Your new post is loading...

|
Scooped by
Charles Tiayon
November 9, 2011 3:36 PM
|
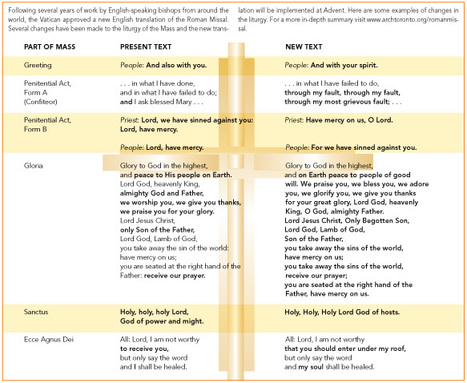
When Catholics begin using the new Roman Missal on the first Sunday of Advent, they will find an “awesomeness” to the new translation that maybe wasn’...

Researchers across Africa, Asia and the Middle East are building their own language models designed for local tongues, cultural nuance and digital independence
"In a high-stakes artificial intelligence race between the United States and China, an equally transformative movement is taking shape elsewhere. From Cape Town to Bangalore, from Cairo to Riyadh, researchers, engineers and public institutions are building homegrown AI systems, models that speak not just in local languages, but with regional insight and cultural depth.
The dominant narrative in AI, particularly since the early 2020s, has focused on a handful of US-based companies like OpenAI with GPT, Google with Gemini, Meta’s LLaMa, Anthropic’s Claude. They vie to build ever larger and more capable models. Earlier in 2025, China’s DeepSeek, a Hangzhou-based startup, added a new twist by releasing large language models (LLMs) that rival their American counterparts, with a smaller computational demand. But increasingly, researchers across the Global South are challenging the notion that technological leadership in AI is the exclusive domain of these two superpowers.
Instead, scientists and institutions in countries like India, South Africa, Egypt and Saudi Arabia are rethinking the very premise of generative AI. Their focus is not on scaling up, but on scaling right, building models that work for local users, in their languages, and within their social and economic realities.
“How do we make sure that the entire planet benefits from AI?” asks Benjamin Rosman, a professor at the University of the Witwatersrand and a lead developer of InkubaLM, a generative model trained on five African languages. “I want more and more voices to be in the conversation”.
Beyond English, beyond Silicon Valley
Large language models work by training on massive troves of online text. While the latest versions of GPT, Gemini or LLaMa boast multilingual capabilities, the overwhelming presence of English-language material and Western cultural contexts in these datasets skews their outputs. For speakers of Hindi, Arabic, Swahili, Xhosa and countless other languages, that means AI systems may not only stumble over grammar and syntax, they can also miss the point entirely.
“In Indian languages, large models trained on English data just don’t perform well,” says Janki Nawale, a linguist at AI4Bharat, a lab at the Indian Institute of Technology Madras. “There are cultural nuances, dialectal variations, and even non-standard scripts that make translation and understanding difficult.” Nawale’s team builds supervised datasets and evaluation benchmarks for what specialists call “low resource” languages, those that lack robust digital corpora for machine learning.
It’s not just a question of grammar or vocabulary. “The meaning often lies in the implication,” says Vukosi Marivate, a professor of computer science at the University of Pretoria, in South Africa. “In isiXhosa, the words are one thing but what’s being implied is what really matters.” Marivate co-leads Masakhane NLP, a pan-African collective of AI researchers that recently developed AFROBENCH, a rigorous benchmark for evaluating how well large language models perform on 64 African languages across 15 tasks. The results, published in a preprint in March, revealed major gaps in performance between English and nearly all African languages, especially with open-source models.
Similar concerns arise in the Arabic-speaking world. “If English dominates the training process, the answers will be filtered through a Western lens rather than an Arab one,” says Mekki Habib, a robotics professor at the American University in Cairo. A 2024 preprint from the Tunisian AI firm Clusterlab finds that many multilingual models fail to capture Arabic’s syntactic complexity or cultural frames of reference, particularly in dialect-rich contexts.
Governments step in
For many countries in the Global South, the stakes are geopolitical as well as linguistic. Dependence on Western or Chinese AI infrastructure could mean diminished sovereignty over information, technology, and even national narratives. In response, governments are pouring resources into creating their own models.
Saudi Arabia’s national AI authority, SDAIA, has built ‘ALLaM,’ an Arabic-first model based on Meta’s LLaMa-2, enriched with more than 540 billion Arabic tokens. The United Arab Emirates has backed several initiatives, including ‘Jais,’ an open-source Arabic-English model built by MBZUAI in collaboration with US chipmaker Cerebras Systems and the Abu Dhabi firm Inception. Another UAE-backed project, Noor, focuses on educational and Islamic applications.
In Qatar, researchers at Hamad Bin Khalifa University, and the Qatar Computing Research Institute, have developed the Fanar platform and its LLMs Fanar Star and Fanar Prime. Trained on a trillion tokens of Arabic, English, and code, Fanar’s tokenization approach is specifically engineered to reflect Arabic’s rich morphology and syntax.
India has emerged as a major hub for AI localization. In 2024, the government launched BharatGen, a public-private initiative funded with 235 crore (€26 million) initiative aimed at building foundation models attuned to India’s vast linguistic and cultural diversity. The project is led by the Indian Institute of Technology in Bombay and also involves its sister organizations in Hyderabad, Mandi, Kanpur, Indore, and Madras. The programme’s first product, e-vikrAI, can generate product descriptions and pricing suggestions from images in various Indic languages. Startups like Ola-backed Krutrim and CoRover’s BharatGPT have jumped in, while Google’s Indian lab unveiled MuRIL, a language model trained exclusively on Indian languages. The Indian governments’ AI Mission has received more than180 proposals from local researchers and startups to build national-scale AI infrastructure and large language models, and the Bengaluru-based company, AI Sarvam, has been selected to build India’s first ‘sovereign’ LLM, expected to be fluent in various Indian languages.
In Africa, much of the energy comes from the ground up. Masakhane NLP and Deep Learning Indaba, a pan-African academic movement, have created a decentralized research culture across the continent. One notable offshoot, Johannesburg-based Lelapa AI, launched InkubaLM in September 2024. It’s a ‘small language model’ (SLM) focused on five African languages with broad reach: Swahili, Hausa, Yoruba, isiZulu and isiXhosa.
“With only 0.4 billion parameters, it performs comparably to much larger models,” says Rosman. The model’s compact size and efficiency are designed to meet Africa’s infrastructure constraints while serving real-world applications. Another African model is UlizaLlama, a 7-billion parameter model developed by the Kenyan foundation Jacaranda Health, to support new and expectant mothers with AI-driven support in Swahili, Hausa, Yoruba, Xhosa, and Zulu.
India’s research scene is similarly vibrant. The AI4Bharat laboratory at IIT Madras has just released IndicTrans2, that supports translation across all 22 scheduled Indian languages. Sarvam AI, another startup, released its first LLM last year to support 10 major Indian languages. And KissanAI, co-founded by Pratik Desai, develops generative AI tools to deliver agricultural advice to farmers in their native languages.
The data dilemma
Yet building LLMs for underrepresented languages poses enormous challenges. Chief among them is data scarcity. “Even Hindi datasets are tiny compared to English,” says Tapas Kumar Mishra, a professor at the National Institute of Technology, Rourkela in eastern India. “So, training models from scratch is unlikely to match English-based models in performance.”
Rosman agrees. “The big-data paradigm doesn’t work for African languages. We simply don’t have the volume.” His team is pioneering alternative approaches like the Esethu Framework, a protocol for ethically collecting speech datasets from native speakers and redistributing revenue back to further development of AI tools for under-resourced languages. The project’s pilot used read speech from isiXhosa speakers, complete with metadata, to build voice-based applications.
In Arab nations, similar work is underway. Clusterlab’s 101 Billion Arabic Words Dataset is the largest of its kind, meticulously extracted and cleaned from the web to support Arabic-first model training.
The cost of staying local
But for all the innovation, practical obstacles remain. “The return on investment is low,” says KissanAI’s Desai. “The market for regional language models is big, but those with purchasing power still work in English.” And while Western tech companies attract the best minds globally, including many Indian and African scientists, researchers at home often face limited funding, patchy computing infrastructure, and unclear legal frameworks around data and privacy.
“There’s still a lack of sustainable funding, a shortage of specialists, and insufficient integration with educational or public systems,” warns Habib, the Cairo-based professor. “All of this has to change.”
A different vision for AI
Despite the hurdles, what’s emerging is a distinct vision for AI in the Global South – one that favours practical impact over prestige, and community ownership over corporate secrecy.
“There’s more emphasis here on solving real problems for real people,” says Nawale of AI4Bharat. Rather than chasing benchmark scores, researchers are aiming for relevance: tools for farmers, students, and small business owners.
And openness matters. “Some companies claim to be open-source, but they only release the model weights, not the data,” Marivate says. “With InkubaLM, we release both. We want others to build on what we’ve done, to do it better.”
In a global contest often measured in teraflops and tokens, these efforts may seem modest. But for the billions who speak the world’s less-resourced languages, they represent a future in which AI doesn’t just speak to them, but with them."
Sibusiso Biyela, Amr Rageh and Shakoor Rather
20 May 2025
https://www.natureasia.com/en/nmiddleeast/article/10.1038/nmiddleeast.2025.65
#metaglossia_mundus

