


The simple, stupid batch framework for Java. Tags: Projects, Job Scheduling. MIT licence.
Get Started for FREE
Sign up with Facebook Sign up with X
I don't have a Facebook or a X account


 Your new post is loading...
Your new post is loading... Your new post is loading...
Your new post is loading...
The simple, stupid batch framework for Java. Tags: Projects, Job Scheduling. MIT licence. 
No comment yet.
Sign up to comment

Got ETL? Meet the reader, processor, writer pattern. Along with all the pre-built implementations, scheduling, chunking and retry features you might need. I think those who are drawn to Spring Batch are right to use it. It's paradigm is sensible and encourages developers to design well and not to reinvent things. It is reliable, robust, and relatively easy to use. I have found, however, that many times people reach for Spring Batch as an excellent technical solution but completely miss the business impact. ETL jobs suck! Many businesses totally neglect the repercussions of copying and renaming data between all the systems in their company. To me, this kind of ETL reinforces bad data practices, delays meaningful standardization, and inhibits future analytics work. Extensive data duplication leads to data quality issues which often leads to added costs for master data management solutions. It's also very wasteful, especially if you are paying for lots of Oracle products. Don’t be that company that names tables in hipster speak (USR_CNTCT_INF) to cut down on data waste and then ETL everything all over your company! If you can get the job done with Spring Batch, you can get the job done in a similar read-process-write paradigm in just about any messaging framework. This encourages loose coupling and enables continuous data transfer (I avoid using the term real-time so as not to confuse with actual real-time systems). If you really miss the pre-built readers and writers, take a look at Apache Camel. Many features are easy to replicate in a streaming/messaging system. Scheduling? Who cares, it streaming. Retry? Make a retry queue. Failure and error handling? Dead letter queue. Partitioning? Just add more workers. The last example is actually much easier than in Spring Batch. There's also a whole host of stream processing and analytics capabilities you probably want out of your batch job but can't make sense of. Say you have to data loads that somehow need to be related. You now need a third batch job to do a join after the first two run. Plus this all requires scheduling or polling and much consideration over efficiency. Please don't be scared away from streaming or message systems. Please do not use Spring Batch solely because you are already doing badly at making batch jobs. Make the leap toward messaging. I don't want to disparage Spring Batch, it's great at what it does. I have just seen too many batch jobs that would be significantly better as streaming architectures. There's also a huge push these days behind event-streaming which is a topic for another post.
Mickael Ruau's insight:
Edit: I had completely forgotten that there is a relatively new area of the industry around “data engineering” to support data scientists and analysts. ETL to data engineers is more like bash scripts to most coders. It ought to work well just once or maybe periodically but generally doesn't require much effort. Data engineers help get huge amounts of data around their companies and will use Python or SQL or whatever gets the job done. There's also a completely different scale of “batch” jobs which is where tools like Spark, Flink, and MapReduce come in. These tools can also be used for significantly more complex processing and analysis in addition to just moving data around.
Not long ago, Spring was the main promoter of AOP technology and gave it its real place in the enterprise landscape. Recently and with the release of Spring-Batch, which is in his own as a framework the first one in this category for the java environment (I don’t know if there is any other equivalent in other platforms), Spring tends to promote one of the most powerful concepts in application development : Domain Driven Design.
Mickael Ruau's insight:
DDD emergence difficulties
![[Spring Batch] REX pour des batchs tombés trop tôt au combat – | Devops for Growth | Scoop.it](https://img.scoop.it/4wMAcjS-slFjc4B32h_3djl72eJkfbmt4t8yenImKBVvK0kTmF0xjctABnaLJIm9)
REX Spring Batch : J’ai développé précipitamment plusieurs batchs puis les ai envoyés au combat. Ils sont tombés, tous. Le coût de ma naïveté a été terrible, mais j’aimerais ici faire le bilan de ce que j‘ai appris de cette aventure. Certains points vous paraitront peut-être évidents mais si je n’ai pas su les anticiper je suppose que d’autres pourraient les éviter en me lisant.
Mickael Ruau's insight:
Eviter les NullPointerException“Je cherche l’information D. Mais si ! Celle dans l’objet C qui est dans l’objet B. D’ailleurs B et D sont optionnels… Bref trouve moi ça.” Ce genre de situation arrive souvent, je présente ici quelques pratiques que j’ai rencontrées, la dernière étant selon moi la meilleure :
1 2 3 4 5 6 7 8 9 10 /** * ATTENTION ! int i = getSafeDeep(() -> A.getI()) enverra une NPE si la méthode renvoie null. */ public static <T> T getSafeDeep(Supplier<T> supplier) { try { return supplier.get(); } catch (NullPointerException npe) { return null; } }
1 2 3 4 5 Optional.ofNullable(A) .map(A::getB) .map(B::getC) .map(C::getD) .orElse(null) //or any other default value

