 Your new post is loading...
Your new post is loading...
8 Version Control Best Practices
Here are 8 of the most critical version control best practices.
Commit Changes Atomically
One best practice is to commit changes atomically in version control.
All files in a commit are either committed together or not at all. No other user should see partial or incomplete changes.
A check-in is similar to a database transaction described by its ACID properties:
Atomic.
Consistent.
Isolated.
Durable.
Commit all files that belong to a task in a single operation to keep the project consistent at all times.
It's critical to apply best practices to commits. Good-quality commits will improve your project, making you more productive and successful.
Commit Files With a Single Purpose — Not as a Backup
Another best practice is committing files with a single purpose.
Each commit should have a single purpose. For example, fixing a bug or adding a new feature. If a single change makes multiple independent changes to your project, it can become difficult to read and to review. Backing out one of these changes then becomes more complex and unnecessarily time-consuming.
Remember: A commit is not a backup of your current state of your local files, even if it occurs at the end of the day.
By breaking down a larger task into smaller chunks, you can more readily understand and review the intent of changes. For example, you could break a task into infrastructure and refactoring tasks before making user-visible changes. Keeping the scope narrow also makes it easier to back out a bad commit.
Write Good Commit Messages
Another commit best practice is to write good commit messages.
Each commit should have a description that explains the why — but not necessarily the how — regarding the change. (How is usually deducible by comparing the file contents before and after the change.)
A good commit message makes it easier for a reviewer — and you — to understand the purpose of the commit later. A good commit message also references the issue ID(s) — or even the requirement ID(s) — that the commit addressed (if applicable).
Don’t Break Builds
Another version control best practice is to avoid breaking builds by doing complete commits.
Provide test cases and at least stubs for new APIs. This ensures every commit is usable by any other member in the team without breaking their build.
A complete commit is easier to propagate between branches. An incomplete commit of an API, for example, might build locally in your work area and pass all tests. But it could break in another team member’s work area.
Working as a Version Control Focal Point
Moving on, I learned a lot during my time as a version control focal point. So things were learned from good experiences; others, not so much.
Good Experiences
You should rename files and directories via the version control system. This way, the physical file is not replicated to the server. Additionally, the full history is preserved and can be seen in a graph.
You can merge a hotfix from one version to another via the version control merge feature.
This is also commonly used for hotfix rollups.
Putting version related files which are often changed under version control.
Less Good Experiences
You should not submit a few non-related changes in one change list. This caused a mess. When only one of the changes had to be merged to a different version, it was going to be hard, time-wasting, manual work.
Don't save a lot of work locally without submitting for a long time. Note: sometimes, this is caused by developers avoiding opening development versions.
It's a bad idea to put files in version control that aren't recommended to be there, like generated files from the build process and large binary files that are not changed.
In summary, the version control system is here to help developers, and when used properly, it can be very helpful.
In the first part of the case-study, we looked at the difficult conditions the team lived in. That was more to do with technical processes they used for handling multiple projects at the same time. This part focuses on how they moved on from the branch merge hell they lived in.
== Part 2==
It was evident that the code branches just postponed the pain. That pain would eventually become huge but difficult-to-deal-with after a couple of months.
Over time, the team realized two things from the Continuous Integration (CI) philosophy (yes, I call it a philosophy).
If it’s hard to do something, you are not doing it often enough!
If delta is small, so is the risk.
The team had a hard time in merging feature branches with mainline. That just meant, the team was not doing the code-merge often enough.
Moving to Trunk Based Development
After lots of analysis and experiments, the team decided to move towards trunk-based development. They stopped creating feature branches for new projects and started working on the trunk only. The merge-pain in this approach, though multiple times every day, was relatively small. The team would sort them out through active collaboration.
The idea is to let developers develop and push code in the trunk at regular intervals. That works only when the code has a safety net around.
The OOD principles of reuse-release equivalence, common closure, and common reuse are all about the appropriate granularity of packages of classes. We wish to investigate the corresponding granularity of packages of evolution within a version control environment. We can consider the scope and granularity of a change, a baseline, a codeline, and beyond. In either case, both (re)use and release imply reuse by some consumer and releasing to some target consumer. Once again, the notion of abstractness in OOD translates to the level of visibility of versioned content that will play a key role.
