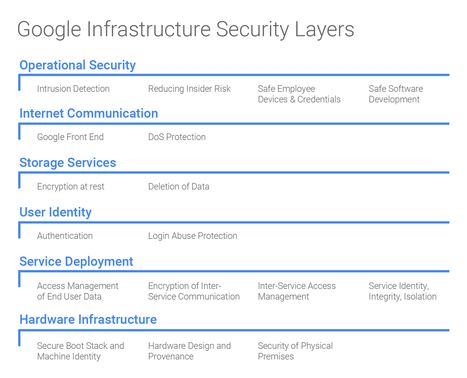
Retrouvez et comparez les différents services proposés par les fournisseurs Cloud : Amazon Web Services, Google Cloud Plateforme et Microsoft Azure !
Get Started for FREE
Sign up with Facebook Sign up with X
I don't have a Facebook or a X account


 Your new post is loading...
Your new post is loading... Your new post is loading...
Your new post is loading...
Retrouvez et comparez les différents services proposés par les fournisseurs Cloud : Amazon Web Services, Google Cloud Plateforme et Microsoft Azure ! 
No comment yet.
Sign up to comment
Learn how a data center fabric is the basis of a cloud data center architecture and how it affects how applications are delivered and deployed.
 Twelve-Factor App methodologyThe Twelve-Factor App methodology is a methodology for building software-as-a-service applications. These best practices are designed to enable applications to be built with portability and resilience when deployed to the web. The methodology was drafted by developers at Heroku, a platform-as-a-service company, and was first presented by Adam Wiggins circa 2011.

Tips and tools for utilizing microservice architecture on Kubernetes; including using kubespray and Prometheus.

C’est un vieux rêve. Prophétisé dès le début du millénaire par quelques ingénieurs visionnaires, alors même que nos connexions Internet ne nous permettent pas de télécharger un film en moins de deux heures, même en piètre qualité. Il aura ainsi fallu près de 20 ans pour transformer ce rêve en réalité. Les acteurs se multiplient, et les infrastructures, surtout, sont prêtes : bienvenue dans le nouveau monde du jeu vidéo. Un monde 100% dématérialisé.
Mickael Ruau's insight:
Toujours actif aujourd'hui, le PlayStation Now est probablement le service de cloud gaming le plus populaire du marché. Si Sony ne communique aucun chiffre, de récentes estimations avancent que le PS Now engrangerait près de 52% des revenus générés par les services d'accès à des jeux vidéo par abonnement. Un chiffre évidemment généreusement poussé par le parc bien établi de PlayStation 4 - 94 millions d'unités vendues au 31 décembre 2018. Quelles perspectives d'avenir pour le cloud gaming ?
La 5G : meilleure alliée du cloud gaming ?
At QCon SF, Yevgeniy Brikman presented "Automated Testing for Terraform, Docker, Packer, Kubernetes, and More". Key takeaways from the talk included the recommendation to use an appropriate mix of all testing techniques discussed, such as static analysis, unit tests, integration tests, and end-to-end tests.
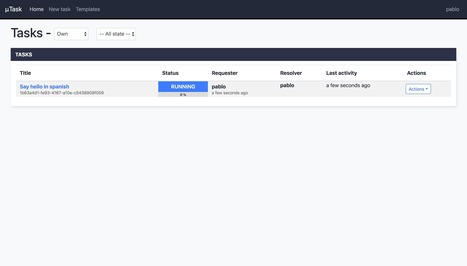
µTask is an automation engine that models and executes business processes declared in yaml. ✏️� - ovh/utask�
Mickael Ruau's insight:
µTask is an automation engine built for the cloud. It is:
µTask allows you to model business processes in a declarative yaml format. Describe a set of inputs and a graph of actions and their inter-dependencies: µTask will asynchronously handle the execution of each action, working its way around transient errors and keeping a trace of all intermediary states until completion.
Mickael Ruau's insight:
Venue
Authors
Research AreasPublication Year

Composable disaggregated infrastructure complements virtualization and SDI technologies to provide the efficiency and agility that today’s hyperscale data centers demand
Mickael Ruau's insight:
CDI virtuesIn a CDI-enabled data center the individual compute modules, non-volatile memory, accelerators, storage, etc. within each server are disaggregated into pools of shared resources — so they can be managed individually and collectively under software control. The disaggregated components can then be reconstituted, or composed, under software control, as workload-optimized servers irrespective of which racks the components happen to physically reside in. Studies show CDI can achieve TCO gains of up to 63 percent (55 percent capex, 75 percent opex) and technology refresh savings of 44 percent capex and 77 percent labor. These savings result from:
Facebook, Google, and other tier one Cloud Service Providers (CSPs) are actively investigating disaggregated architectures for their data centers. Some of their implementations are custom and most use proprietary software and APIs. To match the gains of the largest CSPs, organizations that don’t have the scale of a Google or Facebook need commercial off-the-shelf CDI solutions that anyone can adopt. The commonality of open technology standards will help the industry to achieve scale and make CDI generally available from a choice of suppliers.

