Et pourtant elle(s) tourne(nt) ! Quand la datavisualisation permet d'aider à saisir l'incommensurable et à embrasser un (tout petit) morceau de l'univers.
Depuis de nombreuses années déjà, tous les smartphones se ressemblent, et se ressemblent de plus en plus : une dalle noire aux bords arrondis. C’est le dos du téléphone qui révèle sa marque et parfois son modèle à tous ceux qui vous font face. Leurs capacités photographiques restent d’ailleurs aujourd’hui le principal élément différentiant – car il est visible ? – des nouveaux modèles de chaque marque.
La photo, c'est du calcul
La présentation le 13 Octobre de l’iPhone 12 faisait ainsi la part belle à ses capacités photo et vidéo, et plus précisément à ce que permettait en la matière la puissance phénoménale des 12 milliards de transistors de la puce A14 «Bionic», qu’il s’agisse des cœurs de l’unité centrale (CPU), du processeur graphique (GPU), du sous-système dédié au traitement d’images (IPS), sans oublier le module d’intelligence artificielle (NLP).
Comme si les optiques et les capteurs eux-mêmes, malgré des performances accrues – avec un système de stabilisation optique du capteur lui-même et non des lentilles -, passaient au second plan, éclipsées par une multitude de traitements opérant en temps réel et mobilisant les 3/4 du chipset pendant la prise de vues. Alors que la concurrence a vainement tenté de suivre Apple sur le nombre d’objectifs (seule manière d’assurer un zoom optique de qualité), puis de se différencier par la résolution en affichant des quantités de pixels toujours plus délirantes, la firme à la pomme s’en tient toujours à une résolution de 12 MP, et ce depuis l’iPhone X.
La différence est ailleurs, et réside dans la quantité ahurissante de traitements effectués avant, pendant, et après ce que vous croyez être une seule prise de vue : la vôtre. Apple a d’ailleurs reconnu cette évolution en utilisant le terme de «photographie computationnelle» de manière explicite durant l’événement. Il y avait pourtant un précédent.
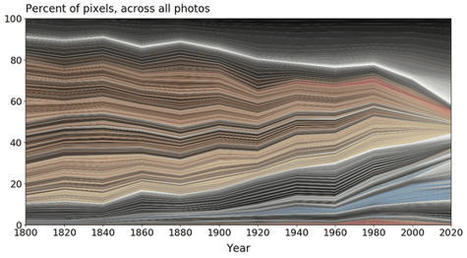
As a result of analyzing more than 7000 photos in 21 categories of the online museum collection, it has been pointed out that the proportion of gray is gradually increasing in the world.
The most common color among the 7083 items targeted was 'charcoal gray'. Charcoal gray appeared in 80% of the photos surveyed, but in most cases it was in only a few pixels. Here is a diagram showing how the colors of various objects changed over time from 1800 to 2020. One of the points is that gray is increasing while brown and yellow are decreasing. thing. It also shows that highly saturated colors have been used since the 1960s. As an example, many of the 1844 telephones were made of mahogany, so there are a lot of brown and yellow ingredients. Presented as a 2008 phone, the iPhone is mostly gray and black. If you look at the color trends, you can see the trends of 'hidden colors' that you can't understand just by looking at them. Below are images of the 'pocket watch' in the dataset, with blue bands below each image to indicate that each photo contains a small amount of blue pixels. Depending on the watch, there are cases where the hands contain blue, but there are also examples where rust-resistant screws called bluing screws are used, and it is believed that blue was detected. .
After five years of offering unlimited free photo backups at “high quality,” Google Photos will start charging for storage once more than 15 gigs on the account have been used. The change will happen on June 1st, 2021, and it comes with other Google Drive policy changes like counting Google Workspace documents and spreadsheets against the same cap. Google is also introducing a new policy of deleting data from inactive accounts that haven’t been logged in to for at least two years.
All photos and documents uploaded before June 1st will not count against that 15GB cap, so you have plenty of time to decide whether to continue using Google Photos or switching to another cloud storage provider for your photos. Only photos uploaded after June 1st will begin counting against the cap.
