 Your new post is loading...

|
Scooped by
Charles Tiayon
February 21, 2022 8:55 PM
|
Spivak, well known for her translation of Derrida as also some works of Mahasweta Devi, was awarded the Sahitya Akademi Prize for Translation in 1997 I am deeply honoured that the Sahitya Akademi have decided to acknowledge my efforts to translate the fiction of Mahasweta Devi. I want to begin by thanking Mahasweta Devi for writing such spectacular prose. I want to thank my parents, Pares Chandra Chakravorty and Sivani Chakravorty for bringing me up in a household that was acutely conscious of the riches of Bangla. My father was a doctor. But we children were always reminded that my father’s Bangla essay for his matriculation examination had been praised by Tagore himself. And my mother? I could not possibly say enough about her on this particular occasion. Married at fourteen and with children coming at ages fifteen and twenty-three, this active and devoted wife and mother, delighted every instance with the sheer fact of being alive, studied in private and received her MA in Bengali literature from Calcutta University in 1937. She reads everything I write and never complains of the obscurity of my style…. Samik Bandyopadhyay introduced me to Mahasweta Devi in 1979. Initially, I was altogether overwhelmed by her. In 1981, I found myself in the curious position of being asked to write on deconstruction and on French feminism by two famous US journals, Critical Inquiry and Yale French Studies respectively. I cannot now remember why that position had then seemed to me absurd. At any rate, I proposed a translation of Mahasweta’s short story ‘Draupadi’ for Critical Inquiry, with the required essay on deconstruction plotted through a reading of the story. When I look back upon that essay now, I am struck by its innocence. I had been away from home for twenty years then. I had the courage to acknowledge that there was something predatory about the non-resident Indian’s obsession with India. Much has changed in my life since then, but that initial observation retains its truth. I should perhaps put it more tactfully today. Why did I think translating Mahasweta would free me from being an expert on France in the US? I don’t know. But this instrumentality disappeared in the doing. I discovered again, as I had when I had translated Jacques Derrida’s De la grammatologie ten years earlier, that translation was the most intimate act of reading. Not only did Mahasweta Devi not remain Gayatri Spivak’s way of freeing herself from France, but indeed the line between French and Bengali disappeared in the intimacy of translation. The verbal text is jealous of its linguistic signature but impatient of national identity. Translation flourishes by virtue of that paradox. The line between French and Bengali disappeared for this translator in the intimacy of the act of translation. Mahasweta resonated, made a dhvani (literally ‘resonance’), with Derrida, and vice versa. This has raised some ire, here and elsewhere. ‘Gayatri Chakravarty Spivak Living Translation’, published by Seagull Books this month.
| Photo Credit: Special Arrangement This is not the occasion for discussing unhappy things. But let me crave your indulgence for a moment and cite a couple of sentences, withholding theory, that I wrote in a letter to my editor Anjum Katyal of Seagull Books, when I submitted to her the manuscript of my translation of ‘Murti’ and ‘Mohanpurer Rupkatha’ by Mahasweta Devi: [In these two stories] the aporias between gendering on the one hand (“feudal” – transitional and subaltern) and the ideology of national liberation (as tragedy and as farce) on the other, are also worth contemplating. But I am a little burnt by the resistance to theory of the new economically restructured reader who would prefer her NRI neat, not shaken up with the ice of global politics and local experience. And so I let it rest. That hard sentence at the end reflects my hurt and chagrin at the throwaway remark about Gayatri Chakravorty Spivak’s “sermonizing” offered by the reviewer, in India Today, of Imaginary Maps (Routledge, 1995), the very book that you have chosen to honour. I was hurt, of course. But I was chagrined because “sermonizing” was also the word used by Andrew Steer, then deputy director for the environment at the World Bank, in 1992, when I had suggested, at the European Parliament, that the World Bank re-examine its constant self-justificatory and fetishized use of the word people. …(M)y concern is for the constitution of the ethical subject – as life/ translator (Klein), narrow-sense/ translator, reader-as-translator (RAT). Why did I decide to gild Mahasweta’s lily? Shri Namwar Singh, professor of Hindi at Jawaharlal Nehru University, who presided over the occasion, will remember that instructors at the Department of Modern Indian Literatures at Delhi University had asked me in 1987 why, when Bangla had Bankim and Tagore, I had chosen to speak on ‘Shikar’, one of the stories included in Imaginary Maps. …My devotion to Mahasweta did not need national public recognition. To ignore the narrative of action or text as ethical instantiation is to forget the task of translation upon which being-human is predicated. Translation is to transfer from one to the other. In Bangla, as in most North Indian languages, it is anu-vada — speaking after, translatio as imitatio. This relating to the other as the source of one’s utterance is the ethical as being-for. All great literature as all specifically good action — any definition would beg the question here — celebrates this. To acknowledge this is not to “sermonize,” one hopes. Translation is thus not only necessary but unavoidable. And yet, as the text guards its secret, it is impossible. The ethical task is never quite performed. ‘Pterodactyl, Puran Sahay, and Pirtha,’ one of the tales included in Imaginary Maps, is the story of such an unavoidable impossibility. The Indian Aboriginal is kept apart or othered by the descendants of the old settlers, the ordinary “Indian”. In the face of the radically other, the prehistoric pterodactyl, the Aboriginal and the settler are historically human together. The pterodactyl cannot be translated. But the Aboriginal and the settler Indian translate one another in silence and in the ethical relation. This founding task of translation does not disappear by fetishizing the native language. Sometimes I read and hear that the subaltern can speak in their native languages. I wish I could be as self-assured as the intellectual, literary critic and historian, who assert this in English. No speech is speech if it is not heard. It is this act of hearing-to-respond that may be called the imperative to translate. We often mistake this for helping people in trouble, or pressing people to pass good laws, even to insist on behalf of the other that the law be implemented. But the founding translation between people is a listening with care and patience, in the normality of the other, enough to notice that the other has already silently made that effort. This reveals the irreducible importance of idiom, which a standard language, however native, cannot annul. And yet, in the interest of the primary education of the poorest, looking forward to the privative norms of democracy, a certain standard language must also be shared and practised. Here we attempt to annul the impossibility of translation, to deny provisionally Saussure’s warning that historical change in language is inherited. The toughest problem here is translation from idiom to standard, an unfashionable thing among the elite progressives, without which the abstract structures of democracy cannot be comprehended. Paradoxically, here, idiomaticities must be attended to most carefully. I have recently discovered that there is no Bangla-to-Bangla dictionary for this level (the primary education of the poorest) and suitable to this task (translation from idiom to standard). The speaker of some form of standard Bengali cannot hear the self-motivated subaltern Bengali unless organized by politically correct editing, which is equivalent to succour from above. It is not possible for us to change the quality of rote learning in the lowest sectors of society. But with an easy-to-use same-language dictionary, a spirit of independence and verification in the service of rule-governed behaviour — essential ingredients for the daily maintenance of a democratic polity — can still be fostered. The United Nations, and non-governmental organizations in general, often speak triumphantly of the establishment of numbers of schools. We hardly ever hear follow-up reports, and we do not, of course, know what happens in those classrooms every day. But a dictionary, translating from idiom to standard even as it resists the necessary impossibility of translation, travels everywhere. It is only thus that subalternity may painstakingly translate itself into a hegemony that can make use of and exceed all the succour and resistance that we can organize from above. I have no doubt about this at all…. Today as we speak to accept our awards for translating well from the twenty-one languages of India, I want to say, with particular emphasis, that what the largest part of the future electorate needs, in order to accede, in the longest run to democracy, rather than have their votes bought and sold, is practical, simple same-language dictionaries that will help translate idiom into standard, in all these languages. I hope the Akademi will move toward the satisfaction of this need. For myself, I cannot help but translate what I love, yet I resist translation into English; I never teach anything whose original I cannot read and constantly modify printed translations, including my own. I think it is a bad idea to translate Gramsci and Kafka and Baudelaire into Indian languages from English. As a translator, then, I perform the contradiction, the counter-resistance, that is at the heart of love. And I thank you for rewarding what need not be rewarded, the pleasure of the text. Excerpted from Gayatri Chakravarty Spivak Living Translation , published by Seagull Books this month.

Are humans the only beings on the planet that use language to communicate?
"Burg Giebichenstein
Kunsthochschule Halle
“Language can only deal meaningfully with a special, restricted segment of reality. The rest, and it is presumably the much larger part, is silence.” George Steiner
Are humans the only beings on the planet that use language to communicate? Can we decipher the nonhuman world around us without harnessing it to our own socialization, syntax, and lexicon? Is interspecies communication even possible? Translation has been described as a precondition that underlies all (human) cultural transactions upon which communication is based. It also is inherently political and stands at the forefront of so many of today’s questions around identity, gender, post-colonial criticism, feminist critique, machine translation and canon creation, yet its connection within the context of the nonhuman turn, interspecies communication, and eco-criticism has not yet been fully explored.
Whether we are talking about classic linguistic and literary translation, or any number of related fields including: language and literature, cultural studies, performance, visual and media arts—the core question that translators and theorists of translation have been debating about for centuries remains the same: is it possible to translate without interpreting? Is linguistic and cultural equivalence even possible? These questions become all the more urgent in the limit-case of interspecies communication. Can we apply empathic modes of translation to nonhuman articulations, wherein translation involves a form of metamorphosis, not of text, but of the translator. As such, translators are something of a hybrid species with one foot in each culture and language, and whose very existence revolves around traveling between worlds. Translators have something of a mythical being about them, akin to a chameleon or centaur. In this course, we will not be engaging in a scientific exploration of interspecies communication, but examining theories around empathic translation-- a process that sees translation not merely as the transformation of a text, but of the translator themself.
Emerging and classical theories of translation can offer a paradigm for engaging with plant and animal articulation, not language as such, but different forms of articulation perceived through the senses, one in which our hearing and seeing,“once intertwined and attentive to the calls and cries of animals, all but disappeared with the invention of the alphabet, retreating into a kind of silence.”
In David Abram's words: “By giving primacy to perception we can see the natural world, not as inert and passive, but as dynamic and participatory. The winds, rivers and birds speak in their own way (if we listen), the sounds of nature not only have informed indigenous languages, but language in general--humans are but one being intertwined with other beings and ‘presences.’ This perspective sees the landscape as a sensuous field, and human perception as but one point of view that is in reciprocity, in expressive communication, with other points of view and ways of being.”
How can theories of translation help us make sense of this new view of a world teeming with language and sentience? What theories abound in reference to multiplicity of “language,” even as Walter Benjamin would argue for a “universal (human) language.” What practical tools does translation studies offer, and what bridges can it forge between the disciplines? The first half of the seminar focuses on key theoretical concepts relevant to the history and practice of translation. In the second half, students will engage in translation experiments that intersect with their own artistic/design practice. A final project should be considered a first draft of something that could develop later into a larger project.
The course will be taught in English and German.
This seminar is ideally suited to students interested in: Literature, Translation Theory / Translation / Cultural Studies / Critical Theory, Creative Writing/ Post-humanism, Trans-humanism, Eco-criticism, the More-than-Human Turn.
Teachers
Dr. Zaia Alexander"
https://www.burg-halle.de/en/course/l/talk-with-the-animals-translation-in-a-more-than-human-world
#Metaglossia
#metaglossia_mundus
#métaglossie

