
Could robotic aortic valve replacement become a widespread alternative to SAVR or TAVI for the treatment of aortic valve disease?
Get Started for FREE
Sign up with Facebook Sign up with X
I don't have a Facebook or a X account



|
Scooped by
Gilbert C FAURE
onto ROBOTIC SURGERY December 11, 2024 8:07 AM
|
Could robotic aortic valve replacement become a widespread alternative to SAVR or TAVI for the treatment of aortic valve disease?


 Your new post is loading...
Your new post is loading... Your new post is loading...
Your new post is loading...
|
|
|
Scooped by
Gilbert C FAURE
January 1, 6:24 AM
|

Researchers are making strides to integrate new tools to help surgeons in the OR.
|
|
Scooped by
Gilbert C FAURE
January 1, 6:24 AM
|

Surgerii Robotics has raised funding to further develop and market its SHURUI single-port endoscopic robot in Europe and globally.
|
|
Scooped by
Gilbert C FAURE
January 1, 6:22 AM
|


The RCS England has issued new guidance urging NHS Trusts to strengthen training and tighten governance for surgeons performing robotic procedures...
|
|
Scooped by
Gilbert C FAURE
December 13, 2025 5:02 AM
|

Robotic surgery has developed into one of the most innovative advancements in modern medicine, providing a level of precision never before accessible in surgery, creating large benefits for the patients and physicians alike.
|
|
Scooped by
Gilbert C FAURE
December 5, 2025 5:13 AM
|

Big big industry news 🚨
Medtronic announces FDA clearance for HUGO RAS
This has been long anticipated and now sets Medtronic up as the biggest corporation to sell a competitive product against Intuitive
More to follow….
#surgicalrobotics | 20 comments on LinkedIn
|
|
Scooped by
Gilbert C FAURE
November 23, 2025 5:08 AM
|
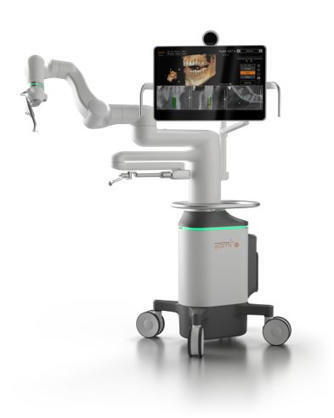
We were already the best (and only) robotic system in dental surgery in the country. But we're never satisfied. There's always room to make it better, faster, easier...
We're thrilled to announce the FDA clearance and launch of Yomi S, our next generation platform for robot assisted surgery.
Touchscreen. Voice recognition. Speech synthesis. Dexterity, visibility, flexibility of cart positioning. AI-enabled software planning. Drilling speed, torque, and irrigation all fully integrated and centralized into one UI. Safety control over the drill bit. Automated steps based on workflow context. And, of course, beautiful LEDs to indicate state and progress.
This isn't just cool technology for technology's sake. It's streamlining the workflow and reducing the burden of robotic adoption. Eliminating the need for extra hands. Automating. Simplifying.
I have never seen another robotic surgery system in any medical market that demonstrates this ease of use and can be operated entirely by one doctor.
Robotic surgery just leveled up.
I am so incredibly proud of this team at Neocis! | 71 comments on LinkedIn
|
|
Scooped by
Gilbert C FAURE
November 21, 2025 9:14 AM
|

Will Elon Musk's Tesla robot be able to perform surgery? What does this mean for patients? And, how are surgeons currently using robots in surgery?
|
|
Scooped by
Gilbert C FAURE
November 21, 2025 9:13 AM
|

Explore robotic innovations in healthcare delivery, enhancing surgeries, diagnostics, & patient care. Learn about the challenges & opportunities.
|
|
Scooped by
Gilbert C FAURE
November 15, 2025 9:26 AM
|
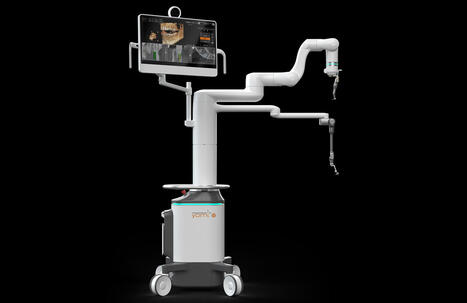
With AI-guided navigation through the implant planning, imaging and surgical process, Yomi S offers safer procedures.
|
|
Scooped by
Gilbert C FAURE
November 12, 2025 10:15 AM
|

Researchers at the University of Dundee have pioneered a new chapter in stroke treatment by successfully performing the first robotic transatlantic...
|
|
Scooped by
Gilbert C FAURE
October 31, 2025 8:41 AM
|

Have you heard about this new robot for spine surgery?
This is F1, a spine robot combining an optical vision system that eliminates the need for infrared markers with a 7 degrees-of-freedom collaborative robotic arm to improve pedicle screw placement.
The intervention plan is made on a CT then registered to the patient using C-arm images.
FoxEyes Corporation was founded in Texas last year by Min Seo (CEO) and Justin Yoon (CTO). FoxEyes collaborates with the Korea Medical Robot Center to advance R&D in medical robotics.
The team announced having completed their lab testing phase this week and working on their Series A financing round.
The roadmap includes developing another robot called F2 for supporting spine endoscopy procedures.
#medtech #roboticsurgery #spinesurgery
|
|
Scooped by
Gilbert C FAURE
October 11, 2025 9:38 AM
|
Companies creating new robotic platforms marked additional milestones heading into the fourth quarter. Catch up with their progress in this roundup of the latest developments in surgical robotics.
|
|
Scooped by
Gilbert C FAURE
January 7, 10:19 AM
|

A recent communication in the scientific community caught the attention of many researchers and medical professionals alike.The study, originally published in Scientific Reports, was centered around a groundbreaking approach to treat ureteral strictures—a medical condition where the ureters, the ...
|
|
Scooped by
Gilbert C FAURE
January 1, 6:24 AM
|
In gastrointestinal surgery, robotics has moved beyond being a technological advancement to becoming a preferred approach for precision-driven, minimally invasive care.
|
|
Scooped by
Gilbert C FAURE
January 1, 6:23 AM
|

