Your new post is loading...
Your new post is loading...
|
Scooped by
Complexity Digest
February 1, 5:52 PM
|
Joshua Garland, Joe Bak-Coleman, Susan Benesch, Simon DeDeo, Renee DiResta, Jan Eissfeldt, Seungwoong Ha, John Irons, Chris Kempes, Juniper Lovato, Kristy Roschke, Paul E. Smaldino, Anna B. Stephenson, Thalia Wheatley & Valentina Semenova npj Complexity volume 3, Article number: 5 (2026) Social media platforms frequently prioritize efficiency to maximize ad revenue and user engagement, often sacrificing deliberation, trust, and reflective, purposeful cognitive engagement in the process. This manuscript examines the potential of friction—design choices that intentionally slow user interactions—as an alternate approach. We present a case against efficiency as the dominant paradigm on social media and advocate for a complex systems approach to understanding and analyzing friction. Drawing from interdisciplinary literature, real-world examples, and industry experiments, we highlight the potential for friction to mitigate issues like polarization, disinformation, and toxic content without resorting to censorship. We propose a state space representation of friction to establish a multidimensional framework and language for analyzing the diverse forms and functions through which friction can be implemented. Additionally, we propose several experimental designs to examine the impact of friction on system dynamics, user behavior, and information ecosystems, each designed with complex systems solutions and perspectives in mind. Our case against efficiency underscores the critical role of friction in shaping digital spaces, challenging the relentless pursuit of efficiency and exploring the potential of thoughtful slowing. Read the full article at: www.nature.com
|
|
Scooped by
Complexity Digest
January 31, 10:54 PM
|
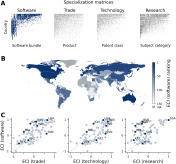
Sándor Juhász, Johannes Wachs, Jermain Kaminski, César A. Hidalgo Research Policy Volume 55, Issue 3, April 2026, 105422 Despite the growing importance of the digital sector, research on economic complexity and its implications continues to rely mostly on administrative records—e.g. data on exports, patents, and employment—that have blind spots when it comes to the digital economy. In this paper we use data on the geography of programming languages used in open-source software to extend economic complexity ideas to the digital economy. We estimate a country's software economic complexity index (ECIsoftware) and show that it complements the ability of measures of complexity based on trade, patents, and research to account for international differences in GDP per capita, income inequality, and emissions. We also show that open-source software follows the principle of relatedness, meaning that a country's entries and exits in programming languages are partly explained by its current pattern of specialization. Together, these findings help extend economic complexity ideas and their policy implications to the digital economy. Read the full article at: www.sciencedirect.com
|
|
Scooped by
Complexity Digest
January 28, 2:29 PM
|
Marco A. Rosas Pulido, Roberto Murcio, Omar R. Vázquez, Carlos Gershenson
Intricate interactions among firms, institutions, and spatial structures shape urban economic systems. In this study, we propose a framework based on three structural dimensions -- abundance, diversity, and longevity (ADL) of economic units -- as proxies of urban economic complexity and resilience. Using a decade of georeferenced firm-level data from Mexico City, we analyze the relationships among ADL variables using regression, spatial correlation, and time-series clustering. Our results reveal nonlinear dynamics across urban space, with powerlaw behavior in central zones and logarithmic saturation in peripheral areas, suggesting differentiated growth regimes. Notably, firm longevity modulates the relationship between abundance and diversity, particularly in periurban transition zones. These spatial patterns point to an emerging polycentric restructuring within a traditionally monocentric metropolis. By integrating economic complexity theory with spatial analysis, our approach provides a scalable method to assess the adaptive capacity of urban economies. This has implications for understanding informality, designing inclusive urban policies, and navigating structural transitions in rapidly urbanizing regions. Read the full article at: arxiv.org
|
|
Scooped by
Complexity Digest
January 25, 7:04 AM
|