"Quebec’s language laws face a new reality online: automatic translation
Tech companies moving toward automatic translation may have profound implications on Quebec's linguistic landscape.
By Harry North
April 26, 2026 at 6:00 a.m.
Quebec’s new premier Christine Fréchette meant to post on X about a very Montreal kind of evening.
Her first appearance as premier on Tout le monde en parle, Radio-Canada’s flagship talk show? Check.
The Canadiens’ 4-3 win? Check.
“Une très belle soirée!” (a great evening), she concluded.
...
In Quebec, French by law is required in workplaces, commerce and public signage, and must be no harder to access than any other language. The responsibility rests with those who post it.
So, what happens when language online is available but sometimes inaccurate? What risks do businesses face in relying on platforms to translate? And what does that mean for connection across communities that speak different languages?
OQLF opens door to auto-translation
Quebec’s language watchdog, the Office québécois de la langue française, told The Gazette that commercial social media posts by companies about products or services intended for the Quebec market must be available in French, and that machine translation can be one way of doing that.
“The OQLF believes that using innovative means based on information and communication technologies can help ensure a greater presence of French,” it said in a statement. “If the automatic translation module allows users to access commercial publications in French, without any changes to the settings, regardless of the device used to view them, then these publications would be considered available in French.”
The office added that compliance must be assessed case by case.
“To assess the compliance of commercial publications on a company’s website, for example, a text is considered not to be in French if, to understand it, one must refer to its version in another language.”
Asked whether the OQLF has analyzed the quality of translations, it said: “The OQLF’s mandate does not include analyzing the language quality of content generated by automatic translation tools.”
A review by The Gazette of X posts translated between both English and French found most translations were accurate. Some, however, did not provide the intended meaning. Others were not translated at all.
Automatic translation settings on TikTok (left), X (right) and YouTube (bottom)
/Montreal Gazette
The OQLF’s current framework was not designed with automatic translation in mind, said Julianne Chu, a lawyer and translator for Éducaloi, and it also does not distinguish between how French is produced, and whether it has been human translated, machine translated or even done automatically.
“It really focuses on whether the French translation is available and meets legal requirements, notably in terms of quality and accessibility.”
For businesses, she said, it presents a confusing picture and carries risks, particularly when relying on a platform to handle translation.
How do machines translate language?
Grok’s translations are powered by what are known as large language models, the same kind of system behind tools like ChatGPT, Google’s Gemini and Anthropic’s Claude. Most operate as what researchers call “black boxes”: they generate an output, but offer little insight into how it was produced. They are trained on vast amounts of text to learn how language works. In 2025, nearly six in 10 Canadians used an AI tool like Grok or ChatGPT, according to a Léger survey.
For translation specifically, that training typically happens in two stages, according to Jackie Cheung, a computer science professor at McGill University who researches how AI understands and generates human language.
First, he said, the systems are exposed to enormous volumes of text in English, French and other languages, allowing them to see how words tend to appear together, how sentences are structured and how meaning is usually conveyed.
Then comes a second stage, more specific to translation. The models are trained on pairs of text, and learn how to map one onto the other.
At a basic level, the systems are learning patterns. However, whether these systems truly understand what they are translating, Cheung said, remains a “thorny” question in the field of AI research.
Still, they can be effective at translating the surface of language, he said, especially in more standard or formal contexts.
“What’s kind of missing is the context necessary to understand the intentions of the original poster fully,” Cheung said.
That is particularly true online. Language often depends on shared references — memes, in-jokes and tone — that exist within a community. Outside that context, a translation can feel off or misleading, even if it is technically accurate.
I don’t think (automatic translation) will help that much in terms of increasing connection or inter-community understanding.
Jackie Cheung
McGill professor
Montreal, Cheung noted, has its own version of that, too, where sometimes it may not even be pure French or English spoken or written, but a mix of both.
“The choice of language that you use itself contains information,” he said. “And this would, by definition, be lost if you have auto-translate on.”
The result is a risk that regional expressions, dialects or ways of speaking are smoothed into something more standardized, more aligned to what the generalized models were trained on.
Why AI models may overlook Quebec
Eeham Khan, a PhD researcher at Concordia University, is building a Quebec-first language model to counter that.
“It’s not always just about language,” he said in an interview with The Gazette. “The data that we have is not just the language of Quebec, but it also represents the terms, the cultures, things that maybe other models or larger models might not know about too well.”
When he began working on the project last year, he recalls asking ChatGPT to translate something into Quebec French. The chatbot’s reply was like “it’s forcing itself to be the most ‘redneck Quebecer’ imaginable.”
“It’ll use eight different slang terms in two sentences,” Khan said. “You read it and think: No one talks like this. No one writes like this.
“It knows what the idea of Quebec is, but it takes it to the extreme.”
The biggest problem, he said, is data availability.
Khan is trying to build that foundation, working with partners including Radio-Canada to gather data with consent.
“Even with all of that, we can’t really hope to compare to the big models,” he said, pointing to the time and resources required to collect data ethically. And as those larger systems become more widely used, he said, they begin to shape how language is expressed.
According to Cheung, Indigenous languages raise even more sensitive questions. Some communities may not want their languages fed into translation systems, especially if the result is more access for outsiders than benefit for the community itself.
“The other issue is that it’s not clear that the same pipeline that works for English and French actually works for other languages where there’s not so much data available,” he said, adding that the copious amounts of data that the models heavily rely on may not exist for many other languages.
This month, draft regulations tabled by Marc Miller, minister of Canadian identity and culture and minister responsible for official languages, set out how federally regulated businesses must provide services in French, targeting sectors that have historically slipped through the cracks of Quebec’s Charter of the French Language because they fall under federal jurisdiction.
The Department of Canadian Heritage told The Gazette: “Language compliance requirements remain the same, but the means to fulfil them are evolving. This was taken into account in the analysis leading to the draft regulations that pertain to the private sector.”
It added: “The obligations for federally regulated private businesses that would fall under the jurisdiction of the draft regulations would be to provide communications and services to consumers in French, regardless of the means used. The use of French would need to be at least equivalent to the use of any other language.”
Governments elsewhere in the world are already starting to respond to X’s move. This month, the U.K. Embassy in Japan posted that it was not responsible for Japanese translations automatically generated on X.
Ultimately, Cheung says he remains cautious about auto-translation’s potential to bridge connection.
“You can even see it within English,” he said. “There are so many sub-communities, and there are still massive misunderstandings and polarization.
“I don’t think it will help that much in terms of increasing connection or inter-community understanding,” he said. “Language is an important part of it. But it’s not the whole thing.”
As for Khan, he says he understands “the benefits of having these translation services,” and that “they’re good in promoting accessibility.”
“But on the other hand, this only works really if the translation service works correctly. If you’re mistranslating information from politicians or CEOs coming from these smaller countries, smaller provinces, etc., who are tweeting in their native languages or native dialects, it could potentially be very damaging for those people or for those cultures.
“So, like everything, it has to be done right. It has to be done responsibly. It has to be done carefully.”
Quebec's language laws face a new reality online: automatic translation - Montreal Gazette https://montrealgazette.com/news/quebecs-language-laws-face-a-new-reality-online-automatic-translation/
#metaglossia
#metaglossia_mundus

Poetry translator serves as cross-cultural ambassador for latest project, ‘Last Stops of the Night Journey’
"LAWRENCE — After more than a decade translating leading North American poets – such as Anne Carson and Michael Ondaatje — into Italian, as well as prominent Italian poets into English, Patrizio Ceccagnoli regards literary translation as central to his professional identity, calling himself “an ambassador of my original language and culture, a bridge between the two literatures embodied in the languages I know best.”
A dual citizen, Ceccagnoli translates in both directions, from Italian into English and vice versa, with a particular specialization in poetry. An associate professor in the University of Kansas Department of French, Francophone & Italian Studies, he continues this work with his latest project: Milo De Angelis’ “Last Stops of the Night Journey.”
Ceccagnoli and local poet Megan Kaminski, a professor of environmental studies at KU, will read from their books April 28 at The Raven Book Store.
“I translate only authors I consider significant, for the sake of being close to their work and understanding their oeuvre more deeply,” Ceccagnoli said. “Everything is driven by my love for literature. I find great fulfillment in literary translation, which exists somewhere between scholarly interpretation and creative writing.”
Ceccagnoli said he shares credit with his longtime collaborator and friend, Susan Stewart, a MacArthur Foundation “Genius” award recipient. Together, they previously translated De Angelis’ “Theme of Farewell and After-Poems: A Bilingual Edition” (University of Chicago Press, 2013), a work Ceccagnoli said helped establish the poet’s reputation among American readers.
Their collaborative process is iterative and meticulous.
“I begin with the Italian text and produce a rough English translation, identifying passages that may present cultural challenges — references that require explanation or place names that may not resonate with an American audience,” he said. “When Susan reviews the draft, she identifies additional issues. We then revise collaboratively until we reach a version that satisfies us both after several back-and-forth exchanges.”
The translators also consulted directly with De Angelis while working on “Last Stops of the Night Journey,” occasionally making independent editorial decisions.
“Of course, the publisher also plays a crucial role,” Ceccagnoli said. “When you’re fortunate to work with a strong editor, they offer valuable suggestions and request revisions. This book benefited from particularly attentive editing.”
That editor, Archipelago Books publisher Jill Schoolman, will attend the Lawrence reading.
Like “Theme of Farewell and After-Poems,” “Last Stops of the Night Journey” brings together two separate poetry collections in one volume: “Encounters and Ambushes” (“Incontri e agguati”), released in Milan in 2015, and “Solid Line, Broken Line” (“Linea intera, linea spezzata”), originally published in 2021. These works reflect themes drawn from De Angelis’ experiences teaching poetry in a high-security prison near Milan, the loss of his wife — the poet Giovanna Sicari — and his growing awareness of mortality.
“This is clearly a late work,” Ceccagnoli said. “Every poetic corpus reflects a life lived; it becomes, in a sense, a biography. A writer can only speak to what they have witnessed and understood, and over time, that accumulates into the story of a lifetime.”
He noted that De Angelis’ poetry demands careful, attentive reading.
“A poet like Milo does not necessarily strive for easy accessibility,” Ceccagnoli said. “He has sometimes been described as ‘orphic’ or hermetic – not out of elitism, but because he is committed to a rigorous poetic tradition shaped by earlier models and governed by a highly disciplined literary code.”
At the same time, Ceccagnoli said he finds the collection deeply moving.
“Here is a man who understands that his time is finite,” he said. “In his 70s, he may see this as his final book — a series of farewell messages to the people who shaped his life. That gives the work a powerful sense of authenticity and emotional depth.”
While the collection does not attempt to resolve life’s fundamental questions — about meaning, mortality or what lies beyond — Ceccagnoli said it offers something equally valuable.
“It provides an honest and, at times, dramatic portrait of the people the poet encountered,” he said. “Through his writing, their lives endure — and, in a way, become part of our own.”
Media Contacts
Rick Hellman
KU News Service
785-864-8852
rick_hellman@ku.edu"
Fri, 04/24/2026
Rick Hellman
https://news.ku.edu/news/article/poetry-translator-serves-as-cross-cultural-ambassador-ARTICLE-KHRJWD-ARTICLE-KHRJWD-ARTICLE-KHRJWD-ARTICLE-KHRJWD-ARTICLE-KHRJWD-ARTICLE-KHRJWD
#metaglossia
#metaglossia_mundus
"Luotuo Xiangzi, a landmark work of modern Chinese literature, has been retranslated into English multiple times since its initial success in the United States. This study investigates the translators’ voices in the characterization of Huniu, one of the novel’s most memorable female figures, across four English versions by Evan King, Jean James, Shi Xiaojing, and Howard Goldblatt. Drawing on a self-constructed bilingual parallel corpus, it applies a modified characterization framework together with a three-dimensional model of the translator’s voice appraisal—loudness, pitch, and timbre—by qualitative content analysis and Python-assisted quantitative methods. The findings show that King amplified Huniu’s shamelessness and assertiveness, James softened her portrayal with fewer interventions, Shi preserved her emotional depth while favoring domestication, and Goldblatt significantly softened her vulgar traits through heavy tonal modifications. Variations in lexical choices, sentence length, and syntactic patterns corresponded closely to the dimensions of loudness, pitch, and timbre, demonstrating that translators’ voices actively reframe Huniu’s personality traits, emotional expressiveness, and cultural positioning. This study thus highlights the translator’s voice as a formative force in literary characterization and offers a replicable translator’s voice appraisal model for future translation research."
Jing Cao & Tianli Zhou
Humanities and Social Sciences Communications , Article number: (2026)
providing an unedited version of this manuscript to give early access to its findings. Before final publication, the manuscript will undergo further editing. Please note there may be errors present which affect the content, and all legal disclaimers apply.
Article
Open access
Published: 25 April 2026
Abstract
https://www.nature.com/articles/s41599-026-07326-5
#metaglossia
#metaglossia_mundus