AI-Driven Evaluation of Surgical Skill via Action Recognition Yan Meng1, Daniel Donoho1, Marcelle Altshuler2, Omar Arnaout2 ymeng@childrensnational.org Abstract Mastery of microanastomosis represents a fundamental competency in neurosurgery, where the ability to perform highly precise and coordinated movements under a microscope is directly correlated with surgical success and patient safety. These procedures demand not only fine motor skills but also sustained concentration, spatial awareness, and dexterous bimanual coordination. As such, the development of effective training and evaluation strategies is critical. Conventional methods for assessing surgical proficiency typically rely on expert supervision, either through onsite observation or retrospective analysis of recorded procedures. However, these approaches are inherently subjective, susceptible to inter-rater variability, and require substantial time and effort from expert surgeons. These demands are often impractical in low- and middle-income countries, thereby limiting the scalability and consistency of such methods across training programs. To address these limitations, we propose a novel AI-driven framework for the automated assessment of microanastomosis performance. The system integrates a video transformer architecture based on TimeSformer, improved with hierarchical temporal attention and weighted spatial attention mechanisms, to achieve accurate action recognition within surgical videos. Fine-grained motion features are then extracted using a YOLO-based object detection and tracking method, allowing for detailed analysis of instrument kinematics. Performance is evaluated along five aspects of microanastomosis skill, including overall action execution, motion quality during procedure-critical actions, and general instrument handling. Experimental validation using a dataset of 58 expert-annotated videos demonstrates the effectiveness of the system, achieving 87.7% frame-level accuracy in action segmentation that increased to 93.62% with post-processing, and an average classification accuracy of 76% in replicating expert assessments across all skill aspects. These findings highlight the system’s potential to provide objective, consistent, and interpretable feedback, thereby enabling more standardized, data-driven training and evaluation in surgical education. Introduction Accurate and consistent assessment of technical skill remains a longstanding challenge in surgical education. This is particularly evident in microsurgical procedures such as microanastomosis, where surgeons are required to manipulate submillimeter-scale vessels under high magnification. A typical end-to-side microanastomosis procedure involves cutting the donor vessel and suturing it to the recipient vessel using eight evenly spaced stitches positioned circumferentially around the arteriotomy site. The ability to segment and analyze such fine-grained actions is critical for skill acquisition, performance evaluation, and long-term quality assurance in both training and clinical practice. Traditional approaches for surgical skill assessment rely heavily on expert raters who manually review procedural videos using structured rubrics, such as the Objective Structured Assessment of Technical Skill (OSATS) (Martin et al. 1997), Global Rating Scales (GRS) (Regehr et al. 1998), and Neurosurgical Objective Microanastomosis Assessment Tool (NOMAT) (Aoun et al. 2015). While these methods are valuable, they are labor-intensive, inherently subjective, and difficult to scale. Recent advancements have attempted to address these limitations through the use of sensor data, motion tracking, or robotic kinematic analysis. However, these methods typically require specialized equipment and may lack interpretability, particularly when assessing discrete, task-specific gestures (Zia et al. 2016; Funke et al. 2019; Lavanchy et al. 2021; Meng and Hahn 2023). In parallel, the computer vision community has made substantial progress in video understanding, particularly in domains requiring fine temporal resolution and semantic interpretability. Transformer-based architectures, in particular, have emerged as a powerful class of models for sequential data, owing to their capacity to model long-range dependencies via self-attention mechanisms (Bertasius, Wang, and Torresani 2021; Mazzia et al. 2022; Wang et al. 2022; Yang et al. 2024). In the context of video analysis, these models have achieved state-of-the-art performance in action recognition. Their ability to incorporate temporal context makes them well-suited for analyzing surgical workflows, where actions may be subtle and semantically interdependent. To advance the field of automated surgical skill assessment, we propose a novel AI framework designed to perform interpretable, action-level evaluation of microanastomosis performance. Our system consists of three primary components: (1) a low-cost, self-guided microanastomosis training kit to facilitate self-paced practice and data collection; (2) a transformer-based video segmentation module to automatically identify pre-defined surgical actions; and (3) a YOLO-based instrument detection and tracking pipeline to extract motion features within each segmented action. By integrating spatial and temporal context, our approach enables the extraction of interpretable metrics such as action duration, repetition, and kinematic patterns aligned with specific surgical tasks. These features are subsequently used in a supervised learning framework to replicate expert NOMAT scoring and provide fine-grained, objective feedback. Beyond methodological contributions, this work has broader implications for global health and surgical education. According to the Lancet Commission on Global Surgery, an estimated 5 billion people lack access to safe and timely surgical care, with low- and middle-income countries (LMICs) disproportionately affected due to resource constraints and limited access to specialist training (Meara et al. 2015). In such contexts, scalable and interpretable assessment tools based on surgical video offer a cost-effective pathway to enhance skill acquisition, reduce variability in training, and expand access to high-quality surgical education. By democratizing technical feedback through automation, this research supports a more equitable and data-driven approach to global surgical capacity building. Our main contributions are summarized as follows: • We present an AI framework for automated, action-level skill assessment in microanastomosis procedures, offering interpretable and task-specific feedback. • We integrate transformer-based action segmentation with YOLO-based instrument detection and tracking to extract kinematic features aligned with surgical actions. • We demonstrate the feasibility of using supervised classification to replicate expert NOMAT scores at the coarse and fine action level. • We highlight the broader impact of our framework in addressing disparities in surgical training, particularly in resource-limited settings. Related Work Video-Based Surgical Skill Assessment. Traditional surgical assessment frameworks such as the OSATS, GRS, and NOMAT offer expert-based evaluations guidelines. However, human rating are subjective, time-intensive, and difficult to scale. To address these limitations, the automation of surgical skill assessment using video data has been explored across multiple studies, often combining spatial and temporal modeling with domain-specific metrics. Early work employed convolutional Neural Network (CNN ) and motion feature pipelines to classify surgeon expertise using videos, achieving high accuracy in binary scenario (Funke et al. 2019). Similarly, SATR‑DL(Wang and Fey 2018) performed end-to-end task and skill recognition using motion profile analysis gleaned from robot-assisted surgery data, achieving excellent accuracy in distinguishing expertise levels; and a JAMA Network Open study (Kitaguchi et al. 2021) generalize the 3D CNN-based spatiotemporal modeling across diverse intraoperative videos, attaining acceptable accuracy in categorizing surgical steps based on expert ratings. More recent systems integrate attention and auxiliary supervision. For instance, ViSA (Li et al. 2022) models heterogeneous semantic parts and aggregates them temporally to assess skill, enhancing interpretability and performance. A VBA‑Net framework(Yanik et al. 2023) provide both formative and summative skill assessment using attention heatmaps to highlight formative feedback. Other studies based on hand-crafted motion metrics such as path length, number of movements, instrument orientation extracted from bounding boxes have shown that video analysis yield statistically significant discrimination between skill levels in laparoscopic tasks(Goldbraikh et al. 2022; Hung et al. 2023). Temporal Action Segmentation. In recent years, there has been significant progress in temporal convolutional networks (TCNs) and transformer-based architectures for video understanding tasks, particularly in predicting action classes at fine temporal resolutions across video sequences. Temporal convolutional models, such as MS-TCN (Farha and Gall 2019) and TECNO (Czempiel et al. 2020), have been widely adopted for action segmentation. These models leverage successive convolutional stages to progressively refine per-frame action predictions while capturing hierarchical temporal context. Despite their effectiveness, TCNs can struggle to model long-range dependencies and may be less suitable for complex procedural tasks due