
Organic search traffic to large news sites such as Business Insider, the Washington Post and HuffPost has fallen by large margins over the past three years, a drop publishers blame on AI responses that fulfill searchers’ curiosity without requiring a click.
Marketers in response are racing to make sure their names show up in AI searches. For brands, the most important difference between LLMs and browsers is that LLMs reveal one answer rather than a list of links, giving businesses fewer openings to appear before consumers, said Vogel.
“All the brands are terrified they’re not going to be included in these AI answers,” he said.
The trend has inspired a new wave of AI-optimization startups that promise to help marketers adapt.
Businesses should move cautiously despite the apparent speed of change, according to Goodman, the Datos CEO. Search engines still handle an overwhelming majority of overall search traffic and remain firmly embedded in the smartphones that occupy so much of our time, he said.
Brands must also remember that AI searches often serve different needs than a traditional google search, he said.
“Over 90% of all of the AI searches are what we call informational or productivity-based: Help me solve this problem, help me answer this question,” said Goodman. Traditional search result pages, on the other hand, were designed to lead consumers out to other destinations online, he said.
AI chatbots for now are less a replacement for traditional search engines than another emerging responsibility for marketers, according to Andrew Lipsman, founder of consulting firm Media, Ads + Commerce.
Lipsman compared the emergence of AI to the rise of smartphones, which led to predictions that consumers would abandon computers altogether. Desktop traffic numbers over the past decade have barely budged, however, even as mobile use grew, according to research from Comscore.
The spread of advertising in AI search replies may become the next turning point because it will demand new spending from brands that want to stay competitive online, Lipsman said.
OpenAI says it has no plans to develop ad products. Perplexity has begun experimenting with sponsored searches, however, and last year hired a head of advertising and shopping.
Perplexity this year also released its own web browser, where searches are handled by its AI instead of a traditional engine like Google or Bing. The company says its search gives users “the choice to navigate the web.”
OpenAI is close to releasing a browser as well, Reuters reported this month. The company declined to comment.
News Corp, owner of The Wall Street Journal, has a content-licensing partnership with OpenAI and a commercial agreement to supply content on Google platforms.
Write to Patrick Coffee at patrick.coffee@wsj.com
https://www.wsj.com/articles/ai-search-is-growing-more-quickly-than-expected-f75aa1ca
#metaglossia_mundus

‘Deep research’ AI agents combine large language models with sophisticated reasoning frameworks to conduct in-depth, multi-step analyses.
Published: July 21, 2025 5.37pm SAST
Ali Shiri, University of Alberta
"Generative AI, especially large language models (LLMs), present exciting and unprecedented opportunities and complex challenges for academic research and scholarship.
As the different versions of LLMs (such as ChatGPT, Gemini, Claude, Perplexity.ai and Grok) continue to proliferate, academic research is beginning to undergo a significant transformation.
Students, researchers and instructors in higher education need AI literacy knowledge, competencies and skills to address these challenges and risks.
In a time of rapid change, students and academics are advised to look to their institutions, programs and units for discipline-specific policy or guidelines regulating the use of AI.
Researcher use of AI
A recent study led by a data science researcher found that at least 13.5 per cent of biomedical abstracts last year showed signs of AI-generated text.
Read more: AI-detection software isn't the solution to classroom cheating — assessment has to shift
Large language models can now support nearly every stage of the research process, although caution and human oversight are always needed to judge when use is appropriate, ethical or warranted — and to account for questions of quality control and accuracy. LLMs can:
Help brainstorm, generate and refine research ideas and formulate hypotheses;
Design experiments and conduct and synthesize literature reviews;
Write and debug code;
Analyze and visualize both qualitative and quantitative data;
Develop interdisciplinary theoretical and methodological frameworks;
Suggest relevant sources and citations, summarize complex texts and draft abstracts;
Support the dissemination and presentation of research findings, in popular formats.
However, there are significant concerns and challenges surrounding the appropriate, ethical, responsible and effective use of generative AI tools in the conduct of research, writing and research dissemination. These include:
Misrepresentation of data and authorship;
Difficulty in replication of research results;
Data and algorithmic biases and inaccuracies;
User and data privacy and confidentiality;
Quality of outputs, data and citation fabrication;
And copyright and intellectual property infringement.
Assistant professor of information science Allison Koenecke, who authored a study about hallucinations in a speech-to-text transcription tool, works at Cornell University near a screen in Ithaca, N.Y., in February 2024. (AP Photo/Seth Wenig)
AI research assistants, ‘deep research’ AI agents
There are two categories of emerging LLM-enhanced tools that support academic research:
1. AI research assistants: The number of AI research assistants that support different aspects and steps of the research process is growing at an exponential rate. These technologies have the potential to enhance and extend traditional research methods in academic work. Examples include AI assistants that support:
Concept mapping (Kumu, GitMind, MindMeister);
Literature and systematic reviews (Elicit, Undermind, NotebookLM, SciSpace);
Literature search (Consensus, ResearchRabbit, Connected Papers, Scite);
Literature analysis and summarization (Scholarcy, Paper Digest, Keenious);
And research topic and trend detection and analysis (Scinapse, tlooto, Dimension AI).
2. ‘Deep research’ AI agents: The field of artificial intelligence is advancing quickly with the rise of “deep research” AI agents. These next-generation agents combine LLMs, retrieval-augmented generation and sophisticated reasoning frameworks to conduct in-depth, multi-step analyses.
Research is currently being conducted to evaluate the quality and effectiveness of deep research tools. New evaluation criteria are being developed to assess their performance and quality.
Criteria include elements such as cost, speed, editing ease and overall user experience — as well as citation and writing quality, and how these deep research tools adhere to prompts.
There are now many deep research AI platforms to choose from. (A.C./Unsplash)
The purpose of deep research tools is to meticulously extract, analyze and synthesize scholarly information, empirical data and diverse perspectives from a wide array of online and social media sources. The output is a detailed report, complete with citations, offering in-depth insights into complex topics.
In just a short span of four months (December 2024 to February 2025), several companies (like Google Gemini, Perplexity.ai and ChatGPT) introduced their “deep research” platforms.
The Allen Institute for Artificial Intelligence, a non-profit AI research institute based in Seattle, is experimenting with a new open access research tool called Ai2 ScholarQA that helps researchers conduct literature reviews more efficiently by providing more in-depth answers.