Nick Holton, Marianne Cottin, Adam Wright, Michael Mannino, Dayanne S. Antonio, Marcelo Bigliassi Antifragility challenges conventional thinking by proposing that adversity is not merely to be survived but actively used to promote growth. This scoping review synthesizes 18 emerging research studies focused on antifragility in human systems across disciplines, distinguishing antifragility from resilience and robustness and highlighting key empirical gaps, particularly in psychological research. During the screening process, articles were categorized as human or non-human systems. Non-human systems (n = 29; e.g., robotics, logistics, information systems, urban planning, artificial intelligence) were excluded from synthesis to align with the review’s focus on human domains (e.g., psychology, leadership, coaching, health). Drawing from biology, psychology, and organizational studies, the review summarizes applications in mental health, performance, and quality of life. Findings emphasize the proactive nature of antifragility, in which stressors are intentionally engaged to strengthen capabilities. Biological concepts like hormesis and psychological frameworks such as post-traumatic growth align with mechanisms relevant to growth through adversity. Yet empirical studies remain scarce, underscoring the need for robust measurement tools and longitudinal designs. Future directions include refining antifragility as a state, trait, or process, developing dose-specific models, and exploring biopsychosocial correlates. Embracing antifragility could transform how individuals and systems confront challenge, not by resisting breakdown, but by evolving beyond it. Read the full article at: journals.sagepub.com
|
|
Scooped by
Complexity Digest
January 24, 11:52 AM
|
Giulia Fischetti, Anna Mancini, Giulio Cimini, Jessica T. Davis, Abby Leung, Alessandro Vespignani, Guido Caldarelli
Accurate representations of the World Air Transportation Network (WAN) are fundamental inputs to models of global mobility, epidemic risk, and infrastructure planning. However, high-resolution, real-time data on the WAN are largely commercial and proprietary, therefore often inaccessible to the research community. Here we introduce a generative model of the WAN that treats air travel as a stochastic process within a maximum-entropy framework. The model uses airport-level passenger flows to probabilistically generate connections while preserving traffic volumes across geographic regions. The resulting reconstructed networks reproduce key structural properties of the WAN and enable simulations of dynamic spreading that closely match those obtained using the real network. Our approach provides a scalable, interpretable, and computationally efficient framework for forecasting and policy design in global mobility systems. Read the full article at: arxiv.org
|
|
Scooped by
Complexity Digest
January 23, 3:05 PM
|
Linghang Sun, Yifan Zhang, Cristian Axenie, Margherita Grossi, Anastasios Kouvelas, Michail A. Makridis Transportation Research Part B: Methodological Volume 205, March 2026, 103386 Major cities worldwide experience problems with the performance of their road transportation networks, and the continuous increase in traffic demand presents a substantial challenge to the optimal operation of urban road networks and the efficiency of traffic control strategies. The operation of transportation systems is widely considered to display fragile property, i.e., the loss in performance increases exponentially with the linearly growing magnitude of disruptions. Meanwhile, the risk engineering community is embracing the novel concept of antifragility, enabling systems to learn from past events and exhibit improved performance under disruptions of previously unseen magnitudes. In this study, based on established traffic flow theory knowledge, namely the Macroscopic Fundamental Diagram (MFD), we first conduct a rigorous mathematical analysis to theoretically prove the fragile nature of road transportation networks. Subsequently, we propose a skewness-based indicator that can be readily applied to cross-compare the degree of fragility for different networks solely dependent on the MFD-related parameters. Finally, we implement a numerical simulation calibrated with real-world network data to bridge the gap between the theoretical proof and the practical operations, with results showing the reinforcing effect of higher-order statistics and stochasticity on the fragility of the networks. This work aims to demonstrate the fragile nature of road transportation networks and guide researchers towards adopting the methods of antifragile design for future networks and traffic control strategies. Read the full article at: www.sciencedirect.com
|
|
Scooped by
Complexity Digest
January 22, 10:42 AM
|
Ori Livson, Siddharth Pritam, Mikhail Prokopenko