In version control, the reuse of changes and versions occurs when we view or update (merge/modify) a version of one or more files in our workspace in order to develop, build, test and release our changes. The release of changes and versions occurs when we commit changes to a codeline, transfer changes between codelines, baseline a configuration, or promote a configuration to a new promotion-level. Based on this, we already know a few things about change granularity:
The granule of change is not an individual file/checkout, but is rather a single development task that holds changes we then commit to the codeline.
The granule of baselining and promotion is not an individual change but is, instead, the unit of integration for building and testing the component or product undergoing change on the codeline, which is the configuration.
The granule of progressive collaboration and evolution is the codeline
Not all of the above require principles. Furthermore it’s not apparent that each of these three OOD principles will translate to individual version control principles. Instead, we want to see if we can apply these three principles together as a group for each of changes, baselines, and codelines.
Package Coupling - Change-Flow
The package coupling principles of OOD translate almost directly to version-control, with only slight modification. Sometimes dependency translates into flow, but note that change-flow does not imply dependency. These deal with branching, merging, and the flow and structure of changes across codelines.
What's Next?
Now that we've set the stage and introduced the players, we will exit the stage until next month, when we try to directly apply our translations to each of the different types of version control containers: changes/workspaces, baselines, and codelines. We're very interested in your feedback on these ideas and our initial mapping of them into the version-control domain. So if you have some insights to share, please let us know.
With Git platforms like Bitbucket, GitLab, GitHub, Azure DevOps offered on the cloud, it is now easier than ever to create code repositories on a platform that you prefer. Devbridge can help to choose the right platform in an unbiased way.
Git Flow Pros and Cons
As you can see, doing pull requests might not always be the best choice. They should be used where appropriate only.
When Does Git Flow Work Best?
When you run an open-source project.
This style comes from the open-source world and it works best there. Since everyone can contribute, you want to have very strict access to all the changes. You want to be able to check every single line of code, because frankly you can’t trust people contributing. Usually, those are not commercial projects, so development speed is not a concern.
When you have a lot of junior developers.
If you work mostly with junior developers, then you want to have a way to check their work closely. You can give them multiple hints on how to do things more efficiently and help them improve their skills faster. People who accept pull requests have strict control over recurring changes so they can prevent deteriorating code quality.
When you have an established product.
This style also seems to play well when you already have a successful product. In such cases, the focus is usually on application performance and load capabilities. That kind of optimization requires very precise changes. Usually, time is not a constraint, so this style works well here. What’s more, large enterprises are a great fit for this style. They need to control every change closely, since they don’t want to break their multi-million dollar investment.
When Can Git Flow Cause Problems?
When you are just starting up.
If you are just starting up, then Git flow is not for you. Chances are you want to create a minimal viable product quickly. Doing pull requests creates a huge bottleneck that slows the whole team down dramatically. You simply can’t afford it. The problem with Git flow is the fact that pull requests can take a lot of time. It’s just not possible to provide rapid development that way.
When you need to iterate quickly.
Once you reach the first version of your product, you will most likely need to pivot it few times to meet your customers’ need. Again, multiple branches and pull requests reduce development speed dramatically and are not advised in such cases.
When you work mostly with senior developers.
If your team consists mainly of senior developers who have worked with one another for a longer period of time, then you don’t really need the aforementioned pull request micromanagement. You trust your developers and know that they are professionals. Let them do their job and don’t slow them down with all the Git flow bureaucracy.
How to choose the right branching strategy for your project
L'on estime que les développeurs restent cantonnés à leur utilisation de base. Il existerait plusieurs explications à ce problème, mais les plus citées dans la communauté sont : Git est déroutant et difficile à prendre en main ; les débutants se jettent sur les outils GUI pour Git, etc. Dans un billet de blogue la semaine dernière, Dragos Barosan, un développeur, donne son avis sur ce problème.