Google already counts “original quality” photo uploads against a storage cap in Google Photos. However, taking away unlimited backup for “high quality” photos and video (which are automatically compressed for more efficient storage) also takes away one of the service’s biggest selling points. It was the photo service where you just didn’t have to worry about how much storage you had.
4 selfies per human per week #4selfies : today more than 4 trillion photos are stored in Google Photos, and every week 28 billion new photos and videos are uploaded...
Chaque semaine, 28 milliards de photos et vidéos sont ajoutées à Google Photos. Soit l'équivalent de 4 selfies par habitant de notre planète.
Voici ce que révèle la notification envoyée par Google à l'ensemble des utilisateurs de son service d'hébergement Google Drive.
On y relève également toutes les possibilités proposées à l'utilisateur pour récupérer de la place, comme la détection des photos floues, ou encore des photos de slides. L'idée, élégante de prime abord, repose sur des capacités de traitement et d'analyse d'images tout à fait intéressantes. Pourquoi ne pas imaginer de reconstituer des éléments de Google Slides par exemple ?
Un dernier élément — de portée symbolique — est la dénomination de "politique" qui dit quelque chose en creux de la représentation de puissance de Google & co.
La police patrouille au delà du grand public : une des dernières tendances en marketing digital — avoir sa propre fonte — dépasse en effet le strict cadre du "B2C".
Ce levier d'impact considérable a été mis au point par l'imprimerie, puis la presse qui visaient la plus large base de lecteurs possibles : en quelque sorte les débuts du marketing de masse.
Jusqu'alors, très peu de polices "de marque" avaient été créées, en dehors peut-être de celles du Groupe VINCI très essentiellement utilisée pour la création de son logo et sa déclinaison.
Et la France ? Lancée par Apple et Adobe, la typographie numérique a été adoptée au pays de Claude Garamond dès les années 1990 par quelques industriels dont le Groupe Renault dont la police fut, avec le losange, une signature graphique distinctive et consistante.
Quelques années après, les Assedic, précurseur de Pôle emploi, ont utilisée le "A" d'une police de caractères pour leur logo. Savez-vous d'où il vient ?
NB : On exclut ici Arial, Verdana, Open Sans... diffusées par les géants numériques Microsoft ou Google
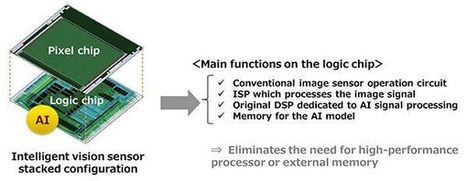
The announcement describes two new Intelligent Vision CMOS chip models, the Sony IMX500 and IMX501. From what I can tell these are the same base chip, except that the 500 is the bare chip product, whilst the 501 is a packaged product.
They are both 1/2.3” type chips with 12.3 effective megapixels. It seems clear that the one of the primary markets for the new chip is for security and system cameras. However having AI processes on the chip offers up some exciting new possibilities for future video cameras, particularly those mounted on drones or in action cameras like a GoPro or Insta 360.
One prominent ability of the new chip lies in functions such as object or person identification. This could be via tracking such objects, or in fact actually identifying them. Output from the new chip doesn’t have to be in image form either. Metadata can be output so that it can simply send a description of what it sees without the accompanying visual image. This can reduce the data storage requirement by up to 10,000 times.
For security or system camera purposes, a camera equipped with the new chip could count the number of people passing by it, or identifying low stock on a shop shelf. It could even be programmed to identify customer behaviour by way of heat maps.
For traditional cameras it could make autofocus systems better by being able to much more precisely identifying and tracking subjects. With AI systems like this, it could make autofocus systems more intelligent by identifying areas of a picture that you are likely to be focussing on. For example if you wanted to take a photograph of a flower, the AF system would know to focus on that rather than, say, the tree branch behind it. Facial recognition would also become much faster and more reliable.
Autofocus systems today are becoming incredibly good already, but if they were backed up by ultra fast on-chip object identification they could be even better. For 360 cameras, too, the ability to have more reliable object tracking metadata will help with post reframing.
As facial recognition technology gets cheaper, faster and more popular, people are looking for ways to subvert it. Reflectacles, a Chicago-based company, makes glasses that can thwart the technology.
The chunky, thick-framed glasses Scott Urban makes in his Humboldt Park workshop look like normal eyeglasses, but when viewed on a security camera, the wearer’s face becomes a shining orb.
Reflectacles, as the glasses are called, are among a growing number of devices developed to protect individual privacy as facial recognition technology becomes cheaper, faster and more commonplace.
Sauf si la loi interdit l'usage de maquillages et d'accessoires permettant de confondre les caméras. Après tout, masquer son visage sur la voie publique est bien interdit...
“The announcement came totally out of the blue and I am very proud to accept the Turing Award,” said Hanrahan, who is the Canon Professor in the School of Engineering and a professor of computer science and of electrical engineering at Stanford University. “It is a great honor, but I must give credit to a generation of computer graphics researchers and practitioners whose work and ideas influenced me over the years.”
Hanrahan splits the award and its $1 million prize with one-time mentor and colleague Edward “Ed” Catmull, former president of Pixar and Disney Animation Studios. The pair’s recognition marks only the second time that the award has been given for computer graphics.
“All of us at Stanford are tremendously proud of Pat and his accomplishments, and I am delighted that he and his colleague Ed Catmull are being recognized with the prestigious Turing Award,” said Stanford President Marc Tessier-Lavigne. “Pat has made pioneering contributions to the field of computer graphics. His work has had a profound impact on filmmaking and has created new artistic possibilities in film, video games, virtual reality and more.”
In the late-1980s, Hanrahan was chief architect at Pixar under Catmull, where he was principally responsible for creating the now-famous RenderMan Interface, the 3D animation application used to make such beloved films as Toy Story, Finding Nemo, Cars and many more. RenderMan is still widely used today. Hanrahan is particularly proud of his work on RenderMan’s Shading Language, which brought dramatic, photorealistic lighting to computer animation for the first time. He has won three Academy Awards for technical achievement.
“Pat Hanrahan’s work is an extraordinary example of the kind of creative research for which Stanford Engineering is known,” said Jennifer Widom, dean of the Stanford School of Engineering and a colleague of Hanrahan’s in the departments of computer science and of electrical engineering. “His work on computer graphics and data visualization have transformed industries and fields, and I am thrilled he is receiving this recognition, which he so richly deserves.”
In a statement, ACM said Hanrahan and Catmull “fundamentally influenced the field of computer graphics through conceptual innovation and contributions to both software and hardware. Their work has had a revolutionary impact on filmmaking, leading to a new genre of entirely computer-animated feature films.”
Netflix now supports the AV1 video codec in its Android app, which it says is 20 percent more efficient than the VP9 codec it currently uses. The codec can be enabled now for "selected titles" by selecting the app’s "Save Data" option.
An argument could be made that Google has over-indulged in its creation of way too many messaging apps in years past. But today’s launch of a new messaging service — this time within the confines of Google Photos — is an integration that actually makes sense.
The company is rolling out a way to directly message photos and chat with another user or users within the Google Photos app. The addition will allow users to quickly and easily share those one-off photos or videos with another person, instead of taking additional steps to build a shared album.
The feature itself is simple to use. After selecting a photo and tapping share, you can now choose a new option, “Send in Google Photos.” You can then tap on the icon of your most frequent contacts or search for a user by name, phone number or email.
The recipient will need a Google account to receive the photos, however, because they’ll need to sign in to view the conversation. That may limit the feature to some extent, as not everyone is a Google user. But with now a billion-some Google Photos users out there, it’s likely that more of the people you want to share with will have an account, rather than not.
You also can use this feature to start a group chat by selecting “New group,” then adding recipients.