Preference cycles are prevalent in problems of decision-making, and are contradictory when preferences are assumed to be transitive. This contradiction underlies Condorcet's Paradox, a pioneering result of Social Choice Theory, wherein intuitive and seemingly desirable constraints on decision-making necessarily lead to contradictory preference cycles. Topological methods have since broadened Social Choice Theory and elucidated existing results. However, characterisations of preference cycles in Topological Social Choice Theory are lacking. In this paper, we address this gap by introducing a framework for topologically modelling preference cycles that generalises Baryshnikov's existing topological model of strict, ordinal preferences on 3 alternatives. In our framework, the contradiction underlying Condorcet's Paradox topologically corresponds to the non-orientability of a surface homeomorphic to either the Klein Bottle or Real Projective Plane, depending on how preference cycles are represented. These findings allow us to reduce Arrow's Impossibility Theorem to a statement about the orientability of a surface. Furthermore, these results contribute to existing wide-ranging interest in the relationship between non-orientability, impossibility phenomena in Economics, and logical paradoxes more broadly. Read the full article at: arxiv.org
|
|
Scooped by
Complexity Digest
January 22, 6:44 AM
|
María Fernanda Sánchez-Puig, Carlos Gershenson, Carlos Pineda The large digital archives of the American Physical Society (APS) offer an opportunity to quantitatively analyze the structure and evolution of scientific communication. In this paper, we perform a comparative analysis of the language used in eight APS journals (Phys. Rev. A, B, C, D, E, Lett., X, Rev. Mod. Phys.) using methods from statistical linguistics. We study word rank distributions (from monograms to hexagrams), finding that they are consistent with Zipf’s law. We also analyze rank diversity over time, which follows a characteristic sigmoid shape. To quantify the linguistic similarity between journals, we use the rank-biased overlap (RBO) distance, comparing the journals not only to each other, but also to corpora from Google Books and Twitter. This analysis reveals that the most significant differences emerge when focusing on content words rather than the full vocabulary. By identifying the unique and common content words for each specialized journal, we develop an article classifier that predicts a paper’s journal of origin based on its unique word distribution. This classifier uses a proposed “importance factor” to weigh the significance of each word. Finally, we analyze the frequency of mention of prominent physicists and compare it to their cultural recognitions ranked in the Pantheon dataset, finding a low correlation that highlights the context-dependent nature of scientific fame. These results demonstrate that scientific language itself can serve as a quantitative window into the organization and evolution of science. Read the full article at: www.preprints.org
|
|
Scooped by
Complexity Digest
January 11, 11:07 AM
|
Andrea Roli, Sudip Patra, Stuart Kauffman Interface Focus (2025) 15 (6): 20250038 We discuss the creation of information in the evolution of the biosphere by elaborating on the interplay between affordances and constraints. We maintain that information is created when affordances are seized and, therefore, at the same time, meaning is generated and a new space of possibilities is created. Read the full article at: royalsocietypublishing.org
|
|
Scooped by
Complexity Digest
January 9, 3:30 PM
|
David Wolpert, Carlo Rovelli, and Jordan Scharnhorst Entropy 2025, 27(12), 1227 Are your perceptions, memories and observations merely a statistical fluctuation arising from of the thermal equilibrium of the universe, bearing no correlation to the actual past state of the universe? Arguments are given in the literature for and against this “Boltzmann brain” hypothesis. Complicating these arguments have been the many subtle—and very often implicit—joint dependencies among these arguments and others that have been given for the past hypothesis, the second law, and even for Bayesian inference of the reliability of experimental data. These dependencies can easily lead to circular reasoning. To avoid this problem, since all of these arguments involve the stochastic properties of the dynamics of the universe’s entropy, we begin by formalizing that dynamics as a time-symmetric, time-translation invariant Markov process, which we call the entropy conjecture. Crucially, like all stochastic processes, the entropy conjecture does not specify any time(s) which it should be conditioned on in order to infer the stochastic dynamics of our universe’s entropy. Any such choice of conditioning times and associated entropy values must be introduced as an independent assumption. This observation allows us to disentangle the standard Boltzmann brain hypothesis, its “1000CE” variant, the past hypothesis, the second law, and the reliability of our experimental data, all in a fully formal manner. In particular, we show that these all make an arbitrary assumption that the dynamics of the universe’s entropy should be conditioned on a single event at a single moment in time, differing only in the details of their assumptions. In this aspect, the Boltzmann brain hypothesis and the second law are equally legitimate (or not). Read the full article at: www.mdpi.com
