
 Your new post is loading...
Your new post is loading...


L'Optical Character Recognition (en français on dit Reconnaissance Optique de Caractères), est une technologie qui permet de convertir en texte ses image ou des es documents imprimés qu'on a scanné.
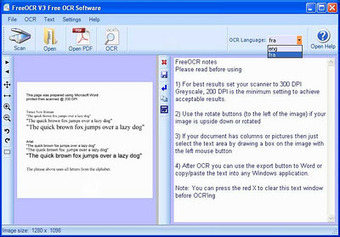
J'ai trouvé FreeOCR.net un freeware basé sur la technologie tesseract :
+ capable de lire les fichiers images et les fichiers PDF
+ gérant les scanners compatibles twain
+ pouvant convertir leur contenu en texte qu'on peut copier, en fichier texte ou en document Word.
De plus, on peut facilement lui rajouter des dictionnaires de conversion dans plusieurs langues.
On est certes loin de la précision de certains outils payant, mais après quelques test sur des fichier pdf et des scans, on gagne quand même pas mal de temps si on a beaucoup de textes à récupérer (par contre, il n'est pas possible de récupérer un tableau formaté)
le site de téléchargement : http://www.paperfile.net/
Les dicos (dont le français) : http://www.paperfile.net/ocr_lang.htm/