Your new post is loading...
Your new post is loading...

|
Scooped by
Mickael Ruau
December 8, 2021 1:47 AM
|
Les différents moteurs de stockage de MySQL
|
|
Scooped by
Mickael Ruau
December 5, 2021 11:53 AM
|
Object-Relational Mappers get a lot of hate from people who misjudge the complexities of the task.
|
|
Scooped by
Mickael Ruau
December 3, 2021 1:17 AM
|
Data quality ensures that an organization’s data is accurate, consistent, complete, and reliable. The quality of the data dictates how useful it is to the enterprise. Ensuring data quality—especially with the sheer amount of data available to today’s enterprises—is a tremendously complex beast. To do this effectively, the modern enterprise relies on data quality tools.
In this post, we will consider five data quality tools and see how they can help you in your data journey:
Great Expectations
Spectacles
Datafold
dbt (Data Build Tool)
Evidently
|
|
Scooped by
Mickael Ruau
December 2, 2021 2:00 AM
|
A step-by-step database sizing and capacity planning example: estimating the workload and operational margins, then calculating the required database resources.
|
|
Scooped by
Mickael Ruau
December 1, 2021 1:43 AM
|
This article demonstrates exactly how to use XPath to the exclusion of shorthand, solely by means of axis specifiers and node tests.
|
|
Scooped by
Mickael Ruau
November 30, 2021 3:17 AM
|
Cette version apporte le mode STRICT qui est activé séparément pour chaque table d’une base de données. « Certains développeurs apprécient la liberté qu'offrent les règles de typage flexibles de SQLite et utilisent cette liberté à leur avantage. Mais d'autres développeurs sont choqués par le non-respect flagrant des règles par SQLite et préfèrent le système de typage rigide traditionnel que l'on trouve dans tous les autres moteurs de base de données SQL et dans le standard SQL. Pour ce dernier groupe, la version 3.37 de SQLite supporte un mode de typage STRICT qui est activé séparément pour chaque table », a déclaré l'équipe de développement de SQLite.
|
|
Scooped by
Mickael Ruau
November 29, 2021 9:45 AM
|
Les modèles par héritage possèdent de nombreux avantages. Parmi ceux-ci, l'économie en volume de données stockées, la standardisation des types et des formats de données. Cet article fait le point sur la modélisation des entités par héritage afin de vous permettre de l'implémenter au sein de vos applications, et cela, en toute sérénité.
|
|
Scooped by
Mickael Ruau
November 28, 2021 10:03 AM
|
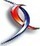
Je me souviens d'une discussion sur le forum dans laquelle il était question d'âge. Les réponses farfelues d'un des membres m'avaient quelque peu irritées, puisqu'il partait de l'idée qu'il suffisait de diviser le nombre de jours entre la date de calcul et la date de naissance par 365 pour trouver la date. De plus, il arrondissait pour avoir une année entière. Du coup, à 47.5 ans, on passait
|
|
Scooped by
Mickael Ruau
November 25, 2021 9:45 AM
|
La technique des métadonnées est pertinente pour laisser toute liberté aux utilisateurs de rajouter autant de rubriques de données qu'ils le souhaitent sans jamais de crainte quant à leur volume ni leur facilité d'interrogation. Et tout cela sans jamais modifier l'architecture de la base de données…
|
|
Scooped by
Mickael Ruau
November 18, 2021 4:29 AM
|
PlanetScale propose deux types de branches de bases de données : développement et production. Les branches de développement fournissent des copies isolées du schéma de la base de données sur lesquelles l’utilisateur peut apporter des modifications, faire des expériences ou exécuter des tests d'intégrité. Les branches de développement fournissent des copies isolées du schéma de votre base de données dans lesquelles vous pouvez effectuer des changements, faire des expériences ou exécuter le CI.
Les branches de production sont des bases de données hautement disponibles destinées au trafic de production. Elles sont protégées par défaut contre les modifications directes de schéma et incluent des sauvegardes quotidiennes automatisées. PlanetScale permet de ramifier les schémas de bases de données de la même façon qu’un code peut être ramifié.
Les entrepôts de données de santé sont des bases de données destinées à être utilisées notamment à des fins de recherches, d’études ou d’évaluations dans le domaine de la santé. Ces traitements peuvent être soumis à l’autorisation de la CNIL. Afin de simplifier les démarches pour les responsables de ces bases de données sensibles, tout en fournissant un encadrement juridique et technique rigoureux, la CNIL a lancé le 8 mars 2021 une consultation publique concernant un projet de référentiel.
Via Frederic GOUTH
|
|
Scooped by
Mickael Ruau
November 11, 2021 8:01 AM
|
Les bases de données SQL et plus particulièrement MySQL restent une des pierres angulaires de l'immense majorité des sites Internet. MySQL fonctionne très bien out of the box, cependant, dès que la base se trouve assez sollicitée, on s'aperçoit que les réglages par défaut méritent une petite optimisation. Jetons un œil à tout ça !