Emerging guidelines
Several guidelines have been developed to encourage the responsible and ethical use of generative AI in research and writing. Examples include:
The Government of Canada Guide on the Use of Generative Artificial Intelligence. This counsels federal institutions and academics to explore potential uses of generative AI tools, and follow a recommended framework for decision-making about them, including responsible communication and transparency.
Guidance from publicly funded federal agencies — collectively known as the Tri-Council Agency — offering research grants and programs covering different research disciplines.
The Observatory in AI Policies in Canadian Post-Secondary Education, run by the firm Higher Education Strategy Associates, lists AI policies and guidelines developed by more than 30 Canadian higher education institutions.
The federal government’s Guide on the Use of AI Federal institutions advises federal institutions to explore potential uses of generative AI tools, but not to use these tools in all cases. A Canadian flag on Parliament Hill in Ottawa in March 2025. THE CANADIAN PRESS/Sean Kilpatrick
LLMs support interdisciplinary research
LLMs are also powerful tools to support interdisciplinary research. Recent emerging research (yet to be peer reviewed) on the effectiveness of LLMs for research suggests they have great potential in areas such as biological sciences, chemical sciences, engineering, environmental as well as social sciences. It also suggests LLMs can help eliminate disciplinary silos by bringing together data and methods from different fields and automating data collection and generation to create interdisciplinary datasets.
Helping to analyze and summarize large volumes of research across various disciplines can aid interdisciplinary collaboration. “Expert finder” AI-powered platforms can analyze researcher profiles and publication networks to map expertise, identify potential collaborators across fields and reveal unexpected interdisciplinary connections.
This emerging knowledge suggests these models will be able to help researchers drive breakthroughs by combining insights from diverse fields — like epidemiology and physics, climate science and economics or social science and climate data — to address complex problems.
Read more: The world is not moving fast enough on climate change — social sciences can help explain why
Research-focused AI literacy
Canadian universities and research partnerships are providing AI literacy education to people in universities and beyond.
The Alberta Machine Intelligence Institute offers K-12 AI literacy programming and other resources. The institute is a not-for profit organization and part of Canada’s Pan-Canadian Artificial Intelligence Strategy.
Many universities are offering AI literacy educational opportunities that focus specifically on the use of generative AI tools in assisting research activities.
Collaborative university work is also happening. For example, as vice dean of the Faculty of Graduate & Postdoctoral Studies at the University of Alberta (and an information science professor), I have worked with deans from the University of Manitoba, the University of Winnipeg and Vancouver Island University to develop guidelines and recommendations around generative AI and graduate and postdoctoral research and supervision.
Many universities are offering AI literacy educational opportunities.
Considering the growing power and capabilities of large language models, there is an urgent need to develop AI literacy training tailored for academic researchers.
This training should focus on both the potential and the limitations of these tools in the different stages of the research process and writing."
https://theconversation.com/ai-in-universities-how-large-language-models-are-transforming-research-260547
#metaglossia_mundus

Une journée d’étude lance la course contre-la-montre pour traduire et produire les lois marocaines en amazigh d’ici 2034
"Mardi 22 Juillet 2025
Le Maroc accélère l’intégration de l’amazigh dans l’arsenal législatif
Traduire 110 ans de textes juridiques en amazigh d’ici 2034. C’est le pari fou que s’est lancé le Maroc ce mardi à Rabat. Ministres, juristes et linguistes ont planché toute la journée sur cette montagne législative à gravir. Entre conventions signées et vérités qui dérangent, cette rencontre révèle l’ampleur du fossé entre les promesses constitutionnelles et la réalité du terrain. Récit d’une journée où l’on a parlé franchement des retards, des moyens qui manquent et d’un héritage juridique amazigh oublié qui pourrait bien changer la donne.
BRAHIM MOKHLISS | 22 JUILLET 2025 À 17:37
Il est 9 heures du matin, ce mardi 22 juillet 2025. Dans la salle des conférences située au Centre d’accueil et de conférences du ministère de l’Équipement à Rabat, un débat houleux et de grandes annonces ont lieu. Mohamed Hajoui, le patron de l’administration juridique marocaine, sait que les mots qu’il va prononcer pèsent lourd. Très lourd. «Nous sommes à moins de neuf ans de l’échéance», lâche-t-il d’emblée. Neuf ans pour traduire des milliers de lois.
Une mission impossible?
En effet, pour la première fois, les principaux architectes de la politique linguistique marocaine se réunissent autour d’une ambition commune : transformer la reconnaissance constitutionnelle de l’amazigh en réalité juridique tangible. Cette journée d’étude, fruit d’un partenariat tripartite entre le Secrétariat général du gouvernement, le ministère de la Transition numérique et de la réforme de l’administration, et l’Institut Royal de la culture amazighe (IRCAM), symbolise l’accélération d’un processus longtemps resté au stade des déclarations d’intention.
Une mobilisation institutionnelle sans précédent
L’allocution d’ouverture de Mohamed Hajoui, secrétaire général du gouvernement, donne immédiatement le ton. «Cette rencontre s’inscrit dans le sillage des directives Royales qui n’ont cessé de souligner que la promotion de l’amazigh constitue une responsabilité nationale partagée», affirme-t-il devant un parterre de hauts responsables, de juristes et d’experts linguistiques. Le haut fonctionnaire ne cache pas l’ampleur du défi : avec moins de neuf ans pour atteindre l’objectif fixé par la loi organique 16-26, les institutions marocaines doivent désormais passer à la vitesse supérieure.
Cette urgence temporelle trouve un écho particulier dans les propos d’Amal El Fallah Seghrouchni, ministre déléguée chargée de la Transition numérique et de la réforme de l’administration. «Entre 2002 et 2003, l’IRCAM a déjà réalisé un nombre considérable de traductions dans des domaines variés. Nous disposons donc d’une base solide», souligne-t-elle, avant d’énumérer les avancées concrètes : 488 agents d’accueil formés à l’amazighe dans les administration, 11 centres d’appel activés avec 72 téléopérateurs dédiés, sans oublier l’introduction historique de la langue dans les sessions parlementaires.
La dimension symbolique de cette journée n’échappe à personne. Trois conventions de partenariat sont signées sous les applaudissements nourris de l’assistance, matérialisant ainsi la volonté politique affichée. Ces accords-cadres visent à structurer la coopération entre les institutions et à définir des mécanismes opérationnels pour la traduction et la production de textes juridiques en amazigh. La signature des trois conventions prend alors une tout autre dimension. Plus qu’un rituel protocolaire, c’est un engagement solennel. Le SGG avec l’IRCAM. Le SGG avec le ministère de la Transition numérique. Des partenariats censés débloquer la situation.
