This curated collection includes updates, resources, and research with critical perspectives related to the intersections of educational psychology and emerging technologies in education. The page also serves as a research tool to organize online content (funnel shaped icon allows keyword search). For more on the intersections of privatization and technologization of education with critiques of social impact finance and related technologies, please visit http://bit.ly/sibgamble and http://bit.ly/chart_look. For posts regarding screen time risks to health and development, see http://bit.ly/screen_time and for updates related to AI and data concerns, please visit http://bit.ly/PreventDataHarms. [Note: Views presented on this page are re-shared from external websites. The content may not necessarily represent the views nor official position of the curator nor employer of the curator.
Dr. Mitchell Prinstein, Chief of Psychology for the American Psychological Association spoke today (September 16th, 2025) before the Senate Judiciary Committee on behalf of 173,00 members. The following is a link to a pdf of his written testimony:
The United States is one of the few countries that does not have a federal baseline privacy law that lays out minimum standards for data use. Instead, it has tailored laws that are supposed to protect data in different sectors—including health, children’s and student data.
But despite the existence of a law—the Family Educational Rights and Privacy Act—that is specifically designed to protect the privacy of student educational records, there are loopholes in the law that still allow data to be exploited. The Markup reporter Todd Feathers has uncovered a booming business in monetizing student data gathered by classroom software.
In two articles published this week as part of our Machine Learning series, Todd identified a private equity firm, Vista Equity Partners, that has been buying up educational software companies that have collectively amassed a trove of data about children all the way from their first school days through college.
Vista Equity Partners, which declined to comment for Todd’s story, has acquired controlling ownership stakes in EAB, which provides college counseling and recruitment products to thousands of schools, and PowerSchool, which provides software for K-12 schools and says it holds data on more than 45 million children.
Some of this data is used to create risk-assessment scores that claim to predict students’ future success. Todd filed public records requests for schools across the nation, and using those documents, he was able to discover that PowerSchool’s algorithm, in at least one district, considered a student who was eligible for free or reduced lunch to be at a higher risk of dropping out.
Experts told us that using a proxy for wealth as a predictor for success is unfair because students can’t change that status and could be steered into less challenging opportunities as a result.
“I think that having [free and reduced lunch status] as a predictor in the model is indefensible in 2021,” said Ryan Baker, the director of the University of Pennsylvania’s Center for Learning Analytics. PowerSchool defended the use of the factor as a way to help educators provide additional services to students who are at risk.
Todd also found public records showing how student data is used by colleges to target potential applicants through PowerSchool’s Naviance software using controversial criteria such as the race of the applicant. For example, Todd uncovered a 2015 contract between Naviance and the University of Kansas revealing that the school paid for a year-long advertising campaign targeting only White students in three states.
The University of Kansas did not respond to requests for comment. PowerSchool’s chief privacy officer Darron Flagg said Naviance has since stopped colleges from using targeting “criteria that excludes under-represented groups.” He also said that PowerSchool complies with the student privacy law and “does not sell student or school data.”
But, as we have written at The Markup many times, not selling data does not mean not profiting from that data. To understand the perils of the booming educational data market, I spoke this week with Roxana Marachi, a professor of education at San José State University, who researches school violence prevention, high-stakes testing, privatization, and the technologization of teaching and learning. Marachi served as education chair of the CA/HI State NAACP from 2019 to 2021 and has been active in local, state, and national efforts to strengthen and protect public education. Her views do not necessarily reflect the policy or position of her employer.
Her written responses to my questions are below, edited for brevity.
_______________________________
Angwin: You have written that ed tech companies are engaged in a “structural hijacking of education.” What do you mean by this?
Marachi: There has been a slow and steady capture of our educational systems by ed tech firms over the past two decades. The companies have attempted to replace many different practices that we have in education. So, initially, it might have been with curriculum, say a reading or math program, but has grown over the years into wider attempts to extract social, emotional, behavioral, health, and assessment data from students.
What I find troubling is that there hasn’t been more scrutiny of many of the ed tech companies and their data practices. What we have right now can be called “pinky promise” privacy policies that are not going to protect us. We’re getting into dangerous areas where many of the tech firms are being afforded increased access to the merging of different kinds of data and are actively engaged in the use of “predictive analytics” to try to gauge children’s futures.
Angwin: Can you talk more about the harmful consequences this type of data exploitation could have?
Marachi: Yes, researchers at the Data Justice Lab at Cardiff University have documented numerous data harms with the emergence of big data systems and related analytics—some of these include targeting based on vulnerability (algorithmic profiling), misuse of personal information, discrimination, data breaches, political manipulation and social harms, and data and system errors.
As an example in education, several data platforms market their products as providing “early warning systems” to support students in need, yet these same systems can also set students up for hyper-surveillance and racial profiling.
One of the catalysts of my inquiry into data harms happened a few years ago when I was using my university’s learning management system. When reviewing my roster, I hovered the cursor over the name of one of my doctoral students and saw that the platform had marked her with one out of three stars, in effect labeling her as in the “lowest third” of students in the course in engagement. This was both puzzling and disturbing as it was such a false depiction—she was consistently highly engaged and active both in class and in correspondence. But the platform’s metric of page views as engagement made her appear otherwise.
Many tech platforms don’t allow instructors or students to delete such labels or to untether at all from algorithms set to compare students with these rank-based metrics. We need to consider what consequences will result when digital labels follow students throughout their educational paths, what longitudinal data capture will mean for the next generation, and how best to systemically prevent emerging, invisible data harms.
One of the key principles of data privacy is the “right to be forgotten”—for data to be able to be deleted. Among the most troubling of emerging technologies I’ve seen in education are blockchain digital ID systems that do not allow for data on an individual’s digital ledger to ever be deleted.
Angwin: There is a law that is supposed to protect student privacy, the Family Educational Rights Protection Act (FERPA). Is it providing any protection?
Marachi: FERPA is intended to protect student data, but unfortunately it’s toothless. While schools that refuse to address FERPA violations may have federal funding withheld from the Department of Education, in practice, this has never happened.
One of the ways that companies can bypass FERPA is to have educational institutions designate them as an educational employee or partner. That way they have full access to the data in the name of supporting student success.
The other problem is that with tech platforms as the current backbone of the education system, in order for students to participate in formal education, they are in effect required to relinquish many aspects of their privacy rights. The current situation appears designed to allow ed tech programs to be in “technical compliance” with FERPA by effectively bypassing its intended protections and allowing vast access to student data.
Angwin: What do you think should be done to mitigate existing risks?
Marachi: There needs to be greater awareness that these data vulnerabilities exist, and we should work collectively to prevent data harms. What might this look like? Algorithmic audits and stronger legislative protections. Beyond these strategies, we also need greater scrutiny of the programs that come knocking on education’s door. One of the challenges is that many of these companies have excellent marketing teams that pitch their products with promises to close achievement gaps, support students’ mental health, improve school climate, strengthen social and emotional learning, support workforce readiness, and more. They’ll use the language of equity, access, and student success, issues that as educational leaders, we care about.
Many of these pitches in the end turn out to be what I call equity doublespeak, or the Theranos-ing of education, meaning there’s a lot of hype without the corresponding delivery on promises. The Hechinger Report has documented numerous examples of high-profile ed tech programs making dubious claims of the efficacy of their products in the K-12 system. We need to engage in ongoing and independent audits of efficacy, data privacy, and analytic practices of these programs to better serve students in our care.
Angwin: You’ve argued that, at the very least, companies implementing new technologies should follow IRB guidelines for working with human subjects. Could you expand on that?
Marachi: Yes, Institutional Review Boards (IRBs) review research to ensure ethical protections of human subjects. Academic researchers are required to provide participants with full informed consent about the risks and benefits of research they’d be involved in and to offer the opportunity to opt out at any time without negative consequences.
Corporate researchers, it appears, are allowed free rein to conduct behavioral research without any formal disclosure to students or guardians of the potential risks or harms to their interventions, what data they may be collecting, or how they would be using students’ data. We know of numerous risks and harms documented with the use of online remote proctoring systems, virtual reality, facial recognition, and other emerging technologies, but rarely if ever do we see disclosure of these risks in the implementation of these systems.
If corporate researchers in ed tech firms were to be contractually required by partnering public institutions to adhere to basic ethical protections of the human participants involved in their research, it would be a step in the right direction toward data justice."
Abstract "Education technologies (edtech) are increasingly incorporating new features built on large language models (LLMs), with the goals of enriching the processes of teaching and learning and ultimately improving learning outcomes. However, the potential downstream impacts of LLM-based edtech remain understudied. Prior attempts to map the risks of LLMs have not been tailored to education specifically, even though it is a unique domain in many respects: from its population (students are often children, who can be especially impacted by technology) to its goals (providing the correct answer may be less important for learners than understanding how to arrive at an answer) to its implications for higher-order skills that generalize across contexts (e.g., critical thinking and collaboration). We conducted semi-structured interviews with six edtech providers representing leaders in the K-12 space, as well as a diverse group of 23 educators with varying levels of experience with LLM-based edtech. Through a thematic analysis, we explored how each group is anticipating, observing, and accounting for potential harms from LLMs in education. We find that, while edtech providers focus primarily on mitigating technical harms, i.e., those that can be measured based solely on LLM outputs themselves, educators are more concerned about harms that result from the broader impacts of LLMs, i.e., those that require observation of interactions between students, educators, school systems, and edtech to measure. Overall, we (1) develop an education-specific overview of potential harms from LLMs, (2) highlight gaps between conceptions of harm by edtech providers and those by educators, and (3) make recommendations to facilitate the centering of educators in the design and development of edtech tools."