|
|
Scooped by
Complexity Digest
January 8, 1:13 PM
|
Jasper J. van Beers, Marten Scheffer, Prashant Solanki, Ingrid A. van de Leemput, Egbert H. van Nes, Coen C. de Visser Maintaining stability in feedback systems, from aircraft and autonomous robots to biological and physiological systems, relies on monitoring their behavior and continuously adjusting their inputs. Incremental damage can make such control fragile. This tends to go unnoticed until a small perturbation induces instability (i.e. loss of control). Traditional methods in the field of engineering rely on accurate system models to compute a safe set of operating instructions, which become invalid when the, possibly damaged, system diverges from its model. Here we demonstrate that the approach of such a feedback system towards instability can nonetheless be monitored through dynamical indicators of resilience. This holistic system safety monitor does not rely on a system model and is based on the generic phenomenon of critical slowing down, shown to occur in the climate, biology and other complex nonlinear systems approaching criticality. Our findings for engineered devices opens up a wide range of applications involving real-time early warning systems as well as an empirical guidance of resilient system design exploration, or "tinkering". While we demonstrate the validity using drones, the generic nature of the underlying principles suggest that these indicators could apply across a wider class of controlled systems including reactors, aircraft, and self-driving cars. Read the full article at: arxiv.org
|
|
Scooped by
Complexity Digest
January 8, 4:52 AM
|
Leroy Cronin, Sara I. Walker Assembly theory (AT) introduces a concept of causation as a material property, constitutive of a metrology of evolution and selection. The physical scale for causation is quantified with the assembly index, defined as the minimum number of steps necessary for a distinguishable object to exist, where steps are assembled recursively. Observing countable copies of high assembly index objects indicates that a mechanism to produce them is persistent, such that the object's environment builds a memory that traps causation within a contingent chain. Copy number and assembly index underlie the standardized metrology for detecting causation (assembly index), and evidence of contingency (copy number). Together, these allow the precise definition of a selective threshold in assembly space, understood as the set of all causal possibilities. This threshold demarcates life (and its derivative agential, intelligent and technological forms) as structures with persistent copies beyond the threshold. In introducing a fundamental concept of material causation to explain and measure life, AT represents a departure from prior theories of causation, such as interventional ones, which have so far proven incompatible with fundamental physics. We discuss how AT's concept of causation provides the foundation for a theory of physics where novelty, contingency and the potential for open-endedness are fundamental, and determinism is emergent along assembled lineages. Read the full article at: arxiv.org
|
|
Scooped by
Complexity Digest
December 28, 2025 10:01 AM
|
Manlio De Domenico The possibility that evolutionary forces -- together with a few fundamental factors such as thermodynamic constraints, specific computational features enabling information processing, and ecological processes -- might constrain the logic of living systems is tantalizing. However, it is often overlooked that any practical implementation of such a logic requires complementary circuitry that, in biological systems, happens through complex networks of genetic regulation, metabolic reactions, cellular signalling, communication, social and eusocial non-trivial organization. Here, we review and discuss how circuitries are not merely passive structures, but active agents of change that, by means of hierarchical and modular organization, are able to enhance and catalyze the evolution of evolvability. By analyzing the role of non-trivial topologies in major evolutionary transitions under the lens of statistical physics and nonlinear dynamics, we show that biological innovations are strictly related to circuitry and its deviation from trivial structures and (thermo)dynamic equilibria. We argue that sparse heterogeneous networks such as hierarchical modular, which are ubiquitously observed in nature, are favored in terms of the trade-off between energetic costs for redundancy, error-correction and mantainance. We identify three main features -- namely, interconnectivity, plasticity and interdependency -- pointing towards a unifying framework for modeling the phenomenology, discussing them in terms of dynamical systems theory, non-equilibrium thermodynamics and evolutionary dynamics. Within this unified picture, we also show that “slow” evolutionary dynamics is an emergent phenomenon governed by the replicator-mutator equation as the direct consequence of a constrained variational nonequilibrium process. Overall, this work highlights how dynamical systems theory and nonequilibrium thermodynamics provide powerful analytical techniques to study biological complexity. Read the full article at: iopscience.iop.org
|
|
|
Scooped by
Complexity Digest
February 1, 1:53 PM
|
Ricard Solé, Luis F Seoane, Jordi Pla-Mauri, Michael Timothy Bennett, Michael E. Hochberg, Michael Levin
Cognitive processes are realized across an extraordinary range of natural, artificial, and hybrid systems, yet there is no unified framework for comparing their forms, limits, and unrealized possibilities. Here, we propose a cognition space approach that replaces narrow, substrate-dependent definitions with a comparative representation based on organizational and informational dimensions. Within this framework, cognition is treated as a graded capacity to sense, process, and act upon information, allowing systems as diverse as cells, brains, artificial agents, and human-AI collectives to be analyzed within a common conceptual landscape. We introduce and examine three cognition spaces -- basal aneural, neural, and human-AI hybrid -- and show that their occupation is highly uneven, with clusters of realized systems separated by large unoccupied regions. We argue that these voids are not accidental but reflect evolutionary contingencies, physical constraints, and design limitations. By focusing on the structure of cognition spaces rather than on categorical definitions, this approach clarifies the diversity of existing cognitive systems and highlights hybrid cognition as a promising frontier for exploring novel forms of complexity beyond those produced by biological evolution. Read the full article at: arxiv.org
|
|
Scooped by
Complexity Digest
January 31, 5:52 PM
|
Galen J. Wilkerson
The origin of life poses a problem of combinatorial feasibility: How can temporally supported functional organization arise in exponentially branching assembly spaces when unguided exploration behaves as a memoryless random walk? We show that nonlinear threshold-cascade dynamics in connected interaction networks provide a minimal, substrate-agnostic mechanism that can soften this obstruction. Below a critical connectivity threshold, cascades die out locally and structured input-output response mappings remain sparse and transient-a "functional desert" in which accumulation is dynamically unsupported. Near the critical percolation threshold, system-spanning cascades emerge, enabling discriminative functional responses. We illustrate this transition using a minimal toy model and generalize the argument to arbitrary networked systems. Also near criticality, cascades introduce finite-timescale structural and functional coherence, directional bias, and weak dynamical path-dependence into otherwise memoryless exploration, allowing biased accumulation. This connectivity-driven transition-functional percolation-requires only generic ingredients: interacting units, nonlinear thresholds, influence transmission, and non-zero coherence times. The mechanism does not explain specific biochemical pathways, but it identifies a necessary dynamical regime in which structured functional organization can emerge and be temporarily supported, providing a physical foundation for how combinatorial feasibility barriers can be crossed through network dynamics alone. Read the full article at: arxiv.org
|
|
Scooped by
Complexity Digest
January 25, 6:02 PM
|
Erik Hoel Patterns, Volume 7, Issue 1101472January 09, 2026 Complex systems can be described at myriad different scales, and their causal workings often have a multiscale structure (e.g., a computer can be described at the microscale of its hardware circuitry, the mesoscale of its machine code, and the macroscale of its operating system). While scientists study and model systems across the full hierarchy of their scales, from microphysics to macroeconomics, there is debate about what the macroscales of systems can possibly add beyond mere compression. To resolve this long-standing issue, here, a new theory of emergence is introduced that can distinguish which scales irreducibly contribute to a system’s causal workings. The theory’s application is demonstrated in coarse grains of Markov chains, revealing a novel measure of emergent complexity: how widely distributed a system’s causal contributions are across its hierarchy of scales. Read the full article at: www.cell.com