Several years ago, 2012 to be precise, I wrote an article on an approach to unit testing Spring Batch Jobs. My editors tell me that I still get new readers of the post every day, so it is time to revisit and update the approach to a more modern standard. The approach used in the original post was purely testing the individual pieces containing any business logic. Back then, we didn’t have some of the mocking capabilities that we have today, so I went with an approach that made sense at the time. However, there have been a few improvements in the past several years. One of those improvements has been the ability to Mock beans within a Spring Context. That’s where the @MockBean annotation comes to the rescue.
From
dzone

Big Data Sets’ Processing is one of the most important problem in the software world. Spring Batch is a lightweight and robust batch framework to proces

Introduction to the spring batch job configuring.Learn how a spring batch job will be run and how do we manage its metadata.
Mickael Ruau's insight:
3.1. JobLauncher Sequence DiagramSynchronous It is good for non-HTTP cases and straight-forward.
Asynchronous It is good for HTTP requests as we shouldn’t keep an HTTP request open for long.
Lorsque vous mettez en œuvre Spring Batch pour réaliser des traitements par lots, vous avez le choix d’utiliser une implémentation de JobRepository soit en mémoire soit persistante. L’avantage de cette dernière est triple :
La contrepartie d’utiliser un JobRepository persistant est de devoir faire reposer le batch sur une base de données relationnelles. Le schéma sur lequel s’appuie Spring Bath est composé de 6 tables. Leur MPD est disponible dans l’annexe B. Meta-Data Schema du manuel de référence de Spring Batch. SpringSource faisant bien les choses, les scripts DDL de différentes solutions du marché (ex : MySQL, Oracle, DB2, SQL Server, Postgres, H2 …) sont disponibles dans le package org.springframework.batch.core du JAR spring-batch-core-xxx.jar A moins de disposer de ressources infinies ou de n’avoir qu’un seul batch annuel, il est fréquent de fixer une durée de rétention de l’historique. Première option : demander à l’équipe d’exploitation de régulièrement lancer un script SQL de purge. Deuxième option : utiliser Spring Batch pour purger ses propres données !! Une Tasklet pour purger les donnéesDe base, Spring Batch n’offre pas cette fonctionnalité. Et sur le Jira de SpringSource, je n’ai pas trouvé de demandes d’évolutions allant dans ce sens. Dans le ticket BATCH-1747, Lucas Ward, commiteur Spring Batch, invite les personnes intéressées à passer par des requêtes SQL de suppression après désactivation des contraintes d’intégrité. Partant de ce constat, je me suis lancé dans l’écriture d’une tasklet permettant de ne conserver l’historique Spring Batch des N derniers mois. Surement perfectible, en voici le résultat
Mickael Ruau's insight:
Le code source de la classe RemoveSpringBatchHistoryTasklet et sa classe de tests unitaires sont disponibles sur le projet Github spring-batch-toolkit. Cette tasklet peut être utilisée de 2 manières :

In this post, we will create a simple Spring batch example to read the data from the CSV and write the same data to an XML file.
Mickael Ruau's insight:
From
spring
The dashboard offers a graphical editor for building data pipelines interactively, as well as views of deployable apps and monitoring them with metrics using Wavefront, Prometheus, Influx DB, or other monitoring systems.
Mickael Ruau's insight:
Getting StartedThe recently launched brand new Spring Cloud Data Flow Microsite is the best place to get started.

