Your new post is loading...
Your new post is loading...

|
Scooped by
Mickael Ruau
December 7, 2021 4:52 AM
|
Let's take an example of, you have a nice idea that we can trade in the stock market based on tweets, which is possible. It's just going to be hard to do that at scale because a lot of tweets, we don't know what it means. Say we have a startup, and that's our product. We need investors, and we tell them, we're just constantly scouring the web, getting tweets, making trades. We need to move fast because we're a startup. We're also very poor, but we're smart. It's going to be a central theme of this talk. We're very smart so we could do dangerous things. Basically, this just means you have a machine that takes tweets, takes a bunch of data, and then gets you money out of it by trading.
|
|
Scooped by
Mickael Ruau
June 2, 2021 7:46 AM
|
Dans ce premier eMag, nous parlerons DevOps : un retour d'expérience de Déploiement Continu avec intérêts et difficultés rencontrés, ainsi qu'une perspective complémentaire autour de l'Intégration Continue, suivi d'un éclairage sur le tuning de performance et ses caractéristiques dans l'environnement actuel. Et pour finir, la gestion des logs avec une critique de LogStash Book.
|
|
Scooped by
Mickael Ruau
November 16, 2020 3:00 AM
|
Avez-vous déjà mis en place des tests sur un projet qui n'en avait aucun ? Du multi-tenant sur un produit mono-tenant ? Un outil d'analyse statique de code sur un projet bien avancé ? C'est (très) douloureux, n'est-ce pas ?
|
|
Scooped by
Mickael Ruau
November 4, 2019 8:26 AM
|
This group of numbers is from Brett Slatkin in Building Scalable Web Apps with Google App Engine. Writes are expensive! - Datastore is transactional: writes require disk access
- Disk access means disk seeks
- Rule of thumb: 10ms for a disk seek
- Simple math: 1s / 10ms = 100 seeks/sec maximum
- Depends on:
* The size and shape of your data
* Doing work in batches (batch puts and gets)
Reads are cheap! - Reads do not need to be transactional, just consistent
- Data is read from disk once, then it's easily cached
- All subsequent reads come straight from memory
- Rule of thumb: 250usec for 1MB of data from memory
- Simple math: 1s / 250usec = 4GB/sec maximum
* For a 1MB entity, that's 4000 fetches/sec
|
|
Scooped by
Mickael Ruau
November 4, 2019 8:13 AM
|
Le dernier numéro des Communications of the ACM [1] (CACM) contient un article intitulé Attack of the Killer Microseconds écrit par des ingénieurs de Google, dont David Patterson, qui fut dans des vies antérieures professeur à Berkeley, architecte principal des processeurs SPARC de Sun Microsystems et co-auteur avec John Hennessy (architecte principal des processeurs MIPS et actuel président de l’université Stanford) du manuel de référence sur l’architecture des ordinateurs (pour dire qu’il ne s’agit pas d’élucubrations d’amateurs). (...) Ces problèmes de temps de latence pénalisants surgissent aujourd’hui parce que des événements qui étaient relativement rares dans les traitements d’hier (appel de procédures à distance, déplacement de machine virtuelle par exemple) sont désormais au cœur des architectures de traitement de données. Tant que ces événements étaient rares, les architectes de système adoptaient des solutions simples, telles que, simplement, attendre la fin de l’action, mais dès lors que ces événements sont fréquents la pénalité encourue devient de moins en moins supportable. Pour alléger ces pénalités, nos auteurs suggèrent de concevoir à nouveaux frais des optimisations pour les mécanismes de bas niveau, tels que contention de verrou et synchronisation. Les spécialistes du calcul à haute performance (HPC) se sont confrontés à ces problèmes depuis longtemps, mais les solutions qu’ils ont adoptées ne répondent pas forcément très bien aux questions actuelles, parce qu’ils travaillaient généralement dans un contexte où les contraintes économiques étaient faibles, ce qui n’est pas le cas des grands centres de données d’aujourd’hui. De surcroît, les logiciels déployés par les grands opérateurs tels que Google et Amazon évoluent rapidement, ce qui impose des méthodes de génie logiciel rigoureuses et simplificatrices, impératif ignoré du monde HPC. Des solutions doivent également être cherchées du côté des processus légers, du parallélisme à grain fin, de la gestion plus efficace des files d’attente, etc. Je ne puis mieux faire que vous recommander la lecture de cet article.
