Instead of making you go through ad network boot camp like a good campaign manager would, we’ve concentrated the 8 best CPC hacks that will get you optimizing like the pros.
Get Started for FREE
Sign up with Facebook Sign up with X
I don't have a Facebook or a X account



 Your new post is loading...
Your new post is loading... Your new post is loading...
Your new post is loading...
Instead of making you go through ad network boot camp like a good campaign manager would, we’ve concentrated the 8 best CPC hacks that will get you optimizing like the pros. 
No comment yet.
Sign up to comment
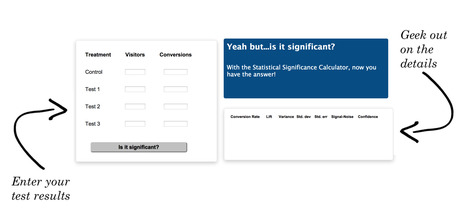
The real problem with CRO is in knowing how to start and what to test. This post covers the latter.
This video explains the purpose of t-tests, how they work, and how to interpret the results.
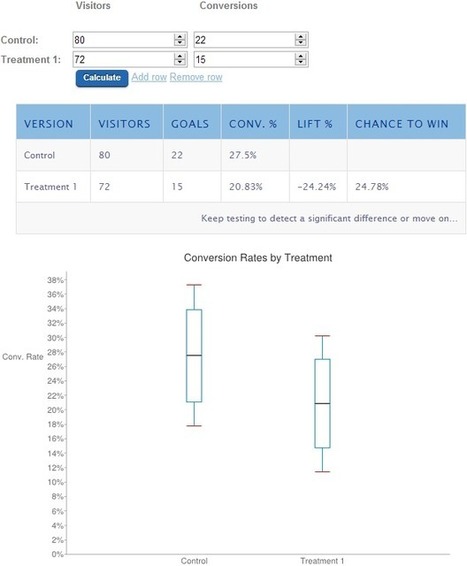
Dear readers – Long time, no see. For those of you who don’t know, I have recently become a freelance analytics and optimisation consultant. Fortunately I’ve been keeping busy :). Don’t you love working in digital right now? Today’s guide covers an activity I perform almost daily: Measuring A/B and MVT split tests within Analytics
Vincent Demay's insight:
It seams google analytics is one of the best tool for split testing

A/B testing is fun. With so many easy-to-use tools around, anyone can (and should) do it. However, there's actually more to it than just setting up a test.
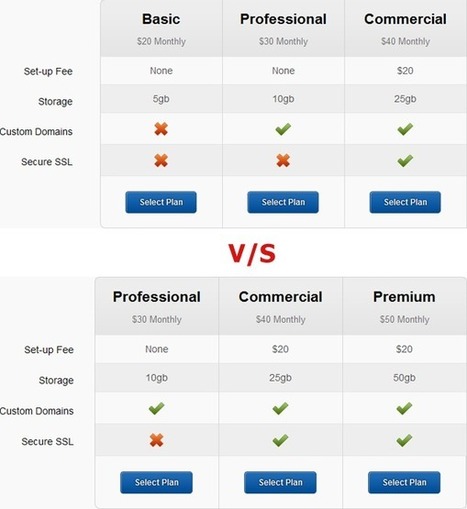
From
vwo

We are extremely proud to release a brand new feature in Visual Website Optimizer: Revenue Tracking. This is a significant new development for our product because it means now in addition to tracking conversion rate (for multiple goals such as clicks on links, visit to pages, form submissions, engagement, etc.), you can track various revenue metrics as well (including revenue per visitor, total revenue, average order value, etc.) Why you should track revenue in your split tests? Revenue tracking.
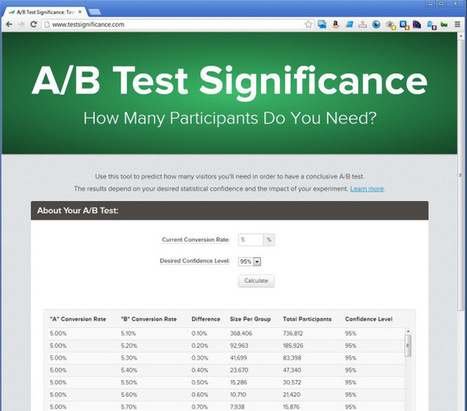
At RJMetrics, we believe in data-driven decisions, which means we do a lot of testing. However, one of the most important lessons we’ve learned is this: Not all tests are worth running. In a data-driven organization, it’s very tempting to say things like “let’s settle this argument about changing the button font with an A/B test!” Yes, you certainly could do that. And you would likely (eventually) declare a winner. However, you will also have squandered precious resources in search of the answer to a bike shed question. Testing is good, but not all tests are. Conserve your resources. Stop running stupid tests.
A demo of a work-in-progress tool for exploring the performance of "Bayesian Bandits" for solving the Multi-Armed Bandit problem