Facebook’s production network by itself is a large distributed system with specialized tiers and technologies for different tasks: edge, backbone, and data centers. In this post, we will focus on the latest developments in our data center networking and unveil the next-generation architecture that we have successfully deployed in our new Altoona facility: data center fabric.

Operation Time (nsec) L1 cache reference 0.5 Branch mispredict 5 L2 cache reference 7 Mutex lock/unlock 25 Main memory reference 100 Compress 1KB bytes with Zippy 3,000 Send 2K bytes over 1 Gbps network 20,000 Read 1MB sequentially from memory 250,000 Roundtrip within same datacenter 500,000 Disk seek 10,000,000 Read 1MB sequentially from disk 20,000,000 Send packet CA -> Netherlands -> CA 150,000,000
Some useful figures that aren’t in Dean’s data can be found in this article comparing NetBSD 2.0 and FreeBSD 5.3 from 2005. Approximating those figures, we get: Operation Time (nsec) System call overhead 400 Context switch between processes 3000 fork() (statically-linked binary) 70,000 fork() (dynamically-linked binary) 160,000
Mickael Ruau's insight:
Update: This recent blog post examines the question of system call and context switch overhead in more detail. His figures suggest the best-case system call overhead is now only ~60 nsec (for Linux on Nehelem), and that context switches cost about 30 microseconds (30,000 nsec) — when you account for the cost of flushing CPU caches, that is probably pretty reasonable. In comparison, John Ousterhout’s RAMCloud project aims to provide end-to-end roundtrips for a key-value store in the same datacenter within “5-10 microseconds,” which would represent about a 100x improvement over the 500 microsecond latency suggested above. The keynote slides are worth a glance: Dean talks about the design of “Spanner”, a next-generation version of BigTable he is building at Google. See also James Hamilton’s notes on the keynote, and Greg Linden’s commentary.

Google Data Center FAQ & Locations. Google data centers are the object of great fascination, and the intrigue about these facilities is only deepened by Google's secrecy about its operations. We've written a lot about Google's facilities, and thought it would be useful to summarize key information in a series of Frequently Asked Questions

We’ve written a lot about Facebook’s infrastructure, and have compiled this information into a series of Frequently Asked Questions. Here’s the Facebook Data Center FAQ (or “Everything You Ever Wanted to Know About Facebook’s Data Centers”).
|
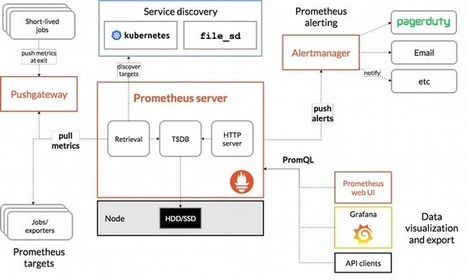
Metrics are the primary way to represent both the overall health of your system and any other specific information you consider important for monitoring and alerting or observability. Prometheus is a leading open source metric instrumentation, collection, and storage toolkit built at SoundCloud beginning in 2012.
 Fabric computingFabric computing or unified computing involves constructing a computing fabric consisting of interconnected nodes that look like a "weave" or a "fabric" when viewed/envisaged collectively from a distance. Usually the phrase refers to a consolidated high-performance computing system consisting of loosely coupled storage, networking and parallel processing functions linked by high bandwidth interconnects (such as 10 Gigabit Ethernet and InfiniBand) but the term has also been used[by whom?
A methodology for building modern, scalable, maintainable software-as-a-service apps.
Mickael Ruau's insight:
Les 12 facteurs
I. Base de codeUne base de code suivie avec un système de contrôle de version, plusieurs déploiementsII. DépendancesDéclarez explicitement et isolez les dépendancesIII. ConfigurationStockez la configuration dans l’environnementIV. Services externesTraitez les services externes comme des ressources attachéesV. Build, release, runSéparez strictement les étapes d’assemblage et d’exécutionVI. ProcessusExécutez l’application comme un ou plusieurs processus sans étatVII. Associations de portsExportez les services via des associations de portsVIII. ConcurrenceGrossissez à l’aide du modèle de processusIX. JetableMaximisez la robustesse avec des démarrages rapides et des arrêts gracieuxX. Parité dev/prodGardez le développement, la validation et la production aussi proches que possibleXI. LogsTraitez les logs comme des flux d’évènementsXII. Processus d’administrationLancez les processus d’administration et de maintenance comme des one-off-processes

L’ANSSI est l'autorité nationale en matière de sécurité et de défense des systèmes d’information. Prévention, protection, réaction, formation et labellisation de solutions et de services pour la sécurité numérique de la Nation.