Les défis colossaux de la traduction juridique
Derrière l’enthousiasme affiché, les intervenants ne masquent pas l’immensité de la tâche. Taoufik Mediani, conseiller juridique au Secrétariat général du gouvernement, dresse un constat sans complaisance : «Nous devons traduire plus de 110 ans de production législative. Des milliers de textes, dont beaucoup restent en vigueur, attendent leur version amazighe». Cette accumulation historique représente un défi technique et humain considérable, d’autant plus que les ressources spécialisées font cruellement défaut.
Hassan Akyoud, directeur du Centre de traduction de l’IRCAM, confirme cette analyse tout en apportant des nuances importantes. «La traduction juridique vers l’amazigh nécessite bien plus qu’une simple transposition linguistique. Il s’agit de créer une langue juridique amazighe cohérente, accessible et juridiquement sûre», explique-t-il. L’expert pointe du doigt plusieurs obstacles structurels : l’absence de terminologie juridique standardisée, le manque de formation spécialisée pour les traducteurs et la faible structuration actuelle de la langue juridique amazighe.
Ces défis techniques se doublent d’enjeux institutionnels complexes. Rachid Tounfi, chercheur à l’IRCAM, plaide pour une approche qui dépasse la simple traduction : «Nous devons viser la production directe de textes juridiques en amazigh. Cela suppose de doter l’État de capacités linguistiques et juridiques durables». Cette vision ambitieuse nécessite une refonte profonde des processus de production normative, impliquant la formation de juristes capables de rédiger directement en amazigh.
Lancement de la campagne "Azul Agadir" pour promouvoir la région d’Agadir Souss-Massa
La deuxième édition de la campagne promotionnelle pour la destination Agadir Souss Massa "Azul Agadir" a été lancée, jeudi à la place "Al Wahda" sur la corniche d'Agadir, à l’occasion du début de la saison estivale.
L’héritage méconnu du droit coutumier amazigh
Une autre intervention importante lors de cette journée vient d’Ahmed Arahmouch, avocat au barreau de Rabat et président du Réseau amazigh pour la citoyenneté. Devant un auditoire captivé, il rappelle l’existence historique de systèmes juridiques amazighs sophistiqués : «Du XIe au XXe siècle, les communautés amazighes ont développé des corpus normatifs codifiés, couvrant des domaines aussi variés que la justice arbitrale, l’égalité successorale entre hommes et femmes, ou encore la protection de l’environnement».
Cette révélation bouscule les idées reçues et ouvre des perspectives inédites. Les Anflas (délégués tribaux) et les Tanfloust (conseils coutumiers) constituaient des institutions juridictionnelles élaborées, produisant un droit vivant adapté aux réalités locales. «Ce patrimoine normatif constitue une base légitime pour l’élaboration d’un droit amazigh positif contemporain», argumente l’avocat, suggérant que le Maroc pourrait s’inspirer de cette tradition juridique millénaire plutôt que de partir d’une page blanche.
Cette proposition trouve un écho favorable auprès d’Ahmed Boukouss, recteur de l’IRCAM, qui rappelle le rôle pionnier de son institution : «L’Institut offre son expertise et ses conseils pour les projets majeurs visant à activer le caractère officiel de la langue amazighe. Nous soutenons activement le développement des capacités des acteurs impliqués.» Toutefois, le recteur ne cache pas sa préoccupation face aux retards accumulés : «Les mesures prévues aux articles 9 et 10 de la loi organique, ainsi que le délai fixé par l’article 31, n’ont pas encore été pleinement mises en œuvre».
Une stratégie nationale en construction
Face à ces défis multidimensionnels, les participants convergent vers la nécessité d’une stratégie nationale cohérente et planifiée. Le secrétaire général du gouvernement esquisse les contours de cette approche : «Il nous faut adopter une méthodologie commune pour la publication des textes législatifs et réglementaires à caractère général en langue amazighe. C’est un travail collectif qui concerne tous les départements
ministériels».
Cette vision stratégique s’articule autour de plusieurs axes prioritaires. D’abord, la création d’un référentiel juridique amazigh unifié, projet phare mentionné dans les conventions signées. Ensuite, la mise en place de formations spécialisées pour constituer un vivier de traducteurs et de juristes compétents. Enfin, l’adoption de technologies innovantes pour accélérer le processus de traduction et garantir la cohérence terminologique. La ministre de la Transition numérique détaille les mécanismes de mise en œuvre : «Le Fonds de modernisation de l’administration publique, doté d’un milliard de dirhams à l’horizon 2025, soutiendra directement ces initiatives. Nous avons également mis en place une commission centrale de pilotage et des commissions thématiques spécialisées pour assurer le suivi opérationnel».
Les expériences internationales comme source d’inspiration
Plusieurs intervenants soulignent l’importance de s’inspirer des bonnes pratiques internationales en matière de multilinguisme juridique. Les exemples de l’Union européenne, avec ses 24 langues officielles, ou des Nations unies, démontrent la faisabilité technique d’un système juridique multilingue, à condition de disposer des ressources et de l’organisation adéquates. «Nous devons tirer les leçons de ces expériences tout en développant un modèle adapté à notre contexte national», suggère Karima Khaldoun, directrice du développement de l’utilisation de la langue amazighe au ministère. Elle évoque notamment la nécessité d’harmoniser les variantes amazighes tout en respectant leur diversité, défi spécifique au contexte marocain.
Des avancées concrètes malgré les obstacles
Malgré les défis évoqués, la journée d’étude a permis de mettre en lumière des réalisations tangibles. L’usage de l’amazigh dans les conférences de presse gouvernementales, la signalétique bilingue dans de nombreuses administrations, ou encore la traduction simultanée des débats parlementaires constituent autant de signes encourageants. «Ces avancées, aussi modestes soient-elles, démontrent que le changement est possible», affirme le secrétaire général du gouvernement. Il cite l’exemple de la publication prochaine de la version amazighe du guide d’élaboration des textes législatifs et réglementaires, première pierre d’un édifice juridique bilingue.
