


The simple, stupid batch framework for Java. Tags: Projects, Job Scheduling. MIT licence.
Get Started for FREE
Sign up with Facebook Sign up with X
I don't have a Facebook or a X account


 Your new post is loading...
Your new post is loading... Your new post is loading...
Your new post is loading...
The simple, stupid batch framework for Java. Tags: Projects, Job Scheduling. MIT licence. 
No comment yet.
Sign up to comment
Avec Internet et les nouvelles technologies, les échanges d’information au sein d’une même entreprise mais aussi avec l’extérieur (partenaires, fournisseurs, clients, etc…) se développent à vitesse grand V. Les entreprises sont alors confrontées à des problématiques complexes d’intégration. La mise en place de formats pivot est une réponse idéale à l’intégration de flux au sein du Système d’Informations de l’entreprise.
Mickael Ruau's insight:
Comment créer son format pivot ?Plusieurs démarches sont possibles pour créer son modèle de formats pivot. La démarche « top-down »La démarche « top-down consiste à conceptualiser l’existant métier. Elle préconise de construire ces formats pivot à partir de la sémantique métier de l’entreprise. A partir de ces formats pivot, dans les systèmes, on modifie les traitements et les structures pour qu’elles tiennent compte des ces nouveaux formats, qui peuvent être loin de la réalité technique. La démarche « bottom-up »La démarche « bottom-up » re-conceptualise l’existant technique. Elle guide le concepteur vers une rétro-conception de l’existant technique, à partir des formats manipulés dans les applications, pour en déduire des formats pivot. La démarche « meet in the middle »Cette démarche préconise de mener en parallèle un chantier « Top Down » et un chantier « Bottom Up ». Une fois ces deux chantiers en phase finale, l’objectif est de trouver une passerelle entre ces deux résultats et donc entre les formats pivot orientés métier et les formats pivot orientés techniques. Elle présente les avantages des deux premières méthodes : alignement parfait sur le métier et réutilisation de l’existant. Son principal inconvénient est le risque d’effet « tunnel » qu’elle engendre : attendre la fin des deux chantiers pour construire des formats pivot alternatifs entre une approche métier et une approche technique. Le risque principal est que durant le temps de construction de la passerelle, les besoins métier ou plus vraisemblablement les formats pivot techniques aient changé : les formats pivot alternatifs deviennent alors obsolètes. La démarche « middle-out »Cette démarche préconise de commencer à mi-chemin (« middle ») entre le métier et la direction opérationnelle du SI (DOSI), c’est-à-dire à partir d’un vocabulaire commun aux gens du métier et aux informaticiens. Elle s’attaque au problème principal des projets informatiques actuels : la compréhension des problématiques métier côté IT, et vice-versa. Les deux parties trouvent un consensus par l’intermédiaire d’une base d’entités composants-entités métiers nécessaires, à partir duquel découleront les entités haut niveau côté métier (domaines sémantiques, classes sémantiques…), et les entités bas niveau côté DOSI (objets de type Data Transfert Objects).
Comme dans beaucoup de situations, il faut simplement faire preuve de bon sens… Illustration

Palo for Data Integration (ETL Server) - Extraction, Transformation and Loading of Mass Data from Heterogeneous Sources.

Analyse comparative des performances : Microsoft SQL Server Integration Services 2008 et TALEND Open Studio 3.0.2 Dossier complet de 32 pages, téléchargeable gratuitement.
Mickael Ruau's insight:
Cette étude se focalise sur les temps de traitement nécessaires aux réalisations d’opérations basiques de transfert de données, et ceci avec les deux ETL dans diverses combinaisons de sources et cibles, de nombres de colonnes plus ou moins importants et de volumétries multiples.
|

Got ETL? Meet the reader, processor, writer pattern. Along with all the pre-built implementations, scheduling, chunking and retry features you might need. I think those who are drawn to Spring Batch are right to use it. It's paradigm is sensible and encourages developers to design well and not to reinvent things. It is reliable, robust, and relatively easy to use. I have found, however, that many times people reach for Spring Batch as an excellent technical solution but completely miss the business impact. ETL jobs suck! Many businesses totally neglect the repercussions of copying and renaming data between all the systems in their company. To me, this kind of ETL reinforces bad data practices, delays meaningful standardization, and inhibits future analytics work. Extensive data duplication leads to data quality issues which often leads to added costs for master data management solutions. It's also very wasteful, especially if you are paying for lots of Oracle products. Don’t be that company that names tables in hipster speak (USR_CNTCT_INF) to cut down on data waste and then ETL everything all over your company! If you can get the job done with Spring Batch, you can get the job done in a similar read-process-write paradigm in just about any messaging framework. This encourages loose coupling and enables continuous data transfer (I avoid using the term real-time so as not to confuse with actual real-time systems). If you really miss the pre-built readers and writers, take a look at Apache Camel. Many features are easy to replicate in a streaming/messaging system. Scheduling? Who cares, it streaming. Retry? Make a retry queue. Failure and error handling? Dead letter queue. Partitioning? Just add more workers. The last example is actually much easier than in Spring Batch. There's also a whole host of stream processing and analytics capabilities you probably want out of your batch job but can't make sense of. Say you have to data loads that somehow need to be related. You now need a third batch job to do a join after the first two run. Plus this all requires scheduling or polling and much consideration over efficiency. Please don't be scared away from streaming or message systems. Please do not use Spring Batch solely because you are already doing badly at making batch jobs. Make the leap toward messaging. I don't want to disparage Spring Batch, it's great at what it does. I have just seen too many batch jobs that would be significantly better as streaming architectures. There's also a huge push these days behind event-streaming which is a topic for another post.
Mickael Ruau's insight:
Edit: I had completely forgotten that there is a relatively new area of the industry around “data engineering” to support data scientists and analysts. ETL to data engineers is more like bash scripts to most coders. It ought to work well just once or maybe periodically but generally doesn't require much effort. Data engineers help get huge amounts of data around their companies and will use Python or SQL or whatever gets the job done. There's also a completely different scale of “batch” jobs which is where tools like Spark, Flink, and MapReduce come in. These tools can also be used for significantly more complex processing and analysis in addition to just moving data around.
From
adbi