La semaine dernière, nous avons fait un tour d’horizon du concept du cloud gaming. Mais qui va en profiter en 2019 et après ?
Mickael Ruau's insight:
Deux angles principaux se dégagent : l’accès à un ordinateur dans le cloud et le gaming-as-a-service tout intégré, sur le modèle de Netflix. Normalement, ces deux services devraient fusionner avec la maturation du marché. Votre ordinateur dans le cloudParmi les nombreux acteurs qui sont en train de se faire une place dans le domaine du cloud computing personnel, retenons-en trois. Le service Shadow, développé par la startup française Blade, est bien positionné. Si l’angle d’attaque est le jeu, c’est en vérité un ordinateur surpuissant situé dans le cloud que vous louez. Il peut servir à tout, comme faire du montage vidéo ou toute autre activité un peu gourmande en ressources. Avec l’abonnement à ce service, vous disposez d’un ordinateur toujours au top du marché contre 29,95 € par mois (engagement 12 mois). Soyons clairs, si la startup fondée en 2015 propose l’accès à l’ordinateur, il faudra payer les logiciels qui tournent dessus. La jeune pousse va jusqu’à proposer un boîtier pour accéder à son service. Vous pourrez y brancher un écran, un clavier, une souris ou un joystick. LiquidSky, quant à lui, propose deux offres, une à destination des gamers et une autre à destination des entreprises. Ici vous disposerez également d’un PC dans le cloud et vous devrez acheter vos jeux. Nvidia (US67066G1040-NVDA), le leader des cartes graphiques, enfin nous permettra de faire la jonction entre les PC dans le cloud et les services de bouquets de jeux. En effet, il propose actuellement le service GeForce Now, accessible gratuitement depuis un ordinateur ou en bouquet payant par le biais de son boîtier multimédia Shield TV. De l’avis de nombreux commentateurs, le service est tout à fait au point. Si vous ne connaissez pas le boîtier Shield TV, sachez qu’il est le cheval de Troie de Nvidia pour s’introduire dans votre salon. Il s’agit d’une box multimédia tournant sur un système d’exploitation Android capable de remplacer la box de votre fournisseur d’accès à Internet. Il participe à ce mouvement de fond qui renforce la concurrence entre les fournisseurs d’accès à Internet et les box multimédias proposées par Apple, Google ou Amazon. Le Netflix du jeu vidéoA notre connaissance, un seul acteur indépendant propose véritablement une offre simple combinant l’accès à un bouquet de jeux premium et à un cloud computer. Il s’agit de Vortex qui se présente explicitement comme le Netflix du jeu vidéo. Il propose actuellement l’accès à plus de 80 jeux sous la forme d’un abonnement de 9,99 $… Une offre simple et directe bien placée sur le game-as-a-service. Les autres propositions comme Blacknut ou Hatch se positionnent plutôt sur des jeux moins gourmands ou moins récents.
L’arrivée des géantsDeux annonces de grande importance ont eu lieu début octobre. Google (US02079K3059-GOOGL) a révélé son Project Stream, sa solution de jeu vidéo en streaming. Et de l’avis de tous les testeurs, l’arrivée dans l’arène du géant de Mountain View a de quoi inquiéter les acteurs déjà en place. Il propose en bêta privée, uniquement accessible aux Etats-Unis, de jouer au dernier titre d’Ubisoft, Assassin’s Creed Odyssey, directement dans Chrome avec une fluidité absolue ou presque. Beaucoup parient sur le lancement d’un service dédié par Google, dont la force de frappe dans le monde du web et des smartphones est sans commune mesure. Un autre acteur évident qui dispose de toutes les qualités pour réussir dans ce domaine est Microsoft (US5949181045 – MSFT). En effet, il combine une double compétence : son expertise dans le cloud d’infrastructure avec Azure et son expérience dans le domaine du jeu vidéo avec la Xbox. De tous les acteurs évoqués, c’est probablement celui qui présente la plus forte intégration verticale. Il a confirmé son désir de se lancer dans cette nouvelle course du cloud gaming avec le Project xCloud. Le principe sera de proposer un accès à l’ensemble des jeux de la Xbox par Internet, sans que les développeurs n’aient quoi que ce soit à faire de plus. Le lancement de la bêta publique est prévu pour 2019.

The Technology Radar is an opinionated guide to technology frontiers. Read the latest here.

Over the years, because of the competitive advantage that technology brings to Google, the company has been very secretive about its servers, storage, and networks. But every once in a while, though, Google gives the world a peek at its infrastructure and, in a certain sense, gives us all a view of what the future of the datacenter will look like.