L’enjeu démocratique de l’accès au droit
Au-delà des aspects techniques et institutionnels, les participants soulignent unanimement l’enjeu démocratique fondamental que représente l’intégration de l’amazigh dans la législation. «Il s’agit de garantir à tous les citoyens marocains l’accès au droit dans une langue qu’ils comprennent et maîtrisent», rappelle la ministre Amal El Fallah Seghrouchni. Cette dimension citoyenne trouve une résonance particulière dans le contexte actuel de réformes législatives majeures. Avec la révision en cours du Code pénal, du Code de procédure civile et pénale, ou encore du Code de la famille, l’opportunité est unique d’intégrer dès l’origine la dimension amazighe dans ces textes fondamentaux.
Un horizon temporel contraignant mais mobilisateur
L’année 2034 apparaît à la fois proche et lointaine. Proche au regard de l’ampleur de la tâche, lointaine pour les militants qui attendent depuis des décennies la concrétisation de leurs revendications. Cette tension temporelle traverse l’ensemble des interventions, créant une dynamique d’urgence productive. «Nous devons être au rendez-vous fixé par la loi organique», martèle le secrétaire général du gouvernement. Cette détermination se traduit par des engagements concrets : calendriers de travail, indicateurs de suivi, mécanismes d’évaluation. Les conventions signées prévoient notamment des comités de suivi mixtes chargés de veiller à la mise en œuvre effective des engagements pris.
Vers un nouveau paradigme juridique
L’ambition affichée dépasse la simple traduction des textes existants. Il s’agit de repenser fondamentalement la production normative dans un contexte bilingue. Cela implique de nouvelles procédures, de nouveaux acteurs, de nouvelles compétences. «Nous assistons à l’émergence d’un nouveau paradigme juridique», analyse Rachid Tounfi, voyant dans ce processus une opportunité de moderniser l’ensemble du système normatif marocain. Cette transformation systémique nécessite l’adhésion de l’ensemble des acteurs de la chaîne juridique : législateurs, administrateurs, magistrats, avocats, universitaires. La journée d’étude révèle à cet égard des disparités importantes dans les niveaux de préparation et d’engagement des différentes institutions.
Les conditions de la réussite
Au terme de cette journée riche en échanges, plusieurs conditions de réussite émergent des débats. D’abord, l’importance cruciale des moyens humains et financiers, avec la formation massive de professionnels compétents. Ensuite, l’indispensable adhésion sociale, qui passe par une communication efficace sur les enjeux et les bénéfices de cette transformation. Le recteur de l’IRCAM résume l’état d’esprit général : «Cette journée marque un tournant. Nous passons de la phase de reconnaissance symbolique à celle de l’institutionnalisation normative. C’est un défi historique que nous devons relever collectivement.» Contrairement aux craintes de certains sceptiques, l’intégration de l’amazigh dans la législation apparaît comme un facteur de modernisation plutôt que de complication. La nécessité de clarifier, simplifier et rendre accessible le droit pourrait bénéficier à l’ensemble du système juridique, y compris dans sa version arabophone. «En traduisant nos textes en amazigh, nous sommes obligés de les rendre plus clairs, plus accessibles. C’est une opportunité de simplification juridique», observe Hassan Akyoud. Cette dynamique vertueuse pourrait contribuer à rapprocher le droit des citoyens, objectif majeur de toute démocratie moderne. Dans cette perspective, l’amazigh n’est plus seulement une langue à préserver, mais un vecteur de citoyenneté et de modernité démocratique."
https://lematin.ma/nation/traduction-des-lois-en-amazigh-cap-fixe-sur-2034/292630
#metaglossia_mundus
The Academy of Sciences of Afghanistan recently announced that, over the past year, it translated 18 scholarly works from foreign languages into national languages.
The Academy also revealed that it has developed writing systems (alphabets) for three local languages, Sawi, Ishkashimi, and Nuristani, and that efforts are ongoing to develop alphabets for several other languages.
"Despite longstanding criticism over the performance and scientific achievements of The Academy of Sciences of Afghanistan, the institution has recently announced that over the past year, it translated 18 scholarly works from foreign languages into national languages.
In its annual report presentation, the Academy stated that it had organized dozens of scientific and research programs across the country during the past year.
The Academy also revealed that it has developed writing systems (alphabets) for three local languages, Sawi, Ishkashimi, and Nuristani, and that efforts are ongoing to develop alphabets for several other languages.
Seyyed Nazim Sayedi, head of the Academy’s Center for Languages and Literature, said: “We have created alphabets for the Sawi, Ishkashimi, and Nuristani languages, and many speakers of other languages have also reached out to us. We're working on alphabets for them too. This is a complex and sensitive task that requires the involvement of linguists, local residents, as well as both literate and illiterate community members. We plan to interview and consult them all.”
Amir Jan Saqeb, Deputy for Natural and Technical Sciences at the Academy, added: “In the past year, we organized seven major scientific and research seminars across various scientific fields. Additionally, 67 academic and research conferences were held in the areas of Islamic and human sciences, as well as natural and technical sciences.”
According to the Academy’s data, more than 200 academic articles were authored in the past year, and over 1,000 foreign terms were submitted for review and standardization. Officials stated they aim to reduce the use of foreign terminology in government institutions.
Meanwhile, the Academy’s Ethnographic Museum received visits from 400 Afghans and 75 foreign nationals over the past year—most of the foreign visitors came from the United States, Germany, France, Turkey, and Russia.
The Academy of Sciences emphasized that in the current year, it plans to implement new initiatives aimed at advancing scientific research, raising academic standards, and strengthening national languages."
By TOLOnews, TV Network
TODAY - 9:14 AM
https://tolonews.com/afghanistan-195116
#metaglossia_mundus
«Défendre la souveraineté et les données européennes»
«étendre la disponibilité des données» dans au moins 10 des 24 langues officielles de l’Union européenne
"...Microsoft va investir plusieurs millions de dollars en Europe pour produire des données numériques à destination des modèles d'intelligence artificielles (IA) dans plus d'une dizaine de langues, a annoncé lundi son président. Alors que les principaux modèles d'IA sont en grande partie entraînés en anglais, leurs bases de données doivent proposer davantage de sources dans d'autres langues, sans quoi la survie de celles-ci «est en jeu», a défendu Brad Smith lors d'un entretien. Un modèle «est moins performant lorsqu'il est utilisé dans une langue pour laquelle les données sont insuffisantes», a-t-il rappelé, ce qui peut pousser les utilisateurs à favoriser l'anglais.
Dès septembre, le géant américain de la tech compte installer à Strasbourg (est de la France) des antennes de ses centres de recherche pour notamment «étendre la disponibilité des données» dans au moins 10 des 24 langues officielles de l'Union européenne, comme l'estonien et le grec. Le groupe de Redmond (État du Washington) compte par exemple aider à la numérisation de livres en langue non-anglaise et faire enregistrer des centaines d'heures d'audio dans différents langages. «Microsoft ne possédera aucune de ces données» qui seront «accessibles au grand public» et disponibles en source ouverte, a assuré Brad Smith.