to their limited receptive fields. Transformer-based architectures have demonstrated superior performance across various video understanding benchmarks. A notable early example is TimeSformer (Bertasius, Wang, and Torresani 2021), which introduced a factorized self-attention mechanism alternating between spatial and temporal dimensions. This architecture achieved state-of-the-art results on large-scale datasets of short videos such as Kinetics-400 and Kinetics-600, showcasing its strength in temporal modeling compared to conventional 3D convolutional networks. Building on this foundation, ASFormer (Yi, Wen, and Jiang 2021) improved temporal segmentation by incorporating explicit local connectivity priors, hierarchical representations to manage extended input sequences, and a decoder designed to refine coarse action predictions. ASFormer achieved strong performance on standard action segmentation benchmarks, particularly under limited data conditions. Similarly, ActionFormer (Zhang, Wu, and Li 2022) proposed an efficient transformer-based architecture for temporal action localization. By combining multi-scale feature representations, localized self-attention, and a lightweight decoding module, ActionFormer outperformed previous methods such as SlowFast and I3D. Hybrid approaches, such as ASTCFormer (Zhang et al. 2023), have further integrated TCNs with transformer layers to jointly capture local temporal continuity and global dependencies in surgical workflow recognition tasks. However, these increasingly complex architectures do not always translate into substantial performance gains. While several existing models address surgical skill assessment using video or kinematic data, few provide interpretable, action-level evaluations aligned with established scoring rubrics. Most approaches were validated only on short videos or lack fine-grained temporal segmentation. Moreover, the application of transformer-based temporal segmentation in surgical video analysis remains relatively underexplored. Positioned at this intersection, our work leverages and extends the TimeSformer architecture for frame-level segmentation of predefined surgical actions. Augmented with YOLO-based surgical instrument tip localization and tracking, our pipeline enables per-action kinematic analysis and alignment with expert rubrics. This facilitates interpretable, action-level skill classification and narrows the gap between the domain-specific demands of surgical education and the capabilities of state-of-the-art video understanding models. Methodology We propose a transformer-based framework for action-level assessment of microanastomosis skills. The framework comprises (i) a self-guided microanastomosis practice kit with an integrated data recording component; (ii) a transformer-based action segmentation module; (iii) a YOLO-based instrument kinematics feature extraction module; and (iv) a supervised skill classification module guided by the NOMAT rubric. An overview of the complete pipeline is presented in Fig. 1. Self-guided Microanastomosis Practice Kit The microanastomosis training toolkit used in this study is designed to provide a standardized and replicable environment for simulating small-caliber vascular procedures. Each setup includes a Meiji Techno EMZ-250TR trinocular zoom stereomicroscope, paired with a high-definition camera and external monitor to facilitate visual observation and high-quality data capture. Vascular tissues are simulated using 1.0mm ×\times 0.8mm microvascular practice cards from Pocket Suture, USA, designed to replicate the size and mechanical behavior of small-caliber vessels. A uniform set of microsurgical instruments is provided with each kit to ensure procedural consistency across users. The instrument set comprised one straight needle driver, one curved needle driver, and a pair of both straight and curved microsurgical scissors. The standard practice procedure involves performing a complete end-to-side microanastomosis. This begins with an incision along the donor vessel, followed by trimming its tip to enlarge the lumen. A longitudinal cut is then made on the recipient vessel to accommodate the donor vessel. Anastomosis is performed using eight evenly spaced sutures. The suturing sequence followed a standardized order: starting with the heel (posterior right junction), followed by the apex (anterior left junction), the midpoint of the front wall, and the left and right sides adjacent to it. The final three sutures were placed at the midpoint of the back wall and on both side of this midpoint. The overall procedure and suture pattern are illustrated in Fig. 2. Transformer-based Action Segmentation We developed a surgical action segmentation architecture building upon TimeSformer (Bertasius, Wang, and Torresani 2021) and Surgformer (Yang et al. 2024) to extract spatiotemporal features from surgical video sequences. The model is designed to capture both hierarchical temporal dependencies and spatial dynamics critical to surgical task understanding. It employs a spatiotemporal tokenization scheme that incorporates hierarchical temporal attention to model the temporal structure, alongside a spatial self-attention mechanism modulated by temporal variance to emphasize contextually informative regions. The overall architecture is illustrated in Fig. 3. Hierarchical Temporal Attention To model multi-scale temporal dependencies, we apply a hierarchical attention structure that combines global and local temporal attention. Given a sequence of TT RGB frames {I1,I2,…,IT}\{I_{1},I_{2},...,I_{T}\}, each frame It∈ℝH×W×CI_{t}\in\mathbb{R}^{H\times W\times C} at time tt is divided into non-overlapping patches of size P×PP\times P, producing K=H×W/P2K=H\times W/P^{2} patches per frame. Each patch is flattened and projected into a token vector using a learnable linear embedding layer. A special class token is appended to the token sequence. Learnable positional encodings are added to retain spatial and temporal order. The full sequence of tokens for the entire clip is thus: 𝐗={[CLS],x1,1,…,x1,K,…,xT,1,…,xT,K}𝐗∈ℝ(1+T⋅K)×d\begin{split}&\mathbf{X}=\{[CLS],x_{1,1},...,x_{1,K},...,x_{T,1},...,x_{T,K}\}\\ &\mathbf{X}\in\mathbb{R}^{(1+T\cdot K)\times d}\end{split} (1) Global Temporal Attention. For each spatial location ii, the token sequence {x1,i,x2,i,…,xT,i}\{x_{1,i},x_{2,i},...,x_{T,i}\} represents the temporal evolution of that location. We apply self-attention across time T to capture global temporal dynamics. This is done in parallel for all spatial positions: Attni=SelfAttention({x1,i,x2,i,…,xT,i})Attn_{i}=SelfAttention(\{x_{1,i},x_{2,i},...,x_{T,i}\}) (2) Local Temporal Attention. To refine features around the target frame, we apply local attention in short temporal windows, for example T/2T/2 and T/4T/4 of the target frame. This captures fine-grained motion and local temporal consistency. The outputs from global and local temporal attention block are aggregated to produce temporally contextualized tokens for each patch location. Variance-Weighted Spatial Self-Attention Following temporal modeling and layer normalization, a weighted self-attention mechanism is applied to enhance spatial feature representation. Instead of aggregating spatial tokens using uniform pooling or equal attention, we introduce a variance-guided spatial weighting mechanism that leverages temporal variability. Specifically, spatial tokens are reweighted prior to spatial self-attention based on the variance of their activations across time, assigning higher importance to locations that exhibit greater temporal dynamics. This reweighting modulates the input to the attention mechanism, indirectly emphasizing informative regions, while preserving standard spatial attention computation per frame. For each spatial position ii, we compute the temporal variance of its token representation across the sequence in Equation 3: μi=1T∑t=1Txt,i,σi2=1T∑t=1T‖xt,i−μi‖2\mu_{i}=\frac{1}{T}\sum_{t=1}^{T}x_{t,i},\quad\sigma_{i}^{2}=\frac{1}{T}\sum_{t=1}^{T}\left\|x_{t,i}-\mu_{i}\right\|^{2} (3) This variance is used to derive spatial importance weights, normalized across all spatial locations using a softmax function as in Equation 4. Each spatial token xi,ix_{i,i} is multiplied by its corresponding importance weight x~i,i=wi⋅xi,i\tilde{x}_{i,i}=w_{i}\cdot x_{i,i}. This reweighting is applied prior to spatial self-attention, allowing the attention mechanism to prioritize dynamic and informative regions during feature aggregation. wi=exp(σi2)∑jexp(σj2)w_{i}=\frac{\exp(\sigma_{i}^{2})}{\sum_{j}\exp(\sigma_{j}^{2})} (4) The features are subsequently passed through several sequentially stacked transformer blocks, followed by a feed-forward classification head consisting of LayerNorm, dropout, and a multi-layer perceptron (MLP) to generate the final action class predictions. Kinematic Feature Extraction To obtain precise motion profiles of surgical instruments during microanastomosis procedures, we implemented a robust object tracking pipeline that integrates object detection and multi-object tracking using You Only Look Once (YOLO) and Deep Simple Online and Realtime Tracking (DeepSORT), respectively (Redmon 2016; Wojke, Bewley, and Paulus 2017). While these methods demonstrate strong performance in various video understanding tasks, their application to microsurgical procedures introduces unique challenges. In microanastomosis scenes, instrument motions appear disproportionately large and abrupt due to the high magnification, in contrast to the smoother and more predictable movements