Organizations such as Google, Amazon and Facebook posses sheer size, scale and distribution of data that pose a new class of challenges for networking, one which traditional networking vendors cannot meet.
Mickael Ruau's insight:
Google has been an advocate of SDN for quite some time, and is a member of the Open Networking Foundation (ONF), a consortium of industry leaders such as Facebook, Microsoft, Deutsche Telecom, Verizon and of course Google, promoting open standards for SDN, primarily the OpenFlow project which Google fully adopted. SDN and network virtualization have been major trends in the networking realm, especially with cloud-based deployments with their highly distributed, scalable and dynamic environments. All major cloud vendors have been innovating in their next gen networking. Most notably, Google has been actively competing with Amazon on driving its cloud networking to next gen, where Google presented its Andromeda project for network virtualization.

Facebook's enormous scale comes with enormous technological challenges, which go beyond conventional available solutions. For example, Facebook decided to abandon Microsoft's Bing search engine and instead develop its own revamped search capabilities. Another important area is Facebook's massive networking needs, which called for a whole new paradigm, code named data center fabric.
Mickael Ruau's insight:
Facebook made the design of “6-pack” open as part of the Open Compute Project, together with all the other components of its data center fabric. This is certainly not good news for Cisco and the other vendors, but great news for the community. You can find the full technical design details in Facebook’s post. Faceook is not the only one in the front line of scaling challenges. The open cloud community OpenStack, as well as the leading public cloud vendors Google and Amazon also shared networking strategies to meet the new challenges coming with the new workloads in modern cloud computing environment.
Le dernier numéro des Communications of the ACM [1] (CACM) contient un article intitulé Attack of the Killer Microseconds écrit par des ingénieurs de Google, dont David Patterson, qui fut dans des vies antérieures professeur à Berkeley, architecte principal des processeurs SPARC de Sun Microsystems et co-auteur avec John Hennessy (architecte principal des processeurs MIPS et actuel président de l’université Stanford) du manuel de référence sur l’architecture des ordinateurs (pour dire qu’il ne s’agit pas d’élucubrations d’amateurs).
(...) Ces problèmes de temps de latence pénalisants surgissent aujourd’hui parce que des événements qui étaient relativement rares dans les traitements d’hier (appel de procédures à distance, déplacement de machine virtuelle par exemple) sont désormais au cœur des architectures de traitement de données. Tant que ces événements étaient rares, les architectes de système adoptaient des solutions simples, telles que, simplement, attendre la fin de l’action, mais dès lors que ces événements sont fréquents la pénalité encourue devient de moins en moins supportable. Pour alléger ces pénalités, nos auteurs suggèrent de concevoir à nouveaux frais des optimisations pour les mécanismes de bas niveau, tels que contention de verrou et synchronisation. Les spécialistes du calcul à haute performance (HPC) se sont confrontés à ces problèmes depuis longtemps, mais les solutions qu’ils ont adoptées ne répondent pas forcément très bien aux questions actuelles, parce qu’ils travaillaient généralement dans un contexte où les contraintes économiques étaient faibles, ce qui n’est pas le cas des grands centres de données d’aujourd’hui. De surcroît, les logiciels déployés par les grands opérateurs tels que Google et Amazon évoluent rapidement, ce qui impose des méthodes de génie logiciel rigoureuses et simplificatrices, impératif ignoré du monde HPC. Des solutions doivent également être cherchées du côté des processus légers, du parallélisme à grain fin, de la gestion plus efficace des files d’attente, etc. Je ne puis mieux faire que vous recommander la lecture de cet article.
Mickael Ruau's insight:
Nos auteurs donnent les ordres de grandeur suivants pour 2017 : En nanosecondes : En microsecondes : En millisecondes : Accès registre : 1ns-5ns réseau local : O(1µs) Accès disque : O(10ms) Accès cache : 4ns-30ns Mémoire non-volatile : O(1µs) Clé USB : O(1ms) Accès mémoire : 100ns Mémoire flash rapide : O(10µs) Internet : O(10ms)Les efforts les plus importants (ils se chiffrent en milliards d’euros de recherche-développement) ont porté sur les actions de la première et de la troisième colonne, même si l’on peut noter la relative stagnation des performances des disques durs. En d’autres termes, voici le nombre d’instructions qu’un processeur moderne peut effectuer pendant les opérations de lecture-écriture suivantes : Mémoire flash 225 000 instructions = O(100µs) Flash rapide 20 000 instructions = O(10µs) Mémoire NVM 2 000 instructions = O(1µs) Mémoire centrale 500 instructions = O(100ns)
We’ve compiled our coverage of Apple’s data center expansion projects into a series of Frequently Asked Questions. Here’s the Apple Data Center FAQ (or “Everything You Ever Wanted to Know About Apple’s Data Centers”).
|