" "The Running Flame" is the third work by Fang Fang that Berry has translated into English.
By Peggy McInerny, Director of Communications
UCLA International Institute, April 24, 2026 — Director of the UCLA Center for Chinese Studies Michael Berry and celebrated contemporary Chinese novelist Fang Fang (author of “Wuhan Diary”) and have together won the 2025 Baifang Schell Book Prize for Fiction as translator and author, respectively, of the English-language translation of Fang Fang’s novel, “The Running Flame.”
“I am especially happy for Fang Fang; one of the most courageous people I know,” said Berry, who is also professor of contemporary Chinese cultural studies in the department of Asian languages and literatures at UCLA.
“She is a writer with an uncanny sensitivity, a gift for storytelling and an unwavering set of moral convictions. Working with her has been one of the greatest honors of my career,” he added. “I hope she sees this award as an affirmation that her words matter and we are listening.”
In an interview with Berry last year, Fang Fang described the predicament faced by Yingzhi, the protagonist of “The Running Flame,” as illuminating the larger challenges faced by rural women in contemporary China. “Women appear to have a home, but internally they may feel rootless. They may feel they have no place in the world at all. Their birth family has cast them out, and their new family does not fully accept them in the beginning,” she said.
“This creates a period of emotional limbo — a vacuum where they feel utterly empty inside. Yingzhi is one such woman caught in this state.”
Originally published in China in 2001, “The Running Flame” is one of only two novels by Fang Fang that have been translated into English to date. The other, “Soft Burial” (also translated by Berry) was originally published in China in 2016. Both novels were short-listed for the 2025 Baifang Schell Prize, along with only three other works of Sinophone fiction. Synopses of all five novels can be found on the short list.
Berry, a well-known scholar of Chinese culture and film, is a prolific translator of Sinophone fiction. He has translated three works by Fang Fang, the first of which was “Wuhan Diary.” Written by Fang Fang during the outbreak of the COVID-19 pandemic in China in 2020, Berry began translating the diary as the pandemic hit the United States and stay-at-home orders began to be instituted by numerous states and metropolitan jurisdictions.
The Baifang Schell Book Prize is an annual award conferred by China Books Review, a free digital magazine based at Asia Society in New York. It is named in honor of Liu Baifang Schell, who passed away in 2021 after spending her life working to advance U.S.-China relations.
The prize was launched in 2024 and celebrates exceptional book-length works on or from China and the Sinophone world that are published in English. It offers two $10,000 awards: one for nonfiction and one for fiction, with both author and translator awarded the latter. Although the prize is administered by China Books Review, annual winners are chosen by independent juries. An awards ceremony for the 2025 winners will be held on June 9 at Asia Society in New York.
Published: Friday, April 24, 2026
https://www.international.ucla.edu/institute/article/295336
#metaglossia
#metaglossia_mundus

"His role was to act as a liaison between the US forces and the Afghan national army and police officers they worked alongside. He provided translation and cultural advice.
"The Americans did not know which one is the mosque, which one is the normal house. But we would know; we would see books, we would see praying rugs," he says.
"So if you see an American walking inside a mosque with their boots on and with their canine dogs, it would trigger the civilians right away."
Targeted by his own countrymen
Many Afghan civilians resented the Americans, but they also detested the translators, like Sheraz, who worked with them.
"They didn't like interpreters at all. They would treat them as an infidel, who doesn't believe in God," Sheraz says.
Sheraz's brother Ferdows was killed by an IED in 2017, and later, his family home was targeted in a bomb attack that severely injured his father and younger brother.
Sheraz believes the attacks were in revenge for his work.
"His hands, his feet were burned … when the explosion happened, they ran away," Sheraz tells 7.30.
"But as soon as they remembered that my dad is inside, he just went back to the fire and grabbed him and pulled him out. So they got burned while they were taking my dad out of the fire."
By that time it had become clear that Afghanistan was no longer safe for Sheraz, or his family.
In 2019, he along with his wife and son were granted visas to Australia as part of a government scheme to help those who had worked with Australian troops.
Gus McFarlane had written supporting letters to help the family come to Australia.
"He, in my opinion, directly contributed to my safety and the safety of other Australian soldiers that were deployed in Afghanistan," says Lieutenant Colonel McFarlane.
Sheraz's parents and younger brother have subsequently been granted visas.
On the eve of Anzac Day he told 7.30 that he doesn't have lingering trauma from the years of conflict in Afghanistan.
"Maybe Afghans are tough," he says.
"They face war for more than 50 years now. Maybe that's another reason, because since we were kids, we hear firearms … we're talking about war, about losing family members, losing relatives, and they see bombs, they see people get blown up, they see vehicles blown up."
As he is explaining the impact of war on Afghanistan's people, his children Sultan and Sophia come barrelling into the lounge room.
"What if I was stuck in Afghanistan still, so my daughter wouldn't be able to go to school and my family and I wouldn't be safe," Sheraz says.
"I think about the positives that I have in my life now."
Lieutenant Colonel McFarlane says he's proud that the RSL is recognising Sheraz, and all the locally-engaged staff this Anzac Day...."
By Adam Harvey
7.30
Topic:Anzac Day
https://www.abc.net.au/news/2026-04-23/sheraz-ahmadi-afghan-translator-australia-troops-anzac-day/106585112
#metaglossia
#metaglossia_mundus

"Next-word prediction has been hypothesized as the central computational objective of the human language system, akin to that of current large language models. Here we put this conjecture to the test, investigating whether the brain predicts each upcoming word as precisely as possible when listening to connected speech. In three magnetoencephalography experiments with Mandarin Chinese speakers, we demonstrate that the response related to word unpredictability, that is, word surprisal calculated using large language models, is significantly stronger for words within an ongoing constituent than words across a major constituent boundary, and this effect is further modulated by the certainty of a constituent boundary. This constituent-boundary effect is also observed behaviorally unless speech is very slowly presented, and it is confirmed by analyzing a dataset of electrocorticography responses to natural English narratives. The constituent-boundary effect demonstrates that the language system does not solely optimize word-prediction precision; rather, it balances word-prediction contributions by constituent-constrained management of linguistic contextual representations."
Jiajie Zou (邹家杰), David Poeppel & Nai Ding (丁鼐)
Abstract
https://www.nature.com/articles/s41593-026-02272-6
#metaglossia
#metaglossia_mundus

There is (or should be) perfect harmony between faith and reason...!
"Christ does not appear as a religious escape in the face of intellectual endeavors, as if faith began where reason ended. On the contrary, in Him the profound harmony between truth, reason and freedom are manifested."
Pope Leo XIV made this point in Equatorial Guinea when meeting with the World of Culture in Malabo at the National University's León XIV Campus on 21 April 2026.
He acknowledged the inauguration of the new campus of the National University of Equatorial Guinea in his name, expressing his gratitude for the kind gesture, but stressing that "such a decision goes beyond the person being honored as it reflects the values that we all want to pass on to others."
The inauguration of a university campus is more than a mere administrative act, but rather is "an act of trust in human beings, an affirmation of the fact that it is worth the effort to continue wagering on the formation of new generations and on the task, so demanding and yet so noble, of seeking the truth and putting knowledge at the service of the common good."
He stressed therefore that a space for hope, encounter and progress is opened, and accordingly used the image of a tree to speak of the university’s mission, as he remembered that for the people of Equatorial Guinea, the ceiba, the national tree, has a great symbolic meaning.
Deep roots and persevering search for truth
The Pope remembered that a tree puts forth deep roots, and ascends slowly with patience and strength to the heights, embodying a fruitfulness that does not exist for itself.
Likewise, he suggested, "a university is called to be well rooted in the seriousness of study, in the living memory of a people and in the persevering search for truth...
Christ does not appear as a religious escape in the face of intellectual endeavors, as if faith began where reason ended.
On the contrary, Pope Leo insisted, in Him the profound harmony between truth, reason and freedom are manifested.
In this context, the Holy Father explained that truth presents itself as a reality that precedes human beings, challenges them and calls them to come out of themselves, saying this is why truth can be sought with trust.
"Faith, far from shutting itself off from this search," he added, "purifies it of self-sufficiency and opens it to a fullness towards which reason strives, even if it cannot completely embrace it."
...
Christ manifests harmony between faith and reason - Pope Leo in Equatorial Guinea (Vatican News)
By Deborah Castellano Lubov
21 April 2026, 18:22
https://www.vaticannews.va
#metaglossia
#metaglossia_mundus