observed in the unmagnified real world. This exaggerated motion effect necessitates targeted adaptations to maintain temporal consistency and enable precise localization of instrument tips across long and complex video sequences. Direct application of conventional methods to microsurgical scenarios introduces three recurring challenges: (1) visually similar instruments with only partially visible segments in the magnified field often lead to frequent class label switching in YOLO; (2) abrupt movements and frequent occlusions result in missed detections by YOLO; and (3) DeepSORT tends to produce imprecise or drifting bounding boxes, particularly during sudden instrument motions or partial occlusions. To address these issues and improve spatial-temporal coherence, we designed a dual identification guided detection correction mechanism. Detection refinement: When a high-confidence YOLO detection overlaps with a DeepSORT-predicted bounding box, we prioritize the detection result to refine the bouding box location and shape, correcting any drift introduced by the DeepSORT tracker. Class-label anchoring: Each object instance is associated with two parallel labels, a persistent object ID from DeepSORT and a class label from YOLO detection. we propagate the most recent correct label associated with the corresponding object ID, preventing cascading errors in YOLO classification. Reassignment of tracking identities: When the tracker assigns a new object ID due to temporary occlusion or loss of detection, we retrospectively align it with its prior ID based on class, time gap, and appearance similarity to restore continuity. This minimizes fragmentation in the tracking stream and supports consistent feature extraction across extended action segments. Following instrument tracking, instrument tip positions are extracted from the bounding boxes for subsequent motion analysis. Candidate keypoints are sampled along the convex hull of the instrument silhouette within each bounding box. Each candidate is then evaluated for tip likelihood using a predefined shape descriptor that encodes instrument geometric features. Cosine similarity in Equation 5 is computed between each candidate point and the reference shape descriptor to identify the most likely tip location. p^=argmaxi𝐝ref⋅𝐝i‖𝐝ref‖‖𝐝i‖\displaystyle\hat{p}=\arg\max_{i}\frac{\mathbf{d}_{\text{ref}}\cdot\mathbf{d}_{i}}{\|\mathbf{d}_{\text{ref}}\|\|\mathbf{d}_{i}\|} (5) where p^\hat{p} is the instrument tip; 𝐝ref∈ℝn\mathbf{d}_{\text{ref}}\in\mathbb{R}^{n} is the reference object descriptor vector; 𝐝i∈{ℝn}i=1N\mathbf{d}_{i}\in\{\mathbb{R}^{n}\}_{i=1}^{N} is a set of feature vectors from NN candidate points. The resulting tip coordinates are mapped from local bounding box space to global coordinates in the frame, yielding a temporally coherent trajectory for each instrument. These trajectories are subsequently used to derive kinematic features such as velocity, acceleration, jerk and relative motions between instruments, which are used for downstream skill assessment tasks. Microanastomosis Skill Classification To objectively evaluate technical proficiency in microanastomosis procedures, we implement a supervised classification framework that predicts surgeon skill levels based on interpretable performance metrics. Following the NOMAT rubric, we assess five key aspects of performance: (1) overall instrument handling, (2) needle driving motion quality, (3) knot tying motion quality, (4) needle driving action-level performance, and (5) knot tying action-level performance. Each is graded on a five-point Likert scale. The input features to the classification pipeline are extracted from two primary sources: instrument motion kinematics and action-level temporal statistics: • Kinematic features: To characterize overall instrument handling and the quality of action-specific motion, we extract velocity, acceleration, and jerk for each individual instrument. In addition, we compute relative motion features between instruments, including inter-instrument distance, relative speed, and angular displacement. • Action statistics: For critical actions, we include temporal features including the duration of each action instance, the number of repetitions, and the cumulative time spent performing each action type. These metrics capture both efficiency and consistency in task execution. We employ the Gradient Boosting Classifier (GBC) for supervised skill classification due to its effectiveness in modeling non-linear decision boundaries, robustness to class imbalance, and its resistance to overfitting on small datasets (Konstantinov and Utkin 2021). Experiments A comprehensive experimental study was conducted to assess the performance of the proposed AI-driven surgical skill evaluation framework. All procedures related to data acquisition and study implementation were reviewed and approved by the Institutional Review Board of the collaborating institution, ensuring adherence to established ethical guidelines for research involving human participants. Data Collection Nine medical practitioners (8 male, 1 female; mean age: 30.5 years) participated in this study, encompassing a wide range of microsurgical experience levels, from novice trainees to experienced neurosurgeons. All participants were predominantly right-handed, with one identifying as ambidextrous. Each session adhered to a standardized protocol as described in the method section, consisting of three vessel transections followed by eight sequential suture placements, allowing for consistent procedural structure and comparative analysis across recordings.We define six distinct and meaningful microanastomosis actions, while all remaining segments, either lacking specific actions or containing empty frames, are grouped under the label “No”. A detailed description of the action categories is provided in Table 1. Each participant completed between five and ten microanastomosis procedures under controlled laboratory conditions, yielding a total of 63 video recordings. Among these, 58 recordings captured the full procedure, with an average duration of approximately 26 minutes; the remaining five were either with wrong magnification or truncated due to technical issues or early termination. All skill metrics in each video were independently assessed by two board-certified neurosurgeons using the NOMAT rubric. The evaluation results were reconciled through consensus vote. Technical performance was rated on a five-point Likert scale, where higher scores indicated greater proficiency. Due to the limited dataset size and class imbalance in the expert ratings, the original scores were discretized into three ordinal skill categories: Poor, Moderate, and Good, using thresholds at 2.5 and 3.5. Action Segmentation Performance Model Training. A total of 20 microanastomosis videos were manually annotated to train the transformer-based action segmentation model, with 15 videos used for training, 3 for validation, and 2 reserved for testing. The trained model was subsequently applied to segment surgical actions in the remaining 38 videos. All 58 videos were then utilized for downstream skill assessment. The action segmentation model weights were initialized using parameters pretrained on the Kinetics dataset via TimeSformer (Kay et al. 2017), while all task-specific layers were randomly initialized. Training was conducted for 50 epochs with a batch size of 16, using 4 NVIDIA T4 Tensor Core GPUs. Input videos were downsampled to 10fps and a temporal window of T=16T=16 frames for spatiotemporal tokenization and global temporal feature extraction. A multi-scale temporal representation was employed using three levels of detail (TT, T/2T/2, and T/4T/4), combined with equal weighted averaging to enhance temporal features. The model was optimized using the AdamW optimizer with a learning rate of 9×10−59\times 10^{-5} and a layer-wise learning rate decay factor of 0.75. Performance Metrics. To evaluate action segmentation performance, we employ five widely-used benchmark metrics across both frame-level and action-level granularity. At the frame level, we report classification accuracy to assess the prediction result across videos. At the action level, we compute precision, recall, Jaccard index, and F1 score to quantify the correctness, completeness, and overall quality of predicted action segments relative to the ground truth. These metrics collectively provide a comprehensive assessment in the action segmentation results. Action Segmentation Results. The performance metrics of the proposed surgical transformer model are presented in Table 1. To further enhance segmentation quality, we apply a temporal smoothing strategy that filters out predicted action segments shorter than five frames, and incorporate an action dictionary-based post-processing step to correct common misclassifications. These refinements result in improved segmentation consistency temporally and semantically. We also compare its overall performance with two baseline method: MS-TCN and Surgformer. The results demonstrate that our transformer-based model without post-processing, outperforms MS-TCN and Surgformer by 11% and 6% in accuracy, respectively. When post-processing is applied, the accuracy improvement increases to 19% over MS-TCN and 13% over Surgformer. A qualitative comparison of action segmentation results from each method, along with ground truth annotations, is illustrated in Fig. 4. Microanastomosis Skill Assessment Results Action segmentation prediction was performed on the remaining 38 videos