In a recent post, a company selling A/B testing services made the claim that A/B testing is superior to bandit algorithms. They do make a compelling case that A/B testing is superior to one particular not very good bandit algorithm, because that particular algorithm does not take into account statistical significance. However, there are bandit algorithms that account for statistical significance.
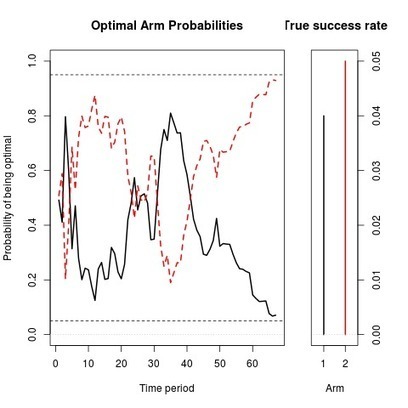
This article describes the statistical engine behind Google Analytics Content Experiments. Google Analytics uses a multi-armed bandit approach to managing online experiments.
|
From
moz
-Google is increasingly relying on machine learning and artificial intelligence, making ranking factors harder to understand, less predictable, and less uniform across keywords.
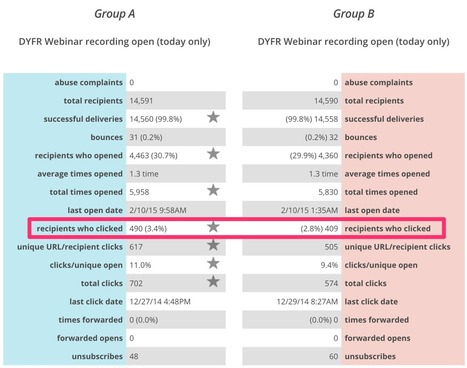
From
kadavy
There are few things wantrepreneurs (all due respect, I'm a recovering wantrepreneur myself) love to talk about more than running A/B tests. The belief seems
Fred's insight:
Must read if you consider running A/B tests and think this is easy stuff
Philippe Gassmann's insight:
En français, mais très instructifs ;)
This is a Bayesian formula. Bayesian statistics are useful in experimental contexts because you can stop a test whenever you please and the results will still be valid. (In other words, it is immune to the “peeking” problem described in my previous article, How Not To Run an A/B Test.) Usually, Bayesian formulas must be computed with sophisticated numerical techniques, but on occasion the math works out and you can say something interesting with a simple analytic formula. This is one of those occasions.

The chances are you are going to make mistakes. Some of these mistakes can cost you thousands of dollars. So before you start testing, make sure you avoid these mistakes
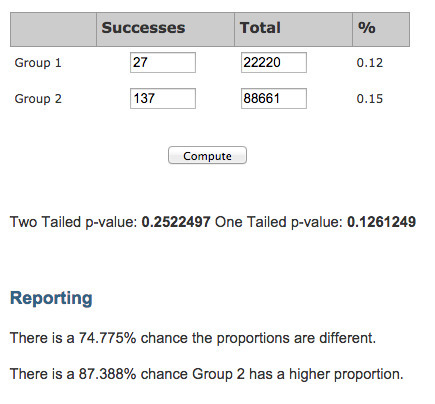
N-1 Two Proportion test for comparing independent proportions for small and large sample sizes