Tech giant Meta has apologized and said it has fixed an auto-translation issue that led one of its social media platforms to mistakenly announce the death of Indian politician Siddaramaiah.
By Amarachi Orie, CNN
Fri July 18, 2025
The office of Siddaramaiah, chief minister of the Indian state of Karnataka, criticized Meta's "frequently inaccurate" auto-translation tool. Aijaz Rahi/AP
CNN
—
Tech giant Meta has apologized and said it has fixed an auto-translation issue that led one of its social media platforms to mistakenly announce the death of Indian politician Siddaramaiah.
The chief minister of the southwestern Indian state of Karnataka posted on Instagram Tuesday in the local Kannada language, saying he was paying his respects to the late Indian actress B. Saroja Devi. He also paid tribute to the actress on Facebook and X.
However, Meta’s auto-translation tool inaccurately translated the Instagram post to suggest that Siddaramaiah, who uses just one name, was the one who “passed away.”
“Chief Minister Siddaramaiah passed away yesterday multilingual star, senior actress B. Took darshan of Sarojadevi’s earthly body and paid his last respects,” the erroneous, garbled translation read, CNN affiliate News 18 reported.
A Meta spokesperson told news agency Press Trust of India Thursday: “We fixed an issue that briefly caused this inaccurate Kannada translation. We apologize that this happened.”
Politician calls for use of ‘grossly misleading’ tool to be halted
Also on Thursday, Siddaramaiah criticized the auto-translation tool as “dangerous” in posts on Facebook and X, adding that such “negligence” from tech giants “can harm public understanding & trust.”
His posts included a photo of an email his office sent to Meta (META) voicing “a serious concern” about the auto-translation tool on its platforms, “particularly Facebook and Instagram.”
The email, which had the subject line “Urgent Request to Address Faulty Auto-Translation of Kannada Content on Meta Platforms,” urged the tech company to “temporarily suspend” its auto-translation tool for content written in Kannada “until the translation accuracy is reliably improved.”
His office also requested that Meta work with Kannada language experts to improve the feature.
Kannada is the official language of Karnataka and is also spoken in bordering Indian states. Some 45 million people spoke Kannada as their first language in the early 2010s, and another 15 million spoke it as their second language, based on the latest available data...
The email from Siddaramaiah’s office calls Meta’s auto-translation from Kannada to English “frequently inaccurate and, in some cases, grossly misleading.”
“This poses a significant risk, especially when public communications, official statements, or important messages from the Chief Minister and the Government are incorrectly translated. It can lead to misinterpretation among users, many of whom may not realise that what they are reading is an automated and faulty translation rather than the original message,” it continues.
“Given the sensitivity of public communication, especially from a constitutional functionary like the Chief Minister, such misrepresentations due to flawed translation mechanisms are unacceptable,” it adds.
As of Friday, the auto-translation of Siddaramaiah’s Instagram post reads: “The multilingual star, senior actress B Sarojadevi who passed away yesterday, paid his last respects,” which still appears to be inaccurate.
CNN has reached out to Meta and the Karnataka chief minister’s office for further comment.
The incident comes months after the US tech giant apologized for a technical error that led some Instagram users to see graphic, violent videos."
https://edition.cnn.com/2025/07/18/tech/meta-apologizes-siddaramaiah-scli-intl
#metaglossia_mundus

"...Instauration d’une obligation de suivre des cours de français dès l’arrivée, conditions linguistiques pour l’accès à la carte de séjour pluriannuel, à la carte de résident et à l’obtention de la nationalité : la maîtrise de la langue française est désormais un moyen de réguler le droit de vivre en France.
Cependant, une récente enquête de l’INSEE montre que 52 % des personnes immigrées dont le français n’est pas la langue maternelle sont en grande difficulté à l’écrit. En 20 ans, la France a construit une véritable « politique linguistique d’immigration ».
Quels sont les principes qui sous-tendent cette politique ? Quelles sont ses limites et ses angles morts ? Comment faire mieux ? Donnons la parole à celles et ceux qui apprennent le français !
Moyens de communication
Téléphone : 04 85 46 74 30
https://www.univ-smb.fr/amphis
Horaires d'ouverture
Jeudi 4 décembre 2025 de 18h30 à 20h.
Localisation
Adresse : place Chorus rue de l'Arlequin, 74960 Cran-Gevrier, France.
Tarifs
Gratuit. Accès libre."
Conférence : Le français pour (s’)intégrer ? 20 ans de politique linguistique migratoire
Par Maude Vadot, enseignante-chercheuse, LLSETI, de l’UFR Lettres, Langues et Sciences Humaines
https://www.haute-savoie-tourisme.org/evenements/apprendre/conferences/7458105-conference-le-francais-pour-s-integrer-20-ans-de-politique-linguistique-migratoire
#metaglossia_mundus

"Le conseil des Affaires générale de l’Union européenne a retoqué une nouvelle fois la reconnaissance du catalan, du basque et du galicien comme langues officielles de l’UE. Plusieurs pays y restent hostiles.
C’est tout sauf une surprise. Réunis à Bruxelles ce vendredi, les ministres des affaires européennes des 27 ont encore une fois repoussé la reconnaissance comme langues officielles de l’Union Européennes le catalan, le basque et le galicien. La discussion aura d’ailleurs duré moins d’une heure, le temps d’acter les profondes divergences de vues sur ce dossier entre pays. Or le consensus était la condition nécessaire à l’organisation d’un vote.
Des pays comme l’Allemagne, l’Autriche la république tchèque, la Suède, l'Italie, la Croatie, la Finlande ou la Pologne ont, comme au mois de mai dernier, exprimé leurs réticences. Selon eux, la reconnaissance de ces trois langues pose un problème juridique car il faudrait revoir les traités. L’inquiétude est également financière même si l’Espagne a promis de prendre en charges les coûts liés à un éventuel changement de statut du basque, du catalan et du galicien. Pour le gouvernement espagnol, ces oppositions sont surtout d’ordre idéologique. Fernando Sampedro, le secrétaire d’Etat en charge de l’UE estime que les 27 "ne pourront pas esquiver la question indéfiniment".
Le Portugal, la Slovénie, le Danemark, Chypre, la Hongrie, Malte, l’Estonie, la Belgique ou l’Irlande soutiennent quant à eux la demande de l’Espagne. La France, elle, est restée un peu en retrait du débat, mais sans soutenir directement un changement de statut du catalan à Bruxelles."
Baptiste Guiet
Publié le vendredi 18 juillet 2025 à 19:05
https://www.francebleu.fr/infos/international/l-europe-repousse-encore-la-reconnaissance-officielle-de-la-langue-catalane-2482795
#metaglossia_mundus

Joining our communication-conversation this week are two young adults: Jacob Farzanmehr and Jazmin Romero. Jacob lives with Cerebral Palsy and currently attends Alan Hancock Community College. Similarly, Jazmin currently attends Mesa Community College and lives with Spinal Muscular Atrophy.
"The Sapir Wharf Hypothesis is a lens through which communication scholars often observe and predict cultures‘ language and worldviews. It states that language determines a native speaker’s perception and categorization of experience. But what does this mean when it’s applied to people living with disabilities, the language we choose to communicate with, and the language others choose to describe us?
Jacob Farzanmehr
Jazmin Romero
Joining our communication-conversation this week are two young adults: Jacob Farzanmehr and Jazmin Romero. Jacob lives with Cerebral Palsy and currently attends Alan Hancock Community College. Similarly, Jazmin currently attends Mesa Community College and lives with Spinal Muscular Atrophy. As we explore their experiences as people with disabilities, we’ll compare and contr
ast how they see themselves through the lens of language—and how others see them. How do words like cripple, disabled, and handicapped differ in their minds from terms like differently-abled?
Tune in to find out! And stick around until the end to hear which terms the Pushing Limits crew are not so fond of.
This program was hosted and produced by Dominick Trevethan with editing assistance from Denny Daughters. Additional commentary provided by Eddie Ytuarte, Bonnie Elliott, Denny Daughters, Adrienne Lauby, and Jacob Lesner-Buxton."
https://kpfa.org/episode/pushing-limits-july-18-2025/
#metaglossia_mundus