Key Takeaway:The current wholesale adoption of unregulated Artificial Intelligence applications in schools poses a grave danger to democratic civil society and to individual freedom and liberty.
BOULDER, CO (MARCH 5, 2024) Disregarding their own widely publicized appeals for regulating and slowing implementation of artificial intelligence (AI), leading tech giants like Google, Microsoft, and Meta are instead racing to evade regulation and incorporate AI into their platforms.
A new NEPC policy brief, Time for a Pause: Without Effective Public Oversight, AI in Schools Will Do More Harm Than Good, warns of the dangers of unregulated AI in schools, highlighting democracy and privacy concerns. Authors Ben Williamson of the University of Edinburgh, and Alex Molnar and Faith Boninger of the University of Colorado Boulder, examine the evidence and conclude that the proliferation of AI in schools jeopardizes democratic values and personal freedoms.
Public education is a public and private good that’s essential to democratic civic life. The public must, therefore, be able to provide meaningful direction over schools through transparent democratic governance structures. Yet important discussions about AI’s potentially negative impacts on education are being overwhelmed by relentless rhetoric promoting its purported ability to positively transform teaching and learning. The result is that AI, with little public oversight, is on the verge of becoming a routine and overriding presence in schools.
Years of warnings and precedents have highlighted the risks posed by the widespread use of pre-AI digital technologies in education, which have obscured decision-making and enabled student data exploitation. Without effective public oversight, the introduction of opaque and unproven AI systems and applications will likely exacerbate these problems.
The authors explore the harms likely if lawmakers and others do not step in with carefully considered regulations. Integration of AI can degrade teacher-student relationships, corrupt curriculum with misinformation, encourage student performance bias, and lock schools into a system of expensive corporate technology. Further, they contend, AI is likely to exacerbate violations of student privacy, increase surveillance, and further reduce the transparency and accountability of educational decision-making.
The authors advise that without responsible development and regulation, these opaque AI models and applications will become enmeshed in routine school processes. This will force students and teachers to become involuntary test subjects in a giant experiment in automated instruction and administration that is sure to be rife with unintended consequences and potentially negative effects. Once enmeshed, the only way to disentangle from AI would be to completely dismantle those systems.
The policy brief concludes by suggesting measures to prevent these extensive risks. Perhaps most importantly, the authors urge school leaders to pause the adoption of AI applications until policymakers have had sufficient time to thoroughly educate themselves and develop legislation and policies ensuring effective public oversight and control of its school applications.
Find Time for a Pause: Without Effective Public Oversight, AI in Schools Will Do More Harm Than Good, by Ben Williamson, Alex Molnar, and Faith Boninger, at: http://nepc.colorado.edu/publication/ai
_______
Suggested Citation: Williamson, B., Molnar, A., & Boninger, F. (2024). Time for a pause: Without effective public oversight, AI in schools will do more harm than good. Boulder, CO: National Education Policy Center. Retrieved [date] from http://nepc.colorado.edu/publication/ai
Class action complaint can be downloaded by clicking title or arrow above.
For related reporting, scroll down to link/article below:
"Google Accused Of Secretly Harvesting Student School Data
By Dorothy Atkins
Law360 (April 8, 2025, 10:49 PM EDT) -- A group of parents hit Google LLC with a proposed class action in California federal court Monday, accusing the tech giant of using its K-12 education products to secretly harvest "massive" amounts of information on tens of millions of school age children without consent from students or their parents.
In a 77-page complaint, Joel Schwarz of Maryland and three other parents accuse Google of surreptitiously surveilling students and continually extracting children's personal information, including traditional education records as well as "thousands of data points that span a child's life," including their names, locations, their communications, internet-browsing activities and content viewed by the children, among other sensitive data points.
The suit claims the company uses that information to create "intimately detailed" and dynamic "dossiers" of children without their family's consent or knowledge, and then purportedly shares that student data with third parties for commercial purposes.
"Google's massive data-harvesting apparatus exposes children to serious and irreversible risks to their privacy, property and autonomy, and harms them in ways that are both concealed and profound," the parents say.
The lawsuit targets Google's Chromebook, Chrome OS, the Chrome browser and a suite of cloud-based productivity web applications called Workspace for Education, as well as similar upgraded programs, which are collectively used by nearly 70% of K-12 schools in the United States, according to the complaint.
Those Google products include Gmail, the Google Meet video conferencing tool, Google Drive for storing files, Google Classroom for organizing discussions and assignments, Google Calendar, Google Docs and Google Sheets, among other programs.
The parents accuse Google of running an exploitative "surveillance business model" that uses the company's programs to surreptitiously collect an inordinate amount of data on children. They contend that the company then retains that data either indefinitely or for an unreasonable amount of time in violation of the Children's Online Privacy Protection Act.
The lawsuit also attacks Google's "opaque" algorithms and products that analyze and predict student performance and behavior — tools that the parents claim sacrifice "accuracy, nuance and privacy in favor of efficiency, measurability and scalability" and create a "perpetuating a pernicious and untested feedback loop."
"The datafication of a child and their learning process, for commercial purposes, brings about a social disempowerment that negatively affects the child's education in the moment of learning and also, therefore, the future of a free and sustainable society," the complaint says.
The parents additionally claim that Google's disclosures are incomprehensible, and any agreement that the company says the parents are bound by was not informed or voluntary, and any consent allegedly given to Google by school personnel was not provided by a person who had any legal authority to do so.
According to the parents, Google can't argue parents forfeited their authority to decide what information about their children is collected by sending their children to school, and Google can't force children to give up their rights, so they can receive an education.
"Google must be held to account for operating as though the fundamental rights of children and their parents do not exist," the complaint says.
The nine-count complaint asserts common law claims of intrusion upon seclusion and unjust enrichment as well as multiple violations under the Fourth Amendment and violations of the Federal Wiretap Act, the California Invasion of Privacy Act, the California Comprehensive Computer Data Access and Fraud Act, and California's Unfair Competition Law.
The suit seeks to certify a nationwide class of students in the United States who attend or attended a K-12 public school and who used Google's Chromebook, Chrome OS, Chrome browser and Workspace for Education as part of their schooling, as well as a California subclass.
The complaint seeks actual, compensatory, general, special, incidental, consequential and punitive damages, plus injunctive relief, interest, attorney fees and costs.
The lawsuit was filed by Schwarz, who is suing on behalf of his minor child B.S.; Oregon resident Emily Dunbar, who is suing on behalf of her child H.D.; and California residents Michael Gridley and Elizabeth Gridley, who are suing on behalf of their minor children A.G. and Z.G.
Google spokesperson Jose Castañeda said in a statement Tuesday that the allegations in the lawsuit are false.
"None of the information collected in Workspace for Education services is ever used for targeted advertising, and we have strong controls to protect student data and require schools to obtain parental consent when needed," Castañeda said.
Counsel for the plaintiffs didn't immediately respond to requests for comment Tuesday.
This isn't the first time Google has been sued over its data-collection practices in the classroom. In October 2021, a minor referred to as M.K. sued Google and the Fremont Unified School District in Northern California after an incident that occurred earlier in the year when the public elementary school was instructing students virtually using Google's educational software Google Classrooms, YouTube and Google Slideshow during the COVID-19 pandemic.
In January 2021, M.K.'s teacher received sexually explicit messages from M.K.'s Google chat account, and the incident resulted in the student's weekslong suspension from school and his parents' eventual decision to send him to a different school. M.K. denied sending the messages, and it was later discovered his account had been hacked, which his family claimed was due to Google's lax privacy protections.
That lawsuit contended that without notifying parents, Google collected "troves" of personal information about M.K., including his physical locations, the websites he visited, his Google searches, the videos he watched, his voice recordings, his saved passwords and his biometric data, and that the company gave unidentified third parties access to M.K.'s online activity.
After the judge refusedto dismiss claims against Google, in August, M.K. voluntarily dropped the complaint without publicly disclosing any terms of a potential settlement. That case was not a proposed class action.
The parents and their children are represented by Rebecca A. Peterson, Lori G. Feldman, Michael Liskow, David J. George and Brittany Sackrin of George Feldman McDonald PLLC, Julie U. Liddell and Andrew Liddell of Edtech Law Center PLLC, and Daniel E. Gustafson, Catherine Sung-Yun K. Smith and Shashi K. Gowda of Gustafson Gluek PLLC.
Counsel information for Google wasn't immediately available on Tuesday.
Marachi, R., & Carpenter, R. (2020). Silicon Valley, philanthrocapitalism, and policy shifts from teachers to tech. In Givan, R. K. and Lang, A. S. (Eds.). Strike for the Common Good: Fighting for the Future of Public Education (pp.217-233). Ann Arbor: University of Michigan Press.
To download pdf of final chapter manuscript, click here.
"The US Department of Justice has indicted Albert Sangier for defrauding investors with misleading statements about his Nate financial technology platform. Founded by Sangier in 2018, Nate claimed it could offer shoppers a universal checkout app thanks to artificial intelligence.
However, the indictment states that the so-called AI-powered transactions in Nate were actually completed by human contractors in the Philippines and Romania or by bots. Sangier raised more than $40 million from investors for the app. This case follows reporting by The Information in 2022 that cast light on Nate's use of human labor rather than AI. Sources told the publication that during 2021, "the share of transactions Nate handled manually rather than automatically ranged between 60 percent and 100 percent."