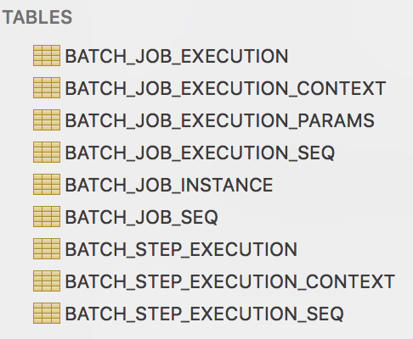
The Spring Batch Metadata tables closely match the Domain objects that represent them in Java. For example, JobInstance, JobExecution, JobParameters, and StepExecution map to BATCH_JOB_INSTANCE, BATCH_JOB_EXECUTION, BATCH_JOB_EXECUTION_PARAMS, and BATCH_STEP_EXECUTION, respectively. ExecutionContext maps to both BATCH_JOB_EXECUTION_CONTEXT and BATCH_STEP_EXECUTION_CONTEXT. The JobRepository is responsible for saving and storing each Java object into its correct table. This appendix describes the metadata tables in detail, along with many of the design decisions that were made when creating them.
Sommaire de la présentation :
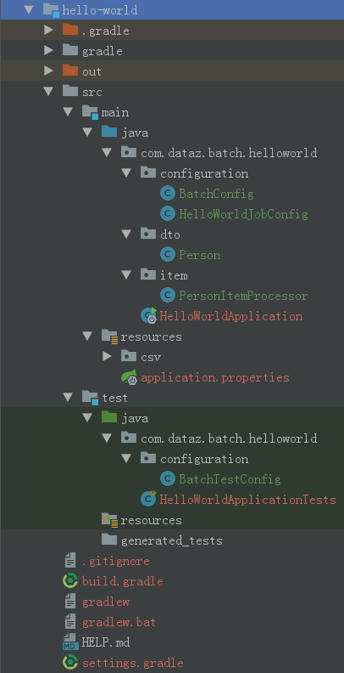
A typical general scenario of batch application is as follows:
Spring Batch automatically performs these batch iteration operations and provides the function of processing similar transactions. IT is usually processed in offline environment without any user interaction. Batch jobs are part of most IT projects, and Spring Batch is the only open source framework that provides powerful enterprise class solutions.
Mickael Ruau's insight:
Flexibility: Spring batch applications are very flexible. Just change the XML file to change the processing order in the application. Maintainability: Spring Batch applications are easy to maintain. The Spring Batch job includes steps. Each step can be separated, tested and updated without affecting other steps. Scalability: using partitioning technology, you can scale Spring Batch applications. These techniques allow you to perform the steps of a job in parallel. Execute a single thread in parallel. Reliability: in case of any failure, the operation can be restarted from the stopped place through the removal procedure. Support a variety of file formats: Spring Batch supports a large number of writers and readers such as XML, Flat file, CSV, MYSQL, Hibernate, JDBC, Mongo, Neo4j, etc. There are many ways to start the job: Web application, Java program, command line, etc. can be used to start the Spring Batch job. In addition, the Spring Batch application supports automatic retrying after failure. Track status and statistics during and after batch processing. Run parallel jobs. Some services, such as logging, resource management, skip and restart processing, etc.
|