If you run A/B tests on your website and regularly check ongoing experiments for significant results, you might be falling prey to what statisticians call repeated significance testing errors. As a result, even though your dashboard says a result is statistically significant, there’s a good chance that it’s actually insignificant. This note explains why.
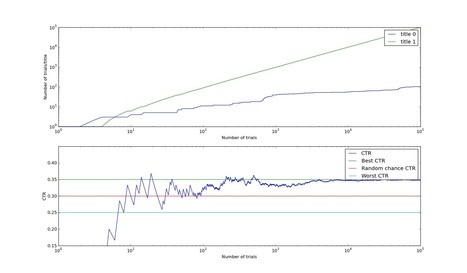
Great news! A murder victim has been found. No slow news day today! The story is already written, now a title needs to be selected. The clever reporter who wrote the story has come up with two potential titles - "Murder victim found in adult entertainment venue" and "Headless Body found in Topless Bar". (The latter title is one I've shamelessly stolen from the NY Daily News.) Once upon a time, deciding which title to run was a matter for a news editor to decide. Those days are now over - the geeks now rule the earth. Title selection is now primarily an algorithmic problem, not an editorial one. One common approach is to display both potential versions of the title on the homepage or news feed, and measure the Click Through Rate (CTR) of each version of the title. At some point, when the measured CTR for one title exceeds that of the other title, you'll switch to the one with the highest for all users. Algorithms for solving this problem are called bandit algorithms. In this blog post I'll describe one of my favorite bandit algorithms, the Bayesian Bandit, and show why it is an excellent method to use for problems which give us more information than typical bandit algorithms. Unless you are already familiar with Bayesian statistics and beta distributions, I strongly recommend reading the previous blog post. That post provides much introductory material, and I'll depend on it heavily.
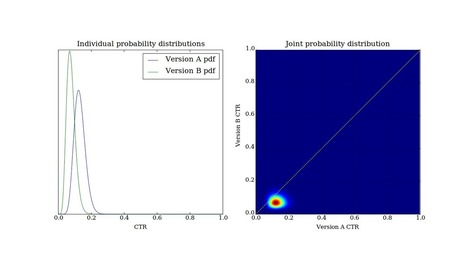
Here at BayesianWitch, we’re huge proponents of A/B testing. However, we’ve discovered that the normal method of A/B testing often confuses people. Some questions we commonly get include: How do you know how many samples to use? What P-value cutoff should you pick? 5%? 10%? How do you know what to choose for the null hypothesis? Mastering these concepts are the most critical parts of A/B testing, and yet we find them very unintutitve for the average hacker and marketer to use on a day to day basis. Another issue with standard A/B testing methods is the the issue of when to end the test. If you are dead certain version A is better than B, it’s great to end a test early. But standard statistical techniques don’t allow you to do this - once you gather the data and run the test, it’s over. For a deeper explaination, I strongly recommend reading Evan Miller’s seminal article How Not to Run an A/B Test.. (Side note - Ben Tilly has a Frequentist Scheme for addressing this problem.) These two factors make it difficult for real life marketers to long-term continue using the standard, frequentist technique. It makes sense to choose a method which is more intellectually intutive as well as one that has flexibility to end a test when the conclusion is obvious. The technique that is described in the rest of this post is the Bayesian technique which avoids these issues. Further, this testing model works extremely well, particuarly in many business situations where time is critical. I also want to emphasize that the method I’m describing is not untested. A version of it with slightly less accurate math was used at a large news site where I previously worked. A non-technical manager used this script to make changes to email newsletters. Each change provided a marginal (0.5-2%) increase in the conversion rate. But over a few months, he had nearly doubled the open rate and click through rate of the emails through implementing each change.
A/B testing is used far too often, for something that performs so badly. It is defective by design: Segment users into two groups. Show the A group the old, tried and true stuff. Show the B group the new whiz-bang design with the bigger buttons and slightly different copy. After a while, take a look at the stats and figure out which group presses the button more often. Sounds good, right? The problem is staring you in the face. It is the same dilemma faced by researchers administering drug studies. During drug trials, you can only give half the patients the life saving treatment. The others get sugar water. If the treatment works, group B lost out. This sacrifice is made to get good data. But it doesn't have to be this way.
|