Ce court tutoriel traite de l’intégration (l’appel) d’un batch Talend dans une application type Java/J2EE.
Microsoft SQL Server Integration Services (SSIS) est un ETL (Extract, Transform, Load). Les préconisations en matière de développement varient d’une entreprise à l’autre. Cependant certaines bonnes pratiques garantissent une intégration des données et des développement facile à maintenir.
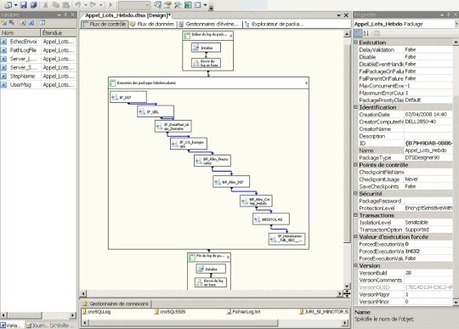
Microsoft SQL Server Integration Services (SSIS) est une plateforme conçue pour élaborer des solutions d'intégration de données très performantes, notamment des packages d'extraction, de transformation et de chargement (ETL) pour l'entreposage des données (Data Warehouse). SSIS propose des outils graphiques et des assistants permettant de créer et de déboguer des packages ; des tâches permettant de réaliser des fonctions de flux de travail comme les opérations FTP, l'exécution d'instructions SQL et l'envoi de messages électroniques ; des sources de données et des destinations permettant d'extraire et de charger des données ; des transformations permettant de nettoyer, d'agréger, de fusionner et de copier des données ; un service de gestion, le service Integration Services, permettant d'administrer l'exécution et le stockage des packages, et des API (Application Programming Interface) permettant de programmer le modèle objet Integration Services.
Mickael Ruau's insight:
Au cours de ce didacticiel, vous allez apprendre à utiliser le Concepteur SSIS pour créer un package Microsoft SQL Server Integration Services simple. Ce package extrait les données d'un fichier plat, les reformate et les insère dans une table de faits. Au cours des leçons suivantes, ce package est développé pour illustrer le bouclage, les options de configuration de package, l'écriture dans un journal et le flux d'erreurs.
|





Easy Batch is a framework that aims at simplifying batch processing with Java. It was specifically designed for simple, single-task ETL jobs. Writing batch applications requires a lot of boilerplate code: reading, writing, filtering, parsing and validating data, logging, reporting to name a few.. The idea is to free you from these tedious tasks and let you focus on your batch application's logic.
How does it work?
Easy Batch jobs are simple processing pipelines. Records are read in sequence from a data source, processed in pipeline and written in batches to a data sink:
The framework provides the Record and Batch APIs to abstract data format and process records in a consistent way regardless of the data source/sink type.
Let's see a quick example. Suppose you have the following tweets.csv file:
id,user,message 1,foo,hello 2,bar,@foo hi!and you want to transform these tweets to XML format. Here is how you can do that with Easy Batch:
Path inputFile = Paths.get("tweets.csv"); Path outputFile = Paths.get("tweets.xml"); Job job = new JobBuilder<String, String>() .reader(new FlatFileRecordReader(inputFile)) .filter(new HeaderRecordFilter<>()) .mapper(new DelimitedRecordMapper<>(Tweet.class, "id", "user", "message")) .marshaller(new XmlRecordMarshaller<>(Tweet.class)) .writer(new FileRecordWriter(outputFile)) .batchSize(10) .build(); JobExecutor jobExecutor = new JobExecutor(); JobReport report = jobExecutor.execute(job); jobExecutor.shutdown();This example creates a job that:
At the end of execution, you get a report with statistics and metrics about the job run (Execution time, number of errors, etc). All the boilerplate code of resources I/O, iterating through the data source, filtering and parsing records, mapping data to the domain object Tweet, writing output and reporting is handled by Easy Batch. Your code becomes declarative, intuitive, easy to read, understand, test and maintain.