Once a chat has been started, you can return to it at any time from the “Sharing” tab in Google Photos. Here, you’ll be able to see the photos and videos you each shared, comments, text chats and likes. You also can save the photos you want to your phone or tap on the “All Photos” option to see just the photos themselves without the conversations surrounding them.
A photographer captures the paths that birds make across the sky.
This story appears in the January 2018 issue of National Geographic magazine. If birds left tracks in the sky, what would they look like? For years Barcelona-based photographer Xavi Bou has been fascinated by this question. Just as a sinuous impression appears when a snake slides across sand, he imagined, so must a pattern form in the wake of a flying bird. But of course birds in flight leave no trace—at least none visible to the naked eye. Bou, now 38, spent the past five years trying to capture the elusive contours drawn by birds in motion, or, as he says, “to make visible the invisible.”
First he had to shed the role of mere observer. “Like a naturalist, I used to travel around the world looking at wildlife,” he says. He began exploring photographic techniques that would allow him to express his love of nature and show the beauty of birds in a way not seen before.
Ultimately he chose to work with a video camera, from which he extracts high-resolution photographs. After he films the birds in motion, Bou selects a section of the footage and layers the individual frames into one image. He finds the process similar to developing film: He can’t tell in advance what the final result will be. There’s one magical second, he says, when the image—chimerical and surreal—begins to emerge.
Before Bou began this project, which he calls “Ornitografías,” he earned degrees in geology and photography in Barcelona, then worked as a lighting technician in the fashion industry and also co-owned a postproduction studio. This current work, he says, combines his passion and his profession. “It’s technical, challenging, artistic, and natural. It’s the connection between photography and nature that I was looking for.”
Are you reading this on a handheld device? There’s a good chance you are. Now imagine how’d you look if that device suddenly disappeared. Lonely? Slightly crazy? Perhaps next to a person being ignored? As we are sucked in ever more by the screens we carry around, even in the company of friends and family, the hunched pose of the phone-absorbed seems increasingly normal.
US photographer Eric Pickersgill has created “Removed,” a series of photos to remind us of how strange that pose actually is. In each portrait, electronic devices have been “edited out” (removed before the photo was taken, from people who’d been using them) so that people stare at their hands, or the empty space between their hands, often ignoring beautiful surroundings or opportunities for human connection. The results are a bit sad and eerie—and a reminder, perhaps, to put our phones away.
In Eric Pickersgill's interesting and somewhat disturbing "Removed" photos, people stare at their hands, or the empty space between them, ignoring opportunities for human connection.
Samsung "space zoom" moon shots are fake, and here is the proof
"Many of us have witnessed the breathtaking moon photos taken with the latest zoom lenses, starting with the S20 Ultra. Nevertheless, I've always had doubts about their authenticity, as they appear almost too perfect. While these images are not necessarily outright fabrications, neither are they entirely genuine. Let me explain.
There have been many threads on this, and many people believe that the moon photos are real (inputmag) - even MKBHD has claimed in this popular youtube short that the moon is not an overlay, like Huawei has been accused of in the past. But he's not correct. So, while many have tried to prove that Samsung fakes the moon shots, I think nobody succeeded - until now.
I downsized it to 170x170 pixels and applied a gaussian blur, so that all the detail is GONE. This means it's not recoverable, the information is just not there, it's digitally blurred: https://imgur.com/xEyLajW
3) I full-screened the image on my monitor (showing it at 170x170 pixels, blurred), moved to the other end of the room, and turned off all the lights. Zoomed into the monitor and voila - https://imgur.com/ifIHr3S
Micro-sized cameras have great potential to spot problems in the human body and enable sensing for super-small robots, but past approaches captured fuzzy, distorted images with limited fields of view.
Now, researchers at Princeton University and the University of Washington have overcome these obstacles with an ultracompact camera the size of a coarse grain of salt. The new system can produce crisp, full-color images on par with a conventional compound camera lens 500,000 times larger in volume, the researchers reported in a paper published Nov. 29 in Nature Communications.