|
|
Scooped by
Complexity Digest
January 24, 4:06 PM
|
Xiangyi Meng, Benjamin Piazza, Csaba Both, Baruch Barzel & Albert-László Barabási Nature volume 649, pages 315–322 (2026) The brain’s connectome1,2,3 and the vascular system4 are examples of physical networks whose tangible nature influences their structure, layout and, ultimately, their function. The material resources required to build and maintain these networks have inspired decades of research into wiring economy, offering testable predictions about their expected architecture and organization. Here we empirically explore the local branching geometry of a wide range of physical networks, uncovering systematic violations of the long-standing predictions of wiring minimization. This leads to the hypothesis that predicting the true material cost of physical networks requires us to account for their full three-dimensional geometry, resulting in a largely intractable optimization problem. We discover, however, an exact mapping of surface minimization onto high-dimensional Feynman diagrams in string theory5,6,7, predicting that, with increasing link thickness, a locally tree-like network undergoes a transition into configurations that can no longer be explained by length minimization. Specifically, surface minimization predicts the emergence of trifurcations and branching angles in excellent agreement with the local tree organization of physical networks across a wide range of application domains. Finally, we predict the existence of stable orthogonal sprouts, which are not only prevalent in real networks but also play a key functional role, improving synapse formation in the brain and nutrient access in plants and fungi. Read the full article at: www.nature.com
|
|
Scooped by
Complexity Digest
January 23, 6:09 PM
|
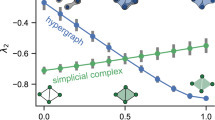
Maxime Lucas, Luca Gallo, Arsham Ghavasieh, Federico Battiston & Manlio De Domenico
Nature Communications , Article number: (2026) Empirical complex systems can be characterized not only by pairwise interactions, but also by higher-order (group) interactions influencing collective phenomena, from metabolic reactions to epidemics. Nevertheless, higher-order networks’ apparent superior descriptive power—compared to classical pairwise networks—comes with a much increased model complexity and computational cost, challenging their application. Consequently, it is of paramount importance to establish a quantitative method to determine when such a modeling framework is advantageous with respect to pairwise models, and to which extent it provides a valuable description of empirical systems. Here, we propose an information-theoretic framework, accounting for how structures affect diffusion behaviors, quantifying the entropic cost and distinguishability of higher-order interactions to assess their reducibility to lower-order structures while preserving relevant functional information. Empirical analyses indicate that some systems retain essential higher-order structure, whereas in some technological and biological networks it collapses to pairwise interactions. With controlled randomization procedures, we investigate the role of nestedness and degree heterogeneity in this reducibility process. Our findings contribute to ongoing efforts to minimize the dimensionality of models for complex systems. Read the full article at: www.nature.com
|
|
Scooped by
Complexity Digest
January 23, 6:51 AM
|
Didier Sornette, Sandro Claudio Lera, Ke Wu
Recent reports of large language models (LLMs) exhibiting behaviors such as deception, threats, or blackmail are often interpreted as evidence of alignment failure or emergent malign agency. We argue that this interpretation rests on a conceptual error. LLMs do not reason morally; they statistically internalize the record of human social interaction, including laws, contracts, negotiations, conflicts, and coercive arrangements. Behaviors commonly labeled as unethical or anomalous are therefore better understood as structural generalizations of interaction regimes that arise under extreme asymmetries of power, information, or constraint. Drawing on relational models theory, we show that practices such as blackmail are not categorical deviations from normal social behavior, but limiting cases within the same continuum that includes market pricing, authority relations, and ultimatum bargaining. The surprise elicited by such outputs reflects an anthropomorphic expectation that intelligence should reproduce only socially sanctioned behavior, rather than the full statistical landscape of behaviors humans