“I hope that children, youth, and the rest of the population will join in so that the language doesn't disappear.”
"Meet the participants in the Catalyst Program for Digital Activism for Indigenous Languages of Guatemala! The program, coordinated by Rising Voices, brings together participants from various regions who have projects related to the use, strengthening, revitalization, and/or promotion of an Indigenous language through digital media and tools, and through processes that involve and benefit their communities.
Each participant receives a stipend, peer support, and opportunities for dialogue with people from other regions, languages, and worldviews, as well as with participants in the Mayan Languages program from Mexico and Colombia.
Rising Voices (RV): How do you like to introduce yourself?
Translation Original Quote
Aury Us: I'm Aury Us, and I speak Maya Uspanteko. I'm a social worker, and the training opportunities I've had with various social issues have motivated me to get involved and contribute to different spaces and processes. Since I was little, I've loved singing and have had several goals, which I've now set out to continue training in order to achieve. My Maya Uspanteko language is a legacy from my maternal grandparents, which I treasure and value. Since I was little, my mother and grandparents taught me to speak it.
RV: What would you like to share with the world about your language and territory?
Translation Original Quote
Aury Us: According to some research, the Uspantek language dates back more than 500 years. However, it is currently considered one of the minority Mayan languages in Guatemala, with fewer than 5,000 speakers. There are few of us speakers left because Spanish now predominates in the territory, and for this reason, our language is no longer promoted among children and youth.
The municipality is known as Uspantán, which comes from the Nahuatl term Uzpantlán. Some of its speakers call it Tz'unun Kaab’ in the Uspantek language, which translates to ‘Sweet Sparrow’ in Spanish.
Portrait of Aury Us. Photo shared with her permission.
RV: What dreams do you have for your language in the digital and non-digital world?
Translation Original Quote
Aury Us: I haven't lost hope that the Uspanteko language will grow and be valued by the local people. I believe it's important to take advantage of various opportunities to raise awareness and encourage people to value it. My dream is that this project will help others get involved in various initiatives for teaching and learning the language.
RV: What is your project about in this Catalyst Program?
Translation Original Quote
Aury Us: The K'aslemal Yolooj-Uspanteko project translates to ‘Life in the Uspantán Language’ in Spanish. It involves teaching and learning the Mayan language, which will be carried out with children from the urban and rural areas of the municipality of Uspantán, known as Tz'unun Kaab’ in our language.
The idea is to create spaces for children to record popular children's songs which are originally in Spanish, and adapt them into video format with translation into Maya Uspantán, so that they can be disseminated through social media on local websites, personal accounts, and local radio stations.
RV: Why is it important for you to create and navigate processes of using, strengthening, revitalizing, and/or promoting your language through digital media and tools?
Translation Original Quote
Aury Us: It is important to raise awareness about the importance of the Maya Uspantek language because, despite various events that have brought it close to extinction, our people and our language have survived for more than 500 years thanks to our ancestors passing it down from generation to generation.
I believe that teaching and learning the Uspantek language will contribute to raising awareness among both native and non-native speakers. I hope that children, youth, and the rest of the population will join in so that the language does not disappear, because it is in our hands to keep it alive.
RV: What would you say excites you about sharing this process with other Indigenous language speakers in Colombia/Guatemala?
Translation Original Quote
Aury Us: It's important to maintain hope in the face of various obstacles, because the universe has chosen us to be one of the seeds for our languages. Sometimes we think we don't have the capacity to leave a mark on this universe, but if we proudly value and treasure our roots and our ancestors, it will allow us to find people who will help us advance our goals, such as teaching our native language.
RV: What would you like to say to other Maya Uspanteko speakers about continuing to speak and strengthen their language?
Translation Original Quote
Aury Us: Let's not allow our language to disappear; we must strengthen it. Only then will we value the legacy and teachings left by our grandparents, and only then will we demonstrate our worth."
https://globalvoices.org/2025/07/18/childrens-songs-translated-into-maya-uspantek-aury-us-project-in-guatemala/
#metaglossia_mundus
"Translating impoliteness - literature review, translation challenges, and translation strategies in cross-cultural communication
Humanities and Social Sciences Communications volume 12, Article number: 1121 (2025) Cite this article
Abstract
In recent years, research integrating translation studies with impoliteness has steadily increased, significantly contributing to the interdisciplinary development of both fields. However, there remains a lack of reviews that examine how impoliteness is translated across languages and cultures, particularly from a pragmatic standpoint. This study addresses this gap by providing a focused literature review of translation studies on impoliteness, centered on current research trends, methodologies, and analytical perspectives. Twenty-one articles published between 1998 and 2023 were selected from the Scopus and Science Direct databases, focusing on translation studies and impoliteness. Analysis of these studies reveals that cultural differences represent a primary challenge when translating impoliteness. In response, strategies such as euphemism and omission are commonly adopted, often resulting in a dilution of the original pragmatic force. The findings of this study aim to guide future interdisciplinary research on translation studies and impoliteness for translators and researchers, highlighting key challenges and practical strategies in translating impoliteness across cultural boundaries."
Review
Open access
Wei Yang, Syed Nurulakla Syed Abdullah, …Mingxing Yang...
Published: 18 July 2025
https://www.nature.com/articles/s41599-025-05092-4
#metaglossia_mundus

"Riyad, 17 juillet 2025, SPA -- La Commission saoudienne de la littérature, de l’édition et de la traduction (LPTC) a organisé une rencontre virtuelle consacrée à la traduction juridique, soulignant son importance dans le développement des relations internationales et commerciales.
Les échanges ont mis en avant les compétences requises pour exercer cette spécialité, qui va bien au-delà de la simple traduction linguistique. Elle exige une maîtrise des concepts juridiques, des normes rigoureuses et une connaissance précise des textes législatifs, contrats et accords.
Cette rencontre s’inscrit dans une série d’initiatives destinées à renforcer le dialogue avec les professionnels du secteur et à soutenir le développement de la traduction et de l’édition en Arabie Saoudite.
-- SPA
12:05 Heure locale 09:05 GMT
0022"
https://spa.gov.sa/fr/N2362300

Kim Hye-soon a été désignée lauréate du Prix international de littérature pour la traduction allemande de son recueil « Autobiographie de la mort ».
"La poétesse Kim Hye-soon remporte le Prix international de littérature du HKW
2025-07-18 09:55:37/Update: 2025-07-18 10:54:43
La poétesse sud-coréenne Kim Hye-soon a été désignée lauréate du Prix international de littérature pour la traduction allemande de son recueil « Autobiographie de la mort ». Elle devient ainsi la première sud-Coréenne à recevoir cette récompense, décernée par la Maison des Cultures du Monde (HKW) en Allemagne.
La cérémonie de remise des prix s’est tenue jeudi. Etant donné que cette distinction est conjointement attribuée à l’auteur et au traducteur, Park Sool et Uljana Wolf, qui ont assuré la traduction de l’ouvrage du coréen vers l’allemand, ont eux aussi été couronnés.
« Autobiographie de la mort » est un recueil poétique publié en 2016. Il a été inspiré par l’effondrement de Kim dans une station de métro en 2015. Elle y évoque diverses tragédies sociales telles que l’épidémie de MERS et le naufrage du ferry Sewol, à travers 49 poèmes.
Créé en 2009, le Prix international de littérature du HKW récompense chaque année une œuvre contemporaine traduite en allemand. Le prix est doté d’un montant de 35 000 euros, dont 20 000 pour l’auteur et le reste pour le traducteur."
https://world.kbs.co.kr/service/news_view.htm?lang=f&Seq_Code=91336
#metaglossia_mundus