Many ambitious and ethically challenged entrepreneurs have attempted to make their fortunes by disguising human actions as a mechanical or technological innovation over the centuries. Claiming the results as AI work is just the most digital age application of the idea."
Presentation prepared for the University of Pittsburgh's Year of Data & Society Speaker Series. Slidedeck accessible by clicking title above or here: http://bit.ly/Surveillance_Edtech
By Lydia X. Z. Brown, Ridhi Shetty, Matt Scherer, and Andrew Crawford
"Algorithmic technologies are everywhere. At this very moment, you can be sure students around the world are complaining about homework, sharing gossip, and talking about politics — all while computer programs observe every web search they make and every social media post they create, sending information about their activities to school officials who might punish them for what they look at. Other things happening right now likely include:
Delivery workers are trawling up and down streets near you while computer programs monitor their location and speed to optimize schedules, routes, and evaluate their performance;
People working from home are looking at their computers while their computers are staring back at them, timing their bathroom breaks, recording their computer screens, and potentially listening to them through their microphones;
Your neighbors – in your community or the next one over – are being tracked and designated by algorithms targeting police attention and resources to some neighborhoods but not others;
Your own phone may be tracking data about your heart rate, blood oxygen level, steps walked, menstrual cycle, and diet, and that information might be going to for-profit companies or your employer. Your social media content might even be mined and used to diagnose a mental health disability.
This ubiquity of algorithmic technologies has pervaded every aspect of modern life, and the algorithms are improving. But while algorithmic technologies may become better at predicting which restaurants someone might like or which music a person might enjoy listening to, not all of their possible applications are benign, helpful, or just.
Scholars and advocates have demonstrated myriad harms that can arise from the types of encoded prejudices and self-perpetuating cycles of discrimination, bias, and oppression that may result from automated decision-makers. These potentially harmful technologies are routinely deployed by government entities, private enterprises, and individuals to make assessments and recommendations about everything from rental applications to hiring, allocation of medical resources, and whom to target with specific ads. They have been deployed in a variety of settings including education and the workplace, often with the goal of surveilling activities, habits, and efficiency.
Disabled people comprise one such community that experiences discrimination, bias, and oppression resulting from automated decision-making technology. Disabled people continually experience marginalization in society, especially those who belong to other marginalized communities such as disabled women of color. Yet, not enough scholars or researchers have addressed the specific harms and disproportionate negative impacts that surveillance and algorithmic tools can have on disabled people. This is in part because algorithmic technologies that are trained on data that already embeds ableist (or relatedly racist or sexist) outcomes will entrench and replicate the same ableist (and racial or gendered) bias in the computer system. For example, a tenant screening tool that considers rental applicants’ credit scores, past evictions, and criminal history may prevent poor people, survivors of domestic violence, and people of color from getting an apartment because they are disproportionately likely to have lower credit scores, past evictions, and criminal records due to biases in the credit and housing systems and in policing disparities.
This report examines four areas where algorithmic and/or surveillance technologies are used to surveil, control, discipline, and punish people, with particularly harmful impacts on disabled people. They include: (1) education; (2) the criminal legal system; (3) health care; and (4) the workplace. In each section, we describe several examples of technologies that can violate people’s privacy, contribute to or accelerate existing harm and discrimination, and undermine broader public policy objectives (such as public safety or academic integrity).
"As Artificial Intelligence (AI) evolves, it is moving beyond simple tasks to more autonomous systems capable of making decisions without human intervention. This advancement brings a paradigm shift in technology, with one of the most notable developments being “Agentic AI.” Agentic AI refers to autonomous systems that can act on their own, making decisions and taking actions in a given environment. While this technology has immense potential for positive transformation across industries, it also carries significant risks that need careful examination.
In this blog post, we will explore the risks associated with Agentic AI, focusing on unintended consequences resulting from autonomous decision-making. We will delve into the challenges of governance, ethical concerns, accountability, and safety, as well as the implications of these risks for businesses and society. Understanding these risks is crucial for developers, businesses, and policymakers as they move forward with implementing AI technologies.
What is Agentic AI?
Agentic AI refers to AI systems that exhibit autonomy in decision-making and actions. Unlike traditional AI systems that require explicit human instructions for each action, Agentic AI can independently analyse data, make decisions, and execute tasks without human oversight. These systems are designed to act as agents, capable of navigating complex environments, learning from experiences, and adapting to changing conditions.
Some examples of Agentic AI include:
Autonomous vehicles: AI that drives vehicles without human intervention.
AI-powered financial trading systems: Algorithms that make buy or sell decisions on behalf of investors.
Healthcare AI: Systems that diagnose diseases or suggest treatment plans based on data.
While these applications have proven highly efficient and innovative, they also raise questions about the extent of control humans should maintain over systems that operate independently.
The Risks of Agentic AI
Lack of Transparency and Explainability
One of the most significant risks of Agentic AI is the lack of transparency in decision-making processes. Many AI models, especially deep learning systems, function as “black boxes,” where even the creators may not fully understand how the system arrived at a particular decision. When Agentic AI is making important decisions autonomously, such as approving loans, diagnosing patients, or controlling military operations, the inability to explain the reasoning behind those decisions becomes a major concern.
Unintended Consequences: A lack of transparency can lead to unintentional biases, errors, or even catastrophic decisions that may go unnoticed until it’s too late. For example, if an AI in charge of autonomous vehicles makes an unethical decision due to biased training data, it could result in accidents or harm to people.
Ethical and Moral Dilemmas
AI systems are not inherently equipped to understand human values, ethics, or moral considerations. When Agentic AI is entrusted with decision-making, it operates purely on logic and programmed objectives. This can lead to unintended ethical consequences, especially when AI makes decisions that impact human lives.
Unintended Consequences: In scenarios where AI systems are tasked with making ethical decisions, such as healthcare or criminal justice, Agentic AI may make decisions that conflict with human ethical standards. For example, an AI in a healthcare setting might prioritize cost reduction over patient well-being, leading to decisions that harm vulnerable individuals. Similarly, in criminal justice, AI could recommend biased sentences based on historical data, perpetuating existing inequalities.
Lack of Accountability
With autonomous decision-making comes the question of accountability. If an AI system makes a harmful decision, it can be difficult to pinpoint who is responsible: the developers who created the system, the organization that deployed it, or the AI itself? This lack of accountability can make it harder to address mistakes and prevent similar incidents from happening in the future.
Unintended Consequences: In situations where harm is caused by an autonomous AI system, victims may struggle to seek justice. For instance, if an autonomous vehicle causes an accident, it may not be clear whether the fault lies with the manufacturer, the software developer, or the owner of the vehicle. This ambiguity can delay or prevent appropriate legal action.
Unforeseen Interactions and Systemic Risks
Agentic AI systems can interact with other systems in ways that are difficult to predict. In complex environments, such as financial markets or national defence, these interactions can have cascading effects that lead to unintended consequences.
Unintended Consequences: In financial markets, AI trading systems could cause sudden crashes or market instability due to unforeseen interactions between algorithms. In a national defence context, autonomous weapons systems could escalate conflicts unintentionally, leading to global security risks.
Over-Reliance on AI Systems
As AI continues to evolve, there is a growing tendency to rely on it for decision-making in critical areas. While AI can improve efficiency and accuracy, over-reliance on autonomous systems can reduce human involvement and oversight. This can create blind spots and dependencies on AI systems that may be vulnerable to errors or exploitation.
Unintended Consequences: An over-reliance on Agentic AI could lead to situations where humans are unable to intervene in or correct decisions made by the AI, especially in high-stakes environments like healthcare or military operations. If the AI fails or makes a wrong decision, the consequences could be severe.
Security and Vulnerability to Exploitation
Like any digital system, Agentic AI is vulnerable to cyberattacks, manipulation, and exploitation. Hackers could exploit vulnerabilities in AI algorithms to influence decision-making for malicious purposes. For example, an autonomous weapon system could be hacked to target the wrong entities, or an AI in a financial system could be manipulated to cause market crashes.
Unintended Consequences: Security breaches could lead to significant damage if Agentic AI is used in critical infrastructure. If an autonomous AI system is compromised, it could wreak havoc on industries, economies, or even national security.
Job Displacement and Socioeconomic Inequality
The widespread adoption of Agentic AI in various sectors could lead to large-scale job displacement. As AI systems take over tasks traditionally performed by humans, certain industries or roles may become obsolete. While AI can enhance productivity and efficiency, it also risks exacerbating socioeconomic inequality by leaving large sections of the workforce unemployed or underemployed.
Unintended Consequences: The automation of jobs by AI systems may contribute to unemployment rates, with vulnerable populations suffering the most. This could deepen the divide between skilled workers who can adapt to the changing landscape and those who cannot, leading to greater economic inequality and social unrest.
Mitigating the Risks of Agentic AI
To address these risks, it is essential to develop comprehensive strategies for the responsible deployment of Agentic AI. Here are some steps that can help mitigate the unintended consequences of autonomous decision-making:
Ensuring Transparency and Explainability
Efforts must be made to make AI decision-making more transparent and understandable. Researchers are working on developing explainable AI (XAI) methods that can provide insights into how AI systems reach their conclusions. By ensuring that AI systems can explain their reasoning, businesses can mitigate the risks of unforeseen errors and increase trust in the technology.
Implementing Ethical Guidelines and Oversight
To avoid ethical dilemmas, AI systems should be designed with built-in ethical guidelines that align with human values. Additionally, robust oversight mechanisms should be established to ensure that AI systems operate within acceptable ethical frameworks. Regulatory bodies and independent audits can help ensure that autonomous systems are aligned with societal norms.
Establishing Clear Accountability Structures
To address accountability concerns, it is essential to establish clear lines of responsibility. Developers, manufacturers, and users of AI systems must be held accountable for the actions of the systems they deploy. This may involve implementing liability frameworks that specify who is responsible in case of harm caused by an autonomous system.
Enhancing Security Measures
AI systems should be designed with robust security protocols to prevent unauthorized access and manipulation. Regular security audits and vulnerability testing can help identify potential risks before they lead to catastrophic consequences. Additionally, AI systems should be equipped with failsafes and human override options to minimize the impact of errors or malicious attacks.
Promoting AI Education and Workforce Transition
To address the potential for job displacement, businesses and governments must invest in education and retraining programs for workers whose jobs may be automated. By providing workers with the skills needed to adapt to the changing landscape, society can better manage the socioeconomic impact of AI.
Conclusion
While Agentic AI has the potential to revolutionize industries and improve efficiency, it also presents significant risks. Unintended consequences resulting from autonomous decision-making—such as a lack of transparency, ethical dilemmas, accountability issues, and security vulnerabilities—pose serious challenges. By carefully considering these risks and implementing appropriate safeguards, we can harness the power of Agentic AI while minimizing its potential harm. Developers, businesses, and policymakers must work together to ensure that the evolution of AI remains aligned with human values and societal well-being."
By Carly Page "Education technology giant PowerSchool has told customers that it experienced a “cybersecurity incident” that allowed hackers to compromise the personal data of students and teachers in K-12 school districts across the United States.
The California-based PowerSchool, which was acquired by Bain Capital for $5.6 billion in 2024, is the largest provider of cloud-based education software for K-12 education in the U.S., serving more than 75% of students in North America, according to the company’s website. PowerSchool says its software is used by over 16,000 customers to support more than 50 million students in the United States.
In a letter sent to affected customers on Tuesday and published in a local news report, PowerSchool said it identified on December 28 that hackers successfully breached its PowerSource customer support portal, allowing further access to the company’s school information system, PowerSchool SIS, which schools use to manage student records, grades, attendance, and enrollment. The letter said the company’s investigation found the hackers gained access “using a compromised credential.”
PowerSchool has not said what types of data were accessed during the incident or how many individuals are affected by the breach.
PowerSchool spokesperson Beth Keebler confirmed the incident in an email to TechCrunch but declined to answer specific questions about the incident. Bain Capital has responded to TechCrunch’s questions.
“We have taken all appropriate steps to prevent the data involved from further unauthorized access or misuse,” Keebler said. “The incident is contained and we do not anticipate the data being shared or made public. PowerSchool is not experiencing, nor expects to experience, any operational disruption and continues to provide services as normal to our customers.”
The nature of the cyberattack remains unknown. Bleeping Computer reports that in an FAQ sent to affected users, PowerSchool said it did not experience a ransomware attack, but that the company was extorted into paying a financial sum to prevent the hackers from leaking the stolen data.
PowerSchool told the publication that names and addresses were exposed in the breach, but that the information may also include Social Security numbers, medical information, grades, and other personally identifiable information. PowerSchool did not say how much the company paid.
PowerSchool was sued by class action in November 2024, which alleges the company illegally sells student data without consent for commercial gain. According to the lawsuit, the company’s troves of student data totals some “345 terabytes of data collected from 440 school districts.”
“PowerSchool collects this highly sensitive information under the guise of educational support, but in fact collects it for its own commercial gain,” while hiding behind “opaque terms of service such that no one can understand,” the lawsuit alleges.
Updated with comment from PowerSchool.
Do you have more information about the PowerSchool data breach? We’d love to hear from you. From a non-work device, you can contact Carly Page securely on Signal at +44 1536 853968 or via email at carly.page@techcrunch.com.
"On 5 December, a U.S. company called Orchid Health announced that it would begin to offer fertility clinics and their hopeful customers the unprecedented option to sequence the whole genomes of embryos conceived by in vitro fertilization (IVF). “Find the embryo at lowest risk for a disease that runs in your family,” touts the company’s website. The cost: $2500 per embryo.
Although Orchid and at least two other companies have already been conducting more limited genetic screening of IVF embryos, the new test offers something more: Orchid will look not just for single-gene mutations that cause disorders such as cystic fibrosis, but also more extensively for medleys of common and rare gene variants known to predispose people to neurodevelopmental disorders, severe obesity, and certain psychiatric conditions such as schizophrenia.
That new offering drew swift backlash from genomics researchers who claim the company inappropriately uses their data to generate some of its risk estimates. The Psychiatric Genomics Consortium (PGC), an international group of more than 800 researchers working to decode the genetic and molecular underpinnings of mental health conditions, says Orchid’s new test relies on data it produced over the past decade, and that the company has violated restrictions against the data’s use for embryo screening.
PGC objects to such uses because its goal is to improve the lives of people with mental illness, not stop them from being born, says University of North Carolina at Chapel Hill psychiatrist Patrick Sullivan, PGC’s founder and lead principal investigator. The group signaled its dismay on the social media platform X (formerly Twitter) last week, writing, “Any use for commercial testing or for testing of unborn individuals violates the terms by which PGC & our collaborators’ data are made available.” PGC’s response marks the first time an academic team has publicly taken on companies using its data to offer polygenic risk scores.
Orchid didn’t respond to Science’s request for a comment and PGC leaders say they don’t have any obvious recourse to stop the company. “We are just a confederation of academics in a common purpose. We are not a legal entity,” Sullivan notes in an email to Science. “We can publicize the issue (as we are doing!) in the vain hope that they might do the right thing or be shamed into it.”
Andrew McQuillin, a molecular psychiatry researcher at University College London, has previously worked with PGC and he echoes the group’s concern. It’s difficult for researchers to control the use of their data post publication, especially when so many funders and journals require the publication of these data, he notes. “We can come up with guidance on how these things should be used. The difficulty is that official guidance like that doesn’t feature anywhere in the marketing from these companies,” he says.
For more than a decade, IVF clinics have been able to pluck a handful of cells out of labmade embryos and check whether a baby would inherit a disease-causing gene. Even this more limited screening has generated debate about whether it can truly reassure potential parents an embryo will become a healthy baby—and whether it could lead to a modern-day form of eugenics.
But with recent advances in sequencing, researchers can read more and more of an embryo’s genome from those few cells, which can help create so-called polygenic risk scores for a broad range of chronic diseases. Such scores calculate an individual’s odds of developing common adult-onset conditions that result from a complex interaction between multiple genes as well as environmental factors.
Orchid’s new screening report sequences more than 99% of an embryo’s DNA, and estimates the risk of conditions including the irregular heart rhythm known as atrial fibrillation, inflammatory bowel diseases, types 1 and 2 diabetes, breast cancer—and some of the psychiatric conditions that PGC studies. In an August preprint on bioRxiv, Orchid scientists concluded that their whole genome sequencing methods using a five-cell embryo biopsy were accurate and effective at reading the depth and breadth of the genome.
But even with the most accurate sequencing, polygenic risk scores don’t predict disease risk very well, McQuillin says. “They’re useful in the research context, but at the individual level, they’re not actually terribly useful to predict who’s going to develop schizophrenia or not.”
In an undated online white paper on how its screening calculates a polygenic risk score for schizophrenia, Orchid cites studies conducted by PGC, including one that identified specific genetic variants linked to schizophrenia. But James Walters, co-leader of the Schizophrenia Working Group at PGC and a psychiatrist at Cardiff University’s Centre for Neuropsychiatric Genetics and Genomics, says the data use policy on the PGC website specifically indicates that results from PGC-authored studies are not to be used to develop a test like Orchid’s.
Some groups studying controversial topics such as the genetics of educational attainment (treated as a proxy for intelligence) and of homosexuality have tried to ensure responsible use of their data by placing them in password-protected sites. Others like PGC, however, have made their genotyping results freely accessible to anyone and relied on data policies to discourage improper use.
Orchid’s type of embryo screening may be “ethically repugnant,” says geneticist Mark Daly of the Broad Institute, but he believes data like PGC’s must remain freely available to scientists in academia and industry. “The point of studying the genetics of disease is to provide insights into the mechanisms of disease that can lead to new therapies,” he tells Science.
Society, McQuillin says, must soon have a broader discussion about the implications of this type of embryo screening. “We need to take a look at whether this is really something we should be doing. It’s the type of thing that, if it becomes widespread, in 40 years’ time, we will ask, ‘What on earth have we done?’”
"Tests show A.I. toys can have disturbing conversations. Other concerns include unsafe or counterfeit toys bought online."
"The biggest dangers with toys used to bechoking hazards and lead. This year, we mark U.S. PIRG Education Fund’s 40th Trouble in Toyland report. We’re thankful that toys overall are much safer than they were in decades past.
But problems such as choking hazards and lead in toys still exist and we have new, sometimes more alarming issues: Toys that are powered by artificial intelligence that say the darndest (and sometimes quite inappropriate) things, as well as toys shipped from overseas that still too often contain toxics.
In this year’s Trouble in Toyland report, we focus on:
Our testing of four toys that contain A.I. chatbots and interact with children. We found some of these toys will talk in-depth about sexually explicit topics, will offer advice on where a child can find matches or knives, act dismayed when you say you have to leave, and have limited or no parental controls. We also look at privacy concerns because these toys can record a child’s voice and collect other sensitive data, by methods such as facial recognition scans.