"L’entreprise d’IA linguistique DeepL lance Voice-to-Voice, une suite de solutions de traduction vocale en temps réel pour les entreprises.
Le leader de l’intelligence artificielle linguistique, DeepL, a annoncé aujourd’hui le lancement de DeepL Voice-to-Voice, une nouvelle gamme de solutions de traduction en temps réel conçue pour la communication orale. Cette innovation majeure permet une traduction vocale instantanée pour les réunions virtuelles, les conversations en face à face et les interactions avec la clientèle, avec l’ambition de supprimer définitivement les barrières linguistiques dans le monde professionnel.
« Aujourd’hui, nous franchissons une nouvelle étape dans le domaine de la traduction : la communication vocale en temps réel », a déclaré Jarek Kutylowski, fondateur et PDG de DeepL. « Notre mission a toujours été de supprimer les barrières linguistiques et nous venons de faire tomber l’une des plus importantes. DeepL Voice-to-Voice permet à chacun de s’exprimer naturellement dans sa propre langue, et cela sans engendrer de frictions ni de coûts liés aux interprètes. Désormais, seule l’expertise compte, pas la langue ».
Une suite complète pour la communication en temps réel
DeepL Voice-to-Voice a été développée pour répondre à un besoin critique des organisations internationales : la traduction orale. La suite se décline en plusieurs outils intégrés :
* Voice for Meetings : Une solution de traduction en temps réel pour les plateformes de visioconférence comme Microsoft Teams et Zoom. Les participants parlent dans leur langue et sont entendus par les autres dans la leur. Un programme d’accès anticipé débutera en juin.
* Voice for Conversations : Déjà disponible sur mobile, cette fonctionnalité est désormais étendue au web pour une expérience multi-plateforme, facilitant son déploiement dans des environnements professionnels stricts.
* Group Conversations : Disponible à partir du 30 avril, cet outil est conçu pour les formations et ateliers multilingues. Les participants peuvent rejoindre une conversation via un code QR et bénéficier d’une traduction simultanée.
* API Voice-to-Voice : Permet aux entreprises d’intégrer la technologie de DeepL directement dans leurs applications, notamment dans les centres de contact.
* Personnalisation : Dès le 7 mai, les glossaires de traduction seront intégrés pour garantir la transcription et la traduction correctes de terminologies spécifiques (noms de produits, jargon sectoriel), même à un débit de parole rapide.
Qualité et accessibilité au cœur de la stratégie
Pour valider la performance de sa technologie, DeepL a commandité une évaluation indépendante menée par Slator. Les résultats montrent que 96 % des linguistes professionnels ont préféré DeepL Voice aux solutions natives de Google, Microsoft et Zoom, saluant sa fluidité et sa précision contextuelle. Les intégrations pour Zoom et Microsoft Teams ont obtenu des scores de qualité de 96,4/100 et 96,3/100 respectivement.
DeepL a également élargi le nombre de langues prises en charge à plus de quarante, incluant les 24 langues officielles de l’UE ainsi que l’arabe, le vietnamien, le thaï, ou encore l’hébreu. En parallèle, l’entreprise rend sa technologie plus accessible en proposant un modèle en libre-service, permettant aux petites équipes de tester la solution via un essai gratuit avant un déploiement plus large.
Un levier de performance pour les équipes internationales
L’impact de cette technologie sur la collaboration globale est déjà mesurable chez les premiers utilisateurs. Yoichi Okuyama, directeur du département DX Systems chez Pioneer, témoigne de cette transformation : « S’appuyer uniquement sur la maîtrise de l’anglais pour collaborer à l’échelle mondiale nous ralentissait souvent, car les membres de l’équipe hésitaient à partager des idées complexes. En mettant en place DeepL Voice, nous avons supprimé cette friction et instauré un environnement plus inclusif où chacun peut s’exprimer en toute confiance dans sa langue maternelle. Ce changement a permis d’accélérer nos processus métiers : une fois les barrières levées, nous avons constaté une participation plus engagée et une prise de décision plus rapide au sein de nos équipes internationales ».
DeepL Translate : une plateforme pour repenser les flux de travail
En parallèle de cette annonce, DeepL fait évoluer son outil principal vers une plateforme d’IA entièrement intégrée, DeepL Translate. L’objectif est de s’attaquer aux lenteurs et aux coûts des processus de traduction traditionnels en entreprise. « Les entreprises internationales ne se confrontent plus à une difficulté de traduction. Elles rencontrent un problème de modèle opérationnel », a ajouté Jarek Kutylowski. La nouvelle plateforme vise à centraliser et automatiser les flux de traduction, à évaluer la qualité des textes générés et à permettre des améliorations continues grâce aux corrections des utilisateurs.
Cette vision d’une traduction fluide et intégrée est partagée par des clients comme Mondelez International. « Notre ancien processus de traduction, c’était comme rouler avec un pneu crevé, tandis qu’avec DeepL, nous passons à la vitesse supérieure, à 160 km/h », souligne Geoffrey Wright, Global Solution Owner chez Mondelez. « Grâce à l’intégration de leur IA linguistique, des équipes telles que celles en charge des fusions-acquisitions et des affaires juridiques traitent des documents sensibles avec rapidité et en toute confidentialité ».
Fondée en 2017 par Jarek Kutylowski, DeepL est une entreprise spécialisée dans l’IA linguistique qui compte aujourd’hui plus de 1 000 employés. Elle est soutenue par des investisseurs de premier plan comme Benchmark, IVP et Index Ventures."
COLOGNE : Jarek KUTYLOWSKI : « Seule l’expertise compte, pas la langue »19 Avr 2026
https://presseagence.fr/cologne-jarek-kutylowski-seule-lexpertise-compte-pas-la-langue/
#metaglossia
#metaglossia_mundus
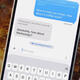
"There are all kinds of ways to use your phone to help you learn a language of course, but here’s one you might not have come across before: You can enable real-time translations for a host of different languages right inside the Messages app on iOS.
It works through the Apple Translate built into your iPhone, and it’s a great way to keep reminding yourself of conversational words and phrases. As demoed by @thetarynarnold over on TikTok, they’ll appear right alongside the messages you’re sending and receiving.
However, you will need Apple Intelligence on your iPhone for this to work. Apple’s proprietary AI is built into the operating system that runs on the iPhone 15 Pro and iPhone 15 Pro Max from 2024, plus every iPhone released since then, as well as a few other Apple devices like the iPad mini and Apple Watch Series 6. Head to Apple Intelligence & Siri in the iOS Settings to make sure Apple Intelligence is enabled on your phone.
How to enable translations in Messages
Open up the conversation you’d like to translate inside the iOS Messages app, then tap the name of the person you’re messaging up at the top of the screen. Next, enable the Automatically Translate toggle switch, and you’ll be asked to pick a language.
At the time of writing there are 20 available, and you can change the language you’re translating from and to at any time—the relevant options are underneath the Automatically Translate toggle switch, once you’ve turned it on.
From this point on in the conversation, every message you send in English will have the foreign translation right next to it, and every message you receive in the selected foreign language will have an accompanying English translation too. There’s a little drop-down menu just above the text input box that you can use to swap languages or stop the translation at any time.
This should work with anyone else on an iPhone, whether or not they have Apple Intelligence installed on their device. You should also see these translations from anyone texting you with an Android phone (Google Messages has a similar translation feature they can use too).
It’s not complicated, but that’s the beauty of it. While you couldn’t really learn an entirely new language just from doing this, it’ll definitely help you stay familiar with foreign words and phrases, as you get instant translations for what you’re saying.
Other translation tools on your iPhone
Assuming you do have Apple Intelligence installed on your iPhone, there are a host of other ways you can get translations from English into another language right away. It starts with the built-in Translate app of course, which can convert typed text and spoken audio between languages.
You’ll also notice a Camera button down at the bottom of the Translate app. Tap on this and you can point your iPhone camera at anything written in a foreign language—whether it’s a sign at a train station or something on a menu—and have the text translated. The Conversation tab, meanwhile, lets both you and someone else speak in different languages, and have the iPhone do the translating.
If you have a pair of AirPods Pro 2, AirPods Pro 3, or AirPods 4 with active noise cancelling attached to your iPhone, there will also be a Live button. Tap on this, and as other people speak to you in a foreign language, you’ll get translations right into your ears, through your AirPods. The dialog will show up on your phone too.
Translation is built into the FaceTime app as well. Tap on the screen to bring the controls up, then tap the three dots and pick Live Captions to use it. Something similar is available for live calls through the Phone app too, which you can access by tapping the three dots during a call, and choosing Live Translation.
All the language processing for these features is done on your device, and nothing is sent to the cloud or Apple’s servers. To change the languages you have downloaded to your iPhone and available in these apps, open the main iOS Settings screen and choose Apps > Translate > Languages."
David Nield
Published Apr 18, 2026 1:00 PM EDT
https://www.popsci.com/diy/translations-iphone-messages/
#metaglossia
#metaglossia_mundus
"New Voices in Translation Studies
Call for Special Issue Proposals
Deadline for proposals: 1 December 2026."
New Voices in Translation Studies invites original and innovative proposals for Special Issues that explore new or under-researched areas of translation. The journal welcomes contributions that explore diverse aspects of translation studies.
Your proposal should include:
Proposed topic/title
Brief outline of the topic (including its significance and relevance to the field)
Names and short biographies of the proposed guest editor(s) [NB: guest editor (or most members of the editorial team) should be early career or emerging scholars.]
Proposed timeline (including dates for call for papers, submission deadline, peer review, revisions, and final submission)
If applicable, a list of confirmed contributors with paper titles and abstracts. [The journal accepts that in such a case, some prior work may have been done, but all contributions will still need to pass through New Voices in Translation Studies submission and review processes as usual. NB: contributors should also be early career or emerging scholars.]
Submission Guidelines
Email your proposal to marija.newvoices@gmail.com
Use the subject line: NVTS Special Issue Proposal
You may submit as an individual guest editor or as part of a team.
All proposals will be evaluated by the editorial board based on originality, feasibility, academic quality, and relevance to our readership.
Deadline for proposals: 1 December 2026."
More information: https://newvoices.arts.chula.ac.th/index.php/en/announcement/view/4
#metaglossia
#metaglossia_mundus

Imparfait, plus-que-parfait, passé composé… Muriel Gilbert révèle l'origine étonnante des noms de nos temps...
Pourquoi l'imparfait porte un nom si étrange
Ce samedi 18 avril, un Bonbon grammatical, amis des mots, sur une idée de Gilles, sur la page Facebook du Bonbon sur la langue : "Bonjour Muriel... Pourriez-vous consacrer un Bonbon à nous expliquer la signification (et l'origine) du nom des temps des verbes ? Ils m’ont toujours étonné. À part le présent, le futur et l'impératif, qui sont assez clairement compréhensibles, quid de l'imparfait, du passé composé, du plus-que-parfait ? Merci Mumu."
Eh bien, "Mumu" s'exécute. C’est vrai que ces noms sont bizarroïdes, et pas très parlants. On va se contenter de parler du mode indicatif, on gardera les autres pour une autre fois ! Je trouve que le passé composé, c’est quand même assez clair : "Antoine a préparé le petit déj", "Valérie est venue manger" : on est dans le passé, mais ce passé est composé parce qu’il faut deux mots pour l’exprimer : a + préparé, est + venue.
L'imparfait c'est : "Antoine préparait le petit déj". "Valérie venait manger". À l’origine, le mot "imparfait" était un adjectif : on parlait de prétérit imparfait. Le terme "prétérit", qui s’emploie encore pour l’anglais, n’est plus utilisé en grammaire du français. Il vient du latin praeteritum, à l’origine praeteritum tempus, qui désignait un "temps passé" (praeter c’est devant, et ire c’est aller, donc le praeteritum c’est "passé devant", comme qui dirait… "dépassé"). On parlait au XVIIe siècle de "prétérit imparfait", de "prétérit simple" et de "prétérit antérieur", qui sont devenus nos actuels "imparfait", "passé simple" et "passé antérieur".
Pourquoi le mot "imparfait" ?
Et donc pourquoi ce mot, "imparfait" ? Il faut revenir à l’étymologie : évidemment, imparfait découle de parfait, parfait venant du perfectum latin qui n’a pas du tout le sens d’aujourd’hui : il veut dire "achevé", "terminé", "accompli", c’est plus tard en français qu’il a glissé vers le sens de "idéal, excellent". Bref, l'imparfait, ce n’est pas un temps qui ne serait pas parfait dans le sens qu’il aurait un défaut, c’est un temps du passé qui est décrit comme non achevé. "Muriel lisait quand le livreur sonna." La lecture se fait sur une certaine durée, "sonna" en revanche est au passé simple, car c’est un fait ponctuel. Bref l’intéressant, c’est que "parfait" signifie “accompli”, et non pas "génial", donc "imparfait" signifie "non accompli", pas "un peu nase".
Et pour le plus-que-parfait ? Il se construit avec être ou avoir à l’imparfait suivi d’un participe passé. Le plus-que-parfait est censé désigner une action passée antérieure à une autre action passée. Exemple : "J’avais terminé ma chronique, donc je sortis du studio" (je sortis du studio, ça se produit dans le passé, mais avant cela encore, j’avais terminé ma chronique, plus-que-parfait). Quoi qu’il en soit, ces appellations mériteraient un bon coup de ménage, si vous voulez mon avis, parce qu’elles n’ont pas grand-chose de logique..."
Muriel Gilbert
https://www.rtl.fr/culture/culture-generale/langue-francaise-pourquoi-l-imparfait-porte-ce-nom-si-etrange-7900624484
#metaglossia
#metaglossia_mundus

"...«Continuer à communiquer le désir de chacun de trouver la paix, non pas une paix d'indifférence, non pas une paix qui nie la richesse des différences, mais une paix qui naît de la reconnaissance que nous sommes tous frères et sœurs, tous créatures de l'Un, tous appelés au respect de la dignité de tous». Au Cameroun, a expliqué le Pape, il existe une formidable opportunité de réaliser ce rêve, ce désir qui se mue en engagement. Léon XIV a encouragé les personnes présentes à poursuivre ce beau chemin, à porter ce même message, ce même rêve, aux autres, aux musulmans, et à tous ceux qui ne comprennent pas encore, mais peuvent apprendre à percevoir la beauté de la fraternité pour le plus grand bien de tout le Cameroun..."
Vatican News https://share.google/MQAXWw9KQaFKp0Ds9
#metaglossia
#metaglossia_mundus