Enabled by a joint design of the camera’s hardware and computational processing, the system could enable minimally invasive endoscopy with medical robots to diagnose and treat diseases, and improve imaging for other robots with size and weight constraints. Arrays of thousands of such cameras could be used for full-scene sensing, turning surfaces into cameras.
While a traditional camera uses a series of curved glass or plastic lenses to bend light rays into focus, the new optical system relies on a technology called a metasurface, which can be produced much like a computer chip. Just half a millimeter wide, the metasurface is studded with 1.6 million cylindrical posts, each roughly the size of the human immunodeficiency virus (HIV).
Each post has a unique geometry, and functions like an optical antenna. Varying the design of each post is necessary to correctly shape the entire optical wavefront. With the help of machine learning-based algorithms, the posts’ interactions with light combine to produce the highest-quality images and widest field of view for a full-color metasurface camera developed to date.
Et pourtant elle(s) tourne(nt) ! Quand la datavisualisation permet d'aider à saisir l'incommensurable et à embrasser un (tout petit) morceau de l'univers.
Hybrid neural network can reconstruct Arabic or Japanese characters that it hasn’t seen before
Image analysis is ubiquitous in contemporary technology: from medical diagnostics to autonomous vehicles to facial recognition. Computers that use deep-learning convolutional neural networks—layers of algorithms that process images—have revolutionized computer vision.
But convolutional neural networks, or CNNs, classify images by learning from prior-trained data, often memorizing or developing stereotypes. They are also vulnerable to adversarial attacks that come in the form of small, almost-imperceptible distortions in the image that lead to bad decisions. These drawbacks limit the usefulness of CNNs. Additionally, there is growing awareness of the exorbitant carbon footprint associated with deep learning algorithms like CNNs.
One way to improve the energy efficiency and reliability of image processing algorithms involves combining conventional computer vision with optical preprocessors. Such hybrid systems work with minimal electronic hardware. Since light completes mathematical functions without dissipating energy in the preprocessing stage, significant time and energy savings can be achieved with hybrid computer vision systems. This emerging approach may overcome the shortcomings of deep learning and exploit the advantages of both optics and electronics.
In a recent paper published in Optica, UC Riverside mechanical engineering professor Luat Vuong and doctoral student Baurzhan Muminov demonstrate viability for hybrid computer vision systems via application of optical vortices, swirling waves of light with a dark central spot. Vortices can be likened to hydrodynamic whirlpools that are created when light travels around edges and corners.
Vivo has started teasing its next flagship phone, the X50. A video posted to Weibo shows off the camera module, which includes a periscope telephoto, two normal-looking lenses, and one much larger module that is presumably for the primary camera. The lens rotates as the module is manipulated by a robotic gimbal, suggesting the key feature here is image stabilization.
One of the big inclusions in Vivo’s Apex 2020 concept phone, which we weren’t able to see in person due to the COVID-19 pandemic, was “gimbal-like” stabilization on a 48-megapixel camera. Vivo said the design was inspired by chameleons’ eyes and is 200 percent more effective than typical OIS, allowing for longer nighttime exposures and smoother video. It looks like the X50 will be the first commercial deployment of this idea; another teaser videotouts the camera’s low-light ability.
Trying to pack a 16-135 mm lens into a smartphone is a real challenge. Adding optical stabilization thanks to a robotic gimbal takes the challenge way further.
The smartphone has recently and definitely morphed into a high end digital camera with phone capabilities. 16-135 mm focal lens in such a flat form factor is an achievement per se.
Two key Pixel execs, including the computer researcher who led the team that developed the computational photography powering the Pixel’s camera, have left Google in recent months, according to a new report from The Information. The executives who left are distinguished engineer Marc Levoy and former Pixel general manager Mario Queiroz.
Queiroz had apparently already moved off the Pixel team two months before the launch of the Pixel 4 into a role that reported directly to Google CEO Sundar Pichai. However, he left in January to join Palo Alto Networks, according to The Information and his LinkedIn. Levoy left Google in March, which is also reflected on his LinkedIn.