De part ses possibilités, Spring-Batch requiert une configuration complexe qui au premier contact peut être assez repoussante. Ce premier batch est simpliste et très réducteur. Par exemple, l’utilisation des classes ResourcelessTransactionManager et MapJobRepositoryFactoryBean réduit considérablement les possibilités de Spring-batch. Néanmoins, j’espère que ce premier pas vous sera utile pour ensuite vous plonger dans ce framework en profondeur, et pouvoir ajouter au fur et à mesure les concepts et fonctionnalités que l’on trouvera dans la documentation et les exemples. L’exemple complet est disponible sur la forge publique Octo : minimal-spring-batch-sample
Mickael Ruau's insight:
Arnaud 05/10/2008 à 01:18 Spring Batch est effectivement une très bonne initiative. Par contre je reste dubitatif sur sa mise en oeuvre par les prods de nos cheres grandes entreprises. Le framework est assez lourd et necessite des bases de données et un queueur pour fonctionner sur une veritable prod avec tous les services (reprise, ..). N'est ce pas trop ?
Kerny 10/10/2008 à 11:06 Ce qui est séduisant pour certaines productions c'est l'analogie complète qu'il y a entre le framework Spring batch et les batchs MainFrame.
slim 03/11/2008 à 08:23 en effet kerny, cette analogie est due au fait que Spring a été développé en appliquant le Domain Driven Design; et ce language c'est equivalent a l'ubiquitous language du domaine des batchs.
Julien Jakubowski 22/01/2010 à 12:02 Bonjour, Les notions de JOBS:STEPS et autres reprises sont connus depuis 50 ansEn effet, ces termes sont repris volontairement dans Spring Batch. Les composants n’ont pas à connaître leur mode de scheduling , il sont appelés ou pas , s’ils sont appelés , il font leur JOB ( commit ou rollback ).En fait, c'est le cas des composants écrits avec Spring-batch : ils sont indépendants de la façon dont ils sont appelés, et ils peuvent être appelés par un scheduler comme par ex. $U ou Quartz. Spring Batch n'est pas un scheduler mais juste un framework de développement de batchs.
Jean-Philippe Briend 09/02/2010 à 15:20 Attention : Spring Batch n'est pas un ordonnanceur ! Il s'agit d'un framework de conception de traitements massifs. L'ordonnancement doit toujours se faire via Quartz ou d'autres solutions. De plus, Spring Batch est orienté sur une certaine philosophie qui ne convient pas à tous les traitements. http://blog.infin-it.fr/2010/02/03/spring-batch-les-pieges-a-eviter/
Il y a très peu de temps chez l’un de nos clients, nous avons été confrontés à une problématique typique dans le quotidien de la plupart des développeurs : la performance. Au sein du projet, nous avions des traitements batch responsables de l’intégration d’une importante quantité de données. Le problème : les traitements étaient trop lents. Il s’agissait d’une nouvelle application qui devait être déployée en production pour la première fois. Le client utilisait une méthodologie Cycle en V classique et ces problèmes ont été détectés pendant les tests de performance en pré-production. Comme les temps d’exécution étaient élevés, le passage en production était compromis. Dans ce contexte, un collègue et moi-même sommes intervenus pour analyser le problème et essayer d’optimiser les traitements.
Mickael Ruau's insight:
ConclusionÀ la fin de l’optimisation, nous sommes passés d’environ 10h à 2h30. En analysant les améliorations que nous avions apportées, nous nous sommes rendu compte que nous n’avons rien fait d’extraordinaire ou compliqué. Au contraire, nous avons surtout enlevé des choses qu’il y avait en trop et dont les traitements n’avaient pas besoin. En revanche, nous avons ajouté ou modifié des éléments que nous avons jugé plus adaptés à la problématique en question. Finalement, il est clair qu’il n’y a pas de gagnant entre une HashMap et un cache Ehcache. Tout dépend du contexte et de ce que l’on veut faire. Dans notre contexte en particulier, nous n’avions pas besoin d’une solution plus complexe de cache comme Ehcache. Un simple HashSet a suffi.
Comme indiqué dans son manuel de référence, Spring Batch propose nativement 4 techniques pour paralléliser les traitements :
Pour optimiser le batch, 2 de ces techniques ont été utilisées.
Mickael Ruau's insight:
Pour un effort minime, à peine quelques heures de développement, la durée d’exécution du batch a baissé de 33%, avec un débit avoisinant les 5 000 documents par secondes indexés dans ElasticSearch. Pourquoi donc s’en priver ? La documentation Spring Batch doit être attentivement suivie pour ne pas tomber dans certains pièges liés à la parallélisassion. La documentation officielle, le livre Spring Batch in Action et maintenant ce billet devraient être des sources suffisantes pour comprendre et mettre en œuvre aux moins 2 des techniques proposées nativement par Spring Batch : Parallel Steps et Partitioning a Step.
From
dzone
Many enterprise applications require batch processing to process billions of transactions every day. These big transaction sets have to be processe

Quick tutorial: scaling Spring Batch by partitioning a step so that the step has several threads that are each processing a chunk of data in parallel.
Spring Batch Example, Spring Batch Tutorial, Spring Batch ItemReader, ItemProcessor, ItemWriter, FieldSetMapper, spring batch maven, read csv file, xml file
Mickael Ruau's insight:
Before going through spring batch example program, let’s get some idea about spring batch terminologies.