«Défendre la souveraineté et les données européennes»
Alors que la question de la souveraineté numérique européenne agite le monde de la politique et de la tech depuis plusieurs mois, le géant américain cherche à se positionner comme l'entreprise la plus compatible avec le marché européen. En juin, il avait par exemple annoncé renforcer sa coopération avec les gouvernements de l'UE en matière de cybersécurité et de nouvelles mesures de contrôle sur les données stockées dans ses centres en Europe. «Nous nous engageons sans réserve à défendre la souveraineté et les données européennes», a de nouveau martelé Brad Smith. Si la plupart des géants de l'IA sont américains et chinois, l'Europe abrite quelques pépites du secteur comme le français Mistral et la start-up franco-américaine Hugging Face, plateforme d'IA en accès libre.
Des initiatives européennes, comme TildeLM, cherchent aussi à développer des modèles d'IA pour les langues européennes. Microsoft a également annoncé lundi la création à l'automne d'une réplique numérique de la cathédrale Notre-Dame de Paris, en partenariat avec l'Institut du Patrimoine et l'entreprise française Iconem, dont elle fera don à l'État français. Il a également lundi dévoilé des partenariats avec la Bibliothèque nationale de France (BNF) et le Musée des arts décoratifs visant à numériser une partie de leurs collections..."
Dado Ruvic
REUTERS
https://www.lefigaro.fr/flash-eco/microsoft-veut-ameliorer-les-performances-des-ia-dans-les-langues-europeennes-20250721
#metaglossia_mundus

Germany launches a special freelancer visa to attract skilled professionals from around the world. Apply now for new global work .
"Germany Introduces Freelancer Visa To Attract Global Talent
Germany has opened its doors wide for independent professionals worldwide with the launch of its Freiberufler visa, commonly known as the Germany freelancer visa. Priced at just €75 (approximately Dh388), this visa allows skilled freelancers to live and work in Europe’s largest economy for up to three years.
This exciting opportunity is designed for creative minds and specialized professionals who prefer flexibility over traditional employment. Unlike standard work permits, the Freiberufler visa doesn’t require a job offer—freelancers simply need to prove expertise, financial independence, and a solid business plan.
Who Can Apply for the German Freelancer Visa?
The visa is available to a broad range of professionals, including:
Artists, authors, and educators
Doctors, lawyers, and therapists
Architects, engineers, and consultants
Journalists, translators, and interpreters
Pilots and aviation experts
Germany Freelancer Visa Requirements
To be eligible, applicants must provide:
Proof of qualifications (academic degrees or professional certifications)
A well-defined business plan with existing client contracts
Financial stability documents to show self-sufficiency
Pension scheme documentation (mandatory if over age 45)
Valid German health insurance
Evidence of professional ties within Germany or the EU
Once approved, the visa is valid for three years and can be extended. In many cases, applicants may even qualify for permanent residency after a successful term.
Read More: Study Free in Germany: NHR PhD Scholarships 2026 Open Now
Why Germany?
Germany’s freelance sector is growing fast, and the country currently faces a shortage of skilled labor. This makes it the perfect time for qualified professionals to tap into European markets, collaborate with international clients, and boost their career while enjoying the benefits of self-employment.
Read More: DAAD 2026 PhD Scholarships for Ancient Languages in Germany
The application process usually takes between 6 to 10 weeks, and successful candidates can begin working legally across Germany with access to top-tier infrastructure, clients, and lifestyle."
Mawadat Fatima
July 20, 2025
https://bloompakistan.com/germany-introduces-freelancer-visa-to-attract-global-talent/
#metaglossia_mundus
"Dictionaries Are Better Than Artificial Intelligence - The New York Times
The New York Times
By Alessandro Tersigni
Mr. Tersigni is a cultural critic.
Have you ever obeyed the suggestions of a digital writing assistant to replace a word or restructure a sentence without knowing how, why or even if it made your writing better? Before the reign of digital tools, you’d probably have turned to a dictionary for the same assistance. Our parents and grandparents picked up a heavy book and looked up what words meant, how they’re used, maybe glanced at their etymology — and then made a linguistic choice, however shaky or idiosyncratic, to express their ideas.
In today’s universe of spell-check, autocorrect and artificial intelligence — each of which is capable of making those choices for us — why should we keep producing and owning actual, cinder-block-sized dictionaries?
Because dictionaries enable us to write not with fail-safe convenience but with originality and a point of view. While A.I. assistants manufacture phrases and statements so writers don’t have to think them up, dictionaries provide us with the knowledge to use language ourselves in expressive and potentially infinite ways. They place choice — and authority — literally in human hands, forcing us to discover how we want to explain ourselves and our ideas to the world.
Dictionaries aren’t merely long lists of words and meanings; they’re also instructions for how best to use those words. Since the debuts of Samuel Johnson and Noah Webster, English dictionaries have reflected the language of particular populations — the Oxford English Dictionary and Merriam-Webster don’t quite say the same things. Simultaneously, by codifying the meanings, uses and connotations of words, those same dictionaries have shaped language. Lexicographers look to the public to determine words’ meanings, and we in turn look to lexicographers to verify that our understanding of words is shared and mutually understood. The parameters of English are formed both top-down and bottom-up. Dictionaries amalgamate and standardize these two linguistic influences and, in doing so, define our most fundamental cultural medium.
Standard English doesn’t exist today the way it did as recently as the late 20th century. Thanks to the colloquial tone of ubiquitous internet-based communication, formal English has become essentially absent from most people’s lives. Where my parents’ letters to friends and colleagues would have adopted genial but brittle tones and structures, the vast majority of my social and professional correspondence is informal. Smartphone messaging conventions — like using exclamation points to indicate pleasant normalcy and ellipses to evoke impatience or indifference — routinely seep into follow-ups from artists and lawyers alike. It’s almost as if the more informal one’s writing is, the more capable, authoritative and trustworthy it reads.
This acceptance of vernacular in contemporary mainstream English is new, but by no means uniform. English-speaking societies have always used an array of dialects, but until relatively recently, lexicographers arbitrarily viewed nonstandard Englishes as unsophisticated and therefore unworthy of regular inclusion in dictionaries. Today there is a general awareness that particular nations, for instance, speak not one but a group of different Englishes. Dictionaries are therefore no longer confronted with the task of defining a prestige dialect but rather with describing and legitimizing the contrasting ways people use words, a task for which they, unlike less deliberate digital alternatives, are well suited.