"COLOGNE, Germany, April 17, 2026 /PRNewswire/ -- Today, Language AI leader DeepL launched DeepL Voice-to-Voice, a real-time translation product suite designed for live spoken communication. By expanding into speech-to-speech translation, DeepL now delivers instant voice translation for virtual meetings, in-person conversations, and customer-facing touchpoints via API, empowering teams to collaborate anywhere without language barriers.
Jarek Kutylowski, Founder & CEO of DeepL said: "Today, we reach another frontier in translation: real-time, spoken communication. Our mission has always been to break down language barriers and we've now overcome one of the biggest of all. DeepL Voice-to-Voice allows everyone to speak naturally in their own language without the friction or cost of interpreters. We're fusing world-class voice models with the gold-standard translation AI we've been pushing to new heights. Now, expertise is all that counts, not language."
DeepL Voice: Real-Time Communication Across Platforms
DeepL Voice is built to overcome one of the critical language barriers remaining in organizations - spoken translation, whether in person or virtually. The DeepL Voice-to-Voice product suite includes:
- Voice for Meetings: Provides real-time translation in platforms like Microsoft Teams and Zoom, allowing participants to speak their native language while others hear it in theirs. (Early access programme in June, registration now open).
- Voice for Conversations (Mobile & Web): Voice for Conversations now extends beyond mobile, enabling a true multi platform experience that can be deployed in environments where installing apps is not practical or allowed. (Now generally available).
- Group Conversations: Facilitates multilingual exchanges in training, coaching, and workshop settings, with participants joining instantly through a QR code. This enables frontline workers to maintain shared understanding during hands-on interactions with multiple speakers. With multi device access, participants can receive simultaneous voice translation in real time. (Generally available April 30).
- Voice-to-Voice API: Enables businesses to integrate DeepL's voice translation directly into their own internal applications and customer-facing tools, such as their contact center. (Early access programme ongoing, registration now open).
- Customization with spoken terms: New quality optimization capabilities in DeepL Voice help ensure specific terminology is captured, transcribed, and translated more accurately in real time, including industry specific terms, product and company names, and given names, even when speech is fast or highly technical. As part of this, DeepL translation glossaries will be integrated into DeepL Voice so users can standardize key terminology across conversations. (Generally available on May 7).
DeepL is also making its existing voice-to-text technology more accessible with small teams being able to now purchase DeepL Voice directly online. This self-serve model allows businesses to start a free trial and deploy voice translation immediately to test before expanding.
The launch also introduces support for a broad range of languages for DeepL Voice, including all 24 official EU languages, alongside Vietnamese, Thai, Arabic, Norwegian, Hebrew, Bengali, and Tagalog. The total number of languages for DeepL Voice now stands at over forty.
In blind evaluations, conducted independently by Slator and commissioned by DeepL, DeepL Voice was consistently chosen by professional experts: 96% of linguists preferred DeepL Voice over the native translation solutions provided by Google, Microsoft, and Zoom, citing superior fluency and contextual accuracy. DeepL Voice for Zoom and DeepL Voice for Microsoft Teams achieved exceptional quality scores of 96.4/100 and 96.3/100, respectively, significantly outperforming competing platforms.
Yoichi Okuyama, Head of DX System Department at Pioneer, added: "Relying solely on English proficiency for global collaboration often slowed us down, as team members hesitated to contribute complex ideas. By implementing DeepL Voice, we've removed that friction and created a more inclusive environment where everyone can speak confidently in their native language. This shift has helped accelerate our business processes; with barriers removed, we've seen more active participation and faster decision-making across our global teams. It's transformed translation from a technical necessity into a key enabler for speed and efficiency."
Launching the next generation DeepL Translator platform
Alongside the Voice launch, DeepL is evolving its core Translator into the next-generation DeepL Translator platform, creating the end-to-end translation infrastructure for modern enterprises. DeepL is addressing the inefficiencies of traditional translation management, which often relies on slow, rigid and manual coordination that is very expensive for businesses.
"Global businesses no longer have a translation problem; they have an operating model problem, with today's language solutions often being too slow to scale and a costly drag on growth for businesses," added Jarek. "We're bringing translation and language fully into the AI age. By centralizing translation operations in an AI-first, multilingual platform, every team can access fast, high-quality translations without being held back by legacy tools or relying on expensive third-party language services."
With its new Translator platform, DeepL is tackling key pain points in enterprise translation operations.
- Translation Flow: Translation no longer slows work down or sits in separate tools. Content moves through existing systems and is translated instantly, with the right terminology and tone applied automatically. Every team works from the same voice, without extra steps or manual coordination.
- Translation Quality Assessment: Teams can see exactly how reliable a translation is, with an evaluation criteria highlighting anything that might need attention. Instead of guessing, teams know when content is ready to use and when it needs a second look.
- Ongoing improvements: Edits can be made directly in the product, with full control over the final output. Every correction is learned from, so translations continuously improve over time, adapting to each business as team members work.
By removing friction across the translation process, DeepL's Translator platform extends high-quality translation capabilities beyond a single function and into the hands of teams across the business, directly within their day-to-day workflows.
Geoffrey Wright, Global Solution Owner - GenAI and Digital Experience at Mondelēz International recently highlighted the impact of this shift: "At Mondelēz, we don't settle for slow—on the road or in our workflows. Our old translation process was like driving on a flat tyre, but DeepL is full service at 100 mph. By embedding their Language AI, teams like M&A and Legal are handling sensitive documents with top speed and total confidentiality. When you make the impossible look that easy, word travels fast; we've seen adoption accelerate across the entire organization."
About DeepL
DeepL is a global AI company building the language infrastructure that powers global business. More than 200,000 business teams and millions of individuals use DeepL's Language AI platform to communicate globally, collaborate and operate across languages in real time. By combining breakthrough AI models with enterprise-grade security and privacy, DeepL enables organizations to work seamlessly across markets and cultures. Founded in 2017 by CEO Jarek Kutylowski, DeepL now has more than 1,000 employees and is backed by leading investors including Benchmark, IVP and Index Ventures. Learn more at www.deepl.com.
SOURCE DeepL
https://www.prnewswire.com/apac/news-releases/deepl-unveils-real-time-spoken-translation-breaking-the-next-language-barrier-with-voice-to-voice-302744523.html
#metaglossia
#metaglossia_mundus

"Léon XIV appelle les universitaires à réconcilier science, foi et responsabilité
... Léon XIV a insisté sur la vocation particulière des universités catholiques: devenir de «véritables communautés de vie et de recherche», capables de promouvoir une fraternité intellectuelle et humaine. Citant le Pape François, il a rappelé que leur mission consiste à favoriser «une authentique culture de la rencontre», fondée sur le dialogue entre les cultures et la quête commune de la vérité.
Retrouver le sens de la vérité dans un monde fragmenté
Dans un contexte où «beaucoup dans le monde semblent perdre leurs repères spirituels et éthiques, se retrouvant prisonniers de l’individualisme, de l’apparence et de l’hypocrisie», l’Université est, par excellence, selon le Saint-Père, un «lieu d’amitié, de coopération, mais aussi d’intériorité et de réflexion». S’attardant ensuite sur ses origines qui remontent au Moyen Âge, le Pape a noté que «ses fondateurs lui ont donné pour objectif la Vérité». Aujourd’hui encore, a-t-il continué, «professeurs et étudiants sont appelés à se donner comme idéal et, en même temps, comme mode de vie, la recherche commune de la vérité.» Reprenant ensuite les mots de saint John Henry Newman, Léon XIV a déclaré aux 8000 participants à la rencontre que «tous les principes vrais regorgent de Dieu, tous les phénomènes conduisent à Lui». Le Pape a également souligné la complémentarité entre foi et science, s’appuyant sur Lumen fidei, de son prédécesseur: la foi, loin de freiner la recherche, «élargit les horizons de la raison» et nourrit l’esprit critique.
Sur le «magnifique» continent africain, la recherche est particulièrement mise au défi de s’ouvrir à des perspectives interdisciplinaires, internationales et interculturelles, a expliqué le Saint-Père. Il y a donc un «besoin urgent de repenser la foi au sein des réalités culturelles et des défis actuels, afin d’en faire ressortir la beauté et la crédibilité dans les différents contextes, en particulier ceux qui sont le plus marqués par les injustices, les inégalités, les conflits, la dégradation matérielle et spirituelle.» Pour l’évêque de Rome, la «grandeur d’une nation ne peut se mesurer uniquement en fonction de l’abondance de ses ressources naturelles, ou de la richesse matérielle de ses institutions.»
“L’Afrique peut contribuer de manière fondamentale à élargir les horizons trop étroits d’une humanité qui a du mal à espérer.”
Face aux défis du numérique et de l’intelligence artificielle, le Successeur de Pierre a mis en garde contre les effets d’une numérisation croissante des sociétés, en particulier en Afrique, où les enjeux économiques et environnementaux sont déjà sensibles, alertant sur le risque d’un «remplacement progressif de la réalité par sa simulation». Dans des environnements numériques conçus pour capter l’attention et influencer les comportements, la relation humaine pourrait être réduite à une simple interaction fonctionnelle. «Lorsque la simulation devient la norme, la capacité humaine de discernement est diminuée […] la réalité devient facultative et l’humain gouvernable par des systèmes invisibles», a-t-il averti. Face à cette transformation, il a appelé à une formation humaniste solide, capable de décrypter les logiques économiques et les rapports de pouvoir intégrés dans ces technologies...."
Léon XIV appelle les universitaires à réconcilier science, foi et responsabilité - Vatican News https://www.vaticannews.va/fr/pape/news/2026-04/universite-pape-foi-savoir-intelligence-artificielle-cameroun.html
#metaglossia
#metaglossia_mundus

"Ce 16 avril, nous fêtons les 100 ans de la naissance d’André Goosse. Moins connu du grand public que son beau-père Maurice Grevisse, ce grammairien belge a pourtant façonné "Le Bon Usage", la bible mondiale du français. À cette occasion, Anne-Catherine Simon, linguiste à l’UCLouvain, revient sur l'héritage de ces deux géants.
Par
Alain Nassogne
Si vous ouvrez une grammaire pour trancher un accord épineux, il y a de fortes chances que vous consultiez l'œuvre de deux Belges. Maurice Grevisse et André Goosse sont les architectes du Bon Usage, une institution née en 1936 qui fait encore autorité de Paris à Kinshasa, jusqu'au sein de l'Académie française.
La méthode Grevisse : L'usage avant la règle
Contrairement aux idées reçues, la grammaire "Grevisse-Goosse" n'est pas un code de lois figé. Sa force ? L'observation. " Maurice Grevisse se donnait comme mot d’ordre d’observer l’usage avant de juger ou d’établir les règles ", explique Anne-Catherine Simon.
Pour ces grammairiens, le "bon" français se niche dans la plume des écrivains et écrivaines qui maîtrisent admirablement la langue. C'est en analysant comment la grammaire est réellement appliquée dans les œuvres littéraires que Grevisse a produit une description vivante, révisée sans cesse au fil de ses 11 éditions personnelles.
Le Bon Usage : une histoire de famille
L'histoire du Bon Usage est aussi une affaire de famille. Arrivant à la fin de sa vie, Maurice Grevisse a désigné un successeur qu'il connaissait parfaitement : André Goosse, qui n'était autre que son gendre.
Pour Goosse, déjà renommé, reprendre le flambeau fut un honneur immense. Sa mission ? Continuer à donner vie à l'ouvrage. " La langue étant vivante, elle évolue. Chaque année, de nouveaux usages prennent la place d'usages plus anciens ", souligne la linguiste. C'est ainsi que l'œuvre est devenue ce que l'on appelle aujourd'hui la grammaire "Grevisse-Goosse".
Pourquoi les Belges sont-ils de meilleurs grammairiens ?
Il peut sembler paradoxal que les plus grands référents du français soient belges. Pour Anne-Catherine Simon, cela tient à une forme d'humilité géographique : L'absence de certitude. Contrairement à certains locuteurs en France, les Belges n'ont pas cette " certitude intérieure " de pratiquer naturellement le français parfait. Cette position les pousse à être des observateurs plus attentifs, plus précis et plus fouillés. Résultat : leurs descriptions font autorité, même pour les institutions françaises les plus prestigieuses.
Le "Grevisse" face au "Bescherelle"
Tout le monde connaît le Bescherelle, mais les deux ouvrages ne boxent pas dans la même catégorie. Si Louis-Nicolas Bescherelle est né en 1802 et a publié son célèbre manuel dès 1842, son approche est très différente :
Le Bescherelle : Concis, abrégé, il est l'allié des élèves de l'école primaire.
Le Bon Usage : Monumental et complet, il est l'outil indispensable des spécialistes et des professionnels de la langue.
Vers une 17e édition 100% connectée ?
Depuis 1936, Le Bon Usage a connu 16 éditions, la dernière datant de 2016. Le monde de la linguistique attend désormais la 17e édition avec impatience. Le défi de cette nouvelle version ? Être totalement consultable en ligne pour devenir accessible au plus grand public, tout en restant la référence ultime des experts."
https://share.google/xxbI5edc77ruP3LrA
#metaglossia
#metaglossia_mundus