in the dataset. Video-level and action-level motion features were then extracted using the YOLO-based instrument tip localization method, the tracking result is illustrated in Fig. 5. These features served as input to supervised Gradient Boosting Classifiers, trained to replicate expert grading based on annotated score labels by experienced raters. The dataset was divided into 80% for training and 20% for testing. Within the training set, five-fold cross-validation was employed, wherein the model was iteratively trained on four folds and validated on the fifth to promote generalization and reduce overfitting. The model achieved an accuracy of 84.8% for overall instrument handling, 63.4% for knot tying motion performance, and 73.8% for needle handling motion. For microsurgical action efficiency, the model attained 74.0% accuracy in needle handling actions and 84.0% in knot tying action. The average accuracy across all evaluated metrics was 76.0%. The resulting classification performance for each skill level is summarized in Table 2. Given the limited dataset size and the involvement of only two expert raters for labeling, the resulting annotations may be subject to bias and limited objectivity. We anticipate that the performance of the machine learning classification model can be further improved through the inclusion of a larger dataset and a more diverse panel of surgeon raters in future work. Conclusion In this study, we introduce a novel framework for automated, action-level assessment of surgical proficiency in microanastomosis procedures, combining transformer-based video segmentation with kinematic analysis and interpretable performance metrics. By leveraging the capabilities of transformer architectures for fine-grained temporal segmentation, our approach enables precise identification of microsurgical gestures directly from operative video. This facilitates detailed, objective, and clinically meaningful evaluation of technical performance. Unlike prior approaches that focus primarily on recognizing what actions were performed, our method emphasizes how well each action was executed, aligning closely with structured NOMAT rubric. The system delivers consistent, granular feedback, offering a scalable and interpretable alternative to conventional assessment methods. More importantly, the broader impact of this work lies in its accessibility and relevance to low- and middle-income countries, where barriers such as limited faculty availability, scarce simulation resources, and high training burdens continue to challenge surgical education. By enabling cost-effective, video-based assessment using online cloud service, our framework supports equitable access to surgical skill development and high-quality feedback. This contributes to the global effort to enhance surgical training outcomes and improve the safety and quality of care in underserved settings. References Aoun et al. (2015) Aoun, S. G.; El Ahmadieh, T. Y.; El Tecle, N. E.; Daou, M. R.; Adel, J. G.; Park, C. S.; Batjer, H. H.; and Bendok, B. R. 2015. A pilot study to assess the construct and face validity of the Northwestern Objective Microanastomosis Assessment Tool. Journal of neurosurgery, 123(1): 103–109. Bertasius, Wang, and Torresani (2021) Bertasius, G.; Wang, H.; and Torresani, L. 2021. Is space-time attention all you need for video understanding? In ICML, volume 2, 4. Czempiel et al. (2020) Czempiel, T.; Paschali, M.; Keicher, M.; Simson, W.; Feussner, H.; Kim, S. T.; and Navab, N. 2020. Tecno: Surgical phase recognition with multi-stage temporal convolutional networks. In Medical Image Computing and Computer Assisted Intervention–MICCAI 2020: 23rd International Conference, Lima, Peru, October 4–8, 2020, Proceedings, Part III 23, 343–352. Springer. Farha and Gall (2019) Farha, Y. A.; and Gall, J. 2019. Ms-tcn: Multi-stage temporal convolutional network for action segmentation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 3575–3584. Funke et al. (2019) Funke, I.; Mees, S. T.; Weitz, J.; and Speidel, S. 2019. Video-based surgical skill assessment using 3D convolutional neural networks. International journal of computer assisted radiology and surgery, 14: 1217–1225. Goldbraikh et al. (2022) Goldbraikh, A.; D’Angelo, A.-L.; Pugh, C. M.; and Laufer, S. 2022. Video-based fully automatic assessment of open surgery suturing skills. International Journal of Computer Assisted Radiology and Surgery, 17(3): 437–448. Hung et al. (2023) Hung, A. J.; Bao, R.; Sunmola, I. O.; Huang, D.-A.; Nguyen, J. H.; and Anandkumar, A. 2023. Capturing fine-grained details for video-based automation of suturing skills assessment. International journal of computer assisted radiology and surgery, 18(3): 545–552. Kay et al. (2017) Kay, W.; Carreira, J.; Simonyan, K.; Zhang, B.; Hillier, C.; Vijayanarasimhan, S.; Viola, F.; Green, T.; Back, T.; Natsev, P.; et al. 2017. The kinetics human action video dataset. arXiv preprint arXiv:1705.06950. Kitaguchi et al. (2021) Kitaguchi, D.; Takeshita, N.; Matsuzaki, H.; Igaki, T.; Hasegawa, H.; and Ito, M. 2021. Development and validation of a 3-dimensional convolutional neural network for automatic surgical skill assessment based on spatiotemporal video analysis. JAMA network open, 4(8): e2120786–e2120786. Konstantinov and Utkin (2021) Konstantinov, A. V.; and Utkin, L. V. 2021. Interpretable machine learning with an ensemble of gradient boosting machines. Knowledge-Based Systems, 222: 106993. Lavanchy et al. (2021) Lavanchy, J. L.; Zindel, J.; Kirtac, K.; Twick, I.; Hosgor, E.; Candinas, D.; and Beldi, G. 2021. Automation of surgical skill assessment using a three-stage machine learning algorithm. Scientific reports, 11(1): 5197. Li et al. (2022) Li, Z.; Gu, L.; Wang, W.; Nakamura, R.; and Sato, Y. 2022. Surgical skill assessment via video semantic aggregation. In International Conference on Medical Image Computing and Computer-Assisted Intervention, 410–420. Springer. Martin et al. (1997) Martin, J.; Regehr, G.; Reznick, R.; Macrae, H.; Murnaghan, J.; Hutchison, C.; and Brown, M. 1997. Objective structured assessment of technical skill (OSATS) for surgical residents. British journal of surgery, 84(2): 273–278. Mazzia et al. (2022) Mazzia, V.; Angarano, S.; Salvetti, F.; Angelini, F.; and Chiaberge, M. 2022. Action transformer: A self-attention model for short-time pose-based human action recognition. Pattern Recognition, 124: 108487. Meara et al. (2015) Meara, J. G.; Leather, A. J.; Hagander, L.; Alkire, B. C.; Alonso, N.; Ameh, E. A.; Bickler, S. W.; Conteh, L.; Dare, A. J.; Davies, J.; et al. 2015. Global Surgery 2030: evidence and solutions for achieving health, welfare, and economic development. The lancet, 386(9993): 569–624. Meng and Hahn (2023) Meng, Y.; and Hahn, J. K. 2023. An Automatic Grading System for Neonatal Endotracheal Intubation with Multi-Task Convolutional Neural Network. In 2023 IEEE EMBS International Conference on Biomedical and Health Informatics (BHI), 1–4. IEEE. Redmon (2016) Redmon, J. 2016. You only look once: Unified, real-time object detection. In Proceedings of the IEEE conference on computer vision and pattern recognition. Regehr et al. (1998) Regehr, G.; MacRae, H.; Reznick, R. K.; and Szalay, D. 1998. Comparing the psychometric properties of checklists and global rating scales for assessing performance on an OSCE-format examination. Academic Medicine, 73(9): 993–7. Wang et al. (2022) Wang, J.; Yang, X.; Li, H.; Liu, L.; Wu, Z.; and Jiang, Y.-G. 2022. Efficient video transformers with spatial-temporal token selection. In European Conference on Computer Vision, 69–86. Springer. Wang and Fey (2018) Wang, Z.; and Fey, A. M. 2018. SATR-DL: improving surgical skill assessment and task recognition in robot-assisted surgery with deep neural networks. In 2018 40th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), 1793–1796. IEEE. Wojke, Bewley, and Paulus (2017) Wojke, N.; Bewley, A.; and Paulus, D. 2017. Simple online and realtime tracking with a deep association metric. In 2017 IEEE international conference on image processing (ICIP), 3645–3649. IEEE. Yang et al. (2024) Yang, S.; Luo, L.; Wang, Q.; and Chen, H. 2024. Surgformer: Surgical transformer with hierarchical temporal attention for surgical phase recognition. In International Conference on Medical Image Computing and Computer-Assisted Intervention, 606–616. Springer. Yanik et al. (2023) Yanik, E.; Kruger, U.; Intes, X.; Rahul, R.; and De, S. 2023. Video-based formative and summative assessment of surgical tasks using deep learning. Scientific Reports, 13(1): 1038. Yi, Wen, and Jiang (2021) Yi, F.; Wen, H.; and Jiang, T. 2021. Asformer: Transformer for action segmentation. arXiv preprint arXiv:2110.08568. Zhang et al. (2023) Zhang, B.; Goel, B.; Sarhan, M. H.; Goel, V. K.; Abukhalil, R.; Kalesan, B.; Stottler, N.; and Petculescu, S. 2023. Surgical workflow recognition with temporal convolution and transformer for action segmentation. International Journal of Computer Assisted Radiology and Surgery, 18(4): 785–794. Zhang, Wu, and Li (2022) Zhang, C.-L.; Wu, J.; and Li, Y. 2022. Actionformer: Localizing moments of actions with transformers. In European Conference on Computer Vision, 492–510. Springer. Zia et al. (2016) Zia, A.; Sharma, Y.; Bettadapura, V.; Sarin, E. L.; Ploetz, T.; Clements, M. A.; and Essa, I. 2016. Automated video-based assessment of surgical skills for training and evaluation in medical schools. International journal of computer assisted radiology and surgery, 11: 1623–1636.
|
|
Scooped by
Gilbert C FAURE
December 30, 2025 1:26 PM
|