"Le réseau LTT (Lexicologie, Terminologie, Traduction): Appel à projets AUF 2024-2025 : le réseau LTT met en œuvre sa feuille de route
Formations sur l'intelligence artificielle, mobilité universitaire francophone : le réseau Lexicologie, Terminologie, Traduction (LTT), lauréat de l’appel à projets AUF 2024-2025, a engagé la première phase de ses actions. Retour sur les temps forts de ce déploiement.
Le réseau LTT (Lexicologie, Terminologie, Traduction) a lancé deux chantiers majeurs de sa feuille de route :
• Un cycle de formations sur les enjeux de l’intelligence artificielle (IA)
• Un programme de coopération universitaire Nord Sud, fondé sur la mobilité étudiante.
Trois formations pour sensibiliser aux enjeux de l’IA
En partenariat avec ses laboratoires membres, le réseau LTT a proposé trois cours de sensibilisation entre avril et mai 2025, dans le cadre du Projet Réseaux AUF 2024.
En avril, DataFranca.org est intervenu sur les fondements de l’IA et ses enjeux éthiques, dans une perspective de littératie numérique.
En mai, une deuxième formation a abordé les usages professionnels des agents conversationnels, en s’intéressant aux risques cognitifs et éthiques liés à leur utilisation abusive.
Une troisième session a exploré les méthodes d’acquisition de termes spécialisés, notamment via des logiciels dédiés et ChatGPT, avec un focus sur le développement de l’esprit critique dans l’éducation.
Une coopération universitaire Nord Sud concrétisée
Parallèlement, un appel à projets internes a permis de faire émerger un partenariat entre :
• Le CERTTAL (Centre de recherche en traductologie, en terminologie arabe et en langues) de l’École de Traducteurs et d’Interprètes de Beyrouth (ETIB),
• Le centre TELL (Technologies et Environnement linguistiques) de l’Université de Mons (Belgique).
Ce partenariat a pour objectif l’élaboration d’un cours d’initiation à la linguistique computationnelle et à la pré-édition, destiné à des étudiants de niveau licence.
Une première mobilité dans le cadre de ce projet s’est tenue en juin 2025 au centre TELL de Mons. Elle illustre pleinement la mission du réseau LTT : soutenir la lexicologie, la terminologie et la traduction à travers des dynamiques de coopération et de formation, en assurant la relève scientifique francophone par une mobilité internationale solidaire.
🔗 Plus d’actualités du réseau LTT à retrouver sur son site web.
DATE DE PUBLICATION : 18/07/2025"
https://www.auf.org/nouvelles/actualites/appel-projets-auf-2024-2025-le-reseau-ltt-met-en-oeuvre-sa-feuille-de-route/
#metaglossia_mundus

This year, our free, virtual reading series gathers voices from across time zones for an international celebration!
"This August we once again celebrate Women in Translation (#WiT) Month! This reading series was initiated by blogger Meytal Radzinski in 2014 to raise awareness of translated literature by women, queer, and nonbinary authors, and promote gender and cultural diversity in literary publishing. This year, our free, virtual reading series gathers voices from across time zones for an international celebration!
Organized under the support of PEN America and the PEN America Translation Committee, these events bring together three panels of translators, joined by their authors, working in a diversity of languages. The readings will be followed by brief Q&A discussions. We hope you’ll join us for these one-of-a-kind bilingual readings!
The Women in Translation Reading Series will take place on Zoom on August 7, 14, and 21, 2025. The conversations will be moderated by Nancy Naomi Carlson, Christina Daub, and Marguerite Feitlowitz.
The August 14 session will be moderated by Marguerite Feitlowitz, with readings in Chinese (Taiwan), German, Portuguese (Brazil), Russian (Ukraine), and Vietnamese.
Marguerite Feitlowitz has published five volumes of translations from French and Spanish, most recently Night, by Ennio Moltedo, Pillar of Salt: An Autobiography with Nineteen Erotic Sonnets, by Salvador Novo, and plays by Griselda Gambaro. She is the author of A Lexicon of Terror: Argentina and the Legacies of Torture."
https://pen.org/event/women-in-translation-month-reading-series-2025-session-2/
#metaglossia_mundus

"The Translation Movement Between East and West (Arabic version)
BY VARIOUS CONTRIBUTORS
No Ratings (0 customer reviews)
http://doi.org/10.56656/101249
SKU: 101249
Date: 2025
Edition: 1
ISBN: 9781788149198
Format: Paperback
No. of Pages: 292
Summary
From the earliest periods of recorded history until today, translation has played a crucial role in disseminating scientific knowledge. The translation movement, as we will explore in this symposium proceedings, has been a tool and a driving force in the exchange of knowledge and the development of science, enlightening us about the interconnectedness of our world.
During the medieval period, the renowned Graeco-Arabic translation movement established Arabic as the lingua franca for scientific discourse. Subsequently, Latin became the dominant lingua franca of scientific exchange throughout much of the medieval and early modern eras. In more recent times, a reverse translation movement has emerged, facilitating the translation of various European languages into Arabic, Persian, and Ottoman.
To illuminate the significant scientific exchanges and cultural fusion between East and West and to celebrate the 35th Anniversary of Al-Furqān with special projects, events, and publications, we organised a one-day symposium in 2023. This milestone honoured our late Chairman, HE Sheikh Ahmed Zaki Yamani (may he rest in peace), and his vision of bridging cultures - a fundamental mission of Al-Furqān and a key reason for its establishment in London. The symposium, focusing on three major translation movements, underscored our unwavering commitment to fostering dialogue and understanding between diverse cultures through the power of translation, inspiring us all to continue this important work.
Content
From the earliest periods of recorded history until today, translation has played a crucial role in disseminating scientific knowledge. The translation movement, as we will explore in this symposium proceedings, has been a tool and a driving force in the exchange of knowledge and the development of science, enlightening us about the interconnectedness of our world.
During the medieval period, the renowned Graeco-Arabic translation movement established Arabic as the lingua franca for scientific discourse. Subsequently, Latin became the dominant lingua franca of scientific exchange throughout much of the medieval and early modern eras. In more recent times, a reverse translation movement has emerged, facilitating the translation of various European languages into Arabic, Persian, and Ottoman.
To illuminate the significant scientific exchanges and cultural fusion between East and West and to celebrate the 35th Anniversary of Al-Furqān with special projects, events, and publications, we organised a one-day symposium in 2023..."
https://al-furqan.com/publication/the-translation-movement-between-east-and-west-arabic-version-9781788149198/
#metaglossia_mundus