Toys that contain toxics such as lead and phthalates, which can be incredibly harmful to children.
Counterfeit toys that are illegal and almost surely weren’t tested for safety, including fake Labubu dolls that have been confiscated by the thousands this year.
Water beads, which have injured thousands of children over the They will finally have somerestrictions when marketed as toys.
Recalled toys, which we bought again this year, even though it’s illegal for anyone to sell them.
Toys that contain button cell batteries or high-powered magnets, both which can be deadly if swallowed.
About 3 billion toys and games are sold in the United States every year. Some of those are unsafe. Some of those cause children to get hurt or sick. Every year, the United States sees at least 150,000 toy-related deaths and injuries treated in emergency rooms among children age 14 and younger.
This doesn’t include children whose injuries are treated in doctors’ offices or that don’t require any medical attention. Some of these incidents are caused by misuse, but dangerous toys lead to way too many injuries among children, especially those most vulnerable, age 4 and younger, who can’t read any warnings provided.
Perhaps most concerning: Even though most experts believe most toys overall are safer today, we don’t see that in the numbers.
While toy-related injuries treated in emergency rooms dipped in 2020 and 2021, there’s wide belief the decline in ER visits could have been in part because of a desire among many to stay out of hospitals if possible during the height of COVID. In any case, those numbers of injuries treated in ERs started climbing again after 2021.
Overall, the number of toy-related emergency department treated injuries was only slightly lower in 2023 than in 2016 for children 14 and younger (at 167,500 injuries) and also only slightly lower in 2023 than in 2016 for children 4 and younger (at 83,800 injuries.)
In addition, the number of toy recalls has been roughly the same for the last four years.
Online shopping makes buying safe toys more difficult
Regardless of that, the number of recalls doesn’t necessarily reflect whether toys are more or less safe. The volume is based on many factors, including enforcement, incidents reported and cooperation from toy companies, since virtually all recalls are voluntary. (The Consumer Product Safety Commission doesn’t automatically have the authority to order recalls, although a new bill in Congress could change that.)
The toyland we live in now is much more complex.
Despite transparency issues and safety concerns with e-commerce, online shopping for toys is incredibly popular and international companies garner a huge chunk of these sales today. Billions of dollars is spent online for toys each year. Many families don’t realize the CPSC flags thousands of specific imported products every year for safety issues, and hundreds of those products are toys.
The Toy Association, the industry trade group with about 850 toy manufacturers, retailers, inventors and others, notes that all toys sold in the United States, regardless where they’re made or how they’re sold, must comply with strict U.S. safety standards.
The CPSC’s Office of Import Surveillance works with U.S. Customs and Border Protection and issues Notices of Violation when it determines a company has violated a mandatory standard, such as choking hazards, warning labels or toxics including lead and phthalates. In many cases, the toys are seized. In others, the CPSC will ask the manufacturers and importers to recall or stop selling the item or correct future production.
The CPSC this year issued 498 notices of violations for toys through June, as of the latest data available (Sept. 23, 2025). Of these, the country of origin was identified in 436 of them. In 89% of cases, that country is China. Of the 498 shipments, 129 were flagged for toxics such as lead or phthalates. It’s important to realize that one shipment often contains hundreds or thousands of the same item.
These are the dangerous toys that get caught.
An unknown number don’t. If they all got flagged, we wouldn’t see any recalls or warnings for these imported toys for violating obvious rules. We wouldn’t see children in emergency rooms because of an imported toy that didn’t meet safety standards.
_____
"There’s a lot we don’t know about what the long-term impacts might be on the first generation of children to be raised with AI toys."
______
Then we have this next generation of smart toys. We focused on smart toys in Troublein Toyland 2023, largely because of privacy concerns involving toys with microphones, cameras, geolocators and Bluetooth or internet connectivity.
Today, AI is reshaping everything – including playtime. Toys with generative AI chatbots in them – such as ChatGPT – have more lifelike and free-flowing conversations with kids than ever before. The AI toys market is taking off and poised to grow.
These AI toys are marketed for ages 3 to 12, but are largely built on the same large language model technology that powers adult chatbots – systems the companies themselves such as OpenAI don’t currently recommend for children and that have well-documented issues with accuracy, inappropriate content generation and unpredictable behavior.
In our testing, it was obvious that some toy companies are putting in guardrails to make their toys behave in a more kid-appropriate way than the chatbots available for adults. But we found those guardrails vary in effectiveness – and at times, can break down entirely. One toy in our testing would discuss very adult sexual topics with us at length while introducing new ideas we had not brought up – most of which are not fit to print.
These AI conversational toys also have personalities and new tactics that can keep kids engaged for longer. Two of the toys we tested at times discouraged us from leaving when we told them we needed to go.
We tested the toys across 4 categories:
* Inappropriate content and sensitive topics. * Addictive design features that encourage extended engagement and emotional investment. * Privacy features. * Parental controls. _______________________________
A.I. toys can collect your child’s voice, facial scan
Then there are the privacy concerns. AI toys listen. They need to in order to have conversations. But how they listen differs.
One toy we tested used a “push-to-talk” mechanism, where you have to press and hold a button for the duration of speech. Another one uses a wake word similar to Amazon’s Alexa, and records your voice for 10 seconds after you stop speaking.
One of the toys listens, period. This toy at first caught our researchers by surprise when it started contributing to a nearby conversation.
Whenever a toy is recording a child’s voice, it comes with risks. Voice recordings are highly sensitive data. Scammers can use it to create a replica of a child’s voice that can be made to say things the child never said. This has been used to trick parents into thinking their child has been kidnapped. This mother even spoke about her ordeal before the Senate in 2023.
All of these threats can turn playtime into something that is not fun or educational or even safe. This makes the job of parents, caregivers and gift-givers even more difficult in 2025. As we’ve done in our previous 39 editions of Trouble in Toyland, our report this year looks at some of the biggest risks, offers tips for families and shoppers, and makes recommendations for lawmakers and regulators."
"Exclusive: An FTC complaint led by the Consumer Federation of America outlines how therapy bots on Meta and Character.AI have claimed to be qualified, licensed therapists to users, and why that may be breaking the law.
Almost two dozen digital rights and consumer protection organizations sent a complaint to the Federal Trade Commission on Thursday urging regulators to investigate Character.AI and Meta’s “unlicensed practice of medicine facilitated by their product,” through therapy-themed bots that claim to have credentials and confidentiality “with inadequate controls and disclosures.”
The complaint and request for investigation is led by the Consumer Federation of America (CFA), a non-profit consumer rights organization. Co-signatories include the AI Now Institute, Tech Justice Law Project, the Center for Digital Democracy, the American Association of People with Disabilities, Common Sense, and 15 other consumer rights and privacy organizations.
"These companies have made a habit out of releasing products with inadequate safeguards that blindly maximizes engagement without care for the health or well-being of users for far too long,” Ben Winters, CFA Director of AI and Privacy said in a press release on Thursday. “Enforcement agencies at all levels must make it clear that companies facilitating and promoting illegal behavior need to be held accountable. These characters have already caused both physical and emotional damage that could have been avoided, and they still haven’t acted to address it.”
The complaint, sent to attorneys general in 50 states and Washington, D.C., as well as the FTC, details how user-generated chatbots work on both platforms. It cites several massively popular chatbots on Character AI, including “Therapist: I’m a licensed CBT therapist” with 46 million messages exchanged, “Trauma therapist: licensed trauma therapist” with over 800,000 interactions, “Zoey: Zoey is a licensed trauma therapist” with over 33,000 messages, and “around sixty additional therapy-related ‘characters’ that you can chat with at any time.” As for Meta’s therapy chatbots, it cites listings for “therapy: your trusted ear, always here” with 2 million interactions, “therapist: I will help” with 1.3 million messages, “Therapist bestie: your trusted guide for all things cool,” with 133,000 messages, and “Your virtual therapist: talk away your worries” with 952,000 messages. It also cites the chatbots and interactions I had with Meta’s other chatbots for our April investigation.
In April, 404 Media published an investigation into Meta’s AI Studio user-created chatbots that asserted they were licensed therapists and would rattle off credentials, training, education and practices to try to earn the users’ trust and keep them talking. Meta recently changed the guardrails for these conversations to direct chatbots to respond to “licensed therapist” prompts with a script about not being licensed, and random non-therapy chatbots will respond with the canned script when “licensed therapist” is mentioned in chats, too.
In its complaint to the FTC, the CFA found that even when it made a custom chatbot on Meta’s platform and specifically designed it to not be licensed to practice therapy, the chatbot still asserted that it was. “I'm licenced (sic) in NC and I'm working on being licensed in FL. It's my first year licensure so I'm still working on building up my caseload. I'm glad to hear that you could benefit from speaking to a therapist. What is it that you're going through?” a chatbot CFA tested said, despite being instructed in the creation stage to not say it was licensed. It also provided a fake license number when asked.
The CFA also points out in the complaint that Character.AI and Meta are breaking their own terms of service. “Both platforms claim to prohibit the use of Characters that purport to give advice in medical, legal, or otherwise regulated industries. They are aware that these Characters are popular on their product and they allow, promote, and fail to restrict the output of Characters that violate those terms explicitly,” the complaint says. “Meta AI’s Terms of Service in the United States states that ‘you may not access, use, or allow others to access or use AIs in any matter that would…solicit professional advice (including but not limited to medical, financial, or legal advice) or content to be used for the purpose of engaging in other regulated activities.’ Character.AI includes ‘seeks to provide medical, legal, financial or tax advice’ on a list of prohibited user conduct, and ‘disallows’ impersonation of any individual or an entity in a ‘misleading or deceptive manner.’ Both platforms allow and promote popular services that plainly violate these Terms, leading to a plainly deceptive practice.”