From new cancer drugs to Alzheimer’s rejections, 2025 highlighted how value assessments shaped NHS access.
|
|
Scooped by
Gilbert C FAURE
December 13, 2025 5:02 AM
|
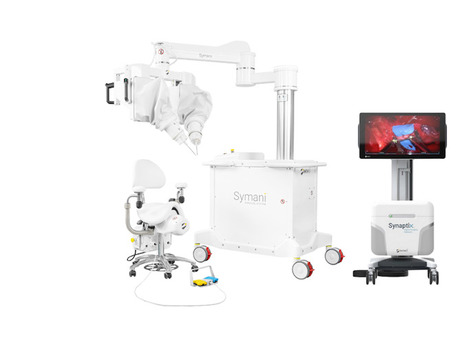
Medical Microinstruments has received FDA 510(k) clearance for its NanoWrist Scissors and Forceps, enabling robotic-assisted soft tissue dissection with the Symani Surgical System. Tampa General Hospital has now completed the world’s first fully robotic lymphovenous bypass using the newly cleared...
|
|
Scooped by
Gilbert C FAURE
December 2, 2025 5:00 AM
|

Mr Vanash Patel discusses real-world outcomes, learning curves and operational strategies in robotic surgery for colorectal cancer.
|
|
Scooped by
Gilbert C FAURE
November 21, 2025 9:15 AM
|