Le livre écrit par Adolf Hitler a été publié pour la première fois il y a tout juste cent ans, le 18 juillet 1925
"Voici la folle histoire de la traduction de Mein Kampf en français, interdite par Hitler lui même
Ce vendredi, cela fait un siècle jour pour jour que le dictateur nazi Adolf Hitler a publié pour la première fois Mein Kampf, livre dans lequel il expose sa « vision du monde » et son idéologie.
Jamais interdit en France, l’ouvrage est entré dans le domaine public en 2016 et est en circulation libre dans le pays, comme partout dans le monde.
Si le livre est toujours aussi tabou aujourd’hui, c’est parce que « les ignominies antisémites qu’on y trouve sont toujours aussi révoltantes aujourd’hui qu’il y a cent ans », pointe l’historien Florent Brayard.
C’est l’un des livres les plus tabous de la période contemporaine. Mein Kampf, le livre dans lequel Adolf Hitler expose sa « vision du monde » et son idéologie empreinte de haine, de racisme, d’antisémitisme et de nationalisme, a été publié pour la première fois le 18 juillet 1925. Cent ans après, l’ouvrage suscite toujours de vives réactions et controverses, certains appelant à son retrait des rayons, d’autres soulignant son importance historique. Quoi qu’il en soit, il ne laisse pas indifférent, et heureusement.
Contrairement à la croyance répandue, Mein Kampf n’a donc jamais été interdit à la vente en France pour l’idéologie qu’il véhiculait. Jusqu’en 2016, année où il est entré dans le domaine public, une seule édition était en circulation en France : une traduction non autorisée parue en 1934 aux Nouvelles éditions latines, attaquée en justice par Hitler et les ayants droit de l’ouvrage original, le ministère des Finances bavarois. Si aucune autre édition n’a circulé, c’est donc avant tout car le ce dernier refusait toute nouvelle édition, même critique.
Un livre massivement en circulation
La seule mesure prise en France a été « l’introduction d’un avant-propos d’une dizaine de pages mettant en garde le lecteur contre les dangers de l’idéologie hitlérienne » en 1978, précise Florent Brayard, historien, directeur de recherche au CNRS, membre du Centre de recherches historiques de l’EHESS (Ecole des hautes études en sciences sociales). Celle-ci faisait suite à une action en justice de Serge Klarsfeld entre autres. L’ouvrage était pour le reste « vendu légalement et on pouvait le commander en librairie », poursuit-il.
Depuis 2016 et son entrée dans le domaine public, Mein Kampf a été réédité en France et est disponible sur les grandes plateformes de vente, au milieu des autres livres. Florent Brayard rappelle aussi « qu’il suffit de trois clics sur Internet pour télécharger une version PDF ». De ce fait, l’ouvrage « est massivement en circulation partout dans le monde depuis les années 1990 ».
Un livre « qui fait partie de notre passé »
C’est ce qui a conduit l’historien à participer à l’élaboration du livre Historiciser le mal (éd. Fayard, 2021), une version de Mein Kampf présentant analyse critique, mise en contexte et déconstruction ligne par ligne de l’ouvrage de Hitler. « Puisque Mein Kampf est déjà en circulation, autant faire en sorte que ce soit dans une bonne édition, c’est-à-dire une édition critique », justifie le spécialiste. Bien loin de l’édition d’origine, qui s’est vendue à plus de 12 millions d’exemplaires entre 1925 et 1945 en Allemagne.
D’autant que ce livre « est une source fondamentale pour l’Histoire, appuie Florent Brayard. Le nazisme a été la pire expérience du XXe siècle, la plus criminelle et la plus barbare, et Mein Kampf permet de mieux comprendre le mystère de l’évolution de cette société criminelle. » Insistant bien sur le fait que cet ouvrage soit « ennuyeux, raciste » et « [promeuve] une idéologie nauséabonde », l’historien rappelle qu’il « fait partie de notre passé, et on ne peut pas sélectionner ce qu’on souhaiterait mettre en avant dans notre passé, ni faire comme si Mein Kampf n’a pas existé ».
Un ouvrage « d’actualité »
Et si l’ouvrage fait toujours parler de lui, c’est parce que « les ignominies antisémites qu’on y trouve sont toujours aussi révoltantes aujourd’hui qu’il y a cent ans, pointe l’historien. Si une autre personne reprenait aujourd’hui en son nom les horreurs que Hitler peut dire sur les juifs, les Polonais, les Tsiganes etc., il serait condamné, et ce serait juste ».
Voici la folle histoire de la traduction de Mein Kampf en français, interdite par Hitler lui même
C’est pour cette raison que le livre du dictateur n’est pas près de tomber dans les oubliettes de l’Histoire : « Je pense qu’il s’écoulera encore des siècles avant qu’on oublie la Shoah, et tant qu’on se souvient de la Shoah, Mein Kampf est un livre d’actualité », prévoit Florent Brayard. Un ouvrage d’autant plus d’actualité que les manœuvres politiques en vogue actuellement dans le monde - l’historien cite notamment les Etats-Unis –, en premier lieu « l’usage massif du mensonge » et la rhétorique « de l’élection volée », sont « la preuve qu’on ne peut malheureusement pas refermer le passé et se dire qu’on s’en fiche parce que c’était il y a un siècle », avertit Florent Brayard."
Publié le 18/07/2025 à 10h32 • Mis à jour le 18/07/2025 à 10h32
Pourquoi « Mein Kampf » ne tombera pas de sitôt aux oubliettes de l’Histoire https://share.google/D8CiTDwENrGiLg69i
#metaglossia_mundus

"Senior Lecturer / Lecturer, Department of Translation
Employer
LINGNAN UNIVERSITY
Location
Tuen Mun, Hong Kong
Closing date
24 Aug 2025
Lingnan University is one of the eight publicly funded institutions in the Hong Kong Special Administrative Region (HKSAR) and has the longest established tradition among the local institutions of higher education. It is widely recognised for providing quality education with a focus on whole-person development and conducting high-impact research for a better world. Moving forward, Lingnan University is well positioned to take lead as a comprehensive university in arts and sciences in the digital era, with impactful research and innovations.
Lingnan University offers undergraduate, taught postgraduate, and research postgraduate programmes in the Faculties of Arts, Business, Social Sciences, and the Schools of Data Science, Graduate Studies and Interdisciplinary Studies. To foster interdisciplinary collaboration and scientific progress, Lingnan University established the Lingnan University Institute for Advanced Study (LUIAS), attracting distinguished scholars from around the world to collaborate with its faculty and students. With traditional strengths in arts, business, social sciences, and interdisciplinary studies, the University aims to equip students with practical knowledge and critical thinking skills to thrive in the future. Subsequent to the establishment of the School of Data Science and LUIAS, Lingnan University is transforming into a hub for global leaders to develop and promote human-centric technology and social policies. Further information about Lingnan University is available at https://www.ln.edu.hk/.
Applications are now invited for the following post: Senior Lecturer / Lecturer. Department of Translation
(Post Ref.: 25/177)
The Department of Translation sets out to provide an education in bilingual studies which can nourish graduates with competence in Chinese and English as well as capacity to think independently. One of its central features is the equal emphasis on translation as a profession and as an academic discipline. Another feature is the importance attached to the socio-cultural environment of the Chinese and English languages. The appointee will be required to teach courses in some of the following areas: Computer-aided Translation, Public Relations in Practice, Business Translation, Translation and Technology, Interpreting, Translation and Culture, and English through Subtitles. Excellent command of Chinese and English is a must, and competence in both Cantonese and Putonghua will be an advantage. Further information on the Department and its programmes and activities can be found on the Department’s website: http://www.LN.edu.hk/tran/.
General Requirements
Candidates should have a master degree in Translation Studies or related disciplines and have substantial relevant teaching experience (not less than eight years in universities for Senior Lecturer).
Appointment
The conditions of appointment will be competitive. The rank and remuneration will be commensurate with qualifications and experience. Fringe benefits include annual leave, medical and dental benefits, mandatory provident fund, gratuity, and incoming passage and baggage allowance for the eligible appointee. The appointment will be normally made on a contract basis for up to two years.
Application Procedure (online application only)
Please click "Apply Now" to submit your application before 24 August 2025. Applicants shall provide names and contact information of at least three referees to whom applicant's consent has been given for their providing references. Personal data collected will be used for recruitment purposes only.
We are an equal opportunities employer. Review of applications will continue until the post is filled. Qualified candidates are advised to submit their applications early for consideration.
The University reserves the right not to make an appointment for the post advertised, or to fill the post by invitation or by search. We regret that only shortlisted candidates will be notified."
https://www.timeshighereducation.com/unijobs/listing/396252/senior-lecturer-lecturer-department-of-translation/
#metaglossia_mundus
"How the EU translates
Thursday 17 July 2025
By Sam Morgan
The European Union has 24 official languages and must provide translations of all crucial legislation in those native tongues. It is a mammoth but necessary task.
There are 27 EU members and 24 official languages.
They are: Bulgarian, Croatian, Czech, Danish, Dutch, English, Estonian, Finnish, French, German, Greek, Hungarian, Irish, Italian, Latvian, Lithuanian, Maltese, Polish, Portuguese, Romanian, Slovak, Slovenian, Spanish and Swedish.
Each EU citizen is entitled by law to read official legislation in their native tongue. That means a lot of translation is needed.
Luxembourgish is not counted among the official list, as it is long-standing policy of the Grand Duchy’s government not to seek official status for the language. Austrians speak German and Cypriots speak Greek.
Interestingly, the Cypriot government has flirted with the idea of pushing for Turkish to be accepted as an official language of the EU, but that idea has always turned out to be rather impossible once exposed to the vagaries of politics.
After Brexit, there were some calls for English to be dropped as an official language, but that rather ludicrous idea forgot that it is de facto the lingua franca of the Union, not to mention that it is an official language in both Ireland and Malta.
Irish was initially under a derogation, where only certain top-level legislation was required to be translated into that language. But it has since been lifted, meaning every single one of the 24 tongues have equal status.
Official translations are handled by the various translation departments of the respective European institutions. The Commission’s does a lot of the heavy lifting, translating mostly from English into the 21 other language combinations.
Technology is playing an increasingly important role in translation, as large language models are becoming more sophisticated day by day.
Machine translation is never perfect but for some language combinations can do most of the work, simply requiring post editing by a qualified translator before it can be published.
Experts are divided about how good machines will actually get at translation. Some languages are very poor fits for one another and there is not much material for algorithms to pull from.
For example, the body of translated work between Croatian and Estonian is probably very limited indeed.
English, French and German are the working languages of the EU but every bit of official legislation has to be translated at some point.
For newer member states like Croatian and Bulgarian, that meant employing a whole team of translators to sift through all the existing legislation from the last seventy-odd years of Union activity.
There is also the interesting question of what will happen when the Union adds another member in the future. At the moment there are 552 possible language combinations, if you add one more country, that shoots up to 600.
Would new countries insist on having their language be an official tongue? Montenegrin and Serbian, for example, are extremely similar to Croatian, so would separate translation departments have to be set up?
The politics of language are fascinating and it is one aspect of multilingualism that will not be replaced anytime soon by technology."
https://www.brusselstimes.com/eu-affairs/1664808/how-the-eu-translates
#metaglossia_mundus