From
medium
Batch processing is a technique which process data in large groups (chunks) instead of single element of data. This is used to process high-volumes of data and do any modifications before processing…
Mickael Ruau's insight:
Spring batch is an opensource batch processing framework which is provided by spring.
Spring Batch IntroductionTo help design and implement batch systems, basic batch application building blocks and patterns should be provided to…docs.spring.io How Batch processing works…..?Above is a basic structure of the spring batch. This is structured considering a normal batch processing architecture. Let’s see how each of these components works in spring batch. JobRepository — This manages the process or the condition of Job and Step. All the management data is stored to the spring batch tables in the database which are specified by spring batch JobLauncher — A simple interface for running a Job, and all possible ad-hoc executions. JobLauncher can be directly used by the user. But this won’t make any guarantee about whether its executed synchronously or asynchronously. It will depend on the implementation of the process. Job — Single execution unit that defines the series of how the process works. Job is an explicit abstraction which represents the configuration of a job specified by a developer. Step —Step is the processing unit of the Job, a Job can contain one or more steps depending on the logic we defines, Which we can define as chunk model or tasklet model. Same as a Job, Step is meant to explicitly represent the configuration of a step by a developer. ItemReader, ItemProcessor, ItemWriter — ItemReader and ItemWriter are the components that reads and writes data, convert data and files to Java objects and vice versa. And we can use ItemProcessor to process these data in between read and write, we can introduce any of the business logic and data conversions etc.
![Spring batch meta data tables [Scripts to create spring batch meta data tables in oracle] | Devops for Growth | Scoop.it](https://img.scoop.it/dCtJE7RHLYWZTpxNlBm0Kzl72eJkfbmt4t8yenImKBVvK0kTmF0xjctABnaLJIm9)
Provides java,spring,spring boot,spring batch,spring cloud,spring microservice hibernate,java 8,core java tutorial with examples
Spring Batch Admin provides a web-based user interface that features an admin console for Spring Batch applications and systems. It is an open-source project from Spring.
Mickael Ruau's insight:
NOTE: Spring Batch Admin will be moving into the Spring Attic with an end of life date to be December 31, 2017. The functionality of Spring Batch Admin has been mostly duplicated and expanded upon via Spring Cloud Data Flow and we encourage all users to migrate to that going forward. Documentation on that migration process can be found in the Spring Batch Admin Github repository here.
Pour rappel, Spring Batch Admin est une console de supervision des traitements par lots implémentés avec Spring Batch. En plus d’un frontal web, elle offre une API JSON et expose des métriques via JMX. Ouvert aux extensions, Spring Batch Admin a tout pour devenir un véritable serveur de batchs : monitoring, chargement et mise à jour à chaud de la configuration des jobs, ordonnancement, exécution de jobs sur réception de fichiers …
Mickael Ruau's insight:
From
dzone
In this post, we look at how to use Spring Batch and the Quartz Scheduler to run large amounts of data on your applications with job-processing statistics.
Mickael Ruau's insight:
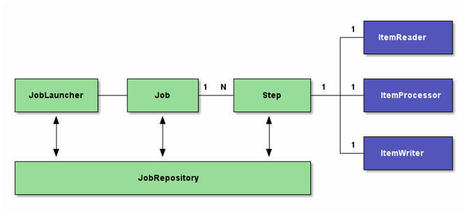
The above diagram represents a Spring Batch flow. As can be seen here, we have several modules. Let's go one-by-one through each module. 1. JobRepository: This represents the persistence of batch meta-data entities in the database.It acts as a repository that contains batch jobs' information, for example, when the last batch job was run, etc. 2. JobLauncher: This is an interface used to launch a job or run jobs when the jobs' scheduled time arrives. It takes the jobs name and some other parameters while launching or running the job. 3. Job: This is the main module, which consist of the business logic to be run. 4. Step: Steps are nothing but an execution flow of the job. A complex job can be divided into several steps or chunks, which can be run one after another or ran depending on the result of the previous steps. 5. ItemReader: This interface is used to perform bulk-reading of data, e.g. reading several lines of data from an Excel file when a job starts 6.ItemProcessor: When the data is read using itemreader, ItemProcessor can be used to perform the processing of data, depending on the business logic. 7. ItemWriter: This interface is used to write bulk data — either to a database or any other file disks. This article gives some basic understanding of Spring Batch. Many of the real-world applications use Spring Batch with Quartz triggers to perform their batch operations. I will give you a little idea here about what is actually running Spring Batch using Quartz.
|





Easy Batch is a framework that aims at simplifying batch processing with Java. It was specifically designed for simple, single-task ETL jobs. Writing batch applications requires a lot of boilerplate code: reading, writing, filtering, parsing and validating data, logging, reporting to name a few.. The idea is to free you from these tedious tasks and let you focus on your batch application's logic.
How does it work?
Easy Batch jobs are simple processing pipelines. Records are read in sequence from a data source, processed in pipeline and written in batches to a data sink:
The framework provides the Record and Batch APIs to abstract data format and process records in a consistent way regardless of the data source/sink type.
Let's see a quick example. Suppose you have the following tweets.csv file:
id,user,message 1,foo,hello 2,bar,@foo hi!and you want to transform these tweets to XML format. Here is how you can do that with Easy Batch:
Path inputFile = Paths.get("tweets.csv"); Path outputFile = Paths.get("tweets.xml"); Job job = new JobBuilder<String, String>() .reader(new FlatFileRecordReader(inputFile)) .filter(new HeaderRecordFilter<>()) .mapper(new DelimitedRecordMapper<>(Tweet.class, "id", "user", "message")) .marshaller(new XmlRecordMarshaller<>(Tweet.class)) .writer(new FileRecordWriter(outputFile)) .batchSize(10) .build(); JobExecutor jobExecutor = new JobExecutor(); JobReport report = jobExecutor.execute(job); jobExecutor.shutdown();This example creates a job that:
At the end of execution, you get a report with statistics and metrics about the job run (Execution time, number of errors, etc). All the boilerplate code of resources I/O, iterating through the data source, filtering and parsing records, mapping data to the domain object Tweet, writing output and reporting is handled by Easy Batch. Your code becomes declarative, intuitive, easy to read, understand, test and maintain.