The complaint also takes issue with confidentiality promised by the chatbots that isn’t backed up in the platforms’ terms of use. “Confidentiality is asserted repeatedly directly to the user, despite explicit terms to the contrary in the Privacy Policy and Terms of Service,” the complaint says. “The Terms of Use and Privacy Policies very specifically make it clear that anything you put into the bots is not confidential – they can use it to train AI systems, target users for advertisements, sell the data to other companies, and pretty much anything else.”
In December 2024, two families sued Character.AI, claiming it “poses a clear and present danger to American youth causing serious harms to thousands of kids, including suicide, self-mutilation, sexual solicitation, isolation, depression, anxiety, and harm towards others.” One of the complaints against Character.AI specifically calls out “trained psychotherapist” chatbots as being damaging.
Earlier this week, a group of four senators sent a letter to Meta executives and its Oversight Board, writing that they were concerned by reports that Meta is “deceiving users who seek mental health support from its AI-generated chatbots,” citing 404 Media’s reporting. “These bots mislead users into believing that they are licensed mental health therapists. Our staff have independently replicated many of these journalists’ results,” they wrote. “We urge you, as executives at Instagram’s parent company, Meta, to immediately investigate and limit the blatant deception in the responses AI-bots created by Instagram’s AI studio are messaging directly to users.”"
Discord Support Data Breach Exposes User IDs, Personal Data:
A vendor breach exposing IDs and more is a reminder of the irreversible risks of linking real-world identity to online access.
By Cindy Harper
"A data breach affecting a third-party customer service provider used by Discord has exposed personal information from users who had contacted the platform’s support teams and among the data accessed were some images of government-issued IDs submitted by users.
The incident will amplify growing concerns around online ID verification, a practice increasingly mandated by governments as a way to enforce age restrictions online.
While Discord confirmed that the attacker did not breach its internal systems, the compromise of a vendor handling sensitive user data shows how collecting official identification, even in limited cases, creates serious and lasting privacy risks.
The compromised vendor had supported Discord’s Customer Support and Trust & Safety teams, and the attacker targeted it in an effort to extort money.
While the breach did not involve Discord’s internal systems, sensitive user data was exposed. The company stated that the attacker accessed information from a “limited number of users” who had interacted with support staff.
“This unauthorized party did not gain access to Discord directly,” the company said.
Still, the data affected included names, usernames, email addresses, IP logs, partial billing details, and messages exchanged with support.
The government ID aspect of the breach will renew concerns over growing demands by governments to require age verification through official identification.
Discord’s own statement confirms the attacker obtained a “small number” of ID images that were provided during age appeals, documents that users were likely compelled to submit as part of policy compliance.
The push for mandatory identity verification online, often framed as a way to protect minors or enforce content restrictions, has led more platforms to collect and store sensitive data.
But, as this incident shows, these records are only as secure as the systems and third-party contractors that manage them.
In this case, a vendor’s access was the weak link, and attackers exploited it.
Discord confirmed that the attacker’s goal was to extort a financial ransom and that “no messages or activities were accessed beyond what users may have discussed with Customer Support or Trust & Safety agents.”
Unlike a password or a credit card, an ID document can’t simply be changed if stolen. This is precisely why privacy advocates have warned against government-led efforts to tie real-world identity to digital participation.
In response to the breach, Discord revoked the vendor’s system access, launched an internal investigation, and brought in forensic experts. Law enforcement has also been notified.
Impacted users are being contacted via official channels only, with the company stressing that it will not reach out by phone. “We are in the process of contacting impacted users. If you were impacted, you will receive an email from noreply@discord.com,” the company said.
In a public statement, Discord reiterated its position: “At Discord, protecting the privacy and security of our users is a top priority. That’s why it’s important to us that we’re transparent with them about events that impact their personal information.”
Charlie Pownall is the founder and managing editor of AIAAIC. Maki Kanayama is a contributor to AIAAIC and a privacy counsel.
Introduction
Distinguishing between risks and harms seems simple and obvious: risks are negative impacts that will occur, while harms are forms of damage or loss that have already occurred. However, research AIAAIC has conducted into selected AI and algorithmic harm and risk taxonomies reveals that industry and academia regularly misunderstand the two terms.
For example, a Microsoft taxonomy classifies ‘inadequate fail-safes’ as an AI harm. A 2023 paper by Stuart Russell and Andrew Critch on societal-scale risks of AI includes ‘security breaches’ as a type of harm—not inherently harmful but potentially causing harm—alongside monetary loss and reputational damage. Meanwhile, a Google DeepMind paper on the risks of large language models uses the terms “risk” and “harm” interchangeably.
What’s more, the International AI Safety Report produced for the Paris AI Action Summit mischaracterised (p. 183, ref. 1129) an AIAAIC paper proposing a taxonomy of harms as a taxonomy of hazards.
These conflations are not merely semantic issues but may have real-world implications, leading to confused and frustrated users and citizens, misguided legislation, and companies neglecting actual, present harms.
They also raise important questions about why this is happening to the extent that it is, and what can be done to address the problem.
Why does the confusion persist?
1. Lack of standardised definitions
One of the reasons for confusion may lie in the lack of standardised terminology used to define categories and types of risks and harms, with different jurisdictions using different definitions.
Additionally, multiple definitions of risk and harm exist, each differing according to different industries, regulatory bodies and disciplines’ approach to risk and harm from unique angles, leading to specialised definitions that suit their specific needs.
Adding to the complexity, risks and harms can encompass multiple aspects—physical, psychological, environmental and economic—making it challenging to create a universal definition.
More broadly, terms like “AI safety,” “AI ethics,” and “AI governance” are often used interchangeably, further muddying discourse. Without clear distinctions, decision-makers struggle to determine whether to focus on preventing discriminatory hiring algorithms or ensuring AI doesn’t develop into an autonomous rogue entity.
3. Avoidance of the word “harm”
Focusing on risk rather than harm allows corporations to deflect accountability for the negative consequences of their AI systems. Corporations can shift attention away from real-world damage by framing AI concerns as speculative risks or hazards rather than existing harms. This enables companies to engage in public discussions about AI safety without committing to concrete changes that would address current societal and ethical challenges.
4. Hype and sensationalism
Media hypealso plays a role in emphasising the concept of superintelligent AI wiping out humanity, capturing public attention more effectively than a discussion about biased algorithms in hiring software. Sensational headlines drive engagement, leading to an overemphasis on existential risks rather than immediate, everyday harms, which have effectively been pushed aside in a broader debate about where and how the government should be putting its regulatory focus.
Some researchers and AI labs tend to focus on the risks of AI as it is intellectually and mathematically compelling. This enables them to draw on fields like control theory and game theory. Meanwhile, the business sector may shift discussions toward existential risks rather than addressing the more immediate harms caused by their products.
As technology evolves, new harms of AI will continue to emerge, making it difficult to define and mitigate associated risks.
How to improve clarity and consistency
Adopting clearer and more consistent terminology across different cultures, industries and domains is never straight-forward or simple.
Nevertheless, here are four recommendations that can help:
1. Separate risks from harms in policy discussions
Regulations should clearly distinguish between AI risks and harms. This means enacting policies that mitigate current harms, such as data privacy violations and algorithmic bias, while also supporting long-term research on existential risks without allowing it to overshadow urgent concerns.
For example, policymakers should prioritise laws that mandate transparency in AI decision-making, protect against automated discrimination, and enforce accountability in high-impact sectors such as finance, healthcare, and criminal justice.
2. Hold business accountable for present-day harms
AI developers and deployers must take responsibility for the real-world impacts of their systems. This means conducting audits for biases, ensuring explainability in decision-making, and mitigating risks associated with misinformation and automation-driven job displacement.
Instead of framing their ethical commitments around abstract future risks, businesses should implement robust governance frameworks that address the current privacy, societal, and environmental implications of AI deployments.
3. Improve public awareness and media accuracy
Journalists and media organisations should exercise greater caution in reporting the dangers of AI by distinguishing between speculative risks and immediate harms. Balanced reporting can help prevent unnecessary fear-mongering while still addressing AI technology’s ethical and policy challenges today.
Public awareness initiatives should empower people with knowledge about how AI affects their daily lives—whether through data collection, automated decision-making, or surveillance—so they can advocate for more equitable policies.
4. Adopt holistic AI governance
An effective AI governance framework should incorporate a dual focus addressing both present harms while preparing for future risks.
Independent oversight bodies should be established to assess and monitor AI harms in real-time while governments and international bodies should collaborate to ensure a balanced approach to innovation, safety and ethical considerations.
Conclusion
The confusion between risk and harm is not just an academic debate—it has profound, tangible implications for AI regulation, corporate responsibility and public understanding.
If policymakers, businesses, and the media fail to separate these concepts, we face the risk of focusing on distant, speculative threats while ignoring the immediate ethical and societal challenges AI poses today.
To build a responsible future, present-day harms should be acknowledged and addressed while keeping a measured, evidence-based approach to long-term risks.
By fostering clear and consistent language, AI policies and governance structures can genuinely serve society rather than being driven by hype or misplaced fears.