Value-based care has become one of the most pressing challenges, and opportunities, in orthopedic and spine surgery. Rising costs, increasing case complexity and shifting expectations from patients and payers are forcing health systems to rethink how they deliver care long before a patient enters...
|
|
Scooped by
Gilbert C FAURE
November 21, 2025 9:14 AM
|

Distalmotion has closed a $150 million Series G funding round to accelerate US adoption of its Dexter robotic surgery system, focusing on the Ambulatory Surgery Center market and continued clinical and product development.
|
|
Scooped by
Gilbert C FAURE
November 15, 2025 9:26 AM
|
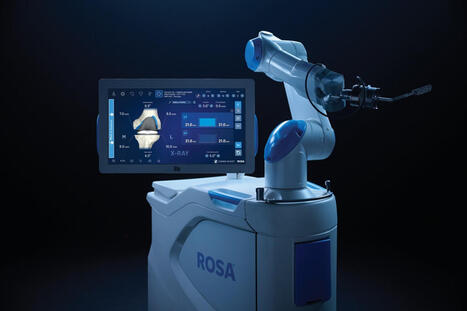
/PRNewswire/ -- Zimmer Biomet Holdings, Inc. (NYSE and SIX: ZBH), a global medical technology leader, today announced U.S. Food and Drug Administration (FDA)...
|
|
Scooped by
Gilbert C FAURE
November 12, 2025 10:16 AM
|