|
|
Scooped by
Mickael Ruau
September 3, 2018 9:11 AM
|
Suite à une demande d’évolution que vous avez développée, les temps de chargements de votre application ont augmenté ? Les régressions se sont multipliées et la qualimétrie s’est affolée ? Si tel est le cas, votre application vient sans doute d’éprouver les limites de sa conception CRUD (Create/Read/Update/Delete) et de ses implications en termes de gestion de la modélisation du métier complexe et en termes de scalabilité. Cette modélisation, pourtant simple à mettre en place et à transmettre, peut devenir un réel frein à l’agilité globale de l’application, tant bien du point de vue technique que métier. Parmi les axes de travail qui vont permettre de rétablir une délivrabilité optimale et d’améliorer les performances et l’évolutivité des applications, nous traitons dans ce livre blanc de deux motifs architecturaux.
|
|
Scooped by
Mickael Ruau
February 26, 2018 5:05 AM
|
L'outil logiciel de test de charge Micro Focus LoadRunner vous permet d'analyser et d'éviter les problèmes de performances des applications et de détecter les goulots d'étranglement avant le déploiement ou la mise à niveau.
|
|
Scooped by
Mickael Ruau
February 26, 2018 5:02 AM
|
HPE LoadRunner est un outil de test logiciel de Hewlett-Packard Enterprise. En septembre 2016, HPE annonçait la vente de ses logiciels d'entreprise, y compris les produits Mercury, à Micro Focus. Il est utilisé pour tester les applications, mesurer le comportement système et la performance en charge.
|
|
Scooped by
Mickael Ruau
January 20, 2018 5:16 AM
|
Utilizing Resource Monitor, Performance Monitor and the Worker Processes IIS utility to track down App hangs and unresponsiveness on dedicated and cloud servers
|
|
Scooped by
Mickael Ruau
October 26, 2017 3:48 AM
|
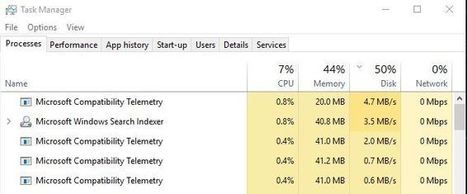
Using telemetry built into Windows 10, Microsoft tries to improve the features. Here is how to Fix Microsoft Compatibility Telementary High Disk Usage.
|
|
Scooped by
Mickael Ruau
June 13, 2017 2:46 AM
|
Pour bien comprendre de quoi il retourne, appuyons-nous sur l'exemple d'un test de charge réalisé par Aftab Alam d'Infosys avec SOASTA pour la simulation de charge, et Dynatrace pour l'analyse des performances de l'application à charge constante.
|
|
Scooped by
Mickael Ruau
December 26, 2016 9:59 AM
|
Description de l'architecture web "idéale" pour le développement d'une application web en 2015. Mise en lumière des best practices de développement web pour la performance.
|
|
Scooped by
Mickael Ruau
May 15, 2016 2:29 PM
|
L’ordonnanceur d’un système d’exploitation est une partie cruciale pour la performance. Il décide de l’affectation des fils d’exécution aux différents cœurs et processeurs d’une machine afin d’utiliser au mieux la machine à disposition, tout en garantissant une certaine réactivité pour les applications qui en ont besoin (notamment les interfaces graphiques : elles ne peuvent pas rester plusieurs minutes sans pouvoir exécuter la moindre instruction, car elles ne peuvent alors pas répondre
|
|
|
Scooped by
Mickael Ruau
December 7, 2021 4:50 AM
|
General solutions are great, because they are general. They work in all situations. This generality comes at a cost. What I'm going to do is to encourage you to embrace your inner snowflake, find out what's really your problem, and solve just that. As one who has been responsible for more bugs than I'd care to admit, I'm highly biased towards picking solutions with low complexity, both in terms of implementation and maintenance.
|
|
Scooped by
Mickael Ruau
May 20, 2021 3:40 AM
|
Le langage de programmation Python dispose déjà de nombreux moyens de s'exécuter plus rapidement, qu'il s'agisse des runtimes d'exécution alternatifs comme PyPy ou de modules écrits en C/C++. Mais presque aucune de ces méthodes n'implique l'accélération de CPython lui-même – l'implémentation de référence de Python, écrite en C, qui est la version la plus largement utilisée du langage. Lors du Python Language Summit qui s'est tenu au PyCon 2021 la semaine dernière, le créateur du langage Python
|
|
Scooped by
Mickael Ruau
July 8, 2020 4:24 AM
|
En algorithmique, la complexité en espace est une mesure de l'espace utilisé par un algorithme, en fonction de propriétés de ses entrées. L'espace compte le nombre maximum de cases mémoire utilisées simultanément pendant un calcul. Par exemple le nombre de symboles qu'il faut conserver pour pouvoir continuer le calcul.