Optical Destabilization is underway at Google. I was lucky to meet Marc Levoy 10 yrs ago while I was running #imsense #eye-fidelity, impressive engineer, he will be a great loss.
There is a certain beauty in the expanses of public space, now vacant amid the pandemic, these photos from around the world show. There is also a reminder: True beauty comes when the builders roam the built.
"During the 1950s, New York’s Museum of Modern Art organized a famous photo exhibition called “The Family of Man.” In the wake of a world war, the show, chockablock with pictures of people, celebrated humanity’s cacophony, resilience and common bond.
Today a different global calamity has made scarcity the necessary condition of humanity’s survival. Cafes along the Navigli in Milan hunker behind shutters along with the Milanese who used to sip aperos beside the canal. Times Square is a ghost town, as are the City of London and the Place de la Concorde in Paris during what used to be the morning rush.
The photographs here all tell a similar story: a temple in Indonesia; Haneda Airport in Tokyo; the Americana Diner in New Jersey. Emptiness proliferates like the virus.
The Times recently sent dozens of photographers out to capture images of once-bustling public plazas, beaches, fairgrounds, restaurants, movie theaters, tourist meccas and train stations. Public spaces, as we think of them today, trace their origins back at least to the agoras of ancient Greece. Hard to translate, the word “agora” in Homer suggested “gathering.” Eventually it came to imply the square or open space at the center of a town or city, the place without which Greeks did not really regard a town or city as a town or city at all, but only as an assortment of houses and shrines.
Thousands of years later, public squares and other spaces remain bellwethers and magnets, places to which we gravitate for pleasure and solace, to take our collective temperature, celebrate, protest. Following the uprisings in Tiananmen Square, Tahrir Square, Taksim Square and elsewhere, Yellow Vest protesters in France demonstrated their discontent last year not by starting a GoFundMe page but by occupying public sites like the Place de la République and the Place de l’Opéra in Paris.
Both of those squares were built during the 19th century as part of a master plan by a French official, Baron Georges-Eugène Haussmann, who remade vast swaths of Paris after the city passed new health regulations in 1850 to combat disease. Beset by viruses and other natural disasters, cities around the world have time and again devised new infrastructure and rewritten zoning regulations to ensure more light and air, and produced public spaces, buildings and other sites, including some of the ones in these photographs, that promised to improve civic welfare and that represented new frontiers of civic aspiration.
Their present emptiness, a public health necessity, can conjure up dystopia, not progress, but, promisingly, it also suggests that, by heeding the experts and staying apart, we have not yet lost the capacity to come together for the common good. Covid-19 doesn’t vote along party lines, after all. These images are haunted and haunting, like stills from movies about plagues and the apocalypse, but in some ways they are hopeful.
They also remind us that beauty requires human interaction.
I don’t mean that buildings and fairgrounds and railway stations and temples can’t look eerily beautiful empty. Some of these sites, like many of these photographs, are works of art. I mean that empty buildings, squares and beaches are what art history textbooks, boutique hotel advertisements and glossy shelter and travel magazines tend to traffic in. Their emptiness trumpets an existence mostly divorced from human habitation and the messy thrum of daily life. They imagine an experience more akin to the wonder of bygone explorers coming upon the remains of a lost civilization.
They evoke the romance of ruins.
Beauty entails something else. It is something we bestow.
We have created a new AI-powered tool using convolutional neural nets that can turn virtually any standard 2D picture into a 3D image. No depth information required.
From the "author : "This video has recently been getting a lot of attention from the media (something of a shock to me). In some articles they are crediting me for having done something unique, but in my opinion this is unfair. Anyone can repeat this process with algorithms that are currently published on Github; all of them are in the video description. Credit should go to DIAN, Topaz AI, ESRGAN, Waifu2x, DeOldify, Anime 4K and other developers who are part of the worldwide ML-community and contributing to humanity by making these algorithms publicly available."