Selon lui, si les utilisateurs ont une connaissance limitée de Git et le trouvent déroutant, c'est parce qu'ils n'explorent pas ou n'apprennent pas en profondeur le système de contrôle de version. Barosan donne l'exemple de nouvelles fonctionnalités introduites dans la version 2.23 du logiciel, notamment "switch" et "restore", pour tenter de réduire les agacements que pourrait engendrer la commande "git checkout". Ces commandes seraient très peu populaires. Il estime que "git checkout" est l'une des nombreuses raisons pour lesquelles les nouveaux arrivants trouvent Git déroutant. L'effet de "git checkout" dépend du contexte.
La notion de commits atomiques est souvent méconnue des développeurs. Mais qu'est-ce qu'un commit atomique et pourquoi l'utiliser ?
Astuce
Les branches ne servent pas uniquement à travailler sur les fonctionnalités. Elles peuvent mettre l'équipe à l'abri de changements d'architecture importants, tels que la mise à jour des frameworks, des bibliothèques communes, etc.
Trois stratégies de création de branches pour les équipes agiles
Les modèles de création de branches diffèrent souvent d'une équipe à l'autre. De nombreux débats animent la communauté des développeurs à ce sujet. L'un des thèmes majeurs concerne la quantité de travail qui doit demeurer au sein d'une branche avant de faire l'objet d'un merge dans la branche principale.
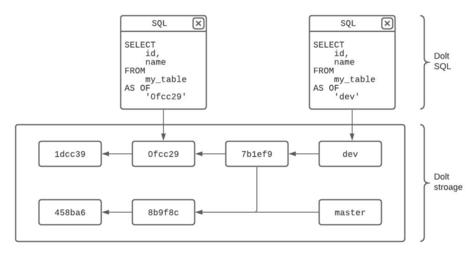
Dolt implémente un surensemble de MySQL. Il serait compatible avec MySQL et fournit des constructions supplémentaires exposant les fonctionnalités de contrôle de version qui sont étroitement modelées sur Git. « Dolt est le véritable Git pour l'expérience des données dans une base de données SQL, fournissant un contrôle de version pour les schémas et les données au niveau des cellules, le tout optimisé pour la collaboration », explique l'équipe. Selon elle, ces fonctionnalités sont combinées (Git + MySQL) pour créer un nouveau type de base de données relationnelle puissante et idéale pour le paysage des données évoluées.
Dolt est un outil libre et open source, sous licence Apache 2.0. Par ailleurs, DoltHub est un site Web qui héberge les bases de données Dolt, tout en fournissant des outils tels que l'hébergement, les autorisations, l'interface de requête, et plus encore, pour faciliter une collaboration transparente sur les données.
Ajout de fonctions de contrôle de version à une base de données SQL
Selon l'équipe, Dolt ajoute les fonctions de contrôle de version suivantes à une base de données SQL familière
Ce document a pour objectif de : - présenter rapidement l'outil de gestion de version CVS ;
- présenter les programmes clients associés à CVS ;
- aider à l'installation et à la configuration des clients ;
- expliquer les opérations classiques ;
- expliquer quelques opérations plus complexes.
Note de l'auteur : pour l'instant, seul CVS et le client WinCVS seront expliqués dans ce document. Il sera mis à jour plus tard pour intégrer un client alternatif TortoiseCVS.
Learn about trunk-based development, a version control management practice where developers merge small, frequent updates to a core “trunk” or main branch
|
Table of contents
Introduction
Goals
Single page summary (downloadable for wall mounting)
The version control pattern
Branch owner & policy
The "done" concept
The Done branch
When do we create additional branches?
Work branches
Publishing from work to trunk
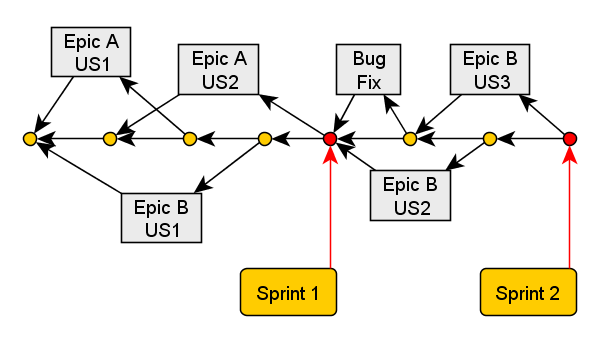
What if our team implements multiple stories in parallell?
Done includes regression testing!
Diverging code (merging conflicts)
Multiple teams - what if other teams are publishing to the trunk as well?