The profusion of digital writing assistants like Grammarly and Microsoft Editor gives greater urgency to debates about what a dictionary should be. In 1946, George Orwell described good writing as “picking out words for the sake of their meaning,” a practice that dictionaries catalyze and writing programs stifle. Writers consulting a dictionary make a choice — writers guided by an app like Grammarly have their choices made for them.
Where Grammarly says, “Stay on-brand with consistent communication,” Orwell warns that “the great enemy of clear language is insincerity.” Grammarly urges users to “generate text with A.I. prompts,” while Orwell cautions that “ready-made phrases” inevitably “construct your sentences for you — even think your thoughts for you.” Grammarly brags that its users can “rewrite full sentences with a click,” while Orwell notes that “the worst thing one can do with words is to surrender to them.”
It’s a fight between robotic consistency and human creativity. The digital-native approach delivers hands-off, derivative communication. The analog approach requires leafing through pages without knowing exactly where you’ll end up. One cedes the conviction of writing to a machine. The other bestows the crucible of thinking critically about what and how to write solely on an imperfect writer. Without dictionaries to provide us with a manual guide to English’s potential, writing that way is nearly impossible.
Web dictionaries like Wiktionary and Google Dictionary — whose contents are often derived from existing works by actual lexicographers and resources such as Google’s Ngrams — empower writers to some degree, but they can be lexicographically lax. I’m not convinced, for instance, that listing “amazeballs” as a synonym for “astonishing” helps clarify the scope and potency of the English language. Codifying English as it is spoken requires not just itemizing neologisms but making deliberate choices. It’s traditional dictionaries’ human scrutiny and advocacy that make them catalysts for exploration rather than aggregators of information.
Our ability to express ourselves is critical — it helps us define our culture and our being. Dictionaries aid us in achieving this: They catalog our unique ways of thinking through language. I’m a Canadian; my feeling of pride and belonging in my native land is elevated by small linguistic Canadianisms (not many Americans say “eaves trough” or “serviette” — nor do A.I. chatbots, for the most part).
The new Canadian English Dictionary — still a work in progress, it will be the first of its kind in over two decades — is a critical part of constructing that identity. It takes a novel stance on describing the usage and orthography, or spelling, of particularly Canadian words — especially those derived from Canada’s mosaic of Indigenous and immigrant cultures. This approach privileges not the popularity but the heterogeneity of words, and it is equally descriptive and prescriptive, teaching a word’s origins and suggesting a better future for it at once. It’s a choice — like the choices we make when we use a word in our writing.
As digital writing — A.I.-generated, spell-checked, its words suggested for us — extends deeper into our lives and minds, we need dictionaries more than ever, not to write efficiently or correctly, but to cultivate relationships with the words we use. Abandoning dictionaries and embracing mechanized writing would erode our capacity for collective identity quite as much as the ability to express ourselves. We need these books on our shelves to flip through, animate, and surprise ourselves with. Without the impetus for self-expression and lifelong learning, we have to ask ourselves, why write at all?
Alessandro Tersigni (@atersig) is a cultural critic based in Toronto.
https://www.nytimes.com/2025/07/20/opinion/dictionary-ai-spelling-writing.html
#metaglossia_mundus

"Literary Notes: Glossaries of Federal Board’s Urdu textbooks: inaccurate, misleading
Rauf Parekh Published July 21, 2025 Updated a day ago
MUHAMMAD Ahsan Khan is a 90-year-old scholar from Lahore. A voracious reader, expert lexicographer and true connoisseur of the Urdu language, he loves words. That’s why whenever he comes across some erroneous expressions or incorrectly explained words of Urdu, he gets irritated, makes a phone call to me and expresses his concern.
Last week, too, Ahsan Khan Sahib gave me a ring. Sounding shocked, he lamented that even the textbooks of Urdu are now full of errors and the glossaries in them are misleading. He then asked me to have a look at some Urdu textbooks, especially the ones published by the Federal Textbook Board in collaboration with the National Book Foundation, Islamabad.
On his suggestion, I got copies of Urdu textbooks for class IX, X, XI and XII, published by the Federal Textbook Board, and leafed through them. The back title of each book says “Approved by Government of Pakistan; Ministry of Federal Education & Professional Training; National Curriculum Council Secretariat”.
Let us have a quick look at the glossaries appended to these textbooks, published by the Federal Textbook Board, to find why Ahsan Sahib was so annoyed. The book titled Model Darsi Kitab (Model Textbook): Urdu, for Class XI, has listed in its glossary, for instance, “pesh khaima” (page 130). The meanings given are “nateeja, kisi kaam se pehle aane vali soorat”, which can be translated into English as ‘result, something happening before some work is done’. Aside from what pesh khaima actually means, what makes one wonder is how result can occur before something is done.
Another entry on the same page is “tees maar khani dikhana” and instead of explaining, the same expression is repeated as meaning. It simply means that nobody has bothered to proofread it even. On the next page, an entry is “dastak”. The meanings given are “darvaza khatkhatana”. What the compilers could not understand is that the word dastak means ‘knock at a door’ (noun) and not ‘to knock on a door’ (verb), but the definition given has turned the noun into an infinitive.
“Laa ubaali tabiyet” is the entry on page 131. The meanings given are “josh vala tabiyet”. Firstly, tabiyet is a feminine noun but the compilers think it is masculine, hence vala, instead of vali. Secondly, the meanings given are exactly opposite: laa ubaali is an Arabic phrase which literally means ‘I don’t care’. The correct meaning would be ‘careless disposition’.
The book for class X says “khalish” means “khwahish jo poori na ho” (page 167). But literal meaning of khalish, a Persian word, is ‘prick of a thorn’ and it signifies mental prick, continued resentment or concern. “Safed posh”, says the book on page169, is someone clothed in white. But it is a metaphor and it refers to someone not rich but maintaining a certain standard and good reputation. Class IX book says “maoof hona” means “sochne smajhne ke qabil” (page 122). Apparently, the words na hona are missing and it has reversed the sense. On page 123, the explanation to the word “bhaar” is incomplete and the word bhatti is spelt as “bathi”, again proving that proofreading is something unheard of in the Federal Board.