|
|
Scooped by
Mickael Ruau
November 4, 2019 8:24 AM
|
Operation Time (nsec) L1 cache reference 0.5 Branch mispredict 5 L2 cache reference 7 Mutex lock/unlock 25 Main memory reference 100 Compress 1KB bytes with Zippy 3,000 Send 2K bytes over 1 Gbps network 20,000 Read 1MB sequentially from memory 250,000 Roundtrip within same datacenter 500,000 Disk seek 10,000,000 Read 1MB sequentially from disk 20,000,000 Send packet CA -> Netherlands -> CA 150,000,000 Some useful figures that aren’t in Dean’s data can be found in this article comparing NetBSD 2.0 and FreeBSD 5.3 from 2005. Approximating those figures, we get: Operation Time (nsec) System call overhead 400 Context switch between processes 3000 fork() (statically-linked binary) 70,000 fork() (dynamically-linked binary) 160,000
|
|
Scooped by
Mickael Ruau
August 5, 2019 4:52 AM
|
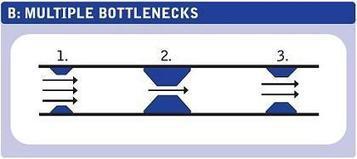
When You're Out to Fix Bottlenecks, Be Sure You're Able to Distinguish Them From System Failures and Slow Spots
|
|
Scooped by
Mickael Ruau
July 13, 2018 7:41 AM
|
La spécification W3C Server Timing est destinée à envoyer des informations complémentaires dans des en-têtes HTTP, notamment pour le suivi de la performance côté serveur. On connaît déjà bien les outils de développement navigateur (F12) et les onglets relatifs au réseau (ou Network). Ceux-ci affichent tous les timings relatifs au côté front-end, c'est-à-dire tout ce que le navigateur peut réunir comme statistiques : le temps nécessaire pour les échanges réseau, l'interprétation des codes HTML, CSS, JavaScript, l'affichage, etc. Il est désormais possible d'y afficher aussi des informations provenant de temps de traitement côté serveur, par exemple : - Accès aux fichiers
- Connexion à la base de données
- Exécution de requêtes
- Interrogation du cache
- Traitements lourds divers et variés
|
|
Scooped by
Mickael Ruau
February 26, 2018 5:03 AM
|
Comparaison NeoLoad et LoadRunner : moins cher, permet de tester 5 à 10 fois plus vite, et supporte mieux les technologies web et mobiles.
|
|
Scooped by
Mickael Ruau
January 27, 2018 5:20 AM
|
Internet Information Services (IIS) expose de nombreux paramètres de configuration qui affectent les performances d’IIS.Cette rubrique décrit plusieurs de ces paramètres et fournit des indications générales pour définir les valeurs de paramètre pour améliorer les performances d’IIS.
|
|
Scooped by
Mickael Ruau
December 21, 2017 7:58 AM
|
Chers membres du club,J'ai le plaisir de vous proposer ce livre sur DevOps : la gestion des performances de l'application pour les nuls.
Les applications ne sont plus conçues dans un processus métier monolithique, mais comme un ensemble de services modulaires, comme des microservices stockés dans des conteneurs. Chaque service inclut une API bien définie, utilisée pour lier les éléments ensemble, afin de pouvoir créer de nouvelles applications suivant les désirs du client
|
|
Scooped by
Mickael Ruau
October 24, 2017 9:49 AM
|
Full Stack Web Performance Modern websites rely on optimized web performance to deliver apps. Yet the same digital technologies that make it possible to accelerate growth has also transformed the roles of software engineers and IT organizations. Ops roles may be now DevOps or DevSecOps. How do they work together and ensure how to manage availability across the enterprise?
|
|
Scooped by
Mickael Ruau
April 19, 2017 9:07 AM
|
Eventually, every website fails. If it's a household-name site like Amazon, then news of that failure gets around faster than a rocket full of monkeys. That's …
|
|
Scooped by
Mickael Ruau
September 22, 2016 4:30 AM
|
Applications métiers : Le cabinet de conseil toulousain Quadran a annnoncé en début de mois la sortie d'appYuser, une offre de mesure de la performance et de l
|










![[HPC] Pour des chercheurs, « une décennie de cœurs perdue » par Linux, quelques modifications améliorent la performance d'un facteur jusque 137 | Devops for Growth | Scoop.it](https://img.scoop.it/ADBtv8BQUpqIzoHGHtsNTTl72eJkfbmt4t8yenImKBVvK0kTmF0xjctABnaLJIm9)