Release branches
The big picture
Variations to the model
FAQ
Where does continuous integration (CI) fit into this?
What's the best tool for this version control model?
What about checkins that aren't related to a user story?
Merging is a pain, so I want to do it as seldom as possible!
I have more questions!
References
Downloadable PDF of this article
Agile version control is very different to traditional version control. It is performed using many small feature branches which are being continually merged back into the trunk (or main development stream). This is necessary for the practice of Continuous Integration (CI) which is a core part of the Agile approach.
CI is an example of JIT (and hence DIRE) allowing problems to be found as soon as possible. It also supports other Agile practices such as short sprints and evolving the software using small, simple, user-centric User Stories. Use of CI depends on a version control system that allows easy branching and merging.
Most Agile teams also have two ongoing code streams (see Diagram 7) - the development "branch(es)" and the delivery "trunk". Again, this relies on a version control system that supports easy merging.
As far as I know Git is the only version control system currently available where a version node in the repository can have two parents. In other words Git allows you to automatically and safely merge code from different sources.
Although Git is not without it's problems (which I will discuss next month) I think using it is essential for Agile development to work smoothly. I will discuss the day-to-day use of different version controls systems (including Git) next month.
Check out the components of Trunk-based Development as implemented by Facebook and Google, and see how it helps resolve and prevent merge conflicts.
When coding an application, it is important to remain in sync with the other engineers working on the project. One strategy that helps a team stay in sync with codebase changes is trunk-based development. When employing trunk-based development, the developers working on a project make all their code changes in a common branch known as "trunk". There are numerous benefits to developing with this approach, which we will discuss in this article.
Development branch
The development branch is a long-lived feature branch that holds changes made by developers before they’re ready to go to production. It parallels the trunk and is never removed. Some teams have the development branch correspond with a non-production environment. As such, commits to the development branch trigger test environment deployments. Development and trunk are frequently bidirectionally integrated, and it’s typical for a team member to bear the responsibility of integrating them.
Feature branch
A feature branch can be short- or long-lived depending on the specific branching flow. The branch often is used by a single developer for only their changes, but it is possible to share it with other developers as well. Again, the branching strategy will determine how exactly you define a “feature branch”.
Release branch
A release branch can be either short-lived or long-lived depending on the strategy. In either case, the release branch reflects a set of changes that are intended to go through the production release process.
Hotfix branch
A hotfix branch is a branch that’s used generally to hold changes related to emergency bug fixes. They can be short-lived or long-lived, though generally they exist as long-lived branches split off from a release branch. They tend to be more common in teams with explicitly versioned products, such as installed applications.
Merge conflicts and pain
It’s easy for development teams to find themselves with a tangled mess of branches that need to be merged with the mainline all at once. And the longer multiple developers keep their code changes from mixing with each other, the higher the risk that those changes will conflict (through changes to common code).
It’s changes to common code that prevent Git from handling merges automatically and cause developers to experience the classic horrors of source control management: merge conflicts that waste time, lost changes that vanish entirely, and regression defects from removed code that somehow finds its way back in. Part of why trunk-based development has grown in popularity is because it helps avoid these painful merge conflicts.
Following are the various factors to look at before selecting Trunk based vs feature branching.
location of team members: when team members are co-located, the trunk is the best bet, helps us to get faster feedback. Also team can just talk about the code changes directly. Since the feedback will be faster in a single trunk, the team need to sync up more frequently. Co-location enables this sync trunk changes to happen frequently and faster. When there is a distributed environment (often in our teams), feature branching works best.
speed development environment: In a high speed dev environment, the trunk just shines as there are less and less process overhead, like branching, Pull request, review etc. Feature branching shines well when there is less speed in churning code.
size of code base: Insanely higher number of code lines can be better handled using feature branching. But for smaller code base, the cost of creating branches etc can be higher.
In our team meetings, we often talk about the right tools for the problem at hand. And using the right branching strategy is an important decision. We often question ourselves if the strategy is right for the given epic/sprint. If the answer is NO for few sprints, we know, we need to change something!
Key Takeaways
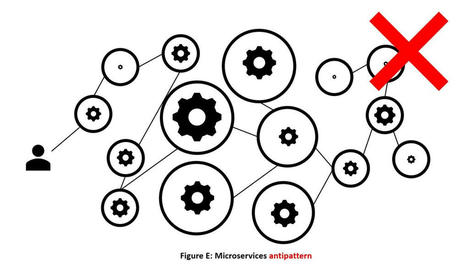
Microservices pattern doesn’t refer to the size of the services, decomposing your solution into ‘micro’ pieces is not the goal of the pattern, think of your solution as one whole then look at the requirements to guide you through what pieces to partition out. The article gives you an example of doing that.
Pros
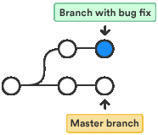
Every branches fork from a stable state.
Prevent side-effects (defect/ad-hoc/config) from merging develop into feature, release and main.
Group stable features according to release plan.
Easily remove features from release.
Cons
Require optional merge branch if using with Pull-Request. PR will merge the target branch on your feature; may cause unknown side-effects and stall you for days to fix it.
Multiple merge conflicts in develop and release.
Monter une usine logicielle moderne c’est avant tout se poser la question du niveau d’intégration au regard de l’ambition de son entreprise et définir deux piliers essentiels : la gestion du contrôle de code source (SCM) et les pratiques combinées d’intégration et de livraison continue (CI/CD).
A good branch-merge strategy facilitates processes among multiple developers and is the basis for any well-functioning DevOps pipeline that uses continuous integration. Let’s explore branching strategies, merging strategies, and how you can put them together in a way that’s right for your team in order to bring quality features to production faster.
TortoiseCVS lets you work with files under CVS version control directly from Windows Explorer.
|




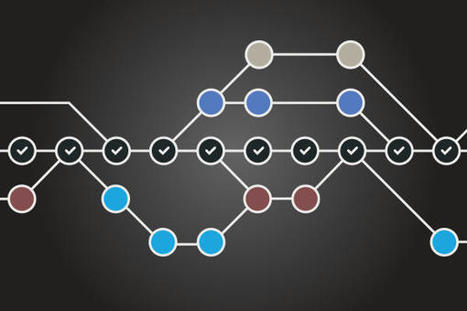





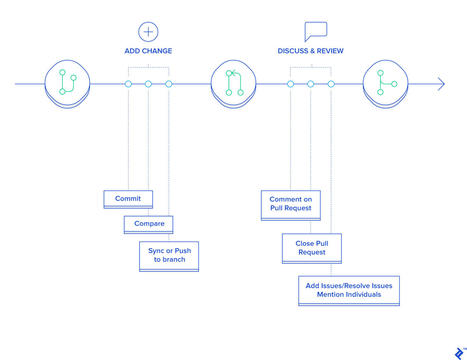
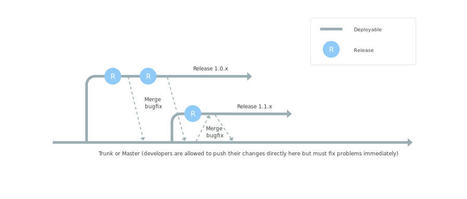
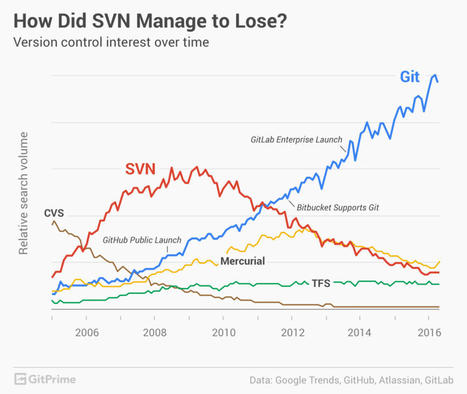












{kind=link}
{kind=link}
{kind=link}
Version Control Checklist
Here’s a quick version control checklist to use to ensure you’re applying the right version control best practices.
Commits
Applying version control best practices to commits is critical. Here’s what you need to consider.
Branching
Applying branching best practices is critical to success. But it can be complicated. To reduce the pain (and effort) for your teams, your branching strategy should aim to:
Security
Security is another critical version control best practice. Your security plan must consider multiple levels.