Several entries in these books are given in plural form or as oblique case while a glossary, and a dictionary, too, must list words in singular forms and avoid oblique cases. A glossary sometimes needs to explain different shades of meanings or use synonyms, separated with commas or semicolon. But the compilers are, perhaps, laa ubaali (according to their own definition of the phrase), leaving punctuation marks out, listing more than one shades of meanings in one go, without separating the nuances. Josh, you know!
Here I have restricted myself to the glossaries only, though there are many other lapses in text as well, for instance, in class X book, Zahra Nigah’s name has been written as “Zahra Niga” in the table of contents, but in the glossary it has been spelt as “Zahra Nigar” (page 173). The signs to show tashdeed (phonetic twining of consonants) and izaafat (enclitic possessive or adjectival compound) are also missing from the glossaries, making pronunciation difficult for the students.
The facts mentioned here are based on a cursory reading and a thorough checking may reveal that much of the glossary in each book is inaccurate and misleading. One hopes the Federal Board would contact a senior lexicographer like Ahsan Khan or Saleemur Rahman for putting the books in order.
Two of these books I purchased from the National Book Foundation’s Karachi office have been stamped with the words “Test Edition”, with print line saying that about 100, 000 or so copies have been printed. One wonders if textbooks can be published in large quantities, sold and taught on a trial and error basis!
drraufparekh@yahoo.com
Published in Dawn, July 21st, 2025"
https://www.dawn.com/news/1925538
#metaglossia_mundus
Hymnbook translation team seeks people fluent in Bulgarian, Czech, Danish, Dutch, Estonian, European Portuguese, Finnish, Haitian, Hungarian, Latvian, Lithuanian, Norwegian, Polish, Romanian, Swedish, Thai and Ukrainian.
"Headquarters (USA) - English
21 July 2025 - SALT LAKE CITY Featured Stories
Call for Applications: Paid and Volunteer Roles for Translations of ‘Hymns—For Home and Church’Individuals fluent in Bulgarian, Czech, Danish, Dutch, Estonian, European Portuguese, Finnish, Haitian, Hungarian, Latvian, Lithuanian, Norwegian, Polish, Romanian, Swedish, Thai and Ukrainian are needed
https://newsroom.churchofjesuschrist.org/article/call-for-applications-paid-volunteer-roles-translations-hymns-for-home-and-church
The hymnbook language translation team is seeking talented individuals fluent in Bulgarian, Czech, Danish, Dutch, Estonian, European Portuguese, Finnish, Haitian, Hungarian, Latvian, Lithuanian, Norwegian, Polish, Romanian, Swedish, Thai and Ukrainian. 2025 BY INTELLECTUAL RESERVE, INC. ALL RIGHTS RESERVED.
Download Photo
On June 18, 2018, The Church of Jesus Christ of Latter-day Saints announced plans to publish a new unified hymnal. The new hymnbook, “Hymns—For Home and Church,” is a major, multi-year project involving thousands of employees and volunteers worldwide. The global hymnbook will become available digitally and in print in dozens of languages over the coming years.
Languages and Roles
The hymnbook language translation team is seeking talented individuals fluent in Bulgarian, Czech, Danish, Dutch, Estonian, European Portuguese, Finnish, Haitian, Hungarian, Latvian, Lithuanian, Norwegian, Polish, Romanian, Swedish, Thai and Ukrainian for three open roles:
Translator or content reviewer (paid, independent contractor, 5+ hours a week)
Singer (paid, independent contractor, 1–10 hours a week)
Community feedback volunteer (unpaid, up to 1 hour a week)
Latter-day Saints and friends of the Church with any background in translation, music, poetry or other creative writing experience in these languages are needed (additional languages may be added later), and all levels of experience are welcome to apply as soon as possible. Translation team members may live anywhere.
Job Descriptions
Translator or Content Reviewer
A translator is responsible for creating the initial translation of a song from English into the target language and for incorporating feedback from reviewers.
A content reviewer is responsible for reviewing the work of a translator, with a focus on meaning and language acceptability.
Applicants should possess solid English skills, be able to write creatively in the target language, have a general familiarity with music and poetry, possess basic technical skills, meet deadlines consistently, and communicate clearly and regularly with other team members.
Singer
A singer is responsible for singing translations of hymns and creating an unofficial audio recording throughout the translation process.
Download Photo
A singer is responsible for singing translations and creating an unofficial audio recording throughout the translation process. These recordings will not be officially published by the Church. They will only be used internally by the translation team and may be shared with volunteers via a survey to solicit feedback on the translations. (The Church will recruit singers for the published audio versions of the hymnbook later.)
A singer does not need to have professional vocal experience, but should generally be familiar with music, be able to sing a melody clearly and on pitch, meet deadlines, and communicate clearly and regularly with other team members.
Community Feedback Volunteer
A community feedback volunteer is asked to complete 5- to 20-minute digital surveys in the target language for hymn translations. Surveys include questions about the meaning, language, and musicality of a hymn translation, and the volunteer has the opportunity to provide feedback before the hymn is published. Where possible, some projects have volunteers meet to sing and offer feedback in person.
Access to an electronic device (phone, tablet, computer) is required. English is not required.
See this link for more details and a link to the online application form."
https://newsroom.churchofjesuschrist.org/article/call-for-applications-paid-volunteer-roles-translations-hymns-for-home-and-church
#metaglossia_mundus

."Traduire Günter Grass avec Olivier Mannoni
Atelier de traduction
Jeu, 02.10.2025
19h00-20h30
| À la découverte de « Prendre la pose », récit posthume
Goethe-Institut Paris, Paris
Langue
En français et en allemand
Prix
Entrée libre
Inscription obligatoire par mail : bibliotheque-paris@goethe.de
Partie de la série: Anna & Günter Grass"
https://www.goethe.de/ins/fr/fr/sta/par/ver.cfm?event_id=26796527
#metaglossia_mundus
"Tanger – L’École supérieure Roi Fahd de Traduction de Tanger (ESRFT) organise, les 11 et 12 novembre prochain, un Congrès international sous le thème “Le Sahara marocain au miroir de la traduction: Questions et approches”.
Ce congrès scientifique, qui se tiendra à l’occasion de la célébration du 50è anniversaire de la glorieuse Marche Verte, vise à approfondir la réflexion sur le rôle de la traduction dans l’affirmation des droits historiques du Maroc, et à explorer les contributions des traducteurs dans la diffusion des preuves historiques et juridiques relatives à cette question, indique un communiqué de l’ESRFT...