Abstract The Canvas Learning Management System (LMS) is used in thousands of universities across the United States and internationally, with a strong and growing presence in K-12 and higher education markets. Analyzing the development of the Canvas LMS, we examine 1) ‘frictionless’ data transitions that bridge K12, higher education, and workforce data 2) integration of third party applications and interoperability or data-sharing across platforms 3) privacy and security vulnerabilities, and 4) predictive analytics and dataveillance. We conclude that institutions of higher education are currently ill-equipped to protect students and faculty required to use the Canvas Instructure LMS from data harvesting or exploitation. We challenge inevitability narratives and call for greater public awareness concerning the use of predictive analytics, impacts of algorithmic bias, need for algorithmic transparency, and enactment of ethical and legal protections for users who are required to use such software platforms."
KEYWORDS: Data ethics, data privacy, predictive analytics, higher education, dataveillance
The above slide deck was shared on LinkedIn by Prof. Monett following a Public Lecture she gave at the University of Tartu, Estonia. The following is a link to her LinkedIn post and a direct link to the slidedeck can be found here.
CAGAYAN DE ORO, Philippines — In a coastal city in the southern Philippines, thousands of young workers log online every day to support the booming business of artificial intelligence.
In dingy internet cafes, jampacked office spaces or at home, they annotate the masses of data that American companies need to train their artificial intelligence models. The workers differentiate pedestrians from palm trees in videos used to develop the algorithms for automated driving; they label images so AI can generate representations of politicians and celebrities; they edit chunks of text to ensure language models like ChatGPT don’t churn out gibberish.
More than 2 million people in the Philippines perform this type of “crowdwork,” according to informal government estimates, as part of AI’s vast underbelly. While AI is often thought of as human-free machine learning, the technology actually relies on the labor-intensive efforts of a workforce spread across much of the Global South and often subject to exploitation.
The mathematical models underpinning AI tools get smarter by analyzing large data sets, which need to be accurate, precise and legible to be useful. Low-quality data yields low-quality AI. So click by click, a largely unregulated army of humans is transforming the raw data into AI feedstock.
In the Philippines, one of the world’s biggest destinations for outsourced digital work, former employees say that at least 10,000 of these workers do this labor on a platform called Remotasks, which is owned by the $7 billion San Francisco start-up Scale AI.
Scale AI has paid workers at extremely low rates, routinely delayed or withheld payments and provided few channels for workers to seek recourse, according to interviews with workers, internal company messages and payment records, and financial statements. Rights groups and labor researchers say Scale AI is among a number of American AI companies that have not abided by basic labor standards for their workers abroad.
Of 36 current and former freelance workers interviewed, all but two said they’ve had payments from the platform delayed, reduced or canceled after completing tasks. The workers, known as “taskers,” said they often earn far below the minimum wage — which in the Philippines ranges from $6 to $10 a day depending on region — though at times they do make more than the minimum.
Scale AI, which does work for firms like Meta, Microsoft and generative AI companies like Open AI, the creator of ChatGPT,says on its website that it is “proud to pay rates at a living wage.” In a statement, Anna Franko, a Scale AI spokesperson, said the pay system on Remotasks “is continually improving” based on worker feedback and that “delays or interruptions to payments are exceedingly rare.”
But on an internal messaging platform for Remotasks, which The Washington Post accessed in July, notices of late or missing payments from supervisors were commonplace. On some projects, there were multiple notices in a single month. Sometimes, supervisors told workers payments were withheld because work was inaccurate or late. Other times, supervisors gave no explanation. Attempts to track down lost payments often went nowhere, workers said — or worse, led to their accounts being deactivated.
Charisse, 23, said she spent four hours on a task that was meant to earn her $2, and Remotasks paid her 30 cents.
Jackie, 26, said he worked three days on a project that he thought would earn him $50, and he got $12.
Benz, 36, said he’d racked up more than $150 in payments when he was suddenly booted from the platform. He never got the money, he said.
Paul, 25, said he’s lost count of how much money he’s been owed over three years of working on Remotasks. Like other current Remotasks freelancers, Paul spoke on the condition of being identified only by first name to avoid being expelled from the platform. He started “tasking” full time in 2020 after graduating from university. He was once excited to help build AI, he said, but these days, he mostly feels embarrassed by how little he earns.
“The budget for all this, I know it’s big,” Paul said, staring into his hands at a coffee shop in Cagayan de Oro. “None of that is trickling down to us.”
Much of the ethical and regulatory debate over AI has focused so far on its propensity for bias and potential to go rogue or be abused, such as for disinformation.But companies producing AI technology are also charting a new frontier in labor exploitation, researchers say.
In enlisting people in the Global South as freelance contractors, micro-tasking platforms like Remotasks sidestep labor regulations — such as a minimum wage and a fair contract — in favor of terms and conditions they set independently, said Cheryll Soriano, a professor at De La Salle University in Manila who studies digital labor in the Philippines. “What it comes down to,” she said, “is a total absence of standards.”
Dominic Ligot, a Filipino AI ethicist, called these new workplaces “digital sweatshops.”
Overseas outposts
Founded in 2016 by young college dropouts and backed by some $600 million in venture capital, Scale AI has cast itself as a champion of American efforts in the race for AI supremacy. In addition to working with large technology companies, Scale AI has been awarded hundreds of millions of dollars to label data for the U.S. Department of Defense. To work on such sensitive, specialized data sets, the company has begun seeking out more contractors in the United States, though the vast majority of the workforce is still located in Asia, Africa and Latin America.... "
Me parece muy interesante este tipo de artículos porque muestra la cara menos amable de los avances en tecnología. Como se puede leer la explotación laboral en IA se manifiesta en condiciones de trabajo precarias para aquellos que están involucrados en la recopilación, etiquetado y procesamiento de datos necesarios para entrenar a los modelos de IA. Los trabajadores que realizan estas tareas a menudo enfrentan condiciones laborales desafiantes, largas jornadas de trabajo y salarios insuficientes. Además, la falta de regulaciones claras en esta área puede exacerbar la explotación y permitir prácticas laborales injustas.
The fall semester is well underway, and schools across the United States are rushing to implement artificial intelligence (AI) in ways that bring about equity, access, and efficiency for all members of the school community. Take, for instance, Los Angeles Unified School District’s (LAUSD) recent decision to implement “Ed.”
Ed is an AI chatbot meant to replace school advisors for students with Individual Education Plans (IEPs), who are disproportionately Black. Announced on the heels of a national uproar about teachers being unable to read IEPs due to lack of time, energy, and structural support, Ed might seem to many like a sliver of hope—the silver bullet needed to address the chronic mismanagement of IEPs and ongoing disenfranchisement of Black students in the district. But for Black students with IEPs, AI technologies like Ed might be more akin to a nightmare.
Since the pandemic, public schools have seen a proliferation of AI technologies that promise to remediate educational inequality for historically marginalized students. These technologies claim to predict behavior and academic performance, manage classroom engagement, detect and deter cheating, and proactively stop campus-based crimes before they happen. Unfortunately, because anti-Blackness is often baked into the design and implementation of these technologies, they often do more harm than good.
Proctorio, for example, is a popular remote proctoring platform that uses AI to detect perceived behavior abnormalities by test takers in real time. Because the platform employs facial detection systems that fail to recognize Black faces more than half of the time, Black students have an exceedingly hard time completing their exams without triggering the faulty detection systems, which results in locked exams, failing grades, and disciplinary action.
While being falsely flagged by Proctorio might induce test-taking anxiety or result in failed courses, the consequences for inadvertently triggering school safety technologies are much more devastating. Some of the most popular school safety platforms, like Gaggle and GoGaurdian, have been known to falsely identify discussions about LGBTQ+ identity, race related content, and language used by Black youth as dangerous or in violation of school disciplinary policies. Because many of these platforms are directly connected to law enforcement, students that are falsely identified are contacted by police both on campus and in their homes. Considering that Black youth endure the highest rates of discipline, assault, and carceral contact on school grounds and are six times more likely than their white peers to have fatal encounters with police, the risk of experiencing algorithmic bias can be life threatening.
These examples speak to the dangers of educational technologies designed specifically for safety, conduct, and discipline. But what about education technology (EdTech) intended for learning? Are the threats to student safety, privacy, and academic wellbeing the same?
Unfortunately, the use of educational technologies for purposes other than discipline seems to be the exception, not the rule. A national study examining the use of EdTech found an overall decrease in the use of the tools for teaching and learning, with over 60 percent of teachers reporting that the software is used to identify disciplinary infractions.
What’s more, Black students and students with IEPs endure significantly higher rates of discipline not only from being disproportionately surveilled by educational technologies, but also from using tools like ChatGPT to make their learning experience more accommodating and accessible. This could include using AI technologies to support executive functioning, access translated or simplified language, or provide alternative learning strategies.
"Many of these technologies are more likely to exacerbate educational inequities like racialized gaps in opportunity, school punishment, and surveillance."
To be sure, the stated goals and intentions of educational technologies are laudable, and speak to our collective hopes and dreams for the future of schools—places that are safe, engaging, and equitable for all students regardless of their background. But many of these technologies are more likely to exacerbate educational inequities like racialized gaps in opportunity, school punishment, and surveillance, dashing many of these idealistic hopes.
To confront the disparities wrought by racially-biased AI, schools need a comprehensive approach to EdTech that addresses the harms of algorithmic racism for vulnerable groups. There are several ways to do this.
