


Learning organizations smoothly morph as they adapt to new challenges—and they unlearn existing ways of working when those become limitations.
Get Started for FREE
Sign up with Facebook Sign up with X
I don't have a Facebook or a X account


 Your new post is loading...
Your new post is loading... Your new post is loading...
Your new post is loading...
Learning organizations smoothly morph as they adapt to new challenges—and they unlearn existing ways of working when those become limitations. 
No comment yet.
Sign up to comment
A good SRE engineer will tell you your service is never down. A great SRE engineer will tell you that’s not what you should be measuring. In fact, they’ll tell you their job is customer service.

Bien souvent je travaille avec des équipes, agiles ou non, dont l’attention se porte naturellement sur la fourniture de nouvelles fonctionnalités. Or, dans cette course à la production de valeur pour rester compétitif face à la concurrence, les équipes doivent faire un choix. Elles se retrouvent régulièrement dans cette situation compliquée où il faut faire…

A deep dive on how we crafted an order of magnitude change in our spend (10x reduction compared to baseline growth) over the last two years with iterative understanding and changes in Slack’s Continuous Integration (CI) infrastructure.

Dans les entreprises du web à grand échelle, on ne parle plus de PROD mais de Site Reliability Engineering. Pourquoi un tel changement, que se cache-t-il derrière cette terminologie, qui sont les acteurs de cette mutation et comment embrasser le mouvement ? Point sur l'état de l'art et retour d'expérience sur cette mutation dans le contexte Criteo.

This eMag on Data-Driven Decision Making provides an overview of how the three main activities in software delivery can be supported by data-driven decision making to increase the effectiveness, efficiency and service reliability of a software delivery organization.
Mickael Ruau's insight:
This eMag on Data-Driven Decision Making provides an overview of how the three main activities in software delivery can be supported by data-driven decision making to increase the effectiveness, efficiency and service reliability of a software delivery organization. The articles in this eMag come from the InfoQ series on Data-Driven Decision Making where Vladyslav Ukis shared his experiences from Siemens Healthineers; a large-scale distributed software delivery organization consisting of 16 software delivery teams located in three countries. Each of the articles highlights an area where data-driven decision making can be applied:
Free download
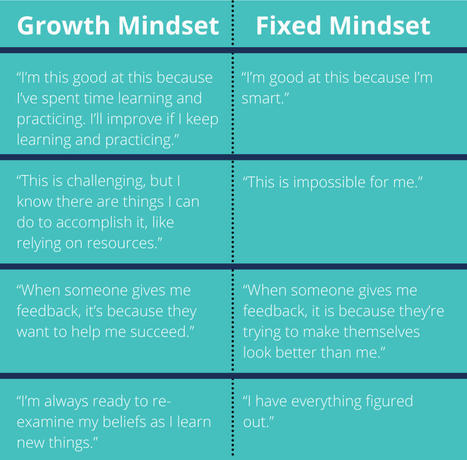
In this blog post, we’ll cover what a growth mindset is and why it helps your SRE team, how to hire for a growth mindset, how to develop people into SREs with a growth mindset, and how a blameless culture empowers a growth mindset.

Blog posts about “What is DevOps” are a dime a dozen. I find myself repeating my 0.8 cent version of this, and other buzzwords that people knock aroun
When responding to an incident, communication templates are invaluable. Get the templates our teams use, plus more examples for common incidents.

Key takeaways or measuring program success in site reliability engineering including service level indicators (SLI), service level objectives (SLO), and service level agreements (SLA).
When Google published its Site Reliability Engineering (SRE) book — a detailed look at how it keeps production systems running — Forrester started getting a lot of questions. “Should I do this in my enterprise IT shop?” “I’m no unicorn — can I even do these things?” And perhaps most important: “What parts of the book are relevant?” To …
Mickael Ruau's insight:
To sum up the findings:
In the end, we recommend applying most of the concepts with some tweaking. Focus on the service delivery, feature velocity, and automation concepts in the book. Focus less on the architecture sections, as Google’s challenges likely don’t mirror your own.
From
medium

Site Reliability Engineering (SRE) is very popular lately, including the “Golden Signals” that you should be monitoring, but HOW do you actually get these data? This is a guide.
Mickael Ruau's insight:
There are three common lists or methodologies:
You can see the overlap, and as Baron Schwartz notes in his Monitoring & Observability with USE and RED blog, each method varies in focus. He suggests USE is about resources with an internal view, while RED is about requests, real work, and thus an external view (from the service consumer’s point of view). They are obviously related, and also complementary, as every service consumes resources to do work. For our purposes, we’ll focus on a simple superset of five signals:

Get a head start on answering the question, "what is observability?" with these articles
Mickael Ruau's insight:
Start hereDistributed Systems Observability – Cindy Sridharan What the hell is observability? How is it any different than monitoring? Is it just the “devops” vs “sysadmin” debate all over again? This article answers these and so much more. Monitoring Isn’t Observability – Baron Schwartz This quote from the article sums it up quite well: Monitoring tells you whether a system is working, observability lets you ask why it isn’t working. Monitoring, Analytics, Diagnostics, Observability, and Root Cause Analysis – Baron Schwartz Now that we’ve introduced some nuance into our world, our terminology is getting overloaded. This post sets out some definitions of what everything means and how they differ. How do I make my applications more observable?Monitoring and Observability with USE and RED – Baron Schwartz USE and RED are two methods for deciding what to instrument why. This article walks you through their meaning and usage. Hierarchical Observability with RED – Baron Schwartz One of the best parts about the RED Method comes when you instrument all of your services to emit the same data: it becomes soooo much easier to spot the troublesome service in a microservice/distributed architecture. Best Practices for Observability – Charity Majors The list of best practices at the end is worthwhile reading. How to Monitor the SRE Golden Signals – Steve Mushero Another method for deciding what to monitor is the Four Golden Signals, popularized by the Site Reliability Engineering book. This article series by Steve Mushero walks you through what the signals mean and how to gather them. Who is actually doing observability?There are a number of teams out there doing observability-like things, and some of the larger, more engineering-focused companies have more mature Observability teams that are focused on providing expertise and a platform to other teams. Dating from 2013, Twitter was one of the first companies to work toward solving the problem of monitoring high-scale, distributed monitoring. For more details on their architecture (from 2016), see these posts: Observability at Twitter: technical overview, part I, Observability at Twitter: technical overview, part II
|
SRE advocates addressing problems blamelessly. When something goes wrong, don't try to determine who is at fault. Instead, look for systemic causes.
Mickael Ruau's insight:
SRE advocates addressing problems blamelessly. When something goes wrong, don't try to determine who is at fault. Instead, look for systemic causes. Adopting this approach has many benefits, from the practical to the cultural. Your system will become more resilient as you learn from each failure. Your team will also feel safer when they don't fear blame, leading to more initiative and innovation. Learning everything you can from incidents is a challenge. Understanding the benefits and best practices of analyzing contributing factors can help. In this blog post, we'll look at:

My name is Tammy Bryant Butow. One of the cool things that I wanted to share was actually a program we created to help new SREs learn all of the skills they needed to observe and understand failures in production.

The October 2021 Facebook outage is a lesson in how even expertly planned systems can sometimes fail, despite having multiple layers of reliability built-in.
Mickael Ruau's insight:
What Happened: A “Cascade of Errors”The outage wasn’t the result of one simple mistake or oversight. It was instead a “cascade of errors” that bred a critical disruption, as the New York Times put it. That cascade started when an engineer ran a command that was supposed to assess capacity for Facebook’s data centers. For reasons that Facebook hasn’t fully explained (maybe it was a typo- a mistake that has caused more than one serious incident in the past- but we’re just guessing), the command disrupted the backbone network that connects Facebook’s data centers. Facebook’s DNS servers also became unreachable. An auditing tool was supposed to have detected and blocked the errant command, but Facebook said that a “bug” prevented the tool from catching the issue.

Il existe une confusion entre DevOps, SRE (Site Reliability Engineer), SysAdmin et Ingénieur Cloud. Nous éclaircissons ces métiers dans cet article.
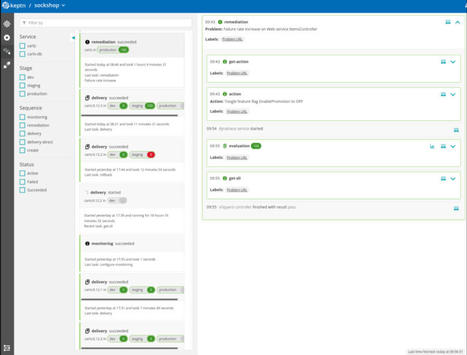
Lorsque l’on exploite un produit ou que l’on monte une infrastructure, il est normal de se poser la question “Est-ce que mon application fonctionne bien ?” En général, il est commun d’avoir deux réponses dans ce genre de cas : Mettre en place du monitoring illustrant le fonctionnement de mon application Mettre en place un système d’alerting pour être prévenu en cas de dysfonctionnement Cependant, rares sont les fois où l’on va se demander si les alertes positionnées sont pertinentes dans mon contexte (ex : redémarrage d’un conteneur) ou si les métriques remontées par mon dashboard préfabriqué me remontent les informations qui me seront vraiment utiles pour identifier un dysfonctionnement.
Mickael Ruau's insight:
Cet article a pour vocation de vous présenter la façon dont les Site Reliability Engineers ou SRE (terme défini dans la série de livres de Google Site Reliability Engineering) approchent les métriques de leurs applications. On y verra comment ils positionnent des objectifs factuels sur celles-ci afin de déterminer si l’application présente réellement la qualité de service attendue et comment ils font pour aller plus loin que la simple visualisation de celle-ci. Ces principes seront ensuite mis en lumière en vous présentant Keptn, une solution assez jeune sur le marché, mais qui illustre bien certaines des possibilités ouvertes par cette façon de faire. SLI,SLO,SLA… SLQuoi ? Les premières questions que l’on va se poser seront bien souvent : Par où commencer ? Quels sont les symptômes d’un dysfonctionnement de mon application ? Comment identifier que mon application fonctionne correctement ? L’approche des SRE explique qu’il est impossible de gérer un service correctement sans comprendre les comportements qui importent pour le service. Cela passe par une capacité à les mesurer et les évaluer. Et c’est ce qui nous permettra, à la fin, de délivrer un niveau de qualité qui répond aux attentes des utilisateurs finaux.