Il réunira d’éminents chercheurs et académiciens en vue d’explorer une panoplie de textes et de documents d’archives historiques, diplomatiques, juridiques et économiques, nationaux et étrangers, qui attestent de la marocanité du Sahara, et ce dans le but de soulever des questions intellectuelles et culturelles liées au domaine de la traduction.
“Ce Congrès sera un véritable plaidoyer en faveur de notre cause nationale, grâce aux contributions scientifiques qui mettront en lumière le rôle de la traduction dans le maintien de la souveraineté du Royaume sur l’ensemble de ses territoires du sud”, relève la même source, notant que cet événement sera l’occasion d’affirmer le rôle de la traduction dans le soutien de la marocanité du Sahara.
L’Ecole rappelle que la traduction n’a cessé de jouer un rôle stratégique dans la défense des causes nationales et leur rayonnement à l’échelle internationale, soulignant que grâce à son efficacité en tant que médiatrice interculturelle, elle contribue à mettre en lumière les enjeux fondamentaux préoccupant les peuples et les nations, tout en renforçant les positions officielles dans divers forums internationaux, et ce à travers des preuves historiques et juridiques.
“La question du Sahara marocain illustre parfaitement cette réalité, s’imposant au-delà des défis et des dilemmes d’ordre politique, économique et diplomatique dans l’Afrique du Nord. Ainsi, elle a su enchaîner des succès remarquables en occupant une place privilégiée à l’échelle des instances juridiques internationales”, ajoute la même source.
A ce titre, les archives historiques étrangères vont offrir une source inépuisable de documents français, espagnols, allemands, britanniques et américains, qui regorgent de preuves irréfutables soutenant cette légitimité.
Elles fournissent également des témoignages et des confessions de Marocains retenus dans les camps de Tindouf, qui constituent un fonds essentiel qu’il est important d’explorer et d’examiner à travers l’acte de traduction.
Il s’agit également d’autres textes relevant de l’anthropologie et de la sociologie coloniale, ainsi que les récits viatiques rédigés par des voyageurs, venus au Maroc sous des motivations multiples."
21 juillet, 2025
https://www.mapexpress.ma/actualite/culture-et-medias/congres-international-sahara-marocain-au-miroir-traduction-les-11-12-novembre-tanger/
#metaglossia_mundus

"Le traducteur Nguyen Le Chi honoré comme « Ami de la littérature chinoise »
Le 21 juillet, à Nanjing (Chine), le traducteur Nguyen Le Chi, fondateur de la société par actions Chibooks, a reçu le titre d'« Ami de la littérature chinoise » des mains de Truong Hong Sam, président de l'Association des écrivains chinois. C'est la première fois qu'un traducteur vietnamien reçoit ce titre.
Hà Nội Mới
21/07/2025
Le titre d'« Ami de la littérature chinoise » récompense le travail de traduction de la littérature chinoise réalisé par des traducteurs littéraires chevronnés de divers pays, sélectionnés par l'Association des écrivains chinois. Le traducteur Nguyen Le Chi a reçu ce titre après plus de 25 ans de travail acharné dans le domaine de la traduction et de l'édition, qui a permis de faire découvrir de nombreuses œuvres littéraires chinoises aux lecteurs vietnamiens.
Des traducteurs récompensés par le titre d'« Amis de la littérature chinoise ». Photo : Chibooks
Outre le traducteur Nguyen Le Chi, 14 traducteurs étrangers ont également reçu ce titre lors de la 7e Conférence internationale sur la traduction de la littérature chinoise pour sinologues, qui s'est tenue du 20 au 24 juillet à Nanjing. Organisée tous les deux ans par l'Association des écrivains chinois depuis 2010, cette conférence a réuni de nombreux écrivains et traducteurs de renom du monde entier .
Sous le thème « Traduction pour l’avenir », la conférence de cette année compte sur la participation de 39 écrivains chinois de premier plan tels que : Liu Zhenyun, Dongxi, Tat Phiyu…, ainsi que de 39 traducteurs littéraires de pays et territoires tels que : le Vietnam, la Thaïlande, la Corée, le Japon, l’Iran, l’Italie, le Mexique, l’Espagne, la Turquie, les Pays-Bas, la Pologne…
Le traducteur Nguyen Le Chi et le certificat d'« Ami de la littérature chinoise ». Photo : Chibooks
S'adressant à la presse chinoise, le traducteur Nguyen Le Chi a déclaré : « Lire et traduire de belles histoires est ma passion de toujours. Pouvoir accéder à d'excellentes œuvres littéraires et les traduire, notamment chinoises, est une grande chance. J'espère poursuivre mon cheminement vers la recherche, la découverte et la diffusion d'histoires précieuses, devenant ainsi un pont littéraire entre les lecteurs vietnamiens et chinois. Parallèlement, j'espère aussi faire découvrir la littérature vietnamienne aux lecteurs chinois et du monde entier. »"
https://www.vietnam.vn/fr/dich-gia-nguyen-le-chi-duoc-vinh-danh-la-nguoi-ban-cua-van-hoc-trung-quoc
#metaglossia_mundus
|












"This August we once again celebrate Women in Translation (#WiT) Month! This reading series was initiated by blogger Meytal Radzinski in 2014 to raise awareness of translated literature by women, queer, and nonbinary authors, and promote gender and cultural diversity in literary publishing. This year, our free, virtual reading series gathers voices from across time zones for an international celebration!
Organized under the support of PEN America and the PEN America Translation Committee, these events bring together three panels of translators, joined by their authors, working in a diversity of languages. The readings will be followed by brief Q&A discussions. We hope you’ll join us for these one-of-a-kind bilingual readings!
The Women in Translation Reading Series will take place on Zoom on August 7, 14, and 21, 2025. The conversations will be moderated by Nancy Naomi Carlson, Christina Daub, and Marguerite Feitlowitz.
The August 14 session will be moderated by Marguerite Feitlowitz, with readings in Chinese (Taiwan), German, Portuguese (Brazil), Russian (Ukraine), and Vietnamese.
Marguerite Feitlowitz has published five volumes of translations from French and Spanish, most recently Night, by Ennio Moltedo, Pillar of Salt: An Autobiography with Nineteen Erotic Sonnets, by Salvador Novo, and plays by Griselda Gambaro. She is the author of A Lexicon of Terror: Argentina and the Legacies of Torture."
https://pen.org/event/women-in-translation-month-reading-series-2025-session-2/
#metaglossia_mundus