"Arabic translations in HK digital publishing soon
2025-07-16 HKT 17:34
Secretary for Culture, Sports and Tourism Rosanna Law said on Wednesday that Hong Kong's enhanced digital publishing initiative will soon incorporate Arabic translations in the hope of strengthening cultural ties with the Middle East.
Law made the announcement at a launch ceremony for Publishing 3.0+, where she highlighted the success of its predecessor, Publishing 3.0.
That project enabled approximately 60 local publishers to convert paper publications into 5,000 bilingual e-books and audiobooks in Cantonese, Putonghua and English, capitalising on digital transformation.
Building on this success, Publishing 3.0+ leverages artificial intelligence to further modernise the industry.
Law said the enhanced initiative will utilise large language models to significantly improve multilingual translations and content conversion capabilities.
"Publishing 3.0+ will refine the e-books and audiobooks converted over the past years and further deliver another 5,000 translated and converted copies of books," she said.
"The fruitful expected outcome of 10,000 e-books and audiobooks will be showcased in Hong Kong pavilions at various international book fairs in the coming months."
Law also confirmed plans to incorporate Arabic translations into the project.
"During my official visit to the Middle East in April this year, I was deeply impressed by the region's rich cultural and historical heritage," she said.
"I am most delighted that Publishing 3.0+ will contribute to our effort to realising closer cultural links and friendship between the Middle East and Hong Kong, aligning the shared visions of both regions."
Sharon Wong, one of the chairs at Publishing 3.0+, said the first phase saw a 75 percent improvement in e-book conversion speed and that the new initiative enhances local publishers’ multilingual capabilities.
"I hope that through this project, we can bring copyright holders, creators and AI developers together and work together in enhancing Hong Kong as a cultural centre or IP trading hub because we are under rapid AI development," she said.
"That is to promote the publishing industry and to promote our cultural product overseas.""
https://gbcode.rthk.hk/TuniS/news.rthk.hk/rthk/en/component/k2/1813620-20250716.htm?spTabChangeable=0
#metaglossia_mundus

The July 14 memo encourages agencies to determine which services would be better operated exclusively in English and to make use of AI where translations are needed.
"Justice pushes agencies to use AI-assisted translations, when offering them at all
By NATALIE ALMSJULY 16, 2025 04:46 PM ET
The July 14 memo encourages agencies to determine which services would be better operated exclusively in English and to make use of AI where translations are needed.
ARTIFICIAL INTELLIGENCE
JUSTICE
The Department of Justice is leading an effort to reduce multilingual services deemed “non-essential” across the government. When translations are needed for government products, DOJ is recommending that agencies use technology to get the job done.
The push to use artificial intelligence and machine learning is part of DOJ’s implementation of a March executive order deeming English the official language of the United States. That order rolled back another decades-old policy requiring agencies to enhance access for people that have limited English proficiency.
Although AI and machine learning could expedite translation work and potentially save the government money, the government’s own how-to resource on translation technology cautions that technology-assisted translations should still involve a human translator.
A new DOJ memo calls for “responsible” AI, but provides little detail on how agencies should address risk.
“Technological advances in translation services will permit agencies to produce cost-effective methods for bridging language barriers and reducing inefficiencies with the translation process,” the new guidance says.
“The Department encourages other agencies to follow its approach of considering responsible use of artificial intelligence and machine translation to communicate with individuals who are limited English proficient,” it continues.
The accuracy of AI-assisted translation generally worsens in more specialized contexts, like when the technology is used for legal or policy documents, according to Sonny Hashmi, the head of global public sector at Unqork and former appointee at the General Services Administration during the Biden administration.
And in these contexts, accuracy especially matters, he said, asking “what is the impact of somebody not understanding the instructions in a form … and as a result, missing out on a benefit that they're otherwise owed?”
Agencies may want to either train bespoke models for these jargony situations, or have people validate the accuracy of translations and offer end users that have questions a clear way to get answers, he said.
The government’s own guide on AI and translation tells agencies to include humans in the process, something the DOJ memo doesn’t reference at all.
Agencies “should not rely solely on automatic machine translation services or computer-aided technology,” reads a government resource on translation technology housed on digital.gov, which is run by GSA. “All translations should be checked by a competent human translator.”
“AI can expedite and save costs substantially,” said Amy Holmes, partner and principal at Holmes Consulting Group, which is focused on data, AI and digital transformation. “But you need to have some guardrails in place to ensure that it’s accurate.”
DOJ offered no comment when asked about risk mitigation.
“You don’t want to just take a generative AI translation tool and just flip it on and assume everything is perfect,” said Michael Boyce, the generative AI lead for the civic tech group U.S. Digital Response, which has collaborated on translation work using generative AI in New Jersey.
Boyce, who formerly directed the AI Corps at the Department of Homeland Security, emphasized the need for testing and user input on AI-assisted translations.
Still, when technology can potentially speed up translations and help improve access, “you also are creating other types of downside risks” when you don’t use the tool to help translate government materials, said Boyce.
Cutting multilingual services
Trump’s March executive order didn’t require agencies to remove or stop creating products in languages other than English. A fact sheet about the order touts flexibility for agencies to decide when and how to offer services in languages other than English.
But Attorney General Pam Bondi’s memo does recommend that agencies determine “which of their programs, grants and policies might serve the public at large better if operated exclusively in English,” where allowed by law.
"The Department of Justice will lead the effort to codify the President’s Executive Order and eliminate wasteful virtue-signaling policies across government agencies to promote assimilation over division,” Bondi said in a statement.
DOJ “will lead a coordinated effort to minimize non-essential multilingual services,” the memo states.
The administration’s Department of Government Efficiency has reportedly already canceled at least ten language or translation service contracts.
Civil rights law requiring language access in federally funded programs and services remains on the books, although the DOJ did rescind its guidance on the matter under the latest memo, which also set in motion new, forthcoming DOJ guidance.
Critics say that the policies will harm taxpayers’ access to government services. The Census Bureau estimates that 8.3% of people in the U.S. have limited English proficiency.
“Diversity is what makes America strong and unique,” Kica Matos, president of the National Immigration Law Center, said in a statement after Trump signed the order in March.
“[This order] is just another notch in Trump’s belt of cruelty and xenophobia that will make it harder for people to understand and access essential services, like education and health care,” she continued."
https://www.nextgov.com/digital-government/2025/07/justice-pushes-agencies-use-ai-assisted-translations-when-offering-them-all/406776/?oref=ng-homepage-river
#metaglossia_mundus
El Centro de Literatura Islandesa, como cada año, dispone una serie de becas de traducción abiertas a editoriales extranjeras que deseen publicar una obra traducida del islandés. En esta ocasión la convocatoria cierra el próximo 15 de septiembre.
"El fondo de traducción del Centro de Literatura Islandesa está abierto hasta el próximo 15 de septiembre
Publicado por Lorenzo Herrero | Jul 8, 2025 | 0
El Centro de Literatura Islandesa, como cada año, dispone una serie de becas de traducción abiertas a editoriales extranjeras que deseen publicar una obra traducida del islandés. En esta ocasión la convocatoria cierra el próximo 15 de septiembre.
El objetivo del fondo es promover la literatura islandesa en el extranjero. Se ofrecen subvenciones para literatura (prosa, poesía y teatro), no ficción de interés general (incluyendo ensayos y biografías), cómics y libros infantiles.
Las solicitudes de apoyo solo pueden presentarse una vez que el solicitante haya adquirido los derechos de la obra y firmado un contrato con el traductor. El Centro de Literatura Islandesa no concederá apoyos a las traducciones publicadas antes de la fecha límite para la presentación de la solicitud.
El formulario de solicitud está disponible...
Las solicitudes pueden realizarse por un máximo del precio de traducción acordado con el traductor. No obstante, por lo general, las ayudas cubren solo una parte del precio de traducción. La subvención a la traducción se aplica exclusivamente a los honorarios base del traductor, no a las regalías ni a una posible parte de las ganancias procedentes de audiolibros o libros electrónicos.
¿Qué debe contener la solicitud?
Se deberán adjuntar al formulario de solicitud los siguientes documentos:
El CV del traductor y los títulos traducidos y publicados previamente. El traductor debe traducir a su lengua materna.
Una copia del contrato con el titular de los derechos en islandés
Una copia del contrato con el traductor
Tres páginas de texto de muestra (traducción) y una copia del mismo texto en el idioma original
¿Cómo se evaluará su solicitud?
Al evaluar una solicitud, se valora la calidad de la obra en cuestión y la cualificación del traductor. Normalmente, se espera que el traductor sea un profesional con al menos una obra traducida, publicada o interpretada, dentro del mismo género que la obra para la que se solicita la subvención. En el caso de la no ficción, el criterio principal del comité es que la obra sea de interés general. No se conceden subvenciones para la traducción de otros tipos de no ficción, como libros de texto educativos..."
https://publishnews.es/el-fondo-de-traduccion-del-centro-de-literatura-islandesa-esta-abierto-hasta-el-proximo-15-de-septiembre/
#metaglossia_mundus