- Amazing is the fact that all of this results from applying openly available AI algorithms
- Equally amazing is the original source quality
- Finally amazing is the fact that all these people couldn''t even concieve the idea of being watched by millions of people through a massive network of networks connected to each other by wires and phone lines in a mobile device in the size of a potato 124 years later.
From my time researching this topic I have come to the realisation that a lot of people don’t actually understand it, or only understand it partly. Also, many tutorials do a bad job in explaining in “lay-mans” terms what exactly it is doing, or leave out certain steps that would otherwise clear up some confusion. So i’m going to explain from start to finish in the most simplest way possible.
There are many approaches to implement facial detection, and they can be separated into the following categories:
Knowledge Based
Rule based (Ex: X must have eyes, x must have a nose)
Too many rules and variables with this method
Feature Based
Locate and extract structural features in the face
Find a differential between facial and non facial regions in an image
Appearance Based
Learn the characteristics of a face
Example: CNN’s
Accuracy depends on training data (which can be scarce)
Template
Using predefined templates for edge detection
Quick and easy
A trade off for speed over accuracy
The approach we are going to be looking at is a mix between feature based and template based. One of the easiest and fastest ways of implementing facial detection is by using Viola Jones Algorithm.
A specialist medical camera that measures just 0.65 x 0.65 x 1.158mm has just entered the Guinness Book of Records. The size of the grain of sand, it is the camera's tiny sensor that is actually being entered into the record book.
The OmniVision OV6948 is just 0.575 x 0.575 x 0.232mm and produces a 40,000-pixel color image using an RGB Bayer back-side-illuminated chip. Each photosite measures just 1.75 µm across.
The resolution may seem low, but the OVM6948-RALA camera is designed to fit down the smallest of veins in the human body giving surgeons views that will aid diagnosis and with surgical procedures. Previously the surgeon would carry out these operations blind, or use a much lower-resolution fibre optic feed.
Manufactured by California-based OmniVision Technologies Inc, the sensor captures its imagery at 30fps, and its analog output can be transmitted over distances of up to 4m with minimal noise. The camera unit offers a 120° super-wide angle of view - so something like a 14mm on a full-frame camera. It gives a depth of field range from 3mm to 30mm.
Nicholas Nixon was visiting his wife’s family when, “on a whim,” he said, he asked her and her three sisters if he could take their picture. It was summer 1975, and a black-and-white photograph of four young women — elbows casually attenuated, in summer shirts and pants, standing pale and luminous against a velvety background of trees and lawn — was the result. A year later, at the graduation of one of the sisters, while readying a shot of them, he suggested they line up in the same order. After he saw the image, he asked them if they might do it every year. “They seemed O.K. with it,” he said; thus began a project that has spanned almost his whole career. The series, which has been shown around the world over the past four decades, will be on view at the Museum of Modern Art, coinciding with the museum’s publication of the book “The Brown Sisters: Forty Years” in November.
Who are these sisters? We’re never told (though we know their names: from left, Heather, Mimi, Bebe and Laurie; Bebe, of the penetrating gaze, is Nixon’s wife). The human impulse is to look for clues, but soon we dispense with our anthropological scrutiny — Irish? Yankee, quite likely, with their decidedly glamour-neutral attitudes — and our curiosity becomes piqued instead by their undaunted stares. All four sisters almost always look directly at the camera, as if to make contact, even if their gazes are guarded or restrained.
To get content containing either thought or leadership enter:
To get content containing both thought and leadership enter:
To get content containing the expression thought leadership enter:
You can enter several keywords and you can refine them whenever you want. Our suggestion engine uses more signals but entering a few keywords here will rapidly give you great content to curate.






 Your new post is loading...
Your new post is loading...
























Et pourtant elle(s) tourne(nt) ! Quand la datavisualisation permet d'aider à saisir l'incommensurable et à embrasser un (tout petit) morceau de l'univers.