Récemment, un des serveurs de Peerus commençait à avoir de sacrés pics de chargement (load) lors des heures de forte charge, avec MySQL pour principal responsable. Une grosse centaine de connexions simultanées et quelques dizaines de requêtes par seconde sur des bases de plusieurs dizaines de giga-octets. C'est un peu plus que le WordPress moyen, mais rien d'ingérable pour un MySQL bien réglé.
Dès lors, avant d'imaginer prendre un serveur plus puissant, sharder (partitionnement horizontal) les tables ou je ne sais quoi encore, il faut tirer le maximum de notre cher SGBDR.
Nous nous concentrerons ici sur le moteur InnoDB, lequel tend à supplanter MyISAM. Cependant, ce n'est pas la réponse magique à tous les types d'usages. Par ailleurs, même si nous parlons de MySQL, c'est avec son fork MariaDB que j'ai l'habitude de travailler depuis quelques années. Vu le peu de soin qu'Oracle apporte au développement de MySQL, Maria est même devenu la variante MySQL par défaut dans Debian.
|
|
Scooped by
Mickael Ruau
November 4, 2021 11:24 AM
|
MongoDB est une technologie qui change la vie de nombreux développeurs, leur permettant de créer des applications plus rapidement qu'avec des bases de données relationnelles. Cependant, MongoDB a abandonné ses racines Open Source, en changeant la licence en SSPL, ce qui le rend inutilisable pour...
|
|
|
Scooped by
Mickael Ruau
December 6, 2021 1:17 AM
|
If you've ever wanted to learn how to write a MySQL cursor or a MySQL loop, you've come to the right place. Let's iterate!
|
|
Scooped by
Mickael Ruau
December 3, 2021 6:15 AM
|
S'il est une chose que Microsoft Excel sait bien faire, c'est comparer des données aussi bien au sein d'une même feuille de calcul qu'entre deux classeurs. Si vous avez à comparer des données, vous aurez le choix entre utilise
|
|
Scooped by
Mickael Ruau
December 2, 2021 2:14 AM
|
In this article, learn how conflict-free replicated data types can help distributed systems handle consistency challenges.
|
|
Scooped by
Mickael Ruau
December 2, 2021 1:46 AM
|
La plupart des développeurs sont persuadés que mettre toutes les informations dans une même table rendra leur base de données plus rapide… Et l’on voit apparaître dans la base de nombreuses tables de plusieurs dizaines de colonnes. C’est une vue à court terme, car dès que la base de données commence à croitre ou que le nombre d’utilisateur augmente, les performances deviennent vite catastrophique… Cet article explique pourquoi…
À chaque audit que je fais, et cela depuis maintenant plus de 15 ans, on trouve régulièrement la même erreur : des tables avec un nombre effrayant de colonnes. Par exemple une table des personnes, dans laquelle on trouve des adresses, des téléphones, des mails, … bref tout un tas d’information relatif à une personne, mais qui ne constitue aucunement des attributs directs de la personne. Et chaque fois que l’on fait remarquer cela aux développeurs, la réponse est la même :
« on m’a dit que les jointures c’était mal »
« les jointures c’est pas performants, c’est connu »
« Je mets tout dans la même table, ça ira plus vite »
…
Bien évidemment, c’est tout le contraire, mais pour le comprendre il faut revenir à ce qu’est une base de données relationnelle, comment fonctionne les SGBDR client/serveur et ce qu’est la normalisation d’un modèle de données, c’est à dire son découpage en de multiples tables, chacune étant bien spécialisé et concentré sur l’objet qu’elle modélise.
|
|
Scooped by
Mickael Ruau
November 30, 2021 10:53 AM
|
Learn how to parse and standardize addresses with different tools, including regex, npm packages, online validators, and geocoding APIs.
|
|
Scooped by
Mickael Ruau
November 30, 2021 2:12 AM
|
Stored procedures have many advantages, including:
High performance in data manipulation in comparison to handling this through another application tier, since transferring data across other tiers introduces at least network delay.
Abstraction of database structure and logic, where comes all the benefits of abstraction.
Ease of DDL execution. Some other languages and frameworks have limitations with DDLs.
Direct access to some database features, which are hidden from clients just executing DMLs.
When Stored Procedures Are Discouraged
However, coding to stored procedures is generally discouraged in multi-tier applications for the following reasons.
Distributed Logic
Usually, multi-tier applications have a business layer that carries the business logic, including validations, orchestration, business rules, etc., making another layer of logic causes the logic to be distributed between multiple layers, violating coherence and separation of concerns
Transaction Management
This is related to the previous point; however, it's more specific to transactions. Transactions should be managed by a single layer, distributing transactions between the business layer. The stored procedure introduces a hard-to-manage burden and usually results in spaghetti code and tough workarounds to manage commits and rollbacks.