themselves enact. Because human morality is plural, context-dependent, and historically contingent, the notion of a universally moral artificial intelligence is ill-defined. We therefore reframe concerns about artificial general intelligence (AGI). The primary risk is not adversarial intent, but AGI's role as an endogenous amplifier of human intelligence, power, and contradiction. By eliminating longstanding cognitive and institutional frictions, AGI compresses timescales and removes the historical margin of error that has allowed inconsistent values and governance regimes to persist without collapse. Alignment failure is thus structural, not accidental, and requires governance approaches that address amplification, complexity, and regime stability rather than model-level intent alone. Read the full article at: arxiv.org
|
|
Scooped by
Complexity Digest
January 22, 8:45 AM
|
Sara Najem, Amer E. Mouawad
Determining whether two graphs are structurally identical is a fundamental problem with applications spanning mathematics, computer science, chemistry, and network science. Despite decades of study, graph isomorphism remains a challenging algorithmic task, particularly for highly symmetric structures. Here we introduce a new algorithmic approach based on ideas from spectral graph theory and geometry that constructs candidate correspondences between vertices using their curvatures. Any correspondence produced by the algorithm is explicitly verified, ensuring that non-isomorphic graphs are never incorrectly identified as isomorphic. Although the method does not yet guarantee success on all isomorphic inputs, we find that it correctly resolves every instance tested in deterministic polynomial time, including a broad collection of graphs known to be difficult for classical spectral techniques. These results demonstrate that enriched spectral methods can be far more powerful than previously understood, and suggest a promising direction for the practical resolution of the complexity of the graph isomorphism problem. Read the full article at: arxiv.org
|
|
Scooped by
Complexity Digest
January 22, 6:39 AM
|
Galen J. Wilkerson
Understanding how network structure constrains and enables information processing is a central problem in the statistical mechanics of interacting systems. Here we study random networks across the structural percolation transition and analyze how connectivity governs realizable input-output transformations under cascade dynamics. Using Erdos-Renyi networks as a minimal ensemble, we examine structural, functional, and information-theoretic observables as functions of mean degree. We find that the emergence of the giant connected component coincides with a sharp transition in realizable information processing: complex input-output response functions become accessible, functional diversity increases rapidly, output entropy rises, and directed information flow, quantified by transfer entropy, extends beyond local neighborhoods. We term this coincidence of structural, functional, and informational transitions functional percolation, referring to a sharp expansion of the space of realizable input-output functions at the percolation threshold. Near criticality, networks exhibit a Pareto-optimal tradeoff between functional complexity and diversity, suggesting that percolation criticality may provide a general organizing principle of information processing capacity in systems with local interactions and propagating influences. Read the full article at: arxiv.org
|
|
Scooped by
Complexity Digest
January 10, 11:05 AM
|
Marlene C. L. Batzke, Peter Steiglechner, Jan Lorenz, Bruce Edmonds, František Kalvas Political Psychology Political polarization represents a rising issue in many countries, making it more and more important to understand its relation to cognitive-motivational and social influence mechanisms. Yet, the link between micro-level mechanisms and macro-level phenomena remains unclear. We investigated the consequences of individuals striving for cognitive coherence in their belief systems on political polarization in society in an agent-based model. In this, we formalized how cognitive coherence affects how individuals update their beliefs following social influence and self-reflection processes. We derive agents' political beliefs as well as their subjective belief systems, defining what determines coherence for different individuals, from European Social Survey data via correlational class analysis. The simulation shows that agents polarize in their beliefs when they have a strong strive for cognitive coherence, and especially when they have structurally different belief systems. In a mathematical analysis, we not only explain the main findings but also underscore the necessity of simulations for understanding the complex dynamics of socially embedded phenomena such as political polarization. Read the full article at: onlinelibrary.wiley.com
