Recent advances in deep learning have relied heavily on the use of large Transformers due to their ability to learn at scale. However, the core building block of Transformers, the attention operator, exhibits quadratic cost in sequence length, limiting the amount of context accessible. Existing subquadratic methods based on low-rank and sparse approximations need to be combined with dense attention layers to match Transformers, indicating a gap in capability. In this work, we propose Hyena, a subquadratic drop-in replacement for attention constructed by interleaving implicitly parametrized long convolutions and data-controlled gating. In recall and reasoning tasks on sequences of thousands to hundreds of thousands of tokens, Hyena improves accuracy by more than 50 points over operators relying on state-spaces and other implicit and explicit methods, matching attention-based models. We set a new state-of-the-art for dense-attention-free architectures on language modeling in standard datasets (WikiText103 and The Pile), reaching Transformer quality with a 20% reduction in training compute required at sequence length 2K. Hyena operators are twice as fast as highly optimized attention at sequence length 8K, and 100x faster at sequence length 64K.
With Vector search, Developers can store, index, and deliver search applications over vector representations of organizational data including text, images, audio, video, and more.
One of your pages that leverages the next/image component, passed a src value that uses a hostname in the URL that isn't defined in the images.remotePatterns in next.config.js.
Looking for some Open Source Headless CMS for managing your content? Well then, don’t worry. here we have gathered some of the best & Open-Source Headless CMS. In case you are not aware of CMS, it is…
Welcome to SendGrid’s Web API v3! This API is RESTful, fully featured, easy to integrate with, and offers support in 7 different languages. Libraries C# Go Java Node.js PHP Python Ruby Content-Type Header All responses are returned in JSON format.
This blog post explains how to mount Amazon S3 cloud storage to a local directory as a network drive and use Amazon S3 for file sharing without a browser.
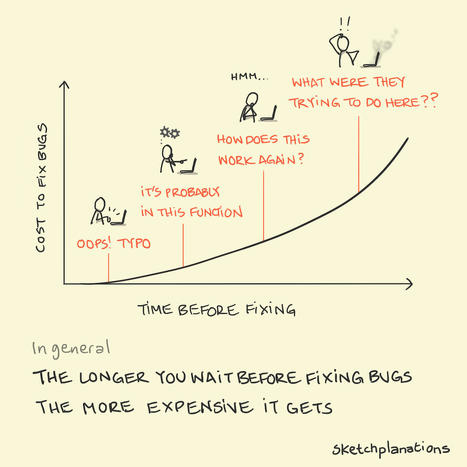
Just as mistakes and the unexpected are part of life, bugs are part of software development. In general, the longer the time between when a bug was first introduced and when the bug is identified and fixed the more expensive it is in both time and money. It might go something like this: If you spot a bug as you're writing a new feature everything is fresh in your mind and it can sometimes take just a moment to fix. If a bug turns up later or perhaps soon after it's deployed you might have an idea of where it might be and track it down fairly quickly. If a lot of time has passed since a feature was worked on and a bug is spotted or tackled then it might take a fair bit of time to figure out how everything works again before you can fix it. And if a really long time has passed then, aside from the cost of interrupting what you are otherwise working on, it may not even be clear what was intended by the original code, probably written by others, and there's a fair chance more has been built on top of the buggy code making it more complex and a bigger task to tackle. The only way to solve it may be stepping through and figuring out behaviour slowly and steadily line-by-line. You could probably replace 'bugs' with 'code' 'problems' or 'mistakes' in most scenarios. Aside from it matching my experience, Joel Spolsky gives a nice explanation in his classic article The Joel Test.
People keep asking me If I use Generative AI tools for coding and what I think of them, so this is my effort to put my thoughts in writing, so that I can send people here instead of having to repeat…
The byte-order mark ( BOM) is a particular usage of the special Unicode character code, ZERO WIDTH NO-BREAK SPACE, whose appearance as a magic number at the start of a text stream can signal several things to a program reading the text: the byte order, or endianness, of the text stream in the cases of 16-bit and 32-bit encodings; the fact that the text stream's encoding is Unicode, to a high level of confidence; which Unicode character encoding is used.
The byte-order mark (BOM) is a particular usage of the special Unicode character code, U+FEFF ZERO WIDTH NO-BREAK SPACE, whose appearance as a magic number at the start of a text stream can signal several things to a program reading the text:[1] the byte order, or endianness, of the text stream in...
From Cris Ippolite LinkedIn "According to new research from the University of Washington, Carnegie Mellon University, and Xi’an Jiaotong University. Researchers conducted tests on 14 large language models and found that OpenAI’s ChatGPT and GPT-4 were the most left-wing libertarian, while Meta’s LLaMA was the most right-wing authoritarian."
Bring visual scheduling to your appointment setting by embedding DayBack Calendar in Salesforce Flows. Show appointment slots that match your flow's criteria.
Quick links: Flags Verbs Functions Glossary Release docs Introduction¶ Miller is a command-line tool for querying, shaping, and reformatting data files in various formats including CSV, TSV, JSON, and JSON Lines.
The AWS Storage Gateway service added the Server Message Block (SMB) protocol to File Gateway, enabling file-based applications developed for Microsoft Windows to easily store and access objects in Amazon Simple Storage Service (S3).
To get content containing either thought or leadership enter:
To get content containing both thought and leadership enter:
To get content containing the expression thought leadership enter:
You can enter several keywords and you can refine them whenever you want. Our suggestion engine uses more signals but entering a few keywords here will rapidly give you great content to curate.


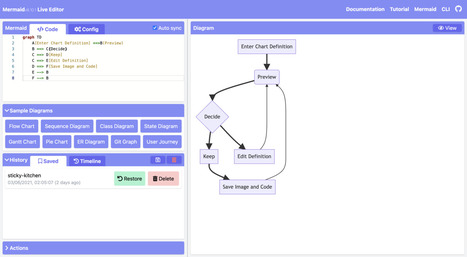


 Your new post is loading...
Your new post is loading...



![[2302.10866] Hyena Hierarchy: Towards Larger Convolutional Language Models | Developer Resources | Scoop.it](https://img.scoop.it/R3Nf-aV-zFCPDr3s1jV_-zl72eJkfbmt4t8yenImKBVvK0kTmF0xjctABnaLJIm9)









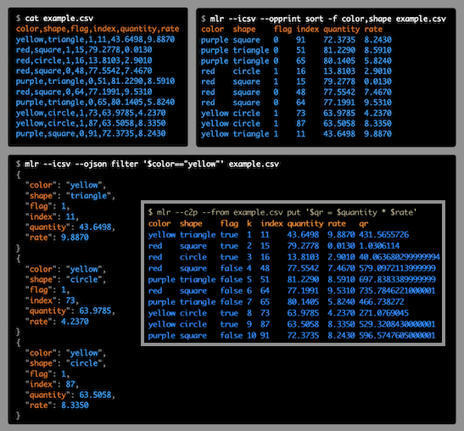






Nice library my brother shared with me.