What is SRE—Site Reliability Engineering—and how can it help companies both maintain reliability and innovate quickly? This e-book explains how it works.

BooksForDevOps is simply “The Product Hunt of Modern IT Books” and yes you can submit your favorite book or apply to feature a book you wrote ! I am the curator of this collection’s website and the…

BetterHelp offre des conseils en ligne privés et abordables lorsque vous en avez besoin auprès de thérapeutes agréés et agréés par le conseil d'administration. Obtenez de l'aide, vous méritez d'être heureux!
Mickael Ruau's insight:
Il est éclairant de voir comment Duncker voyait la «résolution de problèmes». Le processus de résolution de problèmes, développé par Duncker

From
github
The Agile Operations methodology. Contribute to jdumars/agileops development by creating an account on GitHub.
Mickael Ruau's insight:
Note: This is the culmination of years of work managing and optimizing the practice of technical operations groups/DevOps at scale. These are proven tactics and techniques that can be applied across any technical value delivery organization of any size to increase efficiency, satisfaction, and enterprise agility. While I had hoped to write a book on this eventually (see the outline for what that would have looked like), I do not have the time to do so, and yet these topics are extremely relevant especially as the cloud native revolution takes hold. This is not a replacement of DevOps, but instead the overarching framework that DevOps is a part of.
From
devops
As Google SREs can attest, good DevOps monitoring systems need to be more than do-it-yourself toolkits—they need to provide real intelligence.
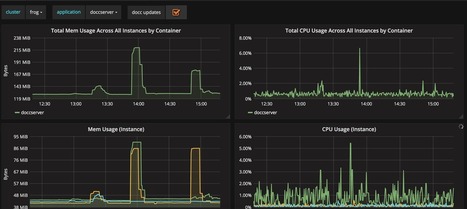
We have a varied tech stack ranging from the many services that power the cloud, from hardware to virtualization software. But with many moving pieces comes a need for observability.
Mickael Ruau's insight:
In addition to monitoring our services, we also monitor our infrastructure. As a former member of the team that maintained our container clusters, I noticed enormous benefits when leveraging the USE method: utilization, saturation, and errors. Coined by Brendan Gregg, the USE method allows one to solve “80% of server issues with 5% of the effort”. Let us take a look at how we leveraged these metrics to monitor our Kubernetes clusters.

From
dzone
|





We are regularly asked if we know any DevOps or site reliability engineering (SRE) experts available for hire. Our answer is, invariably, "Not really." It's a tough market out there.
DevOps and SRE (for large-scale software, at least) are critical approaches for success in modern software delivery and operations, as widely demonstrated every year in the State of DevOps report or the array of presentations at the DevOps Enterprise Summit.
But if you think you can achieve DevOps by hiring "DevOps experts," you are missing some contextual awareness. What exactly are you trying to improve in the first place?
If your software delivery is slow because of work you're handing off among multiple teams with diverse schedules and priorities, will a new hire really help?
We're not suggesting that you not hire people with diverse skills and backgrounds—that can be quite valuable to bring in new perspectives and approaches.
But conventional hiring based on expertise alone is ineffective and prevents organizations from developing the "learning muscles" that can help teams traverse the latest trends (DevOps, SRE, etc.) to their benefit at the right time, and in the right context.
Hiring experts for every need is like engaging in palliative care for organizational health. Preventive care would be to incorporate the necessary team structures and interactions—as well as a focus on people growth and sufficient slack—to effectively take in process, technology, and business changes.
Learning organizations smoothly morph as they adapt to new challenges, and they unlearn existing ways of working when they become limitations rather than enablers.