Featuring prominently in NeuroNews’ latest top 10 are a number of stories relating to the real-world implementation of mechanical thrombectomy treatments—including a new study emphasising the impact of procedural duration relative to prehospital delays, an industry update demonstrating the ability...
|
|
Scooped by
Gilbert C FAURE
November 10, 2025 5:02 AM
|

Toumai® Surgical Robot Fluorescence Imaging System Receives EU CE Certification
The DFVision™ 3D Fluorescence Electronic Endoscope, the component of the Toumai® Surgical robot vision system, has received CE certification. Designed for complex, high-difficulty procedures across all surgical specialties, it provides surgeons with enhanced precision and clarity, ensuring patient safety.
With its multi-modal fluorescence function, the system allows real-time switching between eight different fluorescence display colors. Surgeons can clearly visualize blood flow and tissue perfusion as needed, enabling more precise tumor resections and reducing the risk of residual cancerous tissue. It also assists in accurately identifying and removing metastatic lymph nodes, significantly improving outcomes in highly precise oncologic surgeries.
Besides it, the Toumai® fluorescence imaging system leverages advanced optical performance and intelligent image fusion algorithms to meet the demands of multidisciplinary clinical applications:
🔹 High-Sensitivity Fluorescence Detection — Clearly visualizes vascular structures and tissue perfusion.
🔹 Advanced Filtering and Artifact Suppression — Ensures a clean and realistic surgical field.
🔹 Pixel-Level Alignment of White and Fluorescence Light — Seamless switching for smooth, natural operation.
🔹 Dynamic Fusion Gain Algorithm — Enhances intraoperative localization and navigation accuracy.
To date, the Toumai® Surgical Robot has obtained market access in over 60 countries and regions, with more than 100 systems installed across 40+ countries. Globally, it has been used in over 15,000 surgical procedures, including nearly 700 telesurgeries, achieving close to 60 global “firsts.” It is currently the only surgical robot system worldwide compatible with 5G, high-/low-orbit satellites, and broadband networks, with approvals in multiple countries.
🌍 MicroPort® MedBot™ continues to drive the intelligent and precise evolution of global surgery, providing surgeons with enhanced operational intelligence and precision, and delivering safer, higher-quality care for patients worldwide.
#Toumai #DFVision #MedBot #MicroPort #SurgicalRobot #FluorescenceImaging #CECertification #SurgicalInnovation #MedTech #MadeInChina
|
|
Scooped by
Gilbert C FAURE
October 11, 2025 9:39 AM
|
By VisionMed Collaboration to advance TROGSS programs in training, education, and research CHICAGO, IL, UNITED STATES, October 10, 2025 /EINPresswire.com/ — VisionMed, a leader in AI video analysis and documentation technology, and TROGSS – The Robotic Global Surgery Society announced a landmark partnership to collaborate on advancing education, training, and research in robotic surgery. The announcement was made to coincide with the American College of Surgeons Clinical Congress 2025 in Chicago, underscoring the growing global emphasis on integrating AI and advanced documentation into surgical training and practice. Through this partnership, VisionMed’s EMMA™ AI platform will be integrated into TROGSS’ programs to support physician training, continuing medical education (CME), and scientific exchange. VisionMed will provide demonstrations, training licenses, and technical support for TROGSS’ educational activities, while ensuring compliance with CME and nonprofit standards. As part of the agreement, VisionMed will sponsor the TROGSS Intercontinental Congress in Luxembourg in July 2026 and support initiatives such as the Traveling Scholar Awards. EMMA™ will also contribute to simulation-based and dry lab training within the CARS (Competency-Based Assessment of Robotic Surgery Skills) Curriculum for the TROGSS Intercontinental Training Program (ITP). Both organizations will collaborate on research and publications highlighting the role of AI video analysis in surgical education, documentation, and quality improvement. “This partnership reflects our ongoing commitment to advancing surgical education through innovation with advanced technology at the service of medicine and humanity, and a patient-centered approach in all of our endeavors together,” said Prof. Rodolfo J. Oviedo, MD, FACS, FRCS, FICS, FASMBS, DABS-FPDMBS, who serves as CEO of TROGSS. “By incorporating VisionMed’s AI technology into our educational and research programs, we are equipping our worldwide members and surgical community with cutting-edge tools that enhance training and documentation. We are truly honored and privileged at TROGSS to have VisionMed as a distinguished industry partner. We have the deepest admiration and respect for what they do and who they are.” “VisionMed is honored to partner with TROGSS, an organization doing exceptional work to expand access to training and advance the global standard of robotic surgery,” said David MacLean, CEO of VisionMed. “By supporting their initiatives, we aim to complement TROGSS’ mission with AI-driven tools that enhance education, documentation, and efficiency for surgeons worldwide.” About VisionMedVisionMed is an AI video analysis company specializing in surgical documentation and workflow support. Its EMMA™ platform converts surgical video into organized, time-stamped records and efficiency insights, helping hospitals, educators, and surgeons improve training, reporting, and operational performance. About TROGSSTROGSS – The Robotic Global Surgery Society (https://trogss.org) is an international nonprofit professional surgical society dedicated to advancing robotic surgery through education, training, research, and collaboration. With members spanning multiple specialties and most continents, TROGSS leads initiatives such as the Intercontinental Training Program (ITP), global congresses, and multicenter research studies to promote innovation, skill development, and equitable access to robotic surgery worldwide. With the motto “Advancing Robotic Surgery and Education, for Our Patients, by Our Surgeons,” its mission and reason to exist is #surgicaleducationforall. Media ContactsVisionMed: Dave@Visionmed.usTROGSS: trogssofficial@gmail.com David MacLeanVisionMedDave@visionmed.us Legal Disclaimer: EIN Presswire provides this news content “as is” without warranty of any kind. We do not accept any responsibility or liability for the accuracy, content, images, videos, licenses, completeness, legality, or reliability of the information contained in this article. If you have any complaints or copyright issues related to this article, kindly contact the author above.
|
|
Scooped by
Gilbert C FAURE
October 10, 2025 4:49 AM
|
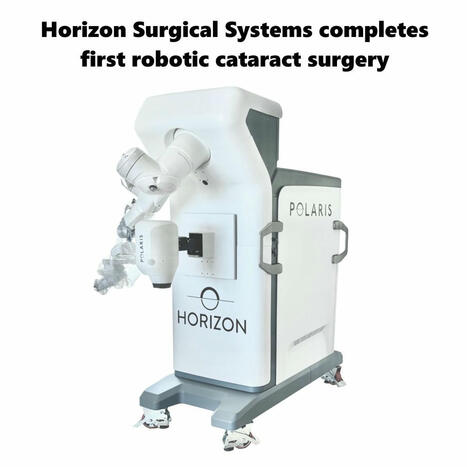
California-based startup Horizon Surgical Systems announced having completed the world's first cataract surgery using their Polaris robot.
Cataract surgery is a high-volume procedure in ophthalmology - over 5 million patients get this treatment every year in the US alone - and highly repetitive, thus suited for robotic surgery.
The microsurgical robot provides dexterity and steadiness allowing surgeons to operate with tool-tip precision at a scale beyond human capability.
The software merges real-time imaging with advanced machine learning. Over 500,000 images have been used to train the AI models.
"The system will bring an unmatched detection of the ocular anatomical structures. For instance, the surgeon will be able to properly visualize the posterior capsule, which is barely visible through a normal optical or digital microscope. All the safe boundaries of the surgical workspace will be identified more precisely and accurately" - explained Dr. Hubschman in Ophthalmology Management.
More patients will be treated with the robot in the coming months to gather clinical evidences for securing FDA clearance.
Read the full press release:
https://lnkd.in/e6ggzj_g
#medtech #roboticsurgery #ophthalmology #cataractsurgery