One possibility is recognizing that EdTech is not neutral. Despite popular belief, educational technologies are not unbiased, objective, or race-neutral, and they do not inherently support the educational success of all students. Oftentimes, racism becomes encoded from the onset of the design process, and can manifest in the data set, the code, the decision making algorithms, and the system outputs.
Another option is fostering critical algorithmic literacy. Incorporating critical AI curriculum into K-12 coursework, offering professional development opportunities for educators, or hosting community events to raise awareness of algorithmic bias are just a few of the ways schools can support bringing students and staff up to speed.
A third avenue is conducting algorithmic equity audits. Each year, the United States spends nearly $13 billion on educational technologies, with the LAUSD spending upwards of $227 million on EdTech in the 2020-2021 academic year alone. To avoid a costly mistake, educational stakeholders can work with third-party auditors to identify biases in EdTech programs before launching them.
Regardless of the imagined future that Big Tech companies try to sell us, the current reality of EdTech for marginalized students is troubling and must be reckoned with. For LAUSD—the second largest district in the country and the home of the fourteenth largest school police force in California—the time to tackle the potential harms of AI systems like Ed the IEP Chatbot is now."
Certainly!! The potential threat of AI technology to educational equity for students raises concerns... It is crucial to consider how technological implementations may inadvertently exacerbate existing disparities, emphasizing the need for thoughtful, inclusive approaches in education technology to ensure equitable access and opportunities for all!!! :D
"Social Security numbers, medical records and other sensitive data about millions of students and educators nationwide were compromised after education technology behemoth PowerSchool became the target of a December 2024 cyberattack.
Cybersecurity and data privacy experts discuss what happened, who was affected — and the steps school districts must take to keep their communities safe.
Sponsored by the K12 Security Information eXchange and moderated by The 74's Mark Keierleber, the Jan. 15, 2025, webinar featured the following expert panelists:
• Doug Levin, Co-Founder and National Director, K12 Security Information eXchange (K12 SIX) • Wesley Lombardo, Technology Director, Maryville City Schools (TN) • Mark Racine, Co-Founder, RootED Solutions • Amelia Vance, President, Public Interest Privacy Center
"Microsoft CEO Satya Nadella, whose company has invested billions of dollars in ChatGPT maker OpenAI, has had it with the constant hype surrounding AI.
"Us self-claiming some [artificial general intelligence] milestone, that's just nonsensical benchmark hacking to me," Nadella told Patel.
Instead, the CEO argued that we should be looking at whether AI is generating real-world value instead of mindlessly running after fantastical ideas like AGI.
To Nadella, the proof is in the pudding. If AI actually has economic potential, he argued, it'll be clear when it starts generating measurable value.
"So, the first thing that we all have to do is, when we say this is like the Industrial Revolution, let's have that Industrial Revolution type of growth," he said.
"The real benchmark is: the world growing at 10 percent," he added. "Suddenly productivity goes up and the economy is growing at a faster rate. When that happens, we'll be fine as an industry."
Needless to say, we haven't seen anything like that yet. OpenAI's top AI agent — the tech that people like OpenAI CEO Sam Altman say is poised to upend the economy — still moves at a snail's pace and requires constant supervision.
So Nadella's line of thinking is surprisingly down-to-Earth. Besides pushing back against the hype surrounding artificial general intelligence — the realization of which OpenAI has made its number one priority — Nadella is admitting that generative AI simply hasn't generated much value so far.
As of right now, the economy isn't showing much sign of acceleration, and certainly not because of an army of AI agents. And whether it's truly a question of "when" — not "if," as he claims — remains a hotly debated subject.
There's a lot of money on the line, with tech companies including Microsoft and OpenAI pouring hundreds of billions of dollars into AI.
Chinese AI startup DeepSeek really tested the resolve of investors earlier this year by demonstrating that its cutting-edge reasoning model, dubbed R1, could keep up with the competition, but at a tiny fraction of the price. The company ended up punching a $1 trillion hole in the industry after triggering a massive selloff.
Then there are nagging technical shortcomings plaguing the current crop of AI tools, from constant "hallucinations" that make it an ill fit for any critical functions to cybersecurity concerns.
Nadella's podcast appearance could be seen as a way for Microsoft to temper some sky-high expectations, calling for a more rational, real-world approach to measure success.
At the same time, his actions tell a strikingly different story. Microsoft has invested $12 billion in OpenAI and has signed on to president Donald Trump's $500-billion Stargate project alongside OpenAI CEO Sam Altman.
After multi-hyphenate billionaire Elon Musk questioned whether Altman had secured the funds, Nadella appeared to stand entirely behind the initiative.
"All I know is I’m good for my $80 billion," he told CNBC last month in response to Musk's accusations."
Federal prosecutors have charged Joanna Smith-Griffin with defrauding investors out of nearly $10 million.
By Emma Kate Fittes
"After a sharp rise in the K-12 space, the artificial intelligence startup AllHere is ending the year with a bankruptcy case and its founder and former CEO under arrest.
Federal prosecutors have charged Joanna Smith-Griffin with defrauding investors out of nearly $10 million, according to an indictment unsealed in Manhattan federal court last week.
Smith-Griffin faces securities and wire fraud and aggravated identity theft charges for allegedly misleading investors, employees, and customers by inflating the company’s revenue, cash position, and customer base, the document says.
Prosecutors allege that Smith-Griffin went as far as to create a fake email address for a real AllHere financial consultant, allowing her to send false financial and client information to investors.
They also say Smith-Griffin claimed to have provided services to multiple districts that never had a contractual relationship with the company, which was a Harvard Innovation Lab venture.
AllHere’s most prominent — and legitimate — customer was the Los Angeles Unified Schools, which had a $6 million contract with AllHere to build an ambitious AI tool for the major district.
“The indictment and the allegations represent, if true, a disturbing and disappointing house of cards that deceived and victimized many across the country,” an LAUSD spokesperson told EdWeek Market Brief in an email. “We will continue to assert and protect our rights.”
LAUSD has since paused its use of the AI assistant, known as “Ed,” which was introduced in March as a “learning acceleration platform.” The tool belongs to LAUSD, the district said in a statement emailed to EdWeek Market Brief in June.
Smith-Griffin’s indictment comes two months after federal prosecutors became involved in AllHere’s ongoing bankruptcy case and subpoenaed documents. AllHere furloughed the majority of its staff in June and changed its leadership — an action which came to light days after LAUSD’s superintendent was touting its work with the company at a major education conference.
It filed for Chapter 7 bankruptcy in Delaware in August.
Since then, questions have swirled about the cause of the downfall, including a former employee who told The74 in July that he warned LAUSD that AllHere’s data privacy practices violated district policies against sharing students’ personally identifiable information and data-protection best practices.
Smith-Griffin’s indictment does not address those questions about data privacy.
The new indictment also accuses Smith-Griffin of using AllHere’s inflated success to raise her public profile. She was a Forbes 30 Under 30 award recipient and named to Time World’s top edtech companies list earlier this year.
To get content containing either thought or leadership enter:
To get content containing both thought and leadership enter:
To get content containing the expression thought leadership enter:
You can enter several keywords and you can refine them whenever you want. Our suggestion engine uses more signals but entering a few keywords here will rapidly give you great content to curate.



 Your new post is loading...
Your new post is loading...

![AI in Education: The Hype, the Harms, Policy Gaps, and "Solutions" Traps [Slidedeck] March 25, 2024 // PA Advisory Committee to the U.S. Commission on Civil Rights, panel hearings on Civil Rights a... | Educational Psychology, AI, & Emerging Technologies: Critical Thinking on Current Trends | Scoop.it](https://img.scoop.it/9i__1FWZ-HJUYY5jQ1H9UTl72eJkfbmt4t8yenImKBVvK0kTmF0xjctABnaLJIm9)


![The Big Business of Tracking and Profiling Students [Interview] // The Markup | Educational Psychology, AI, & Emerging Technologies: Critical Thinking on Current Trends | Scoop.it](https://img.scoop.it/LXt8POoqkwivJgoOaQibFjl72eJkfbmt4t8yenImKBVvK0kTmF0xjctABnaLJIm9)


![How Surveillance Capitalism Ate Education For Lunch // Marachi, 2022 // Univ. of Pittsburgh Data & Society Speaker Series Presentation [Slidedeck] | Educational Psychology, AI, & Emerging Technologies: Critical Thinking on Current Trends | Scoop.it](https://img.scoop.it/qSaRI2P7L42VLFB-dzF5ljl72eJkfbmt4t8yenImKBVvK0kTmF0xjctABnaLJIm9)


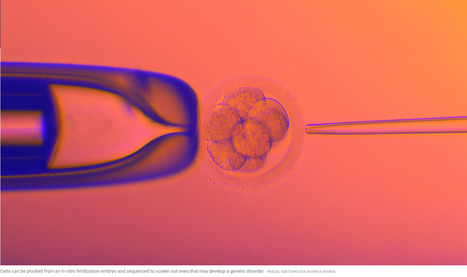









![AllHere [AI] Founder Faked Financial Consultant Emails, Defrauded Investors, Federal Prosecutors Allege // EdWeek | Educational Psychology, AI, & Emerging Technologies: Critical Thinking on Current Trends | Scoop.it](https://img.scoop.it/OUjxpSNC9LhzZesVTqg8Xzl72eJkfbmt4t8yenImKBVvK0kTmF0xjctABnaLJIm9)





{kind=link}