

We have a varied tech stack ranging from the many services that power the cloud, from hardware to virtualization software. But with many moving pieces comes a need for observability.
Get Started for FREE
Sign up with Facebook Sign up with X
I don't have a Facebook or a X account


 Your new post is loading...
Your new post is loading... Your new post is loading...
Your new post is loading...
We have a varied tech stack ranging from the many services that power the cloud, from hardware to virtualization software. But with many moving pieces comes a need for observability. 
No comment yet.
Sign up to comment

Monitoring microservices effectively still can be a challenge, as many of the traditional performance monitoring techniques are ill-suited for providing the required granularity of system performance. Now a former Google and Weave engineer has developed an approach, called the RED Method, that seems to be gaining favor with administrators. RED “encourages you to come to …
|
From
medium

Site Reliability Engineering (SRE) is very popular lately, including the “Golden Signals” that you should be monitoring, but HOW do you actually get these data? This is a guide.
Mickael Ruau's insight:
There are three common lists or methodologies:
You can see the overlap, and as Baron Schwartz notes in his Monitoring & Observability with USE and RED blog, each method varies in focus. He suggests USE is about resources with an internal view, while RED is about requests, real work, and thus an external view (from the service consumer’s point of view). They are obviously related, and also complementary, as every service consumes resources to do work. For our purposes, we’ll focus on a simple superset of five signals:
Selecting the metrics that reveal the the utilization, saturation and errors (the so-called USE method) for these core metrics are a great place to start. Brendan Gregg does an excellent job…
|





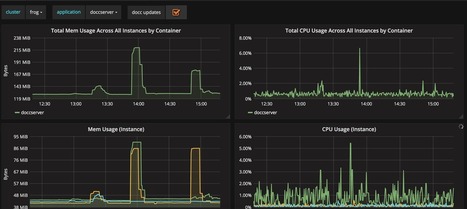
In addition to monitoring our services, we also monitor our infrastructure. As a former member of the team that maintained our container clusters, I noticed enormous benefits when leveraging the USE method: utilization, saturation, and errors. Coined by Brendan Gregg, the USE method allows one to solve “80% of server issues with 5% of the effort”.
Let us take a look at how we leveraged these metrics to monitor our Kubernetes clusters.