


 Your new post is loading...
Your new post is loading...

From
medium
Site Reliability Engineering (SRE) is very popular lately, including the “Golden Signals” that you should be monitoring, but HOW do you actually get these data? This is a guide.

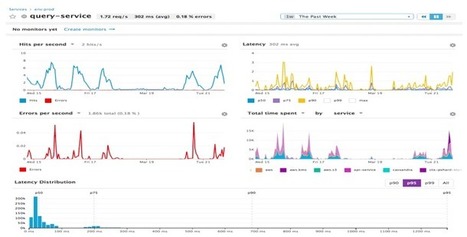







There are three common lists or methodologies:
You can see the overlap, and as Baron Schwartz notes in his Monitoring & Observability with USE and RED blog, each method varies in focus. He suggests USE is about resources with an internal view, while RED is about requests, real work, and thus an external view (from the service consumer’s point of view). They are obviously related, and also complementary, as every service consumes resources to do work.
For our purposes, we’ll focus on a simple superset of five signals: