Utilización de OCR en Google Drive
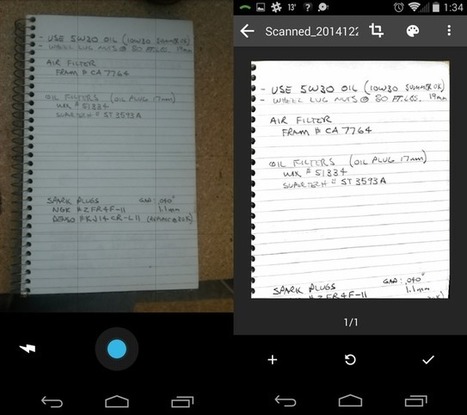
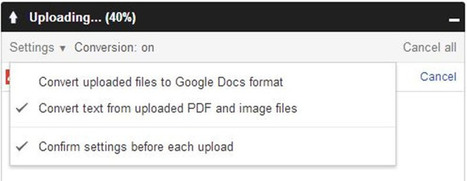
En Google Drive, tomamos los archivos PDF o de imagen que subes, los escaneamos y utilizamos algoritmos informáticos para transformarlos en documentos de Google Docs.
Para obtener los mejores resultados, los archivos PDF o de imagen deben cumplir unos requisitos determinados:
Resolución: los archivos de alta resolución funcionan mejor. Por norma general, recomendamos que cada línea de texto de los documentos tenga una altura de al menos 10 píxeles.
Orientación: solo se reconocen documentos con texto en horizontal de izquierda a derecha. Si has escaneado o capturado un documento con una orientación diferente, utiliza un programa de retoque y edición de imágenes para girarlo antes de subirlo a Google Drive.
Idiomas, fuentes y conjuntos de caracteres: nuestro motor de OCR es compatible con varios conjuntos de caracteres, pero la compatibilidad con caracteres no latinos es solo experimental de momento. Puedes seleccionar el idioma del documento en un menú desplegable. Obtendrás mejores resultados si el archivo utiliza fuentes habituales, como Arial o Times New Roman.
Calidad de imagen: las imágenes nítidas con iluminación regular y contraste claro funcionarán mejor. Los borrones por el movimiento o un enfoque incorrecto de la cámara reducirán la calidad de la detección de texto.
Limitaciones de tamaño de los archivos
El tamaño máximo de las imágenes (.jpg, .gif, .png) y los archivos PDF (.pdf) es de 2 MB. En el caso de los archivos PDF, solo examinaremos las primeras 10 páginas en busca de texto que extraer.
Preservación del formato de texto
Al procesar el documento, intentamos preservar el formato básico del texto, como la negrita y la cursiva, el tipo y el tamaño de fuente y los saltos de línea. Sin embargo, es difícil detectar estos elementos y quizás no podamos hacerlo siempre. Es probable que otros elementos de formato y estructura de texto, como las listas numeradas o con viñetas, las tablas, las columnas de texto, las notas a pie de página o las notas finales, se pierdan.



 Your new post is loading...
Your new post is loading...