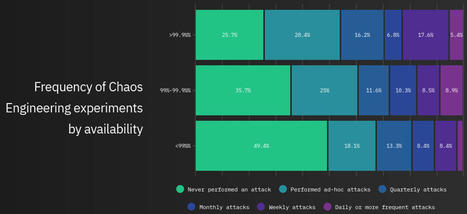
Outre une meilleure compréhension du travail des exploitants par les développeurs, cette démarche a permis à OUI.sncf de renforcer la résilience de son infrastructure de production à plusieurs niveaux. « Nous avons reproduit une panne qui était survenue il y a 5 ans, une panne que nous avons baptisée Irma », souligne Benjamin Gakic. « Il y a 5 ans, nous avions mis 1 heure pour la détecter et la résoudre. Cette année, elle l'a été en moins de 10 minutes. En termes de volume d'affaires que cela représente, c'est très significatif. » Une autre illustration de l'amélioration de la résilience le la production du site concerne sa dépendance vis-à-vis d'un partenaire jugé peu stable. « A chaque incident chez ce prestataire, nous perdions des sessions. La mise en place d'un circuit breaker nous a permis de réduire d'un facteur 40 l'impact de cette instabilité. Là encore, c'est très significatif », résume l'expert en sûreté de fonctionnement.
Désormais, le Chaos Monkey entre peu à peu dans les habitudes du site. Si au premier raid des minions sur le système d'information de Voyages-SNCF tout le monde était prévenu, ce n'est plus le cas aujourd'hui : « Désormais nous exécutons un Chaos Monkey chaque trimestre et on n'a plus de différence entre l'incident de production et le Chaos Monkey », confie Christophe Rochefolle. « Les exploitants ne sont plus informés qu'un Chaos Monkey est en cours. Par contre, il y a une trace que le Chaos Monkey est lancé. Mais nous ne les lançons pas les jours où nous réalisons 20 millions d'euros de chiffre d'affaires ! »



 Your new post is loading...
Your new post is loading...