Source Control and CI Unfriendliness
Till this moment, it is still very difficult to maintain stored procedure codes on source control the same way it is done for other codebases because it usually exists on the database itself rather than being maintained as a separate codebase that can be manipulated, complied with, or tracked independently on an IDE, and it is also difficult to include this code in CI pipeline (like Jenkins).
|
|
Scooped by
Mickael Ruau
November 29, 2021 6:22 AM
|
When you access tables with associated triggers, definitions are put into the stored programs cache even when not fired. While not a bug, it's something to be aware of.
|
|
Scooped by
Mickael Ruau
November 28, 2021 3:43 AM
|
On compte aujourd’hui en France près de 30 000 DPO, ou Data Protection Officer, délégué à la protection des données personnelles en bon français. Quelque 80 000 organisations, dont 26 000 dans le public, en ont désigné un à ce jour. On est bien loin des 18 000 organismes dotés de CIL dans la période pré-RGPD. Et c’est justement pour poursuivre sur cette lancée que la Cnil vient de publier un guide relatif au DPO.
Ce document de 56 pages s’adresse moins aux délégués qu’aux entreprises et aux collectivités qui les désignent (ce qui ne signifie par pour autant que les DPO doivent faire l’impasse sur la lecture de ce guide, bien au contraire). Le guide, profitant de trois années d’accompagnement des DPO par la Cnil s’articule autour de quatre chapitres sur le rôle du DPO, sa désignation, l’exercice de ses missions et son accompagnement par le gendarme des données personnelles.
|
|
Scooped by
Mickael Ruau
November 24, 2021 1:00 AM
|
I never seemed to find the perfect data-oriented Python book for my course, so I set out to write just such a book. Luckily at a faculty meeting three weeks before I was about to start my new book from scratch over the holiday break, Dr. Atul Prakash showed me the Think Python book which he had used to teach his Python course that semester. It is a well-written Computer Science text with a focus on short, direct explanations and ease of learning.The overall book structure has been changed to get to doing data analysis problems as quickly as possible and have a series of running examples and exercises about data analysis from the very beginning.
|
|
Scooped by
Mickael Ruau
November 17, 2021 11:08 AM
|
I have a shop and I decide to grant a bonus discount to a selected number of customers that:
Have an active account to my shop
Match my personal criteria to access the bonus
My application is set to perform batch operations in a moment of less traffic and unattended. This includes reactivating dormant accounts that customers ask to reactivate.
What we will do is to see what happens, by default, and then see what we can do to avoid pitfalls.
The Scenario
I will use three different connections to connect to the same MySQL 8.0.27 instance. The only relevant setting I have modified is the Innodb_timeout that I set to 50 seconds.
Session 1 will simulate a process that should activate the bonus feature for the selected customers
Session 2 is an independent process that reactivates the given list of customers
Session 3 is used to collect lock information
|
|
Scooped by
Mickael Ruau
November 16, 2021 12:02 PM
|
Most enterprises store their massive volumes of transactional and analytics data at rest in data warehouses or data lakes. Sales, marketing, and customer success teams require access to these data sets. Reverse ETL is a buzzword that defines the concept of collecting data from existing data stores to provide it easy and quick for business teams.
This blog post explores why software vendors (try to) introduce new solutions for Reverse ETL, when it is needed, and how it fits into the enterprise architecture.
|
|
Scooped by
Mickael Ruau
November 8, 2021 5:17 AM
|
Neo4j a annoncé la disponibilité générale de Neo4j AuraDB Free, son service gratuit de DBaaS. Avec l'arrivée de AuraDB Free, Neo4j souhaite rendre sa plate-forme de base de données de graphes accessible à tous, et ce, gratuitement dans le cloud. Ceci avec pour objectif d'accélérer l'adoption de cette technologie dans des applications modernes. Les développeurs peuvent désormais prendre en main, prototyper et développer sans se soucier de la gestion de l'infrastructure. Cette version gratuite de la plateforme offre un accès rapide et facile aux graphes à travers un service entièrement hébergé dans le cloud.
« Neo4j AuraDB Free est une offre gratuite de notre base de données graphes, il ne s'agit pas d'une offre d'essai et sa sortie témoigne de notre volonté d'affirmer notre parcours open source ! », déclare Emil Eifrem, PDG et co-fondateur de Neo4j. « Certaines de nos applications les plus innovantes proviennent de notre communauté et nous espérons qu'AuraDB Free favorisera davantage de créativité et réduira les frictions. Aujourd'hui, nous nous efforçons d'offrir aux développeurs passionnés par les graphes le moyen le plus simple d'apprendre, de tester et de grandir avec nous dans le cloud. », conclut-il.
Neo4j AuraDB FreeM est accessible à tous et disponible en suivant ce lien. AuraDB Free comprend une base de données de graphes gratuite avec toutes les fonctionnalités de base et des outils pour les développeurs, dont Neo4j Bloom pour la visualisation des données.
|