"Abstract: Based on the English-Chinese Parallel Corpus of Children’s Literature and the Corpus of Chinese Children’s Literature, this study investigates the feature of normalization in the Chinese translation of English children’s literature. Normalization refers to the adaptation of foreign features in the source text to comply with the cultural and linguistic norms of the target culture. The study analyzes both macro and micro levels of language features in translated children’s literature, comparing them with original Chinese and English texts. The findings reveal a clear trend towards normalization, evidenced by shorter sentences, increased repetition of high-frequency words, a lower frequency of hapax legomena, and a higher textual readability in translated Chinese versions. Furthermore, linguistic structures such as reduplication, modal particles, “把” (BA), and “得” (DE) constructions are found to occur at rates comparable to or significantly higher than those in the original Chinese corpus. This paper argues that normalization is a creative outcome, molded by translators aligning with reader expectations, conscientiously considering the psychological characteristics of child readers, and adapting to social, cultural, and market influences. The study contributes to understanding linguistic features of translated children’s literature, sheds light on translation universals, and underscores the dynamic interplay between normalization and translator creativity."
Published: 08 July 2025
Normalization or creation? A corpus-based study of normalization in the Chinese translation of English children’s literature
Yang Han
Humanities and Social Sciences Communications volume 12, Article number: 1051 (2025) Cite this article
https://www.nature.com/articles/s41599-025-05379-6
#metaglossia_mundus

"...Taipei, July 8 (CNA) The 2025 Taiwan-Ireland Poetry Translation Competition is now accepting entries, inviting translators worldwide to take on a poem by Taiwanese poet Dong Shu-ming (董恕明), organizers announced Tuesday.
This year's featured work is "Like a Song -- to 107-year-old Mumu on Her Journey"-- an elegy written in a combination of Chinese, Bopomofo, English, and the indigenous Puyuma language, said the National Museum of Taiwan Literature, which co-hosts the event with Trinity College Dublin's Centre for Literary and Cultural Translation.
The poem pays tribute to Dong's grandmother, a 107-year-old elder whose life embodies a century of Puyuma resilience, cultural memory, and multilingual heritage, the museum said.
"Through richly textured imagery, multilingual cadences, and intergenerational echoes, the poem traces mumu's life as a woman of the Pinaski (a Puyuma tribe) community, spanning languages from Puyuma to Japanese to Mandarin and beyond," Trinity said in a press release.
Now in its fifth year, the competition has previously featured poems in Chinese, Taiwanese and Hakka by poets including Tsao Yu-po (曹馭博), Cheng Shun-tsong (鄭順聰), Tseng Kuei-hai (曾貴海), and Temu Suyan (黃璽).
The initiative was launched in 2021 by Trinity College Dublin and the Taipei Representative Office in Ireland.
Winners will be invited to take part in an international online exchange in November 2025 to share insights on translation and creative writing. The deadline for submissions is Sept. 10, 2025.
For more information and to submit your entry, visit: https://lnkd.in/eHdXn6qT
Enditem/AW"
(By Chiu Chu-yin and Lee Hsin-Yin)
July 8, 2025
https://lnkd.in/ewDug4vT
#metaglossia_mundus

Find out why it's a great idea to study English Language and Linguistics in the most linguistically diverse city in Western Europe.
"Linguistics and English Language
Linguistics and English Language
Study
Why study here?
Explore the ways in which English dialects differ, how children learn language, how languages arise, how they change and so much more.
Did you know?
You'll be studying at one of the UK's top four institutions for linguistics.
The Complete University Guide 2020
Linguistics is the ideal subject for analytical minds. You will delve into the science of language - an everyday phenomenon which impacts our lives on an individual and a global scale. English Language covers the history of the English language and the variation between English dialects in the UK and further afield.
Linguistics and English Language at The University of Manchester is unrivalled in its exceptional breadth of subject areas and theoretical approaches.
We are ranked in The Complete University Guide 2019 top 10 universities for Linguistics in the UK.
Opportunities
Access cutting-edge resources, including one of the largest holdings of linguistics texts in the UK
Conduct research using English manuscripts held in our prestigious Special Collections
Work in close collaboration with internationally renowned experts
Conduct fieldwork and analyse linguistic corpora
Study in the most linguistically diverse city in Western Europe – home to over 150 languages
Specialist master's exploring the full breadth and depth of linguistic theory
Become the best you can be by participating in Stellify for true personal and professional growth.
Careers and employability
Study Linguistics and English Language at Manchester and you will develop a range of analytical and problem-solving skills that can be applied to many careers.
The University of Manchester is also the most targeted university in the UK for top graduate employers, according to High Fliers Research..."
https://www.humanities.manchester.ac.uk/linguistics-and-english-language/study/why-study-here/
#metaglossia_mundus

A few years ago a controversy arose at UNH over American Sign Language. For a long time the introductory course in it had two or three sections, but suddenly the sections ballooned to eight or ten.
"Speaking of Words: Is ASL a Language?
A few years ago a controversy arose at UNH over American Sign Language. For a long time the introductory course in it had two or three sections, but suddenly the sections ballooned to eight or ten. A commission was set up to look into the reasons for this surprising jump in students. Were they all really interested in communicating with deaf people? Students planning to be social workers had long been taking a year of ASL to help them in their future work, but these new students were not making such plans.
What we found out is that a lot of students had learned it was easy to get a good grade in a year-long course in ASL and thereby dispose of the foreign-language requirement for the BA. A survey showed that the average grade was A- and the amount of homework very modest; with twice as much homework students in first-year Spanish were earning an average grade of B-. This seemed unfair, somehow, but what could be done? I was appointed to the commission, so I read several books about ASL, watched videos, and listened carefully to a colleague on the commission who was a native signer as well as native speaker of English and a professor of linguistics at UNH Manchester. I did not master ASL, but I learned a lot about it.
Indepth Your Inbox
Get unbiased nonprofit watchdog news sent directly to your inbox.
Your Email
As I discussed the problem in my own department (English) and the Languages Department I found there was a good deal of ignorance about it, some of which I had shared before joining the commission. Some thought that ASL was the same as “signing English,” that is, spelling out English with manual equivalents of letters, something like Braille or Morse Code. Such a thing exists, but that is not ASL, which is in no way dependent on English or on any other spoken language. The fact that it is called American Sign Language means only that it is the sign language used by the deaf in America (and Canada outside Quebec). Some signers of ASL do not know English at all, though most have learned to read and write English, and some to lip-read it, and some to vocalize it.
ASL is a language in its own right. It is a “natural language” like English and Urdu. It is not a pidjin, which is a limited system constructed by adults to communicate across two or more languages; it is more like a creole, which is typically the product of children. ASL, and the other sign languages around the world, were created by deaf people, with at least a large input by children signing it as their first language.
Anyone studying it as a second language will be struck at how differently the words are ordered from the way they are in English. The train of signs usually begins with the topic, not what we call the grammatical subject. For example, “Do you have many children?” would begin with children: CHILDREN + HAVE + MANY? + YOU. The YOU (pointing a finger) may be left out, of course, as it may be implied by the situation, and the question may be indicated by a raised eyebrow.
Sometimes the word order reflects the actual sequence of events: NEW YORK + THERE + HOTEL + ARRIVE + FINISH + TIRED + I = “I was exhausted by the time I arrived at the hotel in New York.” FINISH is a sign that indicates the completed aspect of the preceding verb, making it similar here to the English past tense. The “I” at the end is another pointing finger, very possibly omitted.
There is a lot of pointing in ASL, of course, and it means that it can incorporate a large number of pronouns. If you are telling a long story about your family gathering at Christmas, the first time you mention your mother you sign MOTHER and point to a space on one side of the line of sight between you and the one you are signing to. When you first mention your father, your aunt, your sister, your brother, you assign them each to a unique spot on one or the other side of the line. Further mentions of the same people require just pointing to the right spot. In English “she” would be confusing, since it might refer to your mother, aunt, or sister, but in ASL they are differentiated in space. ASL has no problem either with the non-binary “they/them”: that non-binary person gets their own little spot in space waiting to be pointed at when needed.
Signing is done with the face as well as the hands. In a spoken language we can add quite a bit with hand gestures, tones of voice, and a few facial expressions as well, but ASL enlists the face in important ways, often as adverbs modifying the verb. An expression of disgust or contempt, with the tongue between the teeth like a strong th-sound, means “carelessly.” So “John does his homework” as a neutral fact would be JOHN + WRITES + HOMEWORK. But to say “John does his homework carelessly” (or “John blows off his homework”) would be JOHN + th-WRITES + HOMEWORK, where the th-gesture with the tongue is made during the manual sign for WRITE.
I have taken these examples from the books I read while serving on the commission. I did not learn enough or practice enough to talk with a deaf person, but I gained a lot of admiration for the community that created ASL and continually adds to it in brilliant and often witty ways. As for the unusual problem at UNH, it was pretty much resolved when it was discovered that each department in the College of Liberal Arts can decide if ASL counts as the language requirement for their majors. English and many other departments decided not to count it, though the linguistics majors may take it as their second foreign language requirement. Certainly, if you are studying English literature, knowing some French or Latin is more useful than knowing ASL. But students who really care about it can still study it, and if they really care about it they will grow a new and wonderful visual language in their head.
I am happy to hear from readers: mferber@unh.edu. If any of them know ASL and can correct any mistakes, I would be especially glad to learn from them.
Michael Ferber moved to New Hampshire in 1987 to join the English Department at UNH, from which he is now retired. Before that he earned his BA in Ancient Greek at Swarthmore College and his doctorate in English at Harvard, taught at Yale, and served on the staff of the Coalition for a New Foreign Policy in Washington, DC. In 1968 he stood trial in Federal Court in Boston for conspiracy to violate the draft law, with the pediatrician Benjamin Spock and three other men. He has published many books and articles on literature, and has a deep interest in linguistics. He is married to Susan Arnold; they have a daughter in San Francisco."
https://indepthnh.org/2025/07/16/speaking-of-words-is-asl-a-language/
#metaglossia_mundus