"... transformer la diversité culturelle en une grâce pour le vivre-ensemble.
Jean-Paul Kamba, SJ – envoyé spécial
Dans le contexte camerounais où la soif de paix et de cohésion n'a jamais été aussi ardente, cette visite apostolique s'annonce comme un tournant décisif. Le père Bassoumboul livre une réflexion profonde sur la portée de cette visite et rappelle que l'unité n'est pas un simple slogan, mais un engagement quotidien à l'école de l'Évangile et des grandes «figures missionnaires de notre terre»...
Dans un pays marqué par des diversités culturelles et parfois des tensions internes, en quoi la présence du Successeur de Pierre constitue-t-elle un «sacrement de l'unité» pour tous les Camerounais, au-delà des clivages religieux ?
La diversité culturelle implique pluralité. Celle-ci est une invitation à l’unité. Pour cela, l’on pourrait dire que le défi de la diversité culturelle est la cohésion, la conscience de l’interdépendance. À ce titre, la diversité culturelle est une belle richesse à bien piloter.
L’histoire biblique de l’humanité présente la fraternité comme un lieu de tensions, souvent pathétiques. Je citerais les fratries de Caïn et Abel, Ésaü et Jacob, Joseph et ses frères, etc. Même entre les douze Apôtres, il y a eu des épisodes de tensions internes. Mais, dans le même temps, ces récits de fraternités tendues sont riches d'enseignement sur les procédés de reconstruction et de réconciliation. C’est l’attitude de Jacob envers son frère, animé d’une rage meurtrière contre lui en Gn 33. Je suis aussi toujours fasciné par les larmes de Joseph en Gn 45. Je les interprète très souvent comme l’eau qui efface les torts subis pour reconstruire la fraternité et l’unité familiale.
Certains ont estimé que les tensions que traverse le Cameroun en ce moment étaient un motif pour que le Saint Père n’y aille pas. Or, cet argument est paradoxalement une raison suffisante pour sa venue. Comme Successeur de Pierre, il vient nous rappeler que la beauté de la vie en famille est dans la paix véritable, la force d’une nation, comme le Cameroun, dans son unité. À cet effet, comme Jacob, Joseph, etc., les uns et autres devraient s’atteler à reconstruire l’unité nationale. La prière de Jésus à son Père: « Qu’ils soient un » (Jn 17,21), l’intention principale de cette visite apostolique du Pape Léon XIV, sollicite l’engagement de tous à être devenir «témoins désarmés et désarmants de la paix qui vient du Christ».
Il est aussi important de relever que le 6 décembre dernier, le Comité directeur des imams du Cameroun lui a rendu visite pour lui dire combien leurs communautés seraient heureuses de le recevoir au Cameroun. Ce geste, fort éloquent, nous rappelle qu’en Dieu la diversité culturelle se révèle comme une grâce pour promouvoir le vivre-ensemble, l’unité nationale, la paix et la solidarité."
Le Pape au Cameroun, un «sacrement de l’unité» pour une nation en quête de paix - Vatican News https://share.google/r2FFWpznqIlCPqrqp
#metaglossia
#metaglossia_mundus

"TransPerfect Acquires Studio Emme
News provided by
TransPerfect
Apr 15, 2026, 09:05 ET
Key Takeaways
TransPerfect has acquired Rome-based post-production and dubbing studio Emme SpA.
The acquisition expands TransPerfect Media's global footprint of studios.
Studio Emme's leadership team will remain on following the transaction.
ROME and NEW YORK, April 15, 2026 /PRNewswire/ -- TransPerfect, the world's largest provider of language and AI solutions for global business, today announced it has acquired Studio Emme SpA, a Rome-based audio-visual post-production and dubbing facility. Studio Emme will operate as part of TransPerfect Media, TransPerfect's media and entertainment division. Financial terms of the transaction were not disclosed.
Founded in 1982 by Giuseppe Morucci, Studio Emme has been a cornerstone of Italy's entertainment industry for more than 40 years, providing dubbing and post-production services across film, television, and commercial projects. Clients include major broadcasters and studios in Italy, along with international distribution partners. Studio Emme is a member of the Trusted Partner Network, reflecting content security practices that meet the stringent requirements of leading studios and streaming platforms.
"Joining TransPerfect positions Studio Emme for international growth while preserving what has made us successful," said Marianna Morucci, CEO of Studio Emme. "With TransPerfect's global reach and advanced technology, we can grow our business and service more clients."
Studio Emme will continue operating from its Rome headquarters. The company's existing leadership team will remain in place following the acquisition.
TransPerfect President and Co-CEO Phil Shawe commented, "Studio Emme brings decades of expertise and a strong reputation in Italian audiovisual production. We're excited to welcome the Studio Emme team into TransPerfect and collaborate closely to serve our entertainment clients."
For more company news and announcements, please visit the TransPerfect News & Press Center at www.transperfect.com/about/news-and-press.
About Studio Emme SpA
Studio Emme SpA is a Rome-based dubbing, mixing, and audiovisual post-production facility serving the global entertainment industry. Founded in 1982 by Giuseppe Morucci, the company delivers end-to-end services for film, television, streaming, and commercial content, combining high-quality output with technical excellence, reliability, and state-of-the-art technology. Studio Emme is a member of the Trusted Partner Network (TPN), a Motion Picture Association initiative focused on content security. For more information, visit www.studio-emme.tv.
About TransPerfect Media
TransPerfect Media elevates storytelling for audiences around the world with media creation and globalization solutions delivered through a network of company-owned and operated studios in 19 countries. TransPerfect Media's hybrid model combines cutting-edge AI technology with creative expertise, all managed in its cloud-based content creation platform, enabling simple localization and distribution.
By combining high-level talent with Dolby Atmos and Dolby HDR projection capabilities, as well as services that include image and sound post-production, subtitling, dubbing, accessibility, voiceover, multi-platform delivery, preservation, and restoration, TransPerfect Media is where boutique expertise meets global scale and excellence to help you tell your story—in any language. To find out more, visit www.transperfect.com/media.
About TransPerfect
TransPerfect is the world's largest provider of language and AI solutions for global business. From offices in over 150 cities on six continents, TransPerfect offers a full range of services in 200+ languages to clients worldwide. More than 6,000 global organizations employ TransPerfect's GlobalLink® technology to simplify the management of multilingual content. With an unparalleled commitment to quality and client service, TransPerfect is fully ISO 9001 and ISO 17100 certified. TransPerfect has global headquarters in New York, with regional headquarters in London and Hong Kong. For more information, please visit our website at www.transperfect.com."
https://www.prnewswire.com/news-releases/transperfect-acquires-studio-emme-302742314.html
#metaglossia
#metaglossia_mundus

""C’est une profonde joie de me trouver au Cameroun, souvent qualifié d’“Afrique en miniature” en raison de la richesse de ses territoires, de ses cultures, de ses langues et de ses traditions. [….] Ma visite exprime l’affection du successeur de Pierre pour tous les Camerounais." C’est en français que Léon XIV s’est exprimé en arrivant au Cameroun. Devant les dirigeants du pays d’Afrique centrale, le 267e pape a une fois de plus recouru à la langue de Molière, qu’il connaît, comprend et lit de façon relativement fluide. Cette tournée de onze jours en Afrique est ainsi l’occasion pour l’Américano-péruvien de faire appel à sa maîtrise de langues variées. Pour sa première étape, en Algérie, il a prononcé ses discours principalement en anglais, sa langue maternelle, avec une traduction assurée par un interprète au fur et à mesure en arabe pour son auditoire. Exception faite cependant de ses deux prises de parole devant la communauté catholique à Alger et à Annaba, où il a parlé en français – une langue qui unit la communauté locale métissée – et sans traduction.
Au Cameroun aussi, le successeur de Pierre alternera le français et l’anglais. Il utilisera cette dernière langue à Bamenda dans le nord du pays, une zone anglophone où il se rendra demain jeudi. Au total, il doit prononcer sept interventions pendant son séjour camerounais. En Angola, le troisième pays qu’il visitera, le Pape parlera portugais, une langue qu’il a apprise en voyageant notamment au Brésil lorsqu’il était prieur général des Augustins. En pratiquant leur langue au fil de ses six interventions, il "fera la joie des Angolais", a glissé le directeur du bureau de presse du Saint-Siège, Matteo Bruni, en présentant le programme de ce premier voyage en Afrique. Enfin, dans ses sept discours en Guinée équatoriale, le pontife passera à une autre langue qui lui est chère : l’espagnol, qu’il a pratiqué pendant deux décennies au Pérou, et qu’il a même employé au balcon de la basilique Saint-Pierre le jour de son élection, en signe d’attachement pour son pays de cœur.
Cinq langues pour un pape polyglotte
Anglais, français, portugais, espagnol… quatre langues coloreront donc cette tournée internationale. Quatre ? C’est sans compter l’italien, que Léon XIV a spontanément utilisé pour parler au côté de l’imam de la grande mosquée d’Alger lundi. Cinq langues donc pour un pape polyglotte, qui n’hésitait pas à lancer "salut soldat !" en turc lors de son voyage en Turquie en novembre dernier. Manifestement enclin à communiquer avec des cultures différentes, le nouveau pape a d’ailleurs repris la tradition des salutations de Noël et de Pâques dans de nombreux idiomes, dont l’arabe et le chinois. Et l’on raconte souvent qu’il a été repéré en train d’apprendre l’allemand sur Duolingo à 3h du matin."
Anna Kurian - publié le 15/04/26
https://fr.aleteia.org/2026/04/15/lafrique-accueille-un-pape-polyglotte/
#metaglossia
#metaglossia_mundus

"English remains the lingua franca of scholarly publications, but other languages are gaining ground
By Martin LaSalle Apr 14th, 2026
Drawing on 88 million articles across all disciplines, an UdeM study examines the global evolution of language use in academic publishing between 1990 and 2023.
In 2023, about 85 per cent of the roughly five million articles indexed in major global databases covering the natural, medical and social sciences were written in English. In 1990, the proportion was considerably higher: 94 per cent.
The nine percentage-point increase in the use of other languages over the past 30 years represents a modest but significant shift in the landscape of scholarly communication, and a step toward greater equity, diversity and inclusion in global knowledge production.
That's what Université de Montréal PhD student Carolina Pradier and postdoctoral fellow Lucía Céspedes reveal in a new study directed by Vincent Larivière, a professor in UdeM's School of Library and Information Science.
Published in the Journal of the American Society for Information Science and Technology, the study is a probing look into the many languages used in nearly 88 million articles and conference proceedings, as well as approximately 1.48 billion references cited in them, since 1990.
Cited works almost all in English
While the relative prevalence of English in scholarly publications has eroded over the years, with researchers gradually publishing more in other languages, the overall volume of articles published in English has not declined at all — quite the contrary.
Indeed, English-language articles have more than quintupled, from about 877,000 in 1990 to nearly 5 million in 2023, the co-authors note in their study.
The dominance of English is especially evident in the analysis of citations. “While publications in English account for 85 per cent of the analyzed corpus, 98.89 per cent of the references cited were in English,” said Pradier.
Even in the countries that publish the least in English—Indonesia, Brazil, Ecuador and Angola –English-language references accounted for at least 92 per cent of all references cited.
“On the one hand, there is the language in which researchers write their articles, and on the other there are the studies they rely on to advance their research,” explained Pradier. “Non-English-speaking researchers can now produce work in their own language, but they must still engage with literature that is overwhelmingly written in English.”
The rise of Indonesian
The authors highlight the case of Indonesian. Virtually absent from citation databases in the early 1990s, it is now used in 2.69 per cent of global scholarly publications, surpassing French and German.
According to Pradier, this breakthrough is no accident.
“In 2014, the Indonesian government issued a decree requiring that all scholarly publications be made freely accessible online, which led to the widespread adoption of Open Journal Systems, an open-source, free-to-use journal publishing platform,” she said.
According to Pradier, this is a good example of how national policies on linguistic diversity can change the publishing landscape.
“The rise of publications in Indonesian essentially started from scratch,” she said. “By contrast, Spanish- and Portuguese-language publications in Latin America grew thanks to existing platforms such as Latindex, SciELO and Redalyc, which allowed the region to build a largely self-sufficient ecosystem for knowledge dissemination.”
French in freefall
In contrast to the rising share of publications in Indonesian, Spanish and Portuguese, the use of French has fallen sharply. Once the second most common language, with a 2.14 per cent share of indexed articles in 1990, French slumped to 1.06 per cent by 2023, well behind these three languages.
German has also declined, slipping from 1.38 per cent to 1.23 per cent over the same period.
Pradier attributes these changes to structural factors, noting that the main francophone research communities—France and Quebec—are well integrated into dominant publishing networks. This gives researchers the resources to publish in English and access English-language publications.
By contrast, more peripheral countries, less exposed to pressures to publish in high-profile journals, are developing more independent networks.
“Evaluation policies have a decisive influence,” explained Pradier. “In Quebec, the focus on publishing in high-impact journals encourages publishing in English, whereas in Latin America, greater value is placed on publishing in the national language.”
One exception to the dominance of English is French-language journals in the humanities and social sciences, where fewer than half the citations are to English-language sources. Pradier attributes this “pocket of resistance” to the localized nature of the research topics and the strength of francophone networks in these disciplines.
Blind spots in knowledge
Beyond the numbers, the study highlights the negative consequences of English dominance.
For example, researchers whose working language is not English face tangible costs, including more time devoted to writing, higher rejection rates and stress. This can lead to what the study’s authors call a “survivorship bias,” where only those with sufficient English proficiency succeed in establishing an international research career.
More broadly, English dominance harms knowledge production. “It leads to an epistemic loss as entire swaths of global knowledge production written in undervalued languages remain invisible to the international community,” Pradier said. “Publishing exclusively in English creates enduring blind spots.”
The researchers have two recommendations for policymakers: implement open-source, no-cost accessible journal publishing platforms, and reform current evaluation systems to make them less dependent on citation counts.
“If we focus just on number of citations, we'll continue to encourage the use of English,” Pradier concluded. “Evaluation should also take into account quality and local relevance.”"
- https://nouvelles.umontreal.ca/en/article/2026/04/14/l-anglais-demeure-la-lingua-franca-de-la-science-mais-d-autres-langues-s-imposent
#metaglossia
#metaglossia_mundus

"Voice actors fight to save their livelihoods and local cultures from Hollywood’s AI push
Voice AI tools are quickly replacing voice-over and dubbing artists, raising concerns not only about jobs but also loss of cultural relevance in non-English-speaking nations.
Global voice actors are mobilizing to protect their livelihoods and personality rights as studios replace human performances with AI dubbing.
Advocates warn that AI lacks the local nuance and emotion required to maintain a country’s unique cultural sovereignty.
Some actors can now earn significantly higher rates by intentionally licensing their voices for AI cloning and enterprise tools.
Hardly anyone would recognize Fabio Azevedo if they passed him on a street in São Paulo. When he begins to speak, however, everyone knows who he is: the voice of some of the best-known characters in Hollywood films dubbed in Portuguese, including Doctor Strange in the Marvel movies, and the Beast in the live-action film Beauty and the Beast.
Azevedo now has a role that may be his most challenging yet: protecting voice-over actors in Brazil from artificial intelligence. As studios, production companies, and streaming platforms increasingly turn to AI for voice-overs and to dub English-language content into local languages, more than 2 million full-time and part-time voice actors worldwide stand to lose their livelihood and the rights to their voice.
We make foreign content sound Brazilian with our Brazilian idiosyncrasies; with AI, we lose that.”
Fabio Azevedo, voice actor and president of the Brazilian Association of Dubbing Professionals
“All the major players have started dabbling in AI for dubbing,” Azevedo, who began acting when he was 13, told Rest of World. Voice actors are not only losing jobs, their voice is also being used to train the AI models that are replacing them, often without their knowledge or compensation.
“With new AI-generated voices, I will be out of a job even though I am the one providing the input,” said Azevedo, who is president of the Brazilian Association of Dubbing Professionals. “On top of that we will have a cultural pasteurization. We make foreign content sound Brazilian with our Brazilian idiosyncrasies; with AI, we lose that.”
AI voice technology, which includes text-to-speech and voice cloning that can replicate a person’s voice, is being adapted for virtual assistants, customer service chatbots, public announcements, and, increasingly, commercials, video games, television shows, and films. San Francisco-based ElevenLabs and Cartesia, as well as Israel’s DeepDub, are among the major players, with more firms entering the space as the technology advances and gets better at lip sync and the flat delivery that audiences have long complained about.
“Please leave us a way to make a living”
Azevedo isn’t the only one fretting about job loss. After the Screen Actors Guild–American Federation of Television and Radio Artists strike in 2023 won protections against AI, including the right to approve how their voices are used, actors and voice actors elsewhere are mobilizing against AI.
Mexico recently banned the use of AI in dubbing and unauthorized use of voice by AI, following a campaign by voice actors. Azevedo’s association has proposed similar protections in Brazil’s AI bill, while in South Korea, voice actors have proposed clauses to limit AI use, and have all citizens’ voices protected from unauthorized AI training and potential criminal misuse.
In China, several voice actors recently posted statements on social media condemning the use of their voices in AI-generated works. “Please leave us a way to make a living,” voice actor Nie Xiying said on Weibo, sharing a statement about AI copyright infringement.
A poster of “The Fantastic Four” announces the Hindi release. Marvl
The rise of streaming platforms has sparked a growing appetite for content dubbed in local languages worldwide. AI is increasingly used to deliver content cheaply and quickly, and voice actors are beginning to push back, even though they don’t have strong unions, Rafael Grohmann, an assistant professor of media studies at the University of Toronto, told Rest of World.
“Particularly in the Global South, they don’t have the economic power, the discursive power, or the institutional support to stop production like the Hollywood unions did,” Grohmann said. “So they are forming collectives, and releasing manifestos, to intervene in how generative AI is used, managed, challenged and refused in their workplace.”
A loss of “cultural sovereignty”
Grohmann built a tracker to map such unions, listing more than 100 movements by creative workers in about 25 countries including Turkey, Argentina, Chile, India, and South Korea. Voice actors, who lack the visibility of actors, are among the hardest hit, and the impact goes beyond job loss to the issue of “cultural sovereignty,” he said.
“In countries like Brazil or Mexico, the oral culture is very strong, and you really need a human to translate for the local context,” he said. “So in Brazil, Peter becomes Pedro. The voice actors have a huge fandom, and they become more famous than the Hollywood actors in the film.”
International markets are critical for Hollywood, generating about two-thirds of revenue. Much of this comes from dubbing films and TV shows in local languages. Streaming platforms such as Netflix and Amazon Prime are also adding more language options for their content to increase their share of foreign markets.
Last year, Amazon Prime announced it would add “AI-aided dubbing on licensed movies and series that would not have been dubbed otherwise.” After viewers ridiculed some AI-generated English and Spanish dubs of anime titles, including the Banana Fish series and the movie No Game No Life: Zero, some of these were removed.
In a country like India, with more than a dozen official languages, commercials, documentaries, and audio books were a gold mine for voice actors. Not anymore.
“These jobs are being annihilated by AI,” Ganessh Divekar, general secretary of the Association of Voice Artists of India, told Rest of World. Recently, Divekar — the voice of Hollywood star Pedro Pascal in the Marvel franchise in Hindi, and Luigi in the Cars films dubbed in Hindi — noticed his voice had been mixed with the voice of another actor using AI, for a film. But there was nothing he could do.
“An entirely new category of high-value work”
Advances in voice cloning — which allows the texture of one voice actor to be used for the performance of another — mean that professionals like Divekar may no longer be required to dub in different languages, beyond providing the material for AI training.
“There is no way to prevent them from using my voice however they wish,” he said. “Earlier, when we were called in for a job, we would not ask what our voice would be used for. Now, we are telling members to ask what it will be used for, and ask for more money when signing perpetuity contracts, because the voice becomes their property in perpetuity and they can do anything with it, including train AI.”
Courts in India have recognized that a person’s voice is “an intrinsic part of their identity and falls within the right to privacy,” and that unauthorized commercial use can violate their personality rights, said Anamika Jha, a media and entertainment lawyer, and the founder of law firm Attorney for Creators. But these provisions do not fully extend to the use of voice data in training AI systems, she told Rest of World.
Earlier, I was a voice; now, I have to say I’m a human voice to distinguish myself from AI.”
Ganessh Divekar, voice actor and general secretary of the Association of Voice Artists of India
“A voice can be cloned and reused indefinitely without further consent or payment,” Jha said. There are also serious reputational concerns. “A cloned voice may be used in contexts that the artist would never endorse, including political messaging, controversial advertising, or explicit content … [and in] impersonation and fraud.”
With appropriate protections and licensing agreements, there can be a big opportunity, too. Voices, a voice solutions company with over 100,000 registered voice actors who can speak in more than 100 languages, now offers voice data and voice AI to enterprise clients. Voice AI jobs pay up to 85 times as much as traditional voice-over work, Julianna Jones, the company’s director of talent success, told Rest of World.
All the voice data on the platform is “intentionally captured” from consenting actors or contributors, and every voice AI agreement includes consent to voice cloning, licensing, and legal protections that ensure their rights and compensation are preserved “even in regions without regulations,” Jones said.
Get The Global, our (free) newsletter
Sign up for our weekly newsletter and we’ll send you our latest stories, insights from our staff, what we’re reading, and more. A world of tech, right in your inbox.
Email
“This opens up an entirely new category of high-value work,” she said. “Actors retain a say in how their voice is used, stay actively involved as the voice evolves, and continue earning as the technology improves.”
For voice actors such as Divekar, however, the fight to retain control over their voice and earn a living continues.
“Earlier, I was a voice; now, I have to say I’m a human voice to distinguish myself from AI,” he said."
By Rina Chandran
15 April 2026
https://restofworld.org/2026/ai-voice-actors-hollywood-dubbing/
#metaglossia
#metaglossia_mundus

"Translation Grants for Publication of Lithuanian literature
Your April Funding Calendar Just Dropped
April is one of the busiest months in the funding calendar. Dozens of international donors are accepting applications right now — but windows are closing fast. Here's what's open and how to get your proposal in on time. DOWNLOAD!
Deadline: 15-May-26
The Translation Grants Programme supports the translation, publication, and international dissemination of Lithuanian literature. Managed by the Lithuanian Culture Institute and funded by the Lithuanian state, the programme helps publishers in Lithuania and abroad bring Lithuanian authors, cultural works, and children’s books to global audiences.
You didn't start your NGO to spend half your time hunting for funding
Premium Membership handles the research so you can focus on what you do best — creating change
What is the Translation Grants Programme?
The Translation Grants Programme is a funding initiative that promotes the global translation and publication of Lithuanian literature.
Its purpose is to help publishers translate and publish Lithuanian works in other languages, making them accessible to readers worldwide. The programme supports both fiction and non-fiction and covers a wide range of literary genres.
What Does the Programme Support?
The programme funds projects that translate, publish, and promote Lithuanian literature internationally.
You didn't start your NGO to spend half your time hunting for funding
Premium Membership handles the research so you can focus on what you do best — creating change
Eligible literary categories include:
Prose
Poetry
Drama
Documentary writing
Children’s literature
Illustrated books
Graphic novels
Fiction and non-fiction by Lithuanian authors
Works by authors of Lithuanian descent
Books related to Lithuanian culture, history, and artists
This broad scope makes the programme valuable for publishers interested in literary translation, cultural publishing, and international rights development.
Why This Programme Matters
The programme has been a major tool for promoting Lithuanian literature globally.
Key impact:
Nearly 600 translated books supported
Published in 43 languages
Operated successfully over several decades
Annual funding allocation of EUR 100,000
This makes it one of the most important public funding opportunities for publishers seeking support for translated literature from Lithuania.
You didn't start your NGO to spend half your time hunting for funding
Premium Membership handles the research so you can focus on what you do best — creating change
Who is Eligible?
The programme is open to publishers and publishing-related legal entities.
Eligible applicants include:
Publishers based in Lithuania
Publishers based outside Lithuania
Other legal entities engaged in publishing activities outside Lithuania
To qualify, applicants should plan to publish a translated work of Lithuanian literature in their own country or market.
How Funding Works
Funding is awarded through a competitive application process.
You didn't start your NGO to spend half your time hunting for funding
Premium Membership handles the research so you can focus on what you do best — creating change
Call frequency:
Calls are published at least twice a year
Funding structure depends on publication timing:
1. If the book is published in the same year as the grant award
A one-stage agreement is signed
The full grant amount is paid after project completion
Payment is made after:
Final reports are submitted
Required documentation is approved
Six copies of the publication are delivered
2. If the book will be published in a later year
A two-stage agreement is used
Up to 60% of the grant is paid first
The remaining balance is paid after:
Final reporting
Submission of required documents
Delivery of six publication copies
How to Apply
Applicants should prepare all materials before starting the application.
Important note:
Incomplete applications are not saved
It is best to collect all documents in advance
Required application materials:
A short presentation of the publishing house
A list of translations published in the last two years
Information on distribution channels and partners
A description of planned marketing activities
A justification of the project’s relevance
Details on the translator’s qualifications
The translator’s motivation for the project
Tips for a Strong Application
To improve your chances:
Show why the selected work is relevant for your market
Highlight strong distribution and sales channels
Include a clear marketing and promotion plan
Demonstrate the translator’s experience and literary fit
Explain how the book will help expand access to Lithuanian literature internationally
Make sure all required documents are complete before submission
Common Mistakes to Avoid
Starting the form without all materials ready
Submitting an incomplete application
Giving weak details about distribution strategy
Not clearly explaining the project’s market relevance
Providing limited information about the translator
Ignoring promotion and dissemination planning
Frequently Asked Questions (FAQs)
1. What is the Translation Grants Programme?
It is a funding programme that supports the translation, publication, and international promotion of Lithuanian literature.
You didn't start your NGO to spend half your time hunting for funding
Premium Membership handles the research so you can focus on what you do best — creating change
JOIN IN
2. Who manages the programme?
The programme is funded by the Lithuanian state and administered by the Lithuanian Culture Institute.
3. Who can apply?
Eligible applicants include:
Publishers in Lithuania
International publishers
Other legal entities outside Lithuania involved in publishing
4. How often are calls announced?
Calls for applications are published at least twice per year.
You didn't start your NGO to spend half your time hunting for funding
Premium Membership handles the research so you can focus on what you do best — creating change
5. What kinds of books are supported?
The programme supports:
Prose
Poetry
Drama
Documentary writing
Children’s books
Illustrated books
Graphic novels
Fiction and non-fiction related to Lithuanian authors, culture, and history
6. How is the grant paid?
Payment depends on publication timing:
Same-year publication: Full payment after completion and reporting
Later-year publication: Up to 60% upfront, with the rest after final reporting
7. What documents are required?
Applicants need to submit publishing house details, recent translation history, distribution and marketing information, project relevance, and translator qualifications/motivation.
You didn't start your NGO to spend half your time hunting for funding
Premium Membership handles the research so you can focus on what you do best — creating change
Conclusion
The Translation Grants Programme is a strong opportunity for publishers looking to bring Lithuanian literature to international readers. With support for multiple genres, regular calls, and a proven record of nearly 600 translated books in 43 languages, it offers meaningful backing for literary translation, publishing, and cultural exchange."
https://www2.fundsforngos.org/individuals/translation-grants-for-publication-of-lithuanian-literature/
#metaglossia
#metaglossia_mundus

"University of Bonn Establishes Translation Hub
New coordination office to support 36 universities in North Rhine-Westphalia (NRW)
Since the beginning of February 2026, the University of Bonn has been home to the new North Rhine-Westphalian Coordination Office for Translation Matters in Higher Education (‘Landeskoordinationsstelle für Übersetzungsangelegenheiten im Hochschulwesen des Landes Nordrhein-Westfalen’). It is developing an online platform offering sample translations, translation resources and training sessions, while serving as a central contact point for translation-related questions. The platform is scheduled to launch in late April 2026.
NRW Coordination Office for Translation Matters in Higher Education at the University of Bonn. - The Coordination Office supports 36 universities in North Rhine-Westphalia. It is developing a platform featuring sample documents and translation tools, serves as a point of contact for questions, and offers training sessions.
© Photo: Gregor Hübl / University of Bonn
Download all images in original size
The impression in connection with the service is free, while the image specified author is mentioned.
Greater orientation for international higher education
Research and teaching are carried out within international networks, as are many administrative processes. The need for reliable information in English—whether HR forms or administrative regulations—is growing accordingly. That’s where the NRW Coordination Office comes in: It seeks to pool existing resources, prevent the unnecessary duplication of work and provide centralized access to English-language documents that are relevant across universities in NRW.
During the initial setup phase, the NRW Coordination Office is mapping which English-language documents and bilingual resources, such as glossaries or terminology, are already available at NRW’s 36 public universities. This information will help set future priorities.
At the same time, a digital platform is under development, set to go live by the end of April. This will serve as the primary access point for sample translations and other materials. Universities will be able to submit translation and proofreading requests via this platform or via email.
Drawing on proven expertise
One of the reasons for establishing the NRW Coordination Office in Bonn was the strong structures already in place. The University of Bonn set up its Central Translation Service within the International Office back in 2019 as a means of reducing language barriers and strengthening its international outreach. Initially, the Central Translation Service focused on translating texts, forms and other content from German into English; a year later, it also took on the coordination of editing services for academic texts in English in collaboration with an external provider.
Today, the Central Translation Service advises staff on all language and translation issues and maintains the University’s German-English glossary and English style guide. Since 2021, its language specialists have also offered an interpreting service for key meetings and public events at the University of Bonn.
A central hub to drive synergies
A few other German states already have similar offices to coordinate translations of cross-university importance or make shared language resources available. In discussions among the universities in NRW, the idea emerged to set up a similar state-wide coordination office here. This led to an application being submitted to the Ministry of Culture and Science of NRW in collaboration with representatives of the universities and the University Rectors’ Conference. In 2025, the University of Bonn’s application was approved, with financing provided through the NRW Future Fund (Zukunftsfonds) for an initial two-year period.
Professor Birgit Ulrike Münch, Vice Rector for International Affairs, stated: “International collaboration relies on solid linguistic foundations, including in administration. With the NRW Coordination Office, we are putting in place a structure that provides concrete support to universities in North Rhine‑Westphalia.” Professor Petra M. Vogel, Prorector for Students and Junior Faculty, Diversity, and International Affairs at the University of Siegen, was also one of the earliest proponents of the project: “Experience from other German states shows that a state-wide coordination office can deliver real value in the field of higher‑education translation. There’s a key focus on connecting existing structures in a meaningful way and creating synergies. I’m very pleased that an office like this could also be set up in NRW.”
The project aims to build a fully functional platform that
- taps into synergies in the translation field and avoids the same work being done multiple times;
- expands the range of information available in English;
- supports university translators, administrative staff and researchers in implementing internationalization strategies.
Services designed to meet real needs
When the platform launches at the end of April, it plans to offer the following services:
- Translations (German to English) of documents that are relevant for all universities in NRW
- A bilingual (German/English) terminology database
- Topic-specific glossaries that can also be integrated into machine translation tools or used in the context of AI-supported translation
- Machine translations for universities that don’t have the relevant licenses themselves
- Proofreading
- Training sessions, especially on the effective use of machine translation tools
Particularly when it comes to machine translation or the use of AI in a translation context, there is growing demand for guidance. That’s why training sessions will aim to give practical tips on how these tools work, where they fall short and what else needs to be considered in practice, for example data protection requirements or established institutional terminology.
Collaboration across the network
The NRW Coordination Office will partner closely with NRW’s 36 public universities. Each institution will receive access to the platform and can use the services offered. Regular exchange formats, a newsletter and feedback channels are also in the works.
The NRW Coordination Office sees itself explicitly as a service provider and networking hub that offers support, but does not establish binding standards. The translations and terminology recommendations provided aim to offer universities guidance and complement their internal language resources.
Significance for the University of Bonn
This state-wide office further embeds the University of Bonn in the cross-institutional structures of higher education development in NRW. At the same time, the NRW Coordination Office aligns perfectly with the University’s Internationalization Strategy, which explicitly calls for the expansion of English-language information resources.
Contact:
NRW Coordination Office for Translation Matters in Higher Education at the University of Bonn: landeskoordinationsstelle.nrw@uni-bonn.de"
https://www.uni-bonn.de/en/news/069-2026
#metaglossia
#metaglossia_mundus
Sze is Building a Signature Project and Tour Focused on Poetry in Translation to Open the World of Poetry to More People
"U.S. Poet Laureate Arthur Sze Appointed for a Second Term
Release Date: 14 Apr 2026
U.S. Poet Laureate Arthur Sze Appointed for a Second Term
Sze is Building a Signature Project and Tour Focused on Poetry in Translation to Open the World of Poetry to More People
This National Poetry Month, the Library of Congress has appointed Arthur Sze to serve a second term as the nation’s 25th Poet Laureate Consultant in Poetry for 2026-2027, the Library announced today.
Sze, who lives in Santa Fe, New Mexico, was named poet laureate in September 2025 and began working to expand appreciation of poetry through his focus on translating poetry originally written in languages other than English. His newest book, “Transient Worlds: On Translating Poetry,” features translations from 13 languages and provides a personal guide to poetry in translation. The book is published today by Copper Canyon Press in association with the Library of Congress.
Sze’s first term will conclude on April 30 when he will return to the Library for a rare, special conversation with the Poet Laureate of the United Kingdom, Simon Armitage, on the art and process of writing and translating poetry. Armitage has a new translation of “Gilgamesh,” also publishing on April 14."
https://newsroom.loc.gov/news/u.s.-poet-laureate-arthur-sze-appointed-for-a-second-term/s/af95199e-5eec-4568-9b62-cc5a9a6e994f
#metaglossia
#metaglossia_mundus

"
Procès ajourné pour un problème de traduction en langue dari
14.04.2026 10h23
Le Tribunal cantonal a été obligé d'ajourner le procès du jour pour une question de traduction 8
Le Tribunal cantonal valaisan aurait dû juger mardi un Afghan pour tentative d'assassinat sur son épouse. En première instance, il avait écopé de 10 ans de prison et d'une expulsion de 15 ans de Suisse. Le procès a finalement été ajourné pour un problème d'interprète.
Le prévenu, désireux de s'exprimer dans sa langue maternelle - le dari -, comme c'est son droit le plus strict, la Cour a entamé le procès en assermentant une interprète de la région. A la deuxième question, celle-ci a admis une connaissance limitée de cette langue.
Président du Tribunal, Christophe Pralong a alors interrompu les débats, cherchant un traducteur remplaçant. Après une petite demi-heure, le TC a choisi d'ajourner le procès, n'ayant pas pu trouver la perle rare. Le fils de l'accusé, puis l'un de ses cousins se sont offerts pour traduire. Au vu de la proximité de ces personnes avec le prévenu, le TC a refusé cette solution.
'Nous essayerons de fixer au plus vite une nouvelle date. Ce dossier est (ndlr: désormais) prioritaire', a conclu Christophe Pralong.
/ATS"
https://www.lemanbleu.ch/fr/Actualite/Suisse/Proces-ajourne-pour-un-probleme-de-traduction-en-langue-dari.html
#metaglossia
#metaglossia_mundus
|