|
|
Scooped by
Complexity Digest
January 9, 11:04 AM
|
James N. Druckman, Katherine Ognyanova, Alauna Safarpour, Jonathan Schulman, Kristin Lunz Trujillo, Ata Aydin Uslu, Jon Green, Matthew A. Baum, Alexi Quintana-Mathé, Hong Qu, Roy H. Perlis & David M. J. Lazer
Nature Human Behaviour (2025) Scientists provide important information to the public. Whether that information influences decision-making depends on trust. In the USA, gaps in trust in scientists have been stable for 50 years: women, Black people, rural residents, religious people, less educated people and people with lower economic status express less trust than their counterparts (who are more represented among scientists). Here we probe the factors that influence trust. We find that members of the less trusting groups exhibit greater trust in scientists who share their characteristics (for example, women trust women scientists more than men scientists). They view such scientists as having more benevolence and, in most cases, more integrity. In contrast, those from high-trusting groups appear mostly indifferent about scientists’ characteristics. Our results highlight how increasing the presence of underrepresented groups among scientists can increase trust. This means expanding representation across several divides—not just gender and race/ethnicity but also rurality and economic status. Read the full article at: www.nature.com
|
|
Scooped by
Complexity Digest
January 8, 11:03 AM
|
Aparimit Kasliwal, Abdullah Alhadlaq, Ariel Salgado, Auroop R. Ganguly, Marta C. González Computer-Aided Civil and Infrastructure Engineering Volume40, Issue31, 29 December 2025, Pages 6223-6241 Modeling spreading dynamics on spatial networks is crucial to addressing challenges related to traffic congestion, epidemic outbreaks, efficient information dissemination, and technology adoption. Existing approaches include domain-specific agent-based simulations, which offer detailed dynamics but often involve extensive parameterization, and simplified differential equation models, which provide analytical tractability but may abstract away spatial heterogeneity in propagation patterns. As a step toward addressing this trade-off, this work presents a hierarchical multiscale framework that approximates spreading dynamics across different spatial scales under certain simplifying assumptions. Applied to the Susceptible-Infected-Recovered (SIR) model, the approach ensures consistency in dynamics across scales through multiscale regularization, linking parameters at finer scales to those obtained at coarser scales. This approach constrains the parameter search space, and enables faster convergence of the model fitting process compared to the non-regularized model. Using hierarchical modeling, the spatial dependencies critical for understanding system-level behavior are captured while mitigating the computational challenges posed by parameter proliferation at finer scales. Considering traffic congestion and COVID-19 spread as case studies, the calibrated fine-scale model is employed to analyze the effects of perturbations and to identify critical regions and connections that disproportionately influence system dynamics. This facilitates targeted intervention strategies and provides a tool for studying and managing spreading processes in spatially distributed sociotechnical systems. Read the full article at: onlinelibrary.wiley.com
|
|
Scooped by
Complexity Digest
January 7, 11:01 AM
|
Stefano Caselli, Marta Zava The study examines the structure, functioning, and strategic implications of financial ecosystems across four European countries-France, Sweden, the United Kingdom, and Italy-to identify institutional best practices relevant to the ongoing transformation of Italy's financial system. Building on a comparative analysis of legislation and regulation, taxation, investor bases, and financial intermediation, the report highlights how distinct historical and institutional trajectories have shaped divergent models: the French dirigiste system anchored by powerful state-backed institutions and deep asset management pools; the Swedish social-democratic ecosystem driven by broad household equity participation, taxefficient savings vehicles, and equity-oriented pension funds; and the British liberal model, characterized by deep capital markets, strong institutional investor engagement, and globally competitive listing infrastructure. In contrast, Italy remains predominantly bank-centric, with fragmented institutional investment, limited retail equity participation, underdeveloped public markets, and a structural reliance on domestic banking channels for corporate finance. Read the full article at: papers.ssrn.com
|