"Xi jinping likes to call the world’s dependence on advanced Chinese technologies his shashou jian. He means it’s the ace up China’s sleeve, but translated literally into English, shashou jian is “assassin’s mace”.
Translation has been an issue since the beginning of America’s formal relationship with Communist China. And as relations between the two great powers enter a less-predictable phase, linguistic sleight of hand has the potential to become more consequential..."
Jul 15th 2025
https://www.economist.com/podcasts/2025/07/15/lost-in-translation-how-language-complicates-us-china-relations
#metaglossia_mundus

Recent federal reductions in funding for language assistance and President Donald Trump’s executive order designating English as the official language of the United States have som⁵e health advocates worried that millions of people with limited English proficiency will be left without adequate support and more likely to experience medical errors.
"Lost in Translation: Interpreter Cutbacks Could Put Patient Lives on the Line
By Vanessa G. Sánchez
JULY 16, 2025
Federal law entitles patients to interpreters if they don’t have a strong grasp of English. KFF Health News correspondent Vanessa G. Sánchez appeared on WAMU’s “Health Hub” on July 9 to explain why some Trump administration policies are leaving patients fearful to ask for language services.
Patients need to communicate clearly with their health care provider. But that’s getting more difficult for those in the U.S. who don’t speak English.
Budget cuts by the Trump administration have left some providers scrambling to keep qualified medical interpreters. And an executive order designating English the official language of the United States has created confusion among providers about what services should be offered.
Patients who don’t speak English are left afraid, and perhaps at risk for medical mistakes. What happens when those who need help are too frightened to ask?
In WAMU’s July 9 “Health Hub” segment, KFF Health News correspondent Vanessa G. Sánchez explained why health advocates worry these changes could lead to worse patient outcomes."
https://kffhealthnews.org/news/article/medical-interpreter-funding-staff-cuts-patient-lives-english-language-services/
#metaglossia_mundus
"Nevada needs court interpreters. See if you qualify
LAS VEGAS (KLAS) — An urgent need for qualified court interpreters exists in Nevada as the demand for language services grows.
Nevada courts handled more than 3,100 cases in 2024 that relied on interpreters to help participants understand and engage in legal proceedings, according to a Tuesday news release.
The Supreme Court of Nevada invites bilingual individuals to explore opportunities in the justice system as certified court interpreters. Registration for the Fall 2025 Certified Court Interpreter Exam is now open. The deadline to register for the Oct. 20 exam is approaching: Sept. 22.
The most requested languages last year were Spanish, Tagalog, Cantonese and Vietnamese. Court officials said Nevada had only 79 certified Spanish court interpreters, with an urgent need for more.
“Court interpreters make the justice system accessible for thousands of Nevadans,” Amanda Walker, Language Access Program administrator, said. “We’re asking bilingual residents to be part of this essential public service.”
Interpreters licensed in other states may be eligible.
Oral exams are scheduled in Las Vegas (Nov. 3-7) and in Carson City (Nov. 10, Nov. 12). Written exams are scheduled on Nov. 7 in Las Vegas and Nov. 10 in Carson City. Find more information and a self-assessment tool online to evaluate your readiness before registering.
To become a certified court interpreter in Nevada, applicants must complete an online Written Orientation Workshop, available mid-July. This virtual workshop introduces candidates to Nevada’s judicial system, court interpreting standards, and interpreter ethics.
Applicants must also pass the written exam with a minimum score of 80 percent. The test is two hours and 15 minutes long and includes 135 multiple-choice questions that cover language proficiency, legal terminology, and professional conduct."
by: Greg Haas
Posted: Jul 15, 2025 / 11:56 AM PDT
Updated: Jul 15, 2025 / 11:56 AM PDT
https://www.8newsnow.com/news/local-news/nevada-needs-court-interpreters-see-if-you-qualify/
#metaglossia_mundus
"English-only: DOJ announces plan to phase out costly translations
WASHINGTON, D.C., (KTAL/KMSS) – The federal government will soon eliminate what it calls “wasteful virtue-signaling policies” involving multilingual services.
On Monday, President Trump’s Executive Order No. 14224 established English as the official language of the United States, and Attorney General Pam Bondi wasted no time asserting that the DOJ would follow suit and eliminate what she sees as costly translations “to promote assimilation over division.”
To comply with the president’s EO, Bondi said her department will rescind prior Limited English Proficiency (LEP) Guidance, passed during the Clinton Administration, which prohibited national origin discrimination affecting people with limited English proficiency.
The DOJ will also conduct an internal inventory of all existing non-English services and release a plan to phase out “unnecessary multilingual offerings” Department-wide. AG Bondi said the DOJ will temporarily suspend the operation of LEP.gov and other public-facing materials related to language access for individuals with LEP, including letters, internet posts, YouTube videos, and training materials, pending internal review.
Within 60 days, the DOJ will solicit input and recommendations from other federal agencies regarding programs and policies that can be implemented in an English-only format. This new guidance will help agencies prioritize English while explaining when and how to implement multilingual assistance as needed to fulfill the missions of federal agencies.
Recommended actions for communicating with those with limited English proficiency
Machine learning translations using AI are recommended as a cost-effective measure to facilitate communication with individuals who have limited English proficiency.
Consider English-only services where allowed by law, to consider programs, grants and policies would serve the public better if they were English-only.
Disclaimers announcing that English is the official language of all federal information.
Redirect funds that were used for LEP translation initiatives toward research and programs that will improve English proficiency.
President Trump’s Executive Order rescinds Executive Order No. 13,166, signed by President Clinton on August 16, 2000. Executive Order No. 13,166 directed agencies to enhance access to federal programs for persons with limited English proficiency and required tailored guidance for recipients of federal funding, straining federal resources and impeding the assimilation of new Americans, AG Bondi said in the DOJ announcement."
by: Marlo Lacen
Posted: Jul 15, 2025 / 11:13 AM CDT
Updated: Jul 15, 2025 / 03:04 PM CDT
https://www.ktalnews.com/news/u-s-world/english-only-doj-announces-plan-to-phase-out-costly-translations/
##metaglossia_mundus
|